目标检测-动手学计算机视觉12
前言
目标检测(object detection)是计算机视觉中的一个核心问题,其目的是识别图像中每个目标的类别并且对它们进行定位。定位(localization)即确定目标的位置和尺寸,通常需要勾勒出目标轮廓的包围盒(bounding box),确定该包围盒的中心点坐标及宽和高。

图12-1展示了一个目标检测的例子,图中的“人”“玩具”和“椅子”被识别出来,它们的包围盒也被勾勒出来。由于目标检测的输出是包围盒这种形状规则的矩形,在工业领域中对下游业务适用性高,所以得到广泛应用,例如辅助驾驶系统中的感知模块的输出就是检测到的目标的包围盒。在本章中,我们将介绍基于深度学习的目标检测方法,并动手实现相应的目标检测框架。
数据集和度量
常用于目标检测的数据集包括:PASCAL VOC、MS COCO和ImageNet,其中PASCAL VOC和ImageNet数据集在之前的章节中已经介绍过,此处不再赘述。
MS COCO(Microsoft common objects in context)数据集是一个广泛用于计算机视觉任务的大型数据集,于2014年由微软发布。它主要用于目标检测、分割、关键点检测和图像描述生成等任务。MS COCO数据集的目标是为了推动计算机视觉技术在更复杂的场景中的发展。 MS COCO数据集有以下特点。
(1)图像数量多:数据集包含了约20万幅标注过的图像,以及约13万幅未标注的图像。
(2)类别和来源丰富:图像涵盖了80个类别的物体,如动物、交通工具、家具等,同时图像来源丰富,包括从网络上抓取的图像、街景图像和室内图像等。
(3)场景复杂:数据集中的图像包含了各种复杂的场景,如拥挤的市场、交通堵塞的道路等,这对计算机视觉模型提出了较高的挑战。
最常用的目标检测评价指标是全类平均精度(mean average precision,mAP)。从mAP的命名可以看出,这是一个定义在每个类别上的精度指标。因此在定义AP之前,需要先定义一个目标是否被检测到的准则。对于图像中的一个目标,令其真实的(ground-tuth)包围盒内部的像素集合为A,一个预测的包围盒内部的像素集合为B,通过这两个包围盒内像素集合的交并比,来定义两个包围盒的重合度,
在目标检测中,IoU也称为Box IoU。给定一个阈值0,如果IoU(A,B)>0,则认为B所属的预测包围盒命中了该目标:反之,则认为B所属的预测包围盒并未命中该目标。根据这个基于IoU的准则,给定一种类别,对每个预测类别为该给定类别的预测包围盒,如果它内部的像素集合与某个类别标签为该给定类别的真实包围盒内部的像素集合之间的IoU大于给定阈值,则这个预测包围盒是真阳性(true positive,TP);如果其内部的像素集合与任意一个类别标签为该给定类别的真实包围盒内部的像素集合的IoU都小于给定阈值,那么这个预测包围盒是假阳性(false positive.,FP);如果一个类别标签为该给定类别的真实包围盒中的目标没有被任何预测包围盒命中,那么这是假阴性(false negative,FN)。这样,对每幅图像的检测结果,可以计算出对于该给定类别的查全率(recall)即正确检测相对于所有真实包围盒的比例,以及查准率(precision,也称为精度),即正确检测相对于所有预测包围盒的比例
总结:
其定义为两个区域的交集面积与并集面积之比
用于衡量模型识别正类样本的能力
用于衡量模型预测为正类的样本中有多少是真正的正类
应用场景
- 高Recall优先:在医疗诊断或安全检测中,漏检(FN)的代价较高,需尽可能识别所有正类。
- 高Precision优先:在垃圾邮件过滤中,误判(FP)会影响用户体验,需确保预测为正类的样本尽可能准确。
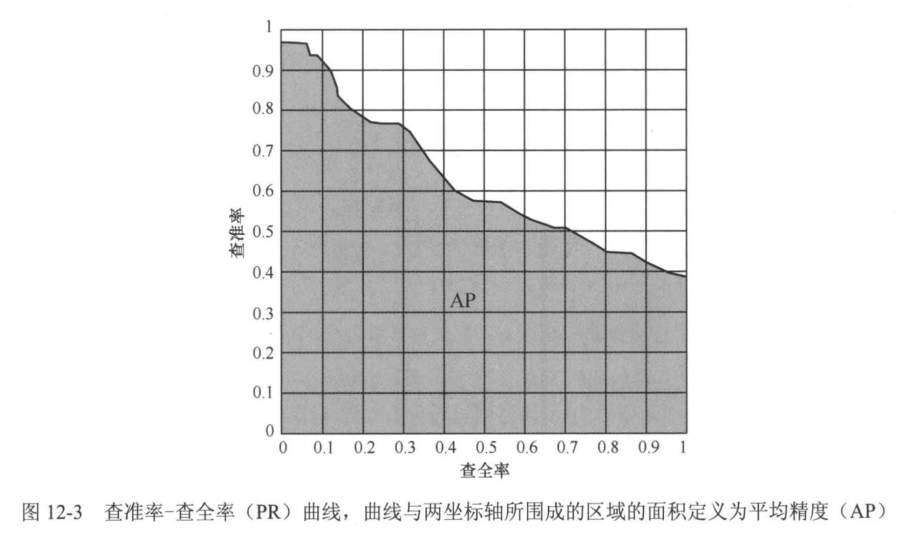
注意,由于预测包围盒是否命中真实包围盒中的目标由IoU阈值决定,通过调整IoU阈值,会得到不同的查全率和查准率。通过将IoU的阈值从0慢慢调大至1,可以得到一个序列的查全率和查准率对。那么,基于这样一个查全率和查准率对的序列,可以做出一条查准率-查全率(precision-recall,PR)曲线,如图12-3所示。PR曲线与两坐标轴所围成的区域的面积定义为平均精度(average precision,AP),而mAP是指各个类别AP的平均值。
目标检测模型
虽然在2012年Geoffrey Hinton和他的学生提出了AlexNet(见第11章),证明了深度卷积神经网络在图像分类上的突出性能,开启了计算机视觉的深度学习时代,但是在接下来的一两年里,研究人员并没有找到能够有效解决目标检测这一视觉识别任务的深度学习模型。这是因为,目标检测过程通常基于滑动窗口(sliding window)的策略,即用窗口(这种窗口就是一种预测包围盒)在图像上滑动,滑动到一个位置,就通过一个分类器去判断该位置窗口内是否存在目标。由于目标大小是未知的,这种滑动窗口策略需要在图像上每个位置尝试多种尺寸的窗口,每幅图总共需要尝试的窗口数可能高达数十万甚至数百万。如果用卷积神经网络作为窗口分类器,那么一幅图像的处理时长可能都需要数小时。这种处理速度是无法接受的。是否有办法提升这种基于滑动窗口的目标检测速度呢?2014年,Ross Girshick等人给出了解决方案一区域卷积神经网络(region convolutional neural network,R-CNN))。他们提出,不必遍历所有位置所有尺寸的窗口,只需要找到可能存在目标的候选窗口,然后用卷积神经网络对这些候选窗口做分类就可以了。那么,如何找到可能存在目标的候选窗口呢?在2010年左右,候选目标检测(object proposal detection)[2的问题被提出,即不关心目标的类别是什么,只从图像中快速找到可能存在目标的区域即可,这些区域称为候选区域(region proposal)。候选区域所属的包围盒即是候选窗口(通常候选区域是矩形区域,这种情况下候选区域就是候选窗口,本章默认这两者等价)。
候选区域可能存在目标的置信度称为objectness。.基于候选目标检测可以找到可能存在目标的候选窗口,而这些候选窗口的数量远远小于所有滑动窗口的数量。这便是R-CNN改善检测速度的基本思想。2014年,R-CNN在PASCAL VOC检测数据集上以绝对优势获得第一名,为目标检测开启了一个新的里程碑。
随后Girshick等人又对R-CNN做了进一步改进和优化,提出了Fast R-CNN和Faster R-CNN,不但进一步提升了检测速度,也提升了检测精度。
R-CNN
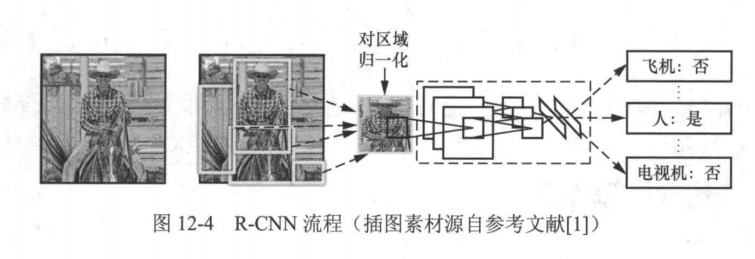
R-CNN是基于深度学习进行目标检测的开山之作,其流程如图12-4所示。可大致分为以下几个步骤:
(1)从输入图像中提取1000~2000个候选区域:
(2)利用深度卷积神经网络(CNN)提取每个候选区域的特征;
(3)基于提取的深度卷积特征,利用SVM分类器对每个候选区域进行目标类别识别:
(4)基于提取的深度卷积特征,利用包围盒回归器修正候选区域的位置与尺寸。
R-CNN是基于深度学习的方法,所以包括训练和测试两个阶段。R-CNN的这两个阶段大体上遵循上述的步骤,但也略有不同。接下来,我们分别详细介绍R-CNN的训练阶段和测试阶段。在训练阶段,首先利用候选目标检测方法,如Selective Search,在每幅训练图像上提取 1000~2000个候选区域:接着,把所有候选区域归一化成相同的空间分辨率,如227像素×227像素,然后训练一个CNN用于提取这些候选区域的特征;此阶段中用到的Selective Search是一种经典的候选目标检测方法。它通过第9章中介绍的图像分割方法得到图像中的一些分割区域,然后基于区域特征,如颜色、亮度和纹理等,分层次合并区域,从图像中提取出可能包含目标的候选区域。
用于提取候选区域特征的CNN一般是常用的主干网络,如AlexNet、VGG、ResNet等。这些主干网络已在ImageNet数据集完成预训练,
在R-CNN的训练过程中需进行再训练。具体操作时,首先为每个候选区域分配类别标签u∈C。对于第n幅训练图像r中的候选区域R,其像素集合为R。我们首先确定与该候选区域IoU(交并比)最高的真实边界框:m=argmax IoU(R,B(m)),其中B(m)表示真实边界框bm的像素集合。该候选区域的类别标签u按以下规则确定:
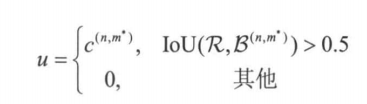
u=0说明该候选区域对应的是背景,因为没有任何一个真实包围盒和它的重合度足够大。对每个候选区域赋予类别标签后,便可以基于该赋予的类别标签以图像分类为目标训练主干网络(训练方法参见10.4节中介绍的图像分类算法)。训练结束后,利用训练好的主干网络提取每个候选区域的特征。最后,基于主干网络提取的特征对每个类别训练一个SVM分类器,用于每个候选区域的类别标签预测。

R-CNN还引入了包围盒回归器来优化候选区域的位置和尺寸。之所以需要这种调整,是因为初始候选区域往往与真实包围盒存在偏差。如图12-5所示:实线框代表目标物体的真实包围盒,虚线框为预测结果,需要通过调整使虚线框更接近实线框。
R-CN测试阶段的步骤和训练阶段类似。给定一幅测试图像,同样也是用候选目标检测方法提取1000~2000个候选区域,然后将它们的空间分辨率归一化到227像素×227像素。接着用训练好的主干网络提取这些候选区域的特征。基于提取的候选区域特征,用训练好的SVM分类器和包围盒回归器分别预测每个候选区域的目标类别和微调其位置及尺寸。因为通常检测得到的预测包围盒的数量非常多,其中存在很多误检,所以测试阶段比训练阶段多一个关键步骤一非极大值抑制(NMS),用以去除冗余的预测包围盒:对于每个类别,先挑选出置信度最大的预测包围盒(该置信度可以是SVM分类器输出的类别概率),设其内部像素集合为A,并计算与其他预测包围盒内部像素集合(如B)之间的重合度IoU(A,B)。若IoU(A,B)大于给定的阈值,则删去B所属的预测包围盒。然后挑选出下一个置信度最大的预测包围盒,重复上述过程,如此遍历所有剩下的类别为该目标类别的预测包围盒,便得到该类别的最终检测结果,如图12-6所示。

Fast R-CNN
R-CNN的思路虽然很直接,但很明显也存在着许多问题:
(1)对于每幅图像中的每个候选区域都要利用主干网络计算一次特征,而一幅图像通常有 2000个候选区域,计算效率低:
(2)候选区域之间重叠较多,进行特征提取时存在重复计算;
(3)R-CNN的训练阶段包含多个训练过程(主干网络的训练、SVM分类器及包围盒回归器的训练),而这些训练过程并不是端到端的,即目标类别分类和包围盒回归的结果无法反馈给前端的主干网络用以更新网络参数。
为解决这些问题,Ross Girshick于20l5年提出了Fast R-CNN。Fast R-CNN的设计更为紧凑,极大提高了目标检测速度。使用VGG16作为主干网络时,与R-CNN相比,Fast R-CNN在PASCAL VOC2007上的训练时间从84h缩短到9.5h,每幅图像的测试时间从47s缩短到 0.32s。相较于R-CNN,Fast R-CNN有两个重大改进:
(1)不再对每个候选区域单独提取特征,而是在提取整幅图像的特征图后,直接从特征图提取每个候选区域的特征,避免了多次用主干网络计算特征的过程;
(2)Fast R-CNN的候选区域特征提取与分类器及回归器的训练是一个端到端的过程,分类和回归的结果可以反馈给主干网络用以更新网络参数。
实现这两个改进的关键是引入一个感兴趣区域(region of interest,ROI)特征提取器。
ROI池化简介
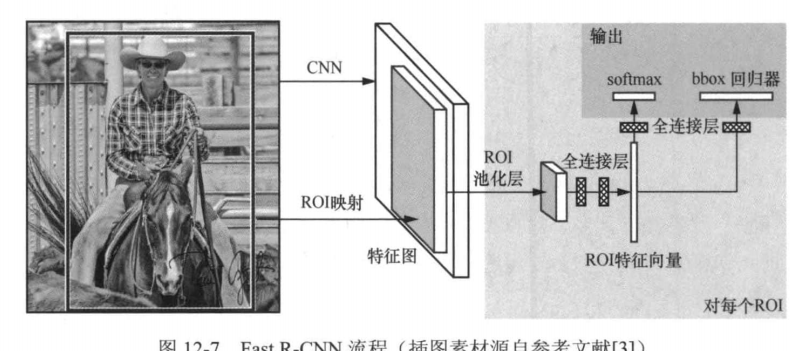
ROI(Region of Interest)池化是一种用于目标检测任务的特征提取技术,主要作用是将不同尺寸的感兴趣区域(ROI)转换为固定大小的特征图。ROI池化通常用于Faster R-CNN等模型中,能够有效处理输入图像中不同尺度和长宽比的候选区域。
ROI池化的数学表达
给定一个ROI区域,其宽度为w、高度为h,目标池化尺寸为。ROI池化将输入区域划分为
个子窗口,每个子窗口的大小为
,并对每个子窗口内的特征值执行最大池化操作。
ROI池化的实现步骤
-
输入特征图与ROI坐标
输入为一个特征图和一组ROI坐标
,其中
为左上角坐标,
为右下角坐标。
-
划分子区域
将ROI区域划分为个子窗口,每个子窗口的尺寸为
-
最大池化操作
对每个子窗口内的特征值取最大值,得到固定尺寸
代码示例
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ROIPool(nn.Module):def __init__(self, pooled_height, pooled_width, spatial_scale):super(ROIPool, self).__init__()self.pooled_width = pooled_widthself.pooled_height = pooled_heightself.spatial_scale = spatial_scaledef forward(self, features, rois):batch_size, num_channels, _, _ = features.size()num_rois = rois.size()[0]output = torch.zeros(num_rois, num_channels, self.pooled_height, self.pooled_width)for roi_idx, roi in enumerate(rois):batch_idx = int(roi[0])x1, y1, x2, y2 = roi[1:].mul(self.spatial_scale).int()roi_features = features[batch_idx, :, y1:y2, x1:x2]roi_height, roi_width = roi_features.shape[1:3]bin_h = roi_height / self.pooled_heightbin_w = roi_width / self.pooled_widthfor ph in range(self.pooled_height):h_start = int(ph * bin_h)h_end = int((ph + 1) * bin_h)for pw in range(self.pooled_width):w_start = int(pw * bin_w)w_end = int((pw + 1) * bin_w)pool_region = roi_features[:, h_start:h_end, w_start:w_end]output[roi_idx, :, ph, pw] = pool_region.max(dim=-1)[0].max(dim=-1)[0]return output
ROI应用场景
ROI池化主要用于目标检测任务中,将不同尺寸的候选区域映射为固定长度的特征向量,便于后续的分类和回归任务。其优点是能够保留空间信息,同时减少计算量。
Faster R-CNN
尽管Fast R-CNN相较于R-CNN在测试时间上实现了显著的提升,从每幅图像的47s缩减至0.32s,测试速度提升了146倍,但需要注意的是,这个测试时间并未包含候选区域提取所用的时间。实际上,候选区域提取过程正是目标检测速度的瓶颈所在。
为了进一步提升目标检测的速度,任少卿、何恺明、Ross Girshick和孙剑于2015年提出了 Faster R-CNN。该方法通过引入候选区域网络(region proposal network,RPN)实现了高效的候选区域提取,将目标检测的测试时间缩短到每幅图分类器像0.2s(包含候选区域提取过程),相较于R-CNN实现了近250倍的速度提升。
相较于Fast R-CNN, Faster R-CNN通过RPN直接从图像的特征图生成若 ROI池化干候选区域,取代了之前传统的候选目标检测方法候选区域(如Selective Search),实现了端到端的训练模式。简单地说,Faster R-CNN可以被理解为“RPN+Fast R-CNN”,其整体流程如图12-9所示
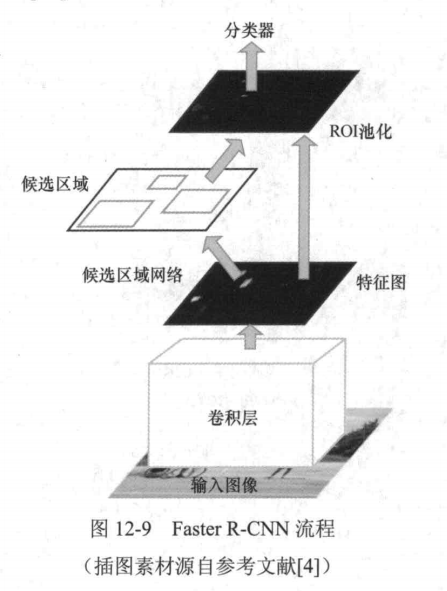
主要包括以下两特征图个步骤:
(1)通过RPN从输入图像中提取候选区域:
(2)基于Fast R-CNN的框架对这些候选区域进卷积层行目标类别分类与包围盒回归:输入图像 RPN是Faster R-CNN中引入的核心模块,它采图12-9 Faster R-CNN流程用轻量级的卷积神经网络作用于特征图上,利用卷积操作的滑动窗口特性,实现了滑动窗口检测策略,从而取代了传统的候选区域生成方法,其过程如图12-10所示。
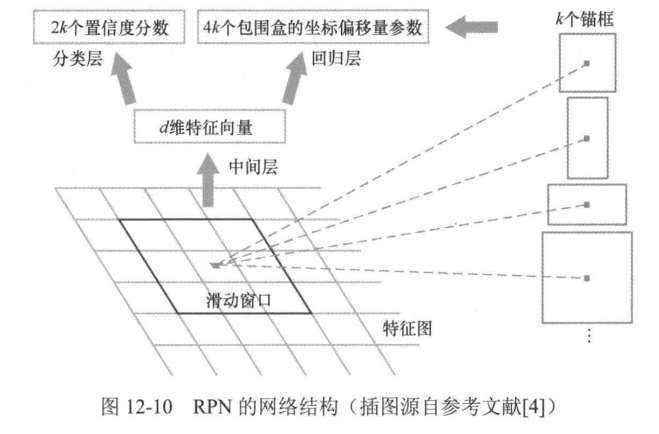
RPN以主干网络中的卷积层输出的特征图为输入,利用轻量级的卷积神经网络在特征图上滑动,每滑动到一点处,将以当前点为中心的空间分辨率为s×s(一般s=3像素)的滑动窗口内的特征映射成一个维度为d(通常, d=256或者512)的特征向量。该特征向量被输入到两个并行的全连接层一一个分类层和一个回归层,实现候选区域生成。注意,目前我们只提及了候选区域的位置,即当前滑动窗口的中心,而候选区域的尺寸仍然是未知的。
为此,RPN中引入了一个重要概念一锚框(anchor)。锚框是居中于当前滑动窗口的一个矩形区域,通过预定义的尺寸和高宽比确定其空间分辨率。这样,上述分类层输出两个分数,即当前锚框中存在目标的置信度和不存在目标的置信度;回归层输出4个包围盒的坐标偏移量参数,即当前锚框(锚框是矩形区域,也是一个包围盒)与其对应目标的真实包围盒之间的坐标偏移量。由于图像中的目标尺寸是未知的,为了实现多尺寸目标检测,RPN在特征图的每个点生成多个候选区域,生成的候选区域个数k由预定义的锚图像中锚框的总数为HxWxk个。
RPN
Faster R-CNN同样包括训练和测试两个阶段。在训练阶段,相比Fast R-CNN的训练阶段, Faster-CNN增加了RPN的训练。类似于R-CNN和Fast R-CNN的训练过程,为了训练RPN,需要给每个锚框赋予一个真实类别标签,该真实类别标签是一个二类标签,表示该锚框中是否存在需要检测的目标。真实类别标签的赋予仍然基于IoU的准则。满足以下两个条件之一,一个锚框就可以被赋予正的真实类别标签(该锚框为正锚框,其中存在需要检测的目标):
(1)该锚框内部的像素集合与某个真实包围盒内部的像素集合之间的IoU是所有锚框中最大的:
(2)该锚框内部的像素集合与任意一个真实包围盒内部的像素集合之间的IoU大于0.7。
通常来说,根据条件2已经足够确定一个锚框的真实类别标签为正标签,但在有些极端情况下,对一个真实包围盒,可能无法找到任何一个锚框满足条件2,这时就需要条件1作为补充。如果一个锚框不满足上述任意一个条件,并且该锚框内部的像素集合与每个真实包围盒内部的像素集合之间的IσU都小于0.3,那么这个锚框将被赋予负的真实类别标签(该锚框为负锚框,其中不存在需要检测的目标)。如果一个锚框既没有被赋予正标签,也没有被赋予负标签,那么这个锚框将不参与RPN的训练过程。 RPN也为每个锚框指定了一个真实包围盒,用于后续包围盒回归任务。
具体而言,首先计算每个真实包围盒内部的像素集合与所有锚框内部的像素集合的IoU,找到最大IoU对应的真实包围盒与锚框,并将它们匹配;接着,对剩下未匹配的锚框,先寻找与其内部的像素集合IoU最大的像素集合对应的真实包围盒,若该IoU大于设定的阈值(一般为0.5),则将该真实包围盒匹配给该锚框。反之,则不进行匹配。
Faster R-CNN在测试阶段的步骤与训练阶段类似,也是包含了上述几个步骤。对一幅测试图像,Faster R-CNN先利用RPN生成一系列候选区域,利用NMS对这些候选区域进行筛选,后利用Fast R-CNN对这些候选区域进行包围盒的预测。
Faster R-CNN 代码
由于Faster R-CNN代码规模比较大
我们将直接调用相关接口进行效果展示。先导入必要的包,并使用在MS COCO数据集上预训练的ResNet50作为主干网络。
微软发布的 COCO 数据库是一个大型图像数据集, 专为目标检测、分割、人体关键点检测、语义分割和字幕生成而设计,用于Object Detection + Segmentation + Localization + Captioning。
下载链接如下,数据包括了物体检测和keypoints身体关键点的检测:
MSCOCO不需要下载
> 当然我们运行代码是在已经pretained的模型上进行的,如果你想自己训练模型的话可以用下载MSCOCO自己训练,前提是你的算力足够
安装
安装 COCO API
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
克隆 PyTorch Vision 并复制文件
git clone https://github.com/pytorch/vision.git
cd vision
cp references/detection/utils.py ..
cp references/detection/transforms.py ..
cp references/detection/coco_eval.py ..
cp references/detection/engine.py ..
cp references/detection/coco_utils.py ..
我们在ImageNet_数据集-飞桨AI Studio星河社区数据集上面进行验证模型效果
Faster R-CNN具体代码
import os
import cv2
import numpy as np
import torch
import torchvision
import matplotlib.pyplot as plt# 加载预训练的 Faster R-CNN 模型(基于 MS COCO 数据集)
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)# 将模型移动到 GPU 或 CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)# COCO 数据集的类别名称(91 类)
COCO_CLASSES = ['__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus','train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign','parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow','elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella','handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard','sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard','surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork','knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange','broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair','couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv','laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave','oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase','scissors', 'teddy bear', 'hair drier', 'toothbrush'
]# 定义目标检测函数
def obj_detect(img_path):# 读取图像并转换为 RGB 格式img = cv2.imread(img_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)# 归一化图像像素值到 [0, 1] 范围img /= 255.0# 将图像转换为 PyTorch 张量(HWC 转 CHW 格式)img = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0) # 形状: [1, 3, H, W]# 将图像张量移动到指定设备(GPU 或 CPU)img = img.to(device)# 设置模型为评估模式model.eval()# 设置置信度阈值,过滤低置信度的预测threshold = 0.5# 执行预测(禁用梯度计算以节省内存)with torch.no_grad():pred = model(img)# 提取预测结果boxes = pred[0]['boxes'].cpu().numpy() # 边界框坐标scores = pred[0]['scores'].cpu().numpy() # 置信度分数labels = pred[0]['labels'].cpu().numpy() # 类别标签# 过滤低置信度的预测keep = scores > thresholdboxes = boxes[keep]scores = scores[keep]labels = labels[keep]# 返回检测结果return boxes, scores, labels# 定义 ImageNet 验证集的路径
pred_path = "ImageNet/imagenet/val/"
if os.path.exists(pred_path) == False:print("ImageNet 验证集路径不存在!")exit()
pred_files = [os.path.join(pred_path, f) for f in os.listdir(pred_path)]# 设置绘图画布
plt.figure(figsize=(20, 60))
image_list = [0, 11, 17, 28] # 指定要显示的图像索引# 遍历图像文件
for i, image_path in enumerate(pred_files):if i > 30: # 限制处理的图像数量breakif i not in image_list: # 跳过不需要显示的图像continue# 执行目标检测boxes, scores, labels = obj_detect(image_path)# 读取图像用于可视化img = cv2.imread(image_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 绘制边界框和类别标签for j, box in enumerate(boxes):cv2.rectangle(img, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 220, 0), 2)label_name = COCO_CLASSES[labels[j]] if labels[j] < len(COCO_CLASSES) else str(labels[j])cv2.putText(img, f"{label_name} {scores[j]:.2f}", (int(box[0]), int(box[1]) - 5),cv2.FONT_HERSHEY_COMPLEX, 0.7, (220, 0, 0), 1, cv2.LINE_AA)# 显示图像plt.subplot(10, 2, image_list.index(i) + 1)plt.axis('off')plt.imshow(img)plt.show()

当然你也可以替换预测头为21类来匹配ImageNet数据集,不过检测效果很差
因为如果要检测 20 个 VOC 类
-
必须用 VOC 数据集重新训练 或微调这个新预测头。
-
加载 COCO backbone 权重,但新预测头要训练,否则它不会输出有意义的结果。
import os
import cv2
import numpy as np
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
import matplotlib.pyplot as plt# 加载预训练的 Faster R-CNN 模型(基于 MS COCO 数据集)
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 21 # 20 个类别 + 背景
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 替换模型的预测头以匹配自定义类别数
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)# 将模型移动到 GPU 或 CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)# 定义目标检测函数
def obj_detect(img_path):# 读取图像并转换为 RGB 格式img = cv2.imread(img_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)# 归一化图像像素值到 [0, 1] 范围img /= 255.0# 将图像转换为 PyTorch 张量(HWC 转 CHW 格式)img = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0) # 形状: [1, 3, H, W]# 将图像张量移动到指定设备(GPU 或 CPU)img = img.to(device)# 设置模型为评估模式model.eval()# 设置置信度阈值,过滤低置信度的预测threshold = 0.2# 执行预测(禁用梯度计算以节省内存)with torch.no_grad():pred = model(img)# 提取预测结果boxes = pred[0]['boxes'].cpu().numpy() # 边界框坐标scores = pred[0]['scores'].cpu().numpy() # 置信度分数labels = pred[0]['labels'].cpu().numpy() # 类别标签# 过滤低置信度的预测keep = scores > thresholdboxes = boxes[keep]scores = scores[keep]labels = labels[keep]# 返回检测结果return boxes, scores, labels# 定义 ImageNet 验证集的路径
pred_path = "ImageNet/imagenet/val/"
if os.path.exists(pred_path) == False:print("ImageNet 验证集路径不存在!")exit()
pred_files = [os.path.join(pred_path, f) for f in os.listdir(pred_path)]# 定义类别名称字典
classes = {1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat', 5: 'bottle',6: 'bus', 7: 'car', 8: 'cat', 9: 'chair', 10: 'cow',11: 'diningtable', 12: 'dog', 13: 'horse', 14: 'motorbike',15: 'person', 16: 'pottedplant', 17: 'sheep', 18: 'sofa',19: 'train', 20: 'tvmonitor'
}# 设置绘图画布
plt.figure(figsize=(20, 60))
image_list = [0, 11, 17, 28] # 指定要显示的图像索引# 遍历图像文件
for i, image_path in enumerate(pred_files):if i > 30: # 限制处理的图像数量breakif i not in image_list: # 跳过不需要显示的图像continue# 执行目标检测boxes, scores, labels = obj_detect(image_path)# 读取图像用于可视化img = cv2.imread(image_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 绘制边界框和类别标签for j, box in enumerate(boxes):cv2.rectangle(img, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 220, 0), 2)if labels[j] in classes:cv2.putText(img, classes[labels[j]], (int(box[0]), int(box[1]) - 5),cv2.FONT_HERSHEY_COMPLEX, 0.7, (220, 0, 0), 1, cv2.LINE_AA)# 显示图像plt.subplot(10, 2, image_list.index(i) + 1)plt.axis('off')plt.imshow(img)plt.show()
总结
本章介绍了目标检测的基本原理,详细讲解了深度学习时代最具有代表性的目标检测模
型—R-CNN系列模型及它们的发展脉络,并实现了相应的功能。作为计算机视觉的最重要的
基本任务之一,目标检测有着广泛的工业应用场景,如汽车产业的辅助驾驶系统。接下来,我
们将介绍图像语义理解中的另一个重要任务—实例分割。