Linux基本使用和Java程序部署(含 JDK 与 MySQL)
文章目录
- Linux 背景知识
- Linux 基本使用
- Linux 常用的特殊符号和操作符
- Linux 常用命令
- 文本处理与分析
- 系统管理与操作
- 用户与权限管理
- 文件/目录操作与内容处理工具
- Linux系统防火墙
- Shell 脚本与实践
- 搭建 Java 部署环境
- apt(Debian/Ubuntu 系的包管理利器)介绍
- 安装 JDK
- 安装 MySQL
- 部署 Web 项目到 Linux
Linux 背景知识
Linux 是一个操作系统,和 Windows 是"并列"的关系,安卓系统就是基于Linux进行的开发
严格来说 Linux 是一个完全开源免费的操作系统内核,而一个完整的操作系统 = 操作系统内核 + 配套的应用程序。因此有些公司/开源组织又基于 Linux 内核, 提供了不同的配套程序,这就构成了不同的 “发行版”
企业中主要使用的发行版是 RedHat (红帽),CentOS(RedHat的社区免费版本) 和 Ubuntu 。但 RedHat 是收费的,CentOS 已经停止维护了,所以本文以 Ubuntu 为主
Linux的优势
- 开源(意味着免费,便宜)
- 稳定(Linux 可以运行很多年,都不会发生重大问题)
- 安全(对读、写进行权限控制、审计跟踪、核心授权等技术)
- 自由(不会被强加商业产品和服务)
- 社区支持(Linux 在全球社区都非常活跃和使用广泛,有很多志愿者在线帮大家解决问题)
Linux 基本使用
环境我用的是云服务器,并使用远程终端工具(能与远程主机建立网络连接并实现远程操作) XShell 连接

@用来分隔用户名和主机名,左边是用户名,右边是主机名:右边表示所在目录,~表示当前路径是在家目录#是超级用户终端提示符 ,表明这是在以 root 权限操作服务器
关于XShell 下的复制粘贴(可以重新设置快捷键)
复制:ctrl + insert
粘贴:shift + insert
PS:如果不行试试鼠标右键是不是有复制粘贴选项或者右键直接可以复制粘贴(我的 Docker 容器内右键是直接复制粘贴的)
Linux 终端常见操作
Ctrl+C:Linux 终端中最常用的 “万能退出” 命令,其核心作用是强制终止当前正在运行的前台程序(如脚本执行、命令运行等等)。若一次按下后未成功终止程序,可连续多按几次,通常能有效中断进程并返回终端命令行界面,操作简单且适用性广泛
clear:清空当前可见的屏幕内容,使光标回到终端顶部,让界面恢复整洁状态,方便后续操作。不过需要注意的是,clear 命令的 “清屏” 是视觉上的暂时清空,并非彻底删除历史输出记录。执行后,你仍可以通过鼠标滚轮向上滚动,或使用快捷键(如 Shift+PageUp)回溯查看之前的命令和输出内容。部分终端支持 Ctrl+L 快捷键实现类似 clear 的效果。clear 命令因其轻量便捷,仍是日常清屏的首选
Tab 键:可自动补全目录、文件名、命令等。输入部分字符后按一次 Tab,若存在唯一匹配项,会直接补全剩余内容;若有多个匹配项(如输入 “doc” 后对应 “document”“docs” 等),第一次按 Tab 会无反应(以此提示存在多选项),再次按下 Tab 则会列出所有符合条件的选项,便于用户根据需求进一步输入或选择,有效减少手动输入量并避免拼写错误
按 上下方向键:可快速回溯或切换已执行过的历史命令,按↑键向上翻阅更早的命令,按↓键向前查看较新的命令,选中后直接按 Enter 即可重复执行,适合快速调用最近操作过的命令
history:用于列出所有历史命令记录(通常包含序号、时间、用户及具体命令,例如 71 2025-07-29 14:01:18 root cat note.txt),方便回溯过往操作。若需重复执行历史命令,可通过高效方式调用:
- !序号(如 !71 直接执行第 71 条命令)
- !命令前缀(如 !git 执行最近一次以 git 开头的命令)
- !! 作为 “万能重试键”,可快速重复上一条命令,效果等同于按 ↑ 方向键调出上一条命令后回车,适合需要立即复用刚执行的命令场景
根目录下的常见文件夹:
/称为根目录,整个文件系统的起点,所有目录和文件都挂载在根目录下,是系统目录结构的 “根”/etc存放系统和应用程序的配置文件(如网络配置、服务启动脚本等),修改需谨慎/home是普通用户个人主目录(又称家目录)的集中存放地,每个用户在此拥有一个以自己用户名命名的专属子目录(如 /home/user1),用于存储私人文件、用户配置、个人程序等数据
这一设计的核心特点在于权限隔离:/home 下每个用户子目录(如 /home/user1)默认仅允许该用户本人和超级用户(root)进行读写操作,其他普通用户无权随意访问,这是 Linux 权限安全机制的直接体现
需要注意的是,超级用户(root)的家目录并非位于 /home 下,而是独立的 /root 目录。这种设计既避免了普通用户对 root 数据的误操作,也进一步强化了系统最高权限与普通用户权限的隔离,是 Linux 安全架构的重要组成部分
/bin存放所有用户(包括普通用户和 root)均可直接执行的基础命令二进制文件,例如 ls、cp、mkdir等。这些命令是系统启动、修复及日常操作的核心工具/lib存放/bin和/sbin目录中程序依赖的共享库文件(.so 文件),是程序运行的 “底层支撑代码”,不可随意删除/user是 Linux 中用户级软件和资源的核心存放区,包含 /usr/bin(用户日常命令)、/usr/lib(对应共享库)、/usr/share(文档等共享数据)及 /usr/local(用户自行安装软件)等子目录,集中存放非系统启动必需但日常使用的工具、库和数据,是用户软件的主要安装位置/tmp存放临时文件,系统会定期自动清理(或重启后清空),适合程序运行时临时存储数据,所有用户可读写
Linux 常用的特殊符号和操作符
管道符 |
管道是一种古老的 “进程间通信” 方式,在 Linux 指令中可以使用 | 作为管道标记。作用是将前一个命令的标准输出(stdout) 直接作为后一个命令的标准输入(stdin),这使得多个简单命令可以组合成强大的功能链,举例:
# 查看系统中所有包含"java"关键字的进程
# ps -ef 显示系统中所有进程的详细信息(e表示所有进程,f表示完整格式)
# grep "java" 过滤出包含"java"字符串的进程行
ps -ef|grep "java"# 查看系统中前10个进程的详细信息
# head -10 取前10行输出结果
ps -ef|head -10# 实时监控日志文件中包含"Exception"的日志信息
# tail -f log.txt 实时跟踪log.txt文件的新增内容(f表示follow,持续输出新内容)
# grep "Exception" 过滤出包含"Exception"的日志行
tail -f log.txt|grep "Exception"
变量 / 命令替换符 $
在 Shell 脚本和命令行中,$ 是一个非常关键的符号,用途广泛,主要与变量、命令替换、参数传递等相关。以下是其核心用法的详细说明:
- 引用变量($变量名)
示例:
name="Alice"
echo $name # 输出:Alice(解析变量 name 的值)
echo "Hello, $name" # 输出:Hello, Alice(在字符串中嵌入变量)
注意:若变量名后紧跟其他字符,可用 ${} 明确变量边界,例如 echo ${name}123 会输出 Alice123,而 echo $name123 会因变量 name123 未定义而输出空
- 命令替换
$ 结合括号 $(…) 或就用反引号 `…` 包裹时,表示命令替换,即先执行括号/反引号内的命令,再将输出结果作为参数或值使用
示例:
# ls 列出当前目录下的所有文件和目录(默认不包含隐藏文件)
# | 管道符:将 ls 的输出作为 wc -l 的输入
# wc -l 统计输入内容的行数(即文件和目录的总数量)
# 命令替换会将上述命令的输出结果(一个数字)赋值给变量 count
count=$(ls | wc -l)
# 打印变量 count 的值,展示当前目录下的文件和目录总数
echo "文件数:$count"# 等价于上面的写法(但推荐用 $(...),嵌套更清晰)
count=`ls | wc -l`
- 位置参数:$n(n 为数字)
在脚本或函数中,$1、$2…$n 用于获取传入的位置参数(即命令或脚本后的参数)
假设有脚本 test.sh ,内容如下:
#!/bin/bash
echo "第一个参数:$1"
echo "第二个参数:$2"
执行 ./test.sh apple banana 时,输出:
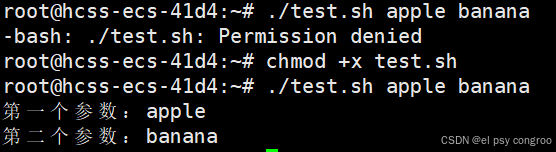
至于为什么有chmod +x test.sh下面的文件权限会介绍
特殊位置参数:
| 特殊参数 | 作用 |
|---|---|
| $0 | 当前脚本 / 命令的名称(包含调用时的路径) |
| $# | 统计 传入脚本或函数的参数总数量 |
| $* | 所有参数的集合,默认以空格分隔,视为单个字符串(加引号时整体作为一个变量) |
| $@ | 所有参数的集合,每个参数独立存在(加引号时保持参数间的独立性) |
| $? | 上一条命令的退出状态码(0 表示成功,非 0 表示失败) |
| $$ | 当前脚本 / 进程的 PID |
| $! | 上一个后台进程的 PID(后台运行命令时,获取其进程 ID) |
| $- | 显示当前 Shell 启用的选项标志 |
| $PPID | 当前进程的父进程 PID(即启动当前脚本的进程 ID) |
常见的环境变量及其作用:
| 环境变量 | 作用说明 |
|---|---|
| HOME | 当前用户的主目录路径 |
| USER / LOGNAME | 当前登录的用户名 |
| UID | 当前用户的用户 ID(数字) |
| GID | 当前用户的主组 ID(数字) |
| PWD | 当前工作目录的绝对路径 |
| OLDPWD | 上一次工作目录的绝对路径(cd - 命令依赖此变量) |
| HOSTNAME | 当前主机的名称 |
环境变量是系统或程序预定义的变量,可通过 echo $变量名(如 echo $HOME)查看其值
用户可通过 export 变量名=值(如 export PATH=$PATH:/new/dir)临时设置环境变量,若需永久生效,需写入 Shell 配置文件
输入输出重定向符(用于控制命令的输入来源或输出方向)
> 覆盖输出到文件(若文件存在则清空原有内容)
echo "Hello" > test.txt # 将 "Hello" 写入 test.txt,覆盖原有内容
>> 追加输出到文件(在文件末尾添加内容)
echo "World" >> test.txt # 在 test.txt 末尾添加 "World"
< 从文件读取输入(代替标准输入)
grep "error" < log.txt # 等价于 grep "error" log.txt,从 log.txt 中查找 "error"
2> 重定向错误输出(2 代表标准错误流)
ls non_exist_file 2> error.log # 将错误信息写入 error.log,而非屏幕
&> 直接合并标准输出和错误输出并重定向到指定位置,写法简洁且不依赖顺序,但兼容性较差
command &> output.log # 命令的所有输出(正常+错误)都写入 output.log
2>&1 需先指定标准输出的重定向,再让错误输出跟随其方向(严格依赖此顺序),兼容性强,是脚本常用写法
# 把命令的正常输出和错误输出都写入 output.log
command > output.log 2>&1 # 错误的,这是先让 stderr 指向 stdout(屏幕),再将 stdout 重定向到文件,导致 stderr 仍输出到屏幕
command 2>&1 > output.log
逻辑运算符(用于组合多个命令,根据前一个命令的执行结果决定是否执行后一个)
&& 逻辑与(前一个命令成功执行,才执行后一个)
make && make install # 只有 make 成功,才执行 make install
|| 逻辑或(前一个命令执行失败,才执行后一个)
command || echo "命令执行失败" # 若 command 失败,输出提示
; 命令分隔符(无论前一个命令是否成功,都执行后一个)
cd /tmp; ls # 先切换到 /tmp,再执行 ls(无论 cd 是否成功)
通配符(用于匹配文件名 / 路径)
* 匹配任意数量的任意字符(包括 0 个)
ls *.txt # 列出所有 .txt 结尾的文件
? 匹配单个任意字符
ls file?.log # 匹配 file1.log、fileA.log 等(中间一个字符任意)
[] 匹配括号内的任意一个字符
ls [abc].txt # 匹配 a.txt、b.txt 或 c.txt
ls [0-9].log # 匹配 0.log 到 9.log
[^] 匹配不在括号内的任意字符(取反)
ls [^a].txt # 匹配除 a.txt 外的 x.txt(x 为任意字符)
引号
反引号 `` 等同于 $(…),用于命令替换,但推荐优先用 $(…)
echo "当前目录:`pwd`" # 等价于 echo "当前目录:$(pwd)"
双引号""保留字符串整体结构(如空格),同时解析 $ 引导的变量 / 特殊参数、` 或 $(…) 形式的命令替换,并仅对 $、`、"、\ 启用 \ 转义
在双引号中,\ 仅对 $、`、"、\ 这四个字符有转义作用,对其他字符(如*、?、\n等),\会被当作普通字符输出,不具备转义功能
name="Alice"; echo "Hello $name" # 输出:Hello Alice(变量被解析)
echo "价格:\$99" # 输出:价格:$99(\$ 转义为 $,不解析为变量)
echo "他说:\"你好\"" # 输出 他说:"你好"(\ 转义 ",避免提前结束双引号)
echo "Line1\nLine2" # 输出:Line1\nLine2(\n 不被转义,原样输出),若要换行需用-e选项
echo "file*.txt" # 输出:file*.txt(* 不解析为通配符,加不加\都一样)
echo "file\*.txt" # 输出:file\*.txt
echo "a\\b" # 输出:a\b(\ 转义自身,最终保留一个 \)
单引号 '' 完全禁用所有特殊字符的解析,包括变量($)、通配符(*)、命令替换(` 或 $())、转义符(\)等,所有字符都会被当作字面量处理
name="Alice"; echo 'Hello $name' # 输出:Hello $name($name 不解析)
echo '价格:\$99' # 输出:价格:\$99($ 按字面输出)
echo '他说:"你好"' # 输出:他说:"你好"(双引号无需转义)
其他实用符号
~ 代表当前用户的主目录(等价于 $HOME)
cd ~ # 切换到主目录
.. 和 . . . 代表上一级目录,. 代表当前目录
cd .. # 进入上一级目录
cp ./file.txt ../ # 将当前目录的 file.txt 复制到上一级目录
# 注释符号(# 后的内容不执行)
echo "Hello" # 这是一条注释,不会被执行
& 将命令放入后台执行(不阻塞当前终端)
python server.py & # 让 server.py 在后台运行,终端可继续输入其他命令
\(转义符)的转义作用具有场景依赖性,既能在特定条件下让 *、?、$、" 等特殊字符失去特殊含义按字面处理,也能在特定条件下与 n、t 等普通字符组成转义序列(如 \n 表示换行)赋予其特殊功能
echo * # 输出:*(\ 转义 *,使其失去通配符功能,仅作字面字符)
echo $HOME # 输出:$HOME(\ 转义 $,使其不解析为变量引用,仅作字面字符)
echo -e "换行:\n" # 输出换行(-e 选项启用转义解析,\n 被识别为换行符)
这些符号是 Shell 命令行和脚本编程的基础,灵活组合使用可以实现复杂的功能(如批量处理文件、条件执行命令、自动化任务等)。掌握它们能显著提升 Linux 命令行的使用效率
Linux 常用命令
在 Linux 命令中,短选项(单横线 + 单个字母)以简洁可合并(如ls -la合并-l和-a)为优势,长选项(双横线+ 完整单词)以可读性见长但无法合并,两者功能等效;多数无参数选项顺序可灵活调整(如rm -rf与rm -fr效果相同)
在命令语法说明中,
[](方括号)和<>(尖括号)是元字符,仅用于描述参数的性质(可选 / 必填),实际输入命令时不用包含这些符号
例如 kill [选项] <PID>... 表示:
- [选项] 可写可不写
- <PID> 必须替换为具体的进程 ID
- … 表示可以跟多个 PID
这些符号的作用是清晰区分参数的必要性,简化命令格式的说明,实际执行时只需替换为具体值即可,比如实际输入可以为 kill -9 1234 而不是 kill [-9] <1234>
文本处理与分析
grep [选项] 模式 [文件]... 在文件或输入流中搜索匹配指定模式(字符串或正则表达式),它会逐行扫描目标内容,输出所有包含匹配模式的行,是文本搜索、日志分析的常用工具
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -n | --line-number | 显示匹配行的行号 |
| -i | --ignore-case | 忽略大小写匹配 |
| -r | --recursive | 递归搜索目录下所有文件(包括子目录) |
| -w | --word-regexp | 全字匹配,仅匹配完整单词,避免部分包含的情况 |
| -c | --count | 只显示匹配到的行数(不显示具体内容) |
| -l | --files-with-matches | 只显示包含匹配内容的文件名(适合多文件搜索) |
| 无 | --color | 高亮显示匹配结果,方便快速定位目标内容 |
| 无 | --include | 指定搜索符合特定模式的文件 |
| 无 | --exclude | 指定排除某些文件 |
示例:
- 在文件中搜索字符串:
# 在 test.txt 中搜索包含 "error" 的行
grep "error" test.txt
- 忽略大小写搜索
# 匹配 "Error"、"ERROR"、"error" 等
grep -i "error" log.txt
- 多文件搜索并显示文件名:
# 在所有 .conf 文件中搜索 "port",并显示包含该内容的文件名
grep -l "port" *.conf
- 与管道配合使用,过滤输出结果:
# 查看进程列表中包含 "nginx" 的进程
ps aux | grep "nginx"
- 指定高亮显示的方式
--color 后面可以跟一些参数来指定高亮显示的具体方式
比如加上 always 表示始终对匹配的内容进行高亮显示,即便输出结果不是输出到终端(例如重定向到文件时也会添加高亮的控制字符),例如:
grep --color=always "success" access.log > result.txt
虽然 result.txt 是文本文件,但其中匹配到 success 的部分添加了相应的颜色控制字符 ,如果用支持显示颜色的文本查看工具打开(如在终端中用 less -r result.txt,-r 选项用于支持显示颜色控制字符),能看到高亮效果
加上 never 表示从不进行高亮显示,即便输出到终端。这在希望输出简洁、不带有颜色控制字符的文本时比较有用,例如:
grep --color=never "warning" system.log
加上 auto(默认情况)表示只有当输出结果是输出到终端时,才对匹配内容进行高亮显示;如果输出重定向到文件,则不进行高亮,例如:
grep --color=auto "info" app.log
# 输出到终端,有高亮
grep --color=auto "info" app.log > backup.log
# 输出到文件,无高亮
awk [选项] '模式 {动作}' [文件]... 对结构化文本(如日志、CSV、配置文件)进行模式匹配、字段提取、数据统计等操作。其核心思想是 “逐行处理输入,按规则执行动作”,广泛用于日志分析、数据清洗、报表生成等场景
- [选项]常用的有:
| 选项 | 功能描述 |
|---|---|
| -F 分隔符 | 指定字段分隔符(默认以连续空格 / 制表符为分隔符,多个空格视为一个) |
| -v 变量=值 | 在 awk 程序开始前定义变量并赋值,可在脚本中直接使用 |
| -f 脚本文件 | 从指定文件中读取 awk 脚本(适合复杂逻辑,避免命令行过长) |
- ‘模式 {动作}’:awk 的核心逻辑(需用单引号包裹),其工作流程是:逐行读取输入,对每行判断是否匹配 “模式”,若匹配则执行 “动作”,直至处理完所有内容,一个动作块({} 内)中如果有多个语句,需要用 ; 分隔
- 模式(Pattern):用于指定条件筛选行,支持正则表达式(如 /error/ 匹配含 “error” 的行)、行号(如 NR == 5 匹配第 5 行)、比较表达式(如 $1 > 100 匹配第一列大于 100 的行)等,不指定则默认匹配所有行,多个模式(条件)之间用逻辑运算符 &&(与)、||(或)连接
- 动作(Action),用 {} 包裹:对匹配的行执行的操作,如打印第 n 个字段 {print $n}、变量运算(如 {sum += $1},累加第一列的值)、条件判断(如 {if ($2 > 0) print $0},每行的第 2 个字段的值大于 0 时,打印整行内容)等。不指定动作时,默认打印整行,等价于 {print $0}
核心特性
- 非交互式处理:可直接处理文件(如 awk ‘…’ file.txt),也可通过管道接收其他命令输出(如 cat file.txt | awk ‘…’)
- 强大的模式匹配:支持正则表达式匹配,例如 $0 ~ /warning/ 可匹配含 “warning” 的行(~ 表示匹配)
- 可编程性:支持变量定义、循环(for/while)、条件判断(if-else)等,可实现复杂逻辑(如统计、过滤、转换)
核心内置变量(必知)
内置变量是 awk 操作行和字段的关键,常用变量如下:
| 变量 | 含义 |
|---|---|
| $0 | 表示当前行的整行内容 |
| $n | 表示当前行的第 n 个字段(n 为正整数) |
| NF | 当前行的字段总数 |
| NR | 当前处理的行号(从 1 开始累计) |
| FS | 字段分隔符(默认是空格 / 制表符,可自定义) |
| OFS | 输出字段分隔符(默认是空格,自定义后可规范输出格式) |
示例:
- 既有模式,又有动作(最常用)
场景:提取特定字段,从 /etc/passwd 中筛选出 bash 登录用户,并显示其用户名和 UID
# -F ':' 指定字段分隔符为冒号(适配/etc/passwd的格式)
# 模式:$7 ~ /bash$/(第7字段以bash结尾);动作:打印第1和第3字段
awk -F ':' '$7 ~ /bash$/ {print "用户:", $1, "UID:", $3}' /etc/passwd
- 只有模式,无动作(默认动作:打印整行)
场景:筛选出access.log中第1字段为192.168.1.1且行中包含ERROR的行
awk '$0 ~ /ERROR/ && $1 == "192.168.1.1"' access.log
# 等价写法(使用/ERROR/简化形式)
awk '/ERROR/ && $1 == "192.168.1.1"' access.log
- 只有动作,无模式(默认匹配所有行)
场景:统计与计算scores.txt(格式:姓名 语文 数学)的数学成绩平均值
# {sum += $3; count++} 对每一行:累加第3个字段(数学成绩)到sum,并增加人数
# END { ... } 所有行处理完后执行:计算并打印平均值
awk '{sum += $3; count++} END {print "平均数学成绩:", sum/count}' scores.txt
对文件中每一行都执行动作,适合批量处理所有内容
-
模式和动作都省略,实际用途较少,更多用于演示 awk 的默认行为
-
外部交互与三段式结构
假设有一个grades.txt文件,内容为学生 ID、语文成绩、数学成绩(空格分隔),需求:
- 从外部传递两个阈值:语文及格线(chinese_pass)和数学及格线(math_pass)
- 循环处理每一行,筛选出 “至少有一门及格” 的学生
- 统计这些学生中两门都及格的人数
chinese_pass=60
math_pass=60awk -v c_pass=$chinese_pass -v m_pass=$math_pass '# BEGIN块:处理文件前执行(只执行一次)BEGIN {print "===== 学生成绩筛选统计 ====="print "语文及格线:" c_pass "分"print "数学及格线:" m_pass "分"print "-------------------------"# 初始化变量(可选,显式初始化更清晰,不初始化用的时候会隐式初始化为 0)total=0both_pass=0}# 逐行处理(隐含循环){# 判断是否至少一门及格if ($2 >= c_pass || $3 >= m_pass) {total++ # 累计符合条件的学生print "学生" $1 ":语文" $2 ", 数学" $3 "(符合条件)"# 统计双及格人数if ($2 >= c_pass && $3 >= m_pass) {both_pass++}}}# END块:处理完所有行后执行END {print "-------------------------"print "统计结果:"print "符合条件的学生总数:" totalprint "两门都及格的学生数:" both_passprint "双及格率:" (both_pass/total)*100 "%"}
' grades.txt
- BEGIN 块:
- 只在处理第一行内容之前执行一次
- 通常用于初始化变量、打印表头、设置分隔符等预处理操作
- END 块:
- 只在处理完所有行之后执行一次
- 通常用于计算最终结果、打印统计信息、汇总数据等收尾操作
这两个块体现了 awk 的可编程性,使它不仅能做简单的文本过滤,还能实现复杂的数据分析逻辑
- 自定义输入分隔符与输出格式(CSV 转 | 分隔格式并加表头)
# -F ',' 指定输入分隔符为逗号(适配CSV格式)
# BEGIN {OFS="|"; print "姓名|年龄|城市"} 处理前执行:设置输出分隔符为|,并打印表头
# {print $1, $2, $3} 按新格式输出每行的3个字段
awk -F ',' 'BEGIN {OFS="|"; print "姓名|年龄|城市"} {print $1, $2, $3}' data.csv
- 结合管道
# 提取日志中所有IP(第1字段)→ 排序去重计数 → 按次数倒序 → 取前3
awk '{print $1}' access.log | # 从日志中提取所有IP地址sort | # 对IP排序(为uniq去重做准备)uniq -c | # 统计每个IP出现的次数(-c显示计数)sort -k1,1nr | # 按第1列(计数)数字倒序排序head -n 3 # 取访问量最高的前3个IP# 生成1-100序列 → 筛选偶数并计算平方和
seq 100 | # 生成1到100的连续数字awk '$1 % 2 == 0 { # 筛选偶数(对2取余为0)sum += $1 * $1 # 累加平方值(用$1*$1替代^,兼容性更好)}END {print "1-100偶数的平方和:", sum # 输出最终结果}'
wc [选项] [文件]... 用于统计文件内容的实用命令,能快速计算行数、单词数、字节数等
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -l | --lines | 仅统计行数(以换行符 \n 为标志) |
| -w | --words | 仅统计单词数(以空白字符分隔的字符串,连续空白视为一个分隔符) |
| -c | --bytes | 仅统计字节数(包含所有字符,包括换行符、空格等) |
| -m | --chars | 统计字符数(多字节字符如中文按单个字符计数) |
| -L | --max-line-length | 显示文件中最长行的长度(以字符为单位,不包含换行符本身) |
示例
- 统计单个文件的信息,默认情况下,wc 会按「行数 单词数 字节数 文件名」的顺序输出
wc access.log
- 计算代码行数(排除空行更精准)
# grep -v:反向匹配(输出不匹配模式的行)
# '^$':正则表达式,表示空行(^ 匹配行开头,$ 匹配行结尾,中间无任何字符)
# *.py:匹配当前目录下所有以 .py 结尾的文件
grep -v '^$' *.py | wc -l
- 统计当前目录文件数
ls | wc -l # 输出当前目录下的文件/文件夹总数
- 对比文件大小(字节级差异)
wc -c config.ini config.bak # 输出两个文件的字节数,便于对比
- 实时监控日志增长
# 使用 watch 命令定期执行统计操作
# -n 10:指定间隔时间为10秒(每10秒刷新一次结果)
# "wc -l access.log":被定期执行的命令
watch -n 10 "wc -l access.log"
sed [选项] '指令' [文件名]... 用于查找、替换、删除、插入等操作,特别适合在管道中处理数据流或批量修改文件内容
常用选项:
| 选项 | 功能说明 |
|---|---|
| -i[SUFFIX] | 直接修改文件内容。若指定后缀,则会对原文件备份(带该后缀), 再修改原文件;若不指定后缀,则直接修改原文件,不保留备份 |
| -e | 指定编辑指令(脚本),用于执行多个编辑操作时使用 |
| -n | 取消默认输出(只显示被 p 指令明确指定打印的行) |
核心指令
| 格式 | 说明 |
|---|---|
| s/原内容/新内容/[选项] | 替换文本内容。[选项] 包括:g(全局替换,不然默认只替换每行 第一个匹配)、数字(替换第 N 次匹配)、i(忽略大小写)等 |
| d(配合模式匹配) | 删除匹配模式的行(如 3d 删除第 3 行,/pattern/d 删除包含 pattern 的行) |
| p(通常配合-n使用) | 打印匹配模式的行 |
| i | 在指定行(或匹配行)前插入内容 |
| a | 在指定行(或匹配行)后追加内容 |
- 不使用 -i 选项时,上述命令仅对输入内容进行处理并输出到屏幕,不会修改原文件
- 使用 -i 选项时,所有命令的操作结果会直接作用于原文件(可通过指定后缀创建备份)
示例
sed 's/hello/HELLO/' file.txt # 替换每行第一个hello为HELLO
sed 's/hello/HELLO/g' file.txt # 替换每行所有hello为HELLO(g表示全局)
sed 's/^#//' file.txt # 去除行首的#(注释符号)sed '/^$/d' file.txt # 删除所有空行(^$表示空行)
sed '3d' file.txt # 删除第3行sed -n '1,10p' file.txt # 只打印第1到10行
sed -n '/pattern/p' file.txt # 只打印包含pattern的行(等效于 grep "pattern" file.txt)sed '1i # 这是注释' file.txt # 在第1行前插入注释
sed '/^exit/a echo "完成"' script.sh # 在所有以exit开头的行(^ 表示行首,确保精确匹配行首的 exit)后追加一行
系统管理与操作
hostname:查看和设置主机名
date:查看和设置系统日期、时间
reboot:重启主机
ifconfig:配置和查看网络接口信息,可以查看IP地址
netstat [参数]:用于查看网络状态的命令,可显示系统的网络连接、路由表、接口统计等
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -a | --all | 显示所有网络连接(包括监听和非监听状态的套接字) |
| -u | --udp | 仅显示 UDP 协议的连接 |
| -t | --tcp | 仅显示 TCP 协议的连接 |
| -l | --listening | 仅显示处于监听(listening)状态的连接 |
| -n | --numeric | 以数字形式显示 IP 地址和端口号(不进行域名解析,速度更快) |
| -p | --program | 显示每个连接对应的 PID 和进程名称(需要 root 权限) |
lsof:列出系统中所有被进程打开的文件。在 Unix/Linux 系统中,“文件” 的概念非常宽泛,不仅包括普通文件,还包括网络套接字、管道、设备、目录等,因此 lsof 常被用于排查系统资源占用、进程依赖、网络连接等问题
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -i <:端口号> | --internet <:端口号> | 显示占用指定网络端口的进程信息 |
| -u <用户名> | --user <用户名> | 查看用户打开的文件 |
| -c <进程名> | --command <进程名> | 按进程名称过滤 |
| -p <PID> | --pid <PID> | 查看进程打开的文件 |
| -t | --terse | 表示仅输出 PID ,便于批量操作 |
# 列出所有占用 8080 端口的进程
lsof -i :8080
# 可指定协议(TCP/UDP)
lsof -i tcp:80
# 可查看与指定 IP 的连接
lsof -i @192.168.1.100
# 列出 root 用户所有进程打开的文件,便于审计特定用户的操作
lsof -u root
# 查看所有 nginx 进程打开的文件
lsof -c nginx
# 列出 PID 为 1234 的进程打开的所有文件,可用于排查进程依赖的资源
lsof -p 1234
# 直接杀死占用 8080 端口的进程
kill $(lsof -t -i :8080)
ps [参数]:用于显示当前系统中运行的进程信息(如进程 ID、运行状态、占用资源等)
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -a | 无 | 显示所有用户的进程(除了后台进程),与 -x 结合可显示所有进程 |
| -u [用户名] | --user [用户名] | 若指定用户名显示该用户的进程;若不指定则显示当前用户进程 |
| -x | 无 | 显示没有控制终端的进程(通常是后台进程) |
| -e | --everyone 或 --all-processes | 显示系统中所有进程(等价于 -A) |
| -f | --full | 显示完整格式的进程信息 |
| -l | --long | 以长格式显示进程信息(包含更详细的状态字段) |
| -p <PID> | --pid <PID> | 只显示指定 PID 的进程信息 |
| -t <终端> | --tty <终端> | 显示指定终端上运行的进程 |
| 无 | --sort <字段> | 按指定字段排序 |
常用组合示例:
# 以 System V 风格显示系统所有进程的完整信息
# -e: 显示所有进程;-f: 输出完整格式
ps -ef# 以 BSD 风格显示所有进程的详细用户信息
# -a: 显示所有有终端的进程;-u: 以用户为中心展示信息;-x: 包含无终端的后台进程
ps -aux# 查看指定 PID(如 1234)的进程详情
# -p: 按进程 ID 过滤,仅显示目标进程信息
ps -p 1234# 显示所有进程并按 CPU 占用率降序排序(顶部为占用最高的进程)
# --sort=-%cpu: 按 CPU 使用率降序排列(- 表示降序,+ 表示升序可省略,默认即为升序)
ps -aux --sort=-%cpu
常见进程状态字段(STAT 含义):
- R:运行中(正在执行或等待 CPU 时间)
- S:睡眠中(等待事件完成,可被唤醒)
- D:不可中断睡眠(通常与 I/O 相关,无法被信号唤醒)
- Z:僵尸进程(已终止但未被父进程回收的进程)
- T:暂停状态(被信号暂停,如 Ctrl+Z 暂停的进程),或被跟踪
- <:高优先级进程
- N:低优先级进程
ps 命令常与 grep 结合过滤特定进程(如 ps -ef | grep “nginx” 查找 nginx 相关进程),是系统监控和进程管理的基础工具
kill [进程信号] <PID>...:用于向进程发送信号(默认是终止信号),实现进程的终止、暂停、重启等操作
进程信号用数字或名称表示,以下是最常用的几个:
| 信号数字 | 信号名称 | 含义 | 典型场景 |
|---|---|---|---|
| 1 | SIGHUP | 挂起信号(让进程重读配置文件,不终止) | 重启服务 |
| 9 | SIGKILL | 强制终止信号(无法被进程忽略,强制杀死) | 常规方法无法终止的顽固进程 |
| 15 | SIGTERM | 终止信号(默认,允许进程优雅退出,清理资源) | 正常终止进程 |
| 2 | SIGINT | 中断信号(等同于 Ctrl+C) | 手动中断前台运行的进程 |
echo [选项] [输出内容]:用于在终端输出字符串、变量值或命令结果,是 Shell 脚本中打印信息的常用工具
常用选项:
| 短选项 | 功能说明 |
|---|---|
| -n | 输出内容后不自动换行(默认情况下,echo 会在输出末尾添加换行符) |
| -e | 启用对输出字符串中转义字符的解析(如 \n 表示换行、\t 表示制表符) |
用户与权限管理
一、用户账户管理
- 核心定义:用户账户是个体或进程使用系统的 “身份凭证”,核心属性包括用户名、唯一数字标识UID、所属用户组、家目录、默认 Shell 等
- 核心标识:UID(User ID)是用户的唯一数字标识,用于区分不同用户。而用户名是为了方便用户记忆而设置的
- 关键文件(依托下述两个文件实现用户信息的存储与管理,为权限控制提供基础身份依据):
- 用户信息文件(/etc/passwd):存储所有用户的基础公开信息,每行对应一个用户,清晰记录用户名、UID、默认组 GID、家目录路径、默认 Shell 等非敏感数据
- 用户密码文件(/etc/shadow):专门存储用户密码及敏感信息(而非 /etc/passwd ),包括加密后的密码、密码最后修改时间、有效期、失效策略等,文件权限严格限制,保障密码安全
二、用户组(Group)管理
- 核心定义:用户组是用于集中组织用户的机制,可将多个用户纳入同一组,实现权限的批量统一管控,一个用户可同时属于多个组
- 核心标识:GID(Group ID)是用户组的唯一数字标识,用于区分不同用户组
- 关键文件:组信息文件(/etc/group) 存储系统所有用户组信息,每行对应一个组,记录组名、GID、组内成员列表等内容,便于快速查询组与用户的关联关系
三、用户与用户组的关联
/etc/passwd 中记录用户的主组 GID(每个用户必须属于且默认生效的组),而 /etc/group 中除了记录组的基本信息,还通过成员列表记录了属于该组的所有用户(包括以该组为主组的用户,以及将该组作为附加组的用户)。这种设计使得一个用户既拥有唯一的主组,又可以加入多个附加组,同时一个组也能包含多个用户,从而形成 “用户 - 组” 的多对多关系
这种机制既通过用户账户实现了个体身份的精准管理,又通过主组与附加组的灵活组合,实现了权限的批量分配与精细化管控 —— 用户既继承主组的基础权限,又能通过附加组获得额外权限,共同构成了 Linux 系统权限体系的基础
whoami:查看当前有效用户身份
sudo <具体命令>:临时提权,以系统管理者的身份执行指令,执行完成后权限自动回收
passwd [用户名]:修改指定用户的密码(不指定用户名则修改当前用户密码)
su [用户名]:切换到指定用户,但保留当前环境变量(如当前目录、PATH 等),不加用户名默认切换 root 。若加 - 或 --login 则加载目标用户的完整环境(如家目录、Shell 配置等,接近重新登录),切换用户后执行 exit 或按 Ctrl+D 退回原用户
用户
useradd <用户名>:创建新用户
执行时,系统会默认完成:
- 在 /etc/passwd 中添加用户记录,包含自动分配的 UID、默认 GID(通常与 UID 相同)等信息
- 在 /etc/shadow 中创建密码占位记录(初始无密码,需用 passwd 用户名 手动设置后才能登录)
- 在 /etc/group 中创建与用户名同名的主组(GID 通常与 UID 一致)
- 若未指定,默认家目录为 /home/用户名(但需手动创建或用 -m 参数自动创建)
- 默认 Shell 为 /bin/sh 或 /bin/bash(依系统而定)
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -m | --create-home | 自动创建用户家目录(推荐使用) |
| -s <shell路径> | --shell <shell路径> | 指定默认 Shell |
| -g <组名/组GID> | --gid <组名/组GID> | 指定用户主组(需预先存在) |
| -G <组1,组2…> | --groups <组1,组2...> | 指定附加组(多个组用逗号分隔) |
| -u <UID> | --uid <UID> | 手动指定 UID(需确保唯一) |
userdel <用户名>:删除用户
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -r | --remove | 删除用户的同时,自动移除其家目录(/home/用户名) 及邮件缓存(通常在 /var/spool/mail/用户名),避免残留文件占用空间 |
| -f | --force | 强制删除用户,即使该用户当前正处于登录状态(需谨慎使用, 可能导致文件权限混乱) |
id [用户名/UID]:查看用户信息(包含 uid、gid、groups)。不指定用户时,默认展示当前登录用户的信息;指定用户时,展示对应用户的信息(需验证操作权限)
在类 Unix 系统中,用户信息通过以下字段体现权限与归属关系:
- uid=0(root)
- uid(用户 ID):系统唯一的用户数字标识,0 是超级用户(root)的专属 ID,括号中 root 为用户名
- 特性:uid=0 的用户拥有最高系统权限,可无限制操作所有文件、进程及系统资源
- gid=0(root)
- gid(组 ID):用户所属主组的唯一标识,此处表示 root 用户的主组 ID 为 0,组名为 root
- 作用:每个用户都有一个主组,用户创建文件 / 目录时,默认归属其主组,主组权限直接影响这些资源的访问控制
- groups=0(root)
- groups:列出用户所属的所有组(含主组和附加组),这里表明 root 仅属于 root 组,没有附加组
- 扩展:实际场景中用户可加入多个附加组(如 sudo、docker 组),从而获得对应权限(如执行管理员命令、管理容器)
uid 唯一区分用户身份,gid 定义主组归属,groups 扩展附加权限,三者共同构成类 Unix 系统的基础权限管理体系
usermod [选项] <用户名>:修改用户信息
cat /etc/passwd :用于查看系统中所有用户的基础信息
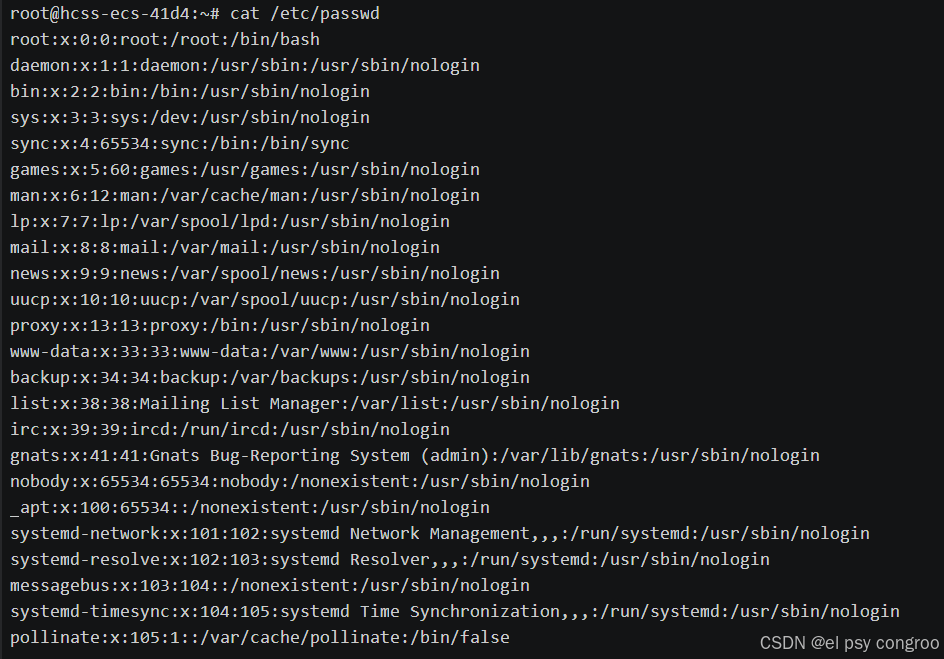
文件中每行对应一个用户,以冒号 : 分隔为 7 个字段,格式为:
用户名:密码占位符:UID:GID:用户描述:家目录:默认Shell(命令解释器)
- 密码占位符:固定为 x,表示密码存储在 /etc/shadow 中
- 用户描述:可选字段(如用户全名),部分系统可能为空
- 默认 Shell:它是用户与 Linux 操作系统进行交互的接口。用户通过在终端中输入命令,Shell 解释并执行这些命令,并向用户提供反馈
列出所有普通用户(UID ≥ 1000):cat /etc/passwd | awk -F: '$3 >= 1000 {print $1}'
用户组
groupadd [选项] <组名>:创建新用户组,执行后会在 /etc/group 中添加一条新组记录
groupdel [选项] <组名>:删除用户组
groups [用户名]:若指定用户则查看指定用户所属的用户组(若不指定用户名,则默认查看当前登录用户所属的用户组)
groupmod [选项] <组名>:修改用户组信息
cat /etc/group:查看所有组
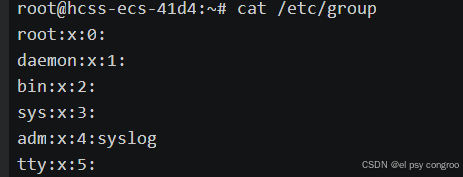
文件中每一行代表一个用户组,以冒号 : 分隔为 4 个字段,格式为:
组名:密码占位符:GID:附加用户列表
- 组名:用户组的名称
- 密码占位符:通常为x(表示密码存储在/etc/gshadow中),实际很少设置组密码
- GID:组的唯一标识(如0对应root组,1000及以上多为普通用户组)
- 附加用户列表:以该组为附加组的用户(用逗号分隔,主组用户不会出现在这里)。可以为空,若字段为空则表示没有用户将此组作为附加组
文件/目录操作与内容处理工具
vim/vi 工作模式
在 Linux 系统中,vi和vim都是文本编辑器,vim是vi的增强版本
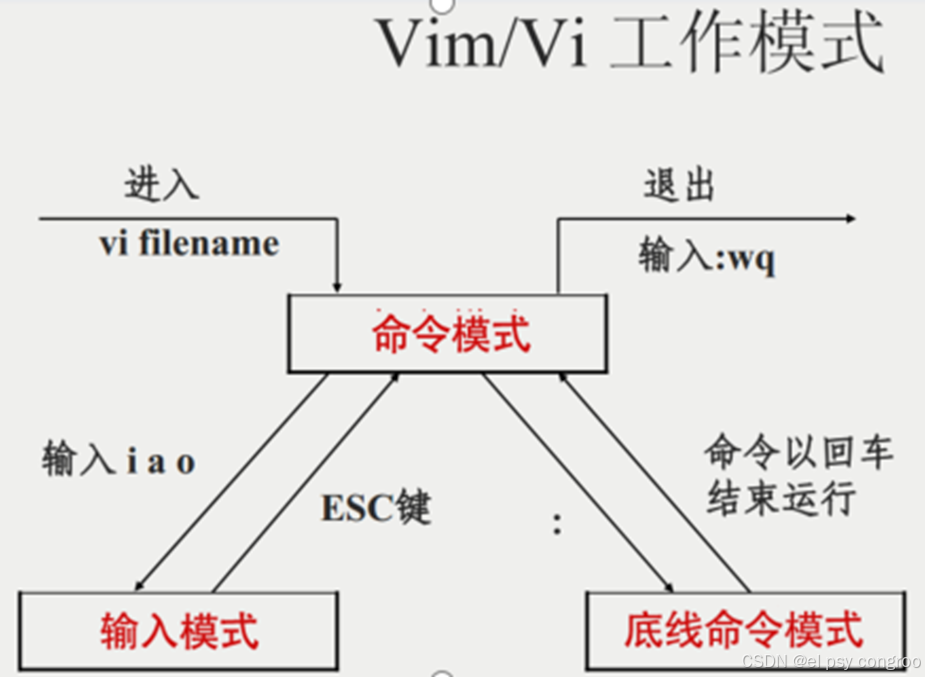
- 启动与初始模式
vi/vim 路径+文件名:
- 若文件存在 → 打开文件并进入命令模式(可浏览、移动光标、删除内容、复制粘贴文本 )
- 若文件不存在 → 新建文件并进入命令模式(后续保存时会实际创建文件 )
在命令模式,可以通过特定的按键操作实现文本浏览与编辑,例如:
- 按 u 键撤销上一次操作
- 移动光标:h 键向左、j 键向下、k 键向上、l(小写的L) 键向右
- 删除内容:x 键删除光标所在字符,dd 删除光标所在行
- 复制粘贴:yy 复制光标所在行,p 键将剪贴板内容粘贴到光标下方
该模式下,键盘输入的字符会被识别为操作命令,而非直接插入文本的内容。若需输入内容,需按下 i、a、o 等按键切换到输入模式(左下角提示 --INSERT-- )
- 模式切换关系(命令模式是 “中转站”)
- 命令模式按 i(在光标前插入)、a(在光标后插入)、o(在当前行的下方插入一个新行)其中一个→ 进入输入模式
- 命令模式按
:→ 进入底线命令模式(可执行保存、退出、查找替换等复杂操作,命令显示在底部状态栏) - 输入模式 / 底线命令模式 → 按 ESC 或者 执行完底线命令(按回车确认)→ 切回命令模式
(3)文件保存与退出(底线命令模式回车执行)
| 场景 | 命令 | 说明 |
|---|---|---|
| 保存文件(不退出) | :w | 写入(write)修改到文件 |
| 文件未修改时退出 | :q | 直接退出(quit) |
| 文件修改后保存并退出 | :wq | 保存(write)+ 退出(quit) |
| 强制退出不保存 | :q! | 强制(!)退出,丢弃修改 |
| 强制保存并退出 | :wq! | 忽略文件的只读属性限制,强制保存修改并退出 (适用于文件本身设为只读但用户拥有写入权限的场景) |
| 全文替换文本(示例) | :%s/old/new/g | 在整个文件(% 表示全文范围)中,替换 old 为 new (g 表示全局替换,若无 g 则仅替换每行第一个匹配项) |
ls[选项][⽬录/⽂件]
- 若指定目录,则列出该目录下的所有子目录与文件(默认以平铺方式显示名称,不含详细信息)
- 若指定文件,则仅列出该文件名(默认不显示额外信息,除非使用 -l 等选项)
- 若不指定目录 / 文件,默认列出当前目录下的内容
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -a | --all | 列出目录下的所有文件和子目录,包括以 . 开头的隐藏文件 |
| -d | --directory | 将目录本身当作文件显示其信息,而非列出该目录下的内容 |
| -k | --block-size=1K | 以 KB(千字节)为单位显示文件大小(1K = 1024 字节) |
| -l | --format=long,通常简化为 --long | 以长格式显示详细元信息,包括权限、所有者、所属组、大小等 |
| -h | --human-readable | 以人类可读格式显示文件大小 |
| -r | --reverse | 对排序结果进行反向显示 |
| -t | --sort=time | 加上按文件的修改时间排序(最新在前),默认按名称排序 |
| -R | --recursive | 递归列出所有子目录中的内容 |
| -S | --sort=size | 按文件大小从大到小排序(结合 -r 可改为从小到大) |
ls -l 与 ll
ls -l 是 ls 命令的标准选项组合,-l 表示以长格式显示文件的详细元信息,它是 Linux 和 macOS 系统的内置命令,所有用户都可以直接使用

ll 并非系统原生命令,而是ls命令的别名(alias),其具体行为取决于系统默认配置或用户自定义设置,不同环境下可能存在差异:
- 在 Ubuntu、Debian 等基于 Debian 的 Linux 发行版中,往往会将 ll 定义为 ls -alF , 这意味着执行 ll 时,会以列表形式展示包括隐藏文件(.开头)在内的所有文件,并在文件名后添加类型标识(如 /表示目录、*表示可执行文件)。不过部分精简版系统或新用户环境可能未预设该别名
- 而在 macOS 系统中,默认的 bash 或 zsh 配置里通常没有 ll 别名,直接输入会提示命令不存在,需要用户手动在配置文件中添加定义(例如alias ll=‘ls -l’)才能使用
- 其他系统中也可能有不同设定,比如部分 RedHat、CentOS 版本默认将 ll 指向 ls -l(仅显示非隐藏文件的详细列表)
若想确认当前环境中 ll 的具体定义,可在终端执行alias ll查看
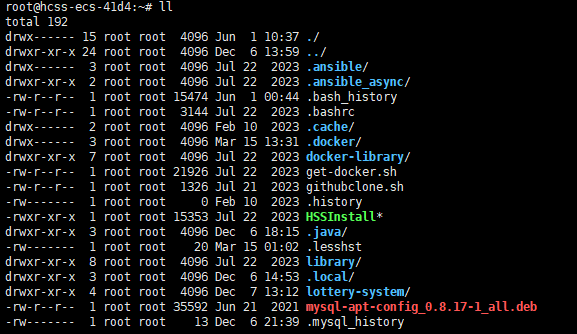
各列从左到右依次为:类型与权限、硬链接数、所有者、所属组、大小、修改时间、名称 ,下面逐个拆解
- 类型与权限(第 1 列):由 10 个字符组成
第 1 位字符表示文件类型,常见值及含义:
| 标识 | 含义 | 通俗类比 / 典型示例 |
|---|---|---|
| d | 目录(Directory) | 类似 Windows 的 “文件夹” |
| - | 普通文件 | 文本文件(.txt)、二进制程序(.exe) |
| l | 软链接(Symbolic Link) | Windows 的 “快捷方式”,指向其他文件 / 目录 |
| b | 块设备(Block Device) | 硬盘、U 盘 |
| c | 字符设备(Character Device) | 键盘、串口 |
| s | 套接字(Socket) | 网络通信的 “端口”(如进程间通信端点) |
| p | 管道(Pipe) | 临时 “数据通道”(如 mkfifo 创建的管道) |
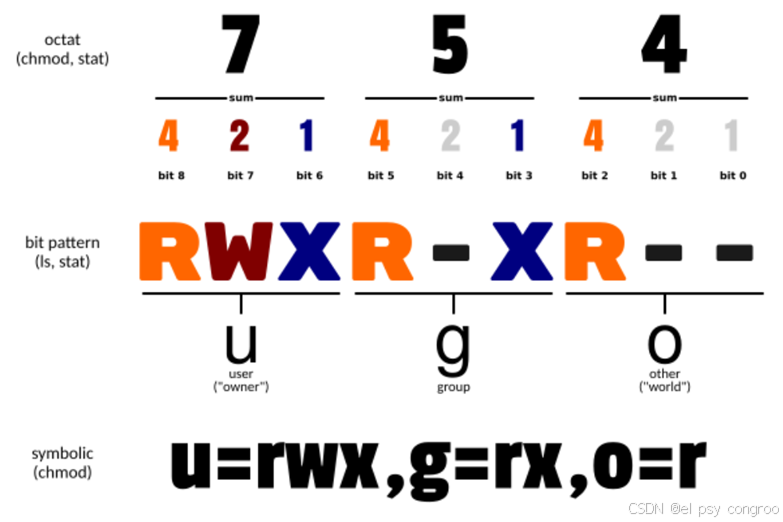
第 2 - 10 位:文件权限分为所有者(u)、所属组(g)、其他用户(o)三组,每组包含读(r,权重 4,可查看文件内容或列出目录文件)、写(w,权重 2,可修改文件内容或在目录中创建 / 删除文件)、执行(x,权重 1,可运行程序或进入目录)三个权限位,无对应权限则用 “-” 占位。比如 rwxr-xr-x 表示:
- 文件拥有者权限(u):rwx ,拥有读、写、执行权限
- 文件所属组用户权限(g):r-x ,拥有读、执行权限,无写权限
- 其他用户权限(o):r-x ,同样读、执行权限,无写权限
权限位的数字表示
| 权限组合 | 二进制 | 数字(4+2+1) | 含义解析 |
|---|---|---|---|
| --- | 000 | 0 | 无任何权限 |
| --x | 001 | 1 | 仅执行权限 |
| -w- | 010 | 2 | 仅写权限 |
| -wx | 011 | 3 | 写和执行权限 |
| r– | 100 | 4 | 仅读权限 |
| r-x | 101 | 5 | 读和执行权限 |
| rw- | 110 | 6 | 读和写权限 |
| rwx | 111 | 7 | 读、写、执行全权限 |
当需要表示所有者、所属组、其他用户的完整权限时,只需将每组对应的数字按顺序拼接即可,例如:
- 所有者有 rwx(7)、所属组有 r-x(5)、其他用户有 r-x(5),组合起来就是 755
- 所有者有 rw-(6)、所属组有 r--(4)、其他用户有 ---(0),组合起来就是 640
权限修改命令:
- chmod (文件权限管理):
chmod <数字权限> <文件/目录名>(数字形式,简洁高效):用三位数字(0-7)分别表示 u、g、o 的权限,每位数字由 r(4)、w(2)、x(1) 相加得到chmod <用户组><操作符><权限> <文件/目录名>(符号形式,直观灵活):通过符号精确调整权限
| 操作符 | 说明 |
|---|---|
| + | 添加权限 |
| - | 移除权限 |
| = | 设置权限(覆盖原有权限) |
示例:
# 权限字符串:rwxr-xr-x
# 含义:所有者有全权限,其他用户可读可执行(不可写)
# 适用:可执行脚本、程序、公共目录(允许他人运行或进入)
chmod 755 script.sh含义:给所有者添加执行权限(不影响已有权限)
场景:刚下载的程序需要运行时
chmod u+x app含义:移除所属组的写权限,同时移除其他用户的读权限
场景:限制组内成员修改重要文件,同时禁止外部用户查看
chmod g-w,o-r file.txt含义:给所有用户(u/g/o)设置读和写权限(覆盖原有权限)
场景:临时共享文件,允许所有人编辑
chmod a=rw shared.doc含义:所有者全权限,所属组可读可进入,其他用户无权限
对应数字形式:chmod 750 data/
场景:部门内部共享数据,拒绝外部访问
chmod u=rwx,g=rx,o=- data/含义:递归给所属组添加写权限(包括目录内所有文件)
场景:团队协作时,允许组内成员修改项目所有文件
chmod -R g+w project/
chown [用户名][:组名] <文件名>:修改文件 / 目录的所有者(用户)和所属组(用户组)
- 硬链接数(第 2 列):表示有多少个硬链接指向该文件或目录 。对于目录,硬链接数计算包含自身、父目录对它的链接以及其他目录通过硬链接关联它的数量;对于普通文件,就是有多少个硬链接指向该文件实体
- 所有者(第 3 列):该文件或目录的所有者用户
- 所属组(第 4 列):该文件或目录所属的用户组
- 大小(第 5 列):文件或目录占用的磁盘空间大小 ,单位默认是字节。对于目录,显示的是目录本身元数据等占用的空间(目录实际包含文件总大小得用 du 等命令看 ),4096 字节是 Linux 系统里目录常见的基础块大小;对于普通文件,就是文件内容实际占用字节数
- 修改时间(第 6 - 8 列):文件或目录的最后一次修改时间(修改文件内容权限、目录内增删文件 / 目录等操作会更新此时间 ),包含月份、日期、具体时间点
- 名称(第 9 列):文件或目录的名称 ,以 . 开头的是隐藏文件 / 目录
pwd:是 Print Working Directory 的缩写,显示当前所在目录的绝对路径
cd <目录路径>:切换工作目录。将当前工作目录改到指定的目录下,cd 命令后面既可以跟绝对路径,也可以跟相对路径
cd ~/cd:快速回到用户主目录cd ..:回到上一级目录cd -:切换回上一次工作目录
mkdir [选项] <目录路径>:创建目录(文件夹),mkdir 命令支持同时创建多个目录
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -p | --parents | 递归创建目录,当需要创建多级目录且父目录不存在时非常实用 |
| -m <权限模式> | --mode=<权限模式> | 创建目录时指定权限(如 -m 755 表示设置权限为 rwxr-xr-x) |
touch [选项] <文件路径>:创建新的空文件,也可以用于修改文件的访问时间和修改时间,touch 命令支持同时操作多个文件
cat [选项] :查看文件,也可以用于创建简单的文件或合并文件内容
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -n | --number | 对输出的所有行编号(包括空行) |
| -b | --number-nonblank | 仅对非空行编号,优先级比 -n 高 |
tail [选项] <文件路径>:查看文件的末尾内容,默认显示文件最后 10 行,常用于实时监控日志文件等场景
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -f | --follow | 实时追踪文件新增内容,按 Ctrl+C 退出 |
| -n <行数> 或 -<行数> | --lines=<行数> | 指定显示文件末尾的行数 |
| -c <字节数> | --bytes=<字节数> | 以字节为单位显示文件末尾内容 |
特殊用法
- 若要从文件的某一行开始显示(而非末尾),可结合 + :
# 从第100行开始显示到文件末尾
tail -n +100 document.txt
- 通过管道符可以截取其他命令输出的末尾内容
# 查看目录下最后5个文件/目录的详细信息
ls -l | tail -n 5
# 查找包含"error"的行,并只显示最后3行
cat large_file.txt | grep "error" | tail -n 3
除此之外还有:
- head:查看文件的开头部分内容,默认显示文件前 10 行
- more :以分页方式查看文件内容,适合查看较长的文件(支持逐页滚动)
- less:高级分页查看工具,功能比 more 更强大,支持自由滚动和搜索
rmdir [选项] <目录路径>:用于删除空目录(目录内必须无任何文件或子目录)
最常用的选项是 -p(或 --parents),用于递归删除空目录链(即当父目录也为空时,一并删除)
示例:
# 若 a/b/c 是一个空目录,且 b 和 a 也为空,会依次删除 c、b、a 三个空目录
rmdir -p a/b/c
rm [选项] <目录/文件>:删除文件或目录,使用 rm 删除目录时,必须使用 -r 或 --recursive,由于删除操作不可逆,使用时需特别谨慎,尤其是针对重要文件或系统目录
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -r | --recursive | 递归删除目录及其所有内容(包括子目录、文件) |
| -f | --force | 强制删除(即使文件属性为只读),忽略不存在的文件,不提示确认 |
| -i | --interactive | 删除前逐一提示确认(加上此选项可强制所有删除都提示,避免误操作) |
cp [选项] <源文件/目录> <目标文件/目录>:复制文件或目录到指定的目标位置
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -r | --recursive | 递归复制目录(包括目录内的所有文件和子目录),复制目录必须使用此选项 |
| -f | --force | 忽略文件的只读属性并强制覆盖,而不是 “开启覆盖功能”,覆盖功能本就存在 |
| -i | --interactive | 目标文件存在时提示确认(避免误覆盖,优先于 -f) |
cp 命令复制时,多源文件 / 目录需以已存在目录为目标才会全部复制过去,否则报错;单源时,若目标是已存在文件则直接覆盖(除非用 -i 选项),是目录则复制到其下
mv [选项] <源文件/目录> <目标文件/目录>:移动或重命名文件 / 目录,操作具有原子性(要么完全成功,要么完全失败)
常用选项:
| 选项 | 对应长选项 | 功能说明 |
|---|---|---|
| -f | --force | 强制操作,若目标文件已存在则直接覆盖,不提示 |
| -i | --interactive | 若目标文件已存在,移动 / 重命名前提示确认(避免误覆盖) |
| -n | --no-clobber | 若目标文件已存在,则不执行移动 / 重命名操作,也不提示(防止意外覆盖文件) |
说明:mv命令可直接操作目录(无需像cp那样加-r),当目标是已存在的文件时,若源是文件则覆盖(除非用-i或-n选项),若源是目录则报错;当目标是已存在的目录时,单个源文件或源目录会被移入该目录,多个源文件或源目录(可混合)也会被移入该目录;当目标不存在时,源文件或源目录会被重命名为目标路径
find [查找路径] [匹配条件] [处理动作]:是强大的文件查找工具,能按多种条件精准定位文件或目录
# 列出 /etc 目录下包含 "localhost" 的文件
find /etc -type f | xargs grep "localhost"# 查找 /var 下 7 天内修改、大小大于 100MB、属主为 root 的 log 文件
find /var -type f -name "*.log" -mtime -7 -size +100M -user root
Linux系统防火墙
一、介绍
防火墙通过管理员设定的规则控制数据包进出,核心作用是保护内网安全,默认状态为关闭。目前 Linux 系统主流防火墙为 iptables(静态)和 firewalld(动态)
| iptables(静态防火墙) | firewalld(动态防火墙) | |
|---|---|---|
| 适用场景 | 早期 Linux 系统默认使用,部分老旧系统仍在使用 | 取代 iptables 成为主流,现代 Linux 系统常用 |
| 工作层级 | 主要工作在网络层 | 主要工作在网络层 |
| 配置方式 | 仅支持命令行配置,配置文件为 /etc/sysconfig/iptables | 支持命令行和图形化界面配置,配置文件位于 /usr/lib/firewalld 和 /etc/firewalld |
| 默认规则 | 默认允许所有数据包,需通过 “拒绝” 策略限制 | 默认拒绝所有数据包,需通过 “允许” 策略放行 |
| 规则生效 | 修改规则后需全部刷新才能生效,会导致现有连接丢失(无守护进程) | 支持动态修改单条规则,更新时不破坏现有会话和连接(支持守护进程) |
| 过滤范围 | 只能过滤互联网的数据包,无法过滤内网到内网的数据包 | 新增区域概念,不仅可以过滤互联网的数据包,也可以过滤内网的数据包 |
常用管理命令
| 操作 | firewalld 命令 | iptables 命令 |
|---|---|---|
| 查看状态 | sudo systemctl status firewalld | sudo systemctl status iptables |
| 安装(RPM 系统) | sudo yum install firewalld | sudo yum install iptables |
| 安装(Debian 系统) | sudo apt install firewalld | sudo apt install iptables |
| 启动服务 | sudo systemctl start firewalld | sudo systemctl start iptables |
| 关闭服务 | sudo systemctl stop firewalld | sudo systemctl stop iptables |
| 开机自启 | sudo systemctl enable firewalld | sudo systemctl enable iptables |
| 禁止开机自启 | sudo systemctl disable firewalld | sudo systemctl disable iptables |
总结
iptables 是静态防火墙,依赖全量刷新规则,适合简单场景;firewalld 作为动态防火墙,支持规则实时更新和多配置方式,更适应现代系统的灵活需求。两者均工作在网络层,核心差异在于规则管理的动态性和配置便捷性
Shell 脚本与实践
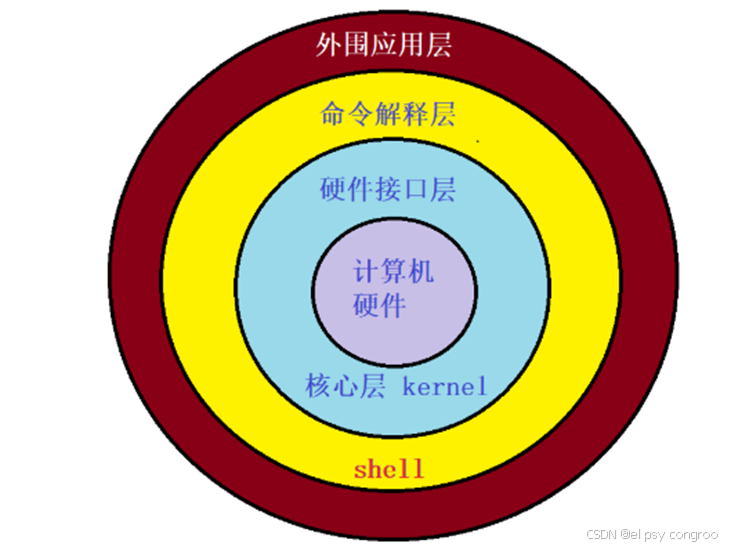
Shell 是一个用 C 语言编写的应用程序,它为用户提供了操作 Linux 内核服务的界面,是用户与 Linux 系统交互的桥梁
Shell 脚本(shell script)则是为 Shell 编写的脚本程序,类似 Windows 的批处理文件,主要用于便捷地批量处理多种操作。作为内置脚本,它语法简单、易学易用,开发效率高,能依赖强大的命令快速完成批处理任务
Linux 系统中有多种 Shell 类型,常见的包括:
- Bourne Shell(路径通常为 /usr/bin/sh 或 /bin/sh)
- Bourne Again Shell(即 bash,路径为 /bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
其中,bash 因易用性和免费特性被广泛使用,是大多数 Linux 系统的默认 Shell
示例
创建文件,注意后缀是sh
输入:
#! /bin/bash
echo "hello world"
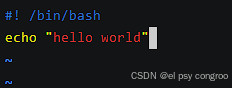
- #! /bin/bash:指定脚本使用的解释器是Bash
- echo “hello world”:打印 hello world 到终端
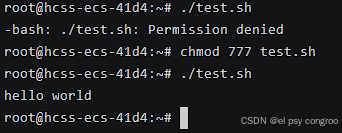
如果没权限的话加上权限
搭建 Java 部署环境
apt(Debian/Ubuntu 系的包管理利器)介绍
apt(Advanced Packaging Tool)是 Ubuntu、Debian 及衍生发行版中管理 .deb 格式软件包的工具,可实现安装、更新、卸载等全生命周期管理,多数操作需 sudo 权限,其工作基于可用软件包的数据库,因此安装 Linux 系统后应首先更新该数据库,否则系统无法知晓是否有更新的软件包可用
一、核心配置:镜像源
镜像源是指在不同地区或网络环境中,通过复制并同步主服务器的软件包与数据而搭建的服务器。其核心作用是为用户提供本地化的资源访问节点,从而大幅提升软件下载与安装速度,优化用户体验。而软件包的具体下载来源,通常由系统或软件管理工具中的镜像源列表进行管控 —— 用户可根据自身网络状况、地理位置等因素,在列表中配置合适的镜像源,系统会据此优先从指定节点获取资源
配置文件为:
vim /etc/apt/sources.list # 编辑镜像源(需 root 权限)
镜像源决定了软件包的下载速度和可用性,国内常用阿里、清华等镜像源
二、常用命令速查表
| 命令 | 说明 |
|---|---|
| sudo apt update | 更新软件包数据库,获取最新可用版本信息(仅更新列表,不升级软件) |
| sudo apt upgrade | 升级所有已安装软件包(保留配置文件) |
| sudo apt install <包名> | 安装指定软件,自动处理依赖关系;可同时安装多个包(空格分隔) |
| sudo apt remove <包名> | 删除软件二进制文件,保留配置文件(便于后续重新安装) |
| sudo apt purge <包名> | 彻底卸载软件及所有配置文件(适合完全清理) |
| apt list --installed | 显示系统中所有已安装的软件包 |
| apt list | grep <关键词> | 搜索包含关键词的软件包(避免直接用 apt list 因数量过多导致卡顿) |
| apt list --all-versions <包名> | 查看指定软件包的所有可用版本及当前安装状态 |
| apt search <关键词> | 搜索包含关键词的软件包(比 apt list | grep 更高效) |
| apt show <包名> | 显示软件包的详细信息(版本、依赖、描述等) |
三、关键细节与注意事项
- remove 与 purge 的选择:
- 常规卸载用 remove(保留配置,如需重新安装可复用配置)
- 需彻底清除痕迹(如配置错乱后)用 purge
- apt 是 apt-get 的优化升级版本,核心功能一致(均管理 .deb 包),但 apt 更简洁直观适合日常使用,apt-get 输出稳定适合脚本或特殊场景
安装 JDK
- 更新软件包
sudo apt update
- 安装 openjdk
# 搜索包含"jdk"关键词的软件包列表(jdk是Java开发工具包的缩写)
apt list | grep "jdk"# 安装 openjdk-17-jdk 软件包(OpenJDK 17版本的Java开发工具包)
sudo apt install openjdk-17-jdk
注意:此处安装的 OpenJDK 是一个开源版本的 JDK,和 Oracle 官方的 JDK 略有差别。此处我们就使用 OpenJDK 即可,安装 Oracle JDK 比较麻烦
使用 java -version 命令验证是否安装成功,如果提示 “java 命令找不到” 则说明安装失败
卸载 OpenJDK
# 检查已安装的 OpenJDK 包
dpkg --list | grep -i jdk# 卸载 OpenJDK 相关包
sudo apt-get purge icedtea-* openjdk-* # icedtea 是 OpenJDK 的相关组件(如浏览器插件),可一并卸载# 清理残留依赖
sudo apt-get autoremove # 自动移除不再需要的依赖
sudo apt-get autoclean # 清理缓存的过时包文件# 验证卸载结果
dpkg --list | grep -i jdk
安装 MySQL
- 使用 apt 安装 MySQL
# 查找安装包
apt list |grep "mysql-server"# 安装 mysql
sudo apt install mysql-server
- 查看 MySQL 状态
sudo systemctl status mysql
- MySQL 安全设置
默认的 MySQL 设置是不安全的,MySQL 提供了一个安全脚本,运行以下命令:
sudo mysql_secure_installation
脚本会依次弹出以下问题(根据实际环境选择,建议按安全最佳实践配置):
Press y|Y for Yes, any other key for No: y# 这是 MySQL 安全配置中设置密码验证策略强度的交互提示,需要输入数字选择强度:
# 输入 0 对应 LOW(低强度,仅检查长度)
# 输入 1 对应 MEDIUM(中等强度,默认推荐,检查长度、数字、大小写、特殊字符)
# 输入 2 对应 STRONG(高强度,在中等基础上增加字典检查)
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 2# 移除匿名用户? 选 y
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y# 禁止 root 远程登录? 生产环境选 y
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y# 移除 test 数据库? 选 y
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y# 刷新权限让配置生效? 选 y
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
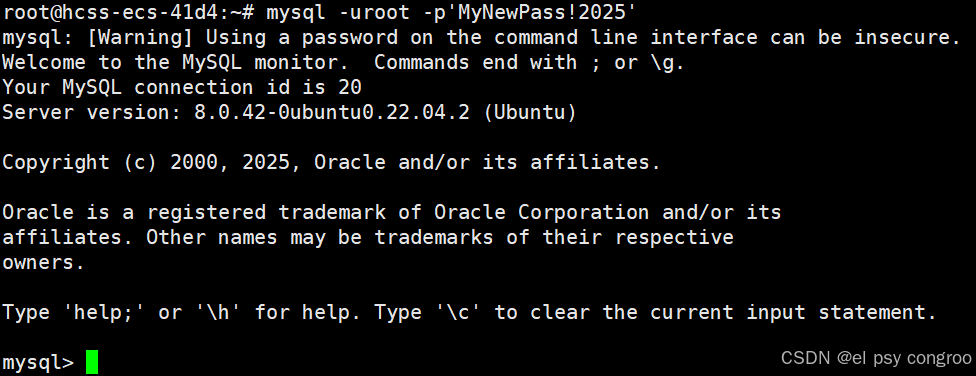
- 设置密码
连接mysql服务器,由于没有设置密码,不用输密码直接就能进入
使用 alter user 命令修改密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
如果要退出 MySQL 的话可以 ctrl+d 或者输入 exit/quit 回车
要连接 MySQL 可以输入mysql -u用户名 -p
- -u后面紧跟用户名
- 执行后,系统会提示 Enter password: ,在这后面输入密码(输入的值是不显示的)
还有一种连接方式:mysql -u用户名 -p密码,密码(如果有特殊符号建议用单引号包裹)紧跟在 -p 后面,无空格。这种写法会将密码明文暴露在命令历史或日志中,存在安全风险
卸载 mysql
# 停止 MySQL 服务
# 说明:卸载前必须先停止服务,避免文件被占用导致卸载失败或残留
sudo systemctl stop mysql# 彻底卸载 MySQL 核心组件
# 包含服务器端(mysql-server)、客户端(mysql-client)和通用组件(mysql-common)
sudo apt-get purge mysql-server mysql-client mysql-common# 删除残留的配置文件和数据目录
# 说明:这些目录不会被 apt 自动清理,包含数据库文件、日志和自定义配置
# /etc/mysql:全局配置文件目录;/var/lib/mysql:实际数据存储目录
sudo rm -rf /etc/mysql /var/lib/mysql# 清理不再需要的依赖和缓存文件
# autoremove:移除因安装 MySQL 而自动安装的、现在无用的依赖包
# autoclean:清理本地缓存中已过时的 .deb 安装包,释放磁盘空间
sudo apt-get autoremove
sudo apt-get autoclean# 验证 MySQL 是否完全卸载
mysql --version
部署 Web 项目到 Linux
程序开发与发布涉及三类核心环境,各自承担不同职能:
- 开发环境:专供开发人员编写、调试代码的机器环境,是程序诞生的 “初稿阶段”
- 测试环境:供测试人员对开发完成的程序进行功能、性能等多维度测试的机器环境,用于排查问题、完善程序,相当于 “审核阶段”
- 生产环境(线上环境):最终发布项目时所使用的机器环境,直接面向外网用户,对稳定性要求极高,是程序的 “正式上线阶段”
而将程序安装到生产环境的过程,被称为 “部署”(也叫 “上线”)。这一步至关重要:部署成功后,程序即可被万千普通用户访问;若程序存在 BUG,用户会直接接触到;一旦部署过程出现问题,甚至可能引发服务器不可用等严重事故
为降低部署风险,企业通常会采用 Jenkins 等自动化部署工具,但本文先通过手工部署的方式实践这一过程
环境配置
一、环境基础准备:数据结构一致性
程序运行依赖的数据库表结构需在各环境(开发、测试、生产等)保持一致。操作方式:
- 复用统一的数据库建表脚本(如 SQL 文件),在目标服务器的数据库中执行
- 执行前建议通过版本控制工具(如 Git)确认脚本为最新稳定版,避免因表结构差异导致程序报错
- 执行后验证表结构完整性(如字段类型、约束、索引等),确保与开发环境完全一致
二、多环境配置管理:区分差异,统一规范
不同环境(开发 dev、测试 test、生产 prod 等)的依赖配置(如数据库账号密码、服务地址、端口等)存在差异,建议通过「环境隔离的不同配置文件」管理,避免手动修改导致的错误
配置文件命名规范
采用「主配置文件 + 环境特定配置文件」 分离,配合动态激活机制,实现配置的安全、高效管理,命名格式固定为:
| 配置文件类型 | 命名格式 | 作用 |
|---|---|---|
| 主配置文件 | application.yml 或者 application.properties | 存放通用的配置(如应用名称、日志格式等),可指定默认激活的环境 |
| 环境特定配置文件 | application-XXX.yml 或者 application-XXX.properties (XXX 为环境标识,如 dev、test、prod) | 存放当前环境独有的配置(如数据库连接信息),仅在该环境激活时生效 |
下面以 application-XXX.yml 为例
- 主配置文件(application.yml):定义公共配置和默认激活环境,例如:
spring:application:name: mybatis-test # 应用名称,自定义(建议小写,用横线分隔)profiles:active: dev # 默认激活开发环境(可被运行时参数覆盖)
- 环境特定配置文件:仅存放当前环境的差异配置,例如数据库信息:
开发环境(application-dev.yml)对应配置:
# 数据库连接配置
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/dev_db?characterEncoding=utf8&useSSL=false # 开发环境数据库地址username: dev_user # 开发环境账号password: dev_pwd # 开发环境密码driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:# 配置 mybatis xml的⽂件路径,在resources/mapper创建表的 xml ⽂件mapper-locations: classpath:mapper/**Mapper.xmlconfiguration:# 开启 MyBatis 的日志打印功能并输出到控制台log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
生产环境(application-prod.yml)对应配置,不用加上 MyBatis 日志打印:
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/prod_db?characterEncoding=utf8&useSSL=false # 生产环境数据库地址username: prod_user # 生产环境账号password: prod_pwd # 生产环境密码driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:mapper-locations: classpath:mapper/**Mapper.xml
环境激活方式
环境激活的核心是指定 Spring 加载对应环境的配置文件,其实现方式可归纳为四类,优先级从低到高依次为:主配置文件默认指定、命令行参数、环境变量、JVM 系统属性。其中,后三类属于运行时参数,是动态切换环境的关键
一、四类环境指定方式
-
主配置文件默认指定,在 application.yml 中通过 spring.profiles.active: XXX 设置默认环境
- 作用:本地开发时无需额外配置,直接启动即可加载预设的环境配置
- 局限性:优先级最低,若通过其他方式指定环境,会被覆盖
-
命令行参数:启动时通过 --spring.profiles.active=XXX 传入参数(如 java -jar app.jar --spring.profiles.active=prod)。优先级高于主配置文件,无需修改配置文件,直接通过启动命令指定环境,适合临时切换场景
-
环境变量:系统中设置 SPRING_PROFILES_ACTIVE=XXX 环境变量(如 Linux 中 export SPRING_PROFILES_ACTIVE=test)。优先级高于命令行参数,适用于固定环境的部署场景(如测试服务器默认激活测试环境),避免每次启动手动输入参数
-
JVM 系统属性:启动时通过 -Dspring.profiles.active=XXX 定义 JVM 参数(如 java -Dspring.profiles.active=dev -jar app.jar)。灵活性极强,可在不修改代码或配置的情况下,快速适配开发、测试、生产等多场景
二、打包与运行阶段的处理逻辑
- 打包阶段:Maven/Gradle 会打包代码、src/main/resources/ 下的所有配置文件(包括主配置文件以及各环境特定配置文件),同时打包依赖库。注意:命令行参数、环境变量、JVM 系统属性 这三类参数不参与打包,仅为运行时参数
- 运行阶段:启动时,JVM 或 Spring 框架按优先级(从低到高:主配置文件默认值 → 命令行参数 → 环境变量 → JVM 系统属性)解析环境指定参数,选择最高优先级的参数值(如 test),加载对应的环境特定配置文件( application-test.yml),并与主配置文件(application.yml)中的通用配置合并后生效
实操技巧: 本地开发(IDE 配置)
主配置文件就指定生产环境的配置文件方便打包部署,而在 IDEA/Eclipse 的 “运行配置” 中添加 JVM 参数 -Dspring.profiles.active=dev,这样启动即加载开发环境
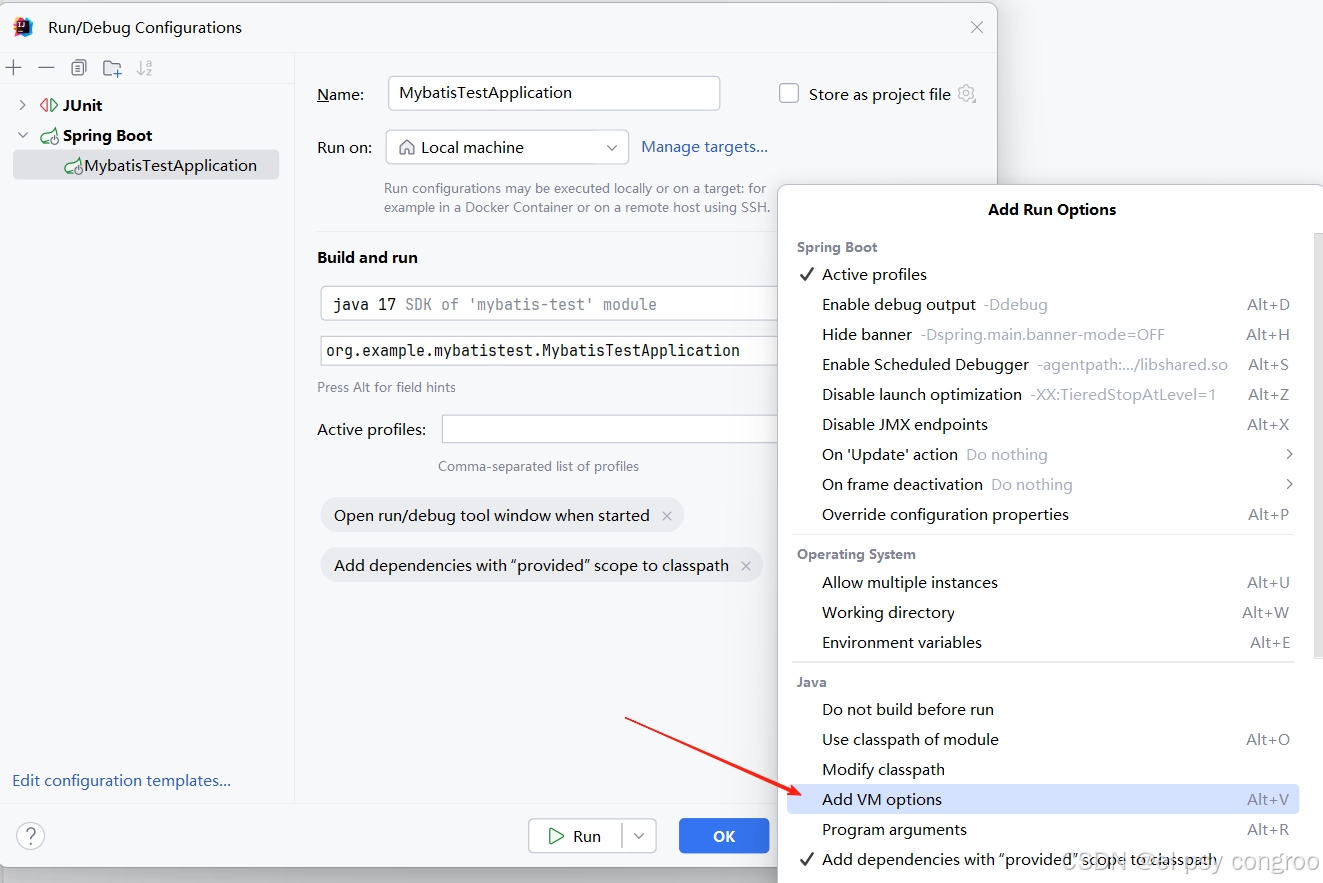
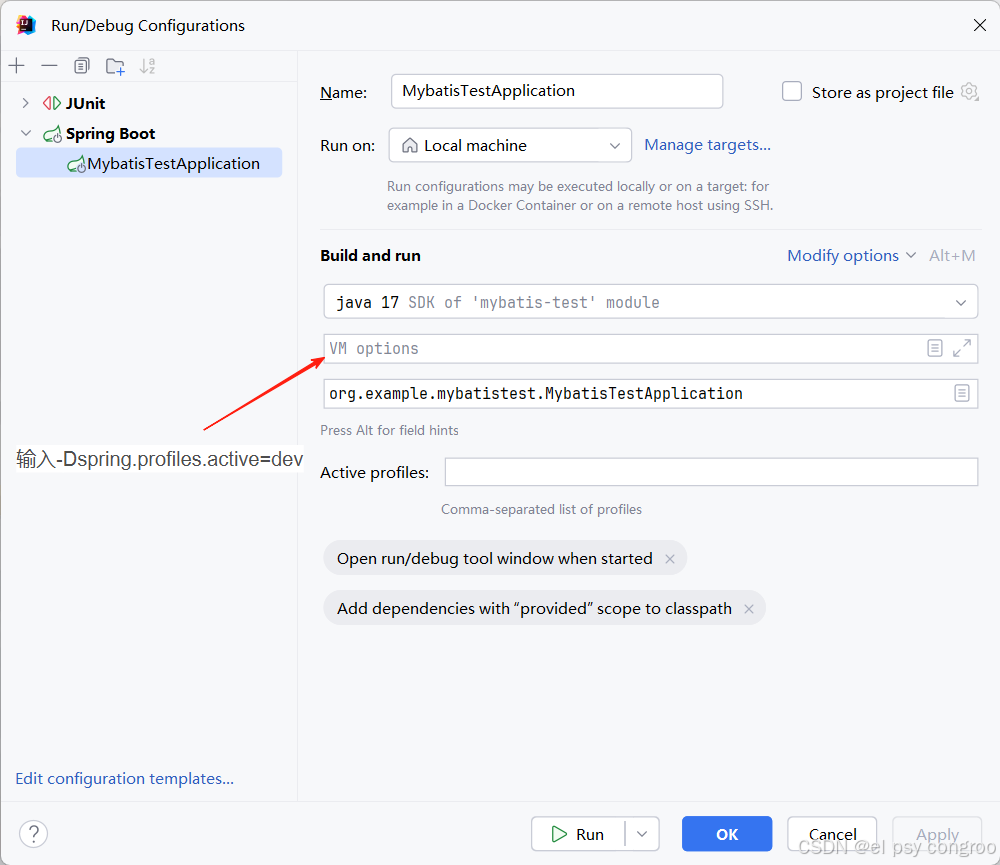
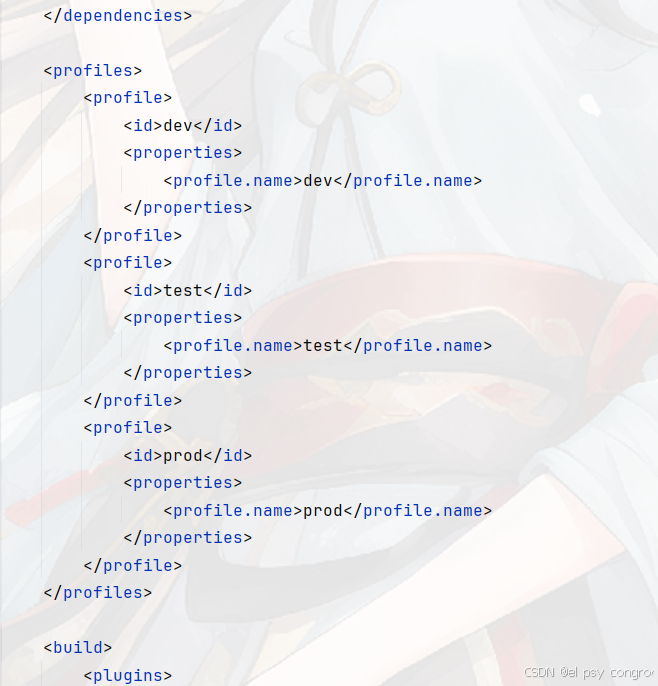
还可以使用 Maven 指定哪个配置文件:
<profiles><profile><id>dev</id><properties><profile.name>dev</profile.name></properties></profile><profile><id>test</id><properties><profile.name>test</profile.name></properties></profile><profile><id>prod</id><properties><profile.name>prod</profile.name></properties></profile></profiles>
主配置文件改成这样:
spring:profiles:active: @profile,name@
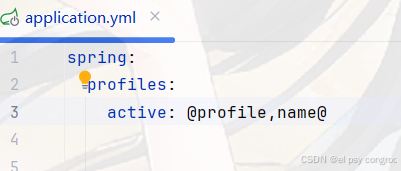
刷新 Maven ,Profiles 里面会多出这三个
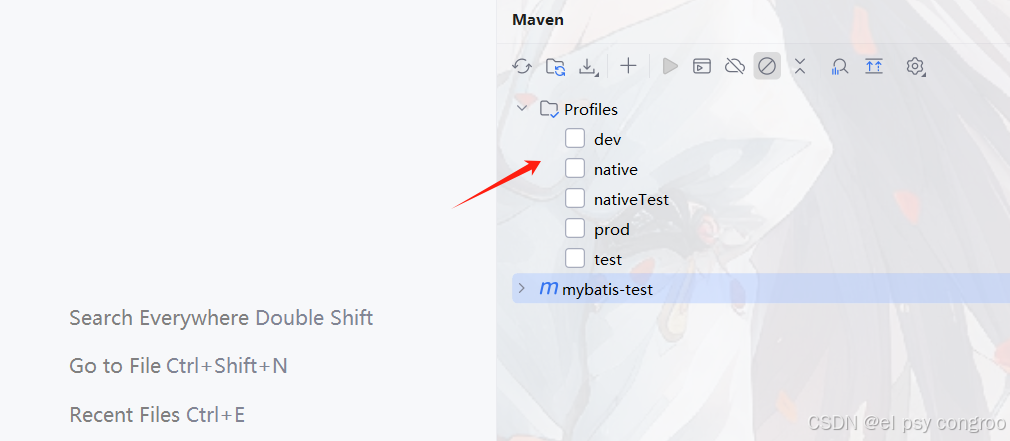
用哪个勾上哪个就行了,勾完记得刷新,还可以配置dev为默认的环境
<profile><id>dev</id><activation><activeByDefault>true</activeByDefault></activation><properties><profile.name>dev</profile.name></properties></profile>
构建项目并打包(使用 Maven )
在使用 Maven 构建 Spring Boot 项目时(如执行 package 命令打包),Maven 默认会先执行项目中的测试代码(如 JUnit 测试用例),再进入打包阶段。打包过程中,我们常常需要跳过测试阶段,原因如下:
- 若测试代码涉及数据库连接、远程服务调用等环境相关操作,例如测试用例要连接数据库,但打包用的是生产环境的配置,就可能导致数据库账号密码错误,从而导致测试失败,中断打包流程。此时跳过测试可避免因环境问题阻塞打包
- 节省构建时间。当项目规模较大、测试用例繁多时,运行全部测试可能耗时数分钟甚至更久。跳过测试能显著加快打包速度
在 IDEA 点击下图的图标,即可跳过测试
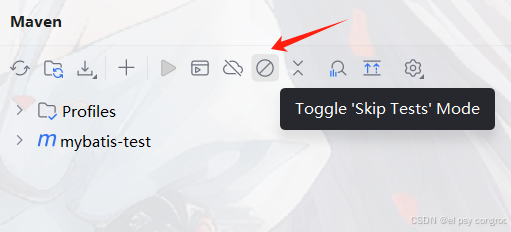
点击该按钮后,在执行 Maven 的 package 等构建命令时,就会跳过测试阶段,直接进行后续的打包等操作;再次点击则关闭 “跳过测试” 模式,恢复 Maven 正常的构建流程
Maven 打包时,多数情况下建议先执行 clean 以避免旧文件残留导致异常,再点击 package 进行打包
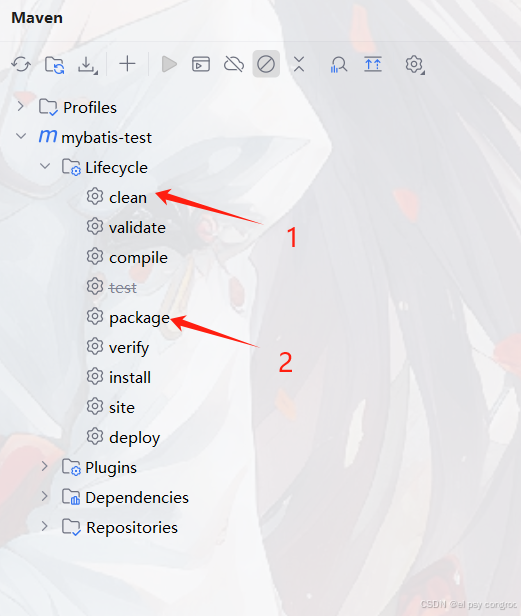
根据打包结果找到 jar 包
上传 jar 包到服务器,并运行
直接拖动打包好的 jar 包到 Xshell 窗口即可完成文件的上传,这个依赖 rz 命令,如果不行可以自己安装或者使用第三方工具
rz(Receive Zmodem)和 sz(Send Zmodem)是基于 Zmodem 协议的文件传输命令,适用于通过 SSH 或 Telnet 连接的终端环境,无需额外图形界面即可快速实现本地与远程服务器的文件互传
如果执行上述命令之后,提示 Command ‘XX’ not found ,表示当前云服务器未安装 lrzsz ,可以通过包管理器安装:
# Debian/Ubuntu/Kali 系统
sudo apt-get install lrzsz # RedHat/CentOS 系统
sudo yum install lrzsz
安装后即可使用 rz(上传)和 sz(下载)命令
运行程序
java -jar mybatis-test-0.0.1-SNAPSHOT.jar
运行没问题之后可以设置后台运行程序,因为是后台运行程序所以看不到日志,推荐把日志输出重定向到指定文件中:
nohup java -jar mybatis-test-0.0.1-SNAPSHOT.jar >> mybatis-test.log 2>&1 &
- nohup: 后台运行程序,退出终端不会影响程序的运行
- 设置输出日志到 mybatis-test.log
- &:将程序放入后台执行,此时终端会立即释放,你可以继续输入其他命令,不影响后台程序的运行
记得云服务器一定要开放安全组/防火墙
常见问题
一个程序的正常运行,既依赖代码本身的正确性,也离不开运行环境的适配性。即便代码完全一致,在 Windows 系统能正常运行,在 Linux 系统中也可能出现问题 —— 不同操作系统对代码的解析逻辑和支持程度存在差异,例如 Windows 系统的 MySQL 不区分大小写,而 Linux 系统的 MySQL 则严格区分大小写,这类细节就可能导致程序行为不一致
当服务无法正常访问时,可从以下主要方向排查原因:
一、服务未启动
- 先通过 ps -ef|grep java 命令检查程序进程是否存在
- 若进程存在,可进一步通过 curl http://127.0.0.1:8080/login.html 测试本地访问
- 若能返回正常 HTML 页面,说明程序启动成功,问题可能出在端口未对外网开放
- 若服务未启动,则需查看日志定位具体原因,常见情况包括:
- 数据库不存在或表不存在(尤其注意 Linux 环境下的大小写问题)
- 数据库账号密码错误
- JDK 未安装、版本不兼容或环境变量配置有误等
二、端口未开放
若服务已正常启动但外部无法访问,需检查云服务器的防火墙规则或安全组配置,确认程序使用的端口(如 8080)是否已允许外部访问
停掉服务
如果我们需要重启服务,或者重新部署等,都需要先停止之前的服务
# 查看当前服务的进程
ps -ef|grep mybatis-test

上图 425197 就是该服务的进程
# 杀掉进程
kill -9 425197