基于Supervision工具库与YOLOv8模型的高效计算机视觉任务处理与实践
随着深度学习在图像识别、目标检测与语义分割等任务中的广泛应用,计算机视觉(
Computer Vision, CV)技术已逐步从实验室研究走向工业级落地。然而,不同模型框架之间的异构性、数据格式的多样性以及可视化与评估流程的碎片化,显著增加了开发与部署的成本。在此背景下,SuperVision 作为一款高效、灵活且开源的计算机视觉工具箱,凭借其模型无关性(model-agnostic)设计与端到端工作流支持能力,正迅速成为开发者构建CV系统的首选基础设施。

1. Supervision的核心功能及其优势
项目地址:https://github.com/roboflow/supervision
官方介绍及文档地址:https://supervision.roboflow.com/latest/
(1) 灵活的自定义模型集成
Supervision的一大亮点在于其无模型依赖的设计理念。无论是Ultralytics的YOLO系列,还是Transformers、MMDetection等主流深度学习框架,开发者都能灵活选择最适合项目的模型进行集成。这种高度开放的模型兼容性使Supervision能够轻松适应各种领域和应用场景,彻底消除了开发者的模型兼容性顾虑。借助这一优势,开发者可以快速构建并优化满足特定需求的计算机视觉系统。
(2) 多格式数据集管理与转换
SuperVision提供了一套完整的数据集操作工具链,支持主流标注格式的加载、分割、合并与导出,包括:
- COCO(Common Objects in Context)
- YOLO(.txt 标注格式)
- Pascal VOC(XML 格式)
通过 Dataset 类接口,开发者可以轻松实现:
- 自动按比例划分训练集、验证集和测试集(如 7:1.5:1.5)
- 跨数据集的类别对齐与合并
- 一键转换标注格式,解决多源数据融合难题
(3) 通用注释与可视化引擎
SuperVision 内置高度可配置的注释渲染引擎(Annotator Engine),可在图像和视频帧上精准绘制多种标注元素,包括:
- 边界框
- 掩码区域
- 关键点
- 标签文本
- 置信度信息
核心功能特色:
① 支持自定义:
- 颜色映射方案
- 字体样式
- 边界框线型
② 提供多种预设视觉模板:
- “box-annotator”
- “mask-annotator”
- 支持视频流实时标注和监控场景回放分析
(4) 高级视觉任务抽象层
SuperVision 将常见高级视觉任务抽象为可复用组件,显著降低复杂逻辑的实现门槛:
| 功能模块 | 技术说明 |
|---|---|
| 区域统计(Zone Analytics) | 能够对特定区域内的检测结果进行精确跟踪和统计。通过定义感兴趣区域,Supervision 可以实时监测该区域内目标的数量、出现频率等信息,这在安防监控、零售数据分析等领域具有广泛的应用。 |
| 越线检测(Line Crossing Detection) | 配置虚拟警戒线,实时判断目标是否越界,广泛应用于交通违规监测、禁区闯入预警 |
| 轨迹平滑(Track Smoothing) | 在目标跟踪过程中,Supervision 能够对目标的轨迹进行平滑处理,减少因检测误差等因素导致的轨迹跳动和不连续现象,使目标的运动轨迹更加稳定和准确,为后续的分析和决策提供更可靠的数据支持。 |
| 切片推理(Slicing Inference) | 将高分辨率图像分割为重叠子图进行分块推理,避免显存溢出,适用于航拍、医学影像等大图处理 |
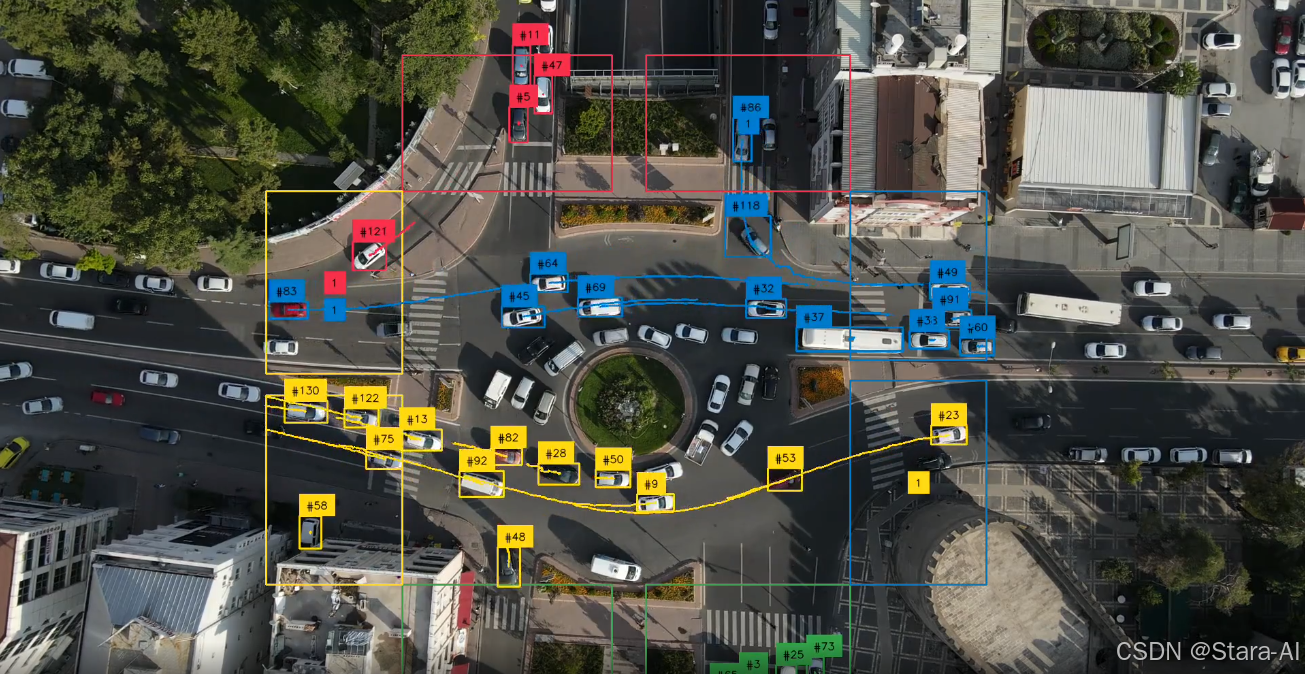
(5) Roboflow API 集成与云推理支持
Supervision支持通过Roboflow API进行推理,开发者只需提供API密钥,便可以快速进行预训练模型的推理。推理结果完成后,Supervision还提供了丰富的分析工具,帮助开发者评估模型的性能,包括计算准确率、召回率、F1分数等常见指标。这些分析工具使得开发者能够更精确地评估模型效果,并根据反馈进行优化。
import cv2
import supervision as sv
from inference import get_modelimage = cv2.imread(...)
model = get_model(model_id="yolov8s-640", api_key=<ROBOFLOW API KEY>)
result = model.infer(image)[0]
detections = sv.Detections.from_inference(result)len(detections)
# 5
2. Supervision与YOLOv8的完美结合
-
Supervision 需要
Python>=3.9环境中安装pip install supervision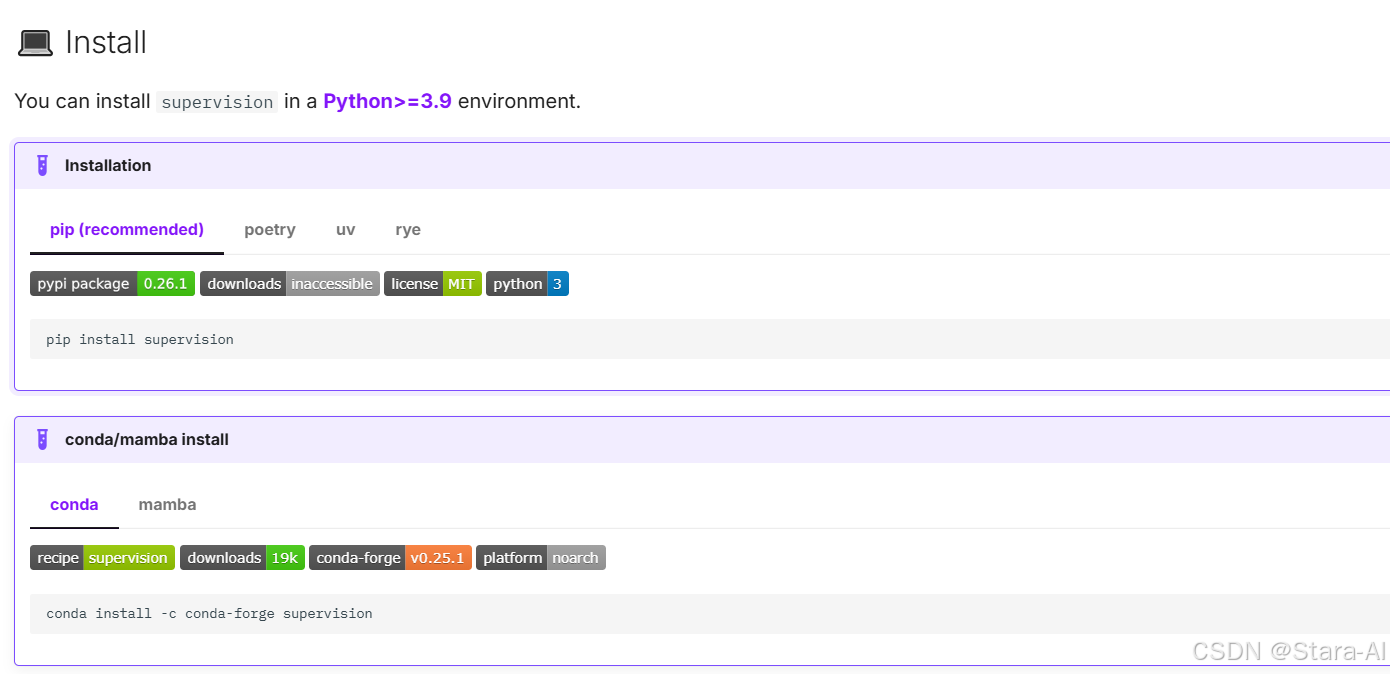
2.1 目标追踪
"""
目标追踪是指在视频序列中持续识别并定位特定目标(单目标或多目标)及其运动轨迹。
Supervision 提供的 ByteTrack 类能够帮助我们快速实现这一功能。"""
import cv2
import supervision as sv
from ultralytics import YOLO
from supervision.assets import download_assets, VideoAssets# 如果不存在则下载视频
video_name = download_assets(VideoAssets.PEOPLE_WALKING)
# 加载 YoloV8n 模型,如果不存在会自动下载
model = YOLO("yolov8n.pt")
# 追踪器
tracker = sv.ByteTrack()
# 初始化展现对象
corner_annotator = sv.BoxCornerAnnotator(corner_length=15,thickness=2,color=sv.Color(r=255, g=255, b=0)
)
label_annotator = sv.LabelAnnotator()
trace_annotator = sv.TraceAnnotator(trace_length=100,color=sv.Color(r=255, g=0, b=0)
)
# 读取视频
cap = cv2.VideoCapture(video_name)
# 初始化计时器
prev_tick = cv2.getTickCount()
while True:# 循环读取每一帧ret, frame = cap.read()# 由于原视频帧比较大,方便处理和后面展现,缩小一些frame = cv2.resize(frame, (1280, 720))if not ret:breakresult = model(frame,conf=0.5,device=[0] # 如果是 cpu 则是 device='cpu')[0]detections = sv.Detections.from_ultralytics(result)# 目标跟踪detections = tracker.update_with_detections(detections)labels = [f"{tracker_id} {result.names[class_id]}" for class_id, tracker_id inzip(detections.class_id, detections.tracker_id)]# 绘制边框frame = corner_annotator.annotate(frame, detections=detections)# 绘制标签frame = label_annotator.annotate(frame, detections=detections, labels=labels)# 绘制轨迹frame = trace_annotator.annotate(frame, detections=detections)# 计算帧率current_tick = cv2.getTickCount()fps = cv2.getTickFrequency() / (current_tick - prev_tick)prev_tick = current_tickcv2.putText(frame, "FPS: {:.2f}".format(fps), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow('video', frame)cv2.waitKey(1)
"""
轨迹平滑处理
直接从追踪算法获取的输出结果常含有噪声和断点,可能导致轨迹不平滑、不自然。
Supervision 提供的 DetectionsSmoother 类可帮助我们快速实现轨迹平滑功能。"""
import cv2
import supervision as sv
from ultralytics import YOLO
from supervision.assets import download_assets, VideoAssets# 如果不存在则下载视频
video_name = download_assets(VideoAssets.PEOPLE_WALKING)
# 加载 YoloV8n 模型,如果不存在会自动下载
model = YOLO("yolov8n.pt")
# 追踪器
tracker = sv.ByteTrack()
# 轨迹平滑器
smoother = sv.DetectionsSmoother(length=4)
# 初始化展现对象
corner_annotator = sv.BoxCornerAnnotator(corner_length=15,thickness=2,color=sv.Color(r=255, g=255, b=0)
)
label_annotator = sv.LabelAnnotator()
trace_annotator = sv.TraceAnnotator(trace_length=100,color=sv.Color(r=255, g=0, b=0)
)
# 读取视频
cap = cv2.VideoCapture(video_name)
# 初始化计时器
prev_tick = cv2.getTickCount()
while True:# 循环读取每一帧ret, frame = cap.read()# 由于原视频帧比较大,方便处理和后面展现,缩小一些frame = cv2.resize(frame, (1280, 720))if not ret:breakresult = model(frame,device=[0] # 如果是 cpu 则是 device='cpu')[0]detections = sv.Detections.from_ultralytics(result)# 目标跟踪detections = tracker.update_with_detections(detections)# 轨迹平滑detections = smoother.update_with_detections(detections)labels = [f"{tracker_id} {result.names[class_id]}" for class_id, tracker_id inzip(detections.class_id, detections.tracker_id)]# 绘制边框frame = corner_annotator.annotate(frame, detections=detections)# 绘制标签frame = label_annotator.annotate(frame, detections=detections, labels=labels)# 绘制轨迹frame = trace_annotator.annotate(frame, detections=detections)# 计算帧率current_tick = cv2.getTickCount()fps = cv2.getTickFrequency() / (current_tick - prev_tick)prev_tick = current_tickcv2.putText(frame, "FPS: {:.2f}".format(fps), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow('video', frame)cv2.waitKey(1)2.2 越线统计
"""
通过在视频中设置虚拟边界线,系统可自动统计越界目标数量。
这一功能广泛应用于交通监控和安防领域。
Supervision库提供的LineZone类能帮助我们快速实现该功能。"""
import cv2
import supervision as sv
from ultralytics import YOLO
from supervision.assets import download_assets, VideoAssets# 如果不存在则下载视频
video_name = download_assets(VideoAssets.VEHICLES)
# 加载 YoloV8n 模型,如果不存在会自动下载
model = YOLO("yolov8n.pt")# 预设界限
start = sv.Point(0, 400)
end = sv.Point(1280, 400)
# 初始预线检测器
line_zone = sv.LineZone(start=start,end=end
)
# 追踪器
tracker = sv.ByteTrack()
# 初始化展现对象
trace_annotator = sv.TraceAnnotator()
label_annotator = sv.LabelAnnotator(text_scale=1
)
line_zone_annotator = sv.LineZoneAnnotator(thickness=1,text_thickness=1,text_scale=1
)# 读取视频
cap = cv2.VideoCapture(video_name)
# 初始化计时器
prev_tick = cv2.getTickCount()
while True:# 循环读取每一帧ret, frame = cap.read()if not ret:break# 由于原视频帧比较大,方便处理和后面展现,缩小一些frame = cv2.resize(frame, (1280, 720))result = model(frame,device=[0] # 如果是 cpu 则是 device='cpu')[0]detections = sv.Detections.from_ultralytics(result)# 目标跟踪detections = tracker.update_with_detections(detections)# 更新预线检测器crossed_in, crossed_out = line_zone.trigger(detections)print(f'in:{line_zone.in_count}', f'out:{line_zone.out_count}')# 获得各边界框的标签labels = [f"{result.names[class_id]}"for class_id, tracker_idin zip(detections.class_id, detections.tracker_id)]# 绘制轨迹frame = trace_annotator.annotate(frame, detections=detections)# 绘制标签frame = label_annotator.annotate(frame, detections=detections, labels=labels)# 绘制预制线frame = line_zone_annotator.annotate(frame, line_counter=line_zone)# 计算帧率current_tick = cv2.getTickCount()fps = cv2.getTickFrequency() / (current_tick - prev_tick)prev_tick = current_tickcv2.putText(frame, "FPS: {:.2f}".format(fps), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)cv2.imshow('video', frame)cv2.waitKey(1)
2.3 切片检测
"""
当图像尺寸过大或目标过小时,会降低检测效果。此时可以采用分片检测的方法:
将图像分割成多个区域分别处理,再合并结果并进行NMS过滤。Supervision已封装该功能,
提供了InferenceSlicer类来快速实现这一流程。
"""
import cv2
import supervision as sv
from ultralytics import YOLO
import numpy as np# 加载 yolov8n 模型
model = YOLO("yolov8n.pt")# 切片之后的处理
def callback(image_slice: np.ndarray) -> sv.Detections:result = model(image_slice, verbose=False)[0]return sv.Detections.from_ultralytics(result)# 初始化切片器
slicer = sv.InferenceSlicer(callback=callback, # 切片后每张子图进行处理的回调函数slice_wh=(320, 320), # 切片后子图的大小overlap_ratio_wh=(0.3, 0.3), # 连续切片之间的重叠率iou_threshold=0.5, # 子图合并nms的iou阈值thread_workers=4 # 处理线程数
)
# 展现对象
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()# 读取图像
image = cv2.imread("img/3.png")
result = model(image,device=[0] # 如果是 cpu 则是 device='cpu'
)[0]
detections = sv.Detections.from_ultralytics(result)
image1 = box_annotator.annotate(image.copy(), detections=detections)
# 绘制标签
labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image1 = label_annotator.annotate(image1, detections=detections, labels=labels)
# 展现未切片的结果
cv2.imshow('img', image1)
cv2.waitKey(0)# 切片检测
detections = slicer(image)
image2 = box_annotator.annotate(image.copy(), detections=detections)
# 绘制标签
labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image2 = label_annotator.annotate(image2, detections=detections, labels=labels)
# 展现切片后的结果
cv2.imshow('img', image2)
cv2.waitKey(0)未切片:
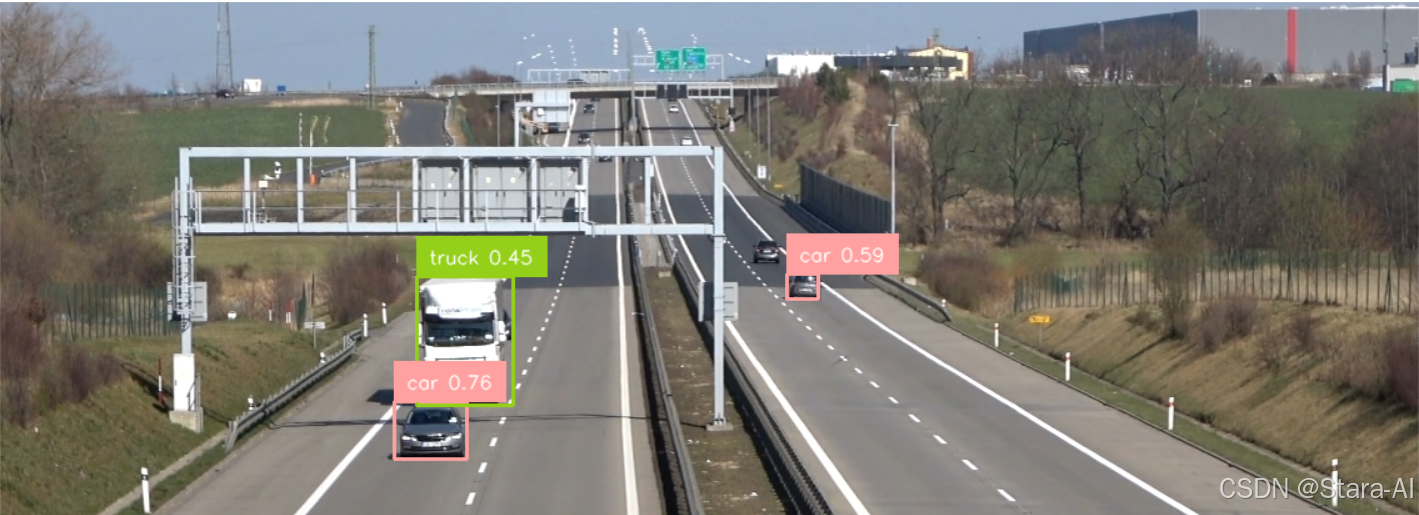
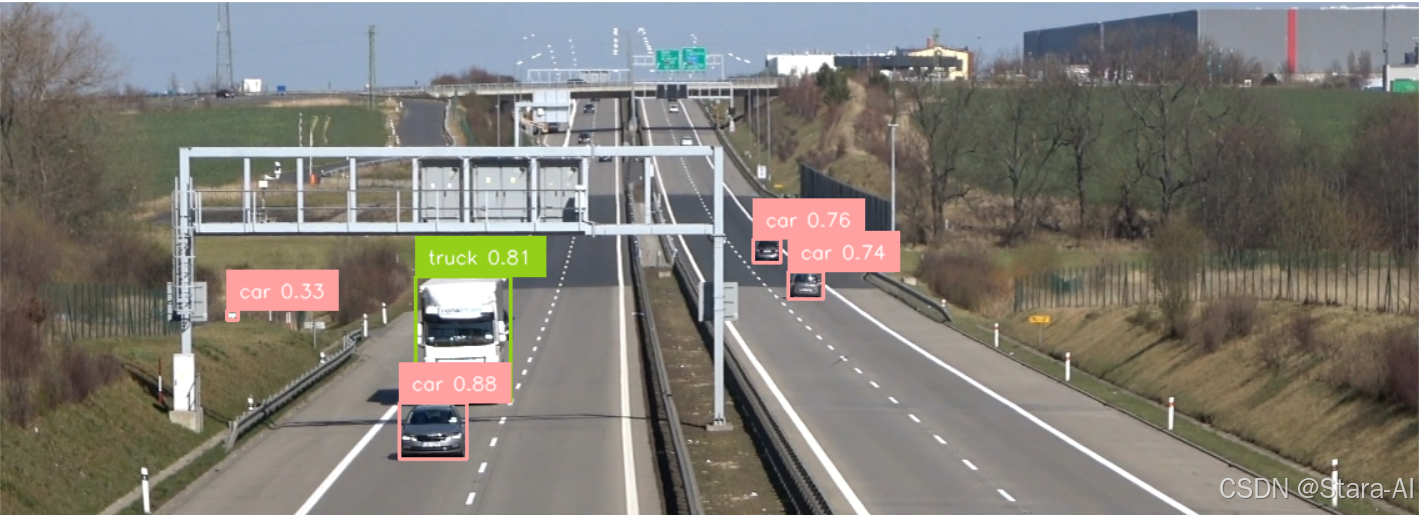
切片后:
2.4 目标检测
通过跟踪 ID 标注视频可以有效区分和追踪各个对象。借助 sv.LabelAnnotator,我们可以在检测到的对象上叠加跟踪器 ID 和类别标签,从而清晰地展示每个对象的类别及其唯一标识信息。
官方代码:
import numpy as np
import supervision as sv
from ultralytics import YOLOmodel = YOLO("yolov8n.pt")
tracker = sv.ByteTrack()
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()def callback(frame: np.ndarray, _: int) -> np.ndarray:results = model(frame)[0]detections = sv.Detections.from_ultralytics(results)detections = tracker.update_with_detections(detections)labels = [f"#{tracker_id} {class_name}"for class_name, tracker_idin zip(detections.data["class_name"], detections.tracker_id)]annotated_frame = box_annotator.annotate(frame.copy(), detections=detections)return label_annotator.annotate(annotated_frame, detections=detections, labels=labels)sv.process_video(source_path="people-walking.mp4",target_path="result.mp4",callback=callback
)

边界呈现
"""
边框展现
"""
import cv2
import supervision as sv
from ultralytics import YOLO
import numpy as np# 加载 yolov8n 模型
model = YOLO("yolov8n.pt")# 方框展现对象
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()# 读取图像
image = cv2.imread("img/img.png")
result = model(image,device=[0] # 如果是 cpu 则是 device='cpu'
)[0]
detections = sv.Detections.from_ultralytics(result)
image = box_annotator.annotate(image, detections=detections)
# 绘制标签
labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image = label_annotator.annotate(image, detections=detections, labels=labels)
cv2.imshow('img', image)
cv2.waitKey(0)
角点边框:
import cv2
import supervision as sv
from ultralytics import YOLO
import numpy as np# 加载 yolov8n 模型
model = YOLO("yolov8n.pt")# 角点边框展现对象
corner_annotator = sv.BoxCornerAnnotator(corner_length=15,thickness=2,color=sv.Color(r=255, g=0, b=0)
)
label_annotator = sv.LabelAnnotator()# 读取图像
image = cv2.imread("img/img.png")
result = model(image,device=[0] # 如果是 cpu 则是 device='cpu'
)[0]
detections = sv.Detections.from_ultralytics(result)
image = corner_annotator.annotate(image, detections=detections)
# 绘制标签
labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image = label_annotator.annotate(image, detections=detections, labels=labels)
cv2.imshow('img', image)
cv2.waitKey(0)
三角形投标
import cv2
import supervision as sv
from ultralytics import YOLO
import numpy as np# 加载 yolov8n 模型
model = YOLO("yolov8n.pt")# 三角展现对象
triangle_annotator = sv.TriangleAnnotator(base = 30,height = 30,position = sv.Position['TOP_CENTER'],color=sv.Color(r=0, g=255, b=0)
)label_annotator = sv.LabelAnnotator()# 读取图像
image = cv2.imread("img/img.png")
result = model(image,device=[0] # 如果是 cpu 则是 device='cpu'
)[0]
detections = sv.Detections.from_ultralytics(result)labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image = label_annotator.annotate(image, detections=detections, labels=labels)image = triangle_annotator.annotate(image, detections=detections)
cv2.imshow('img', image)
cv2.waitKey(0)

2.5 语义分割
import cv2
import supervision as sv
from ultralytics import YOLO# 加载 yolov8n-seg 模型
model = YOLO("yolov8n-seg.pt")# 语义分割展现对象
mask_annotator = sv.MaskAnnotator()
label_annotator = sv.LabelAnnotator()# 读取图像
image = cv2.imread("img/img.png")
result = model(image,device=[0] # 如果是 cpu 则是 device='cpu'
)[0]
detections = sv.Detections.from_ultralytics(result)labels = [f"{class_name} {confidence:.2f}" for class_name, confidence inzip(detections['class_name'], detections.confidence)]
image = label_annotator.annotate(image, detections=detections, labels=labels)image = mask_annotator.annotate(image, detections=detections)
cv2.imshow('img', image)
cv2.waitKey(0)

3. 总结展望
1、总结
通过将Supervision工具库与YOLOv8模型结合使用,开发者可以充分发挥YOLOv8在目标检测任务中的优异性能,同时借助Supervision提供的强大数据处理、模型集成和可视化功能,大幅提升计算机视觉任务的开发效率和精准度。Supervision提供的灵活模型集成、全面的数据集管理、精准的检测结果绘制、强大的注释与推理分析功能,使得开发者能够更加高效地进行目标检测、图像分类、实例分割等计算机视觉任务。
尤其是在YOLOv8的集成应用中,Supervision不仅优化了数据集的加载和处理,还通过封装多样的视觉任务与智能工具,极大地提高了模型的训练和推理效率。在不断更新的功能支持下,Supervision能够持续适应行业的变化和需求,为开发者提供更高效、更可靠的计算机视觉开发平台。
2、展望
- 进一步提升模型集成与扩展性
- 智能化数据处理与自动化优化
- 更高效的推理速度与资源利用
- 跨行业应用与智能化拓展
- 增强的数据增强与自监督学习功能