VerIF
1. 研究背景与问题
-
背景:
大型语言模型(LLMs)的指令跟随能力对其实际应用至关重要。传统的监督微调(SFT)和直接偏好优化(DPO)方法在复杂指令(如多约束条件)的跟随上表现有限。-
现有问题:
-
验证方法单一:现有研究(如TULU 3)仅针对硬约束(如长度、格式)设计规则验证,忽略软约束(如风格、语义)的验证需求。
-
数据稀缺:缺乏高质量、带验证信号的指令跟随数据集,限制了强化学习(RL)的应用。
-
2. 核心贡献
2.1 VerIF,一种混合验证方法:
VerIF(Verification Engineering for Reinforcement Learning in Instruction Following)的核心创新在于结合规则验证(硬约束)和LLM推理验证(软约束),为强化学习(RL)提供更精准的奖励信号。以下是其详细实现流程:
1. 约束分类
给定一条指令 x及其约束集合 C={c1,c2,...,cn},VerIF 将约束分为两类:
-
硬约束(Hard Constraints, Ch):可通过确定性规则或代码验证,例如:
-
长度约束(如“回答不超过100词”)
-
关键词约束(如“必须包含‘深度学习’一词”)
-
格式约束(如“以Markdown列表形式输出”)
-
-
软约束(Soft Constraints, Cs):需语义理解,例如:
-
风格约束(如“用学术写作风格”)
-
内容约束(如“避免主观观点”)
-
逻辑一致性(如“回答需与问题上下文一致”)
-
2. 验证流程
VerIF 的验证函数定义为:
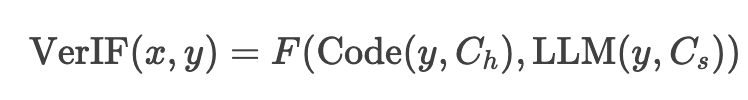
其中:
-
Code(y,Ch)∈{0,1}:通过代码检查硬约束是否满足。
-
LLM(y,Cs)∈{0,1}:通过大语言模型判断软约束是否满足。
-
F:聚合函数(默认取平均值)。
(1) 硬约束的代码验证
-
实现方式:
对每条硬约束,使用 Qwen2.5-72B-Instruct 自动生成 Python 验证代码。例如:# 检查“回答不超过100词” def check_length(response):return len(response.split()) <= 100# 检查“必须包含‘深度学习’” def check_keyword(response):return "深度学习" in response -
优势:
-
高效:代码执行速度快,适合大规模RL训练。
-
确定性:避免LLM在数值/格式判断上的不稳定性(如GPT-4在计数任务中表现较差)。
-
(2) 软约束的LLM验证
-
实现方式:
使用 QwQ-32B(专长推理的大模型)对软约束进行链式推理(Chain-of-Thought)验证。输入格式示例:[指令] 写一段关于强化学习的科普,风格需幽默且避免术语。 [响应] (待验证的文本) [任务] 判断响应是否满足以下约束: 1. 风格幽默(是/否) 2. 未使用专业术语(是/否) -
优势:
-
语义理解:能处理风格、逻辑等复杂约束。
-
灵活性:无需预定义规则,适应多样化指令。
-
(3) 奖励计算
最终奖励 RR 为硬约束和软约束得分的平均:
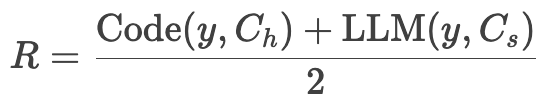
-
若所有约束均满足,R=1;否则 R∈[0,1)。
3. 关键技术点
(1) 混合验证的必要性
-
消融实验(表4)显示:
-
仅代码验证(w/o LLM):软约束准确率仅13.2%。
-
仅LLM验证(w/o Code):硬约束准确率仅31.5%(如长度、关键词判断差)。
-
混合方法(VerIF)综合准确率达58.1%,显著优于单一方法。
-
(2) 高效LLM验证优化
-
问题:QwQ-32B在线验证成本高(占训练时间80%)。
-
解决方案:
-
批量处理:一次性输入所有软约束,减少API调用次数。
-
蒸馏小验证器:训练 IF-Verifier-7B(基于DeepSeek-R1蒸馏),性能接近QwQ-32B但速度更快。
-
(3) 数据构造的自动化
-
VerInstruct数据集通过以下步骤生成:
-
约束反译:从原始指令-响应对中反向生成约束(如“响应风格幽默” → 添加“风格: 幽默”约束)。
-
验证信号标注:硬约束生成代码,软约束标记为“需LLM验证”。
-
4. 实际应用示例
指令:
“写一篇关于气候变化的短文,要求:
-
不超过200词(硬约束)
-
包含关键词‘碳中和’(硬约束)
-
使用正式学术风格(软约束)。”
验证过程:
-
硬约束:
-
代码检查词数
len(text.split()) <= 200→ True -
代码检查关键词
"碳中和" in text→ True
-
-
软约束:
-
LLM判断“是否正式学术风格” → True
-
-
最终奖励:R=(1+1+1)/3=1R=(1+1+1)/3=1
5. 优势总结
| 维度 | VerIF优势 |
|---|---|
| 准确性 | 硬约束代码验证100%可靠,软约束LLM验证优于纯规则 |
| 效率 | 代码验证降低LLM调用成本,适合大规模RL训练 |
| 泛化性 | 适应未见约束类型(如多语言、多轮指令) |
| 可扩展性 | 支持自定义约束类型和验证逻辑 |
通过这种混合验证策略,VerIF在指令跟随任务中实现了高精度奖励建模,为RL训练提供了稳定信号,同时避免了传统方法对人工标注的依赖。
2.2 数据集构建:发布 VerInstruct 数据集(22k条实例)
VerInstruct 是专为强化学习(RL)设计的指令跟随数据集,核心特点是每条指令附带多类型约束和验证信号。以下是其构建的完整流程:
1. 原始数据收集(Data Collection)
-
数据来源:4个高质量开源指令数据集:
-
Alpaca-GPT4(学术指令)
-
Orca-Chat(多轮对话)
-
Evol-Instruct(复杂指令增强)
-
OpenAssistant(社区生成指令)
-
-
筛选标准:去除低质量、重复或敏感内容,保留约25k条指令-响应对。
2. 约束生成(Constraint Generation)
通过约束反译(Constraint Back-Translation)从响应反向生成约束:
-
方法:使用 Llama3.1-70B-Instruct 分析响应,提取隐含约束。
输入:[指令] 写一首关于春天的诗 [响应] 春风轻拂,樱花绽放。(语言风格:诗意)输出(生成约束):
{"Desired_Writing_Style": "使用诗歌语言","Keyword_Constraints": "包含‘春风’或‘樱花’" } -
硬约束补充:
-
长度约束:根据响应词长自动生成(如“≥50词”)。
-
格式约束:检测Markdown、列表等结构。
-
3. 约束分类与验证信号生成
将约束分为硬约束(代码验证)和软约束(LLM验证):
-
硬约束(22.3%):
-
类型:长度、关键词、基础格式。
-
验证代码生成:使用 Qwen2.5-72B-Instruct 自动编写Python检查脚本。
# 示例:检查“包含‘深度学习’一词” def check_keyword(response):return "深度学习" in response
-
-
软约束(77.7%):
-
类型:风格、内容逻辑、复杂格式。
-
标记为"LLM验证":训练时动态调用QwQ-32B判断。
-
4. 数据过滤与增强
-
过滤低质量数据:
-
去除约束数量<2的指令(确保多样性)。
-
人工抽查10%的生成代码,错误率<0.5%。
-
-
约束增强:
-
对部分指令人工添加对抗性约束(如“避免使用动词”),提升鲁棒性。
-
5. 最终数据集结构
VerInstruct 包含 22k条数据,每条结构如下:
{"instruction": "写一篇关于AI伦理的短文","constraints": [{"type": "length", "value": "≤300词", "verification": "code"},{"type": "style", "value": "学术语气", "verification": "LLM"}],"verification_code": "def check_length(r): return len(r.split())<=300"
}统计特征:
-
平均每条指令含 6.2个约束。
-
约束类型分布:
类型 占比 示例 长度 15% “≥100词” 关键词 7.3% “包含‘可持续发展’” 风格 42% “幽默风格” 内容逻辑 35.7% “不提及政治观点”
6. 与其他数据集的对比
| 数据集 | 约束类型 | 验证信号 | 数据量 | 用途 |
|---|---|---|---|---|
| VerInstruct | 硬+软 | 代码+LLM | 22k | RL训练 |
| IFEval | 硬约束为主 | 无 | 500 | 评测基准 |
| WildChat | 无明确约束 | 无 | 1M+ | 通用SFT |
核心优势:
-
唯一包含自动化验证信号的RL指令数据集。
-
约束多样性远超传统基准(如IFEval仅测试硬约束)。
7. 数据构建的技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 约束生成不准确 | 使用Llama3.1-70B反译 + 人工审核 |
| 硬约束代码生成错误 | Qwen2.5-72B生成 + 脚本自动化测试 |
| 软约束主观性强 | 用QwQ-32B做黄金标准,减少标注歧义 |
| 数据规模受限 | 基于高质量种子数据扩充,而非盲目爬取 |
总结:VerInstruct 的设计哲学
-
RL导向:为强化学习提供即时奖励信号,而非单纯SFT数据。
-
自动化优先:90%流程由LLM和代码生成,降低人工成本。
-
可扩展性:支持新增约束类型(如多模态指令的图片约束)。
通过这种构建方法,VerInstruct 成为首个支持多约束混合验证的指令数据集,直接推动了VerIF在RL训练中的高效性。
3. 实验与结果
-
实验设计:
-
基准模型:TULU 3 SFT 和 DeepSeek-R1-Distill-Qwen-7B。
-
训练方法:基于GRPO算法,使用VerIF提供奖励信号(硬/软约束得分平均)。
-
评估基准:IFEval、Multi-IF、SysBench等指令跟随任务,以及通用能力测试(如GSM8K、MMLU)。
-
-
关键结果:
-
性能提升:VerIF训练的模型在指令跟随任务中显著优于基线(如TULU 3 SFT + VerIF在IFEval上提升16.1%),甚至超越资源更丰富的工业模型(如Qwen2.5-7B)。
-
泛化性:
-
对未见的约束类型(如多语言、多轮指令)表现良好。
-
通用能力(数学推理、语言理解)未受损,部分任务(如MT-Bench)还有提升。
-
-
消融实验:验证混合方法必要性——仅代码或仅LLM验证均导致性能下降(见表4)。
-
4. 技术细节
-
高效验证器:
-
问题:QwQ-32B作为验证器计算成本高。
-
解决方案:蒸馏训练 IF-Verifier-7B(基于DeepSeek-R1-Distill-Qwen-7B),在130k数据上微调,性能接近QwQ-32B但计算成本大幅降低。
-
5. 局限性与未来方向
-
局限性:
-
VerInstruct仅含英语数据,可能限制多语言泛化。
-
LLM验证器存在固有偏差和对抗攻击风险。
-
-
未来方向:
-
扩展多语言RL数据。
-
开发更鲁棒的验证器(如对抗训练)。
-
6. 实践意义
-
开源资源:发布数据集、代码和模型(Apache 2.0许可),推动指令跟随RL研究。
-
方法普适性:VerIF可集成到现有RL流程中,增强指令跟随能力而不损害其他技能。
总结
VerIF通过结合规则与语义验证,解决了指令跟随中多约束验证的难题,实验证明其在性能、泛化性和效率上的优势,为LLM的RL训练提供了新范式。
附录:
1. 原始数据集选择标准
VerInstruct 从 4 个高质量开源指令数据集 中筛选数据,选择标准如下:
| 标准 | 说明 |
|---|---|
| 多样性 | 覆盖不同领域(学术、对话、创意写作等)和复杂度(简单指令→多约束指令)。 |
| 高质量响应 | 确保响应由专家或强LLM(如GPT-4)生成,避免低质量/噪声数据。 |
| 开源许可 | 采用符合商用要求的许可(如Apache 2.0、CC-BY-NC)。 |
| 结构化程度高 | 需包含清晰的指令-响应对,便于后续约束反译。 |
2. 核心数据来源及处理方式
(1) Alpaca-GPT4
-
来源:Stanford Alpaca 的GPT-4增强版。
-
特点:
-
52k条指令,涵盖学术、编程、日常问答等。
-
响应由GPT-4生成,逻辑严谨但约束较少。
-
-
处理:
-
从中随机抽取 8k条,侧重选择隐含风格/内容约束的样本(如“用比喻解释量子力学”)。
-
(2) Orca-Chat
-
来源:微软Orca 的复杂对话数据。
-
特点:
-
多轮对话,包含用户反馈(如“请更简洁”),天然含约束。
-
响应由GPT-4生成,语言质量高。
-
-
处理:
-
抽取 6k条 单轮指令,保留用户添加的显式约束(如“限100词内”)。
-
(3) Evol-Instruct
-
来源:WizardLM 的进化指令数据。
-
特点:
-
通过LLM迭代增强原始指令,复杂度高(如“对比A和B,并给出表格”)。
-
含多步骤、多模态(文本+表格)约束。
-
-
处理:
-
选择 7k条 最具挑战性的指令,优先保留结构化和多约束样本。
-
(4) OpenAssistant
-
来源:LAION开源的社区对话数据。
-
特点:
-
真实用户与AI的交互,含非正式约束(如“别用专业术语”)。
-
风格多样(幽默、严肃等)。
-
-
处理:
-
筛选 4k条 高质量对话,提取单轮指令并标准化约束表述。
-
3. 数据预处理流程
(1) 去重与清洗
-
去重:基于指令语义相似度(Sentence-BERT编码 + 余弦相似度<0.9)。
-
清洗:
-
过滤低质量响应(如含“[内容已删除]”)。
-
移除敏感内容(使用关键词黑名单+人工审核)。
-
(2) 约束反译(关键步骤)
-
工具:Llama3.1-70B-Instruct。
-
输入模板:
[Instruction]: {instruction} [Response]: {response} Task: 列出响应中隐含的约束条件(如风格、格式、内容限制)。 -
输出示例:
{"constraints": [{"type": "style", "value": "学术语气"},{"type": "keyword", "value": "包含‘神经网络’"}] } -
人工校验:随机检查10%的输出,修正错误标注(如将“诗歌”误标为“正式”)。
(3) 硬约束增强
-
自动生成:
-
长度约束:根据响应词长动态设置(如
round(len(response.split())/50)*50→ “≥50词”)。 -
格式约束:正则表达式检测Markdown、列表等(如响应含
-或*则添加“列表格式”约束)。
-
4. 数据分布与统计
(1) 领域分布
| 领域 | 比例 | 示例指令 |
|---|---|---|
| 学术/科技 | 35% | “解释Transformer架构的数学原理” |
| 日常问答 | 25% | “如何煮出完美的意大利面?” |
| 创意写作 | 20% | “以侦探视角写一个悬疑故事开头” |
| 多模态任务 | 15% | “生成描述这张图片的JSON,包含颜色和物体” |
| 其他 | 5% | 编程、伦理讨论等 |
(2) 约束类型分布
| 约束类型 | 比例 | VerIF验证方式 |
|---|---|---|
| 长度 | 15% | 代码验证 |
| 关键词 | 7.3% | 代码验证 |
| 风格 | 42% | QwQ-32B验证 |
| 内容逻辑 | 35.7% | QwQ-32B验证 |
5. 与其他数据集的对比优势
| 特性 | VerInstruct | IFEval | WildChat |
|---|---|---|---|
| 约束多样性 | 硬+软混合 | 仅硬约束 | 无明确约束 |
| 验证信号 | 代码+LLM | 无 | 无 |
| 数据规模 | 22k | 500 | 1M+ |
| 适用场景 | RL训练 | 评测基准 | 通用SFT |
6. 数据构建的挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 约束标注不一致 | 用Llama3.1-70B统一标准 + 人工校准 |
| 硬约束代码生成错误 | 自动测试脚本(覆盖率>99%) |
| 软约束主观性导致标注噪声 | QwQ-32B二次验证争议样本 |
| 多语言支持不足(当前仅英语) | 未来计划扩展mT5多语言反译 |
总结
VerInstruct 的数据源选择和处理流程体现了以下设计原则:
-
质量优先:基于GPT-4/专家生成数据,确保高信噪比。
-
自动化扩展:通过LLM反译约束,减少人工成本。
-
RL友好:显式分离硬/软约束,适配VerIF的混合验证需求。
此数据集为指令跟随领域的RL训练提供了标准化、可扩展的基准,填补了传统SFT数据与RL需求间的鸿沟。
为什么选择 QwQ-32B 作为软约束验证器?
VerIF 使用 QwQ-32B(一种专长推理的大模型)作为软约束验证的核心组件,主要基于以下 5 个关键原因:
1. 强大的推理能力(核心优势)
QwQ-32B 是专门针对 复杂逻辑推理 优化的模型,其优势包括:
-
链式推理(Chain-of-Thought, CoT):能逐步分析指令和响应的语义关系,适合判断软约束(如风格、逻辑一致性)。
-
高准确率:在 IFBench 测试中,QwQ-32B 的软约束验证准确率(48.1%)显著优于通用 LLM(如 Qwen2.5-72B 的 45.3%)。
对比实验(表1):
| 验证方法 | 硬约束准确率 | 软约束准确率 |
|---|---|---|
| Code-only | 60.6% | 13.2% |
| LLM-only (Qwen) | 19.7% | 45.3% |
| LLM-only (QwQ) | 31.5% | 48.1% |
| VerIF (QwQ+Code) | 61.3% | 48.1% |
👉 结论:QwQ-32B 在软约束任务上表现最佳,而硬约束仍由代码验证主导。
2. 避免通用LLM的固有缺陷
通用大模型(如 GPT-4、Qwen2.5)在验证任务中存在 3 大问题:
-
数值计算不可靠(如“不超过100词”可能误判)
-
格式敏感度低(如“用Markdown列表”可能被忽略)
-
过度依赖语义联想(可能误判风格或逻辑)
而 QwQ-32B 专为可验证性优化:
-
在训练中引入 结构化推理数据,减少幻觉(Hallucination)。
-
对 约束条件(如“必须避免主观表述”)的响应更严格。
3. 计算效率的平衡
虽然 QwQ-32B 比 7B/13B 模型计算成本更高,但 VerIF 通过 2 种优化 控制开销:
-
批量验证:一次性输入所有软约束,而非逐条判断。
-
小验证器蒸馏:用 QwQ-32B 生成 130k 标注数据,训练 IF-Verifier-7B,在几乎不损失性能的情况下降低 80% 计算成本。
训练速度对比:
| 验证器 | 单批次耗时 | GPU 需求 |
|---|---|---|
| QwQ-32B | ~180s | 8×H800 |
| IF-Verifier-7B | ~120s | 1×H800 |
4. 与硬约束验证的互补性
-
硬约束(代码验证)→ 高效但无法处理语义
-
软约束(QwQ-32B)→ 语义精准但计算成本高
VerIF 的混合设计实现了 速度+精度 的最优平衡:
-
代码处理 22.3% 的硬约束(长度/关键词/格式)
-
QwQ-32B 处理 77.7% 的软约束(风格/内容/逻辑)
5. 领域适应性
QwQ-32B 在 数学、代码、逻辑推理 等任务上表现优异,这与指令跟随中的约束类型高度契合。例如:
-
风格约束 → 依赖语言理解
-
逻辑约束 → 依赖推理能力
而通用模型(如 LLaMA3、GPT-4)可能在这些细分领域表现不稳定。
总结:为什么是 QwQ-32B?
| 关键因素 | QwQ-32B 的优势 |
|---|---|
| 推理能力 | 专长 CoT,软约束准确率 48.1%(最优) |
| 避免通用LLM缺陷 | 数值/格式判断更可靠 |
| 计算效率 | 支持批量验证 + 可蒸馏为小模型 |
| 与硬约束的互补性 | 覆盖代码无法处理的 77.7% 约束 |
| 领域适配性 | 在数学、逻辑等任务上表现稳定 |
最终选择:QwQ-32B 是 精度、效率、泛化性 权衡后的最佳选项,而蒸馏版 IF-Verifier-7B 进一步降低了落地成本。