RAG-Fusion 实战:检索召回率提升新方案
前言
在此之前,基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统,做检索召回率提升的探究,并未知道检索前处理所涉及的方法也是 RAG-Fusion 的实现。又是一次 “先实践,后知觉” 的体会。
什么是 RAG-Fusion
RAG-Fusion 是一种扩展了传统 RAG 技术的方法,旨在通过结合多查询检索和结果融合来提升生成模型的效果。它通过生成多个与原始问题语义相关的查询变体,也可以是同一问题的不同提问方式,还可以是基于原始查询进行扩展等,然后并行地从知识库中检索信息,并将这些检索到的结果进行融合与重排序,从而增强生成答案的准确性和丰富性。
RAG-Fusion 实现
方案一:基于 LangChain 工具类 MultiQueryRetriever
MultiQueryRetriever 介绍
LangChain 提供的工具类:MultiQueryRetriever。它的实现过程:通过提示词把输入问题,利用大语言模型(LLM)生成多个查询变体,然后根据传入的检索器,对查询变体逐个检索,并将检索结果合并去重后返回。
MultiQueryRetriever 源码默认的 prompt:
# Default prompt
DEFAULT_QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""You are an AI language model assistant. Your task is to generate 3 different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""",
)MultiQueryRetriever 源码的检索过程:
def _get_relevant_documents(self,query: str,*,run_manager: CallbackManagerForRetrieverRun,) -> List[Document]:"""Get relevant documents given a user query.Args:query: user queryReturns:Unique union of relevant documents from all generated queries"""queries = self.generate_queries(query, run_manager)if self.include_original:queries.append(query)documents = self.retrieve_documents(queries, run_manager)return self.unique_union(documents)def generate_queries(self, question: str, run_manager: CallbackManagerForRetrieverRun) -> List[str]:"""Generate queries based upon user input.Args:question: user queryReturns:List of LLM generated queries that are similar to the user input"""response = self.llm_chain.invoke({"question": question}, config={"callbacks": run_manager.get_child()})if isinstance(self.llm_chain, LLMChain):lines = response["text"]else:lines = responseif self.verbose:logger.info(f"Generated queries: {lines}")return linesdef retrieve_documents(self, queries: List[str], run_manager: CallbackManagerForRetrieverRun) -> List[Document]:"""Run all LLM generated queries.Args:queries: query listReturns:List of retrieved Documents"""documents = []for query in queries:docs = self.retriever.invoke(query, config={"callbacks": run_manager.get_child()})documents.extend(docs)return documents源码方法实现说明:
- generate_queries 方法,实现查询变体生成;
- retrieve_documents 方法,是文档检索的实现,从代码中也可以看到了,是遍历查询变体来逐一检索,并将检索结果汇总返回;
- _get_relevant_documents 方法,是整个过程:生成查询变体,执行检索,检索结果去重。
方案探究实现简述
(1)检索实现流程图如下:
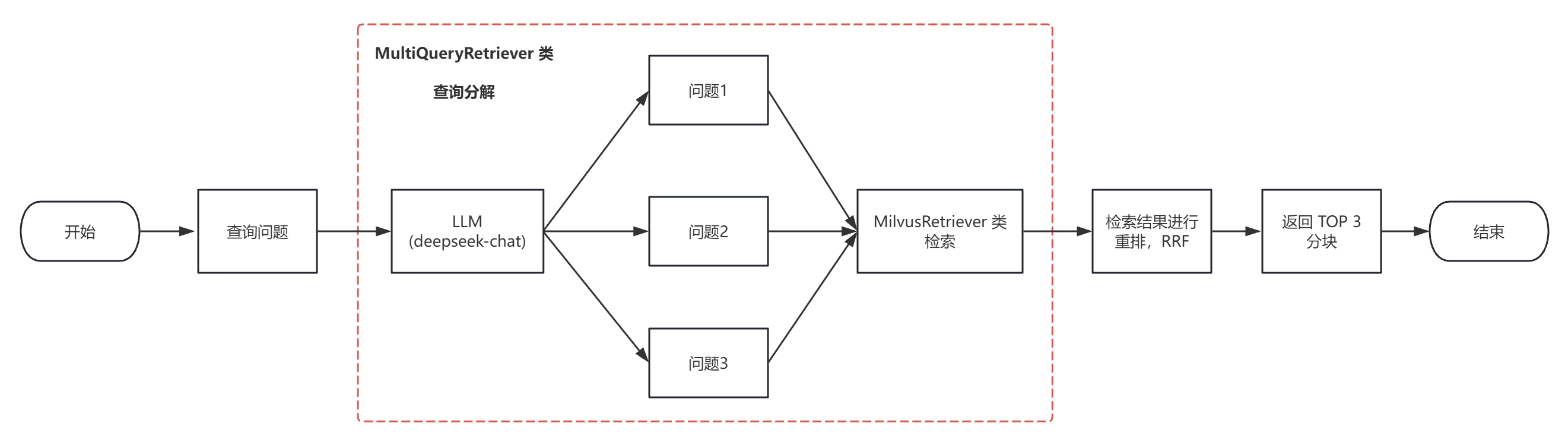
(2)该方案实现,结合了 RRF 重排
RRF 会合并来自多个不同检索器的结果列表,为每个结果分配一个融合得分。如果某个文本块在多个结果列表中均排名靠前,那么它的 RRF 总分会更高。这种方法体现了集成学习的思想。
RRF 算法的关键重排序公式如下:
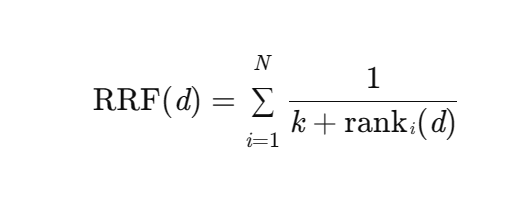
公式说明:
- d:代表某个特定文本块
- RRF(d):是文本块d的融合得分;
- N:是输入的多个检索结果列表的数量;
- k:是平滑参数,用于控制排名对得分的影响,通常取值为一个常熟(如60)
- rank i (d):是文本块d 在第 i 个排序器中的排名(从1 开始计数)。
(3)方案具体实现及评估,请查看:
检索召回率优化探究二:基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的智能问答系统-CSDN博客
方案二:基于 LangChain 工具类 RePhraseQueryRetriever
RePhraseQueryRetriever 介绍
RePhraseQueryRetriever 实现文本检索的源码如下:
def _get_relevant_documents(self,query: str,*,run_manager: CallbackManagerForRetrieverRun,) -> List[Document]:"""Get relevant documents given a user question.Args:query: user questionReturns:Relevant documents for re-phrased question"""re_phrased_question = self.llm_chain.invoke(query, {"callbacks": run_manager.get_child()})logger.info(f"Re-phrased question: {re_phrased_question}")docs = self.retriever.invoke(re_phrased_question, config={"callbacks": run_manager.get_child()})return docs源码默认提示词:
# Default template
DEFAULT_TEMPLATE = """You are an assistant tasked with taking a natural language \
query from a user and converting it into a query for a vectorstore. \
In this process, you strip out information that is not relevant for \
the retrieval task. Here is the user query: {question}"""从中可知,它的实现流程是:依据提示词将原始查询进行重写,之后就调用检索器执行检索,最后将检索结果返回。
方案探究实现简述
(1)方案实现流程图如下:
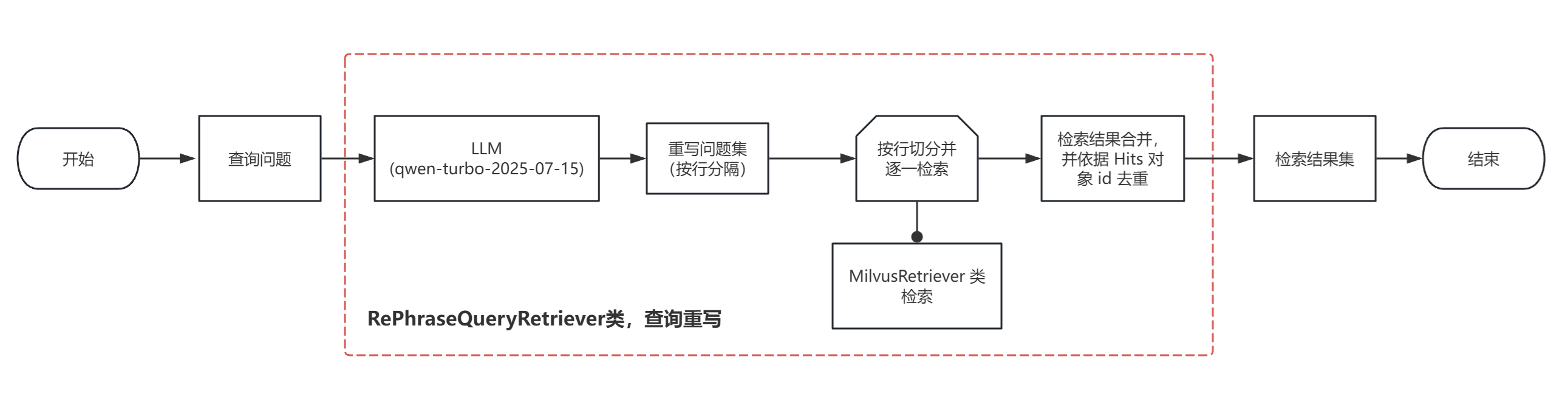
从上图可知,在使用 RePhraseQueryRetriever 上进行了巧用或者说是创新吧。
- 自定义提示词,实现原始查询的重写,要求重写为 3个不同问法;
- 检索器适配性处理,将重写结果切分并逐一检索;
- 自定义去重方法,依据检索结果返回的 Hits 对象的 id进行去重。
(2)方案具体实现及评估,请查看:
检索召回率优化探究三:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统-CSDN博客
方案三:借鉴 HyDE 思想
HyDE 介绍
HyDE,全称为:Hypothetical Docunment Embeddings,翻译为:假设性文档嵌入。它的思想是源于论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》。
论文探讨解决的问题是:零样本密集检索中的学习问题。传统的密集检索方法需要大量的标记数据来进行训练,而HyDE 则不需要任何标记数据或相关性判断,仅需要使用一些简单的文本示例即可完成学习任务。
方案探究实现简述
(1)方案实现流程图如下:
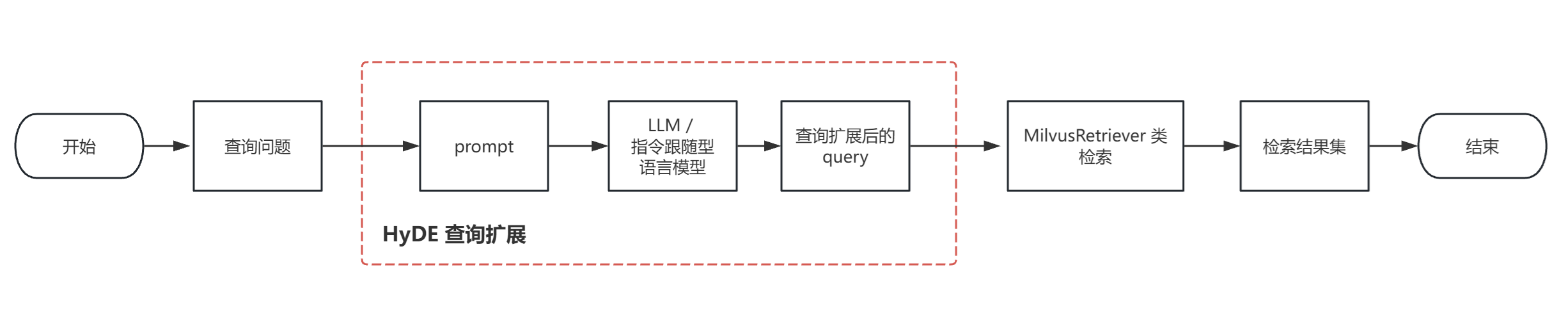
这个流程图,和工具类 RePhraseQueryRetriever 的实现过程基本一样的,唯一不同的就是 prompt 的定义和所使用的 LLM。
也就是因为这两者的不同,它们最终的检索召回率是有差别的,HyDE 这种方式检索召回率要高出一些。这样也是可以理解的,HyDE 对原始查询进行了扩展,会使得语义更丰富、清晰,从而就能更准确地检索到相关的文档片段。
(2)方案具体实现及评估,请查看:
检索召回率优化探究四:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统_langchain 与 fastgpt 召回率-CSDN博客
不同实现方式的评估结果
| 指标 | 实现方案 | 传统 RAG | RAG-Fusion | 召回率提升幅度 |
| 召回@2 | 方案一 | 79.52% | 74.70% | -6.06% |
| 召回@3 | 方案一 | 79.52% | 83.13% | 4.54% |
| 召回@2 | 方案二 | 79.52% | 82.05% | 3.18% |
| 召回@3 | 方案二 | 79.52% | 87.50% | 10.04% |
| 召回@3 | 方案三 | 79.52% | 87.65% | 10.22% |
上述表格说明:
- @2,@3:是指检索最终返回的最相似向量个数;
- 实现方案一、二、三:就是上述 RAG-Fusion 实现章节的方案一、二、三。
RAG-Fusion 总结
使用 RAG-Fusion 的好处
- 提高召回率:通过生成多个语义相关的查询变体,可以覆盖用户意图的更多方面,从而增加找到相关文档片段的概率。
- 增强鲁棒性:多个查询减少了对原始查询表述的依赖,有助于避免由于查询表述偏差导致的检索失败,尤其是在用户输入模糊或不准确的情况下。
- 适应复杂查询:对于复杂或多方面的查询来说,RAG-Fusion 可以将其分解成若干子问题,并分别进行处理,最后将结果整合起来,提供一个全面的回答。
使用 RAG-Fusion 带来的问题
- 计算成本较高:由于需要生成多个查询并执行多次检索,RAG-Fusion 相比传统方法会消耗更多的计算资源和时间。
- 系统复杂度增加:实现 RAG-Fusion 需要集成多个组件(如查询生成模块、向量数据库、大型语言模型),增加了系统的复杂度和维护成本。
- 响应延迟问题:额外的检索步骤可能导致响应时间延长,对于实时性要求高的应用场景来说可能是一个挑战。
- 结果稀释风险:如果不恰当地生成过多查询,可能会导致原本明确的用户意图被稀释,反而影响到最终答案的相关性。
最后汇总一下文章引用:
检索召回率优化探究二:基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的智能问答系统-CSDN博客
检索召回率优化探究三:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统-CSDN博客
检索召回率优化探究四:基于LangChain0.3集成Milvu2.5向量数据库构建的智能问答系统_langchain 与 fastgpt 召回率-CSDN博客