python基于Hadoop的超市数据分析系统
前端开发框架:vue.js
数据库 mysql 版本不限
后端语言框架支持:
1 java(SSM/springboot)-idea/eclipse
2.Nodejs+Vue.js -vscode
3.python(flask/django)–pycharm/vscode
4.php(thinkphp/laravel)-hbuilderx
数据库工具:Navicat/SQLyog等都可以
摘要:
随着大数据时代的到来,超市作为零售行业的重要组成部分,面临着海量数据的处理和分析挑战。为了更有效地利用这些数据,提升超市的运营效率和顾客满意度,本文设计并实现了一个基于Hadoop的超市数据分析系统。该系统能够整合超市各类数据资源,运用Hadoop分布式计算框架进行高效的数据存储和处理,并通过数据分析为超市管理者提供决策支持。本文详细阐述了系统的需求分析、设计思路、实现方法以及测试结果,证明了系统的可行性和有效性。
关键词:Hadoop;超市数据分析;大数据处理;决策支持
一、绪论
1.1 研究背景与意义
随着信息技术的快速发展,超市在日常运营中积累了大量的数据,包括销售数据、顾客数据、商品数据等。这些数据蕴含着丰富的信息,对于超市管理者来说具有重要的价值。然而,传统的数据处理方式往往难以应对如此庞大的数据量,导致数据资源的浪费。因此,如何高效地处理和分析这些数据,挖掘其中的潜在价值,成为超市行业亟待解决的问题。
Hadoop作为一种开源的分布式计算框架,具有高效、可扩展、容错性强等特点,能够很好地解决大数据处理中的存储和计算问题。将Hadoop应用于超市数据分析系统,可以实现对海量数据的高效处理和分析,为超市管理者提供准确、及时的数据支持,有助于提升超市的运营效率和竞争力。
4.2 模块设计
本系统主要包括以下几个模块:
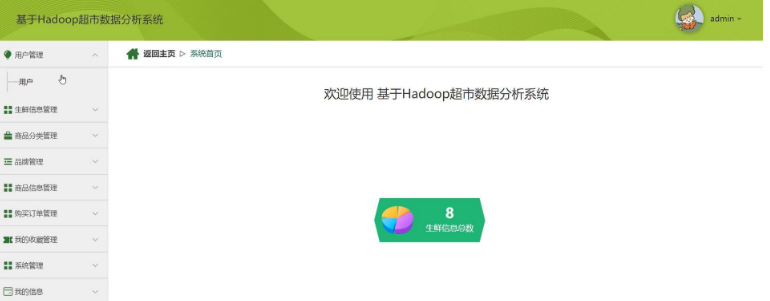
用户管理模块:负责系统用户的注册、登录、权限管理等功能。
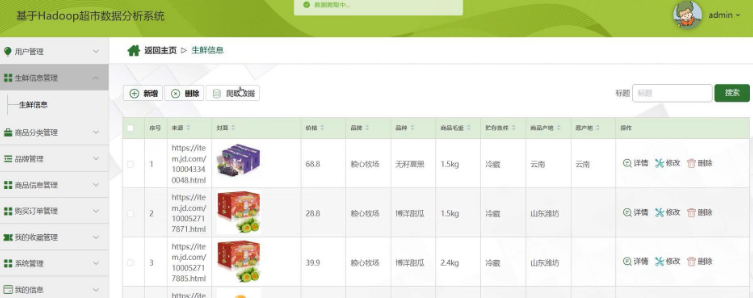
生鲜信息管理模块:对超市的生鲜商品信息进行管理,包括商品分类、品牌管理、商品信息管理等功能。该模块允许用户新增、删除、修改和查询生鲜商品信息,如商品名称、来源、价格、品牌、毛重、存储条件、产地等。
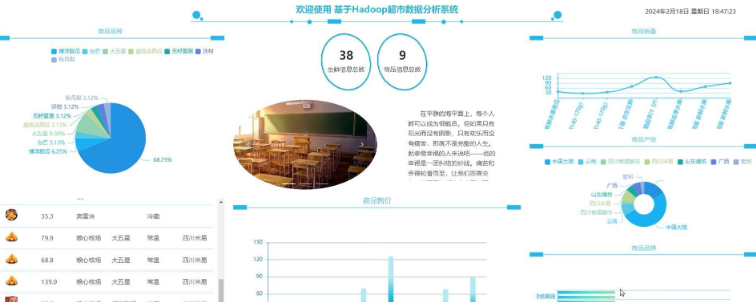
销售数据分析模块:对超市的销售数据进行处理和分析,包括销售额分析、销售量分析、顾客购买行为分析等功能。
库存管理模块:对超市的库存数据进行实时监控和分析,提供库存预警、库存优化建议等功能。
报表生成模块:根据用户的需求生成各类报表,如销售报表、库存报表、顾客报表等。
4.3 数据库设计
本系统的数据库设计主要包括HDFS上的文件存储结构和Hive数据仓库的表结构设计。HDFS上的文件存储结构根据数据的类型和来源进行划分,方便数据的存储和管理。Hive数据仓库的表结构根据业务需求进行设计,包括商品信息表、销售数据表、库存数据表等。
五、系统实现与测试
5.1 系统实现
本系统采用python语言进行开发,使用Hadoop、Hive、HBase等技术实现系统的各个功能模块。在开发过程中,遵循软件工程的原则和方法,进行需求分析、设计、编码、测试等各个阶段的工作。
5.2 系统测试
系统测试是验证系统功能和性能的重要环节。本系统进行了功能测试、性能测试、安全测试等多个方面的测试。测试结果表明,系统能够正常运行,满足用户的需求和性能指标。
语言:Python
框架:django/flask
软件版本:python3.7.7
数据库:mysql
数据库工具:Navicat
前端框架:vue.js
通过比较两个不同因素的框架,可以看出Flask和Django不能被标记为单一功能中的最佳框架。当Django在快速发展的大型项目中看起来更好并且提供更多功能时,Flask似乎更容易上手。这两个框架对于开发Web应用程序都非常有用,应根据当前的需求和项目的规模来选择它们。
最新python的web框架django/flask都可以开发.基于B/S模式,前端技术:nodejs+vue+Elementui+html+css
,前后端分离就是将一个单体应用拆分成两个独立的应用:前端应用和后端应用,以JSON格式进行数据交互.充分保证了系统代码的良好可读性、实用性、易扩展性、通用性、便于后期维护等特点
三、需求分析
3.1 功能需求
本系统的主要功能需求包括:
数据采集与整合:能够从超市的各个业务系统中采集数据,并进行清洗和整合,形成统一的数据仓库。
数据存储与管理:利用Hadoop的HDFS实现海量数据的高效存储,并提供数据备份和恢复功能。
数据处理与分析:运用MapReduce等编程模型对存储的数据进行处理和分析,挖掘数据中的潜在价值。
数据可视化:将分析结果以图表、报表等形式直观地展示出来,方便超市管理者查看和决策。
3.2 性能需求
系统需要满足以下性能需求:
高吞吐量:能够处理大量的数据输入和输出,保证数据处理的效率。
高可扩展性:随着数据量的增长,系统能够方便地进行扩展,增加计算和存储资源。
高容错性:在部分节点出现故障的情况下,系统能够继续正常运行,保证数据的完整性和可用性。
3.3 安全需求
系统需要保证数据的安全性,防止数据泄露和非法访问。具体措施包括:
用户认证与授权:对系统用户进行身份认证,并根据用户的角色和权限分配相应的操作权限。
数据加密:对敏感数据进行加密存储和传输,防止数据被窃取。
日志审计:记录系统的操作日志,方便对系统的使用情况进行监控和审计。