卷积神经网络(CNN):卷积和池化
DD卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域, 往往我们输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格状结构数据的深度学习模型。最初,CNN主要应用于计算机视觉任务,但它的成功启发了在其他领域应用,如自然语言处理等。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低运算量并特征增强;全连接层类似神经网络的部分,用来输出想要的结果。
一、卷积层
1、卷积核
卷积核是卷积运算过程中必不可少的一个“工具”,在卷积神经网络中,卷积核是非常重要的,它们被用来提取图像中的特征。
卷积核其实是一个小矩阵,在定义时需要考虑以下几方面的内容:
卷积核的个数:卷积核(过滤器)的个数决定了其输出特征矩阵的通道数。
卷积核的值:卷积核的值是初始化好的,后续进行更新。
卷积核的大小:常见的卷积核有1×1、3×3、5×5等,一般都是奇数 × 奇数
2、API使用
import torch
import torch.nn as nn
import osimage_path = os.path.relpath(os.path.join(os.path.dirname(__file__),'data','彩色.png'))#img_data (H,W,C)----->转变为(C,H,W)----->转变为(N,C,H,W)
img_data = plt.imread(image_path)
print(img_data.shape)#(501, 500, 4)# 利用transpose进行转置,unsqueeze(0)在0维度上加一个维度
img_data = torch.tensor(img_data.transpose(2,0,1)).unsqueeze(0)
print(img_data.shape)
#得到torch.Size([1, 4, 501, 500])#第一次卷积
conv1 = nn.Conv2d(in_channels=4,#输入通道数out_channels=16,#输出通道数,通过 16 个不同的卷积核提取 16 种特征kernel_size=3,#卷积核大小3X3stride=1,#步长
)
# conv1 ----->(1,16,499,498),因为没有边缘填充,会-2#第二次卷积
conv2 = nn.Conv2d(in_channels=16,#上一次输出为16,所以这次输入为16out_channels=32,kernel_size=3,stride=1,
)
# conv2 ----->(1,32,497,496)#第三次卷积
conv3 = nn.Conv2d(in_channels=32,out_channels=2,kernel_size=3,stride=1,
)
# conv3 ----->(1,2,495,494)out = conv1(img_data)
out = conv2(out)
out = conv3(out)#squeeze(0) 表示移除张量中第 0 个维度(批量维度)上大小为 1 的维度。
#选取第 2 个通道(索引从 0 开始)的数据。最终得到的 out_ 形状为 (H, W),即单通道的特征图(高度 × 宽度)
out_ = out.squeeze(0)[1]
print(out_.shape)
#torch.Size([495, 494])plt.imshow(out_.clone().detach())
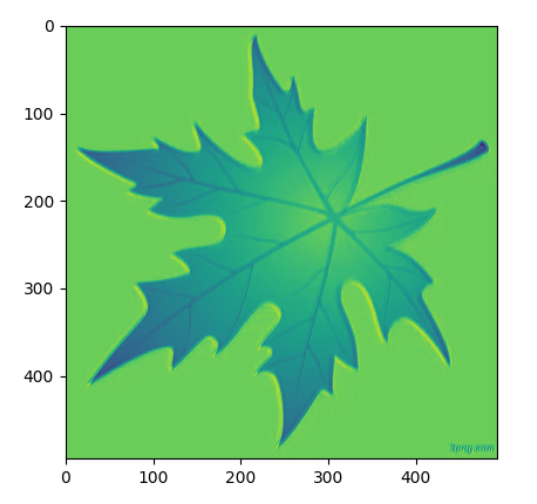
plt.show()原图: 三次卷积后的图:

二、池化层
1、概念
池化层 (Pooling) 降低空间维度, 缩减模型大小,提高计算速度. 即: 主要对卷积层学习到的特征图进行下采样(SubSampling)处理。
池化层主要有两种:
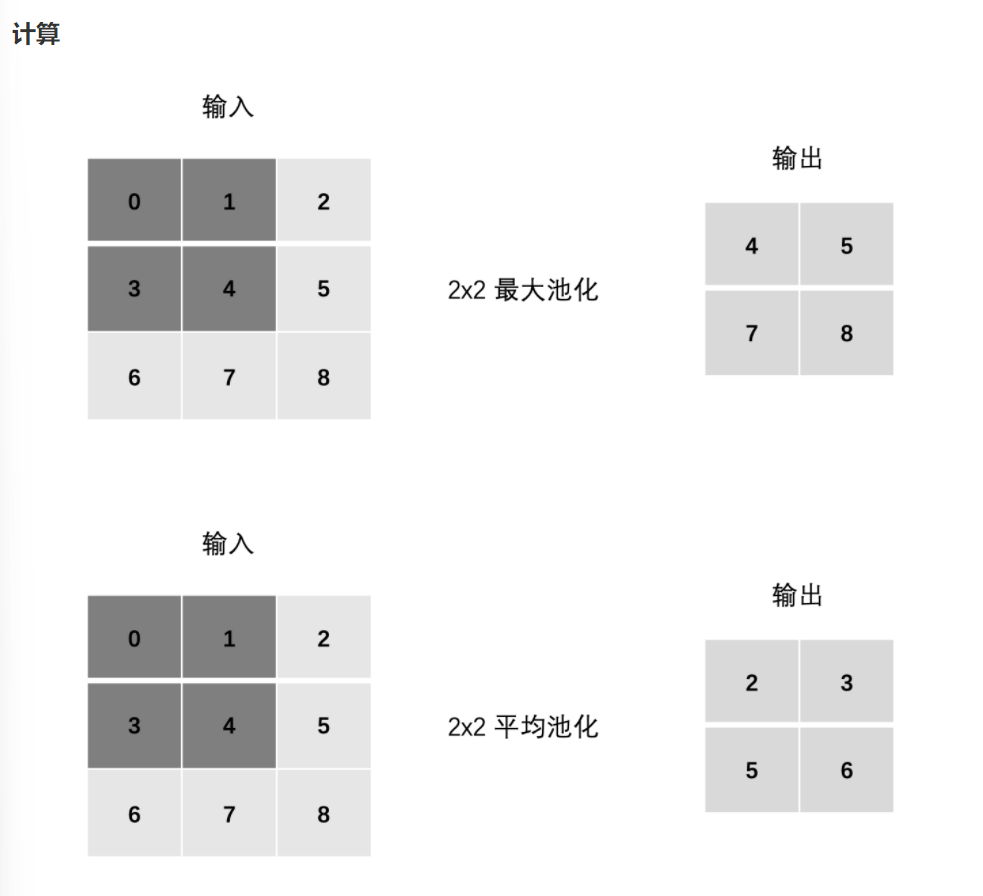
最大池化 max pooling
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
平均池化 avgPooling
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
2、API实现
(1)最大值法
import torch.nn as nn
import torch#1.最大值法
input_map = torch.randn(1,1,7,7)
print(input_map)
"""
四维7x7
tensor([[[[ 0.2770, 0.3865, 0.4463, -0.5237, -0.5254, 1.0389, -0.9945],[-0.0722, 0.1841, 0.9741, 1.1173, 0.2199, -0.5855, 0.4694],[ 0.5589, 0.7294, -0.5574, -1.3827, 0.2244, 0.7090, 1.4051],[-0.2596, 0.3351, 0.6823, 0.4193, 0.7946, -0.9845, 0.4121],[ 0.5969, -0.5453, -1.0438, 0.3483, -3.0112, -0.0483, -0.7215],[-0.9518, -1.4773, 0.4378, -0.3151, -0.0815, -0.0867, 2.3152],[-1.2408, 1.0863, 0.2001, 0.6345, 1.2319, 0.4448, 0.5237]]]])
"""
#最大值池化,选取2X2中最大的一个
pool1 = nn.MaxPool2d(kernel_size=2,stride=1,return_indices=True#是否返回最大值下标
)
out, indices = pool1(input_map)
print(out)
"""
四维6X6
tensor([[[[ 0.3865, 0.9741, 1.1173, 1.1173, 1.0389, 1.0389],[ 0.7294, 0.9741, 1.1173, 1.1173, 0.7090, 1.4051],[ 0.7294, 0.7294, 0.6823, 0.7946, 0.7946, 1.4051],[ 0.5969, 0.6823, 0.6823, 0.7946, 0.7946, 0.4121],[ 0.5969, 0.4378, 0.4378, 0.3483, -0.0483, 2.3152],[ 1.0863, 1.0863, 0.6345, 1.2319, 1.2319, 2.3152]]]])
"""
print(indices)
"""
最大值的下表
tensor([[[[ 1, 9, 10, 10, 5, 5],[15, 9, 10, 10, 19, 20],[15, 15, 23, 25, 25, 20],[28, 23, 23, 25, 25, 27],[28, 37, 37, 31, 33, 41],[43, 43, 45, 46, 46, 41]]]])
"""(2)、平均值法
import torch.nn as nn
import torchinput_map = torch.randn(1, 1, 7, 7)
pool1 = nn.AvgPool2d(kernel_size=2,stride=1)
out = pool1(input_map)
print(out.shape)
#torch.Size([1, 1, 6, 6])(3)、自适应最大值法
import torch.nn as nn
import torchinput_map = torch.randn(1, 1, 7, 7)
pool1 = nn.AdaptiveMaxPool2d(output_size=5#只用填输出的size
)
out = pool1(input_map)
print(out.shape)(4)、自适应平均值法
import torch.nn as nn
import torchinput_map = torch.randn(1, 1, 7, 7)
pool1 = nn.AdaptiveAvgPool2d(output_size=5
)
out = pool1(input_map)
print(out.shape)三、卷积和池化的应用(自定义网络)
import torch
import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel,self).__init__()self.c1 = nn.Sequential(#第一次卷积nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,),#损失函数,多分类多用Relu()nn.ReLU(),)#第一次池化self.pool2 = nn.AdaptiveMaxPool2d(output_size=22)#第二次卷积nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,stride=1,),#损失函数,多分类多用Relu()nn.ReLU(),)#第二次池化self.pool4 = nn.AdaptiveMaxPool2d(output_size=16)#定义全连接层self.l5 = nn.Linear(in_features=16*16*32#输入特征的维度out_features=10#输出10个特征)#前向传播def forward(self, x):# x(1,16,26,26)x = self.c1(x)# x(1,16,22,22)x = self.pool2(x)# x(1,32,20,20)x = self.c3(x)# x(1,32,16,16)x = self.pool4(x)# self.l5(x.view(-1, x.size(1)*x.size(2)*x.size(3)))#-1自动计算批量大小out = self.l5(x.view(x.size(0), -1))return outif __name__ == '__main__':input_data = torch.randn(1, 1, 28, 28)model = MyModel()out = model(input_data)print(out.shape)#torch.Size([1, 10])