【cs336学习笔记】[第5课]详解GPU架构,性能优化
文章目录
- 计算效率
- Dennard scaing
- 并行扩展
- GPU
- CPU和GPU的区别
- 从计算角度理解GPU
- 从内存角度理解GPU
- GPU的逻辑执行模型
- GPU的逻辑内存模型
- TPU
- GPU模型的优势
- 如何让 GPU 运行得更快?
- 和内存无关
- 控制发散(并非内存瓶颈)Control divergence (not a memory bottleneck..)
- 和内存相关
- 1. 低精度计算 Low precision computation
- 2. 算子融合 Operator fusion
- 3. 重新计算 Recomputation
- 4. 内存合并 Coalescing memory
- 5. 分块 Tiling
- 难点一:分块大小的确定
- 难点二:分块和 burst sections 之间的交互
- 屋顶图谜团
- 第一部分:tiling
- 第二部分:wave quantization
- 总结
- flash attention
- 矩阵乘法优化
- softmax优化
- 原始 softmax
- safe softmax
- online softmax
- 前向传播过程
学习目标:
1.理解GPU是如何工作的
2.可以自己实现、加速算法的某些部分
资源推荐:
Horace He’s blog
gpu-mode
How to Scale Your Model
今天的内容只关注硬件堆栈中非并行的部分。
计算效率
Dennard scaing
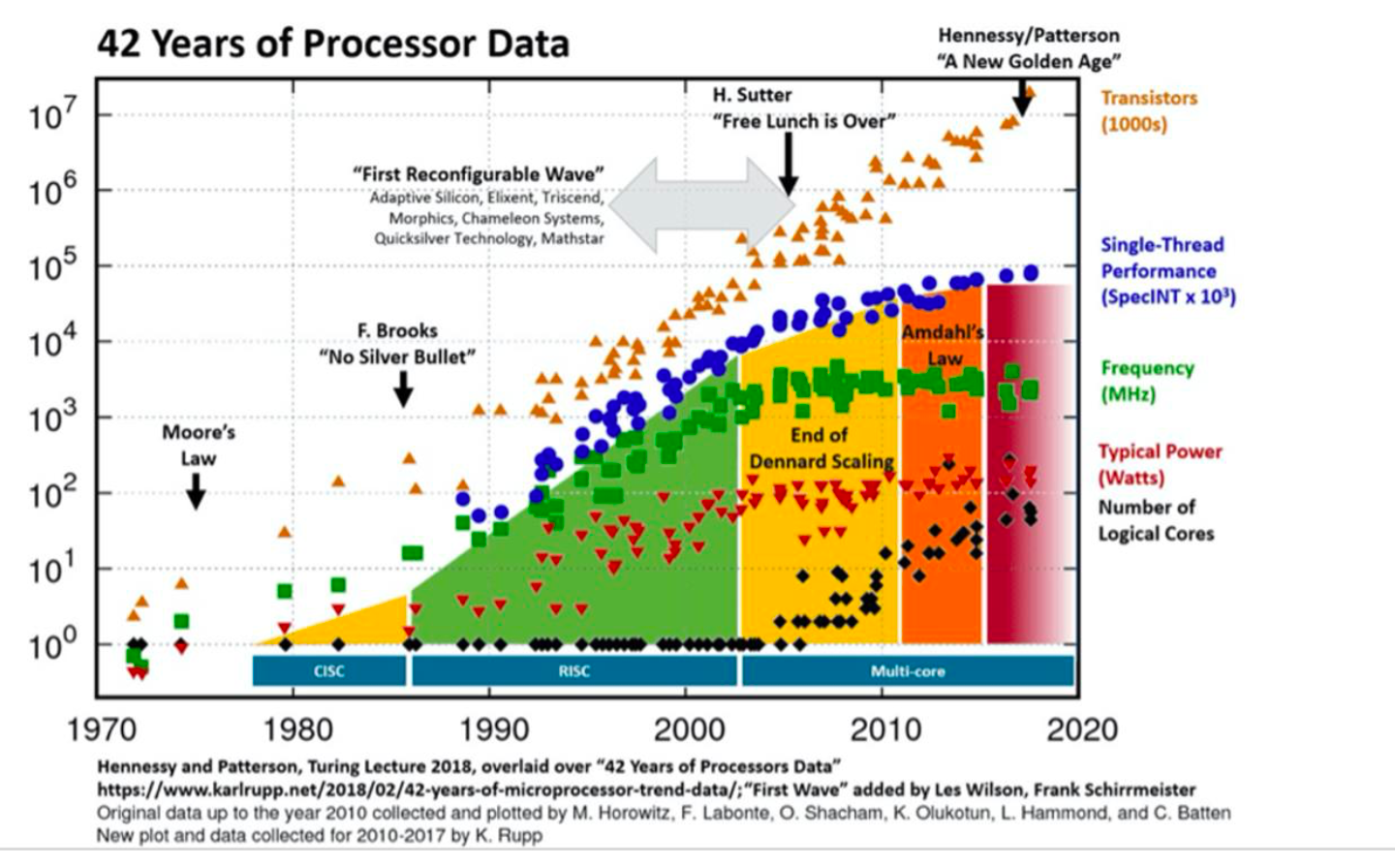
在半导体技术的早期,cpu的计算效率遵循 Dennard scaing(丹德纳缩放定律)。
根据摩尔定律,每年可以将芯片上的晶体管数量翻一番,越来越小的晶体管可以在越来越高的时钟频率下运行,功耗也越来越低,反过来又带来了更高的性能。
但是,21 世纪初,登纳德缩放定律逐渐失效,主要原因包括:
- 物理极限限制:当晶体管尺寸缩小到纳米级(如 20nm 以下),量子隧穿效应加剧(电子不受控制地穿过绝缘层),导致漏电功耗急剧增加,无法再通过降低电压维持电流密度稳定。
- 电压下限瓶颈:电压无法无限降低(受限于阈值电压等物理参数),否则晶体管无法正常开关,导致延迟无法继续按比例降低。
- 散热与功耗失控:单位面积功耗不再保持稳定,而是随晶体管数量增加而上升,导致芯片发热严重(如 “热墙” 问题),频率提升被迫停滞(例如 CPU 从 3-4GHz 后难以突破)。
晶体管的数量并没有减少,但是并没有带来单线程处理能力的提升(更高的吞吐量),导致无法实现计算速度的提升。
并行扩展
通过并行扩展,可以看到,每秒整数运算次数呈超指数级增长。
GPU
CPU和GPU的区别
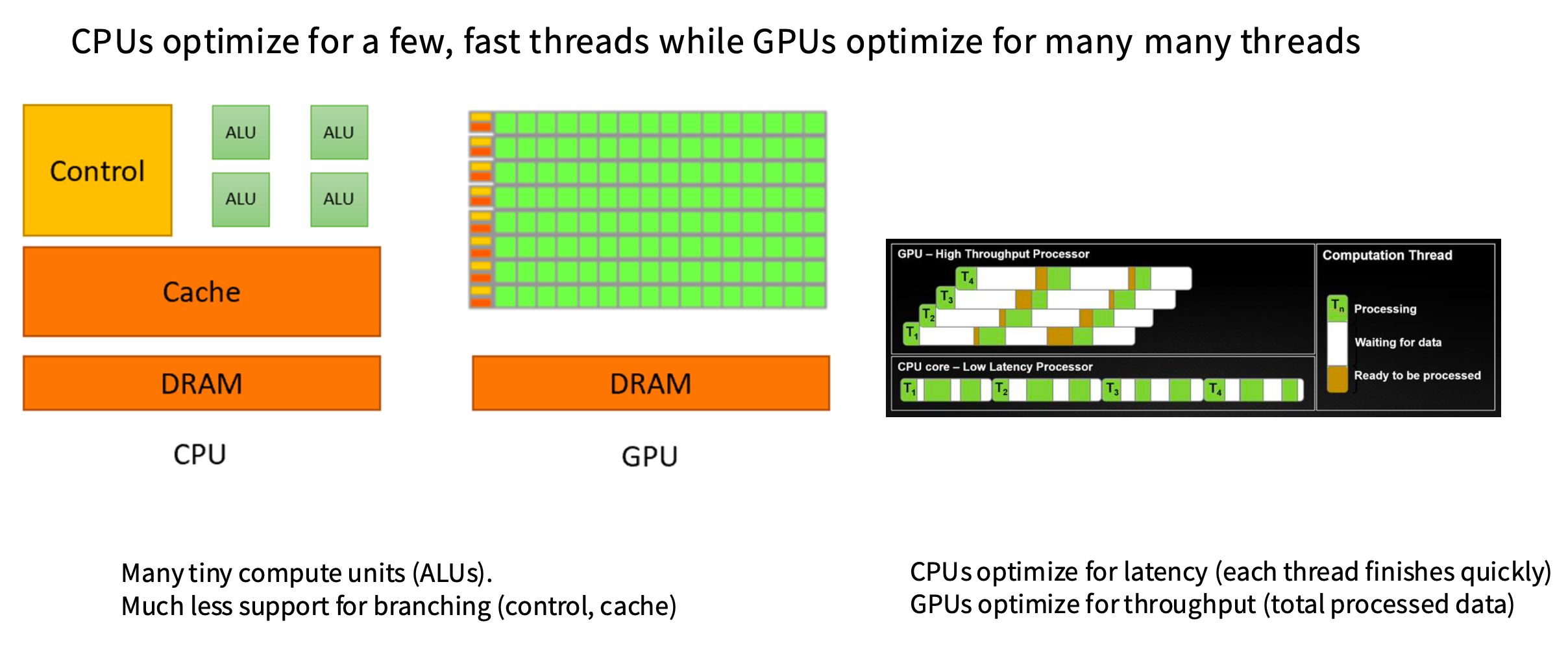
如果你有一个程序,cpu会以单线程的方式一步一步地执行指令。所以,CPU中有大量的控制单元、很多分支和条件控制逻辑(图中的Control、ALU),会有很大一部分芯片面积专门用于控制和分支预测。因为没有很多线程,多以运行非常快。
而GPU有海量的运算单元(图中绿色的小方块),芯片中用于控制的部分要少得多,只有少量的控制逻辑负责协调。
CPU的设计目标:针对低延迟进行优化,也就是尽快完成单个任务。例如有T1~T4四个任务,CPU的主要目标是尽快完成每个任务。
GPU的设计目标:高吞吐量,并不关心单个任务的延迟,只希望总共有多少任务,能尽快全部完成。这些线程可以快速的休眠和唤醒。可以在右图中看到,虽然完成单个任务的延迟更高,但是完成四个任务的总时间会比CPU短。
从计算角度理解GPU
GPU的内部有很多SM(streaming multiprocessors,流式多处理器),编程时,可以把一个SM看成一个原子单元。例如Triton会以SM为单位操作。
每个SM中又有很多SP(SPs,streaming processors,流式处理器),一个SP会并行执行大量的线程。
可以理解为,SM有很多控制逻辑,可以决定执行什么,例如分支操作。SP会接收相同的指令,将其应用于许多不同的数据。所以,在这种模式下,可以进行大量的并行计算,SM就是控制的最小单元。
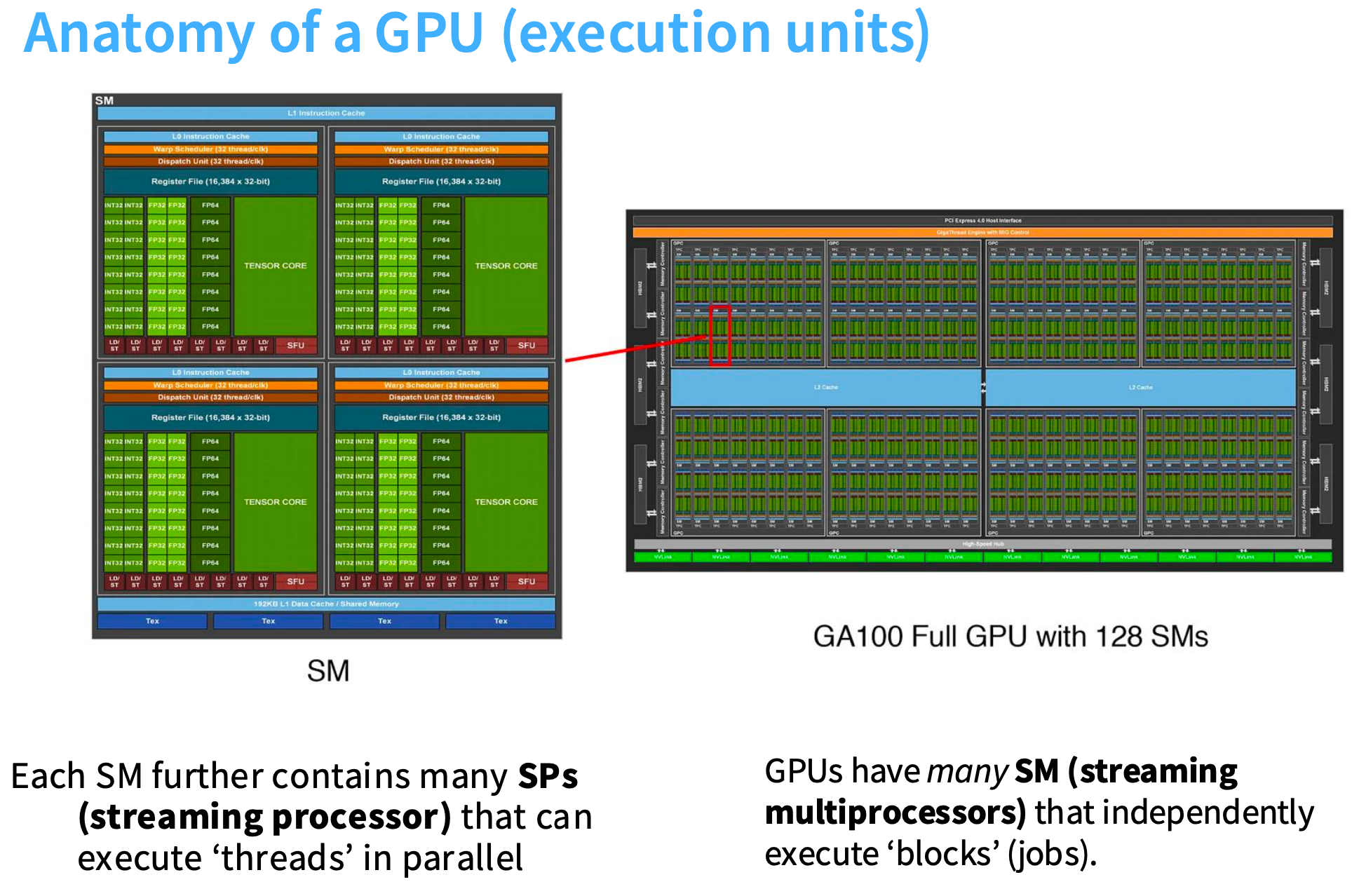
从内存角度理解GPU
一块内存离每个SM越近,它的速度就会越快。L1和共享内存位于SM内,L2 缓存位于芯片上,全局内存是 GPU 旁边的内存芯片。
右图绿色的区域是SMs,蓝色的区域是L2,挨着SMs。左边的Table中可以看到L2的速度比L1慢了6倍(L2-200,L1-33)

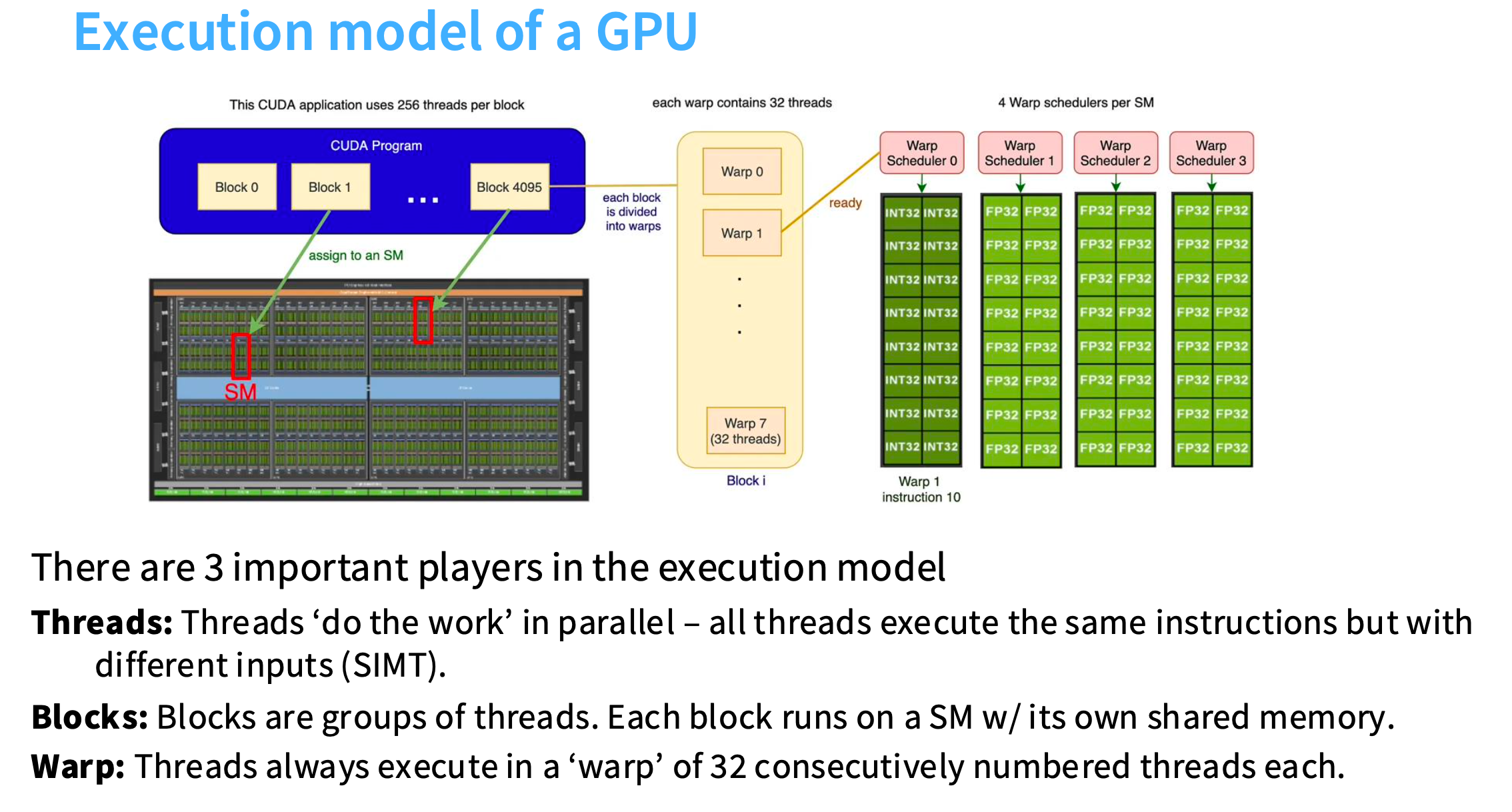
GPU的逻辑执行模型
执行模型中有 3 个重要的参与者:
Blocks(块):块是线程组。每个块在拥有自己共享内存的 SM 上运行。
Warps:线程始终在由 32 个连续编号的线程组成的“Warp”中执行。
Threads(线程):线程并行执行工作——所有线程执行相同的指令,但输入不同(SIMT)。
下图的含义:有一堆blocks,每个block被分配给一个不同的SM,在每个block内部有许多不同的warps,每个warp中又有32个threads,所有的threads将在不同的数据上执行相同的指令。
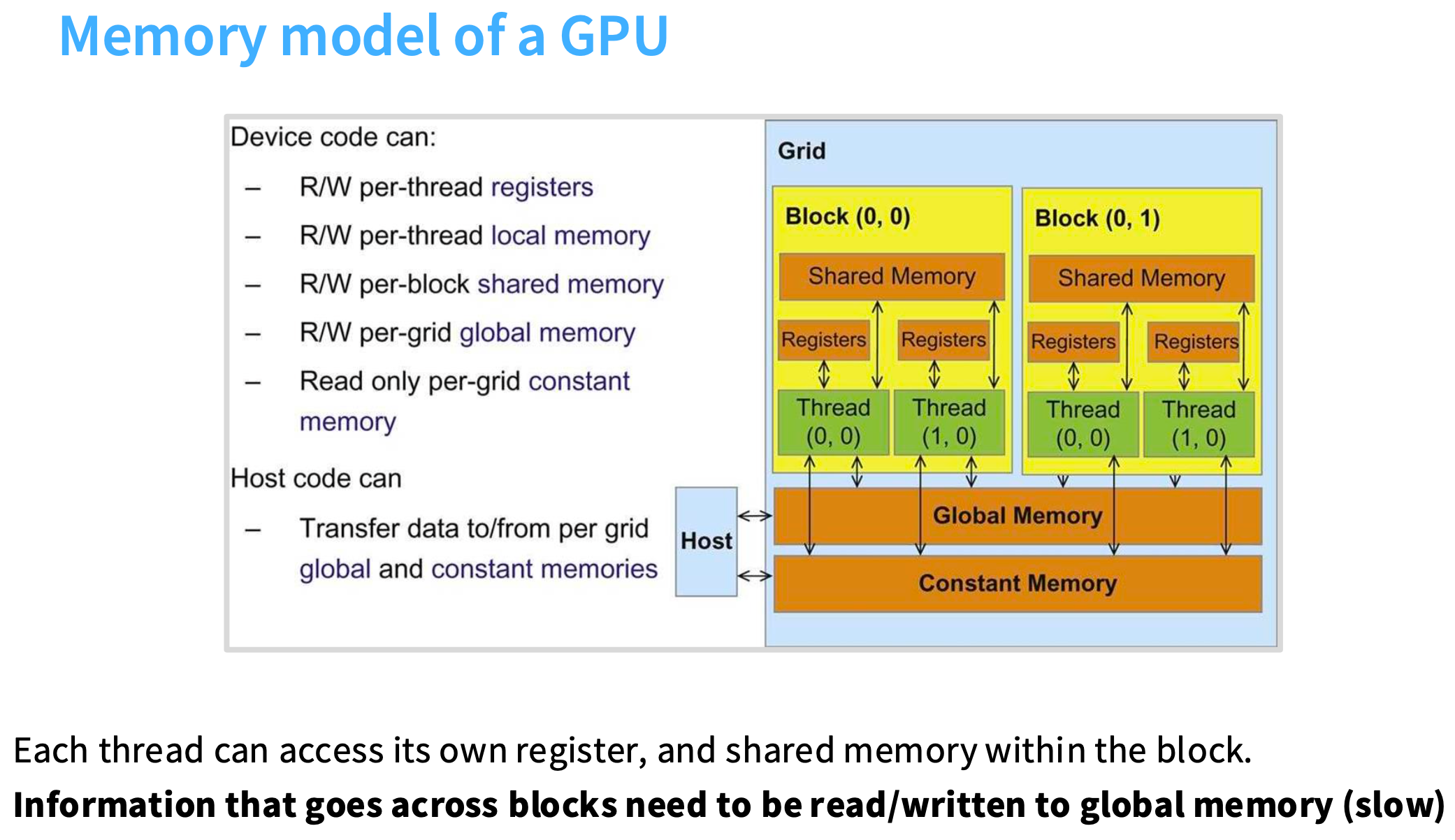
GPU的逻辑内存模型
寄存器(registers):非常快速的存储单元,用于存储单个数值。
有本地内存(local memory)、共享内存(shared memory)和全局内存(global memory)。
在内存层次结构中,层级越高、速度越慢。
每个线程都可以访问自己的寄存器和共享内存,但跨块的信息要写入全局内存。
这意味着,如果你编写一个执行任务的线程,理想情况下操作的是同一小块数据,所以你会将那小块数据载入共享内存,所有的线程都可以非常方便地访问。
但是如果一个线程需要访问分散在各处的数据,就不得不访问全局内存,会导致速度很慢。
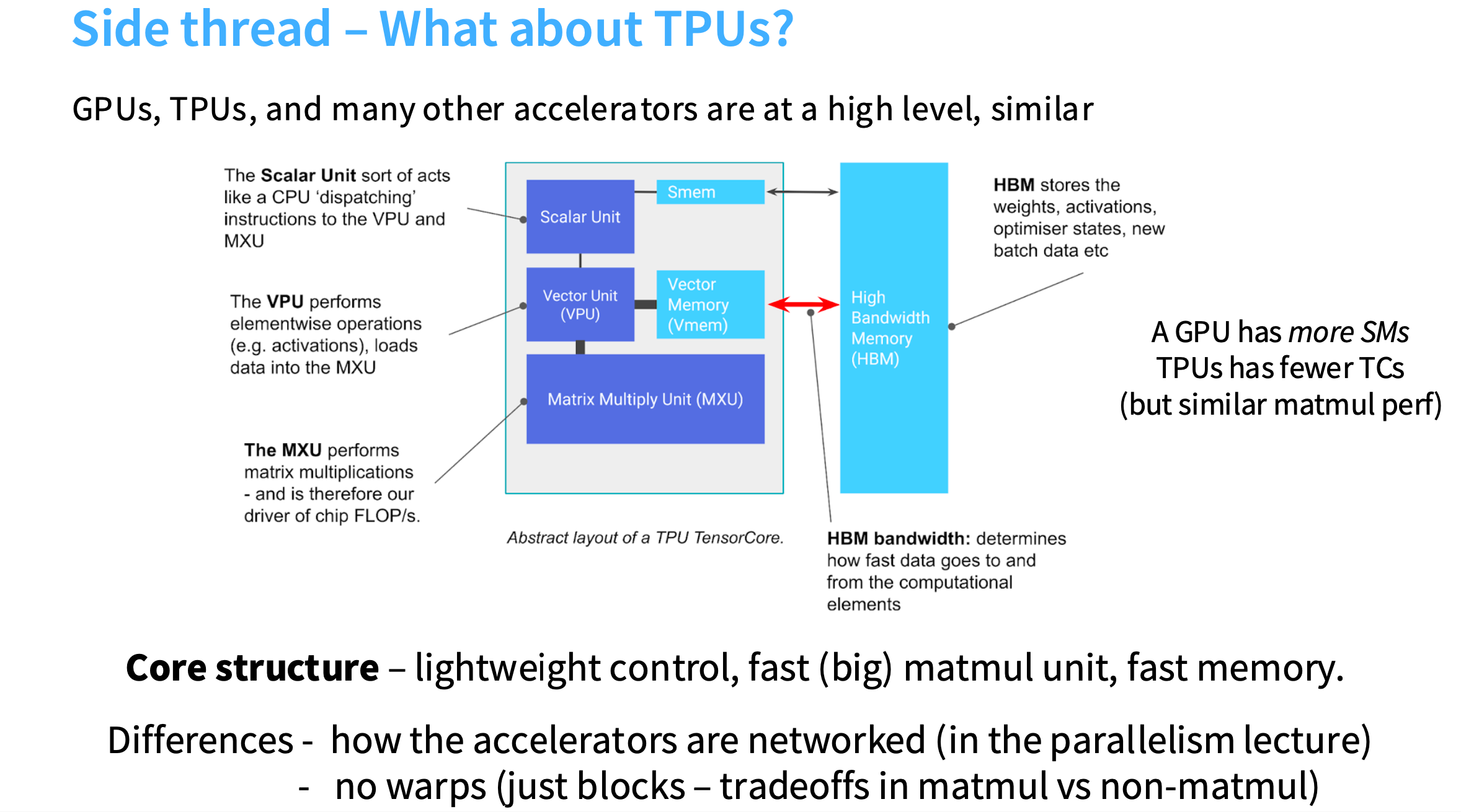
TPU
TPU的架构图,
- 有一个称为张量核心(tensor core)的组件,可以类比为GPU的SM,是独立运作的处理单元。
- 有一个标量单元(scalar unit),本质上是一个控制单元,可以执行类似CPU的任意操作。
- 有一个向量单元(vector unit),可以对向量进行操作。
- 有一块很大的芯片区域,专门用来做矩阵乘法,称为MXU,有非常快的内存。
- 有位于芯片外部的高带宽内存,HBM
外面是慢速内存,里面是快速内存,还有专门的硬件来做矩阵乘法。
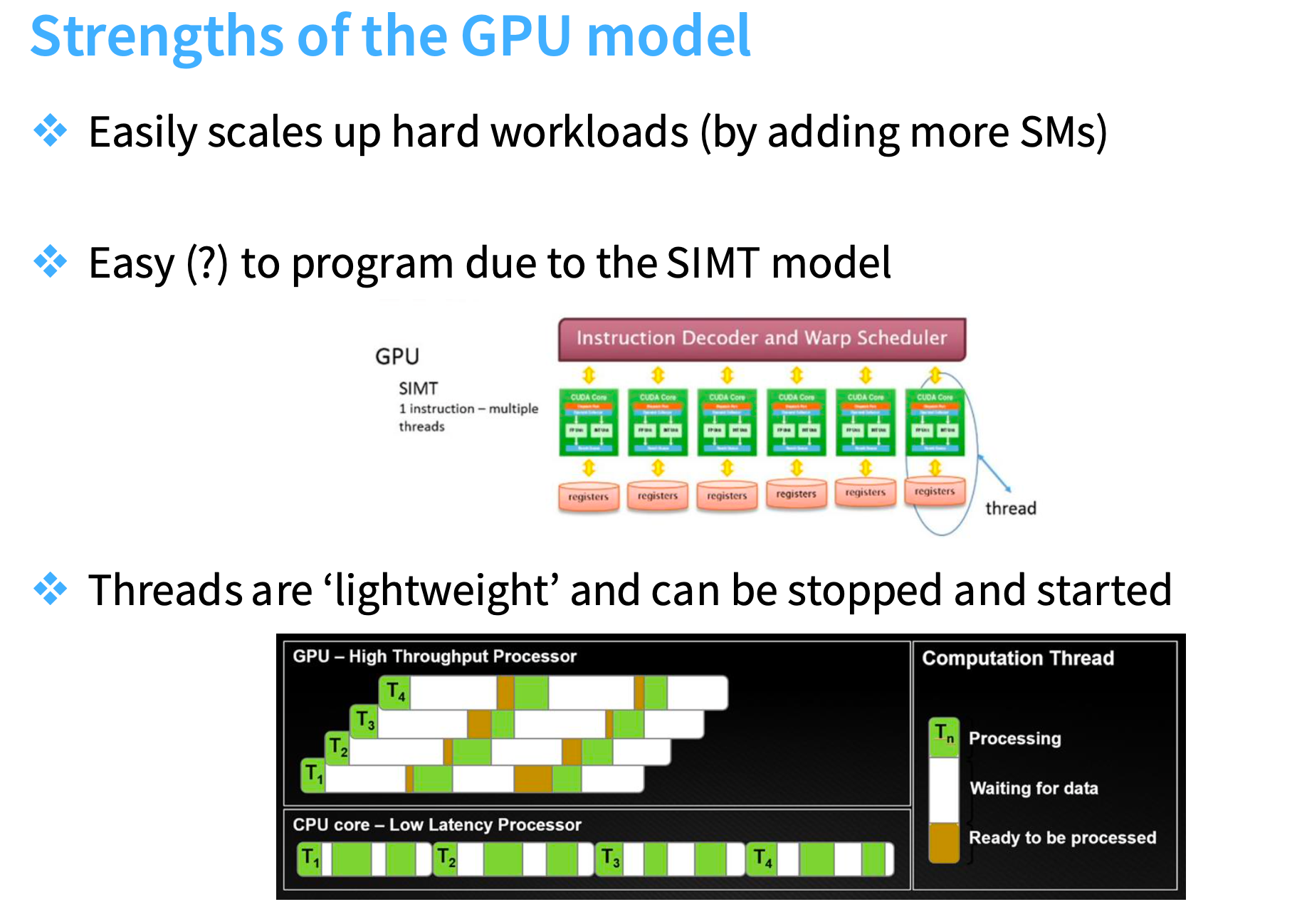
GPU模型的优势
- 轻松扩展硬工作负载(通过添加更多 SM)
- 采用 SIMT 模型,编程简单(?)
- 线程“轻量级”,可停止和启动
如何让 GPU 运行得更快?
和内存无关
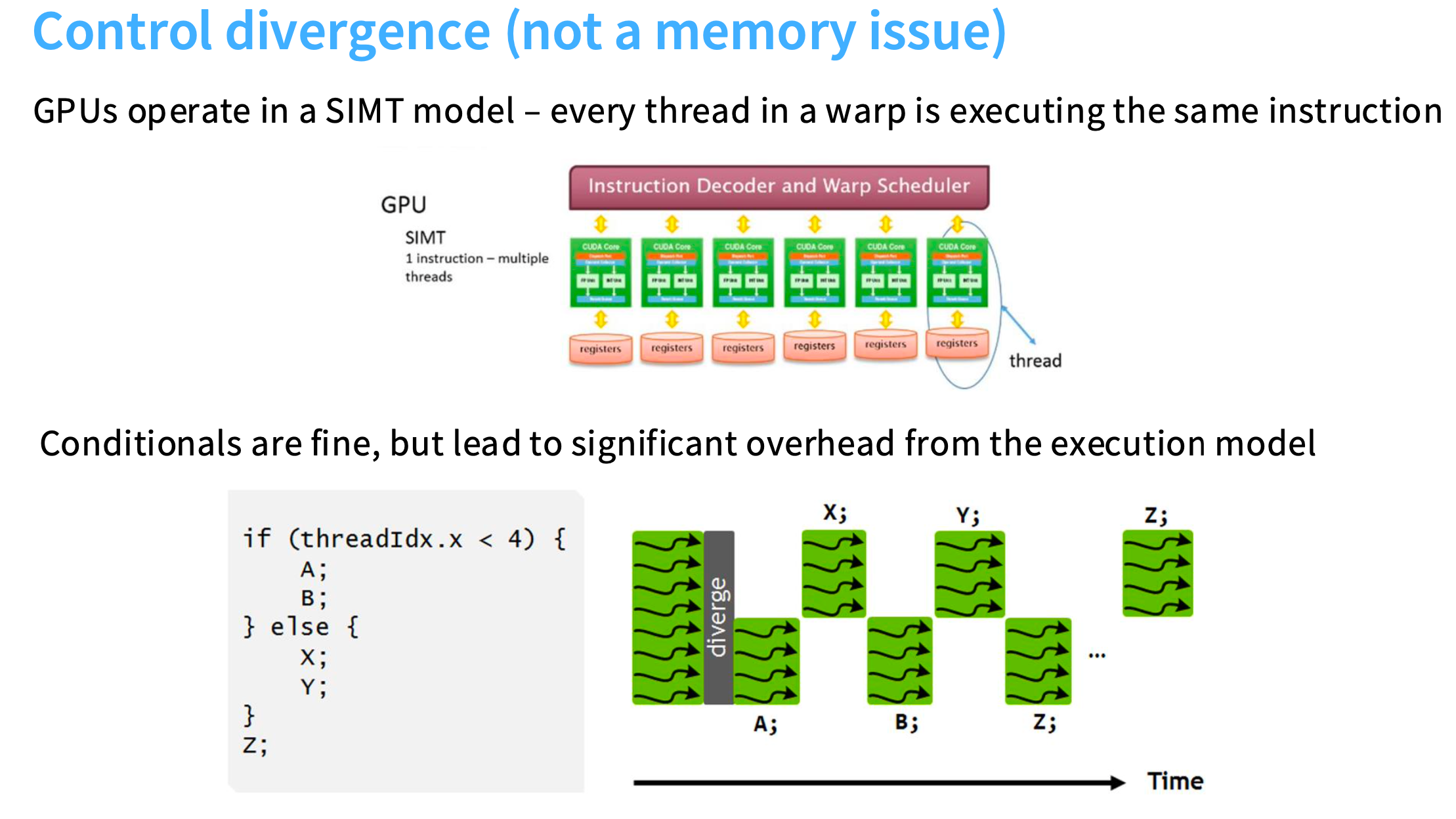
控制发散(并非内存瓶颈)Control divergence (not a memory bottleneck…)
GPU的执行模型叫做SIMT(single instrution multi-thread,单指令多线程),一个warp中的每个线程都会执行相同的指令,但操作的是不同的数据。
如果在GPU上运行下面的代码(如果线程索引小于4,就执行A/B;否则执行X/Y),满足if条件的线程执行A/B时,else条件对应的线程会暂停执行;如果满足else条件的线程执行,if条件的线程会暂停。所以,无法在不同的线程上同时执行A和X。每个线程都必须执行相同的指令,因此,在一个warp内部的条件语句可能非常有破坏性,因为它们会迫使你暂停任何线程。
和内存相关
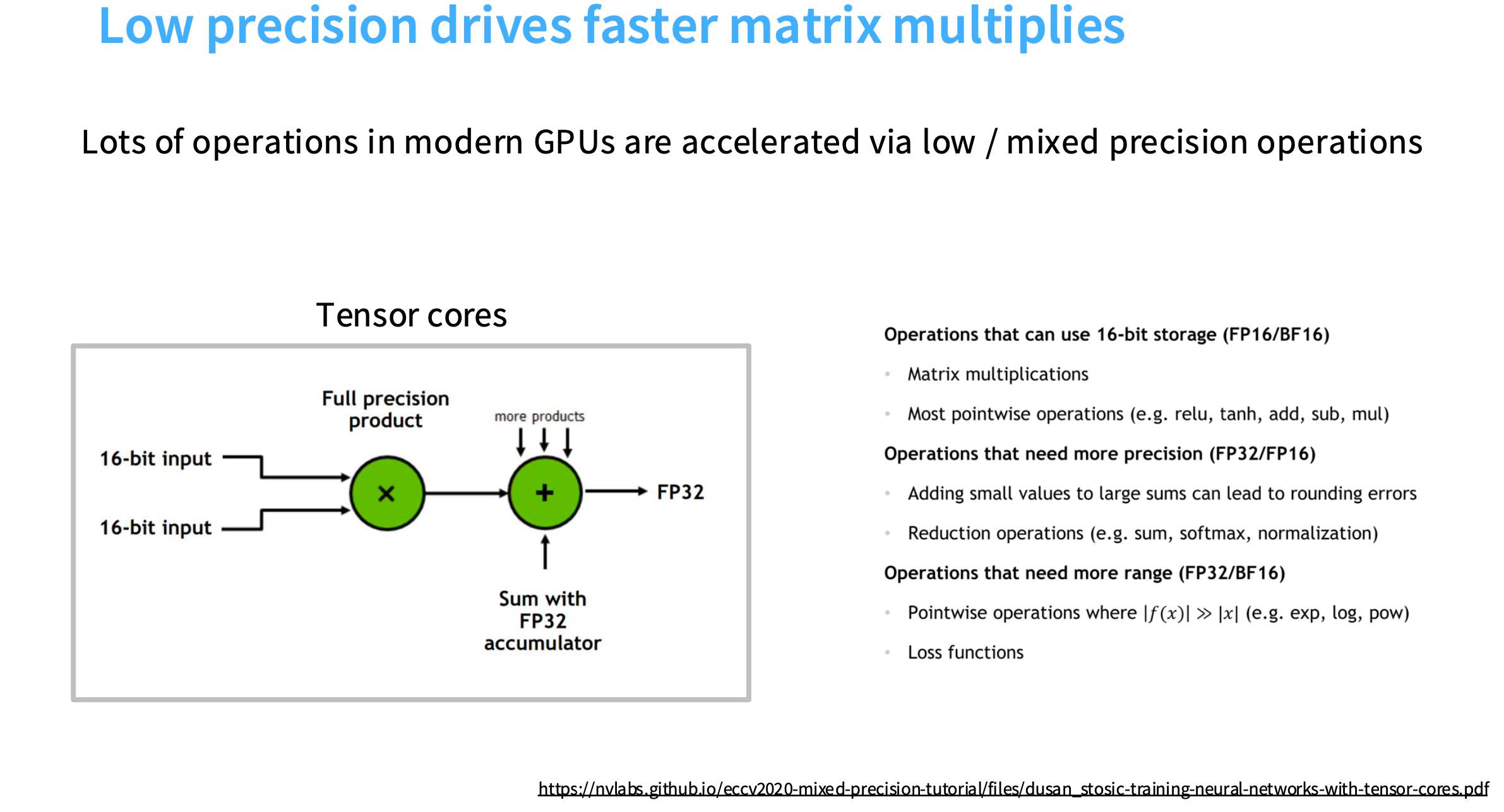
1. 低精度计算 Low precision computation
数据精度: FP32 -> FP16 -> INT8
如果你在计算中使用的位数更少,需要移动的位数就更少。
下面以ReLU为例,
-
Float 32:
内存访问次数:读一次、写一次,需要传输8字节(Float32是4字节,两次是8字节)
操作次数:一次比较,所以是1 FLOP -
Float 16:
内存访问次数:读一次、写一次,需要传输4字节(Float16是2字节,两次是4字节)
操作次数:一次比较,所以是1 FLOP

并非网络的所有部分和训练算法都应该放到低精度,所以在混合精度的矩阵乘法中,输入是FP16,然后进行完整的32位乘法(因为在累积部分和等中间计算时,你会希望在高精度中进行),接着利用FP32的累加器进行求和,最后返回FP32的结果。
https://nvlabs.github.io/eccv2020-mixed-precision-tutorial/files/dusan_stosic-training-neural-networks-with-tensor-cores.pdf
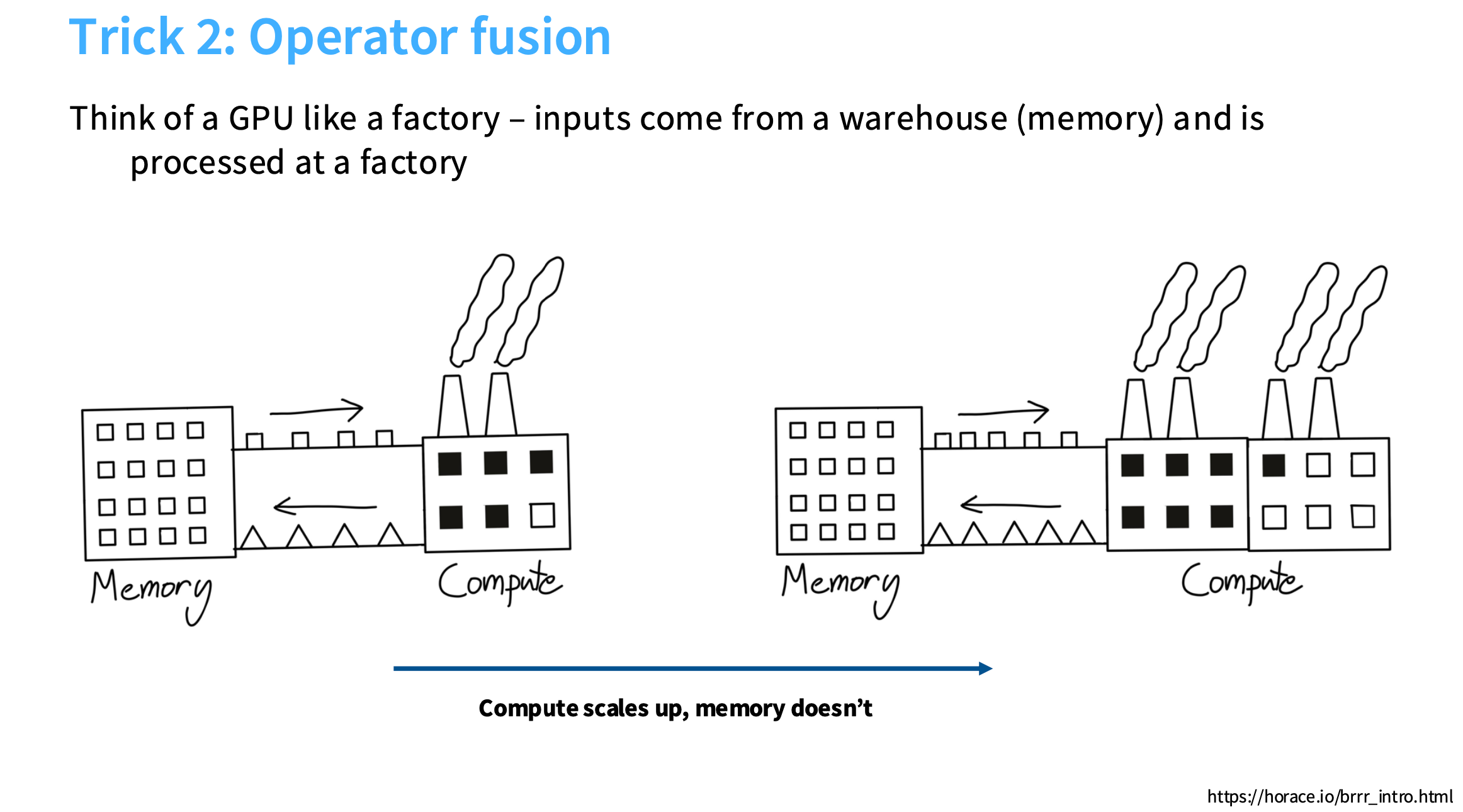
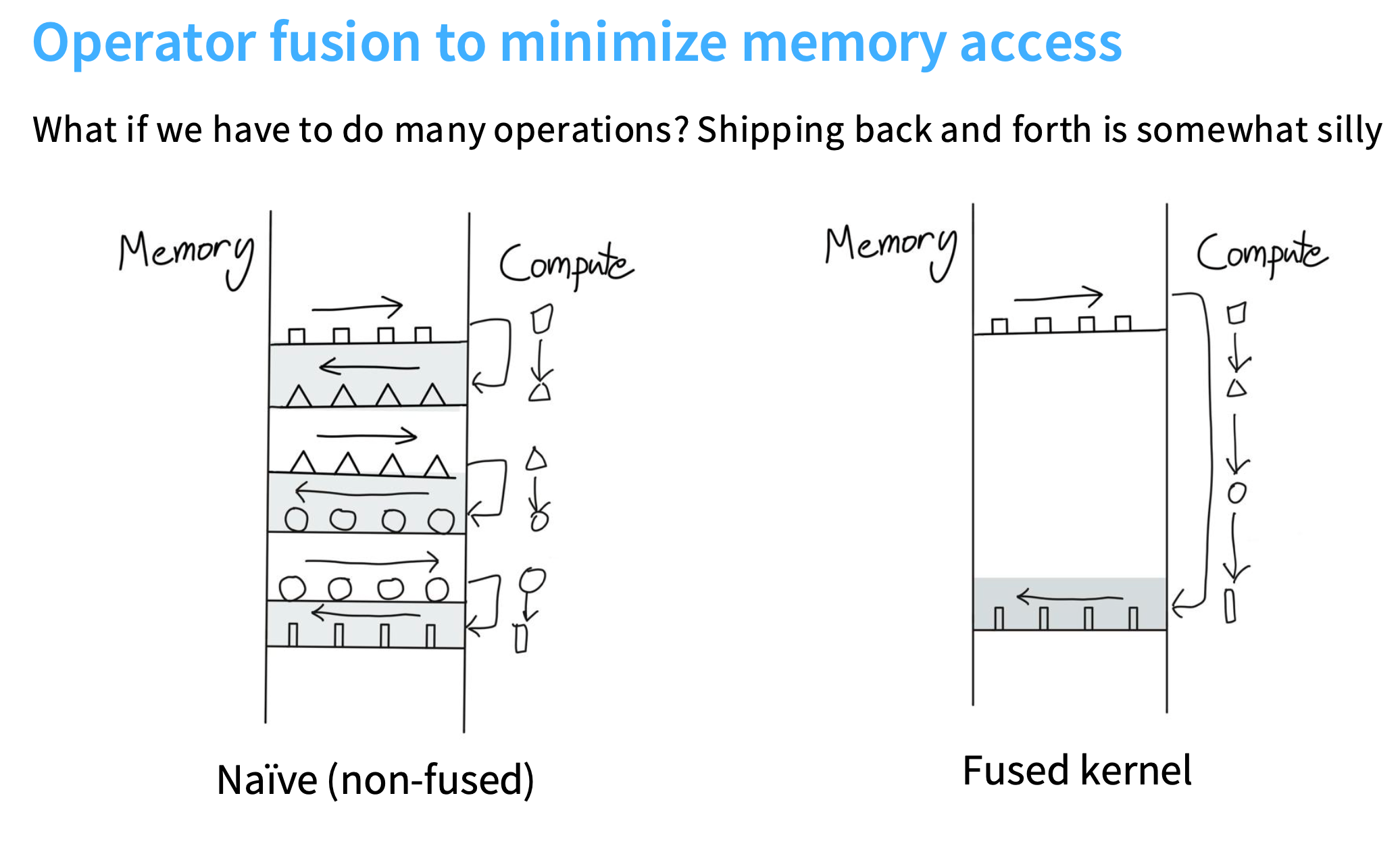
2. 算子融合 Operator fusion
假设你有一个工厂,工厂就是计算部分,它接收方形的小盒子,输出三角形。如果你增加工厂数量,但是传送带(将内存数据传送到计算单元)是有限带宽的,导致无法使用你的第二个工厂。也就是,仍然受限于从内存到计算传输数据的速度,导致存在瓶颈。
https://horace.io/brrr_intro.html
左侧:
内存传送正方形->计算为三角形->传回内存;内存传送三角形->计算为圆形->传回内存,以此类推,把计算结果来来回回地送回内存。这样会导致大量的内存开销。
右侧:
没有依赖关系,直接把所有东西都留在计算单元里,传回最终的长方形
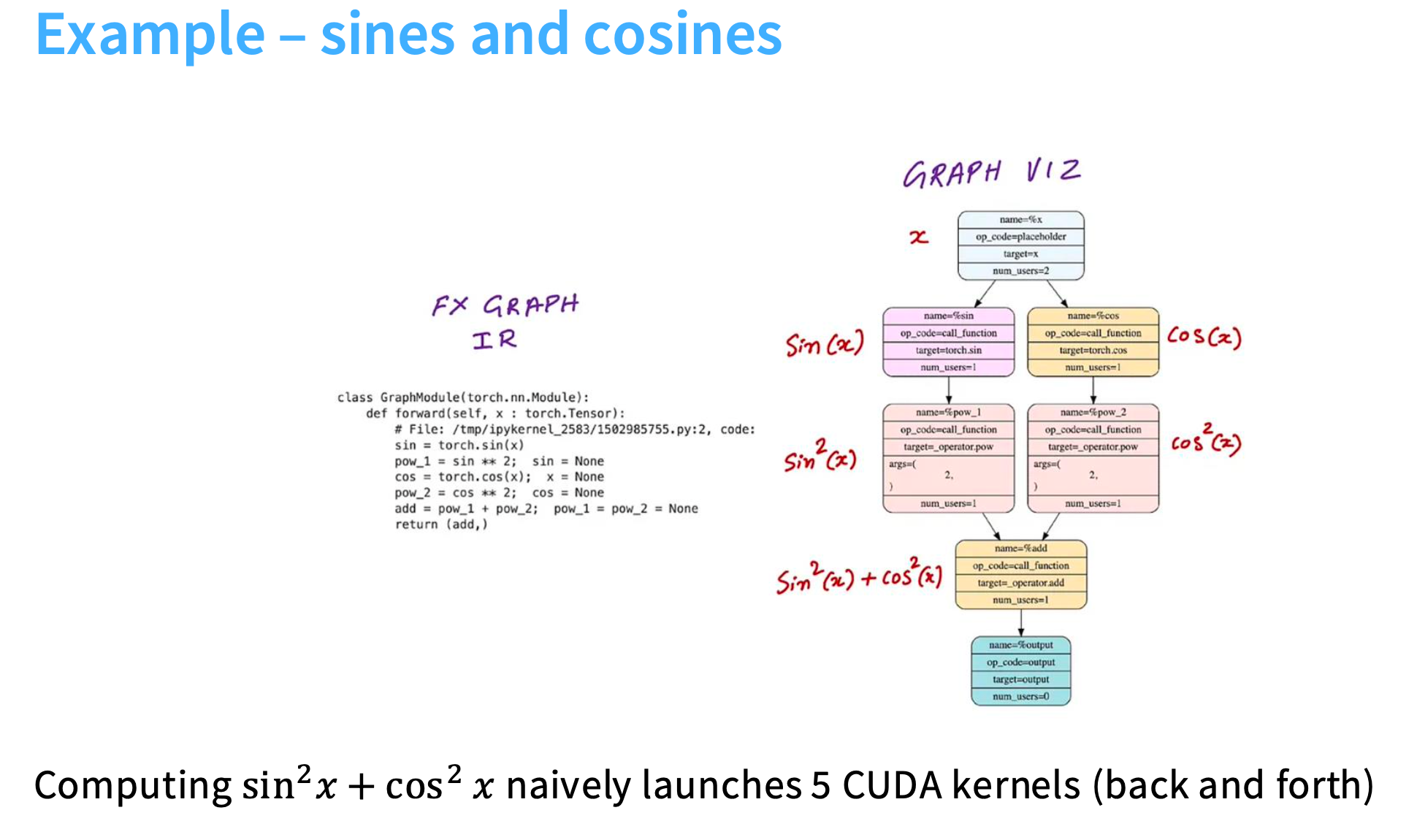
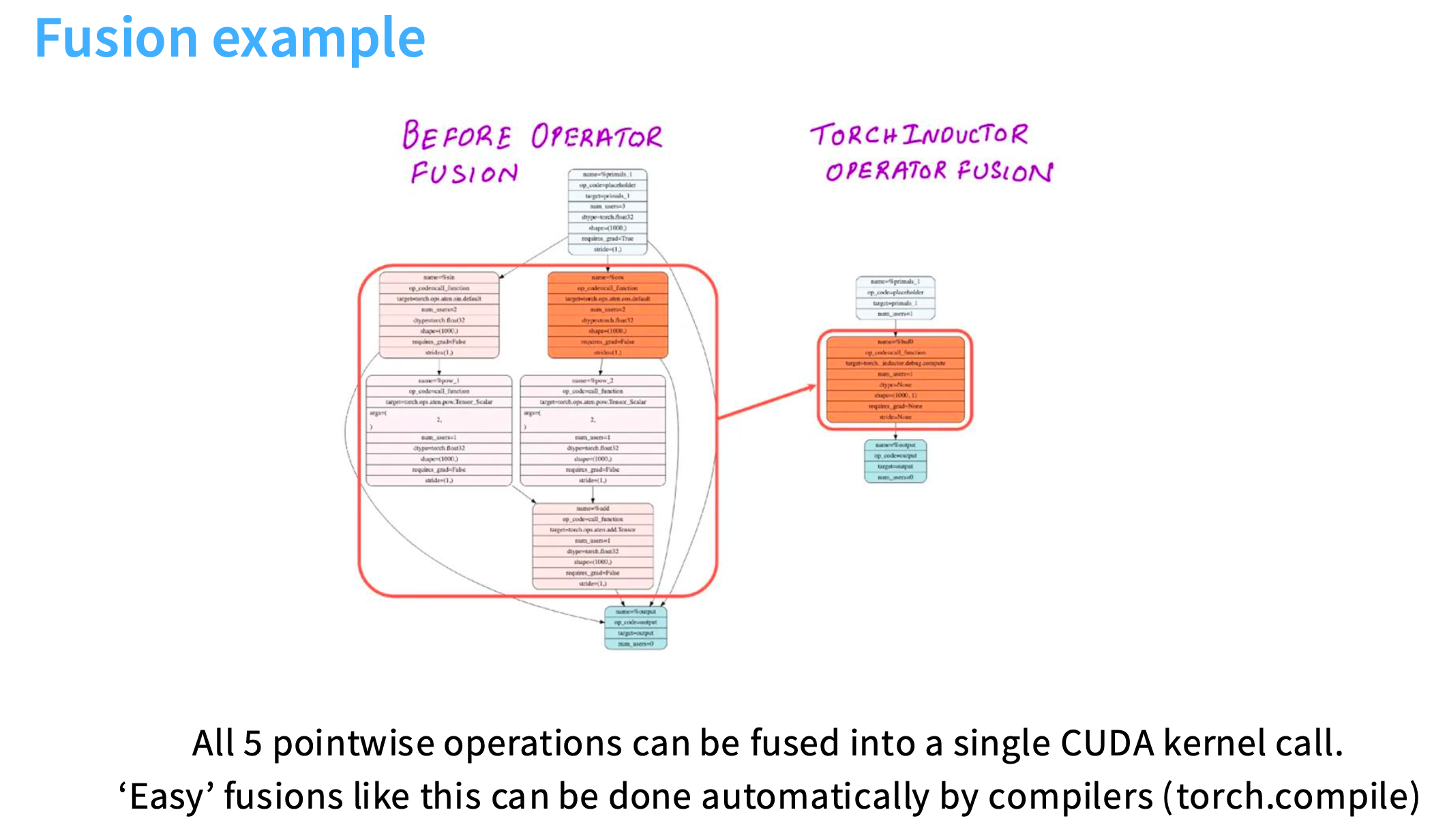
sin2x+cos2x 需要使用5个cuda核,但是使用torch.compile只需要1个cuda核
3. 重新计算 Recomputation
思想是,牺牲一些计算量来避免进行内存访问。
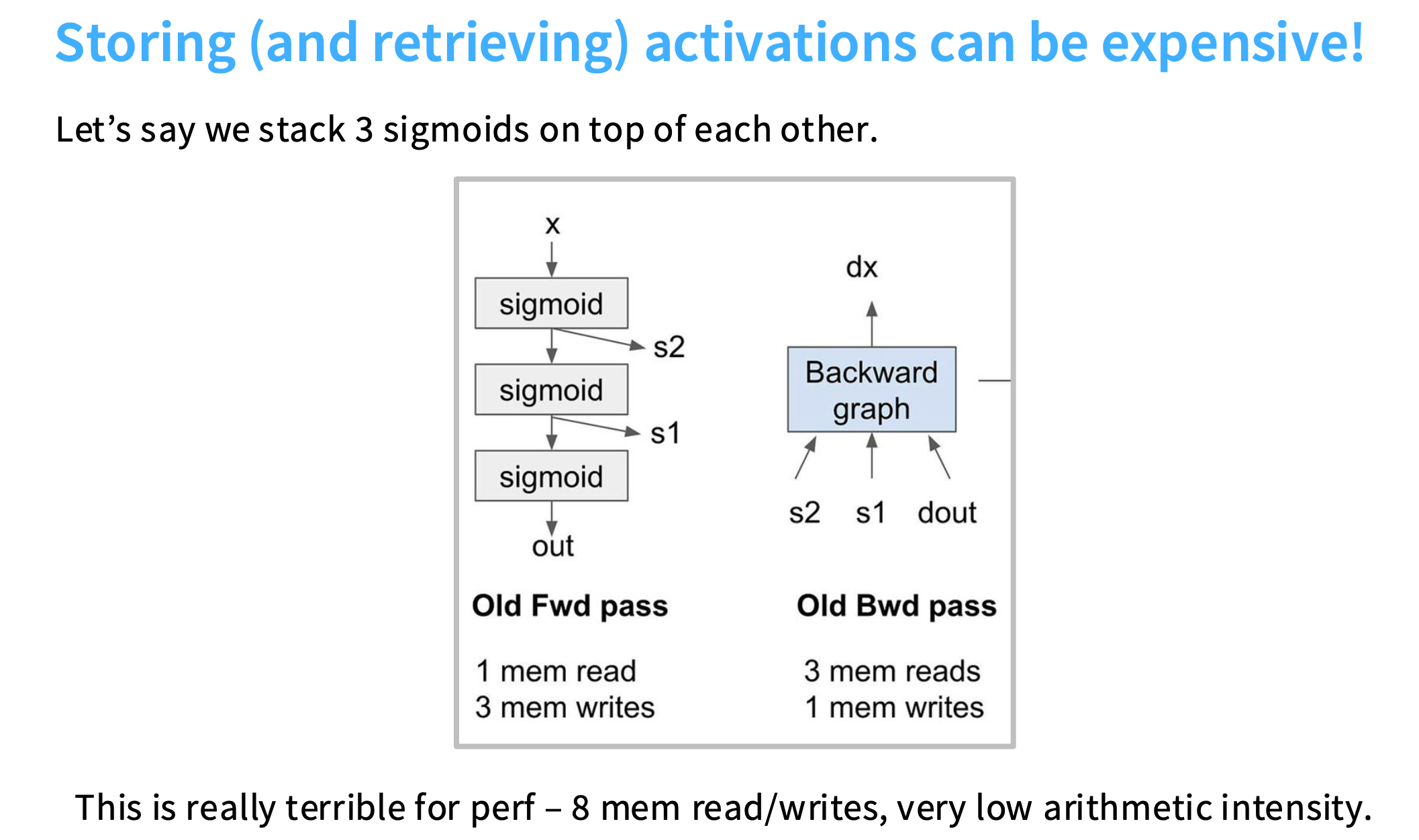
下图是前向传播和反向传播的过程。前向传播自底向上,黄色的值是必须被存储的,然后需要从存储它们的全局内存中取出并放入计算单元,会导致大量的内存输入和输出。
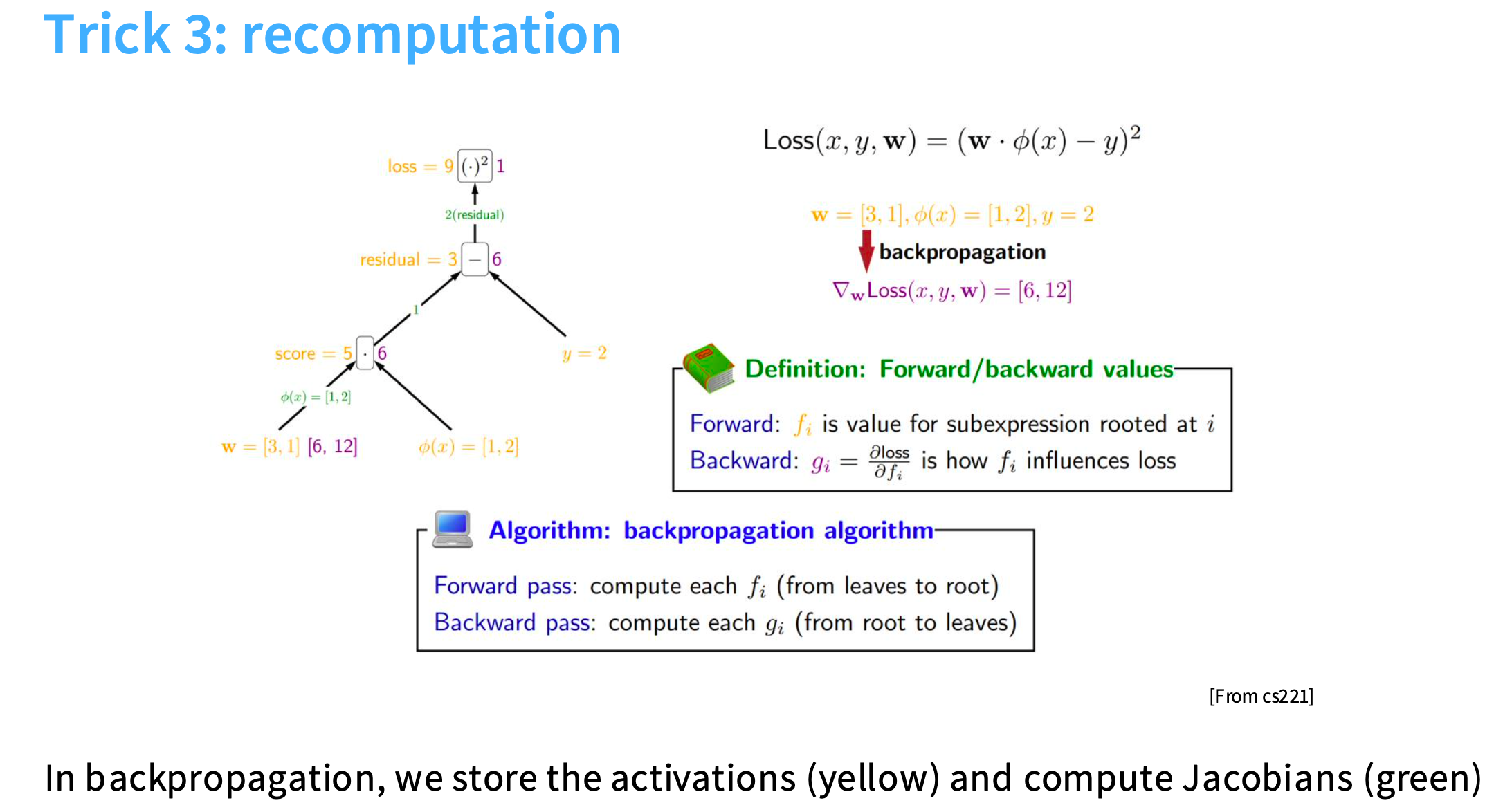
假设堆叠了3个sigmoid函数,前向传播时计算了S1、S2和output,反向传播时需要取出这三个值进行计算得到dx。
前向传播时,需要进行1次内存读取(x)和3次内存写入(S1、S2和output)
反向传播时,需要进行3次内存读取(S1、S2和output)和1次内存写入(x)。
https://dev-discuss.pytorch.org/t/min-cut-optimal-recomputation-i-e-activation-checkpointing-with-aotautograd/467
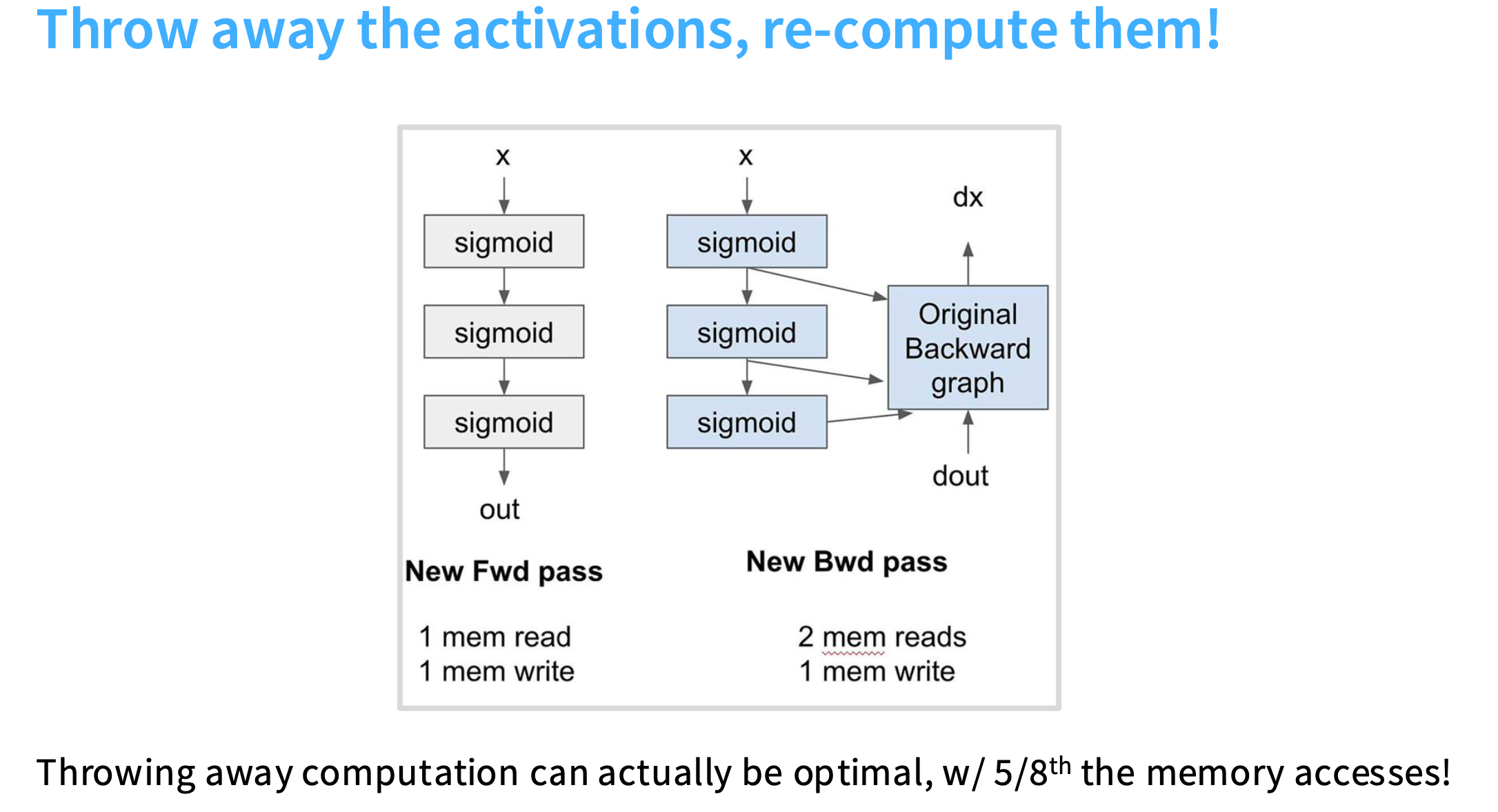
不存储激活值,即不放入内存中,而是在反向传播过程中即时重新计算它们。
所以现在,在前向传播过程中,不存储S1、S2,直接将x作为输入,计算sigmoid函数,然后得到输出,共计需要1次内存读取,1次内存写入。
在反向传播时,读取x和output,然后在我的SM和本地内存中,即时计算每个sigmoid函数的值,并将它们放入反向计算图中。共计需要2次内存读取,1次内存写入。
适用于计算资源闲置,但是内存带宽不足的情况
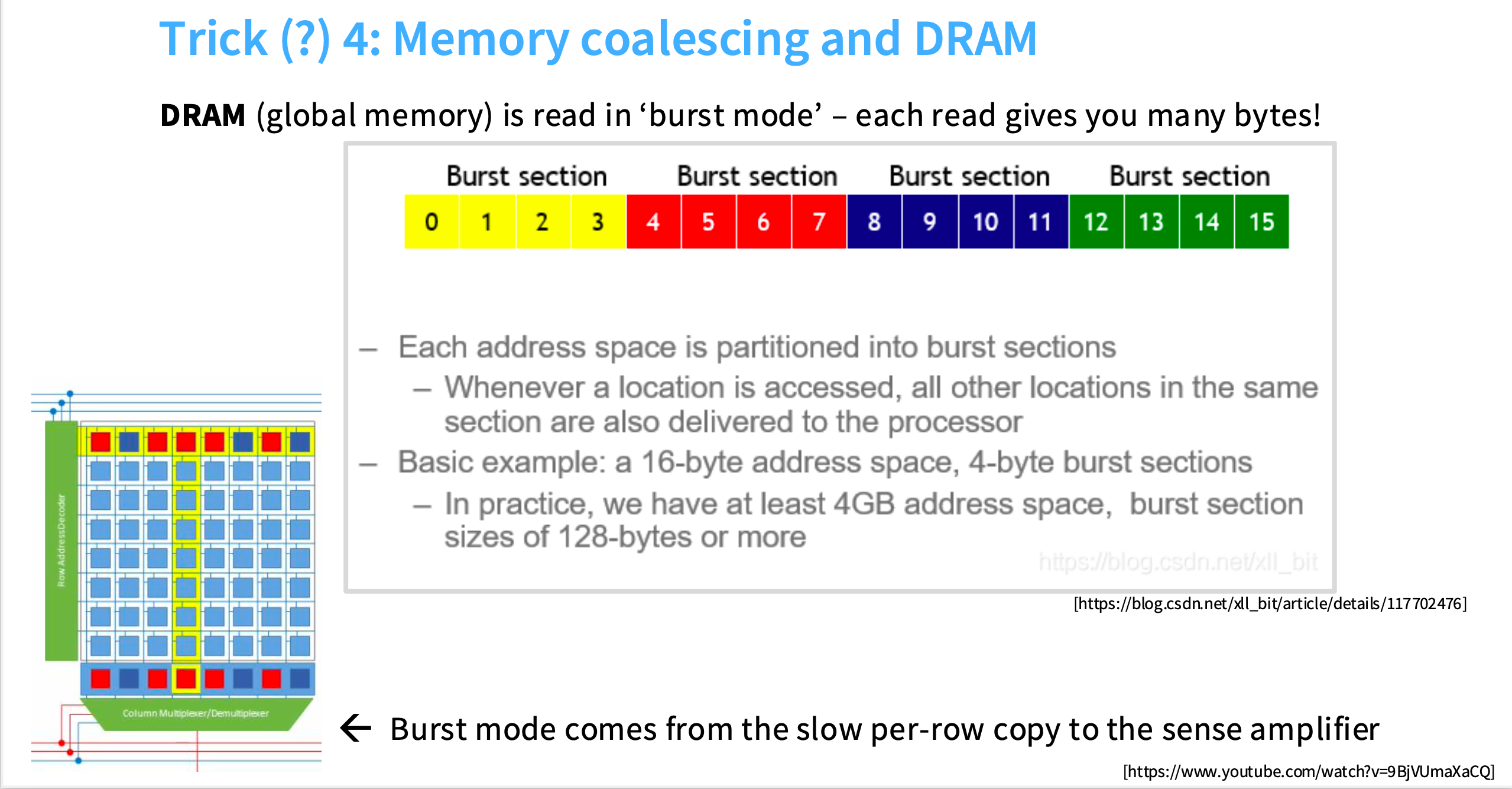
4. 内存合并 Coalescing memory
DRAM(全局内存/慢速内存),实际上非常慢,为了提高速度,在硬件层面进行了一些优化。其中一项是,当你在读取某一块内存区域时,实际上不会只返回那个值,会返回一整块内存区域,被称为burst mode。例如要读取0时,会返回0、1、2、3。
每个地址空间被划分为burst sections,你会得到整个burst section,而不仅仅是你查找的那个值。原因是,当你寻址内存时,为了将信号从内存中发送出去,那些字节必须被移到放大器(amplifier),这是最慢的一步,一旦完成这一步,你就可以得到许多字节。burst mode在一定程度上掩盖了将数据实际移动到放大器这个更昂贵的步骤。
https://blog.csdn.net/xll_bit/article/details/117702476
https://www.youtube.com/watch?v=9BjVUmaXaCQ
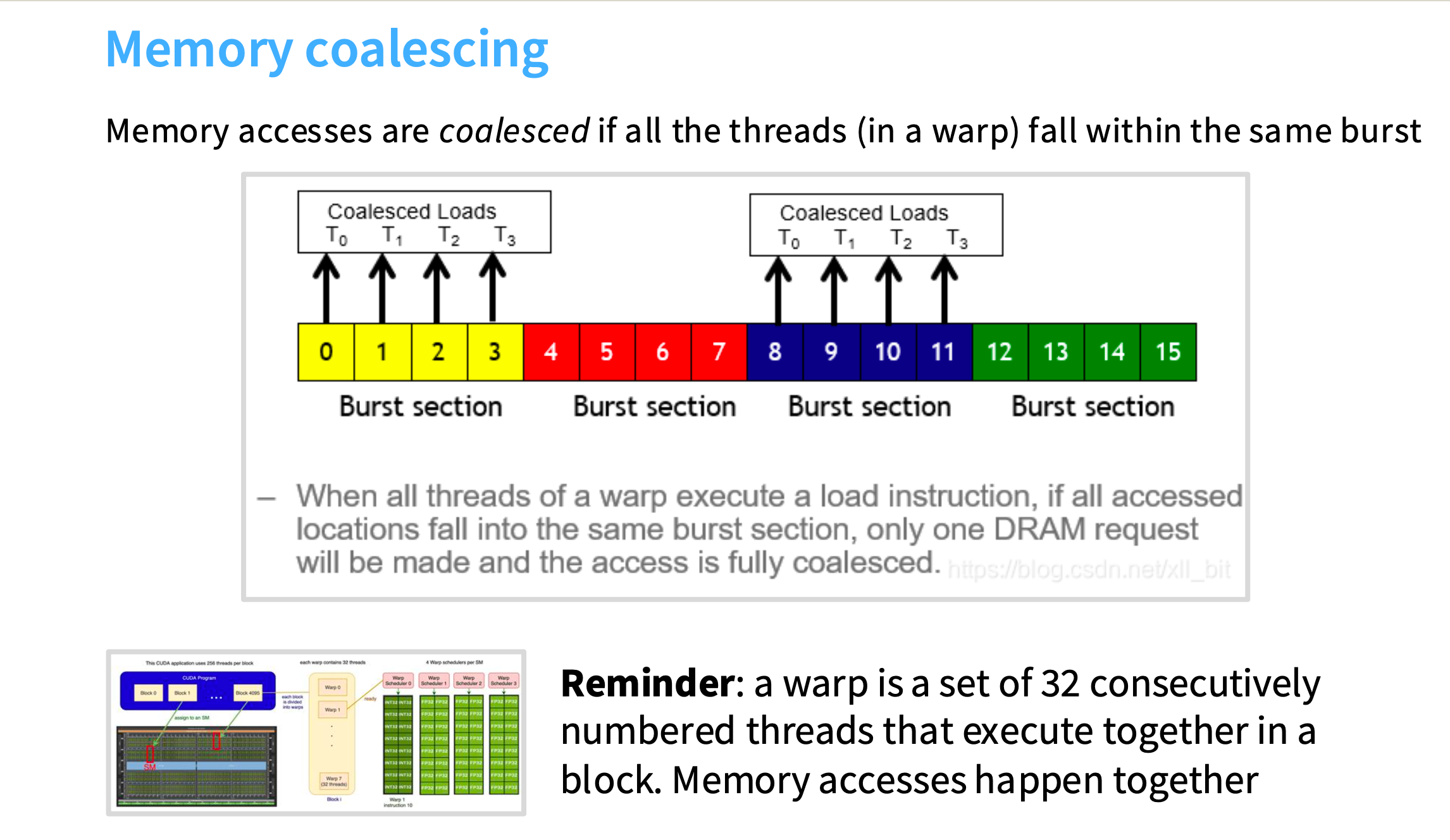
如果我想要整块的数据,以随机的顺序访问,那么访问次数可能会大于数据长度;但如果我先检查第一个值,就能得到burst section的整个部分,就可以获得四倍的吞吐量。
内存合并:如果一个wrap中的所有线程都落在同一个burst section中,智能硬件和编程模型就会将这些查询分组,而不是分别查询0、1、2、3。
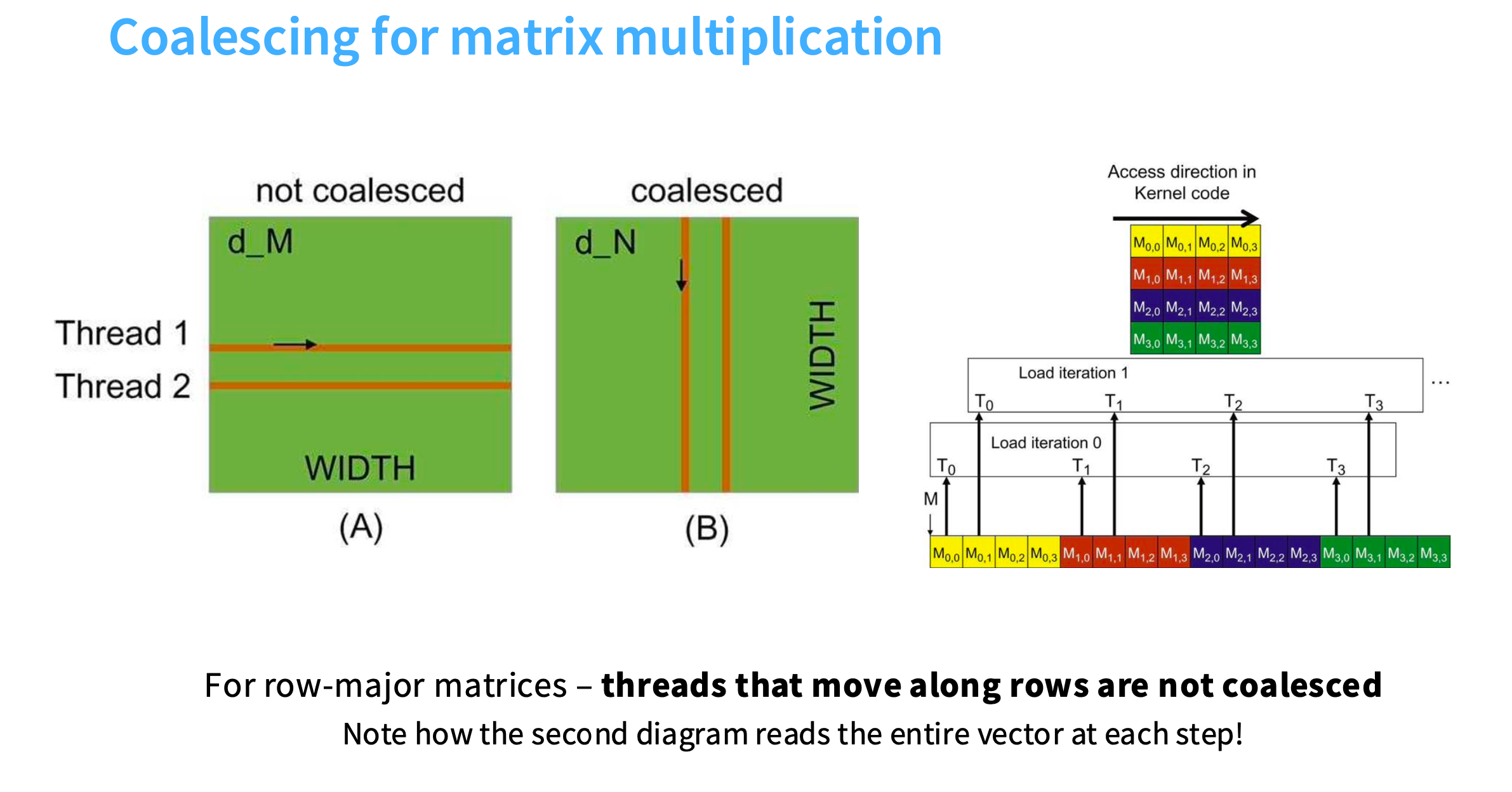
在cuda中,假设要以两种方式(每个线程遍历行/列)之一读取矩阵。
图(A),遍历列:速度会非常慢,因为内存读取不会被合并
图(B),遍历行:速度快,内存读取被合并
为什么?看右边的图
一系列线程试图从左到右访问,T0时刻,每个线程会试图加载第一列元素;在下一个时间步(T1时刻),会加载第二列元素,以此类推。
每个时刻读取的内容无法合并,因为在读取不同的突发段,例如T0时刻读取的是M0,0 、M1,0、M2,0、M3,0。导致只有读取完完整的内存块,才能执行任何操作。
5. 分块 Tiling
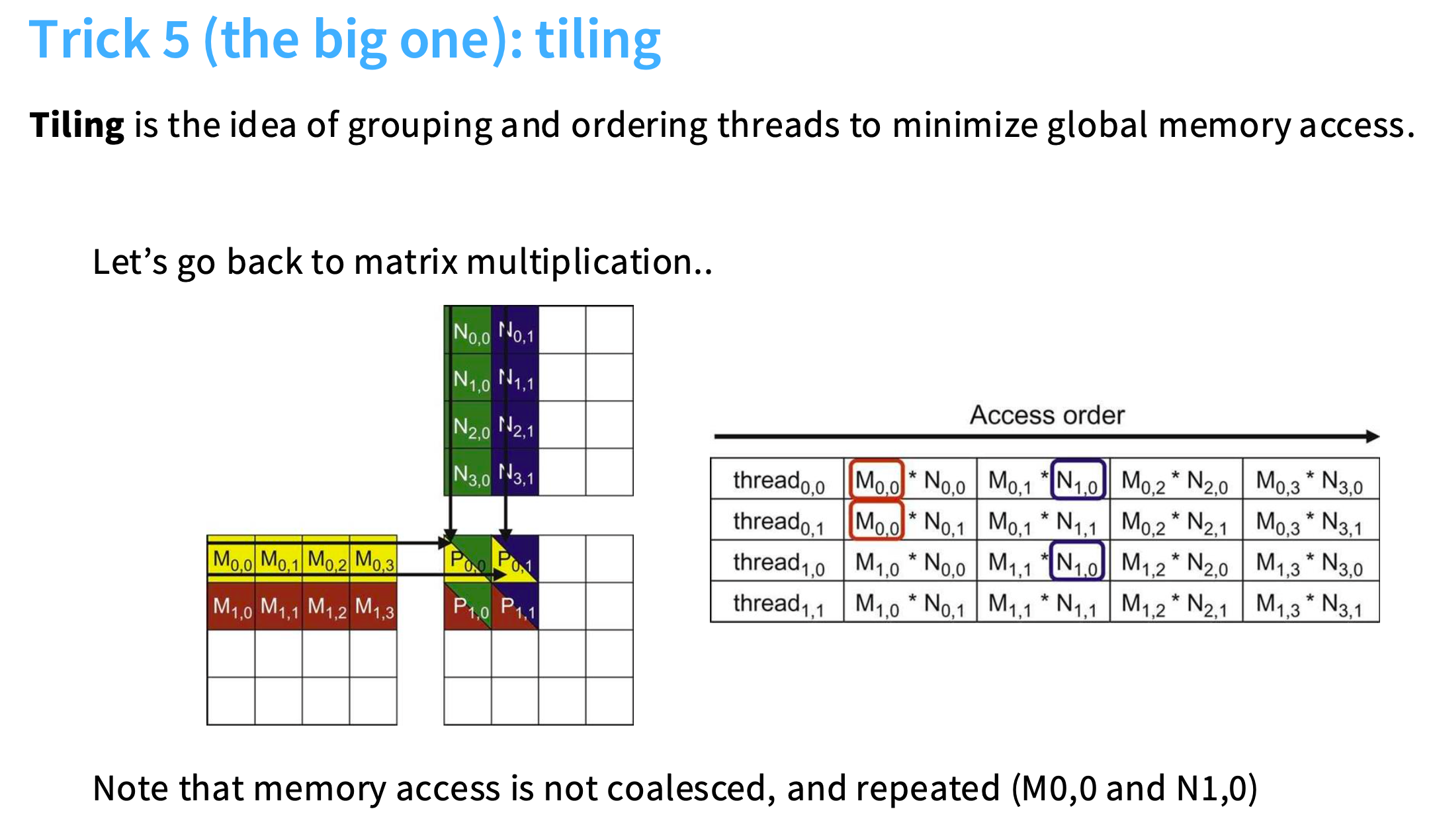
矩阵乘法如下,注意到内存不是合并的(因为线程按列遍历),并且有重复的内存访问。这些值正在从全局内存中被一遍又一遍地读取到许多不同的线程中,所以会非常慢。
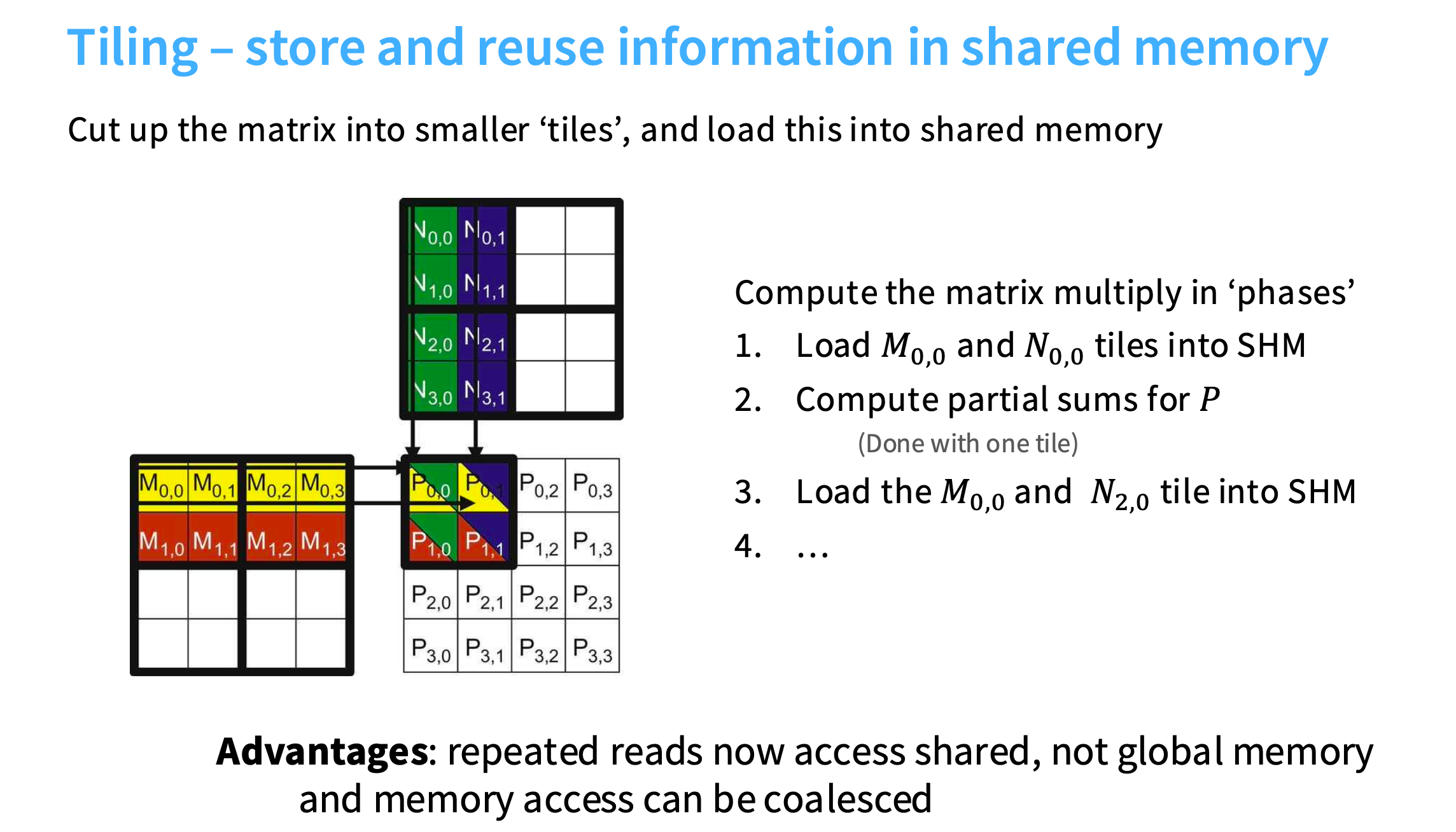
理想情况是,花一段时间,将数据块从全局内存加载到共享内存,在共享内存中进行大量计算。
做法是,将M矩阵和N矩阵切成小块,加载到共享内存中,在左上角的两个块计算完以后,就可以加载新的块(如N矩阵的左下角),和M矩阵左上角继续计算。
结果:减少了全局内存访问量,而且对于子矩阵可以自由决定用行或列遍历,提高效率。
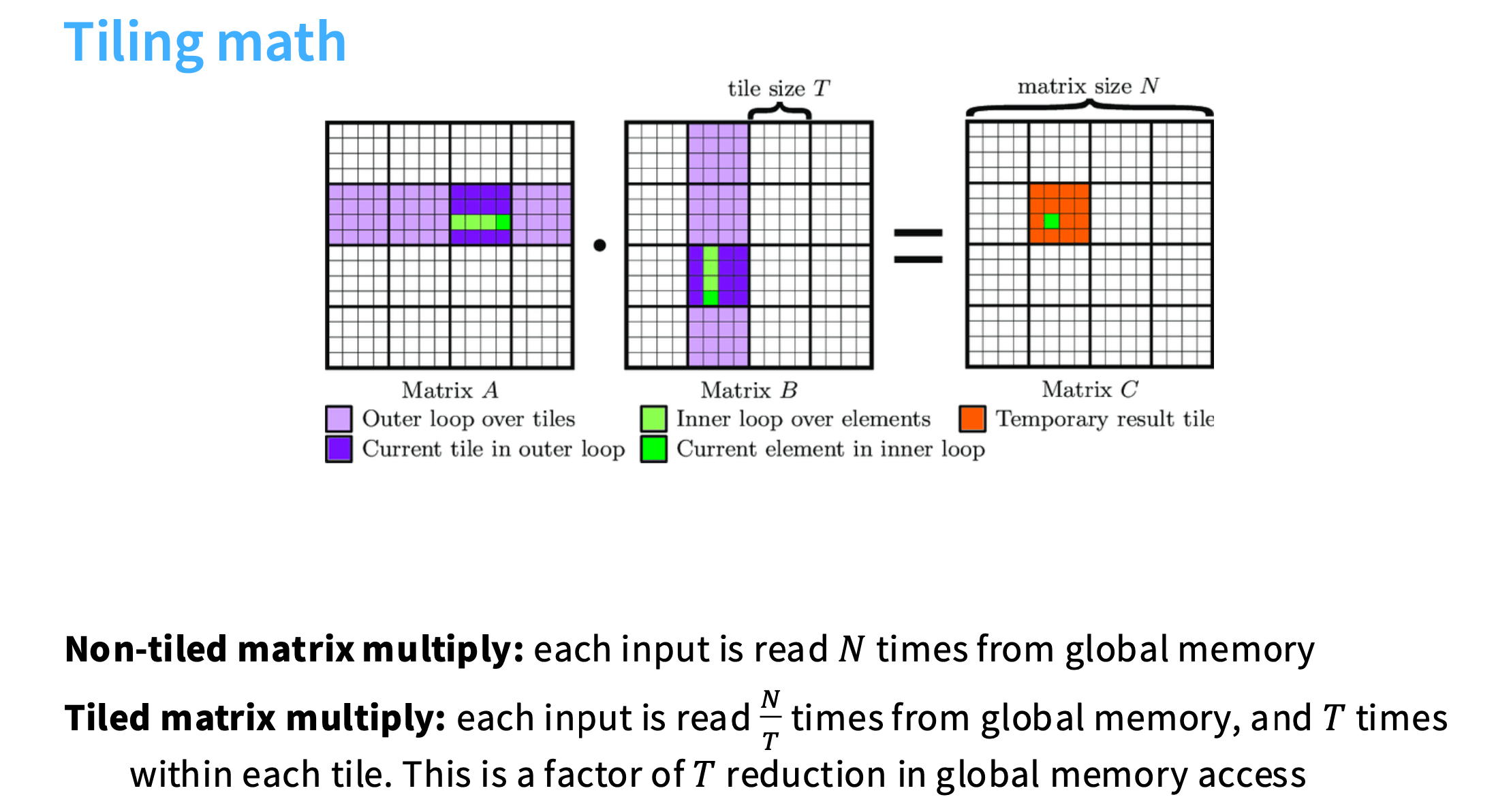
假设要做N*N的矩阵乘法,如果做非分块的矩阵乘法,每个输入 Ai,j 要从全局内存中读取N次。
如果做分块的矩阵乘法,每个分块要读N/T次,每个分块内的Ai,j要读取T次。
比如子矩阵的大小是T
难点一:分块大小的确定
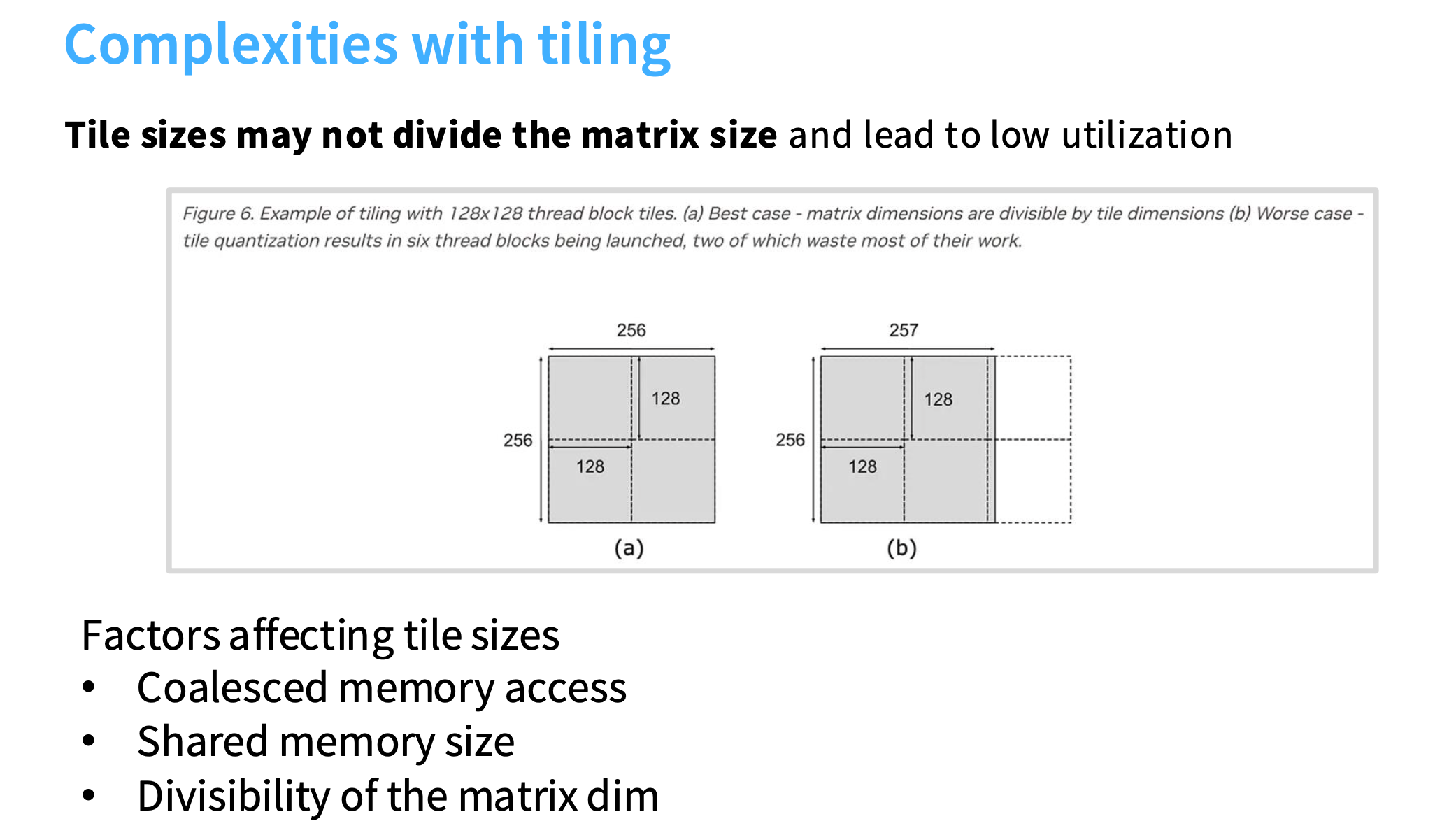
例如右边是256*257,分完块多了一列,导致多出两个小块。因为每个分块会被分配给一个SM,每个线程会在各自的分块内工作,右边的两个小块基本上没什么工作,导致SM被闲置。
所以需要优化分块大小,避免此类情况发生。
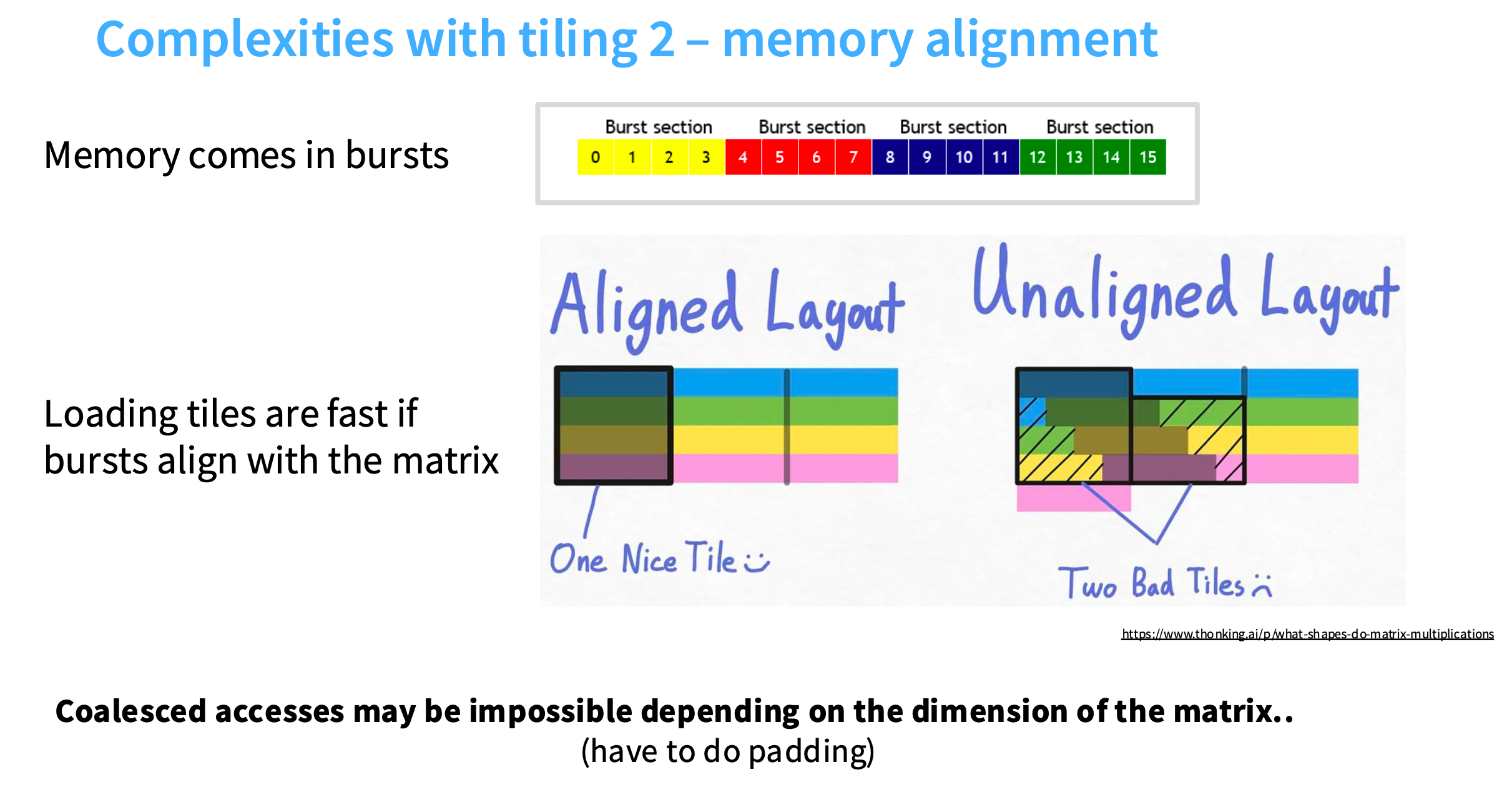
难点二:分块和 burst sections 之间的交互
在Aligned Layout图中,因为分块和burst section对齐得很好,所以只需要读取分块,就可以获得四个不同的burst sections。
在Unaligned Layout图中,多加了一个元素,导致分块和burst section不再对齐,第二行中,分块对应的是两个burst sections,所以要读取两次。导致内存访问量增加一倍。
解决方案是padding,得到规整的矩阵大小。
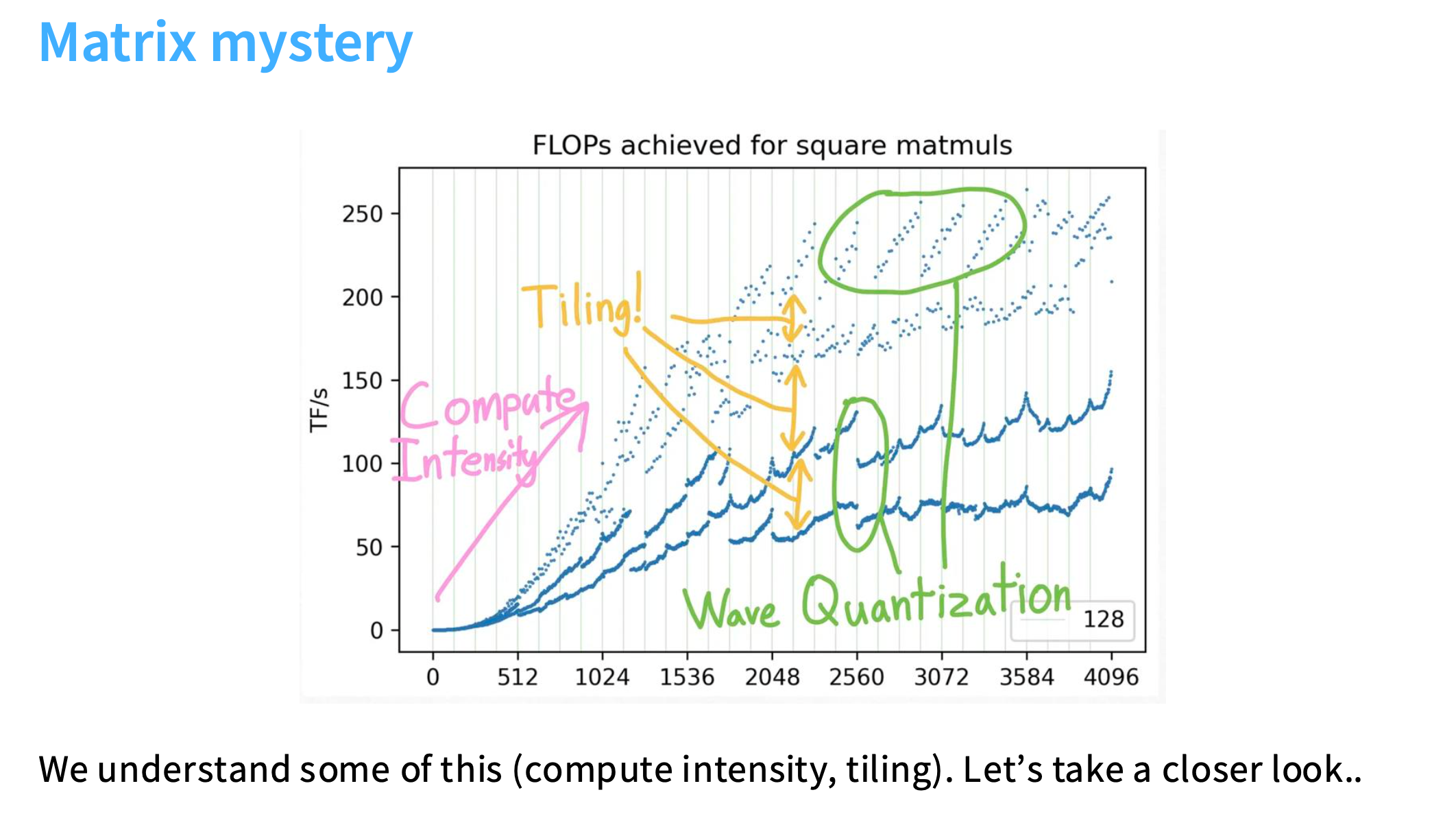
屋顶图谜团
Roofline模型可以直观展示一张曲线图,其中x轴表示AI(Arithmetic Intensity),即每个内存操作对应的浮点运算次数;y轴表示性能,通常以每秒浮点运算次数(Tflops)表示。
图中的“屋顶”(Roofline)由两部分组成:一部分是峰值内存带宽(Memory Bandwidth)限制的斜线,另一部分是峰值计算性能(Peak Performance)限制的水平线。这两部分相交的点是应用程序从内存带宽受限转变为计算性能受限的转折点。
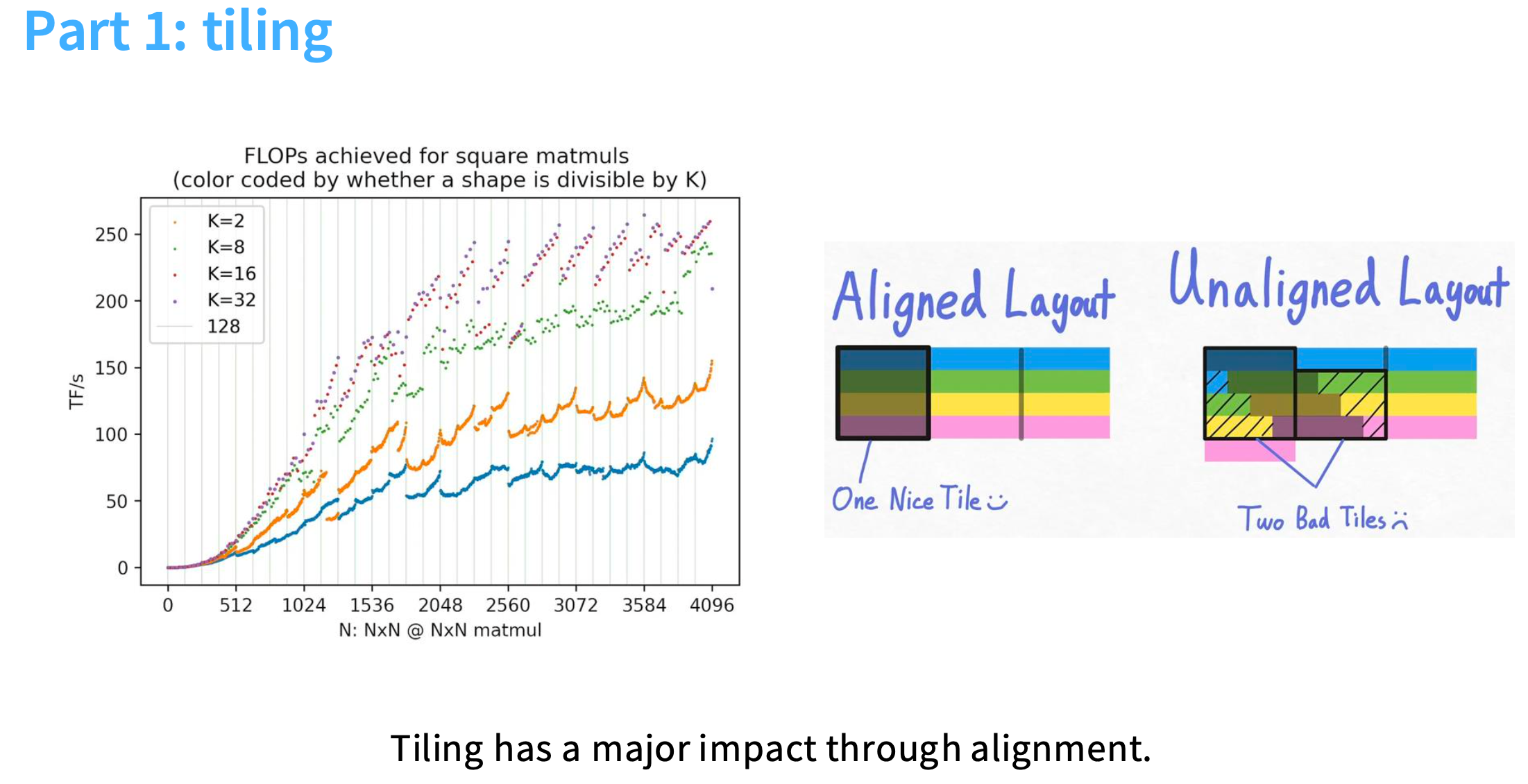
第一部分:tiling
K越大,对应的峰值计算性能越高。
例如K=32或16,可以看成是 aligned layout 的情况,burst section和分块的大小一致,可以达到最高利用效率;
K=8或2,对应的是unaligned layout,容易产生碎片,导致效率低
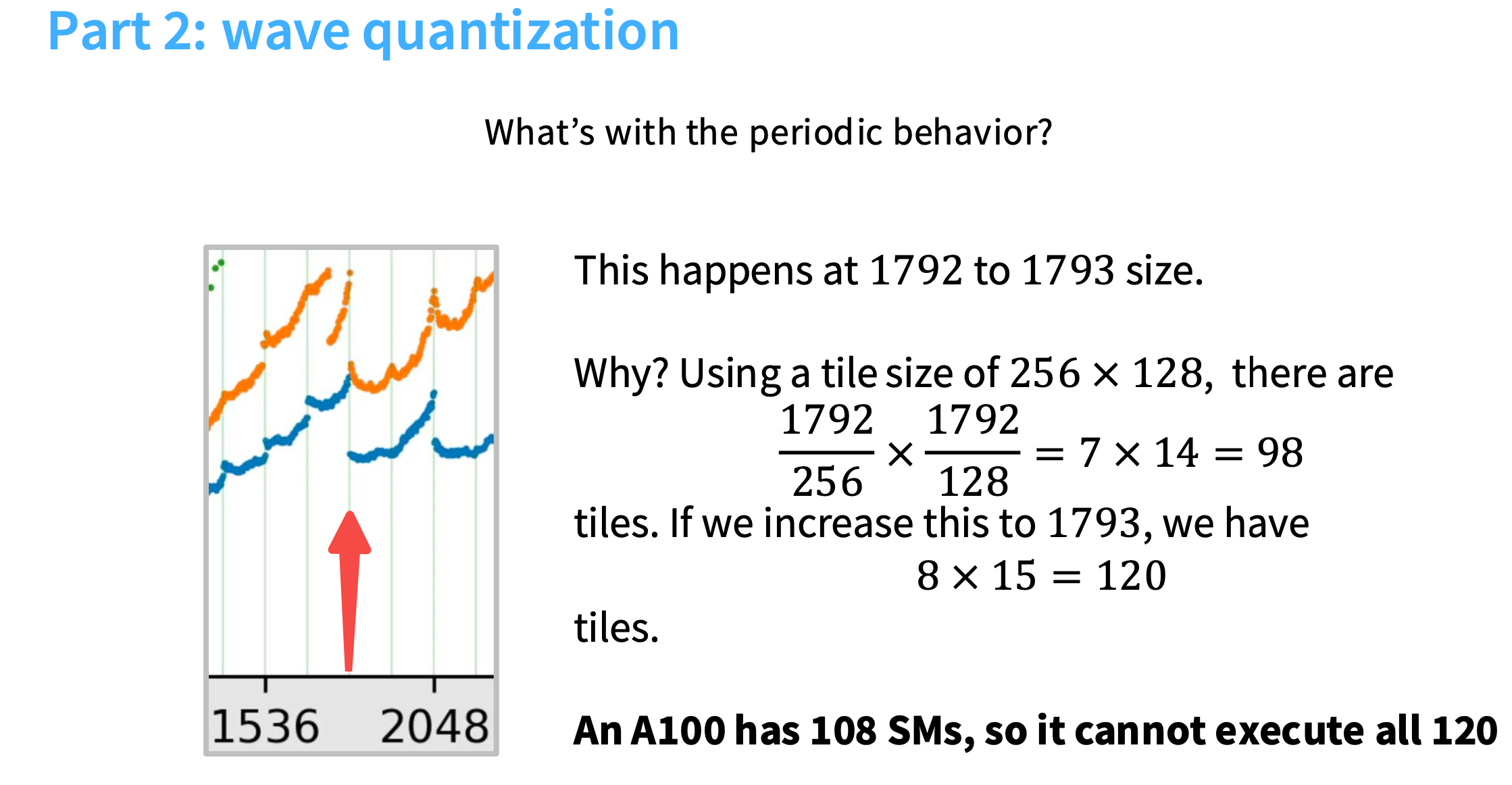
第二部分:wave quantization
从1792到1793,每秒浮点运算次数有一个骤降。
原因是,假设分块大小为256*128,1792可以整除得到98个分块,A100的108个SM能覆盖住;
但是1793得到的是120个分块,超过了108,无法全部执行运算。导致运行时,一会儿是利用率很高,一会儿利用率很低
总结
- 减少内存访问次数
– 算子融合 Operator fusion
– 内存合并 Coalescing memory - 移动到共享内存
– 分块 Tiling - 用内存换取计算效率/精度
– 低精度计算 Low precision computation
– 重新计算 Recomputation
flash attention
思路:用计算成本解决,内存复杂度需要n的平方的问题
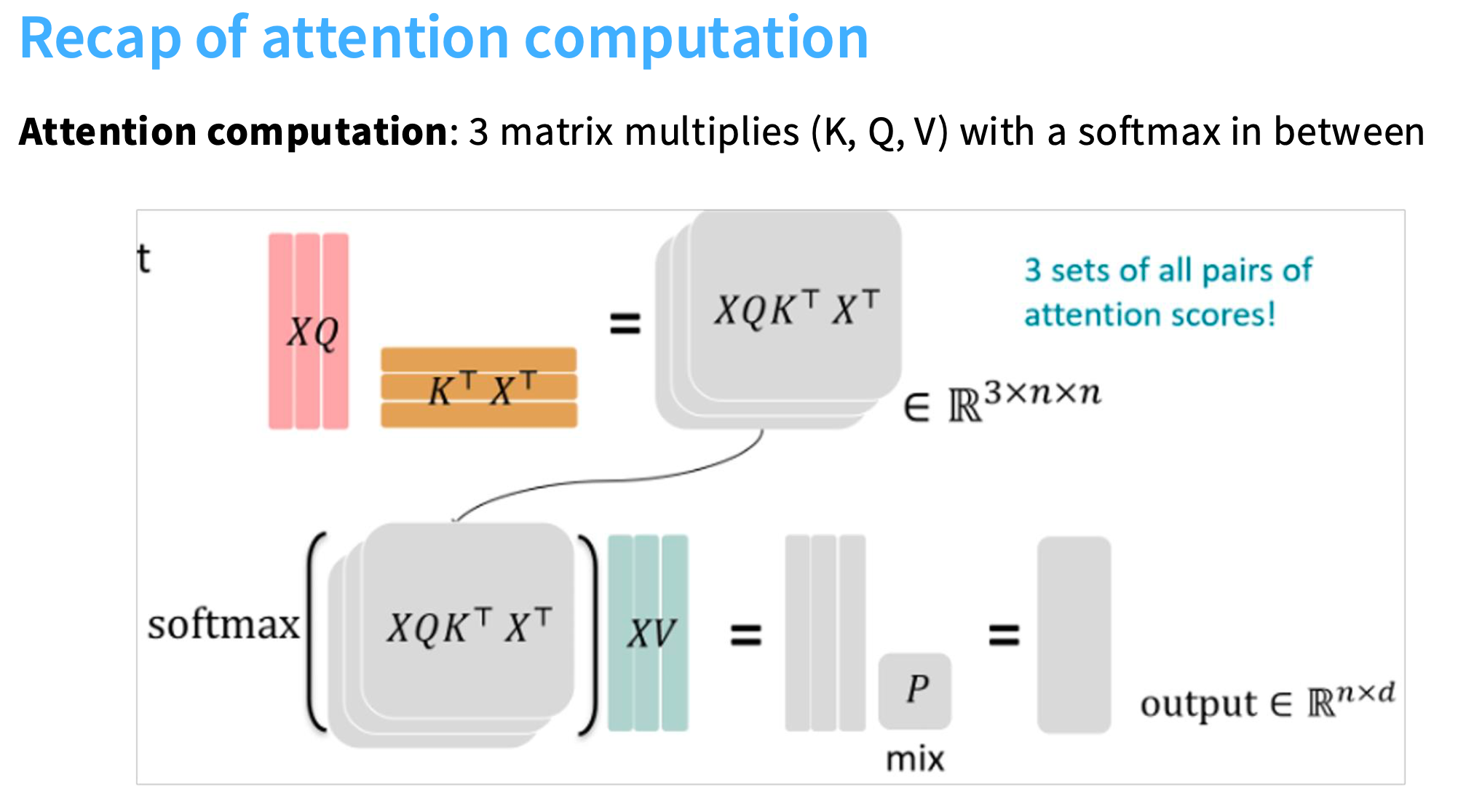
回顾attention的计算方式:
Attention(Q,K,V)=softmax(Q⋅KTdk)⋅V\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_k}} \right) \cdot VAttention(Q,K,V)=softmax(dkQ⋅KT)⋅V
关键就在于矩阵乘法和softmax
矩阵乘法优化
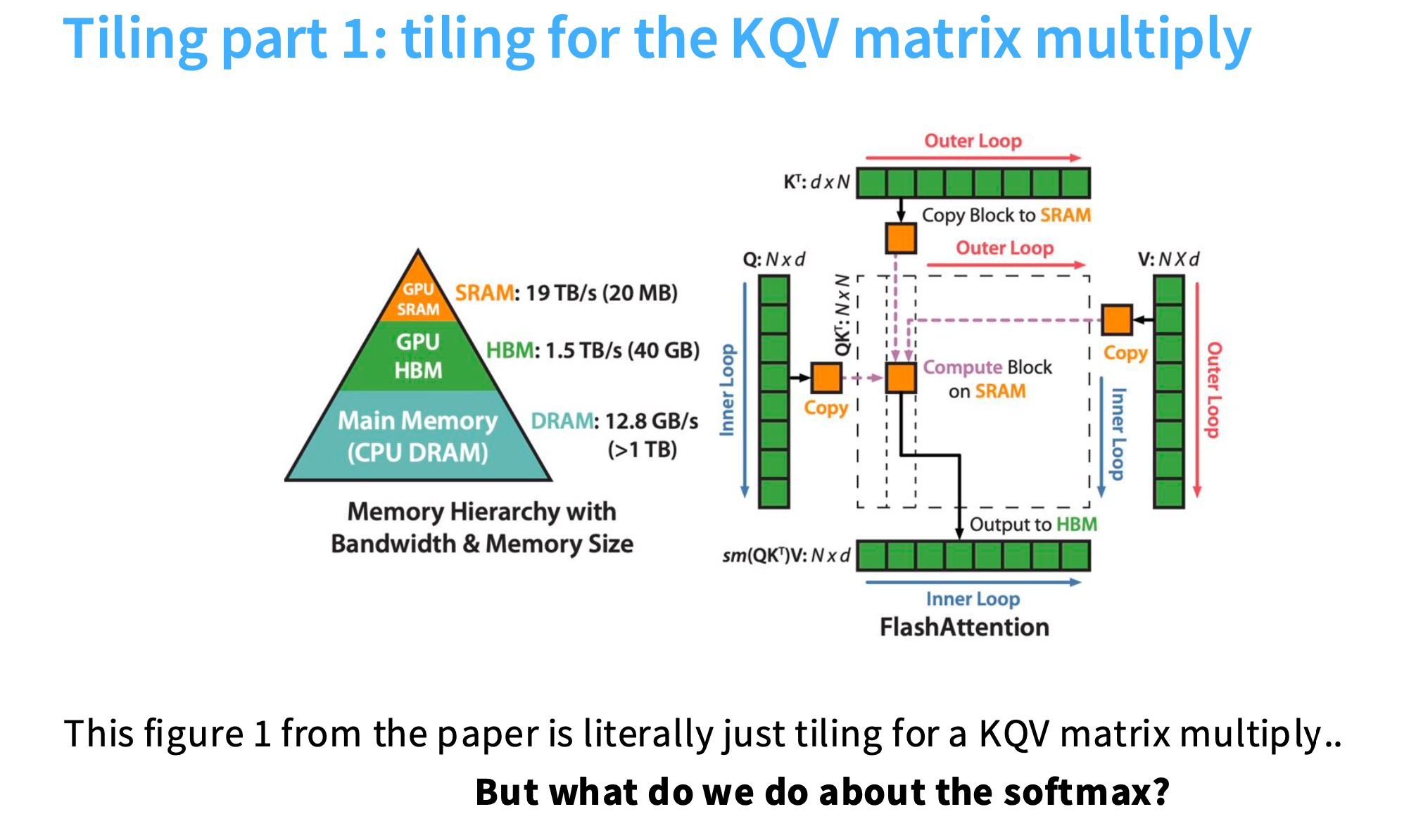
利用分块(tiling),Q矩阵和K矩阵被切成小块,这些小块被复制到SRAM,进行乘法运算,然后累积并发送到HBM,在HBM中进行softmax,再与V相乘。
三者区别可见 SRAM、HBM、DRAM含义及对比
softmax优化
softmax是全局计算的,但是现在使用了分块,如何做到在每个分块内计算softmax?
原始 softmax
对于一个输入向量 x=(x1,x2,…,xV)\mathbf{x} = (x_1, x_2, \dots, x_V)x=(x1,x2,…,xV),其中 VVV 是向量的维度,softmax函数对每个元素 xix_ixi 的计算为:
softmax(xi)=exi∑j=1Vexj\text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{V} e^{x_j}} softmax(xi)=∑j=1Vexjexi
其中:
- exie^{x_i}exi是自然指数函数(以欧拉数 e≈2.718e \approx 2.718e≈2.718为底的指数)
- 分母是向量中所有元素的指数之和,用于归一化,确保输出的所有元素之和为1
特点:
- 概率化:输出值均在 [0, 1] 范围内,且总和为1,可直接作为概率解释
- 单调性:输入值越大,对应的输出概率越高
- 放大差异:相对于较小的输入值,较大的输入值会被赋予更高的相对权重
safe softmax
在实际应用中,为了避免指数运算导致的数值溢出,通常会在分子分母同时减去输入向量中的最大值(这不会改变最终结果),优化后的计算方式为:
softmax(xi)=exi−maxk=1Vxk∑j=1Vexj−maxk=1Vxk,maxk=1Vxk就是x中的最大值\text{softmax}(x_i) = \frac{e^{x_i - \max _{k=1}^{V} x_{k}}}{\sum_{j=1}^{V} e^{x_j - \max _{k=1}^{V} x_{k}}},\max _{k=1}^{V} x_{k} 就是 \mathbf{x} 中的最大值 softmax(xi)=∑j=1Vexj−maxk=1Vxkexi−maxk=1Vxk,k=1maxVxk就是x中的最大值
| 伪代码 | 含义 |
|---|---|
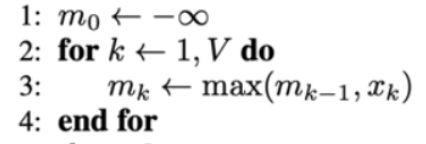 | 这一段逻辑执行完,mVm_VmV就是 x\mathbf{x}x 中的最大值 |
| – | – |
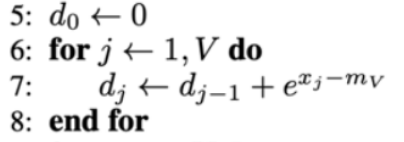 | 这一段逻辑是在计算分母,dVd_VdV就是累积的结果 |
| – | – |
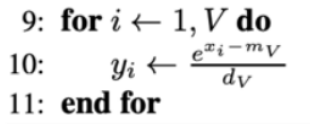 | 这一段逻辑,将每个xix_ixi减去最大值再除以累计和,得到归一化后的结果yiy_iyi |
online softmax

各变量的含义:
- xjx_jxj:输入序列中的第jjj个元素(例如待计算softmax的向量元素);
- VVV:输入序列的总长度(即向量维度);
- mjm_jmj:到第jjj个元素为止的最大值(在线跟踪的当前最大值);
- djd_jdj:到第jjj个元素为止的“安全指数和”(用于后续归一化的分母部分);
- yiy_iyi:第iii个元素的softmax输出(最终概率)。
逐行解释伪代码逻辑
-
初始化
– 初始最大值m0m_0m0通常设为负无穷(−∞(-\infty(−∞),确保第一个元素能成为初始最大值
– d0d_0d0是初始值,通常设为0(或根据第一个元素调整) -
第一个循环:在线跟踪最大值和安全指数和(第3-6行)
这部分是“在线归一化”的核心,逐元素增量计算,不需要提前知道所有输入:for j from 1 to V do: // 遍历每个输入元素m_j = max(m_{j-1}, x_j) // 更新当前最大值:取前序最大值和当前元素的较大者d_j = d_{j-1} × e^(m_{j-1} - m_j) + e^(x_j - m_j) // 更新安全指数和 end for– mj=max(mj−1,xj)m_j = \max(m_{j-1}, x_j)mj=max(mj−1,xj):
在线跟踪截至第jjj个元素的最大值。例如,若前序最大值是mj−1=5m_{j-1}=5mj−1=5,当前元素xj=3x_j=3xj=3,则mj=5m_j=5mj=5;若xj=7x_j=7xj=7,则mj=7m_j=7mj=7。
作用:为后续“安全指数”提供基准(减去最大值避免溢出)。– dj=dj−1×emj−1−mj+exj−mjd_j = d_{j-1} \times e^{m_{j-1} - m_j} + e^{x_j - m_j}dj=dj−1×emj−1−mj+exj−mj:
这是“安全化”和“在线增量计算”的关键公式,用于维护分母的总和(对应softmax分母的∑exk−max(x)\sum e^{x_k - \max(x)}∑exk−max(x))。
分两种情况理解:- 若mj=mj−1m_j = m_{j-1}mj=mj−1(最大值未更新):
emj−1−mj=e0=1e^{m_{j-1} - m_j} = e^0 = 1emj−1−mj=e0=1,则dj=dj−1+exj−mjd_j = d_{j-1} + e^{x_j - m_j}dj=dj−1+exj−mj,即直接累加当前元素的安全指数(exj−maxe^{x_j - \max}exj−max)。 - 若mj>mj−1m_j > m_{j-1}mj>mj−1(最大值更新):
前序的dj−1d_{j-1}dj−1是基于旧最大值mj−1m_{j-1}mj−1计算的,需要“校准”到新最大值mjm_jmj的基准下(因为指数项的参考最大值变了)。
– 校准逻辑:exk−mj−1×emj−1−mj=exk−mje^{x_k - m_{j-1}} \times e^{m_{j-1} - m_j} = e^{x_k - m_j}exk−mj−1×emj−1−mj=exk−mj(前序所有项的指数统一减去新最大值),因此前序总和dj−1d_{j-1}dj−1需乘以emj−1−mje^{m_{j-1} - m_j}emj−1−mj,再加上当前元素的安全指数exj−mje^{x_j - m_j}exj−mj。
- 若mj=mj−1m_j = m_{j-1}mj=mj−1(最大值未更新):
-
第二个循环:计算最终softmax输出(第7-9行)
for i from 1 to V do: // 遍历每个输入元素,计算其概率y_i = e^{x_i - m_V} / d_V // 安全softmax公式 end for– mVm_VmV是所有元素的最终最大值(遍历完所有元素后得到);
– dVd_VdV是所有元素的安全指数总和(∑k=1Vexk−mV\sum_{k=1}^V e^{x_k - m_V}∑k=1Vexk−mV);
– 因此yiy_iyi就是第iii个元素的softmax概率,满足:
yi=exi−max(x)∑k=1Vexk−max(x)y_i = \frac{e^{x_i - \max(x)}}{\sum_{k=1}^V e^{x_k - \max(x)}} yi=∑k=1Vexk−max(x)exi−max(x)
这正是“安全softmax”的公式(减去最大值避免指数溢出)。
核心优势总结
-
数值稳定性(safe):
所有指数项均为( e^{x_j - m_j} )(因( m_j \geq x_j ),指数输入≤0),确保( e^{\cdot} \leq 1 ),避免了标准softmax中( e^{x_j} )可能导致的溢出。 -
在线处理(online):
无需一次性加载所有输入元素,可逐元素增量计算(适用于流式数据、长序列或内存受限场景),通过动态更新最大值和校准指数和,实现实时归一化。 -
正确性:
最终结果与标准安全softmax完全一致,但计算过程更灵活,支持动态输入。

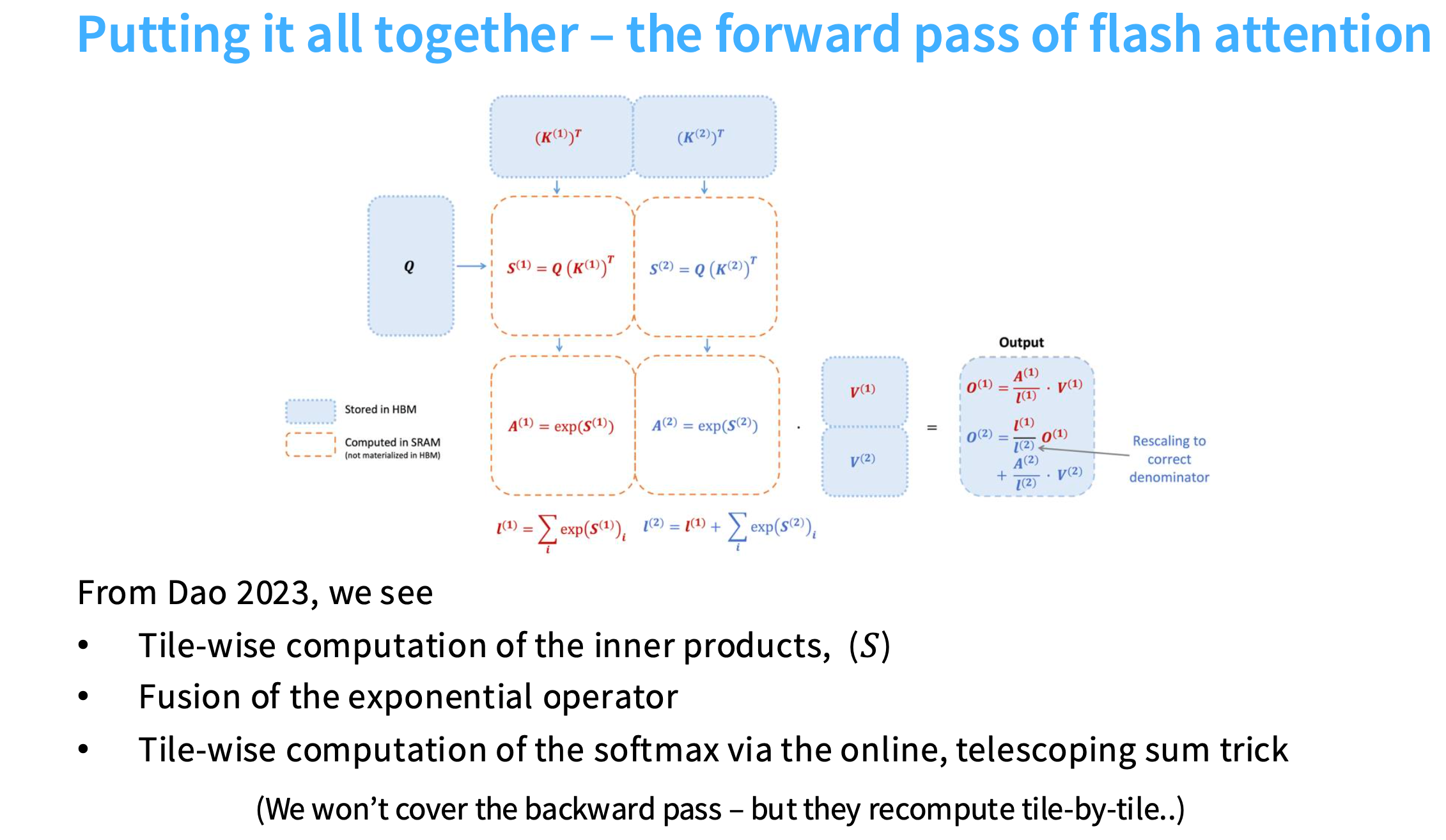
前向传播过程
首先进行QK的矩阵乘法,中间的黄色虚线小方块就是经过tiling后的小分块,那么如何计算softmax?
我将对这些指数化求和保持一个累计值(l(1)l^{(1)}l(1)),然后不断增量更新它并针对最大值进行修正(得到l(2)l^{(2)}l(2)),以此类推。
然后再乘以V对应的分块,就会得到softmax的输出