自动驾驶 HIL 测试:构建 “以假乱真” 的实时数据注入系统
01 引言
在端到端自动驾驶的研发竞赛中,算法的迭代速度远超物理世界的测试能力。单纯依赖路测不仅成本高昂、周期漫长,更无法穷尽决定系统安全性的关键边缘场景(Corner Cases)。
因此,硬件在环(HIL)仿真测试成为唯一的出路。然而,将仿真数据闭环注入域控制器流程中存在诸多技术难度,特别是高像素相机原始数据,如何无损、无延迟地将数据灌入对时序和信号要求极为苛刻的域控制器中成为了当前调试HiL系统的主要挑战!
针对这些问题,康谋也有一些思考、经验与看法,本文将与大家一起交流。下文将介绍高保真实时注入系统架构、核心技术、I2C 作用及实践挑战的相关经验!
02 系统架构概览
高保真实时仿真注入系统的核心目标,是将仿真环境中生成的传感器数据,以极低的延迟和与真实传感器别无二致的物理信号特性,注入到待测的设备(DUT)中。这套系统的典型架构由三个关键部分组成:仿真主机(Simulation Host)、数据注入设备(Injection Device)和待测设备(DUT, Device Under Test)。
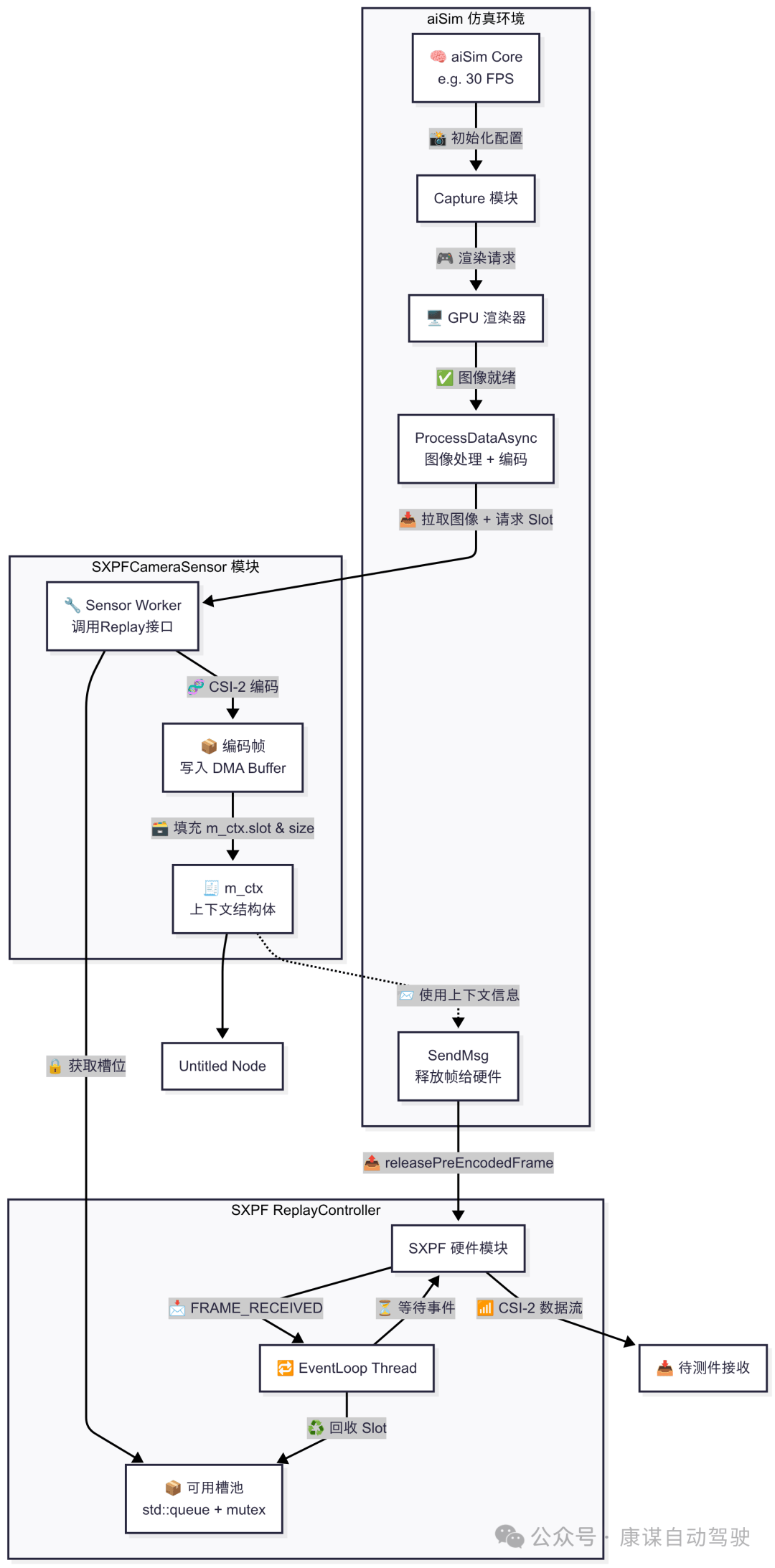
数据流的完整流程如下:
数据生成:仿真软件aiSim在仿真主机上根据预设场景生成相机的原始图像帧数据;
数据传输:这些原始数据通过网络被发送到数据注入设备;
数据处理与编码:注入设备上的应用程序(如camera_sensor.cpp中的逻辑)接收数据。为了实现最低延迟,数据被直接送入一块专用的硬件板卡(proFRAME);
DMA/RDMA传输:数据通过PCIe总线,利用直接内存访问(DMA)或远程直接内存访问(RDMA)技术,被高效地传输到注入板卡的内存或板载GPU内存中,此过程最大限度地减少了CPU的干预;
CSI-2/GMSL2封装:板卡上的FPGA或专用处理器(ASIC)将内存中的图像数据打包成CSI-2协议格式,并驱动GMSL2序列化器(Serializer)芯片将其转换为高速串行信号;
物理注入:GMSL2信号通过同轴电缆传输到DUT的GMSL2解串器(Deserializer),DUT的处理器(SoC)通过其CSI-2接口接收到图像数据,就像从一个真实的相机接收一样。
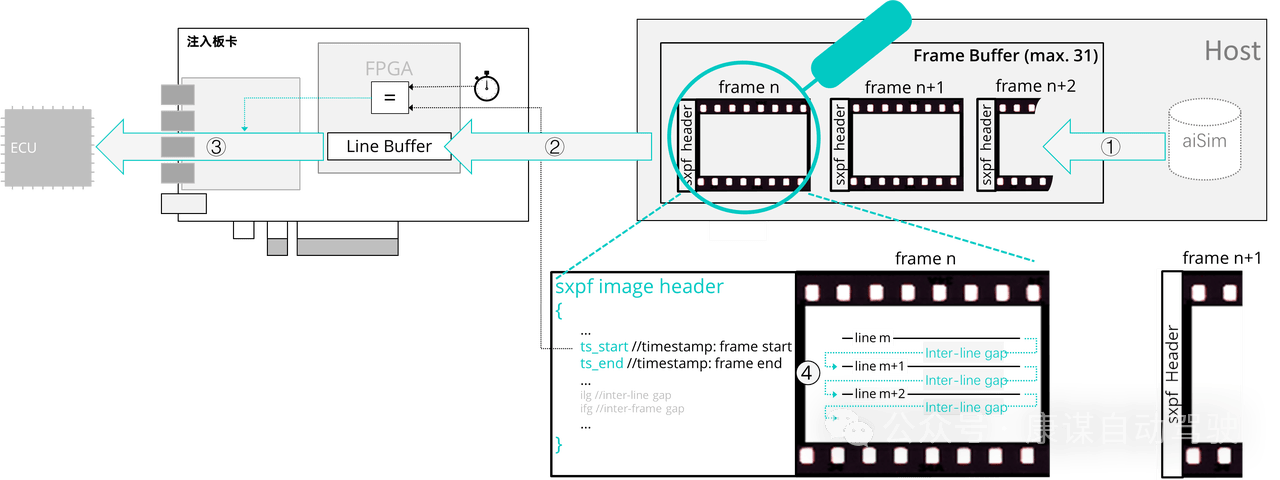
① 仿真主机aiSim高保真相机数据传输到帧缓冲区(DMA);
② 逐行传输到proFRAME硬件(PCIe);
③ 基于时间戳/行间隙的时钟周期数发送图像帧(CSI-2帧);
④ 基于行间隙定义图像帧行间时序。
03 技术深度解析
仿真源数据与准备
仿真注入的起点是仿真软件生成的源数据。在我们的案例中,仿真软件aiSim输出的是原始的相机图像帧(RAW12)。这些数据在注入前,必须经过精心的预处理,以确保DUT能够正确解析。
核心的预处理步骤是在Host端完成的。这个过程并非简单的格式转换,而是严格按照待测件的需求,将aiSim生成的裸数据(payload)封装成一个完整的、符合物理层规范的数据包。具体来说:
数据拷贝:将aiSim生成的图像数据src_image.m_data拷贝到一个临时的暂存缓冲区staging_buffer中;
CSI-2编码:调用核心编码函数csi2_single_encode,将暂存区中的裸数据打包成CSI-2格式。这一步会根据配置添加CSI-2的包头(Packet Header)、数据负载(Data Payload)、错误校验码(ECC)等;
proFRAME头部填充:在编码后的CSI-2数据包前,附加一个sxpf_image_header_t头部。这个头部包含了注入任务所需的关键元数据,例如图像的宽、高、每像素位数(bpp)、时间戳,以及两个至关重要的时序参数:ilg (Image Line Gap) 和 ifg (Image Frame Gap);
- ilg:行间隙,定义了上一行图像数据传输完成到下一行开始之间的精确时间间隔。
- ifg:帧间隙,定义了上一帧图像数据传输完成到下一帧开始之间的精确时间间隔。
这两个参数直接控制了数据在GMSL2链路上的“微观时序”。如果设置不当,即使数据内容完全正确,DUT的解串器也可能因为不符合预期的时序而无法锁定信号或正确接收数据,导致回放帧率异常波动甚至链路失败。
零拷贝与低延迟的基石:DMA与RDMA
要实现“实时”注入,数据在注入设备内部的搬运效率至关重要。DMA和RDMA正是解决此问题的关键。
- DMA (Direct Memory Access):DMA是现代计算机系统的基本特性。它允许外设(如proFRAME板卡)在没有CPU干预的情况下,直接与主内存进行数据读写。在默认的注入流程中,proFRAME从相机或网络获取数据后,通过PCIe总线直接将数据写入由CPU预先分配好的内存缓冲区(Buffer)。这避免了CPU逐字节拷贝数据的开销,显著提升了吞吐量。通常,基于DMA的PCIe Gen3 x8链路,可以将延迟控制在1毫秒级别。
- NVIDIA GPUDirect RDMA:GPUDirect RDMA允许将仿真的图像数据直接从NVIDIA GPU发送到proFrame中,完全无需占用主系统内存(RAM)的带宽,也无需CPU进行任何数据中转。整个数据链路变为:aiSim -> GPU显存 -> PCIe -> proFRAME 。这消除了内存与显存之间的拷贝开销,也为CPU节约了宝贵的内存带宽资源,是构建微秒级延迟注入系统的核心技术。
物理链路注入:GMSL2与CSI-2协议栈
GMSL2 (Gigabit Multimedia Serial Link 2):作为物理层载体,是专为汽车应用设计的高速串行接口。在仿真注入中,它的角色就是将编码好的数字图像信号,转换为能在物理线缆上传输的电信号。
CSI-2 (Camera Serial Interface 2):CSI-2是在GMSL2之上传输的数据协议。它定义了数据如何被组织和打包。
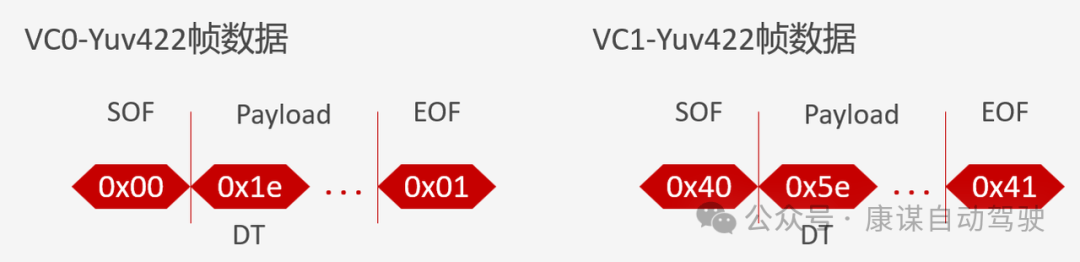
数据包结构
一个CSI-2数据包通常由帧起始符(SOF - Start of Frame)、包头(Packet Header)、数据负载(Payload)和帧结束符(EOF - End of Frame)组成。如资料所示,SOF和EOF的值可以用来区分不同的虚拟通道(Virtual Channel, VC)。例如,VC0的SOF/EOF值为0x00/0x01,而VC1则为0x40/0x41。
实现关键
整个注入链路的最后一公里,就是将内存中(通过DMA/RDMA获取)准备好的、包含sxpf_image_header_t和CSI-2编码后负载的完整数据帧,交给proFRAME板卡。板卡上的逻辑会解析这些数据,驱动GMSL2序列化器芯片,严格按照ilg和ifg定义的时序,将CSI-2数据包序列化后发送出去,即通过sxpf_release_frame()函数将准备好的数据缓冲区slot句柄和数据大小交给硬件,硬件随后便接管了发送任务。
04 I2C调试与验证
在GMSL2链路中,I2C是配置和调试不可或缺的生命线。它负责在主机(proFRAME)和远端设备(DUT)的SerDes(Serializer/Deserializer)芯片之间建立一条双向控制通道。
调试实践
调试GMSL2链路问题时,I2C是最直接的突破口。proFRAME提供的初始化序列文件(.ini文件)就是I2C调试实践的绝佳范例。
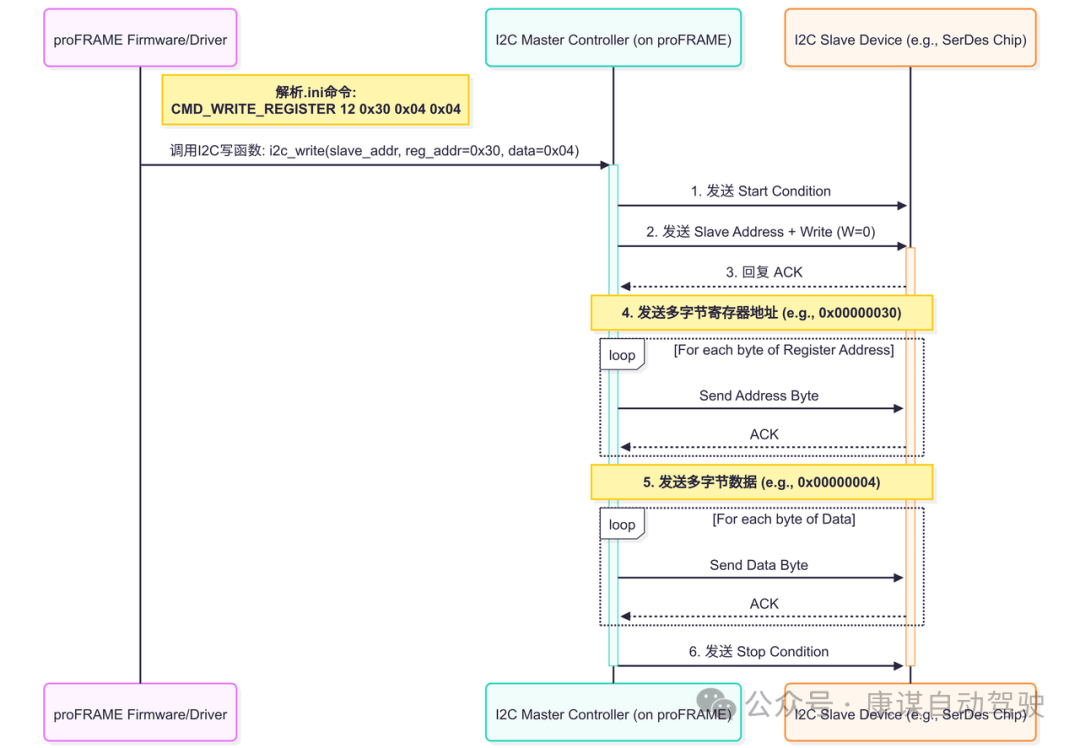
上述序列图直观地展示了.ini文件中的一条高级命令到底层I2C总线时序的完整转换过程。
解析与调用:proFRAME的固件或驱动作为控制大脑,首先解析.ini文件中的CMD_WRITE_REGISTER命令,并提取出目标从设备地址、寄存器地址和要写入的数据;
启动通信:固件调用板载的I2C主控制器,发起一次写操作。控制器首先发送“起始信号”,并在总线上广播目标从设备的地址及写操作位;
地址与数据传输:在收到从设备的“应答信号”(ACK)确认设备存在后,主控制器严格按照顺序,逐字节地发送多字节的寄存器地址和数据。每一次字节传输完成后,都会等待从设备的ACK,以确保数据被成功接收;
结束通信:所有数据发送完毕后,主控制器发送“停止信号”,释放I2C总线,完成本次操作。
05 实践中的挑战与考量
在搭建和运行一套高保真实时注入系统的过程中,会遇到诸多工程挑战
时钟同步与时序精准:严格来说,仿真主机、注入设备和DUT工作在各自的时钟域下。虽然物理层时钟可以由GMSL2链路恢复,但数据流的宏观时序必须严格受控。正如前述,ilg和ifg参数的精确计算和配置至关重要。需要通过工具分析目标相机真实的数据流特性,或通过专用计算表格,调整这些参数,使得注入设备输出的数据速率(Data Lane Rate)与DUT的期望值精确匹配,从而确保时序上的“保真”
带宽瓶颈分析:整条链路的有效带宽受限于最慢的一环。
- 仿真侧:仿真主机的渲染能力和网络出口带宽;
- 注入设备:PCIe总线带宽(例如,x8 Gen3理论值为~7.8 GB/s)、DMA/RDMA的实际效率、CPU到GPU的拷贝速度(在使用DMA时);
- 物理链路:GMSL2本身的带宽上限。
在设计方案时,必须对每个环节的带宽进行评估,确保没有明显的瓶颈。例如,即使GMSL2带宽足够,但如果采用DMA方式且CPU到GPU的拷贝速度跟不上,同样会造成帧率下降和延迟增加。
系统稳定性:硬件在环测试通常需要长时间(数小时甚至数天)连续运行。
- 内存管理:必须杜绝内存泄漏。在上层实现中,通过一个固定大小的缓冲区池(m_availableSlots队列)和严谨的申请(acquirePlaybackSlot)释放(releasePreEncodedFrame)逻辑来循环使用内存。当硬件处理完一帧数据后,会通过事件(SXPF_EVENT_FRAME_RECEIVED)通知上层软件,软件再将被释放的缓冲区重新加入可用队列。这种机制保证了内存使用量的恒定。
- CPU/GPU资源:要避免CPU的忙等待。在acquirePlaybackSlot的实现中,当没有可用缓冲区时,线程会进行短暂休眠(sleep_for),而不是持续空转,这降低了CPU占用率。
06 总结
一套成功的高保真实时仿真注入系统,本质上是一个解决了计算、传输和物理接口三大领域深度集成问题的系统工程。
通过将DMA/RDMA的零拷贝能力、GMSL2 的高带宽物理层以及 I2C 的精确控制能力有机结合,可以有效攻克传统HIL测试中存在的带宽、延迟和保真度瓶颈,从而在实验室环境中构建起连接虚拟仿真与物理ECU的坚实桥梁。这套技术栈,是加速自动驾驶算法迭代和保障其功能安全的关键赋能技术。