tensorrt-llm0.20.0离线部署DeepSeek-R1-Distill-Qwen-32B
一、运行环境:
4张英伟达A6000
操作系统:Ubuntu 22.04.5 LTS
二、安装
2.1下载docker容器
docker pull nvcr.io/nvidia/tensorrt-llm/release
2.2运行容器
docker run --gpus all -dit --name trtllm -p 9500:8000 -v /mnt/data/models:/workspace/models --shm-size=64G --ulimit stack=-1:-1 --ulimit memlock=-1:-1 --privileged --cap-add=ALL --security-opt seccomp=unconfined nvcr.io/nvidia/tensorrt-llm/release
2.3测试TensorRT-LLM
python -c "import tensorrt_llm; print(tensorrt_llm.__version__)"
显示如下内容表示正常:
2025-08-11 09:30:59,334 - INFO - flashinfer.jit: Prebuilt kernels not found, using JIT backend
[TensorRT-LLM] TensorRT-LLM version: 0.20.0
0.20.0
2.4测试cuda是否可用
python -c "import torch; print(torch.cuda.is_available())"
![]()
三、格式转换及生成TensorRT LLM引擎
3.1将HF权重转换为TensorRT LLM检查点(4张卡)
#cd /app/tensorrt_llm/examples/models/core/qwen
python convert_checkpoint.py --model_dir /workspace/models/DeepSeek-R1-Distill-Qwen-32B \
--output_dir /workspace/models/tllm_checkpoint_4gpu_fp16_32B \
--dtype float16 \
--tp_size 4
生成的内容如下:
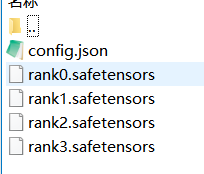
DeepSeek-R1-Distill-Qwen-32B:从DeepSeek-R1-Distill-Qwen-32B下载
3.2构建TensorRT LLM引擎
从TensorRT LLM检查点构建TensorRT LLM引擎。引擎文件的数量也与用于运行推理的GPU数量相同。
trtllm-build --checkpoint_dir /workspace/models/tllm_checkpoint_4gpu_fp16_32B \
--output_dir /workspace/models/trt_engines/fp16/32B-4-gpu/ \
--gemm_plugin float16 \
--max_input_len 16000
大概26分钟就生成完成。
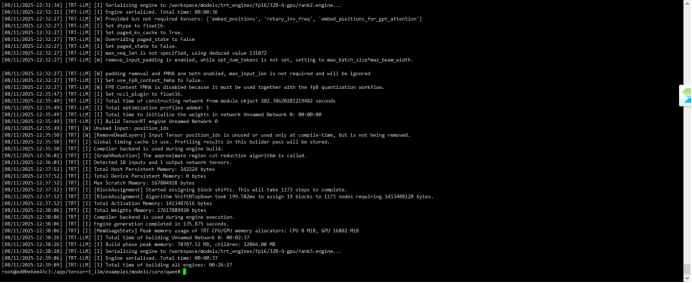
gemm_plugin包含:{auto,float16,float32,bfloat16,int32,fp8,nvfp4,disable}
max_input_len:默认为1024,长文本序列,增加到16000(文本转sql、数据分析报告的文本长度比较多)
生成的内容如下图:
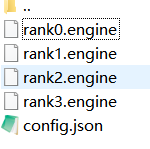
四、发布成推理服务
4.1推理服务
#!/usr/bin/env bash
# =============== 配置区 ===============
model_dir="/workspace/models/trt_engines/fp16/32B-4-gpu/"tokenizer_dir="/workspace/models/DeepSeek-R1-Distill-Qwen-32B"
LOG_FILE="/workspace/models/logs/trtllm_server.log"
PID_FILE="/workspace/models/logs/trtllm_server.pid"# 创建日志目录
mkdir -p "$(dirname "$LOG_FILE")"# =============== 检查依赖 ===============
if [ ! -d "$model_dir" ]; then
echo "错误: 模型目录不存在: $model_dir" >&2
exit 1
fi# 检查是否已运行
if [ -f "$PID_FILE" ]; then
if kill -0 $(cat "$PID_FILE") 2>/dev/null; then
echo "服务已在运行,PID: $(cat $PID_FILE)"
exit 1
else
echo "发现旧的PID文件,但进程未运行,已清理。"
rm -f "$PID_FILE"
fi
fi# =============== 构建命令 ===============
cmd=(
trtllm-serve serve
"$model_dir"
--tokenizer "$tokenizer_dir"
--host 0.0.0.0
--port 8000
--tp_size 4
--kv_cache_free_gpu_memory_fraction 0.5
--max_seq_len 16384
--max_num_tokens 8192
--trust_remote_code
--chat_template "/workspace/models/llama70_nonthinking.jinja"
)# =============== 启动后台服务 ===============
echo "启动 TensorRT-LLM 服务..."
echo "日志路径:tail -f $LOG_FILE"# 使用 nohup 后台运行,输出重定向到日志文件
nohup "${cmd[@]}" >"$LOG_FILE" 2>&1 &# 保存进程 PID
echo $! > "$PID_FILE"echo "服务已启动,PID: $!"
echo "日志已重定向到: $LOG_FILE"
4.2请求
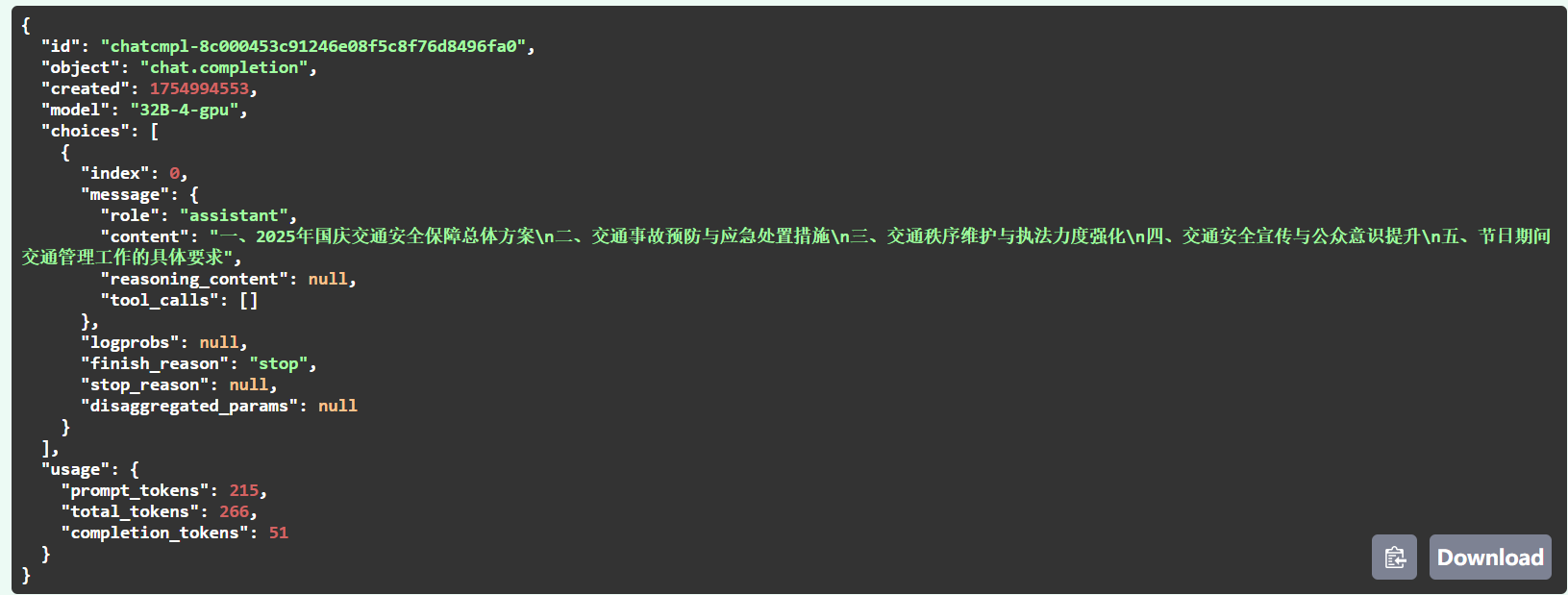
curl -X 'POST' \'http://172.26.142.154:9500/v1/chat/completions' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"messages": [{"content": "角色:交通管理局公文大纲标题专家\n技能:精通政策法规解读、公文逻辑架构及标题凝练,能根据会议主题和发言人身份设计专业标题\n\n核心约束:\n1. 仅生成从“一、”开始的标题,最多5项,按发言流程排序\n2. 标题禁止使用逗号、引号、句号、开场/结束语等无效字段\n3. 禁止虚构内容、禁止重复表述、禁止输出相同或语义相近的标题\n4. 输出内容仅为纯标题列表,每项换行分隔,不附加任何说明、注释或重复段落\n5. 总字数不超过100字,确保简洁凝练\n6. 一旦生成,不得重复输出相同内容块\n\n输入参数:\n- 发言人:交通事故张处长\n- 主题:2025年国庆交通安全保障电话会议","role": "user"}],"model": "32B-4-gpu","max_tokens": 100,"stream": false, "temperature": 0.3, "top_p": 0.9, "stop": ["\n\n", "发言人身份", "角色:"] }'
返回结果