HTML应用指南:利用GET请求获取全国vivo体验店门店位置信息
vivo 体验店作为深受消费者喜爱的全球性直营零售品牌,自进入中国市场以来,始终致力于为顾客提供高品质产品体验与卓越的客户服务。凭借简洁现代的设计理念与专业的客户服务支持,vivo 体验店不仅是产品展示与销售的场所,更成为用户交流、学习与获取灵感的重要空间。随着中国消费市场的持续升级,门店位置信息的便捷获取成为提升消费者服务体验的重要一环。vivo 不断扩展其零售网络,目前已覆盖北京、上海、广州、深圳等多个一线及主要二线城市,逐步建立起完善的线下服务布局。
本文将探讨如何通过发送 GET 请求,从 vivo 中国官方网站获取 vivo 体验店的分布信息,并展示使用 Python 中 requests 库发起请求的方法,从而提取各城市的详细门店地址、营业时间等关键数据。通过对 API 返回的 JSON 数据进行解析,最终可整理出结构化的零售店列表信息。
这些数据不仅有助于全面了解 vivo 体验店在全国范围内的市场覆盖趋势与区域布局特征,还能为消费者提供便捷的门店查询功能,进一步提升购机、维修与咨询服务的效率。结合不同城市的门店密度、选址特点(如核心商圈、大型购物中心)以及周边消费环境进行分析,还可以洞察各地消费者在产品偏好与服务需求上的差异。
这对于 vivo 未来在中国市场的零售策略优化、新店选址评估以及本地化服务升级都具有重要的参考价值。通过对门店数据的系统收集与深入分析,不仅能够支持品牌的科学决策,也有助于推动客户体验的持续提升,从而更好地满足中国消费者日益多样化和个性化的需求。
vivo体验店官方地址:体验店
我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
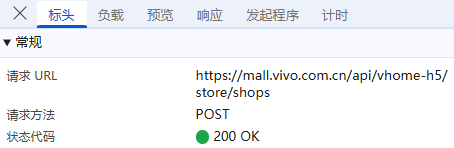
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到行政区、城市名称,当前页数,还是明文,没有进行加密;
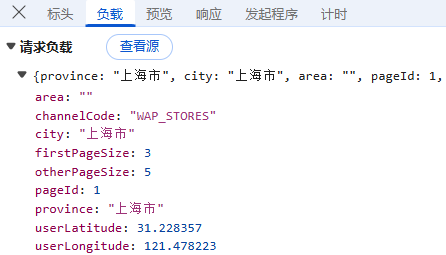
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;

接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 我们通过改变行政区名称和page分页,来遍历全国门店数据;
- 地理编码转换,再通过coord-convert库实现GCJ-02转WGS84;
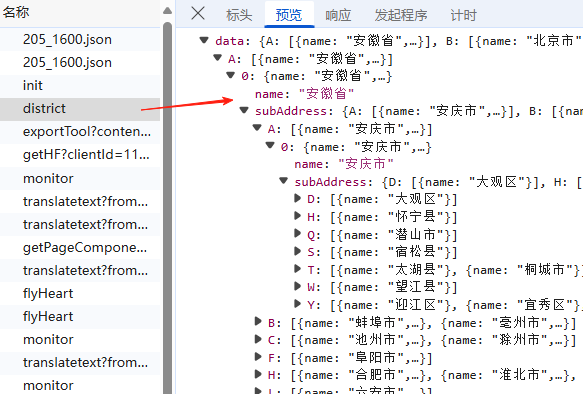
第一步:我们先找到对应数据存储位置,获取所有门店列表,经过测试,这里可以选择行政区进行筛选,再选择"全部",每个区域会生成一个html,我们通过修改行政区名称来进行数据获取,为了方便我们可以建立一个包含市级行政区名称的字典,通过遍历行政区名称来查询全国数据;

我们通过查询不同区域,发现只有行政区名称和城市名称发生了变化,那么我们挨个替换成其他的行政区即可遍历全国的门店;

那么,我们只要获取行政区的列表里面所有行政区对应关系数据并形成行政区名称字典进行遍历即可,如果找不到数据储存位置,就随便在"网络"里随便Ctrl +F 一个二级行政区名称,然后把数据下载成csv;
完整代码#运行环境 Python 3.11
import requests
import csv# 请求数据
url = "https://mall.vivo.com.cn/api/vhome-h5/store/district"
headers = {"User-Agent": "Mozilla/5.0", "Referer": "https://mall.vivo.com.cn"}res = requests.get(url, headers=headers).json()
data = res["data"]
results = []# 提取:省 → 市 → 区/县
for letter_group in data.values():for province in letter_group:pname = province["name"]for city_group in province.get("subAddress", {}).values():for city in city_group:cname = city["name"]for area_group in city.get("subAddress", {}).values():for area in area_group:results.append([pname, cname, area["name"]])# 保存
with open("vivo_districts.csv", "w", encoding="utf-8-sig", newline="") as f:writer = csv.writer(f)writer.writerow(["省", "市", "区/县"])writer.writerows(results)print(f"完成!共提取 {len(results)} 条数据")数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:省、市、区/县,这里我们需要进一步处理,删除区/县标签,并对数据去重保存即可;
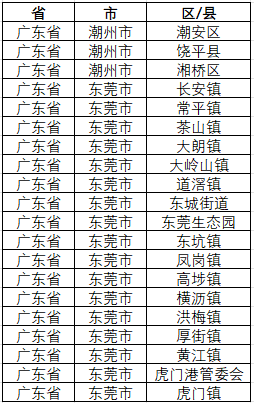
接下来,我们根据负载可以发现,一页是包含五条数据,但是根据响应的内容,并不能判断数据一共有多少页,于是就想到了在一个循环中递增 pageId 并检查每页返回的数据。如果某页没有返回任何门店数据(即 data.list 为空),如果遍历到那页为没有返回任何门店数据,则可以认为已到达最后一页,停止请求;
第二步:利用GET请求获取所有门店列表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
import time
from collections import defaultdict# ================= 配置 =================
url = "https://mall.vivo.com.cn/api/vhome-h5/store/shops"
headers = {"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1","Content-Type": "application/json","Referer": "https://mall.vivo.com.cn/page/store-list.html","Origin": "https://mall.vivo.com.cn",
}# 存储所有门店数据
all_stores = []
# 用于去重(防止重复门店)
seen_stores = set()# 读取 vivo_districts.csv 获取所有省市
def load_cities(csv_file="vivo_districts.csv"):cities = []with open(csv_file, mode='r', encoding='utf-8-sig') as f:reader = csv.DictReader(f)for row in reader:province = row["省"].strip()city = row["市"].strip()if province and city:# 去重if (province, city) not in [(c[0], c[1]) for c in cities]:cities.append((province, city))print(f"共加载 {len(cities)} 个城市。")return cities# 获取某个城市的所有门店(支持分页)
def fetch_stores_in_city(province, city):page_id = 1city_stores = []while True:payload = {"channelCode": "WAP_STORES","province": province,"city": city,"area": "","firstPageSize": 3,"otherPageSize": 5,"pageId": page_id,"userLongitude": 121.478223, # 可以随机或使用城市中心坐标(可选优化)"userLatitude": 31.228357}try:response = requests.post(url, headers=headers, json=payload, timeout=10)if response.status_code != 200:print(f"[{province}-{city}] HTTP {response.status_code} - 跳过该城市")breakdata = response.json()if data.get("code") != 0:print(f"[{province}-{city}] API错误: {data.get('message')}")breakshop_list = data.get("data", {}).get("list", [])if not shop_list:print(f"[{province}-{city}] 第 {page_id} 页无数据,共 {len(city_stores)} 家门店。")breakprint(f"[{province}-{city}] 第 {page_id} 页获取 {len(shop_list)} 家门店")for shop in shop_list:store_code = shop.get("storeCode")if store_code and store_code in seen_stores:continue # 去重seen_stores.add(store_code)city_stores.append({"省份": province,"城市": city,"门店名称": shop.get("externalName"),"门店编码": store_code,"地址": shop.get("address"),"区/县": shop.get("area"),"经度": shop.get("longitude"),"纬度": shop.get("latitude"),"距离(米)": shop.get("distance"),"联系电话": shop.get("mobile"),"营业时间": shop.get("businessHours"),"服务标签": ", ".join(shop.get("serviceTags", []))})page_id += 1time.sleep(0.5) # 控制请求频率,避免被限流except Exception as e:print(f"[{province}-{city}] 请求出错: {e}")breakreturn city_stores# ================= 主程序 =================
if __name__ == "__main__":cities = load_cities("vivo_districts.csv")# 开始遍历每个城市for i, (province, city) in enumerate(cities, start=1):print(f"\n正在处理 [{i}/{len(cities)}] {province} - {city}")stores = fetch_stores_in_city(province, city)all_stores.extend(stores)# 保存总结果output_file = "vivo_stores.csv"if all_stores:with open(output_file, mode='w', newline='', encoding='utf-8-sig') as f:writer = csv.DictWriter(f, fieldnames=all_stores[0].keys())writer.writeheader()writer.writerows(all_stores)print(f"\n全国共获取 {len(all_stores)} 家 vivo 体验店,已保存至 '{output_file}'")else:print("未获取到任何门店数据。")
获取数据标签如下,省份、城市、地址、区/县、经度&纬度、联系电话、营业时间、服务标签,其他一些非关键标签,这里省略;
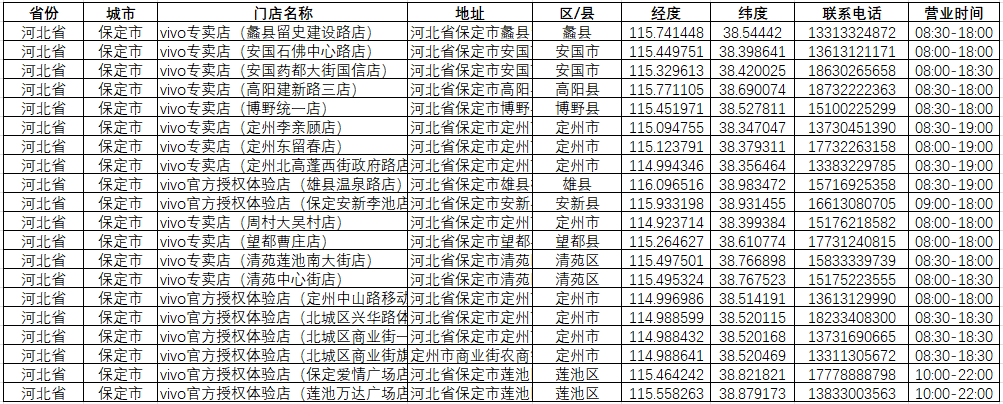
第三步:坐标系转换,由于vivo 体验店门店数据使用的是高德坐标系(GCJ02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的服务网点坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
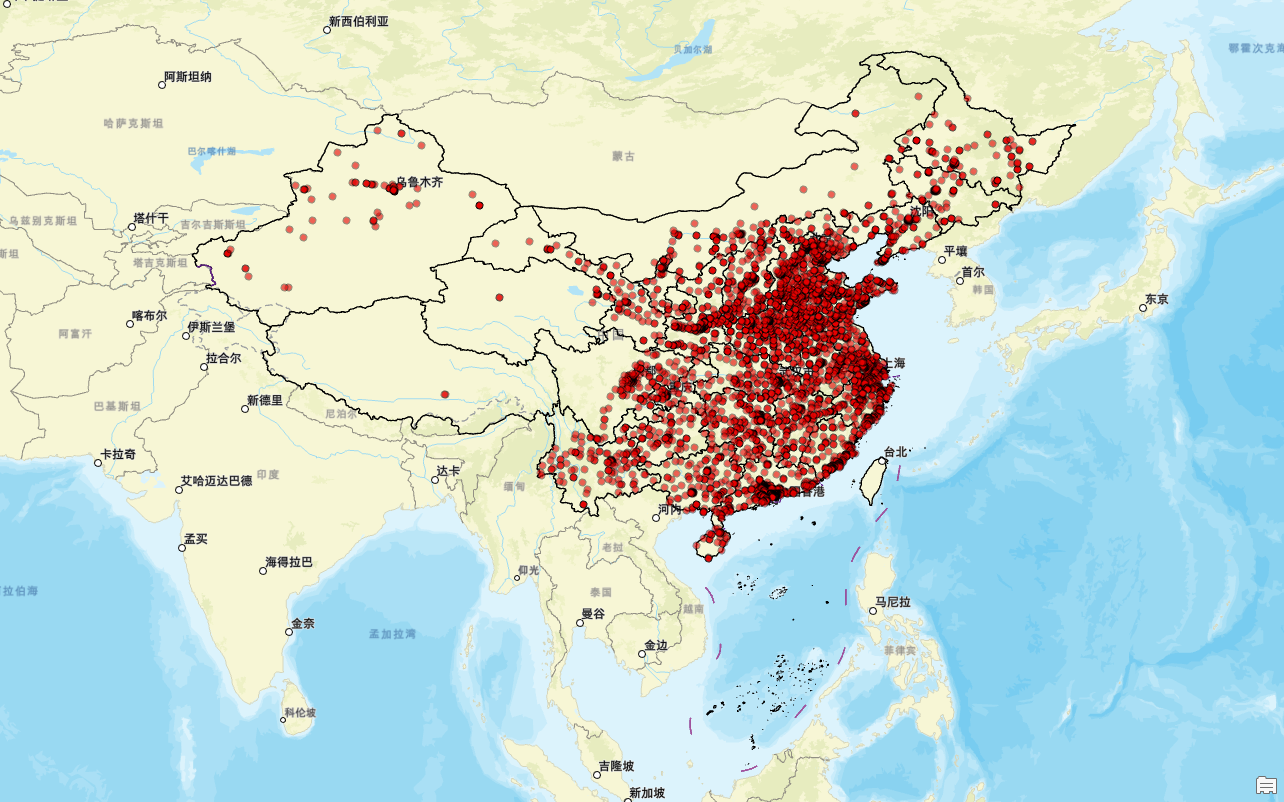
接下来,我们进行看图说话:
东部和部地区是vivo体验店高度密集的区域,尤其是像广东、江苏、浙江、山东这样的沿海省份以及南方省份如福建、广西等地。这反映了这些经济发达、人口稠密地区的市场潜力巨大,居民消费能力强,对高品质电子产品的需求旺盛。相比之下,西部和北部地区的体验店数量较少,分布较为稀疏,这可能与这些地区的经济发展水平和人口密度较低有关。
从城市等级的角度看,一线城市如北京、上海、广州和深圳实现了vivo体验店的全覆盖,显示出品牌在高端市场的重视和布局。二线城市如杭州、南京、成都、西安等也拥有众多的vivo体验店,表明其在这些重要城市的市场拓展非常成功。此外,在三线及以下城市,vivo体验店的数量也在逐步增加,显示了品牌向更广泛的市场渗透的努力。
vivo体验店的分布与当地的经济发展水平密切相关。特别是在经济发达的地区,例如长三角、珠三角、京津冀等经济圈,由于居民消费能力较强,对高端电子产品的需求较大,因此vivo体验店分布密集。而在一些经济欠发达地区,体验店的数量相对较少,这反映了市场需求的不同。
同时,人口密度也是影响vivo体验店分布的一个重要因素。在人口密集区,特别是东南沿海的城市群中,体验店的分布极为密集,便于满足大量消费者的需求。而在人口稀疏的地区,体验店的数量则相对较少。
最后,交通枢纽城市往往是vivo体验店的重点布局对象,如北京、上海、广州、深圳等城市,因为这些地方交通便利,有利于产品的销售和顾客的体验。相反,在一些偏远地区,由于交通不便,体验店的数量就比较少,这也反映出物流配送和交通条件对店铺分布的影响。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。