GCN: 图卷积网络,概念以及代码实现
GCN: 图卷积网络
1. GCN介绍
好的,这是一份关于 GCN 简单明了的介绍。
1.1 GCN (图卷积网络) 是什么?
它是一种专门处理图结构数据(如社交网络、分子结构)的神经网络。
它的核心思想可以用一句话概括:“近朱者赤,近墨者黑”。
1.2 它是如何工作的?
GCN 的每一层都在做一件非常简单的事:
对于图中的每一个节点,把它自己和它所有邻居的信息“混合”一下,来更新自己。
举个例子:
想象一个社交网络,GCN 想更新你的个人资料(特征向量):
- 收集信息:GCN 找到你和你所有朋友的个人资料。
- 混合信息:它把这些资料(包括你自己的)做个“加权平均”,形成一份对你更全面的“新资料”。
就这样,经过一层 GCN,每个节点的新特征都融合了其邻居的特征。
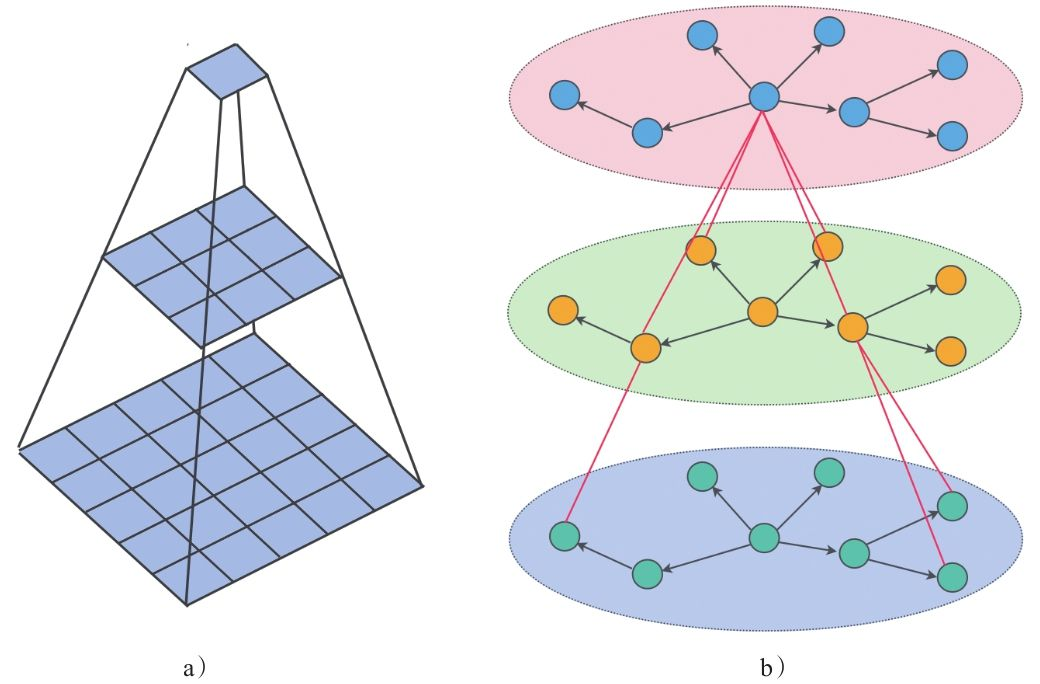
1.3 为什么要堆叠多层?
- 一层 GCN:节点只能看到直接相连的邻居。
- 两层 GCN:信息可以传播到**“邻居的邻居”**。因为你的邻居在第一层已经融合了它邻居的信息。
- 多层 GCN:节点能感知到网络中越来越远的信息,获得更全局的视野。
1.4 总结要点:
- 目标:为图中的每个节点学习一个包含结构信息的强大特征向量。
- 核心操作:聚合邻居信息来更新节点自身。
- 能力:通过堆叠层数,可以捕捉从局部到全局的图结构特征。
- 用途:常用于节点分类(预测用户兴趣)、链接预测(推荐好友)等任务。
2. 代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid# 这段代码的核心任务是节点分类 (Node Classification)。
# 其中的nn.ModuleList: 一个特殊的列表,你放进去的层能被 PyTorch 自动识别,它们的参数(权重)才能被训练。
class GCN(nn.Module):def __init__(self,# 不再需要传入图对象 gin_channels, # PyG 惯例: in_channelshidden_channels, # PyG 惯例: hidden_channelsout_channels, # PyG 惯例: out_channelsnum_layers, # DGL 中叫 n_layersactivation,dropout):super().__init__()# 1. 创建一个列表来存放我们的网络层self.layers = nn.ModuleList()# 2. 定义输入层# GCNConv(输入维度, 输出维度)# 它会把每个节点最初的特征向量,转换成一个更短、更精华的“隐藏”向量self.layers.append(GCNConv(in_channels, hidden_channels))# 3. 定义中间的隐藏层 (如果 num_layers > 1)for _ in range(num_layers - 1):self.layers.append(GCNConv(hidden_channels, hidden_channels))# 4. 定义输出层# 它会把最终的隐藏向量,转换成对应每个类别的“得分” (logits)self.layers.append(GCNConv(hidden_channels, out_channels))# 5. 保存激活函数和 dropout 层self.activation = activationself.dropout = nn.Dropout(p=dropout)def forward(self, x, edge_index):h = x # h 代表每个节点的特征向量,初始就是原始特征 xfor i, layer in enumerate(self.layers):# 在进入非第一层之前,先做 dropoutif i != 0:h = self.dropout(h)# 核心步骤:调用 GCNConv 层# 把当前的特征 h 和图的结构 edge_index 传进去# GCNConv 在内部完成了“邻居信息汇总与自身更新”h = layer(h, edge_index)# 在非最后一层之后,使用激活函数# 作用是增加非线性,让模型能学习更复杂的关系if i < len(self.layers) - 1:h = self.activation(h)return h# 2. 评估函数 (evaluate) 的修改
def evaluate(model, data, mask):model.eval()with torch.no_grad():logits = model(data.x, data.edge_index) # 得到所有节点的得分logits = logits[mask] # 只选择我们关心的节点 (比如测试集节点)labels = data.y[mask] # 获取这些节点的真实标签,mask: 一个布尔类型的张量([True, False, True, ...]),用来精确地挑选出训练集、验证集或测试集的节点。_, indices = torch.max(logits, dim=1) # 找到每个节点得分最高的类别correct = torch.sum(indices == labels) # 计算预测正确的数量return correct.item() * 1.0 / len(labels) # 返回准确率# 3. 训练函数 (train) 的修改
def train(n_epochs=100, lr=1e-2, weight_decay=5e-4, n_hidden=16, n_layers=1, activation=F.relu, dropout=0.5):# 1. 准备工作device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')dataset = Planetoid(root='data/Cora', name='Cora')data = dataset[0].to(device) # 获取图数据对象并送到设备# 2. 获取图的基本信息in_channels = dataset.num_node_featuresout_channels = dataset.num_classes# 3. 实例化模型、损失函数和优化器model = GCN(in_channels=in_channels,hidden_channels=n_hidden,out_channels=out_channels,num_layers=n_layers,activation=activation,dropout=dropout).to(device)loss_fcn = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(),lr=lr,weight_decay=weight_decay)# 4. 开始训练循环for epoch in range(n_epochs):model.train()# 前向传播:计算模型对所有节点的预测得分logits = model(data.x, data.edge_index)# 计算损失:只用训练集节点来计算!# 比较模型在训练节点上的预测得分,和它们的真实标签有多大差距loss = loss_fcn(logits[data.train_mask], data.y[data.train_mask])# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 打印当前周期的损失和在验证集上的准确率val_acc = evaluate(model, data, data.val_mask)print(f"Epoch {epoch:03d} | Loss: {loss.item():.4f} | Val Accuracy: {val_acc:.4f}")print()test_acc = evaluate(model, data, data.test_mask)print(f"Test Accuracy: {test_acc:.2%}")if __name__ == '__main__':train()
3.对于代码的解释
3.1 最终目标:它在做什么?
这段代码的核心任务是节点分类 (Node Classification)。
想象一下你有一个社交网络,网络里有些人你已经知道他们的兴趣爱好(比如“体育迷”、“电影迷”),但大部分人的兴趣是未知的。你想通过他们之间的好友关系,来预测那些未知兴趣的人最可能属于哪个兴趣小组。
这个代码做的就是类似的事情,只不过用的是一个叫 Cora 的学术论文引用网络:
- 节点 (Node):一篇学术论文。
- 边 (Edge):论文A引用了论文B,那么A和B之间就有一条边。
- 特征 (Feature):每篇论文都有一串数字(一个向量)来表示其内容,比如论文中某些关键词是否出现。
- 标签 (Label):每篇论文被分到了一个类别(比如“神经网络”、“强化学习”等)。
代码的目标就是: 训练一个 GCN 模型,只看一小部分论文的标签(训练集),去预测网络里其他所有论文的类别(验证集和测试集)。
3.2 GCN 的核心思想:邻居决定你(“近朱者赤,近墨者黑”)
GCN 的工作原理非常直观,就像一句老话:“物以类聚,人以群分”。一个节点的特性,很大程度上受其邻居的影响。
GCN 的每一层都在做一件事:
对于每个节点,去看一眼它所有直接相连的邻居,把邻居们的信息(特征)“汇总”起来,再结合自己原有的信息,形成一个“新”的信息表示。
- 一层 GCN:一个节点能了解到它1跳邻居的信息。
- 两层 GCN:第一层结束后,每个节点已经融合了1跳邻居的信息。在第二层,它再去汇总“新”邻居的信息,这相当于间接获取了2跳邻居(邻居的邻居)的信息。
通过堆叠多层,一个节点就能感知到网络中越来越远的节点,从而获得更全局的视野。
3.3 代码逐段详解
现在,我们带着“信息汇总”这个思想来看代码。
3.3.1. 模型定义 (class GCN)
这是 GCN 模型的“设计蓝图”。
class GCN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channels, num_layers, activation, dropout):super().__init__()# 1. 创建一个列表来存放我们的网络层self.layers = nn.ModuleList()# 2. 定义输入层# GCNConv(输入维度, 输出维度)# 它会把每个节点最初的特征向量,转换成一个更短、更精华的“隐藏”向量self.layers.append(GCNConv(in_channels, hidden_channels))# 3. 定义中间的隐藏层 (如果 num_layers > 1)for _ in range(num_layers - 1):self.layers.append(GCNConv(hidden_channels, hidden_channels))# 4. 定义输出层# 它会把最终的隐藏向量,转换成对应每个类别的“得分” (logits)self.layers.append(GCNConv(hidden_channels, out_channels))# 5. 保存激活函数和 dropout 层self.activation = activationself.dropout = nn.Dropout(p=dropout)
__init__: 构造函数,负责“搭建”模型。nn.ModuleList: 一个特殊的列表,你放进去的层能被 PyTorch 自动识别,它们的参数(权重)才能被训练。GCNConv: 这是 PyG 库提供的核心“积木”。GCNConv(A, B)的意思是,它能接收一个维度为A的特征向量,通过邻居信息汇总和线性变换,输出一个维度为B的新向量。- 流程:
- 输入层:
(in_channels, hidden_channels)接收原始特征,压缩成隐藏特征。Cora 数据集里,in_channels是 1433。 - 隐藏层:
(hidden_channels, hidden_channels)在隐藏维度上继续“提炼”信息。 - 输出层:
(hidden_channels, out_channels)将最终提炼的特征,映射到每个类别的得分上。Cora 有 7 个类别,所以out_channels是 7。
- 输入层:
dropout: 一种防止模型“死记硬背”(过拟合)的技术。在训练时,它会随机地“丢弃”一些神经元的输出,强迫模型学习到更鲁棒的特征。
def forward(self, x, edge_index):h = x # h 代表每个节点的特征向量,初始就是原始特征 xfor i, layer in enumerate(self.layers):# 在进入非第一层之前,先做 dropoutif i != 0:h = self.dropout(h)# 核心步骤:调用 GCNConv 层# 把当前的特征 h 和图的结构 edge_index 传进去# GCNConv 在内部完成了“邻居信息汇总与自身更新”h = layer(h, edge_index)# 在非最后一层之后,使用激活函数# 作用是增加非线性,让模型能学习更复杂的关系if i < len(self.layers) - 1:h = self.activation(h)return h
forward: 定义了数据在模型中是如何“流动”的。- 输入:
x: 节点特征矩阵,形状是[节点数, 特征维度]。edge_index: 边的列表,形状是[2, 边的数量],记录了哪些节点之间有连接。
- 流动过程:
h = x: 一开始,h就是原始特征。for循环:数据依次流过我们定义的每一层GCNConv。h = layer(h, edge_index): 这就是神奇发生的地方!layer会利用edge_index找到每个节点的邻居,然后执行 GCN 的数学运算,更新h。h = self.activation(h):F.relu等激活函数会让模型不只是做简单的线性叠加,能学到更复杂模式。最后一层通常不加,因为我们需要原始的“得分”来计算损失。
3.3.2. 评估函数 (evaluate)
这个函数用来在验证集或测试集上,检查模型学得怎么样,但它不会更新模型参数。
def evaluate(model, data, mask):model.eval() # 切换到评估模式 (这会关闭 dropout)with torch.no_grad(): # 不计算梯度,节省计算资源logits = model(data.x, data.edge_index) # 得到所有节点的得分logits = logits[mask] # 只选择我们关心的节点 (比如测试集节点)labels = data.y[mask] # 获取这些节点的真实标签_, indices = torch.max(logits, dim=1) # 找到每个节点得分最高的类别correct = torch.sum(indices == labels) # 计算预测正确的数量return correct.item() * 1.0 / len(labels) # 返回准确率
mask: 一个布尔类型的张量([True, False, True, ...]),用来精确地挑选出训练集、验证集或测试集的节点。
3.3.3. 训练函数 (train)
这是整个流程的“总指挥”。
def train(...):# 1. 准备工作device = ... # 判断用 CPU 还是 GPUdataset = Planetoid(root='data/Cora', name='Cora') # 加载数据集data = dataset[0].to(device) # 获取图数据对象并送到设备# 2. 获取图的基本信息in_channels = dataset.num_node_featuresout_channels = dataset.num_classes# 3. 实例化模型、损失函数和优化器model = GCN(...).to(device)loss_fcn = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(...)# 4. 开始训练循环for epoch in range(n_epochs):model.train() # 切换到训练模式 (开启 dropout)# 前向传播:计算模型对所有节点的预测得分logits = model(data.x, data.edge_index)# 计算损失:只用训练集节点来计算!# 比较模型在训练节点上的预测得分,和它们的真实标签有多大差距loss = loss_fcn(logits[data.train_mask], data.y[data.train_mask])# 反向传播和优化optimizer.zero_grad() # 清空上一轮的梯度loss.backward() # 根据损失计算梯度optimizer.step() # 根据梯度更新模型参数(权重)# 打印当前周期的损失和在验证集上的准确率val_acc = evaluate(model, data, data.val_mask)print(...)# 5. 训练结束后,在测试集上报告最终性能test_acc = evaluate(model, data, data.test_mask)print(...)
- Epoch: 指的是把整个训练数据集过一遍。这里我们循环
n_epochs次。 - 损失函数 (
CrossEntropyLoss): 它衡量的是“预测得分”和“真实标签”之间的差距。差距越大,损失值越高。 - 优化器 (
Adam): 它的工作就是根据损失值,微调模型中所有GCNConv层的参数(权重),目标是让下一轮的损失变得更小。 - 训练的核心三步曲:
loss.backward(): 计算出每个参数应该朝哪个方向调整才能让损失变小。optimizer.step(): 执行这个调整。optimizer.zero_grad(): 清理现场,为下一次计算做准备。
3.4 总结:整个故事线
- 加载数据:拿到 Cora 这个论文引用网络,包含节点(论文)、边(引用关系)、特征(论文内容向量)和一小部分已知标签。
- 建立模型:设计一个多层的 GCN 模型。每一层都是一个
GCNConv,负责执行“邻居信息汇总”。 - 开始训练循环:
- 预测:模型对所有节点进行一次预测,得到每个节点属于各个类别的分数(
logits)。 - 算账:只看训练集的节点,用
CrossEntropyLoss计算预测分数和真实标签的差距(loss)。 - 调优:
Adam优化器根据这个差距,微调模型里所有层的参数,争取下次预测得更准。 - 验证:在验证集上跑一下,看看模型在新数据上的表现如何,防止过拟合。
- 预测:模型对所有节点进行一次预测,得到每个节点属于各个类别的分数(
- 循环往复:重复第3步很多次(比如100个 epoch)。
- 最终测试:训练结束后,把模型在从未见过的测试集上跑一次,得到最终的准确率,作为模型的最终成绩。
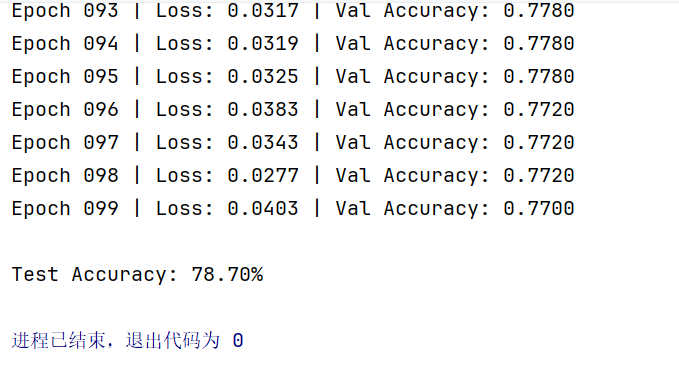
最终结果运行: