爬虫的云服务器代理
代理是网络请求的 “中转站”,客户端(如 Python 脚本)发请求时,不直接连目标服务器,先把请求给代理服务器,代理再转发给目标,目标响应也经代理回传给客户端。这样做能隐藏真实客户端 IP(目标服务器看到的是代理 IP)、突破网络限制(如公司 / 学校网络屏蔽部分站点,代理可绕过)、做请求转发 / 缓存(提升重复请求效率) 。
准备
首先购买一台云服务器,这里我选择使用腾讯云购买的一台2GB*2的windows云服务器测试
关于代理我使用云服务器做测试

首先在云服务器中安装CCProxy代理工具,然后CCProxy的设置中端口为云服务器安全组允许通过的端口。
切记要在安全组中允许指定端口的放行,这里我选择的是5173端口
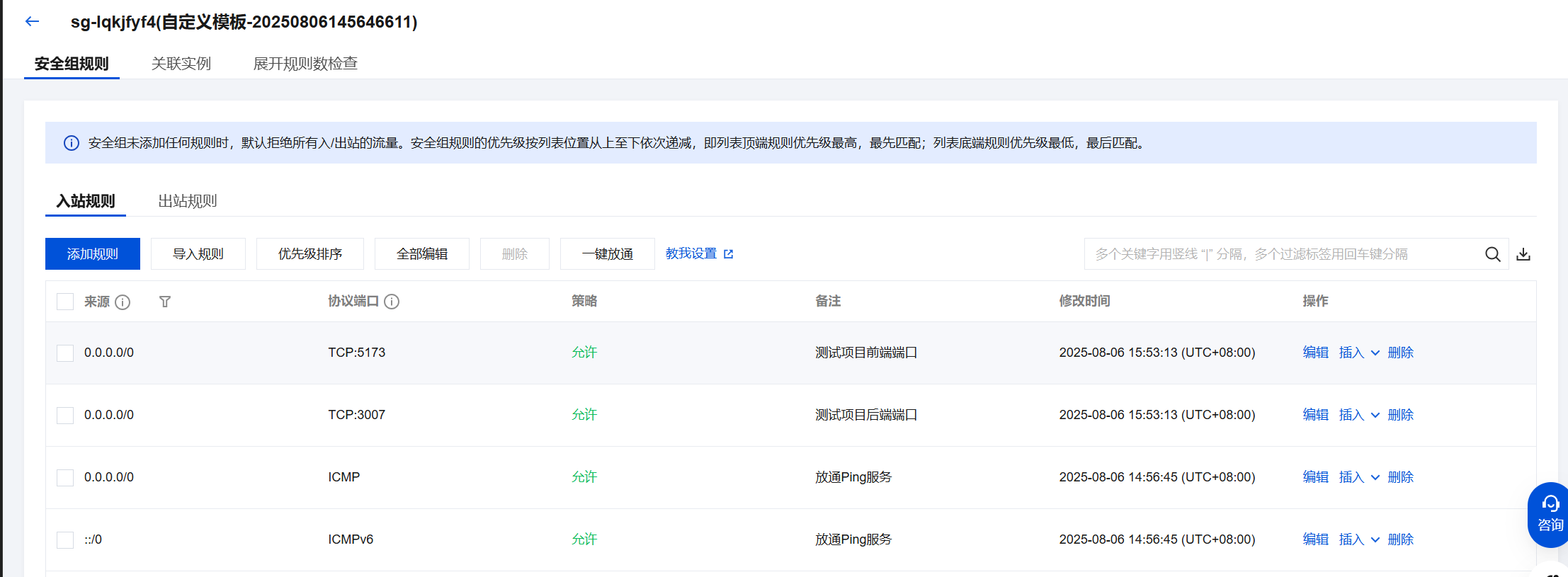
这里我设置为 5173 端口 (已经配置安全组允许5173畅通)
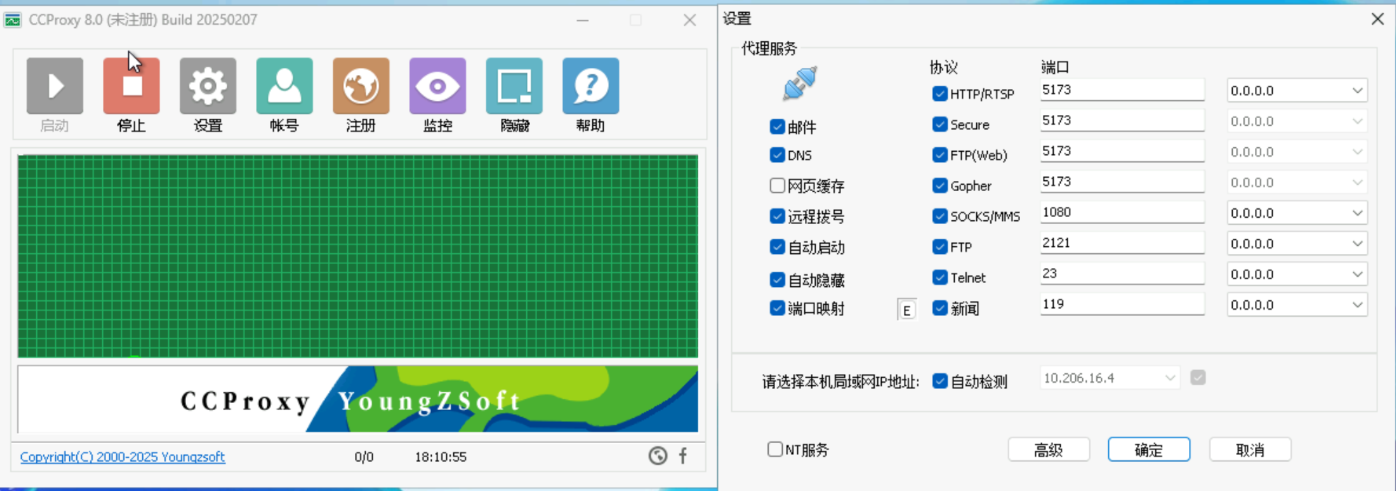
CCProxy 工具配置解析(文中代理服务器搭建)
- 功能定位:CCProxy 是常见代理服务器软件,能在局域网内搭建代理环境,让多设备共享代理上网,还能对代理访问做规则管控(如限制端口、协议、访问时间等)。
- 核心配置(对应文中截图):
- 代理服务协议 & 端口:列表里配置了多种协议(HTTP、HTTPS、FTP 等)及对应端口(如 HTTP 设 5173 端口),代理服务器会监听这些端口,接收客户端协议请求。
- “允许请求来源”:“自动检测” 或手动填 IP 段,决定哪些客户端能连代理(如填
10.206.36.4,仅该 IP 段设备可借代理上网)。 - “安全组 / 防火墙适配”:文中提 “先云服务器安装 CCProxy,设端口为 5173(已配安全组全允许 5173 端口)”,意思是云服务器要在安全组 / 防火墙放通 5173 端口,否则代理请求会被拦截,无法对外转发。
然后使用python爬虫进行代理配置
import urllib.requesturl = 'https://ip.900cha.com/' # 代理后访问的目标网址
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0',
}# 设置代理服务器
proxies = {'http': 'http://云IP:5173', 'https': 'http://云IP:5173'}# 创建代理处理器
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)# 定制请求)
request = urllib.request.Request(url, headers=headers)try:response = opener.open(request, timeout=10) # 增加超时,避免卡壳content = response.read().decode('utf-8')with open('yunfuwudaili.html', 'w', encoding='utf-8') as fp:fp.write(content)print("请求成功,已保存页面")
except Exception as e:print(f"请求失败:{e}") # 捕获错误,方便排查该爬虫模拟使用 云服务器代理,访问网络查询ip工具,如果查询的ip是云服务器的ip而不是自身本地的ip则说明代理成功
测试
1,不做代理直接访问
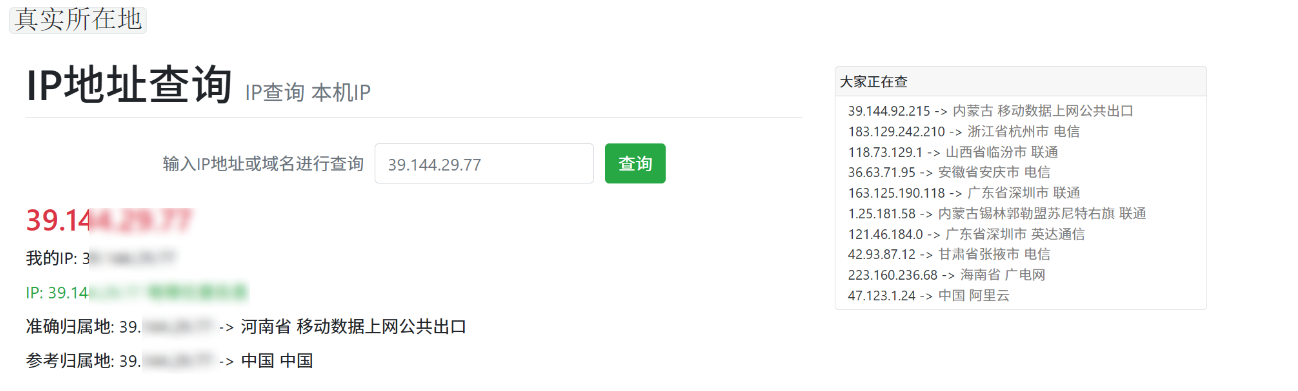
显示在中国河南,也就是我真实所在地
2,使用南京的云服务器做代理
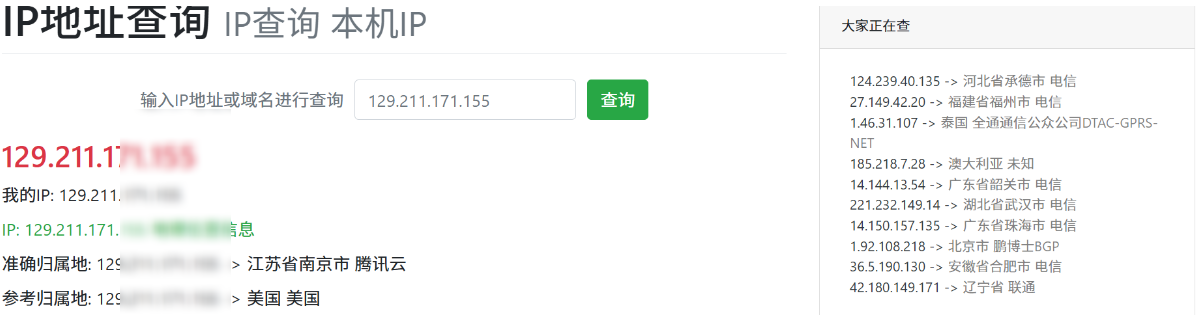
显示在江苏南京,也就是云服务器所在地。
代理的典型应用场景
- 爬虫突破反爬:目标网站限制单个 IP 访问频率,用代理换不同 IP 发请求,降低被封概率(但别恶意爬取,遵守网站
robots.txt规则和法律 )。 - 访问受限资源:如公司内网屏蔽某些站点,通过代理(代理服务器能访问外网),员工可借代理打开受限页面。
- 数据抓包调试:开发 / 测试时,用代理工具(如 CCProxy 配合浏览器代理设置),抓包分析客户端 - 服务器请求细节,排查接口、网络问题。
代理是网络请求的 “中间人”,文中借 CCProxy 搭代理环境,Python 代码用 urllib 走代理发请求,核心是让请求经代理转发,实现隐藏真实 IP、突破限制等效果,实操中多留意代理服务状态、目标网站规则,就能灵活用代理解决网络访问需求