元数据管理与数据治理平台:Apache Atlas 关系搜索 Relationship Search

Apache Atlas 框架是一套可扩展的核心基础治理服务,使企业能够有效、高效地满足 Hadoop 中的合规性要求,并支持与整个企业数据生态系统集成。这将通过使用规范和取证模型,以及技术和运营审计以及由业务分类元数据丰富的沿袭,在 Hadoop 中提供真正的可视性。它还使任何元数据使用者能够互操作,而无需彼此独立的接口——元数据存储是通用的。通过利用 Apache Ranger 来维护元数据的准确性,以防止在运行时对数据进行未经授权的访问。安全性基于角色 (RBAC) 和属性 (ABAC)。
关系搜索
Relationship Search
Apache Atlas 是一个元数据治理工具,具备在已定义模型中搜索预定义实体的能力。
我们可以通过指定通用属性(如 ‘name’、‘qualified name’、‘description’ 等)、实体类型定义特有属性(仅适用于特定实体的属性,如 hdfs_path 类型实体的 ‘cluster name’)以及分类应用、实体子类型及已删除实体等参数来搜索这些实体。然而,这些结果仅返回符合搜索查询参数的实体。
关系(relationship)与实体具有相似结构,用于描述两个实体端点之间的各种元数据。例如,假设 hive_table 与 hive_db 之间存在一个名为 hive_table_db 的关系类型,该关系可拥有自身元数据,这些元数据可作为属性添加到该模型中。
Relationship search 允许通过查询关系类型名称来获取两个实体模型之间的元数据,并支持对关系属性进行过滤。
整个查询结构可使用以下 JSON 结构表示(称为 RelationshipSearchParameters)
{"relationshipName": "hive_table_db","excludeDeletedEntities": true,"offset": 0,"limit": 25,"relationshipFilters": { },"sortBy": "table_name","sortOrder": ASCENDING,"marker": "*"
}
字段描述
relationshipName: 要查找的关系类型
excludeDeletedEntities: 是否排除已删除实体?(默认为 true)
offset: 结果集的起始偏移量(用于分页)
limit: 获取结果的最大数量
relationshipFilters: 关系属性过滤条件
sortBy: 结果排序依据的属性
sortOrder: 结果排序顺序
marker: 添加 offset 或 marker,首页 marker 值为 '*',响应中的 nextMarker 值将用作后续页的 marker 输入
可基于多个属性进行属性过滤,并支持 AND/OR 条件。
Relationship Search 的实时示例
考虑社交媒体应用 ‘Instagram’ 及其基本功能用例:
- User 创建 Posts
- User 对 Posts 做出反应
- User 创建 Highlight
- Posts 被添加到 Highlight
以下为突出上述用例的元数据模型
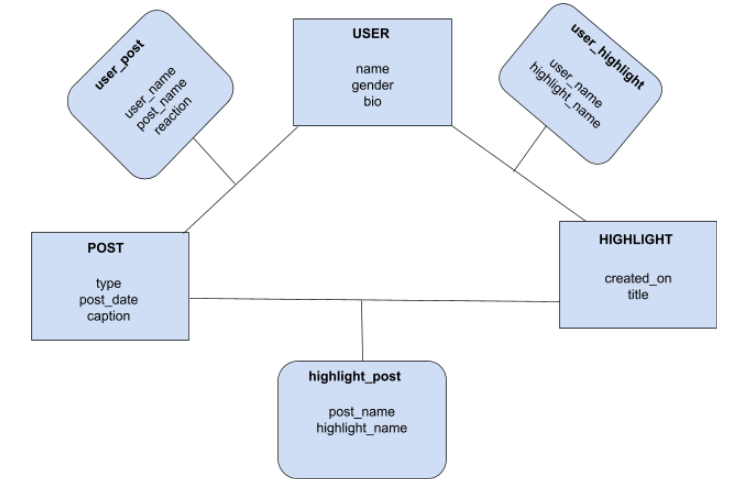
示例:假设用户 Ajay 上传了一张庆祝排灯节的照片作为帖子,Divya、Rahul 等用户对该帖子点了赞。
现在用户 Ajay 想查询其帖子收到的 “like” 反应数量。
为此,他将聚焦于 ‘user_post’ 关系类型,并过滤属性中反应为 ‘like’ 且帖子名称包含 ‘Diwali’ 的记录。
过滤示例(针对 user_post 属性)
{"relationshipName": "user_post","excludeDeletedEntities": true,"offset": 0,"limit": 25,"relationshipFilters": {"condition": "AND","criterion": [{"attributeName": "reaction","operator": "eq","attributeValue": "like"},{"attributeName": "post_name","operator": "contains","attributeValue": "Diwali"}]}}
支持的过滤运算符
与基本搜索相同
CURL 示例
curl -sivk -g-u <user>:<password>-X POST-d '{"relationshipName": "user_post","excludeDeletedEntities": true,"offset": 0,"limit": 25,"relationshipFilters": {"condition": "AND","criterion": [{"attributeName": "reaction","operator": "eq","attributeValue": "like"},{"attributeName": "post_name","operator": "contains","attributeValue": "Diwali"}]}}'<protocol>://<atlas_host>:<atlas_port>/api/atlas/v2/search/relations
Apache Atlas 概览
Apache Atlas 是一套可扩展且可延伸的核心基础治理服务——使企业能够在 Hadoop 中高效且有效地满足其合规要求,并允许与整个企业数据生态系统进行集成。
Apache Atlas 为组织提供开放的元数据管理和治理能力,用于构建其数据资产目录,对这些资产进行分类和治理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作能力。
特性
元数据类型与实例
- 为各种 Hadoop 和非 Hadoop 元数据预定义类型
- 具备为待管理元数据定义新类型的能力
- 类型可包含原始属性、复杂属性、对象引用;可从其他类型继承
- 类型的实例(称为实体)捕获元数据对象详情及其关系
- 提供 REST API 以便更轻松地与类型和实例进行集成
分类
- 具备动态创建分类的能力——例如 PII、EXPIRES_ON、DATA_QUALITY、SENSITIVE
- 分类可包含属性——例如在 EXPIRES_ON 分类中的 expiry_date 属性
- 实体可与多个分类关联,便于发现和安全策略执行
- 通过血缘关系传播分类——自动确保分类随数据在各种处理过程中流转
血缘
- 直观的 UI 查看数据在各类流程中的血缘
- 提供 REST API 以访问和更新血缘信息
搜索/发现
- 直观的 UI 按类型、分类、属性值或自由文本搜索实体
- 丰富的 REST API 以复杂条件进行搜索
- SQL 风格的实体查询语言——领域特定语言(DSL)
安全与数据脱敏
- 针对元数据访问的细粒度安全控制,可对实体实例及添加/更新/移除分类等操作进行权限管控
- 与 Apache Ranger 集成,可根据 Apache Atlas 中实体关联的分类进行基于授权的访问控制/数据脱敏。例如:
- 谁能访问被分类为 PII、SENSITIVE 的数据
- 客户服务用户仅能看到被分类为 NATIONAL_ID 的列的最后四位
快速开始
- Apache Atlas 2.4 的新功能
- 构建与安装
- 快速入门
API 文档
- REST API 文档
- 导出与导入 REST API 文档
- 旧版 API 文档
开发者设置文档
- 开发者设置:Eclipse
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。