理解LangChain — Part 3:链式工作流与输出解析器

在这第三篇文章中,我们将深入探讨结构化输出和输出解析器——这是从大型语言模型(LLM)获取干净、可靠数据的关键工具。从解析 JSON 到正则表达式提取再到自定义格式,LangChain 都让这些操作变得简单。
掌握了如何获取格式化的输出后,下一步自然是如何将这些输出串联起来,构建更复杂的应用流程。 这正是 Chains(链式工作流) 大显身手的地方——作为 LangChain 模块化设计的核心,链式工作流让你能够以最小的努力,将多个独立的步骤(如模型调用、提示、解析等)灵活地组合成可复用的处理流水线。接下来,我们将重点探索它的工作原理和应用场景。
1. 结构化输出与输出解析器
1.1 结构化输出
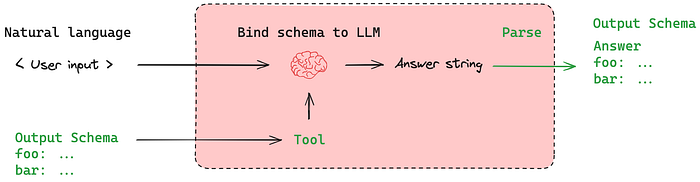
在 LangChain 中,结构化输出意味着让语言模型以清晰、定义好的格式(如 JSON)进行响应,而不仅仅是自由格式的文本。这使得以编程方式处理结果变得容易得多,特别是当你需要提取特定字段或将输出馈送到另一个系统时。
在 LangChain 中使用结构化输出时,尤其是当你期望 LLM 以特定格式(如产品目录、用户档案或知识卡片)响应时,仅仅说“返回 JSON”是不够的。
你需要一个明确定义的模式(Schema)来告诉模型要返回什么样的 JSON。这就是 TypedDict、Pydantic 和 JSON Schema 发挥作用的地方。让我们逐一了解它们。
1.1.1 何时/为何使用它
默认情况下,LLM 生成自由格式的文本,这对于听起来自然的响应很好,但当你的应用程序需要处理或提取特定信息片段时,就不理想了。这正是结构化输出变得必不可少的地方。
何时使用结构化输出:
构建具有可预测数据流的应用程序
# 与其解析:"天气晴朗,75°F,湿度20%" # 不如获取结构化数据:{"condition": "sunny","temperature": 75,"humidity": 20,"unit": "fahrenheit" }多步骤工作流:当你需要将 LLM 的输出传递给需要特定数据类型的其他函数或 API 时。
数据提取任务:当你需要提取特定字段或值时
# 从文档中提取信息# 原始文本:"John Smith, 30岁,在 Google 担任软件工程师" # 结构化输出:{"name": "John Smith","age": 30,"company": "Google","position": "Software Engineer" }API 集成:当 LLM 的响应需要匹配外部 API 的模式时。
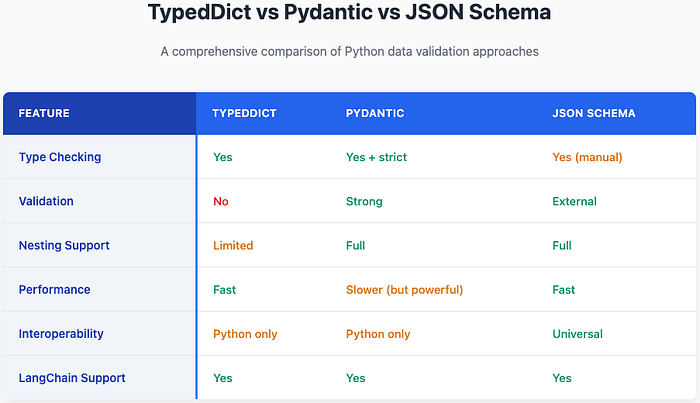
1.1.2 类型:TypedDict, Pydantic, JSON Schema
LangChain 根据你的使用场景支持所有这三种模式格式。
TypedDict:TypedDict 是一种使用类型提示定义字典预期结构的原生方式。
from typing_extensions import TypedDict# Basic TypedDict definition class Person(TypedDict):name: strage: intemail: str # Usage person_data: Person = {"name": "John Doe","age": 30,"email": "john@example.com" }Pydantic:Pydantic 是一个强大的 Python 数据验证和解析库。它有助于确保你处理的数据结构正确、类型安全并符合你定义的模式。
from pydantic import BaseModel, EmailStr, Field from typing import Optionalclass Student(BaseModel):name: str = 'sato'age: Optional[int] = Noneemail: EmailStrcgpa: float = Field(gt=0, lt=10, default=5, description='A decimal value representing the cgpa of the student')new_student = {'age':'28', 'email':'abc@gmail.com'} student = Student(**new_student) student_dict = dict(student) print(student_dict['age'])JSON Schema:这是一个广泛使用的开放标准,用于定义 JSON 数据的结构。
{"type": "object","properties": {"name": {"type": "string"},"price": {"type": "number"},"in_stock": {"type": "boolean"}},"required": ["name", "price", "in_stock"] }
既然我们已经讨论了所有的结构化输出,是时候看看输出解析器了。
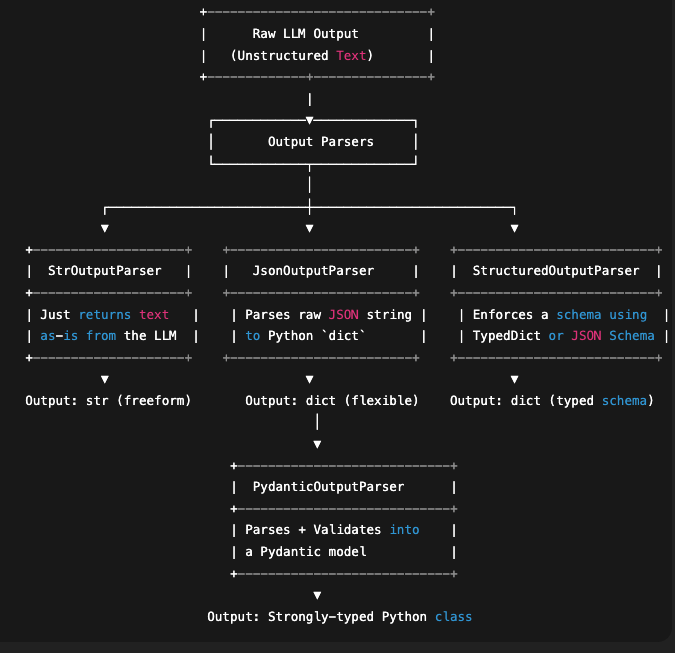
1.2 输出解析器
LangChain 中的输出解析器帮助将原始的 LLM 响应转换为结构化格式,如 JSON、CSV、Pydantic 模型等。它们确保应用程序中的一致性、验证和易用性。
1.2.1 字符串输出解析器 (StrOutputParser)
解析 LLM 的输出并将其作为纯字符串返回。
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain_core.output_parsers import (StrOutputParser,JsonOutputParser,PydanticOutputParser,
)
from pydantic import BaseModel, Field
from typing import Literalload_dotenv()# 1. Define the Gemini model
model = ChatGoogleGenerativeAI(model="gemini-2.0-flash")# 2. Define JSON output parser
parser = StrOutputParser()prompt = PromptTemplate.from_template("Explain {topic} in one sentence.")chain = prompt | model | parserresult = chain.invoke({"topic": "black hole"})
print(result)
输出:
A black hole is a region in spacetime with such strong gravity that nothing, not even light, can escape its pull.
1.2.2 JSON 输出解析器 (JsonOutputParser)
使用 json.loads 将 LLM 的输出解析为有效的 Python 字典。
# 2. Define JSON output parser
parser = JsonOutputParser()# 3. Create prompt with structured output instructions
template = PromptTemplate(template="Give me 2 facts about {topic} \\n{format_instruction}",input_variables=["topic"],partial_variables={"format_instruction": parser.get_format_instructions()}
)
# 4. Create the chain using LCEL pipe operator
chain = template | model | parser
# 5. Invoke the chain
result = chain.invoke({"topic": "Baseball"})
# 6. Print result
print(result)
输出:
{'baseball_facts': [{'fact': 'The highest recorded batting average in a single MLB season is .424, achieved by Rogers Hornsby in 1924 while playing for the St. Louis Cardinals.'}, {'fact': "The 'Curse of the Bambino' supposedly plagued the Boston Red Sox for 86 years after they sold Babe Ruth to the New York Yankees in 1919, finally ending with their World Series victory in 2004."}]}
1.2.3 结构化输出解析器 (StructuredOutputParser)
一种更高级的解析器,允许你定义一个模式(通过 TypedDict 或 JSONSchema)并据此解析模型输出。
LangChain 会根据模式自动生成格式化指令,并确保模型输出匹配预期的结构。
schema = [ResponseSchema(name='fact_1', description='Fact 1 about the topic'),ResponseSchema(name='fact_2', description='Fact 2 about the topic'),
]parser = StructuredOutputParser.from_response_schemas(schema)
template = PromptTemplate(template='Give 2 fact about {topic} \\n {format_instruction}',input_variables=['topic'],partial_variables={'format_instruction':parser.get_format_instructions()}
)
chain = template | model | parser
result = chain.invoke({'topic':'baseball'})
print(result)
输出:
{'fact_1': 'The highest recorded batting average in a single MLB season is .424, achieved by Rogers Hornsby in 1924.', 'fact_2': 'The baseball used in Major League Baseball has 108 double stitches.'}
1.2.4 Pydantic 输出解析器 (PydanticOutputParser)
将模型输出直接解析为 Pydantic 模型——具备数据验证、类型检查和丰富的文档功能。
它与 StructuredOutputParser 非常相似,但使用 Pydantic 类而不是普通字典或 TypedDict。
class WeatherReport(BaseModel):city: str = Field(description="Name of the city")temperature_c: float = Field(description="Temperature in Celsius")condition: Literal["sunny", "rainy", "cloudy", "snowy"]parser = PydanticOutputParser(pydantic_object=WeatherReport)
prompt = PromptTemplate(template="Provide a weather report for Tokyo in this format:\\n{format_instruction}",input_variables=[],partial_variables={"format_instruction": parser.get_format_instructions()},
)
chain = prompt | model | parser
result = chain.invoke({})
print(result)
输出:
city='Tokyo' temperature_c=25.0 condition='sunny'
2. 链式工作流 (Chains)
2.1 什么是链式工作流?
在 LangChain 中,链式工作流(Chains)是最强大的构建模块之一。虽然提示(Prompts)和模型(Models)让你生成单次响应,但链式工作流让你可以将多个步骤组合成一个结构化的、可重复的过程。
如果你正在构建任何比简单问答更复杂的东西,比如摘要生成器、聊天机器人、数据提取器或智能体(Agents),你都需要链式工作流。
可以把一个链式工作流想象成烹饪书中的一个食谱。
- 一个食谱不仅仅是一个动作——它是一系列步骤:切、混合、烘烤、上菜。
- 同样,一个链式工作流是一系列 LLM 调用、提示、解析器、记忆(Memory)和其他工具(Tools)的序列。
2.2 旧方式 vs 新方式:LLMChain vs LCEL
当 LangChain 最初被引入时,大多数应用程序是使用像 LLMChain、SimpleSequentialChain 或 RouterChain 这样的类构建的。这些对于快速原型设计来说很好,但随着应用程序变得越来越复杂,人们开始遇到局限性。
问题是什么? 在 LangChain 的早期版本(v0.1 之前),有许多不同的链和组件,但它们没有标准化。每种链的工作方式略有不同,也没有一致的方式来连接提示、模型、记忆、检索器或工具。最终导致了什么情况?
- 需要手动粘合组件
- 编写自定义的包装函数
- 处理不一致的接口
- 为链接步骤重复编写相同的逻辑
这使得 LangChain 感觉功能强大但零散,尤其对新手来说。这就是引入 LCEL (LangChain 表达式语言) 的主要原因之一——在标准的、可组合的、模块化的接口下统一一切。
2.3 LCEL 简介:可运行架构 (Runnable Architecture)
“如果构建 AI 工作流感觉像用管道连接乐高积木会怎样?这正是 LangChain 表达式语言 (LCEL) 让你做的事情——使用
|运算符。”
LCEL 在标准、可组合和声明式的语法下统一了所有 LangChain 组件。你现在可以使用管道 | 运算符来组合工作流,就像 Unix 管道或 pandas 中的 DataFrame 操作一样,而不是费力处理不同的链类。
PromptTemplate | LLM | OutputParser
每个组件:
- 接收输入
- 执行其工作
- 将其输出传递给下一步
示例:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import StrOutputParser# Prompt to generate a short poem
prompt = PromptTemplate.from_template("Write a short poem about {topic}")# Model
llm = ChatOpenAI()# Output parser to convert model response into plain string
parser = StrOutputParser()# Chain the steps using the pipe operator
chain = prompt | llm | parser# Run it
print(chain.invoke({"topic": "sunsets"}))
在一行代码中,你使用 | 连接了一个 提示 → 模型 → 解析器。
2.4 什么是可运行组件 (Runnables)?
在 LCEL 中,一切都是一个可运行组件:提示、模型、检索器、链、智能体,甚至是自定义函数。可运行组件定义了一个通用接口,允许这些组件无缝地组合、重用和扩展。
可以把可运行组件想象成智能乐高积木:
- 每个积木(组件)都知道如何独立工作或作为管道的一部分工作
- 它们都说同一种语言(
invoke,batch,stream等方法) - 它们可以使用
|运算符连接在一起 - 它们开箱即用地支持强大的功能,如流式传输(streaming)、异步(async)、重试(retries)和并行执行(parallel execution)
简而言之:
LCEL = 组合语法。 Runnables = 驱动这一切的标准协议。
所以,当你这样写:
chain = prompt | llm | parser
每个组件 (prompt, llm, parser) 都是一个可运行组件(Runnable),当你使用 | 将它们“管道连接”在一起时,你正在创建一个新的可运行组件(Runnable)——它代表整个工作流。这个组合而成的可运行组件就是链(chain)。
最终流程:可运行组件在 LCEL 中的位置
┌────────────┐│ 提示 │◄─────────── PromptTemplate (可运行组件)└────┬───────┘│┌────▼───────┐│ 模型 │◄─────────── LLM (可运行组件)└────┬───────┘│┌────▼───────┐│ 解析器 │◄─────────── OutputParser (可运行组件)└────┬───────┘│┌────▼───────┐│ 链 │◄─────────── 组合而成的可运行组件 (通过 |)└────────────┘
这就是 LangChain 中可运行组件的本质!
2.5 构建 LCEL 链式工作流
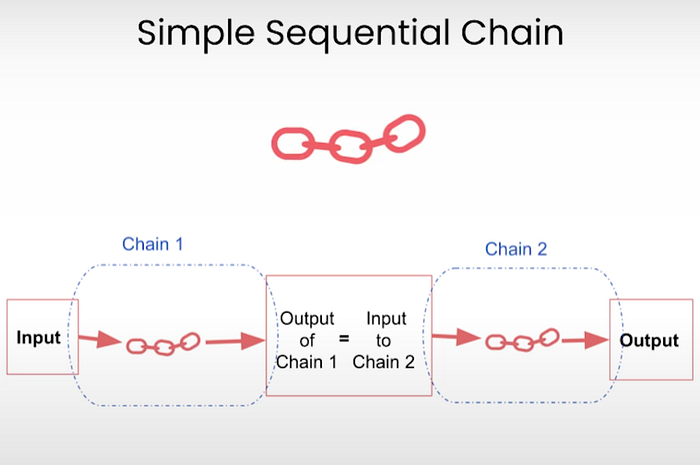
2.5.1 简单顺序链 (Simple Sequential Chain)
这是最基本类型的链;每个步骤一个接一个地运行,将输出从一个步骤传递到下一个步骤。它非常适合线性任务,比如生成摘要,然后将其扩展为博客引言。
可以把它想象成多米诺骨牌效应:一旦第一个模型运行,它就会触发第二个模型,依此类推。
from langchain.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParserllm = ChatAnthropic(model="claude-3.5-sonnet-20240620", anthropic_api_key="...")
prompt = PromptTemplate.from_template("Write a poem on {topic}")
chain = prompt | llm | StrOutputParser()result = chain.invoke({"topic": "autumn"})
print(result)
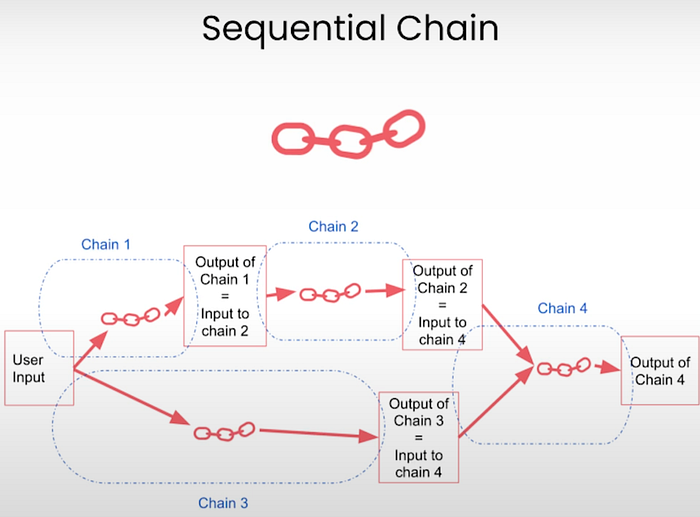
2.5.2 顺序链 (Sequential Chain)
SequentialChain 是功能更丰富的 SimpleSequentialChain 版本。它允许:
- 多个输入和输出
- 变量跟踪
- 命名步骤输出
这使得它非常适合更复杂的工作流,其中一个步骤的输出需要馈送到多个其他步骤,或者需要在稍后被引用。
何时使用它:
- 你需要访问中间结果
- 你在多个步骤中使用记忆或变量
代码:
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParserllm = ChatBedrock( model_id=anthropic.claude-3-5-sonnet-20241022-v2:0, region_name="us-west-2")
prompt1 = PromptTemplate(template='Generate a detailed report on {topic}',input_variables=['topic']
)
prompt2 = PromptTemplate(template='Generate a 2-point summary from the following text \\n {text}',input_variables=['text']
)
parser = StrOutputParser()
chain = prompt1 | llm | parser | prompt2 | llm | parser
result = chain.invoke({'topic': 'Global Recession'})
print(result)
输出:
Here's a 2-point summary of the text:
1. Global recessions are characterized by widespread economic decline, featuring negative GDP growth, reduced trade, rising unemployment, and market volatility, with notable historical examples including the Great Depression (1929-1939), 2008 Financial Crisis, and COVID-19 Recession (2020).
2. Managing global recessions requires a multi-faceted approach combining monetary policies (like interest rate adjustments), fiscal measures (such as government stimulus), and structural reforms, while prevention strategies focus on early warning systems, regulatory frameworks, and building economic resilience at all levels - from international cooperation to individual preparedness.
让我们用这个过程可视化最终创建的链:
chain.get_graph().print_ascii() +-------------+ (输入)| PromptInput |+-------------+***+----------------+ (提示模板1)| PromptTemplate |+----------------+***+-------------+ (模型1)| ChatBedrock |+-------------+***+-----------------+ (字符串解析器1)| StrOutputParser |+-----------------+***
+-----------------------+ (字符串解析器输出1 -> 成为 prompt2 的输入)
| StrOutputParserOutput |
+-----------------------+***+----------------+ (提示模板2)| PromptTemplate |+----------------+***+-------------+ (模型2)| ChatBedrock |+-------------+***+-----------------+ (字符串解析器2)| StrOutputParser |+-----------------+***
+-----------------------+ (最终输出)
| StrOutputParserOutput |
+-----------------------+
从上面的图可以解释:第一个链 prompt1 | llm | parser 的输出作为输入传递给第二个链,然后我们尝试从第一个链生成的报告中创建一个包含 2 个要点的摘要。
2.5.3 并行链 (Parallel Chain)
顾名思义,并行链让你可以同时运行多个链,每个链使用相同的输入,然后收集所有的输出。
何时使用它:
- 你想在同一个输入上运行不同的任务(例如,摘要、情感分析、关键词提取)
- 速度很重要,且步骤可以独立运行
代码:
from langchain_aws import ChatBedrock
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.schema.runnable import RunnableParallel# Initialize model and parser
llm = ChatBedrock( model_id=anthropic.claude-3-5-sonnet-20241022-v2:0, region_name="us-west-2")
parser = StrOutputParser()# Step 1a: Summary prompt
summary_prompt = PromptTemplate.from_template("Summarize this topic:\\n{text}")
summary_chain = summary_prompt | llm | parser# Step 1b: Fun fact prompt
fact_prompt = PromptTemplate.from_template("Give a fun fact about:\\n{text}")
fact_chain = fact_prompt | llm | parser# Run both in parallel
parallel = RunnableParallel({"summary": summary_chain,"fact": fact_chain
})# Step 2: Merge both outputs
merge_prompt = PromptTemplate.from_template("Here is a short summary and a fun fact combined:\\nSummary: {summary}\\nFun Fact: {fact}"
)
merge_chain = merge_prompt | llm | parser# Final full chain
chain = parallel | merge_chain# Sample input
text = "Photosynthesis is the process by which green plants use sunlight to make food from carbon dioxide and water."# Run
result = chain.invoke({"text": text})
print(result)
在实现过程中,我们使用 RunnableParallel 将两个链并行连接。在 LangChain 中,可运行组件是 LCEL 的构建模块。可以把它们想象成可插拔、可组合的函数——每个部分(如提示、模型、解析器、检索器或工具)都变成一个可运行组件,你可以使用 | 运算符轻松地将它们链接起来。
# Visualize the chain
chain.get_graph().print_ascii()+-----------------------------+ (并行输入)| Parallel<summary,fact>Input |+-----------------------------+*** ****** ***** **
+----------------+ +----------------+ (提示模板1) (提示模板2)
| PromptTemplate | | PromptTemplate |
+----------------+ +----------------+* ** ** *+-------------+ +-------------+ (模型1) (模型2)| ChatBedrock | | ChatBedrock |+-------------+ +-------------+* ** ** *
+-----------------+ +-----------------+ (解析器1) (解析器2)
| StrOutputParser | | StrOutputParser |
+-----------------+ +-----------------+*** ****** ***** **+------------------------------+ (并行输出: 包含'summary'和'fact'键的字典)| Parallel<summary,fact>Output |+------------------------------+***+----------------+ (合并提示模板)| PromptTemplate |+----------------+***+-------------+ (模型3)| ChatBedrock |+-------------+***+-----------------+ (最终解析器)| StrOutputParser |+-----------------+***+-----------------------+ (最终输出)| StrOutputParserOutput |+-----------------------+
2.5.4 条件链 (Conditional Chain)
条件链引入了基于逻辑的分支。根据某些条件(如输入文本、分类结果等),链选择运行哪个子链。
何时使用它:
- 你需要在链中做决策(例如,将销售查询路由到一个模型,将支持查询路由到另一个模型)
- 你想要基于上下文或意图的动态行为
代码:
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser, PydanticOutputParser
from langchain.schema.runnable import RunnableParallel, RunnableBranch, RunnableLambda
from pydantic import BaseModel, Field
from typing import Literal# llm = ChatOpenAI()
text_parser = StrOutputParser()
# 1. Define structured output schema
class Feedback(BaseModel):sentiment: Literal["positive", "negative"] = Field(description="Classify the feedback sentiment")
structured_parser = PydanticOutputParser(pydantic_object=Feedback)
# 2. Classification prompt (with parser instruction)
classification_prompt = PromptTemplate(template=("Analyze the feedback and classify it as 'positive' or 'negative'.\\n""Feedback: {feedback}\\n\\n""{format_instruction}"),input_variables=["feedback"],partial_variables={"format_instruction": structured_parser.get_format_instructions()}
)
# Chain: classify → structured output
classifier_chain = classification_prompt | llm | structured_parser
# 3. Conditional branches for response generation
prompt1 = PromptTemplate.from_template("Write a warm thank-you message for this feedback:\\n{feedback}")
positive_response = prompt1 | llm | text_parser
prompt2 = PromptTemplate.from_template("Write a polite and helpful apology response for this feedback:\\n{feedback}")
negative_response = prompt2 | llm | text_parser
# 4. Conditional logic using RunnableBranch
response_branch = RunnableBranch((lambda x: x.sentiment == "positive", positive_response),(lambda x: x.sentiment == "negative", negative_response),RunnableLambda(lambda _: "Sentiment could not be classified.")
)
# 5. Final chain: classify → choose response
chain = classifier_chain | response_branch
# Example usage
feedback_text = "The product arrived late and the box was damaged."
print(chain.invoke({"feedback": feedback_text}))
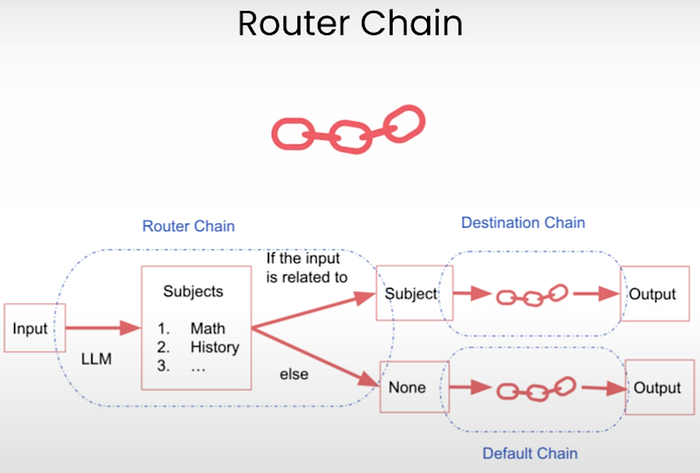
2.5.5 路由链 (Router Chains)
路由链是条件链的一种专门形式,它根据某些逻辑或分类将输入动态路由到不同的子链(或工具/提示)。
可以把它们看作调度器:
“如果用户的查询是关于 Python 的,就发送到 Python 链。如果是关于 SQL 的,就发送到 SQL 链。”
何时使用路由链:
- 当你的应用程序处理多种意图或任务时
- 当不同的查询需要不同的提示或模型时
- 模拟具有单一入口点的多智能体系统时
代码:
from langchain_core.runnables import RunnableLambda, RunnableBranch
from langchain_core.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.output_parsers import StrOutputParser# Base model: Gemini Flash
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")# Output parser
parser = StrOutputParser()# Prompt for Python questions
python_prompt = PromptTemplate.from_template("You are a Python expert. Answer the following question in detail:\\n{question}"
)
python_chain = python_prompt | llm | parser# Prompt for SQL questions
sql_prompt = PromptTemplate.from_template("You are a SQL expert. Explain this SQL-related query in detail:\\n{question}"
)
sql_chain = sql_prompt | llm | parser# Router logic based on keywords
def route_question(input):q = input["question"].lower()if "python" in q:return 0 # Route to Python chainelif "sql" in q:return 1 # Route to SQL chainelse:return 2 # Fallback response# Fallback chain
fallback_chain = RunnableLambda(lambda x: "Sorry, I can only answer questions about Python or SQL at the moment."
)# Router chain using RunnableBranch
router_chain = RunnableBranch((lambda x: route_question(x) == 0, python_chain),(lambda x: route_question(x) == 1, sql_chain),fallback_chain
)# Run it
print(router_chain.invoke({"question": "How does a Python generator work?"}))
输出:
...**In Summary:**Generators are a powerful tool in Python for creating iterators in a memory-efficient and elegant way. They use the `yield` keyword to produce values on demand, pausing execution and preserving state between calls to `next()`. Understanding how generators work is essential for writing efficient and scalable Python code. They are especially beneficial when dealing with large datasets or complex iteration logic.
下一个查询:
print(router_chain.invoke({"question": "Tell me about cloud computing."}))
输出:
Sorry, I can only answer questions about Python or SQL at the moment.