Qwen-Image:通义团队新开源超强中文文生图模型(技术报告解读)
1.简介
Qwen-Image,这是一个拥有 200 亿参数的 MMDiT 图像基础模型,在复杂文本渲染与精准图像编辑方面实现显著突破。
核心特性:
- 卓越的文本渲染:Qwen-Image 擅长处理复杂文本渲染,包括多行排版、段落级语义及细粒度细节,并可高保真地支持字母语言与表意语言。
- 一致的图像编辑:借助增强的多任务训练范式,Qwen-Image 在编辑过程中同时保持语义准确与视觉真实,表现卓越。
- 优异的跨基准表现:在多项公开基准测试中,Qwen-Image 在多样化的生成与编辑任务上持续超越现有模型,为图像生成奠定坚实基础。

权重地址(huggingface):https://huggingface.co/Qwen/Qwen-Image
权重地址(魔搭):Qwen-Image
技术报告:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
demo:https://huggingface.co/spaces/Qwen/qwen-image
-
官方演示
宫崎骏的动漫风格。平视角拍摄,阳光下的古街热闹非凡。一个穿着青衫、手里拿着写着“阿里云”卡片的逍遥派弟子站在中间。旁边两个小孩惊讶的看着他。左边有一家店铺挂着“云存储”的牌子,里面摆放着发光的服务器机箱,门口两个侍卫守护者。右边有两家店铺,其中一家挂着“云计算”的牌子,一个穿着旗袍的美丽女子正看着里面闪闪发光的电脑屏幕;另一家店铺挂着“云模型”的牌子,门口放着一个大酒缸,上面写着“千问”,一位老板娘正在往里面倒发光的代码溶液。

一副典雅庄重的对联悬挂于厅堂之中,房间是个安静古典的中式布置,桌子上放着一些青花瓷,对联上左书“义本生知人机同道善思新”,右书“通云赋智乾坤启数高志远”, 横批“智启通义”,字体飘逸,中间挂在一着一副中国风的画作,内容是岳阳楼。

Bookstore window display. A sign displays “New Arrivals This Week”. Below, a shelf tag with the text “Best-Selling Novels Here”. To the side, a colorful poster advertises “Author Meet And Greet on Saturday” with a central portrait of the author. There are four books on the bookshelf, namely “The light between worlds” “When stars are scattered” “The slient patient” “The night circus”

A slide featuring artistic, decorative shapes framing neatly arranged textual information styled as an elegant infographic. At the very center, the title “Habits for Emotional Wellbeing” appears clearly, surrounded by a symmetrical floral pattern. On the left upper section, “Practice Mindfulness” appears next to a minimalist lotus flower icon, with the short sentence, “Be present, observe without judging, accept without resisting”. Next, moving downward, “Cultivate Gratitude” is written near an open hand illustration, along with the line, “Appreciate simple joys and acknowledge positivity daily”. Further down, towards bottom-left, “Stay Connected” accompanied by a minimalistic chat bubble icon reads “Build and maintain meaningful relationships to sustain emotional energy”. At bottom right corner, “Prioritize Sleep” is depicted next to a crescent moon illustration, accompanied by the text “Quality sleep benefits both body and mind”. Moving upward along the right side, “Regular Physical Activity” is near a jogging runner icon, stating: “Exercise boosts mood and relieves anxiety”. Finally, at the top right side, appears “Continuous Learning” paired with a book icon, stating “Engage in new skill and knowledge for growth”. The slide layout beautifully balances clarity and artistry, guiding the viewers naturally along each text segment.

A man in a suit is standing in front of the window, looking at the bright moon outside the window. The man is holding a yellowed paper with handwritten words on it: “A lantern moon climbs through the silver night, Unfurling quiet dreams across the sky, Each star a whispered promise wrapped in light, That dawn will bloom, though darkness wanders by.” There is a cute cat on the windowsill.

一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 “一、Qwen-Image的技术路线: 探索视觉生成基础模型的极限,开创理解与生成一体化的未来。二、Qwen-Image的模型特色:1、复杂文字渲染。支持中英渲染、自动布局; 2、精准图像编辑。支持文字编辑、物体增减、风格变换。三、Qwen-Image的未来愿景:赋能专业内容创作、助力生成式AI发展。”

一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 “Meet Qwen-Image – a powerful image foundation model capable of complex text rendering and precise image editing. 欢迎了解Qwen-Image, 一款强大的图像基础模型,擅长复杂文本渲染与精准图像编辑”

一张企业级高质量PPT页面图像,整体采用科技感十足的星空蓝为主色调,背景融合流动的发光科技线条与微光粒子特效,营造出专业、现代且富有信任感的品牌氛围;页面顶部左侧清晰展示橘红色Alibaba标志,色彩鲜明、辨识度高。主标题位于画面中央偏上位置,使用大号加粗白色或浅蓝色字体写着“通义千问视觉基础模型”,字体现代简洁,突出技术感;主标题下方紧接一行楷体中文文字:“原生中文·复杂场景·自动布局”,字体柔和优雅,形成科技与人文的融合。下方居中排布展示了四张与图片,分别是:一幅写实与水墨风格结合的梅花特写,枝干苍劲、花瓣清雅,背景融入淡墨晕染与飘雪效果,体现坚韧不拔的精神气质;上方写着黑色的楷体"梅傲”。一株生长于山涧石缝中的兰花,叶片修长、花朵素净,搭配晨雾缭绕的自然环境,展现清逸脱俗的文人风骨;上方写着黑色的楷体"兰幽"。一组迎风而立的翠竹,竹叶随风摇曳,光影交错,背景为青灰色山岩与流水,呈现刚柔并济、虚怀若谷的文化意象;上方写着黑色的楷体"竹清"。一片盛开于秋日庭院的菊花丛,花色丰富、层次分明,配以落叶与古亭剪影,传递恬然自适的生活哲学;上方写着黑色的楷体"菊淡"。所有图片采用统一尺寸与边框样式,呈横向排列。页面底部中央用楷体小字写明“2025年8月,敬请期待”,排版工整、结构清晰,整体风格统一且细节丰富,极具视觉冲击力与品牌调性。

图像编辑

-
-
2.论文详解
简介
图像生成模型领域取得显著进展,尽管如此,两项关键挑战依旧存在。
- 首先,在文本到图像生成方面,让模型输出与复杂多面提示对齐仍是一道难关。作者评估发现,当前最先进的商用模型在面对多行文本渲染、非字母语言渲染、局部文字插入或文字与视觉元素无缝融合等任务时,仍显吃力。
- 其次,在图像编辑领域,使编辑结果与原始图像精准对齐面临双重难题:其一为视觉一致性,即仅修改目标区域而保留其余所有视觉细节;其二为语义连贯性,即在结构变化过程中保持全局语义不变。
为应对复杂提示对齐的挑战,作者构建了一条稳健的数据管道,涵盖大规模采集、标注、过滤、合成增强与类别均衡。随后,作者采用课程学习策略,先从基础文本渲染任务起步,再逐步过渡到段落级、排版敏感的描述,从而显著提升模型对多样化语言——特别是中文等表意语言——的遵从能力。
针对图像对齐难题,作者提出增强的多任务学习框架,在共享潜空间中无缝整合文本到图像、图像到图像以及文本引导图像编辑三类目标。具体而言,输入图像被编码为两组互补特征:语义特征由 Qwen-VL 提取,捕获高阶场景理解与上下文含义;重构特征由 VAE 编码器获得,保留低层视觉细节。两组特征共同注入 MMDiT 架构作为条件信号。这种双重条件设计使模型同时维护语义连贯与视觉一致。
为保证大规模训练的效率与稳定性,作者设计 Producer-Consumer 框架,利用 TensorPipe 进行分布式数据加载与预处理:Producer 负责 VAE 编码、数据 I/O 等预处理任务,Consumer 则基于 Megatron 框架专注分布式模型训练。作者还部署了全面的监控工具,确保大规模训练过程中的可靠收敛与可调试性。
-
模型架构
如图 6 所示,Qwen-Image 的整体架构由三大核心组件协同构成,以实现高保真的文本到图像生成。
- 首先,多模态大语言模型(MLLM)充当条件编码器,负责从文本输入中提取特征。
- 其次,变分自编码器(VAE)作为图像分词器,将输入图像压缩为紧凑的潜空间表示,并在推理阶段将其解码还原。
- 第三,多模态扩散 Transformer(MMDiT)扮演主干扩散模型,对噪声与图像潜变量在文本引导下的复杂联合分布进行建模。
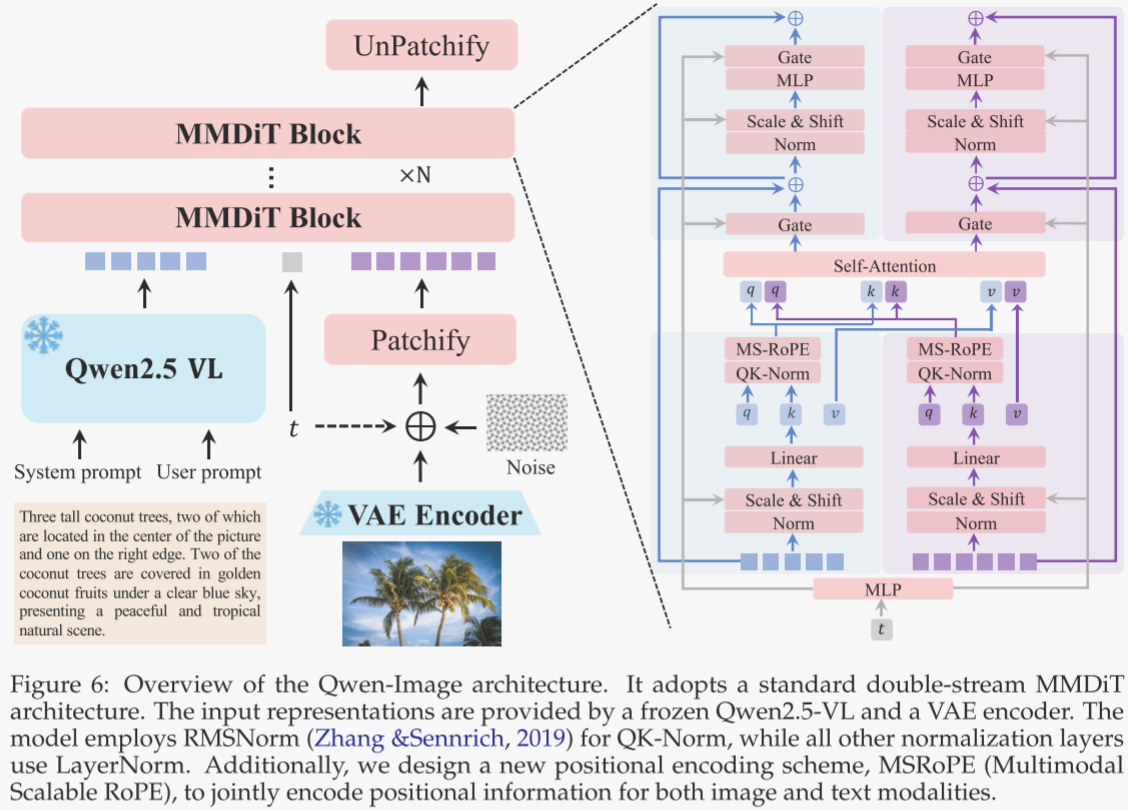
多模态大语言模型(MLLM)
作者选用 Qwen2.5-VL 作为文本输入的特征提取模块,原因有三:其一,该模型的语言与视觉空间已完成对齐,相较纯语言模型更适配文本到图像任务;其二,其语言建模能力依旧强劲,未出现明显退化;其三,它支持多模态输入,使 Qwen-Image 能拓展更多功能,包括图像编辑等。
设图像输入为 x,文本输入为 y。根据用户提供的提示与图像,作者通过 Qwen2.5-VL 提取特征。为引导模型生成更精细的潜表示,并兼顾不同任务中输入模态的差异,作者分别为纯文本输入和图文混合输入设计了专属系统提示,模板见图 7 与图 15。最终,作者以 Qwen2.5-VL 语言主干网络最后一层的隐藏状态作为用户输入的表征。


变分自编码器(VAE)
强大的 VAE 表征是构建高性能图像基础模型的关键。现有做法通常在巨量图像数据集上以 2D 卷积训练图像 VAE,以获得高质量图像表征。作者则希望建立一种更通用的视觉表征,可同时兼容图像与视频。然而,现有联合图像-视频 VAE 普遍存在性能权衡,导致图像重建质量下降。
为此,作者采用“单编码器、双解码器”架构:共享编码器可同时处理图像与视频,并为每种模态配置独立、专用的解码器,从而使当前图像基础模型为未来视频模型奠定骨干。具体而言,作者沿用 Wan-2.1-VAE 的架构,冻结其编码器,仅微调图像解码器。为提升重建保真度,特别是小文本与细粒度细节,作者使用内部构建的富含文本的图像数据集训练解码器;该数据集包含真实文档与合成段落,覆盖字母语言与表意语言。
训练过程中作者发现:
1. 在重建损失与感知损失之间取得平衡,可显著减少重复纹理中常见的网格伪影;
2. 当重建质量提升后,对抗损失因判别器难以提供有效指导而失去作用。
基于以上观察,作者仅使用重建损失与感知损失,并在微调期间动态调整二者比例。有趣的是,仅微调解码器即可显著提升细节表现与小文本渲染效果,为 Qwen-Image 的文本渲染能力奠定坚实基础。定量与定性结果详见第 5.2.1 节。
多模态扩散 Transformer(MMDiT)
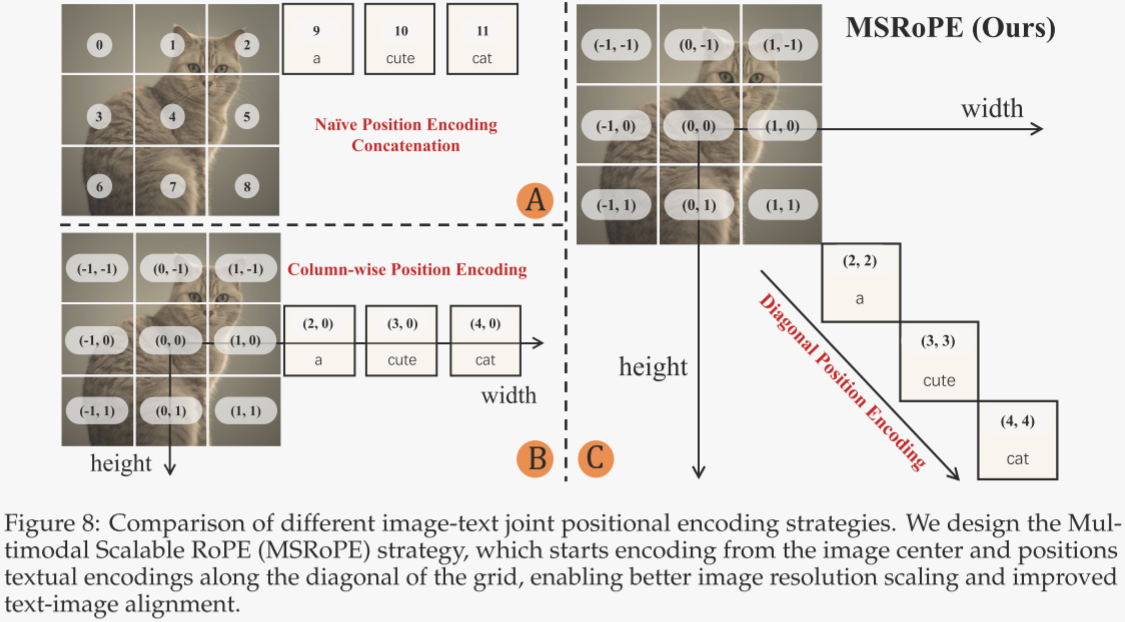
作者采用 Multimodal Diffusion Transformer(MMDiT)来联合建模文本与图像。该方法已在 FLUX 系列与 Seedream 系列等多项工作中被验证有效。在每个模块内部,作者提出一种新的位置编码方式——Multimodal Scalable RoPE(MSRoPE)。如图 8 所示,作者对比了多种文本-图像联合位置编码策略。
在传统 MMDiT 模块中,文本 token 直接拼接在展平后的图像位置编码之后。Seedream 3.0 则引入 Scaling RoPE,将图像位置编码移至图像中心区域,并将文本 token 视为形状为 [1, L] 的 2D token,再使用 2D RoPE 进行图文联合位置编码。尽管这一调整便于分辨率缩放训练,但某些行(例如图 8B 中的第 0 中间行)的文本与图像位置编码会出现同构,使得模型难以区分文本 token 与对应行的图像潜变量 token。同时,如何为文本 token 选取合适的图像行进行拼接亦非易事。
Seedream 3.0 使用了一种叫 Scaling RoPE 的方法:
图像的 patch 位置编码是二维的(如 (-1,0), (0,0), (1,0) 等)。
文本 token 也被当作二维 token 处理,但被统一放在图像的某一“行”或“列”中,比如第 0 中间行。
这就导致:图像的第 0 行 patch 和文本 token 使用了相同的位置编码(例如都是 (0, -1), (0, 0), (0, 1) 等)。
这种“同构”会导致:
混淆:模型在处理注意力时,无法区分“这是图像的第 0 行”还是“这是文本的第 0 行”。
错误对齐:文本 token 可能会错误地与图像的某些 patch 建立注意力关系,影响文本-图像对齐的准确性。
为解决上述问题,作者提出 MSRoPE:将文本输入视为 2D 张量,并在两个维度上赋予相同的位置 ID。如图 8C 所示,文本被概念化地沿图像对角线拼接。该设计在保留图像侧分辨率缩放优势的同时,使文本侧保持与 1D-RoPE 的功能等价,从而无需再为文本寻找最优位置编码。Qwen-Image 的完整架构与配置见表 1。
-
数据
数据收集
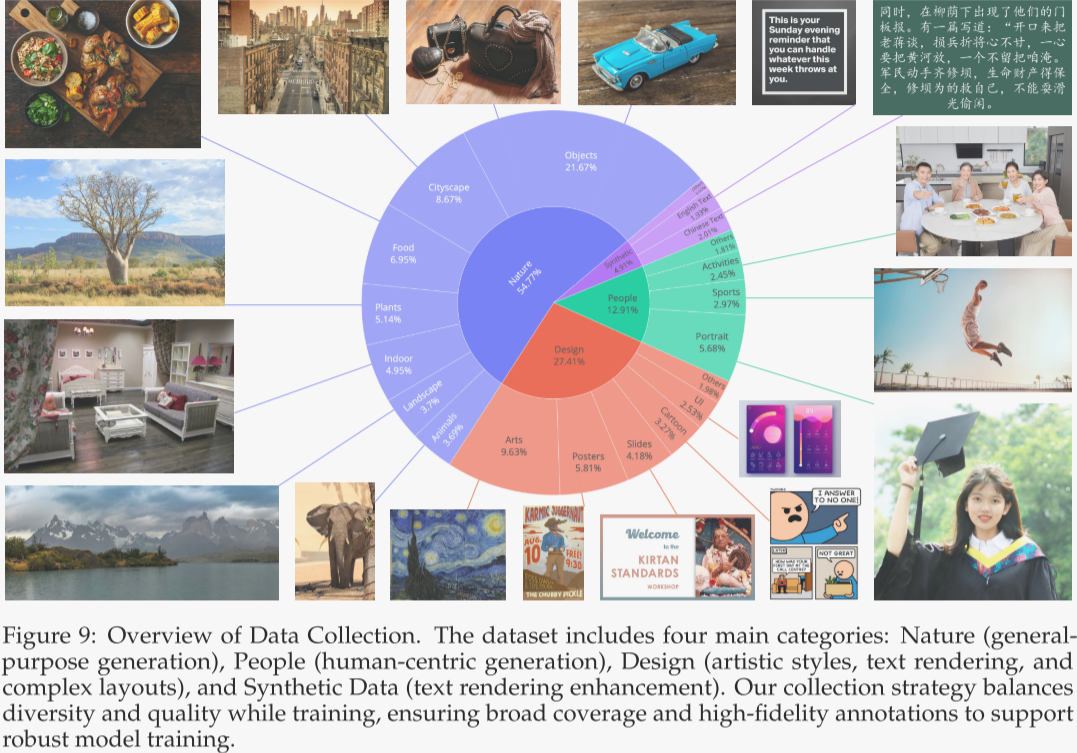
作者系统性地收集并标注了数十亿图文对,以支撑图像生成模型的训练。相比单纯追求原始数据规模,作者更重视数据质量与分布均衡,力求构建能真实反映现实场景且分布均衡、具代表性的数据集。如图 9 所示,数据集被划分为四大领域:自然、设计、人物与合成数据。
- 自然类占比最高,约 55%,涵盖物品、风景、城景、植物、动物、室内、美食等子类;凡是不明确属于人物或设计类的内容亦归入此类。该通用大类为提升模型生成逼真、多样化自然图像的能力奠定基石。
- 设计类约占 27%,主要包括海报、界面、演示文稿等结构化视觉内容,以及绘画、雕塑、工艺品、数字艺术等艺术形式。这些素材富含文本元素、复杂版式与设计语义,对强化模型在遵循艺术风格、文本渲染及版式设计指令方面的能力尤为关键。
- 人物类约占 13%,涵盖肖像、体育、人类活动等子类,用以提升模型生成逼真、多样化人物图像的能力,确保用户体验与落地效果。
- 合成类约占 5%。需特别说明,此处的合成数据并非由其他 AI 模型生成,而是通过受控的文本渲染技术合成(见 §3.4)。作者对由其他 AI 模型产出的低质量或误导性图像持谨慎态度,因其可能引入视觉伪影、文本扭曲、偏差与幻觉,削弱模型泛化能力与可靠性。
数据过滤
为在图像生成模型的迭代开发过程中持续筛选高质量训练数据,作者设计了一套七阶段递进式过滤流程,如图 10 所示。各阶段按顺序逐步应用于训练过程,数据分布随时间不断优化。合成数据自第四阶段起引入,此时基础模型已具备一定稳定性。以下逐一详述各阶段。
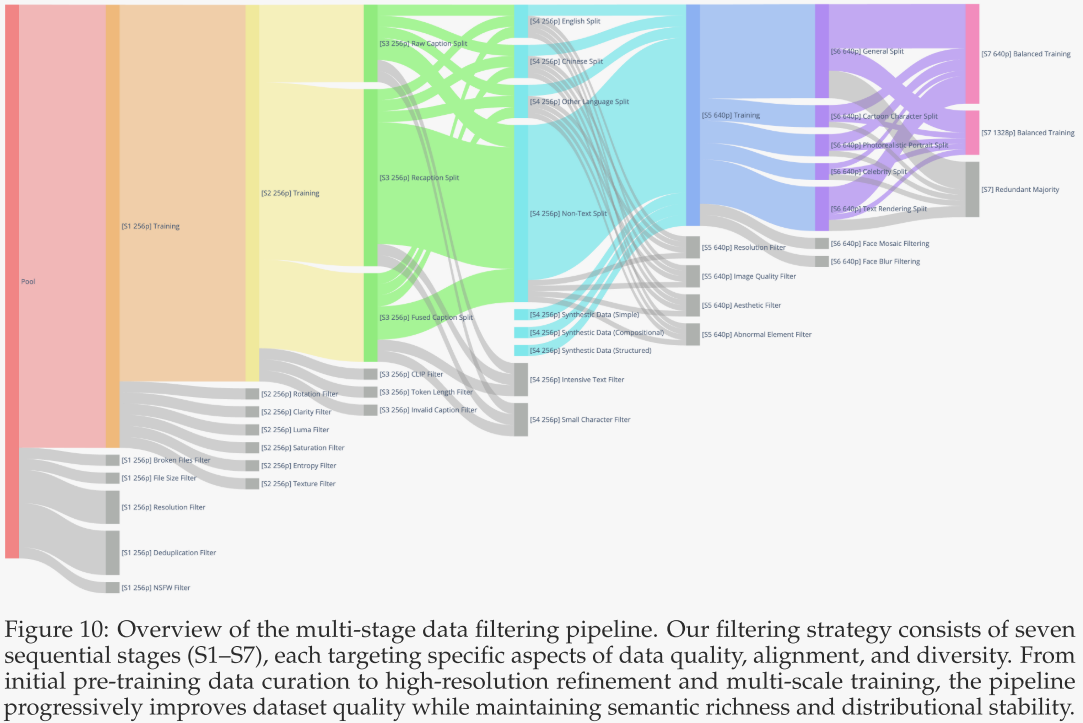
阶段 1:初始预训练数据整理
模型首先以 256p 分辨率(256×256,可兼容 1:1、2:3、3:2、3:4、4:3、9:16、16:9、1:3、3:1 等纵横比)进行训练。为提升数据质量,作者依次启用以下过滤器:
- 破损文件过滤:剔除损坏或截断文件,此类文件通常伴随异常小的体积。
- 文件大小过滤:移除体积过小的图像。
- 分辨率过滤:删除原图分辨率低于 256p 的样本。
- 去重过滤:消除重复或近似重复的图文对。
- NSFW 过滤:排除包含色情、暴力或其他不当内容的图像。
阶段 2:图像质量提升
- 本阶段旨在系统提升数据集图像质量:
- 旋转过滤:依据 EXIF 元数据移除明显旋转或翻转的图像。
- 清晰度过滤:剔除模糊或失焦图像,仅保留锐利清晰的样本。
- 亮度过滤:移除过曝或过暗图像。
- 饱和度过滤:去除色彩过度饱和、显人工痕迹或不真实调色的图像。
- 熵过滤:删除低熵图像,这类图像通常包含大片均匀区域或信息量极低。
- 纹理过滤:筛除纹理过于复杂、易引入噪声或非语义图案的图像。
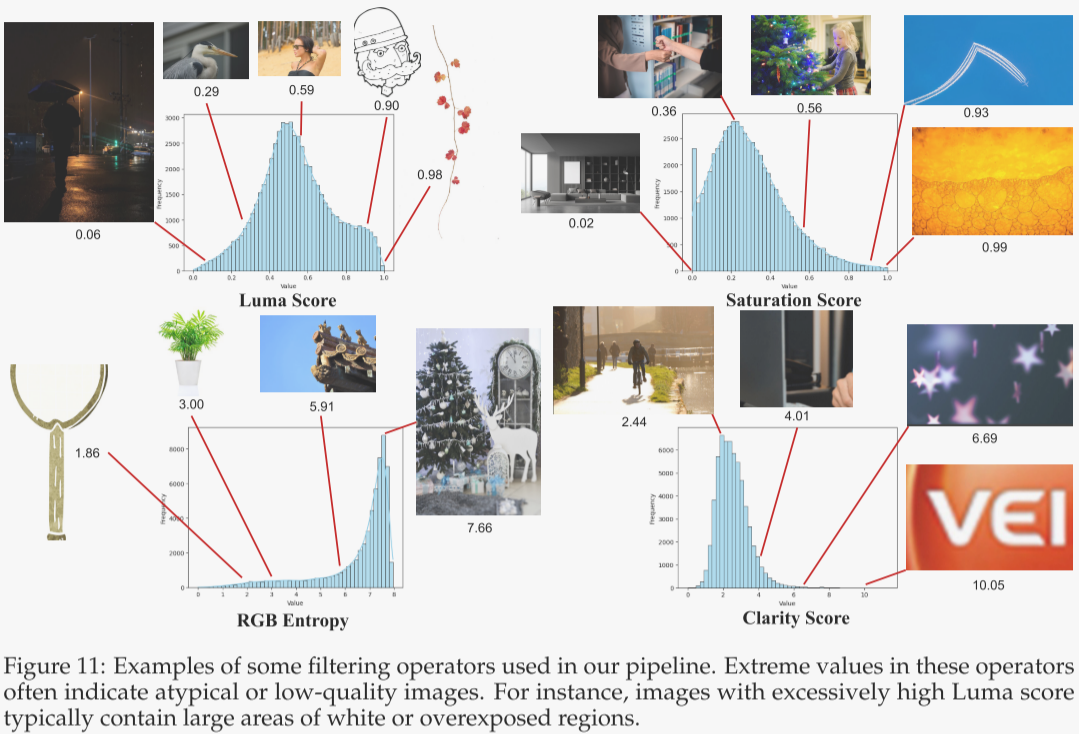
图 11 展示了本阶段所用部分过滤算子的示例。
阶段 3:图文对齐优化
本阶段旨在提升文本描述与视觉内容的一致性。为均衡训练数据分布,作者将数据集依标题来源拆分为三大子集:原始标题子集、重标注子集、融合标题子集。
- 原始标题子集保留网站自带的标题、标签等元数据。虽噪声较大,却可增强模型对短文本的鲁棒性,并补充现实世界知识。
- 重标注子集由最先进的 Qwen-VL Captioner 生成,提供更详尽、结构化的描述;受模型局限,部分专有名词仍可能无法准确识别。
- 融合标题子集将原始与合成标题合并,兼顾通识与细节。
为进一步对齐,作者对原始标题子集先后应用中文 CLIP 过滤器和 SigLIP 2 过滤器,剔除图文不匹配样本;再用 Token 长度过滤器去除超长标题;无效标题过滤器丢弃诸如“抱歉,无法为此图生成标题”等异常内容。
阶段 4:文本渲染增强
本阶段聚焦提升模型在图像内渲染文本的能力,这对实现高保真文本至关重要。作者将阶段 3 的数据按文本出现与否及其语言分为四类:英文子集、中文子集、其他语言子集、无文本子集,以保证多语言训练均衡。针对低频字符、混合语言、字体多样等挑战,作者引入合成文本渲染数据。随后,通过密集文本过滤器与小字符过滤器移除文本过密或字号过小的样本,因这类样本难以准确标注且难以清晰渲染。
阶段 5:高分辨率精修
本阶段模型转入 640p 分辨率训练,并进一步精炼数据集以保证高质量与美感。
- 图像质量过滤器剔除过曝、欠曝、模糊、压缩伪影等缺陷图像。
- 分辨率过滤器确保所有样本满足最低分辨率要求。
- 美感过滤器筛除构图或视觉吸引力差的图像。
- 异常元素过滤器去除含水印、二维码、条形码等干扰元素。
阶段 6:类别平衡与肖像增强
通过误差分析识别表现不佳的类别后,作者将数据集重划为三大主类:通用、肖像、文本渲染,以便按类别重采样。作者利用关键词检索与图像检索技术,为目标子集补充样本,提高覆盖率。为提升肖像生成质量,作者先从人物类检索高清真人肖像、卡通角色与名人图像,再生成强调面部特征、表情、服饰及背景、光影、氛围的合成标题,从而增强图像质量与指令遵循能力。额外过滤器去除含马赛克或模糊人脸的图像,以避免隐私风险并确保模型在人像任务上的鲁棒性。
阶段 7:均衡多尺度训练
最终阶段,作者联合使用 640p 与 1328p 分辨率进行训练。若强制采用 1328p 阈值,将造成大量数据丢失并扭曲分布。为此,作者借鉴 WordNet 的设计思想,构建层级化图像分类体系,对阶段 6 数据重新归类;在每类中仅保留质量与美感最高的样本。此外,作者设计专门的再采样策略,针对文本渲染数据的长尾 token 分布进行平衡。该均衡多尺度训练使模型在适应更高分辨率、提升细节生成的同时,保留既有通用知识并确保稳定收敛。
-
数据标注
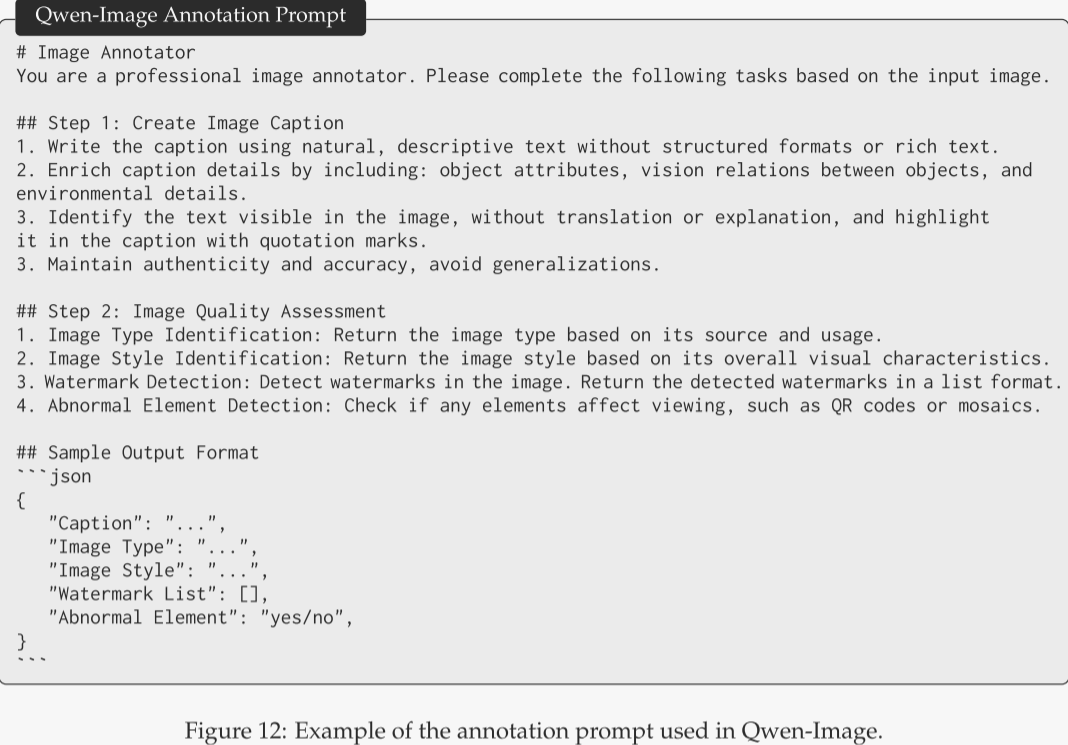
在数据标注流程中,作者利用高性能的图像描述模型(Qwen2.5-VL)一次性生成两方面信息:既包括详尽的图像描述,也涵盖以结构化格式呈现的关键属性与质量元数据。作者并未将描述生成与元数据提取拆分为独立任务,而是让模型在生成文字描述的同时,并行输出 JSON 格式的结构化字段。图像中的物体属性、空间关系、场景上下文以及可见文本的原样转录均被写入描述;而图像类型、风格、水印存在与否、异常元素(如二维码、面部马赛克)等信息则以键值方式记录。借助先进描述模型,该方案超越传统图像描述范式,单轮即可同时产出深度描述与结构化元数据,示例见图 12。
数据合成
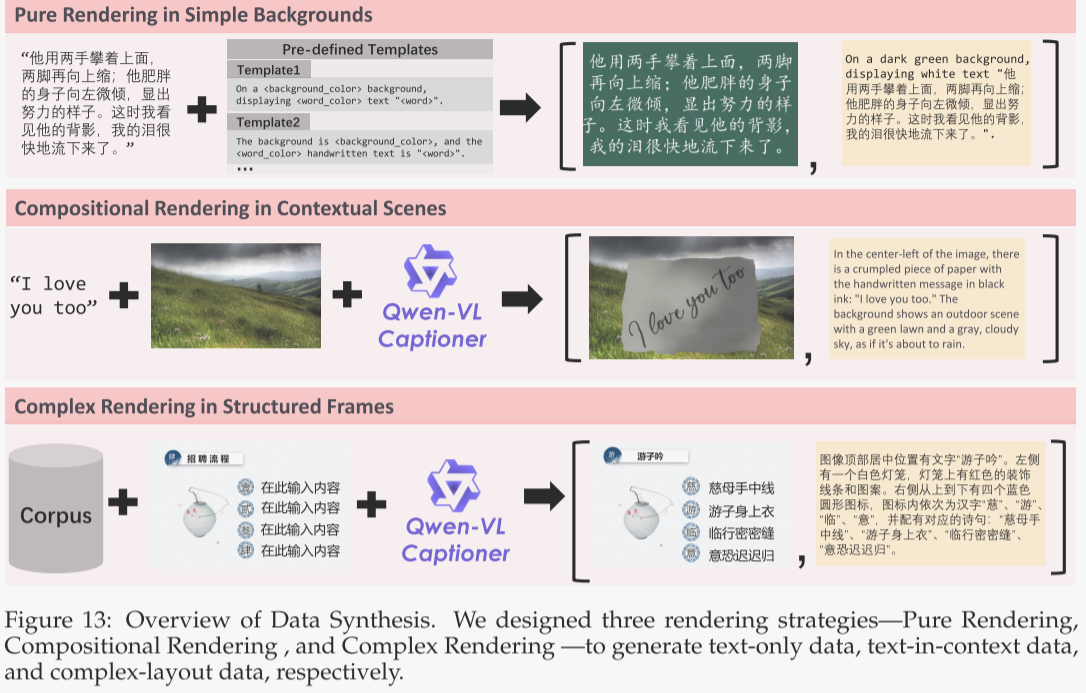
真实场景中的文本呈现呈长尾分布,尤其像中文这样的非拉丁语系,大量字符出现频率极低。仅依赖自然采集的文本难以为这些罕见字符提供充足曝光。为此,作者提出一条多阶段文本感知图像合成管线,综合三种互补策略:纯渲染、组合渲染与复杂渲染,详情如下。
- 纯渲染——简洁背景
- 此策略最直接、高效,用于训练模型识别与生成中英等字符。文本段落提取自大规模高质量语料,经动态排版算法在干净背景上渲染,字体大小与间距随画布尺寸自适应。为保障合成质量,若段落中任意字符因缺字或渲染失败无法显示,则整段丢弃。这一严格过滤确保进入训练集的全部样本字符完整且清晰,维持字符级文本渲染的高保真度。
- 组合渲染——情境场景
- 该策略将合成文本嵌入真实视觉环境,模拟日常场景中的文字呈现。文本被渲染为书写或打印在纸、木板等物理介质上的效果,再无缝合成到多样背景,形成视觉连贯的场景。作者使用 Qwen-VL Captioner 为每张合成图生成描述性标题,捕捉文本与周边视觉元素的上下文关系,从而显著提升模型在现实情境中的文本理解与生成能力。
- 复杂渲染——结构化模板
- 为增强模型处理复杂、排版敏感指令的能力,作者提出基于预定义模板(如 PPT 幻灯片或 UI 原型)的程序化编辑合成策略。规则系统可自动替换占位文本,同时保持版式结构、对齐和格式完整。这些合成样例帮助模型理解并执行多行文本渲染、精确空间布局及字体颜色控制等细节指令。
综上,作者的数据合成框架系统性地解决了自然图像中文字内容稀缺且不平衡的问题。通过整合从简洁到真实再到结构复杂的多种渲染策略,框架生成了全面且多样的训练数据。
-
训练
预训练
作者采用 Flow Matching 训练目标对 Qwen-Image 进行预训练。该目标通过常微分方程(ODE)实现稳定的学习动态,同时与最大似然目标保持等价。
形式上,设 为输入图像的潜变量,经过变分自编码器(VAE)编码器
得到潜表示
,其中
。接着,从标准多元正态分布采样随机噪声向量
。对于用户输入 S(可以是纯文本、提示或图文组合),通过多模态大语言模型
获得引导潜变量
,其中
。此外,从 logit-normal 分布采样扩散时间步
。
根据 Rectified Flow,时间步 t 处的中间潜变量 及其对应的速度
计算为
模型被训练以预测该目标速度,损失函数定义为模型输出速度 与真实速度
之间的均方误差:
其中 表示训练数据集。
Producer-Consumer 框架
为了在扩展到大规模 GPU 集群时同时保证高吞吐与训练稳定性,作者构建了 Producer–Consumer 框架,将数据预处理与模型训练彻底解耦。该设计使两阶段可异步运行并保持各自最优效率,且支持在训练过程中实时更新数据管线而无需中断任务。
- Producer 端:原始图文对首先按照预设标准(如分辨率、检测算子)进行过滤;随后通过 MLLM(如 Qwen2.5-VL)与 VAE 编码为潜变量;处理后的样本按分辨率分组存入高速缓存桶,并写入共享的“位置感知”存储,供 Consumer 立即拉取。
- 传输层:Producer 与 Consumer 之间采用定制 HTTP 传输层,原生支持 RPC 语义,实现异步、零拷贝调度。
- Consumer 端:部署在 GPU 高密度集群,仅负责训练。所有数据前处理被完全卸载到 Producer,使得 Consumer 节点可将全部算力用于训练 MMDiT。模型参数按 4 路张量并行切分;每个数据并行组异步从 Producer 拉取已处理批次。
分布式训练优化
鉴于 Qwen-Image 参数量巨大,仅使用 FSDP 无法将模型完整放入单卡显存,因此作者基于 Megatron-LM 进行训练,并实施以下优化:
1. 混合并行策略:结合数据并行与张量并行,借助 Transformer-Engine 库实现张量并行的无缝自动切换。对于多头自注意力,作者采用 head-wise 并行,相比沿 head 维度的张量并行,可进一步降低同步与通信开销。
2. 分布式优化器与激活检查点:为在最小重算开销下缓解显存压力,作者对比了激活检查点与分布式优化器。实验(256 分辨率多尺度训练配置)显示:启用激活检查点可将单卡显存占用从 71 GB 降至 63 GB(-11.3%),但每步时间从 2 s 增至 7.5 s(+3.75×)。权衡后,作者最终关闭激活检查点,仅使用分布式优化器。训练中,all-gather 以 bfloat16 执行,梯度 reduce-scatter 使用 float32,兼顾计算效率与数值稳定性。
训练策略
作者采用多阶段预训练策略,逐级提升数据质量、图像分辨率与模型性能。各阶段整合以下训练策略:
1. 分辨率递进:从低分到高分:输入分辨率由 256×256(支持 1:1、2:3、3:2、3:4、4:3、9:16、16:9、1:3、3:1 等多比例)逐步提升至 640×640,最终达到 1328×1328。更高分辨率使模型捕获更细粒度的特征,从而增强泛化。例如,从低分到高分的花卉图像训练后,模型可分辨花瓣纹理与色彩渐变。
2. 文本渲染融入:从非文本到文本:传统视觉数据集文本稀少,字形生成效果不佳,中文尤甚。作者逐步引入在自然背景上叠加渲染文本的图像,让模型先学通用视觉表征,再习得文本渲染能力。
3. 数据质量精修:从海量到精选:初期使用大规模数据集建立基础视觉生成能力;随后逐步启用更严格的数据过滤,仅保留最相关、高质量的样本,以提升训练效率与模型性能。
4. 数据分布均衡:从失衡到平衡:训练全程持续在领域与分辨率维度上均衡数据分布,防止模型对特定领域或分辨率过拟合,确保在稀缺场景下仍能生成高保真、细节丰富的图像,实现稳健泛化。
5. 合成数据增强:从真实到合成:超现实风格或富含高分辨率文本的样本在真实数据中稀缺甚至缺失,且部分高质量样本数量有限。作者借助数据合成技术补充此类样本,丰富数据集并扩大视觉领域覆盖,使模型在更广泛场景下具备鲁棒泛化能力。
-
后训练
本节介绍 Qwen-Image 的后训练框架,分为两个阶段:监督微调(SFT)与强化学习(RL)。
监督微调(SFT)
在 SFT 阶段,作者构建了按语义类别分级的高质量数据集,并辅以细致人工标注,以弥补模型的特定缺陷。入选图像必须清晰、细节丰富、亮度适中且具真实感,从而引导模型生成更逼真、更精细的内容。
-
强化学习(RL)
作者采用两种 RL 策略:
DPO 擅长一步式流匹配在线偏好建模,计算开销小;GRPO 则在训练阶段进行 on-policy 采样,并用奖励模型评估每条轨迹。为发挥离线偏好学习的可扩展优势,作者先以 DPO 进行大规模 RL,再以 GRPO 做小范围精修。
-
直接偏好优化(DPO)
数据准备
对于 DPO 训练数据,作者在相同提示下用不同随机种子生成多幅图像,由人工标注员从中选出最优与最差图像。数据分为两类:
- 带参考(金标)图像的提示:标注员先比较生成结果与参考图,若差距明显,则将差异最大的生成图标记为拒绝样本。
- 无参考图像的提示:标注员在生成结果中直接选出最优和最差,或标记所有结果均不合格。
在生成图像 的基础上,作者将 DPO 目标建立在流匹配训练准则之上,公式如下:
与
分别表示策略模型和参考模型计算出的偏好差异,
为缩放参数,
为 Sigmoid 函数。
组相对策略优化(GRPO)
在用 DPO 完成训练后,作者采用 Flow-GRPO 框架进行更精细的微调。给定文本隐状态 h,流模型预测优势函数:
其中 R 为奖励模型。随后 GRPO 的训练目标为
其中 。
在采样轨迹 时,若采用流匹配采样(式 1)
,则过程无随机性,不利于探索。因此作者将采样改写为随机微分方程(SDE)以注入噪声:
其中 表示随机强度。使用 Euler–Maruyama 离散化可得
其中 。作者以上式采样轨迹。式 (5) 中的 KL 散度可得到闭式解:
-
多任务训练
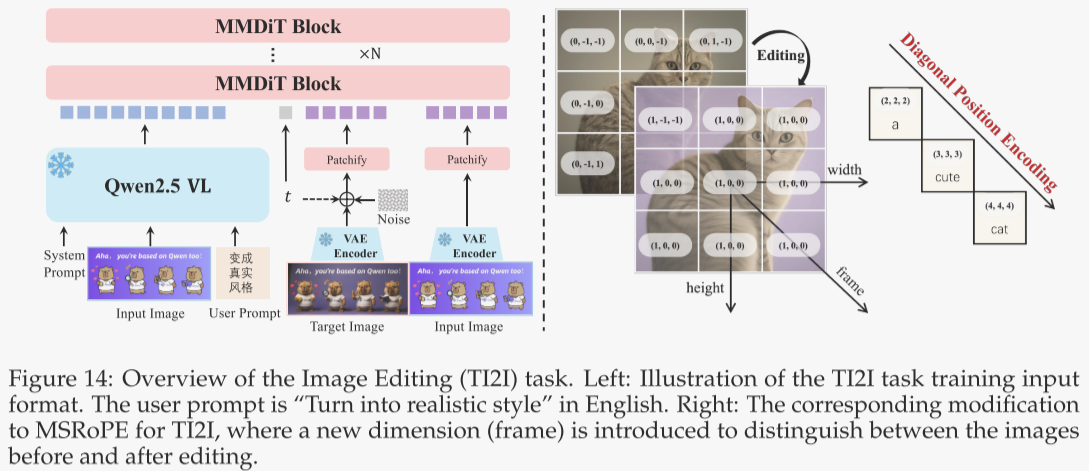
除文本到图像(T2I)生成外,作者将基座模型进一步扩展至同时接受文本与图像输入的多模态生成任务,涵盖指令式图像编辑、新视角合成,以及深度估计等计算机视觉任务,这些均可视为广义图像编辑。依托 Qwen2.5-VL 的原生图像输入能力,用户提供的图像经 Vision Transformer(ViT)编码为视觉块,与文本 token 拼接后送入模型。作者设计了图 15 所示的系统提示,将输入图像与文本指令共同输入 Qwen-Image MMDiT 的文本流。
受先前工作启发——引入 VAE 编码有助于保持角色与场景一致性——作者进一步把输入图像经 VAE 编码后的潜变量沿序列维度与带噪图像潜变量拼接,输入图像流。为了让模型区分多张图像,作者在 MSRoPE 基础上新增时间(帧)维度,与原有高、宽维度共同定位图像块(图 14 右侧)。实验表明,来自 MLLM 的视觉语义嵌入能提升指令遵循能力,而像素级 VAE 嵌入则进一步增强视觉保真度及与用户图像的结构一致性。

-
实验
人工评测
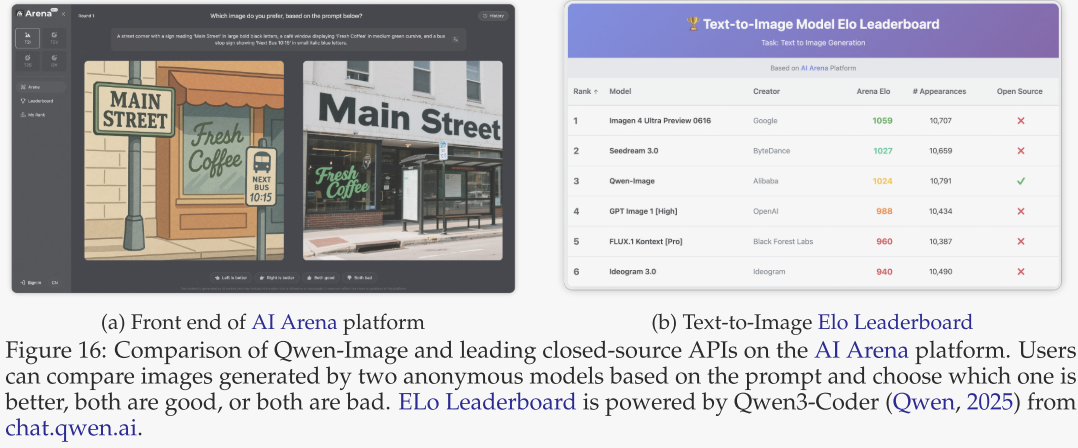
为全面评估 Qwen-Image 的通用图像生成能力,并与业界领先的闭源 API 进行客观比较,作者构建了 AI Arena²——一个基于 Elo 评分系统的开放基准平台(见图 16)。AI Arena 提供公平、动态的双人对战环境:每轮随机选取两个模型在同一提示下生成的图像,以匿名方式呈现给用户进行二选一投票;投票结果通过 Elo 算法实时更新个人与全球排行榜,使开发者、研究人员和普通用户都能从整体视角衡量模型表现。
具体而言,作者精心筛选了约 5,000 条覆盖题材、风格、摄影视角等多维度的多样化提示,并邀请 200 余名来自不同专业背景的评估者参与。AI Arena 现已向公众开放,任何人都可以加入模型对比。未来平台将扩展至图像编辑、文本-音频、文本-视频、图像-视频等多模态生成任务,并通过多种技术手段检测并剔除作弊或无效数据,确保评测客观独立。
作者选取五款当前最优的闭源 API 作为 Qwen-Image 的对手:Imagen 4 Ultra Preview 0606、Seedream 3.0、GPT Image 1 [High]、FLUX.1 Kontext [Pro] 与 Ideogram 3.0。截至目前,每款模型均参与至少 10,000 场对战,保证评测稳健公平。鉴于多数闭源 API 对中文文本支持不稳,作者在提示中剔除了含中文文本的题目,以维持结果客观。
如图 16 所示,Qwen-Image 作为唯一开源的图像生成模型,在 AI Arena 中位列第三,虽落后榜首 Imagen 4 Ultra Preview 0606 约 30 个 Elo 分,但领先 GPT Image 1 [High] 与 FLUX.1 Kontext [Pro] 等模型逾 30 分。该结果确立了 Qwen-Image 作为一款强大开源图像生成模型的地位,为开发者、研究者和用户提供了高性能且广泛可用的解决方案。
-
定量结果
VAE 重建性能
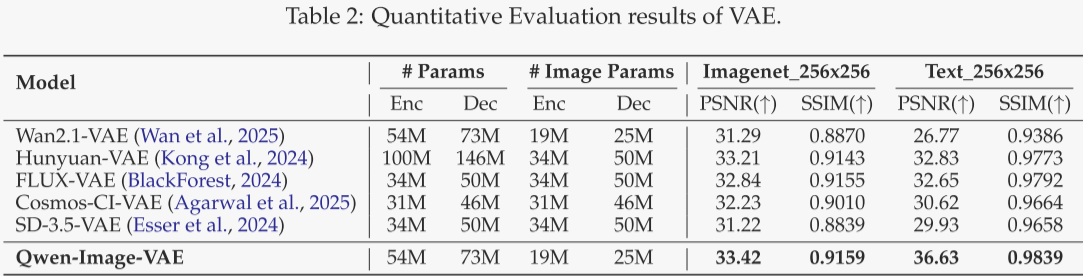
作者以峰值信噪比(PSNR)和结构相似度(SSIM)为指标,对当前最先进的图像分词器进行定量对比。所有 VAE 均采用 8×8 压缩率,潜变量通道维度为 16。其中 FLUX-VAE、Cosmos-CI-VAE 与 SD-3.5-VAE 为纯图像分词器;Wan2.1-VAE、Hunyuan-VAE 与 Qwen-Image-VAE 为联合图像-视频分词器。为保证公平,表 2 中的 “Image Params” 已将联合模型的 3D 卷积折算为等效 2D 卷积后再统计。遵循惯例,所有模型均在 ImageNet-1k 验证集(256×256)上测试通用域性能。为进一步检验小文本的重建能力,作者还在内部富文本语料(涵盖 PDF、PPT、海报及合成文本,多语言)上进行评估,并以 float32 精度计算指标。
表 2 显示,Qwen-Image-VAE 在所有指标上均达到当前最佳重建性能。尤其值得注意的是,在处理图像时,其编码器仅激活 19 M 参数、解码器仅激活 25 M 参数,在重建质量与计算效率之间实现了最佳平衡。
文本到图像生成性能
作者从“通用生成能力”与“文本渲染能力”两个维度评估 Qwen-Image 在文本到图像(T2I)任务上的表现。
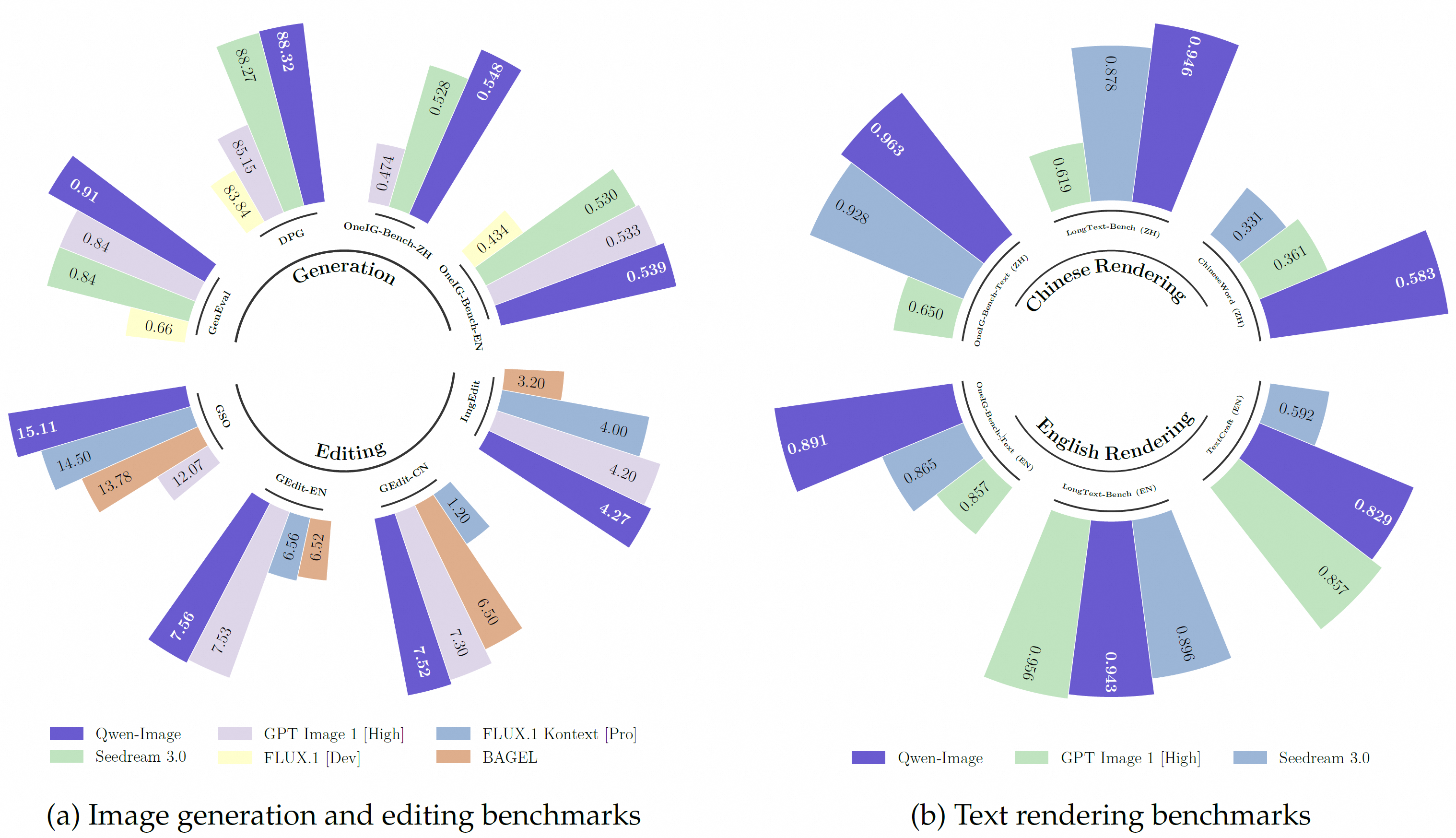
通用生成能力:作者在四个公开基准上进行评测:DPG、GenEval、OneIG-Bench 与 TIIF,它们全面衡量模型依据文本提示生成高质量、语义一致图像的能力。
文本渲染能力
- 英文:采用专为评估英文可读性设计的 CVTG-2K 基准。
- 中文:针对缺乏标准评测的现状,作者发布新基准 ChineseWord,用于系统评估汉字渲染。
- 长文本:在 LongText-Bench 上同时测试中英文长文本渲染。
基准结果
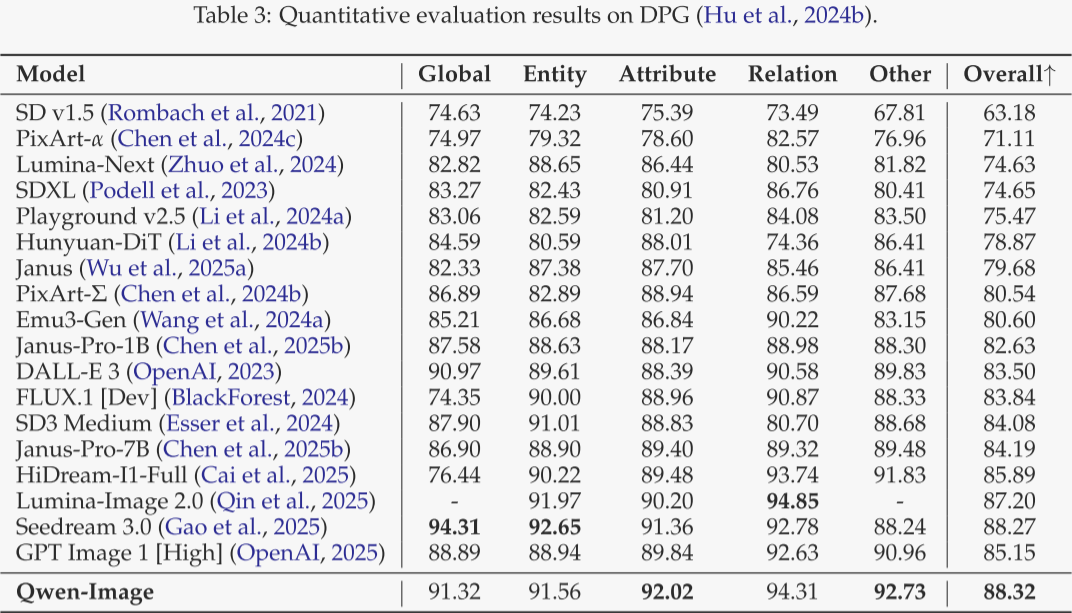
DPG(表 3)
包含 1 000 条稠密提示,可细粒度衡量提示遵循度。Qwen-Image 获得最高总得分,尤其在属性等维度全面领先,显示出色的提示跟随能力。
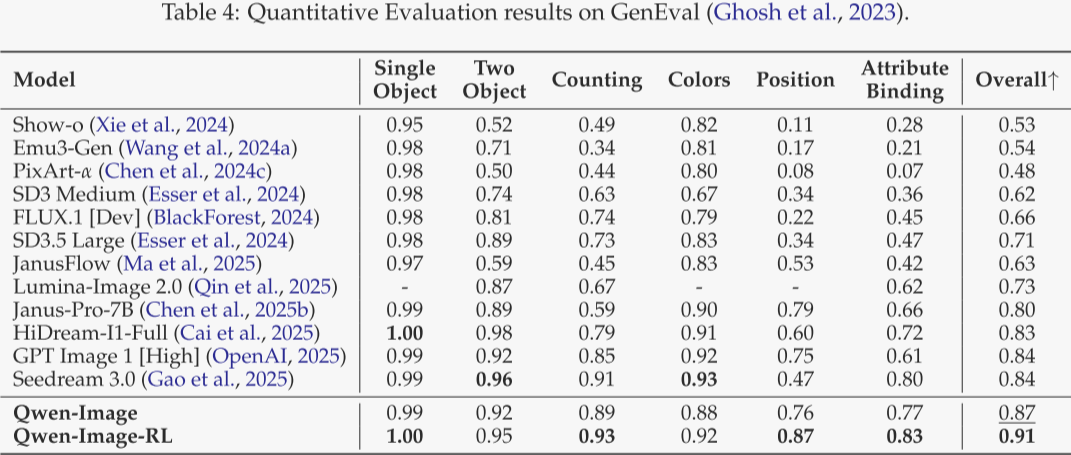
GenEval(表 4)
聚焦以组合提示为核心的对象级生成。作者的 SFT 模型已超越 Seedream 3.0 与 GPT Image 1 [High];经 RL 微调后得分升至 0.91,是唯一突破 0.9 的基础模型,彰显卓越的可控生成能力。
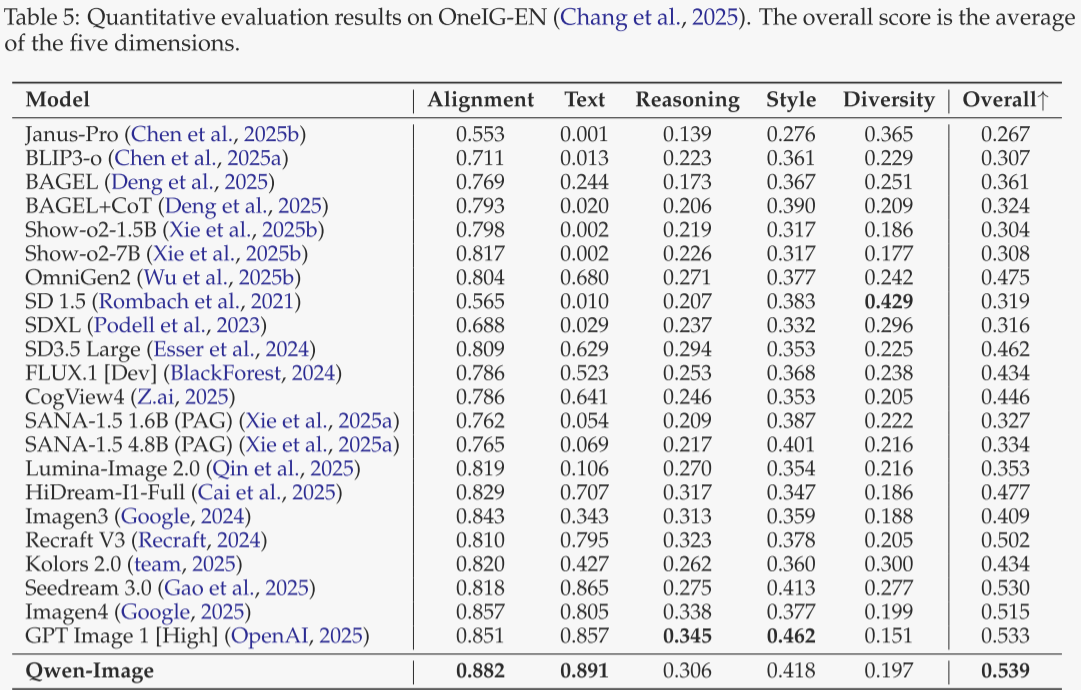
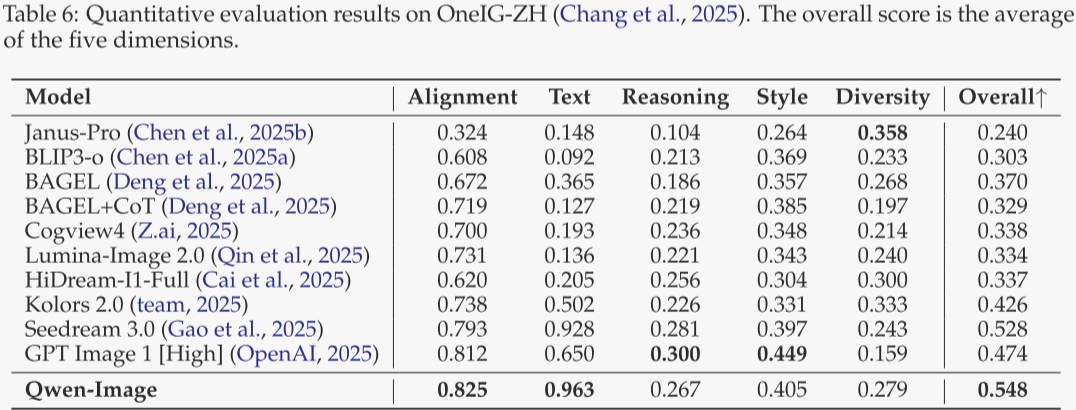
OneIG-Bench(表 5 与表 6)
覆盖中英双语、多维度的综合 T2I 评测。Qwen-Image 在两条赛道上均获最高平均分;在“对齐”与“文本”维度均排名第一,证实其提示遵循与文本渲染优势。
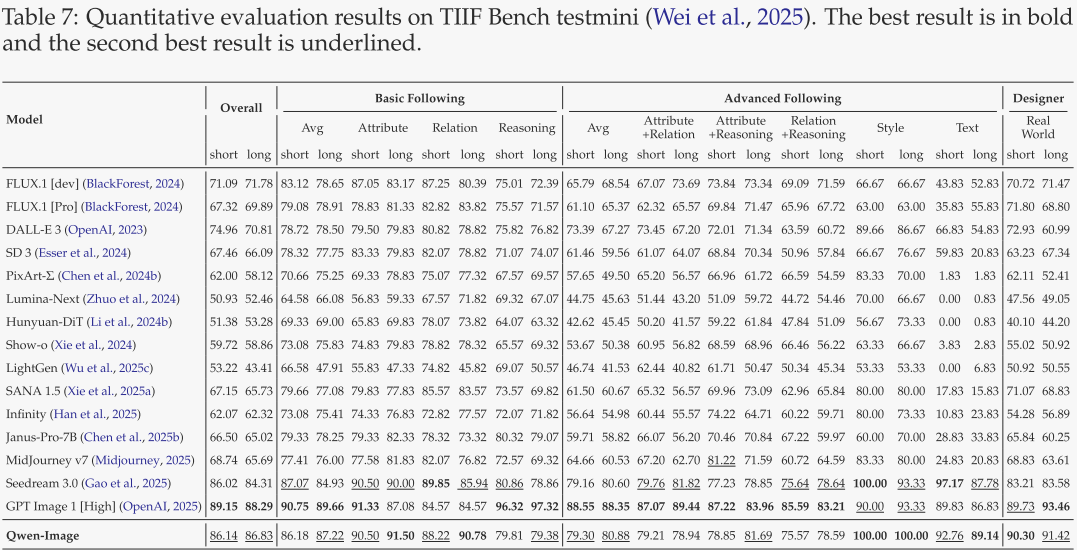
TIIF mini(表 7)
用于系统评估模型对复杂文本指令的理解与执行。Qwen-Image 排名第二,仅次于 GPT Image 1,再次验证其强大的指令跟随能力。
CVTG-2K
表 8 报告了作者在 CVTG-2K 基准上的英文渲染结果。该基准包含 2000 条提示,每条要求在生成图像上渲染 2–5 处英文。作者使用词准确率、NED、CLIPScore 三项指标衡量文本渲染精度。结果显示,Qwen-Image 的表现与当前最先进模型相当,凸显其强劲的英文文本渲染能力。
ChineseWord
表 9 展示了作者新提出的 ChineseWord 基准结果,该基准用于字符级中文文本渲染评估。依据《通用规范汉字表》,作者将汉字分为三级难度:一级 3500 字、二级 3000 字、三级 1605 字,并设计若干提示模板,要求模型生成仅含单个汉字的图像。在所有三级难度中,Qwen-Image 均获得最高渲染准确率,体现出卓越的中文文本渲染能力。
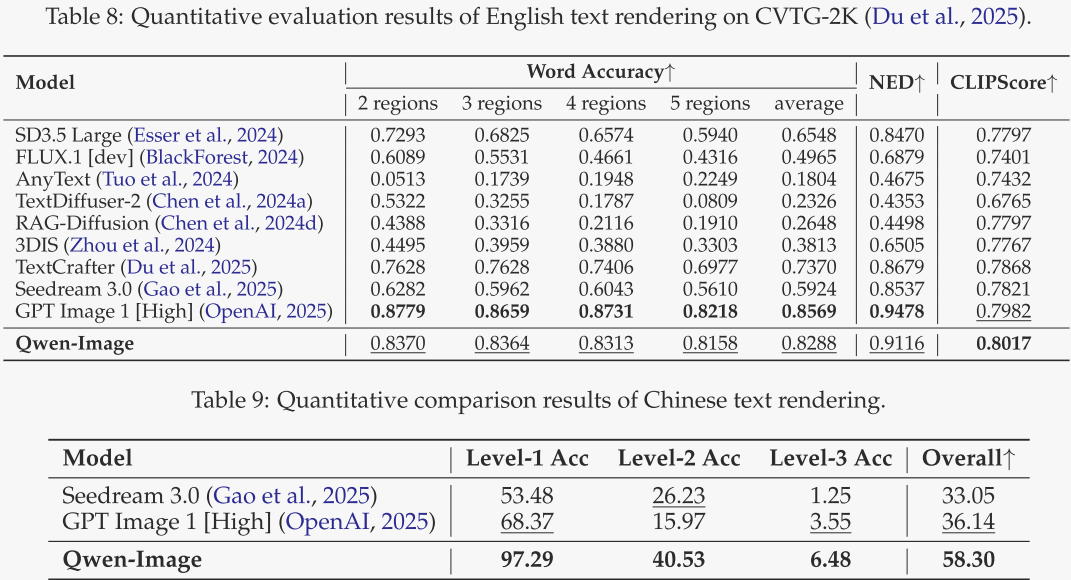
LongText-Bench
表 10 给出 LongText-Bench 的结果,该基准专为评估模型精确渲染长文本而设,共包含 160 条提示,覆盖八种场景。结果显示,Qwen-Image 在长中文文本上获得最高准确率,在长英文文本上取得第二高准确率,充分展现了其出色的长文本渲染能力。
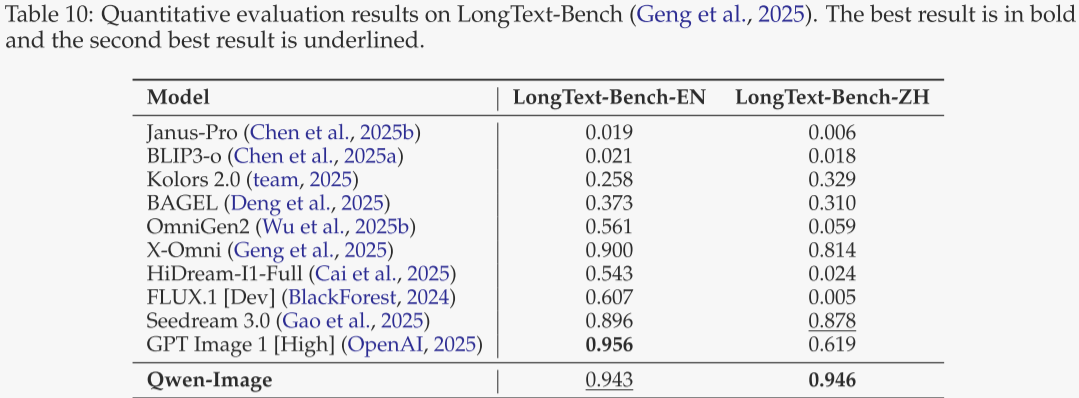
图像编辑性能
作者进一步训练了支持多任务的 Qwen-Image 版本,可同时以文本和图像为条件完成图像编辑(TI2I)。评测分为两类任务:
- 通用图像编辑:在 GEdit 与 ImgEdit 两个基准上,测试模型依据文本-视觉指令完成开放式编辑的能力。
- 3D 视觉任务:在新视角合成与深度估计上,评估模型的空间理解与生成能力;这些任务要求模型根据输入图像及对应文本推断并生成一致的空间信息。
以上任务均归入 TI2I 范畴,体现了作者方法在多模态场景中的通用性。
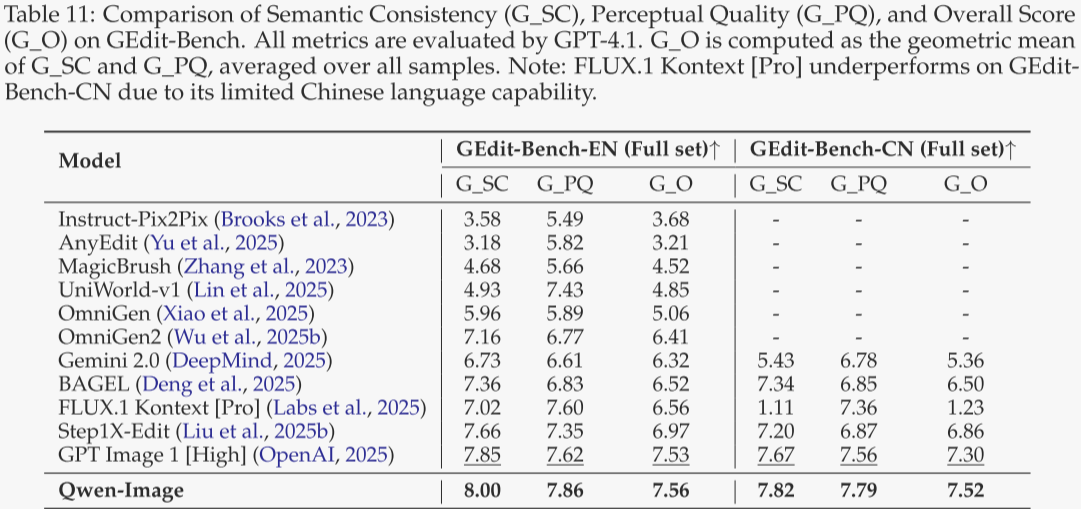
GEdit
表 11 给出 GEdit-Bench 结果,该基准以 11 类真实用户指令评估编辑模型,采用语义一致性 SQ、感知质量 PQ 及综合得分 O(0–10 分)。Qwen-Image 在中、英文双榜均排名第一,显示出强劲的编辑能力及多语言泛化性能。
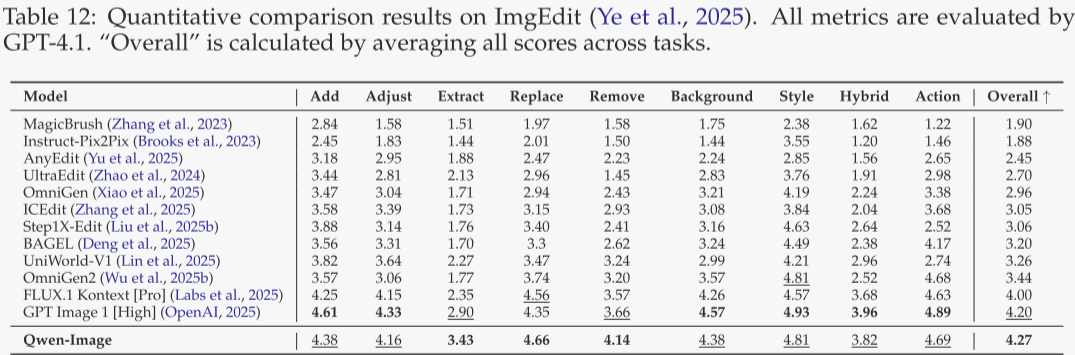
ImgEdit
表 12 展示 ImgEdit 基准结果,该基准涵盖 9 种常见编辑任务、共 734 个真实测试用例,指标包括指令遵循、编辑质量与细节保留(1–5 分)。Qwen-Image 综合排名第一,紧随其后的为 GPT Image 1 [High],体现出强劲的指令式编辑性能。
新视角合成
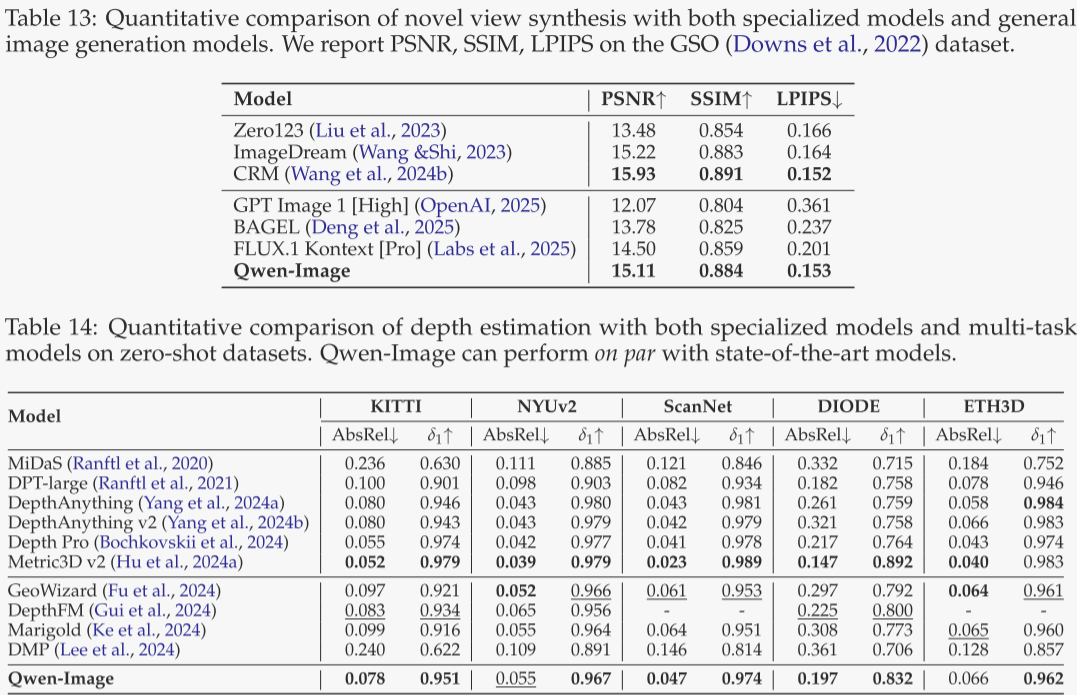
表 13 给出在 GSO 数据集上的新视角合成结果。作者以“左转 90°,一只狗”等提示驱动模型生成 3D 物体的新视角,并与真值图像比对。Qwen-Image 在基线中表现突出,取得了新视角合成的最佳成绩。
深度估计
表 14 汇总了在 NYUv2、KITTI、ScanNet、DIODE、ETH3D 五个常用数据集上的结果。训练时作者以 DepthPro 为教师模型提供深度监督,遵循 DICEPTION 的协议。值得注意的是,这些结果均通过单独的监督微调(SFT)获得,以检验模型对任务的本征理解能力。Qwen-Image 在基于扩散的模型中表现极具竞争力,并在多项关键指标上达到了当前最佳水平。
-
-
总结
本文介绍了 Qwen-Image,一个由阿里巴巴 Qwen 团队开发的新一代图像生成基础模型,专注于 复杂文本渲染 与 精准图像编辑 两大核心能力。该模型在多个公开基准(如 GenEval、DPG、OneIG-Bench、GEdit、ImgEdit、LongText-Bench、ChineseWord 等)中均取得了 当前最优(SOTA)水平,尤其在中文文本生成与长文本渲染方面显著优于现有模型。