零 shot 语义+在线闭环:深度学习让机器人学会“主动”
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
在当下,机器人与深度学习的融合正成为AI领域的核心发展趋势,相关研究在顶会顶刊上热度居高不下。从ICLR到CoRL,诸多前沿成果不断涌现,展现出该技术的巨大潜力。
本文精心整理了3篇聚焦机器人与深度学习融合的前沿论文,旨在助力大家洞悉前沿动态、把握研究思路,以便更好地应用于自身研究,有需要的读者可自行取用 。
Incremental Language Understanding for Online Motion Planning of Robot Manipulators
方法:作者设计了一个基于图表结构的增量解析器,边接收单词边构建并维护多个候选语义树,同时把最新可信的语义片段实时送入 BoundPlanner 生成凸约束参考路径,再由 BoundMPC 在 10 Hz 频率下滚动优化关节轨迹;当后续口语引入新约束时,系统通过松弛变量和局部重规划在 20 ms 内更新轨迹,保证机器人运动连贯且安全。
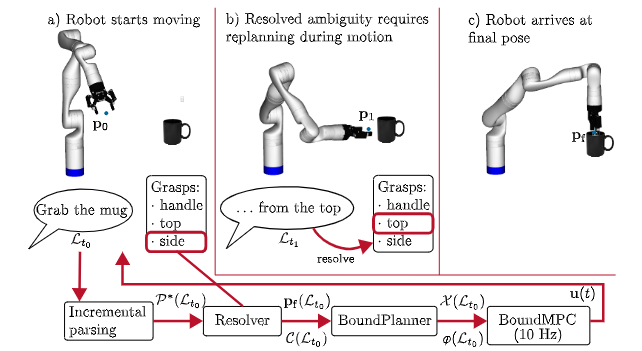
创新点:
首次将增量式语言解析器与在线运动规划器深度耦合,实现毫秒级语言-动作闭环。
提出可回溯的多候选解析机制,机器人在听到新词后仅局部修正运动约束而无需重启整段轨迹。
构建六类口语约束统一形式化框架,可直接映射到实时优化变量,使语音能在任意时刻插入并立即生效。
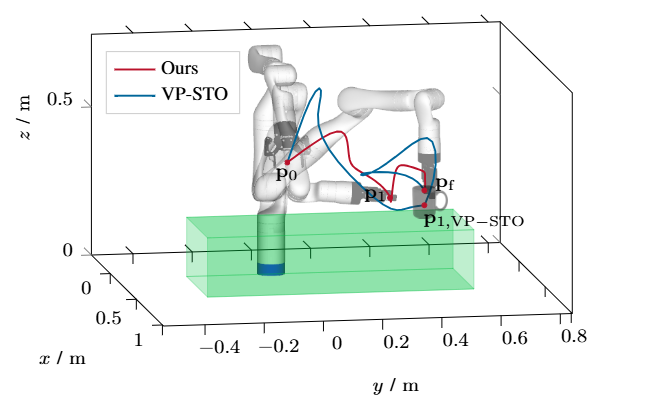
总结:这篇文章让机器人像人一样“边听边改”,在手臂已经运动的过程中实时听懂人类追加或纠正的口语指令,解决了传统方法必须等完整指令、导致机器人频繁停顿重规划的痛点。
Improving Tactile Gesture Recognition with Optical Flow
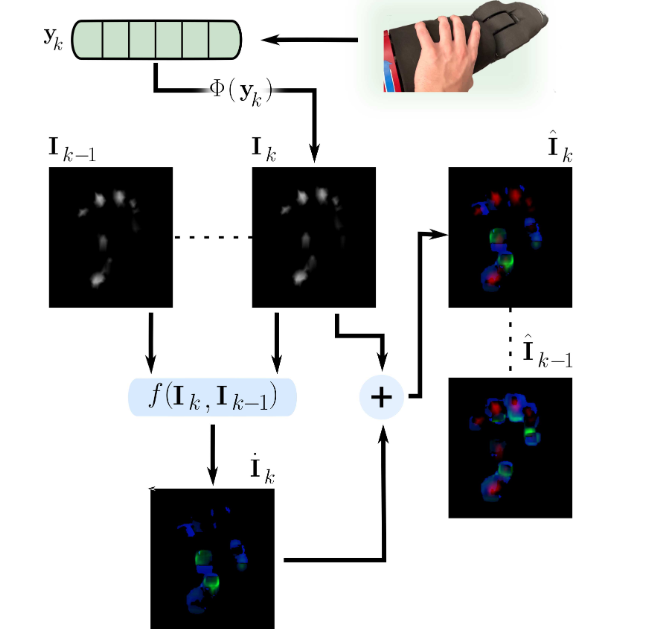
方法:作者先以 10 Hz 采集 1558 个电容式 taxel 的压力阵列,将其空间插值为 357×334 的单通道触觉图像;接着用 Farnebäck 算法在相邻帧间计算稠密光流,把幅值与方向分别写入绿、蓝通道,与红通道压力合成 3 通道图像;随后用 ImageNet 预训练的 EfficientNet-B0 逐帧提取空间特征,LSTM 捕捉时序关系,最后全连接层输出五类手势概率,整套流程在训练与推理阶段实时运行。
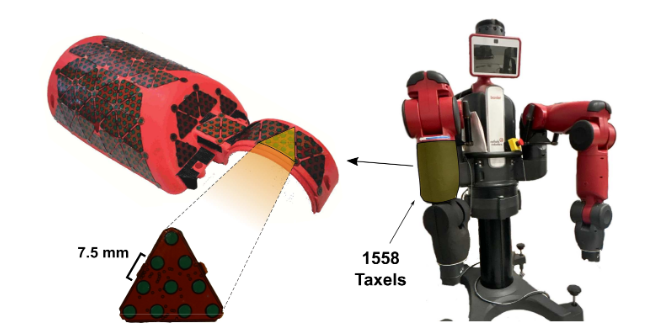
创新点:
首次将稠密光流嵌入触觉图像,把时序接触动态压缩成绿-蓝两通道,无需任何额外硬件即可显著提升可分性。
构建 3 通道触觉帧序列(红通道压力 + 绿蓝光流),直接喂给 CNN-LSTM 架构,把“触觉视频”当视觉视频处理,实现端到端训练。
在包含 38 人、1900 样本的新数据集上验证,仅通过数据层面的光流增强就让分类准确率从 80.7% 跃升到 89.1%,且输入长度 L≥4 帧即可稳定获益。
总结:这篇文章让机器人“触感也能看动态”,仅凭现有触觉垫就解决了静态压力图难以区分相似手势的老大难问题。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
Language as Cost: Proactive Hazard Mapping using VLM for Robot Navigation
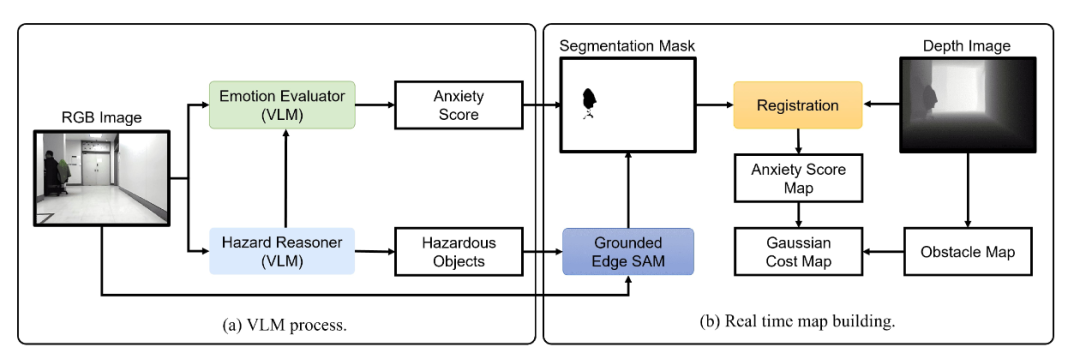
方法:系统先让 GPT-4o 描述场景并列举潜在危险,再由轻量 GPT-4o-mini 为每个危险对象给出 1–3 的焦虑分数;随后 Grounded Edge SAM 依据危险名称零 shot 生成分割掩膜,与深度图融合后投影到 2D 栅格,每个危险单元以焦虑分数为权重生成高斯代价场;最终用 max-fusion 将代价场与传统障碍图合并,供 D*Lite + MPPI 实时规划,实现“未见先避”的主动安全导航。
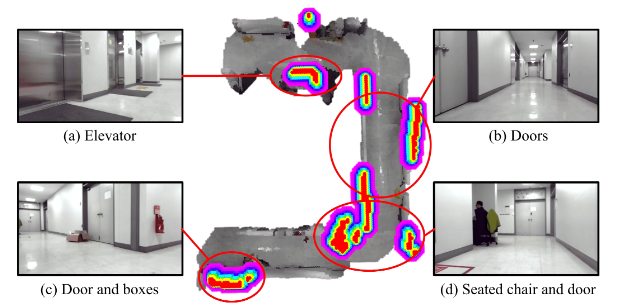
创新点:
首次提出“Language-as-Cost”零 shot 框架,直接拿 VLM 的文本风险描述生成连续代价图,无需任何事先训练或人工标注。
引入心理学启发的“焦虑评分”机制,将 VLM 输出的风险文字量化为 1–3 级数值,并通过高斯扩散动态调节风险空间影响范围。
把零 shot 分割(Grounded Edge SAM)与 VLM 链式推理结合,实现对新物体、新场景的实时语义风险定位与在线地图更新。
总结:这篇文章让机器人像“焦虑人类”一样提前脑补危险,用一句自然语言就能在地图上画出“隐形雷区”,彻底告别等碰撞才改道的被动导航。
关注gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~