STM32H7 以太网配置引申的内存问题
stm32H7 以太网配置引申的内存问题
这个blog主要是整合一下各个关于stm32H7 以太网配置引申的内存问题 blog的内容 感谢各位博主
文章目录
- stm32H7 以太网配置引申的内存问题
- 为什么需要MPU
- MPU 配置 (`MPU_Config`) 代码解析
- `lwipopts.h` 文件解析
- 总结
- 变量分配至不同内存区域
- 查看FLASH与RAM细节
- Cortex M7 MPU配置相关
为什么需要MPU
为什么需要MPU(为了解决CPU缓存和DMA之间的数据同步问题)
在STM32H7这样的高性能芯片里,有几个关键角色:
- CPU内核 (Cortex-M7): 速度飞快,为了不被慢速的RAM拖后腿,它内置了高速缓存(Cache)。CPU读写数据时,会优先操作Cache,而不是直接读写主内存(RAM)。
- DMA控制器 (Direct Memory Access): 一个“搬运工”,可以在没有CPU干预的情况下,直接在内存和外设(比如以太网MAC)之间搬运数据。这大大解放了CPU。
- 主内存 (SRAM): 我们程序中定义的变量、数据缓冲区等都存放在这里。
主内存(RAM) 就像一个大仓库。
DMA 是一个只会看仓库清单、直接去仓库货架上搬货的“搬运工”。
CPU 是个脑子很快的“仓库管理员”,他为了效率,会把常用的货物信息记在自己的**小本本(Cache)**上。
矛盾一:发数据(CPU -> DMA -> 以太网)
- CPU(管理员)要发一个网络包,于是把数据写到了自己的**小本本(Cache)**上。
- 它告诉DMA(搬运工):“去仓库的A货架把货搬走发掉。”
- 但此时,数据可能还在CPU的“小本本”里,还没来得及同步更新到仓库的A货架上。
- DMA直接去A货架一看,发现是旧的、或者根本是空的数据,结果就把错误的数据发出去了。
矛盾二:收数据(以太网 -> DMA -> CPU)
- DMA(搬运工)从以太网收到一个数据包,勤快地把它放到了仓库的B货架上。
- 它通知CPU(管理员):“货收到了,在B货架。”
- CPU想查看数据,但它习惯性地先看自己的小本本(Cache),上面记录的还是B货架之前的老信息。
- 结果,CPU读到了旧数据,以为网络没收到新包。
这就是缓存一致性 (Cache Coherency) 问题。为了解决它,最直接的方法就是:划出一片特殊的内存区域,并告诉CPU:“对于这块区域,不许用你的小本本(Cache),必须每次都老老实实地去仓库(RAM)里读写!”
这个“划定区域、设定规则”的工作,就是由 MPU (Memory Protection Unit) 来完成的。
MPU 配置 (MPU_Config) 代码解析
以stm32H723ZGT6的MPU配置为例
MPU_Config 函数的作用,就是在SRAM(0x30000000开头的地址是STM32H7的SRAM区)里划定几个“特殊区域”,并为它们设定规则。
/* Disables the MPU */
HAL_MPU_Disable(); // 配置前先关闭MPU/* --- Region 0: DMA描述符区 --- */
MPU_InitStruct.Enable = MPU_REGION_ENABLE;
MPU_InitStruct.Number = MPU_REGION_NUMBER0;
MPU_InitStruct.BaseAddress = 0x30000000;
MPU_InitStruct.Size = MPU_REGION_SIZE_256B; // 256字节
MPU_InitStruct.AccessPermission = MPU_REGION_FULL_ACCESS; // 允许完全访问
MPU_InitStruct.IsCacheable = MPU_ACCESS_NOT_CACHEABLE; // **关键:禁止缓存**
MPU_InitStruct.IsBufferable = MPU_ACCESS_BUFFERABLE; // 允许写缓冲
MPU_InitStruct.IsShareable = MPU_ACCESS_NOT_SHAREABLE; // 不共享
MPU_InitStruct.DisableExec = MPU_INSTRUCTION_ACCESS_ENABLE; // 允许执行指令
HAL_MPU_ConfigRegion(&MPU_InitStruct);
这是什么? 这是为**以太网DMA描述符(Descriptors)**准备的区域。你可以把描述符想象成给DMA的“任务清单”,上面写着“数据包在内存的哪个位置”、“长度多少”、“处理完状态写回这里”等等。
为什么这么配? CPU和DMA都会频繁读写这个“任务清单”。为了保证双方看到的信息永远是最新最准确的,这个区域必须是“非缓存(Not Cacheable)”的。这是最重要的属性。
/* --- Region 1 & 2: LwIP主堆和网络缓冲区 --- *//* Region 1 的配置 */
MPU_InitStruct.Number = MPU_REGION_NUMBER1;
MPU_InitStruct.BaseAddress = 0x30004000; // **注意这个地址!**
MPU_InitStruct.Size = MPU_REGION_SIZE_16KB; // 16KB大小
MPU_InitStruct.TypeExtField = MPU_TEX_LEVEL1; // 通常与缓存策略关联
// ...其他属性继承自上一个配置,比如IsCacheable=NOT_CACHEABLE
HAL_MPU_ConfigRegion(&MPU_InitStruct);/* Region 2 的配置 */
MPU_InitStruct.Number = MPU_REGION_NUMBER2;
// 注意:基地址和大小没有修改,所以仍然是针对0x30004000这片区域
MPU_InitStruct.IsShareable = MPU_ACCESS_SHAREABLE; // **关键:设置为共享**
MPU_InitStruct.IsBufferable = MPU_ACCESS_NOT_BUFFERABLE; // **关键:禁止写缓冲**
HAL_MPU_ConfigRegion(&MPU_InitStruct);
代码中Region 2似乎是在修改Region 1区域的属性。更常见的做法是在一个Region定义里设置好所有属性。但我们按其最终效果来分析)
- 这是什么? 这片从
0x30004000开始的16KB内存,是专门留给 LwIP协议栈 使用的主内存堆(Heap)。所有的网络数据包(pbuf)都会从这里分配。这是收发网络数据的核心区域。 - 为什么这么配?
- 地址
0x30004000: 这个地址不是随便写的,它需要和lwipopts.h中的一个宏定义精确对应,我们马上就会看到。 - 非缓存 (Not Cacheable): 和描述符区一样,这是为了避免CPU和DMA之间的数据不一致。
- 共享 (Shareable): 这个属性告诉总线系统,这块内存会被多个“主人”(CPU和DMA)同时访问,系统需要保证一个主人写完的数据能被另一个主人看到。这进一步加强了数据同步。
- 非缓冲 (Not Bufferable): 禁止写缓冲,意味着CPU的写操作会立刻穿透到后端内存(RAM),而不是在某个缓冲区里等待。这提供了最强的数据一致性保证。
- 地址
MPU小结: 通过这几段代码,我们用硬件强制规定了内存 0x30004000 开始的区域是“DMA安全的”,即解决了我们前面提到的“小本本(Cache)”问题。
lwipopts.h 文件解析
如果说MPU是设定了物理规则,那么lwipopts.h就是告诉LwIP软件如何利用这些规则。我们来看几个最重要的配置:
#define CHECKSUM_BY_HARDWARE 1
这告诉LwIP:“我们芯片的以太网MAC硬件很强大,能自己计算TCP/IP的校验和,你(CPU)就别费劲了。”
#define CHECKSUM_GEN_IP 0
#define CHECKSUM_GEN_UDP 0
#define CHECKSUM_GEN_TCP 0
// ...以及所有CHECKSUM_CHECK_* 也都为0
这些配置就是上面那条的必然结果:既然硬件做了,软件层面就全部关闭,从而把CPU解放出来做别的事情,极大提升性能。
#define MEM_ALIGNMENT 4
32位处理器访问4字节对齐的地址效率最高,这是一个通用的性能优化。
#define LWIP_RAM_HEAP_POINTER 0x30004000
这个宏告诉LwIP:“你的专属内存堆,不要自己随便找地方,就从物理地址 0x30004000 开始用!” 这个地址,和我们刚刚在MPU里费劲心思配置的那个“DMA安全区”的起始地址完全一样。这样一来,LwIP分配的所有网络缓冲区(pbuf),就自动落在了我们用MPU保护起来的非缓存、共享内存区里,数据一致性问题就从根源上解决了。
#define MEMP_NUM_PBUF 10 // PBUF缓冲池大小
#define MEMP_NUM_TCP_SEG 10 // TCP分段缓冲池大小
这些值定义了LwIP预先分配的各种内存池的大小。默认值通常是16。这里改成10,可能是为了节省一些RAM空间。这是一个典型的内存占用 vs 网络性能的权衡。如果你的应用网络负载很高,可能会需要调大这些值,反之则可以调小来节省内存。
#define WITH_RTOS 1
#define TCPIP_THREAD_STACKSIZE 1024
#define TCPIP_THREAD_PRIO osPriorityNormal
#define DEFAULT_UDP_RECVMBOX_SIZE 6
#define DEFAULT_TCP_RECVMBOX_SIZE 6
这些配置告诉LwIP它正运行在FreeRTOS这样的操作系统环境下。LwIP会创建自己的核心线程(tcpip_thread)来处理网络事件,这里为它分配了1024字节的堆栈空间和普通优先级。而MBOX_SIZE定义了线程间通信邮箱(队列)的大小,用于在你的应用线程和LwIP核心线程之间传递消息(比如“收到了新数据”)。
总结
- 根本需求: 高性能的STM32H7芯片,CPU带着Cache,以太网用着DMA,两者直接操作内存会产生数据不一致的风险。
- 硬件对策: 使用MPU,在SRAM里划出一块16KB的“DMA安全区”(起始于
0x30004000),并强制设定其属性为非缓存、共享、非缓冲,确保任何对这块内存的读写都是直接、实时的。 - 软件配合: 通过
lwipopts.h文件,精准地告诉LwIP:- 用哪块内存: 使用
LWIP_RAM_HEAP_POINTER宏,将其内存堆的起点指向MPU设定的安全区地址0x30004000。 - 相信硬件: 打开
CHECKSUM_BY_HARDWARE,将校验和计算任务交给以太网硬件,解放CPU。 - 与系统相容: 配置好RTOS相关的线程、邮箱参数,让LwIP能顺利地在多任务环境下运行。
- 用哪块内存: 使用
变量分配至不同内存区域
STM32H743+CubeIDE-将变量定义到指定的内存_stm32把变量定义在外部ram-CSDN博客
【STM32H7教程】第25章 STM32H7的TCM,SRAM等五块内存基础知识 - 硬汉嵌入式 - 博客园
这篇blog主要是讲怎么把变量定义到指定的内存,介绍了
-
内存地址分配的情况
-
DTCM SRAM 等情况
-
一般普通定义的全局变量都是定义在指定的DTCM内存,但是DTCM内存的大小仅仅只有128K,资源很宝贵。如果项目规模较大,就需要考虑将一些全局变量存放到其他RAM里。于是可以通过链接文件ld文件给特定的变量定义到不同的内存里
比如使用_attribute__((section(“name”)))声明变量
在keil里面可以用sct文件配置 以及ld链接文件
在实际项目中,充分发挥STM32H7的性能,必须将频繁存取的数据存放在DTCM内存。TCM:Tightly-Coupled Memory 紧密耦合内存,特点是跟内核速度一样(480M)。但是,其他内存(SRAM1,AXI SRAM,SRAM2,SRAM3等)跟CPU的通讯速度只有200M,CPU需要白白等待一段时间,才能把数据读取出来或者将数据存放进去。为了提高CPU与其他内存的通讯效率,Cortex-M7有了Cache(高速缓冲区,与CPU通讯速度400M)
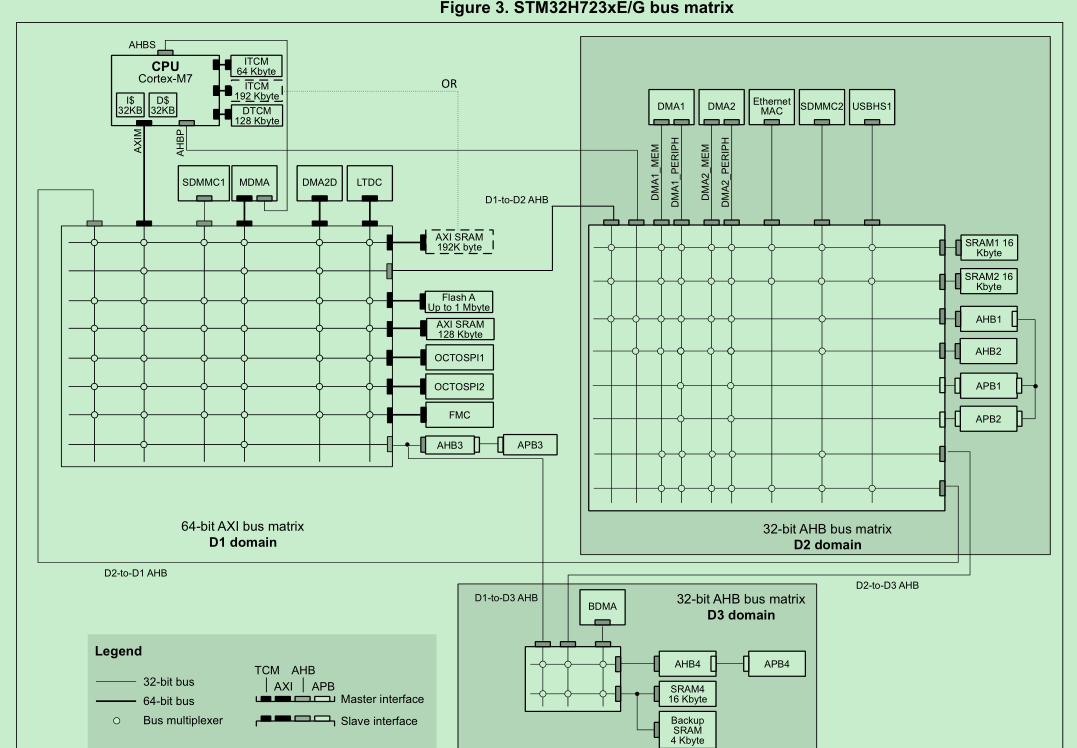
DTCM(在STM32CubeIDE称为RAM): 0x20000000 ~ 0x20020000(size:128K)
AXI SRAM(RAM_D1) : 0x24000000 ~ 0x24080000(size:512K)
AHB SRAM(RAM_D2):0x30000000 ~ 0x30048000(size:288K)
SRAM4(RAM_D3):0x38000000 ~ 0x38010000(size:64K)

查看FLASH与RAM细节
STM32CubeIDE教程-查看FLASH与RAM细节_stm32cubeide build analyzer-CSDN博客
FLASH主要是保存代码而RAM是保存程序运行时的数据(比如全局变量,堆数据与栈数据
栈(stack)空间,用于局部变量,函数调时现场保护和返回地址,函数的形参等。
堆(heap)空间,主要用于动态内存分配,如malloc,calloc,realloc等函数分配的变量空间是在堆上。
Cortex M7 MPU配置相关
STM32H743+CubeMX-梳理MPU的设置_background region privileged accesses only-CSDN博客
番外篇:STM32H7的Cache和MPU以及内存分配问题_xip模式 cache策略 h7-CSDN博客
因为DMA是直接与SRAM交换数据的,而CPU与SRAM之间隔了一个Cache,如果DMA更新了某个数据到SRAM,CPU要去访问,而恰好Cache中有,那么CPU就不会去SRAM中拿,就会拿到Cache中已经过时的数据。因此使用了DMA的内存区要配置为无Cache或者拿数据前清一次Cache
MPU防止不受信任的应用程序访问受保护的内存区域; 防止用户应用程序破坏操作系统使用的数据;通过阻止任务访问其它任务的数据区;允许将内存区域定义为只读,以便保护重要数据;检测意外的内存访问。 简单的说就是内存保护、外设保护和代码访问保护。
为什么使用Cache才能充分发挥CPU的性能?在默认的配置下,静态内存优先使用128KB的DTCM。原因是CPU读写DTCM内存的速度是480M,所以一般优先使用128KB的DTCM。CPU直接读写其他静态内存的速度仅仅只有200M,白白浪费CPU的480M主频了。为了解决这个问题,Cortex-M7架构有了cache。通过提前将数据缓冲到12KB的cache,然后CPU再从cache里读取数据,这样就能解决当CPU读写AXI SRAM与SRAM1等内存时所造成的性能损失。
为什么要学习使用MPU?只有通过设置MPU才能配置cache,才能正常使用cache缓存数据
并不是DTCM挤满了才有机会使用MPU。比如当使用ADC+DMA采集模拟量数据时,DMA并不能将外设采集的模拟量数据存放到DTCM里,一般只能放进AXI SRAM,SRAM1,SRAM2,SRAM3里。此时,就需要使用MPU+cache提高CPU读写AXI RAM,SRAM1等内存的速度。
配置MPU的目的是使用cache,所以可以简单地将MPU的设置分为三部分。第一部分是配置MPU的内存地址,第二部分是配置Cache的读写规则,第三部分设置保护规则(配置MPU是为了使用Cache,所以不用保护)。
模拟量数据时,DMA并不能将外设采集的模拟量数据存放到DTCM里,一般只能放进AXI SRAM,SRAM1,SRAM2,SRAM3里。此时,就需要使用MPU+cache提高CPU读写AXI RAM,SRAM1等内存的速度。
配置MPU的目的是使用cache,所以可以简单地将MPU的设置分为三部分。第一部分是配置MPU的内存地址,第二部分是配置Cache的读写规则,第三部分设置保护规则(配置MPU是为了使用Cache,所以不用保护)。