Pytorch深度学习框架实战教程-番外篇02-Pytorch池化层概念定义、工作原理和作用
相关文章 + 视频教程
《Pytorch深度学习框架实战教程01》《视频教程》
《Pytorch深度学习框架实战教程02:开发环境部署》《视频教程》
《Pytorch深度学习框架实战教程03:Tensor 的创建、属性、操作与转换详解》《视频教程》
《Pytorch深度学习框架实战教程04:Pytorch数据集和数据导入器》《视频教程》
《Pytorch深度学习框架实战教程05:Pytorch构建神经网络模型》《视频教程》
《Pytorch深度学习框架实战教程06:Pytorch模型训练和评估》《视频教程》
《Pytorch深度学习框架实战教程09:模型的保存和加载》《视频教程》
《Pytorch深度学习框架实战教程10:模型推理和测试》《视频教程》
《Pytorch深度学习框架实战教程-番外篇01-卷积神经网络概念定义、工作原理和作用》
《Pytorch深度学习框架实战教程-番外篇02-Pytorch池化层概念定义、工作原理和作用》
《Pytorch深度学习框架实战教程-番外篇03-什么是激活函数,激活函数的作用和常用激活函数》
《PyTorch 深度学习框架实战教程-番外篇04:卷积层详解与实战指南》
《Pytorch深度学习框架实战教程-番外篇05-Pytorch全连接层概念定义、工作原理和作用》
《Pytorch深度学习框架实战教程-番外篇06:Pytorch损失函数原理、类型和案例》
《Pytorch深度学习框架实战教程-番外篇10-PyTorch中的nn.Linear详解》
一、什么是池化层?
池化层(Pooling Layer)是卷积神经网络(CNN)中与卷积层配合使用的重要组件,主要用于特征降维、减少计算量并增强模型的平移不变性。它通常紧跟在卷积层之后,对卷积层输出的特征图进行压缩处理。
与卷积层不同,池化层没有可学习的参数,其操作是确定性的(根据预设规则对局部区域进行聚合计算)。
二、池化层的工作原理
池化层的工作流程与卷积层类似,都通过滑动窗口处理特征图,但计算方式不同:
- 滑动窗口:池化窗口(如 2×2)在特征图上按指定步长滑动。
- 聚合计算:对窗口覆盖的区域执行聚合操作(如取最大值、平均值等),得到一个值作为输出特征图的对应位置像素。
- 输出特征图:所有窗口的聚合结果构成尺寸更小的输出特征图。
三、常见池化方式图示:
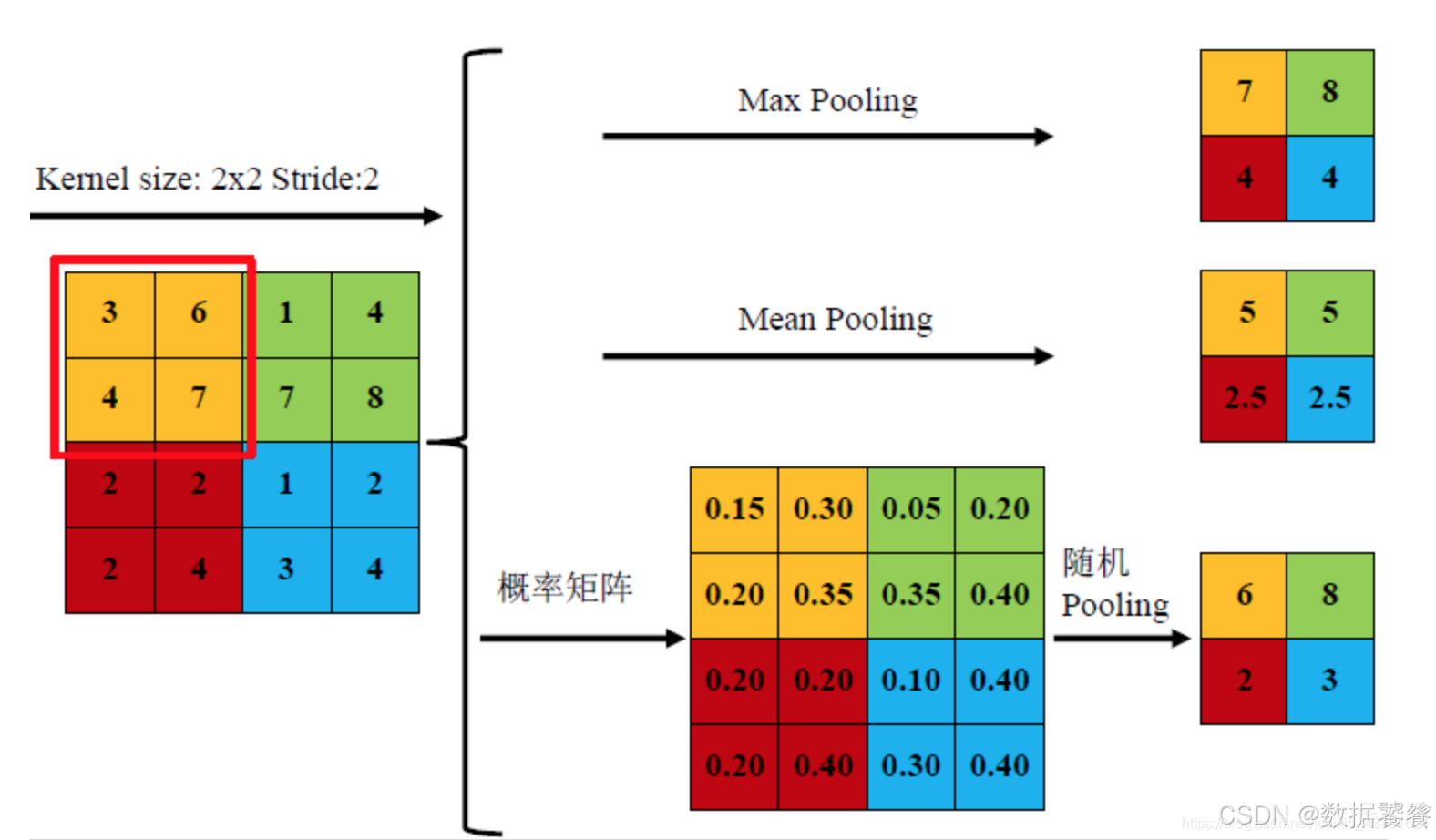
池化层的作用
- 特征降维:通过减少特征图的空间尺寸(如 2×2 池化 + 步长 2 可将尺寸减半),降低后续层的计算量和参数数量。
- 增强平移不变性:局部微小位移不会改变池化结果(如最大值位置轻微移动不影响输出),提高模型对输入变化的鲁棒性。
- 防止过拟合:通过信息聚合减少特征冗余,降低模型对局部细节的过度敏感。
- 扩大感受野:池化操作使高层神经元能感知到输入图像更大范围的区域。
四、PyTorch 中的池化层详解
PyTorch 的torch.nn模块提供了多种池化层,适用于不同场景:
| 池化层 | 作用 | 适用场景 |
|---|---|---|
nn.MaxPool2d | 取窗口内最大值 | 保留显著特征(如边缘、纹理) |
nn.AvgPool2d | 取窗口内平均值 | 保留整体特征,平滑输出 |
nn.MaxUnpool2d | 最大池化的逆操作(上采样) | 特征图恢复 |
nn.LPPool2d | 取窗口内 p 次幂的平均值的 p 次方根 | 灵活控制聚合强度 |
nn.AdaptiveMaxPool2d | 自适应最大池化(指定输出尺寸) | 固定输出尺寸,简化网络设计 |
nn.AdaptiveAvgPool2d | 自适应平均池化(指定输出尺寸) | 同上 |
nn.MaxPool2d核心参数(最常用)
python
运行
nn.MaxPool2d(kernel_size, # 池化窗口大小(int或tuple)stride=None, # 步长(默认与kernel_size相同)padding=0, # 填充大小dilation=1, # 窗口元素间隔(用于空洞池化)return_indices=False, # 是否返回最大值的索引(用于Unpool)ceil_mode=False # 是否使用向上取整计算输出尺寸(默认向下取整)
)
输出尺寸计算公式:
H_out = floor((H + 2×padding - dilation×(kernel_size-1) - 1) / stride + 1)
(与卷积层相同,ceil_mode=True时用ceil替代floor)
五、示例程序:PyTorch 池化层实战
以下示例展示不同池化层的效果,包括:
- 标准池化(MaxPool2d、AvgPool2d)
- 自适应池化(AdaptiveMaxPool2d)
- 池化对特征图的影响可视化
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import transforms# 1. 数据准备:加载图片并生成特征图(模拟卷积层输出)
def prepare_feature_maps():# 加载图片并转为单通道灰度图transform = transforms.Compose([transforms.Resize((128, 128)),transforms.Grayscale(), # 转为单通道transforms.ToTensor()])# 使用示例图片(实际运行时替换为你的图片路径)image = Image.open("example.jpg")image_tensor = transform(image).unsqueeze(0) # 形状:[1, 1, 128, 128]# 模拟卷积层输出:创建4个特征图(实际中来自卷积层)# 这里通过简单变换生成不同特征图以展示效果feature_maps = []for i in range(4):# 对原图进行简单变换生成不同特征图if i == 0:fm = image_tensor * (i+1)elif i == 1:fm = torch.roll(image_tensor, shifts=5, dims=2) # 水平偏移elif i == 2:fm = torch.roll(image_tensor, shifts=5, dims=3) # 垂直偏移else:fm = image_tensor * 0.5 + torch.roll(image_tensor, shifts=3, dims=(2,3)) * 0.5feature_maps.append(fm)# 合并为[1, 4, 128, 128](批次=1,通道=4,高=128,宽=128)return torch.cat(feature_maps, dim=1), image# 2. 定义池化层模型
class PoolingDemo(nn.Module):def __init__(self):super(PoolingDemo, self).__init__()# 2×2最大池化,步长2(默认与kernel_size相同)self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2)# 3×3平均池化,步长2,填充1self.avg_pool = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)# 自适应最大池化,固定输出尺寸为(32, 32)self.adaptive_max_pool = nn.AdaptiveMaxPool2d(output_size=(32, 32))def forward(self, x):max_out = self.max_pool(x)avg_out = self.avg_pool(x)adaptive_max_out = self.adaptive_max_pool(x)return max_out, avg_out, adaptive_max_out# 3. 可视化函数
def visualize_pooling效果(original_img, input_fm, max_out, avg_out, adaptive_out):plt.figure(figsize=(16, 14))# 显示原始图片plt.subplot(5, 1, 1)plt.title("Original Image")plt.imshow(original_img, cmap='gray')plt.axis('off')# 显示输入特征图(4个通道)plt.subplot(5, 1, 2)plt.title("Input Feature Maps (4 channels)")input_grid = np.zeros((128, 128*4))for i in range(4):fm = input_fm[0, i].detach().numpy() # 取第一个样本的第i个通道input_grid[:, i*128:(i+1)*128] = fmplt.imshow(input_grid, cmap='gray')plt.axis('off')plt.text(-20, 64, f"Size: {input_fm.shape[2:]}", va='center', rotation=90)# 显示最大池化结果plt.subplot(5, 1, 3)plt.title("Max Pooling (2×2, stride=2) Output")max_grid = np.zeros((64, 64*4)) # 尺寸减半为64×64for i in range(4):fm = max_out[0, i].detach().numpy()max_grid[:, i*64:(i+1)*64] = fmplt.imshow(max_grid, cmap='gray')plt.axis('off')plt.text(-20, 32, f"Size: {max_out.shape[2:]}", va='center', rotation=90)# 显示平均池化结果plt.subplot(5, 1, 4)plt.title("Average Pooling (3×3, stride=2, padding=1) Output")avg_grid = np.zeros((64, 64*4)) # 尺寸约为64×64for i in range(4):fm = avg_out[0, i].detach().numpy()avg_grid[:, i*64:(i+1)*64] = fmplt.imshow(avg_grid, cmap='gray')plt.axis('off')plt.text(-20, 32, f"Size: {avg_out.shape[2:]}", va='center', rotation=90)# 显示自适应池化结果plt.subplot(5, 1, 5)plt.title("Adaptive Max Pooling (output 32×32) Output")adaptive_grid = np.zeros((32, 32*4)) # 固定尺寸32×32for i in range(4):fm = adaptive_out[0, i].detach().numpy()adaptive_grid[:, i*32:(i+1)*32] = fmplt.imshow(adaptive_grid, cmap='gray')plt.axis('off')plt.text(-20, 16, f"Size: {adaptive_out.shape[2:]}", va='center', rotation=90)plt.tight_layout()plt.show()# 4. 主函数
if __name__ == "__main__":# 准备特征图和原始图片feature_maps, original_img = prepare_feature_maps()print(f"输入特征图形状: {feature_maps.shape}") # [1, 4, 128, 128]# 初始化模型并执行池化操作model = PoolingDemo()max_pool_out, avg_pool_out, adaptive_pool_out = model(feature_maps)# 打印各池化层输出形状print(f"最大池化输出形状: {max_pool_out.shape}") # [1, 4, 64, 64]print(f"平均池化输出形状: {avg_pool_out.shape}") # [1, 4, 64, 64]print(f"自适应池化输出形状: {adaptive_pool_out.shape}") # [1, 4, 32, 32]# 可视化池化效果visualize_pooling效果(original_img=original_img,input_fm=feature_maps,max_out=max_pool_out,avg_out=avg_pool_out,adaptive_out=adaptive_pool_out)
代码说明
-
数据准备:通过加载图片并生成 4 个特征图(模拟卷积层输出),特征图通过简单变换(偏移、混合)模拟不同卷积核提取的特征。
-
池化层定义:
MaxPool2d(2, 2):2×2 窗口,步长 2,输出尺寸为输入的 1/2(128→64)。AvgPool2d(3, 2, 1):3×3 窗口,步长 2,填充 1,输出尺寸接近输入的 1/2。AdaptiveMaxPool2d(32, 32):无论输入尺寸如何,输出固定为 32×32,简化网络设计。
-
可视化结果:
- 最大池化输出更锐利,保留局部显著特征(如边缘)。
- 平均池化输出更平滑,保留整体区域信息。
- 自适应池化严格保证输出尺寸,便于多层网络拼接。
关键结论
- 池化层通过聚合局部特征实现降维,是 CNN 中控制计算复杂度的关键。
- 最大池化更适合保留锐利特征,平均池化更适合平滑特征。
- 自适应池化(
Adaptive*Pool)通过指定输出尺寸简化网络设计,在迁移学习和固定尺寸输出场景中广泛使用。 - 池化层通常紧跟卷积层,形成 "卷积 + 池化" 的经典组合,逐步提取高层特征。