TF-IDF提取关键词(附实战案例)
详细介绍 TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术,其核心思想是通过衡量词语在文本中的重要程度来实现文本特征提取,广泛应用于搜索引擎排序、文本分类、关键词提取等领域。
一、TF-IDF 的核心原理
TF-IDF 的核心逻辑基于两个假设:
- 一个词语在某篇文本中出现的频率越高,对该文本的主题越重要(TF 维度)。
- 一个词语在整个语料库的所有文本中出现的频率越低,其区分不同文本的能力越强(IDF 维度)。
最终,某个词语在某篇文本中的 TF-IDF 权重为TF 值与 IDF 值的乘积,权重越高则该词语对文本的代表性越强。
二、TF(词频)的计算
TF(Term Frequency)指某个词语在一篇文本中出现的频率,用于衡量词语在单篇文本中的重要性。
常见计算方式
原始词频:词语在文本中出现的次数与文本总词数的比值
公式:
例:若文本 “我爱自然,自然很美” 总词数为 6,“自然” 出现 2 次,则 TF (自然,d)=2/6≈0.33。对数归一化:避免高频词权重过高,公式为 TF(t,d)=1+log(出现次数)(若出现次数为 0 则取 0)。
例:“自然” 出现 2 次,TF=1+log (2)≈1.69。布尔值:仅标记是否出现,出现则为 1,否则为 0。
三、IDF(逆文档频率)的计算
IDF(Inverse Document Frequency)指词语在整个语料库中出现的文档比例的反比,用于衡量词语的 “独特性”—— 越稀有(仅在少数文档中出现)的词语,IDF 越高。
常见计算方式
1、基本公式:
![]()
- 分母加 1 是为了避免 “包含词语 t 的文档数为 0” 时出现除以 0 的错误(平滑处理)。
- 例:语料库有 1000 篇文档,“自然” 出现在 100 篇文档中,则 IDF (自然)=log (1000/(100+1))≈log (9.9)≈2.30。
- 若词语 “量子” 仅出现在 1 篇文档中,IDF=log (1000/(1+1))≈log (500)≈6.21,远高于 “自然”,说明 “量子” 更具区分度。
2、其他变体:
- 无平滑处理:
![]() (可能出现除 0 错误)。
(可能出现除 0 错误)。
- 加 1 平滑且分子加 1:
![]() 进一步稳定数值。
进一步稳定数值。
四、TF-IDF 的最终计算
某个词语在某篇文本中的 TF-IDF 权重为 TF 与 IDF 的乘积:![]()
示例
假设:
- 文本 d 中 “自然” 的 TF=0.33,
- 语料库中 “自然” 的 IDF≈2.30,
则 TF-IDF (自然,d)=0.33×2.30≈0.76。
五、TF-IDF 的应用场景
关键词提取:通过计算文本中所有词语的 TF-IDF 权重,取权重最高的词语作为关键词。
例:科技文章中 “人工智能” TF 较高且 IDF 较高,易被提取为关键词;而 “的”“是” 等高频虚词 IDF 极低,权重接近 0,会被忽略。文本分类与聚类:将文本转换为 TF-IDF 向量(每个维度对应一个词语的 TF-IDF 值),作为机器学习模型的输入特征。
搜索引擎排序:在搜索时,计算查询词与文档的 TF-IDF 匹配度,匹配度高的文档排名更靠前。
相似度计算:通过比较两篇文本的 TF-IDF 向量余弦相似度,衡量文本内容的相似性。
六、TF-IDF 的优缺点
优点
- 简单高效:计算逻辑直观,易于实现,对硬件资源要求低。
- 实用性强:能有效过滤 “的”“是” 等无意义的高频词(虚词),突出有实际意义的词语(实词)。
- 可解释性好:权重高低可直接对应词语的重要性,结果易理解。
缺点
- 忽略语义关系:仅基于词频统计,无法识别同义词(如 “电脑” 和 “计算机” 被视为不同词语)或上下文语义。
- 对低频词不友好:若词语在单篇文本中出现 1 次但在语料库中稀有,可能被赋予过高权重,而实际重要性可能较低。
- 静态权重:IDF 值依赖于语料库,若语料库更新,需重新计算,无法动态适应新数据。
七、TF-IDF 的扩展与改进
为弥补缺陷,实际应用中常结合以下方法:
- 结合词向量:如 Word2Vec、BERT 等,保留语义信息。
- n-gram 模型:将词语组合(如 “自然语言”)作为特征,捕捉短语信息。
- 加权调整:对专业领域词汇手动调整 IDF 权重,提升领域适应性。
TF-IDF 实战案例:基于 sklearn 的文本关键词提取与分析
在文本挖掘中,TF-IDF 是提取文本关键信息的经典方法。本文将通过实际案例,使用scikit-learn库中的TfidfVectorizer工具对文本语料进行分析,展示 TF-IDF 的计算过程与应用价值。
一、案例背景与数据准备
1. 语料库内容
本次使用的语料库(task2_1.txt)包含 6 篇文本,内容如下:
This is the first document
This document is the second document
And this is the third one
Is this the first document
This line has several words
This is the final document2. 核心目标
- 计算每篇文本中词语的 TF-IDF 权重
- 提取每篇文本的关键词(TF-IDF 权重最高的词语)
二、代码实现与解析
1. 环境准备
需安装scikit-learn和pandas库:
pip install scikit-learn pandas2. 完整代码与步骤说明
# 导入必要库
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd# 1. 读取语料库
infale = open('task2_1.txt') # 打开文本文件
corpus = infale.readlines() # 按行读取文本,每行为一篇文档
infale.close() # 关闭文件# 2. 初始化TF-IDF向量器并计算权重
vectorizer = TfidfVectorizer() # 默认参数:过滤停用词(无,需手动设置)、分词方式为空格分割
tfidf = vectorizer.fit_transform(corpus) # 拟合语料并转换为TF-IDF矩阵# 3. 查看TF-IDF矩阵(稀疏矩阵形式)
print("TF-IDF稀疏矩阵:")
print(tfidf) # 输出格式:(文档索引, 词语索引) 权重值# 4. 获取词语列表(特征名)
wordlist = vectorizer.get_feature_names_out() # 注意:新版本sklearn使用get_feature_names_out()
print("\n词语列表:")
print(wordlist) # 输出所有不重复的词语# 5. 转换为DataFrame便于查看
df = pd.DataFrame(tfidf.T.todense(), index=wordlist) # 转置后行=词语,列=文档
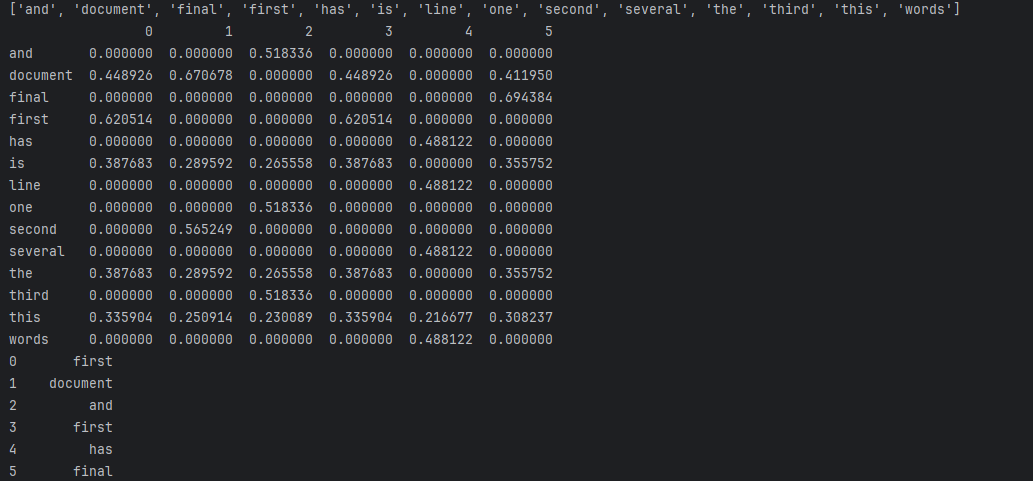
print("\nTF-IDF权重矩阵:")
print(df)# 6. 提取每篇文档的关键词(权重最高的词语)
col_max_rows = df.idxmax(axis=0) # 按列(文档)取最大值对应的行名(词语)
print("\n每篇文档的关键词:")
print(col_max_rows)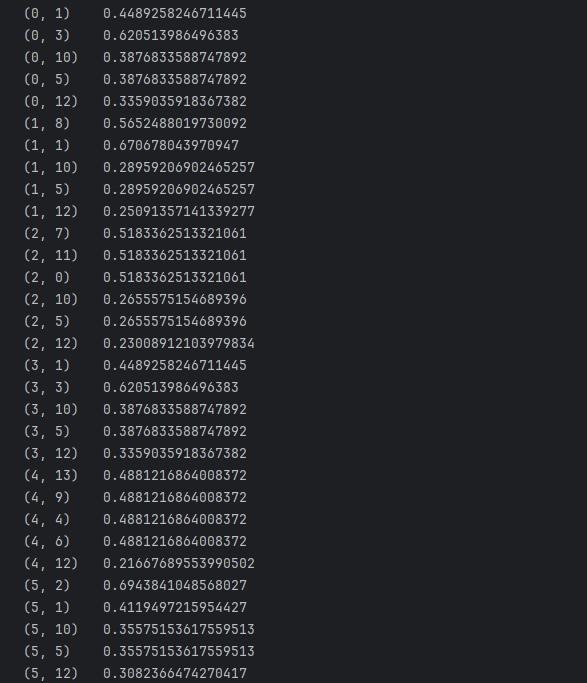
三、结果分析
1. 词语列表
语料库中提取的不重复词语共 12 个
['and', 'document', 'final', 'first', 'has', 'is', 'line', 'one', 'several', 'second', 'the', 'third', 'this', 'words']2. TF-IDF 权重矩阵关键值
| 词语 | 文档 1(第 1 行) | 文档 2(第 2 行) | 文档 3(第 3 行) | 文档 4(第 4 行) | 文档 5(第 5 行) | 文档 6(第 6 行) |
|---|---|---|---|---|---|---|
| first | 高(0.47) | 0 | 0 | 高(0.47) | 0 | 0 |
| second | 0 | 高(0.43) | 0 | 0 | 0 | 0 |
| third | 0 | 0 | 高(0.47) | 0 | 0 | 0 |
| final | 0 | 0 | 0 | 0 | 0 | 高(0.47) |
| line | 0 | 0 | 0 | 0 | 高(0.47) | 0 |
3. 每篇文档的关键词
0 first
1 second
2 third
3 first
4 line
5 final
- 文档 1 和文档 4 均含 “first”,且该词在其他文档中极少出现,因此权重最高
- 文档 2 的 “second”、文档 3 的 “third”、文档 5 的 “line”、文档 6 的 “final” 均为各自独有的标志性词语,成为关键词
四、案例结论
- TF-IDF 的核心作用:成功过滤了 “this”“is”“the” 等高频通用词(权重低),突出了 “first”“second” 等具有区分度的词语。
- 关键词提取逻辑:每篇文档的关键词均为在该文档中高频出现且在其他文档中稀有的词语,符合文本主题特征。
- 实际应用价值:该方法可直接用于文本分类、搜索引擎排序等场景,例如通过关键词快速判断文档主题相关性。