C++学习之STL学习:map/set
通过前面的学习,我们已经对C++ STL有了初步了解。然而,STL作为一个庞大复杂的体系,远不止这些内容。接下来,我们将深入探讨STL中的另外两个重要组件——map和set。
作者的个人gitee:楼田莉子 (riko-lou-tian) - Gitee.com喜欢请点个赞谢谢
目录
前言——序列式容器和关联式容器
set的介绍
set的接口介绍
构造函数和析构函数
构造函数
析构函数
=运算符重载
迭代器
正向
反向
正向const
反向const
容量
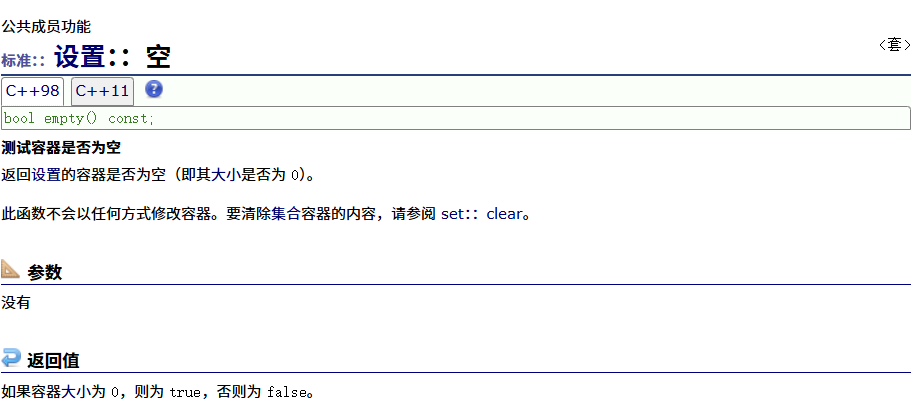
empty
size
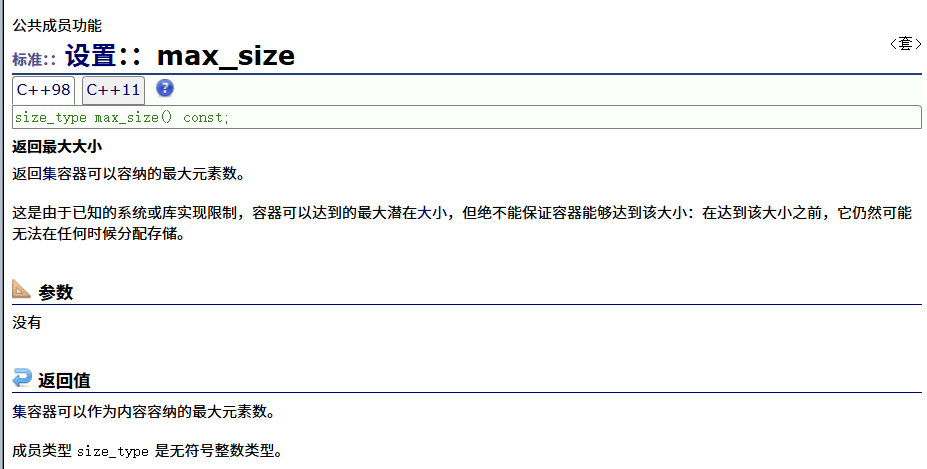
max_size
相关函数
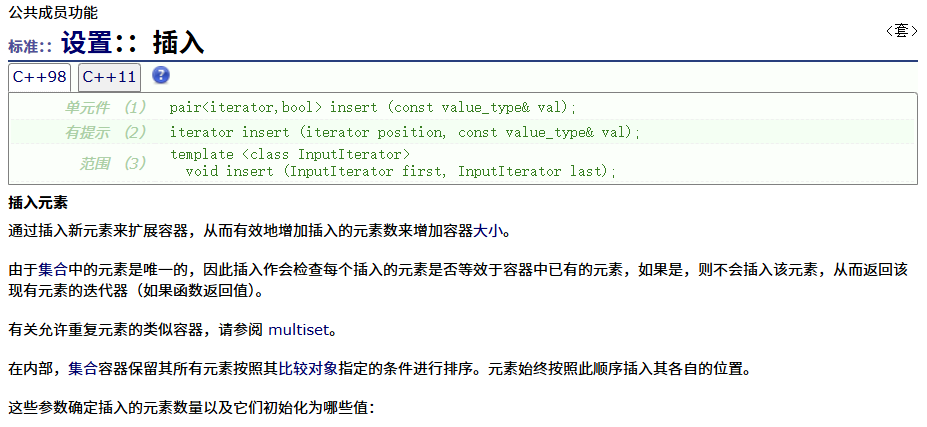
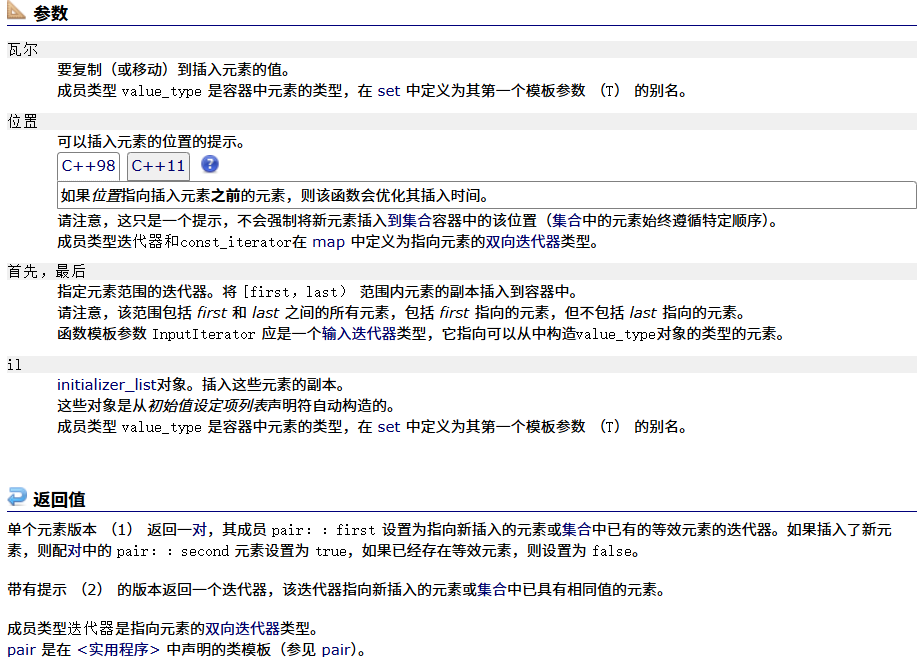
insert
erase
swap
clear
emplace
emplace_hint
观察者
key_comp 编辑
value_comp
操作
find
count
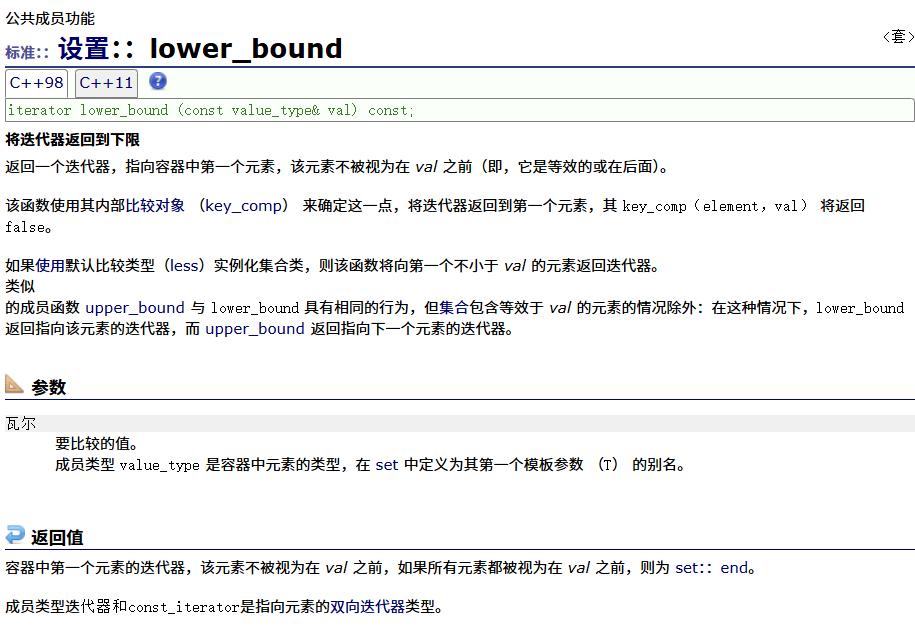
lower_bound
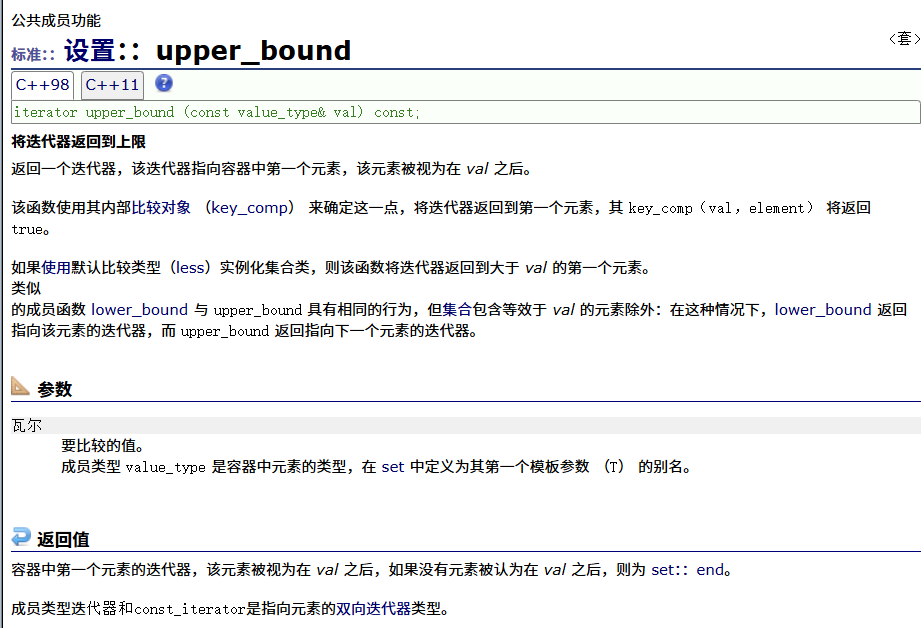
upper_bound
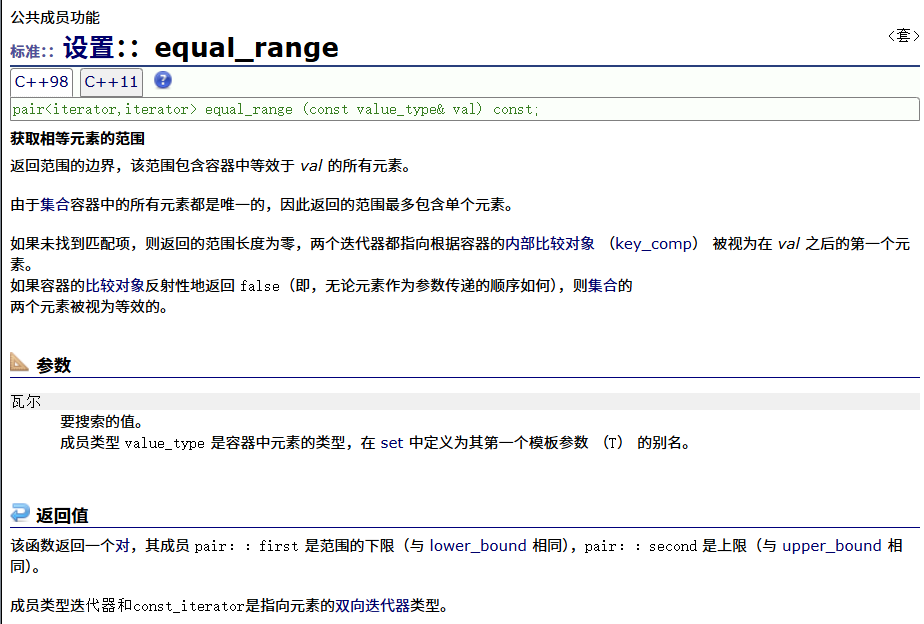
equal_range
multiset和set的区别
set相关的习题
两个数组的交集
环形链表
map的介绍
pair结构介绍
map的接口介绍
构造和析构函数
构造函数
析构函数
=运算符重载
迭代器
正向
反向
const正向
const反向
容量
empty
size
max_size
访问
[]运算符重载
at
相关函数
insert
erase
swap
clear 编辑
emplace
emplace_hint
观察者
key_comp
value_comp
操作
find
count
lower_bound
upper_bound
equal_range
multimap和map的区别
map相关的习题
随机链表的复制
前k个高频词汇
前言——序列式容器和关联式容器
前⾯我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,⽐如交换⼀下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
关联式容器也是⽤来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是⾮线性结构,两个位置有紧密的关联关系,交换⼀下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
本篇中学习的map和set容器底层是红⿊树,红⿊树是⼀颗平衡⼆叉搜索树。set是key搜索场景的结构, map是key/value搜索场景的结构。
set的介绍
set和multiset的文档:<set> - C++ Reference
在使用set和multiset的时候要包含头文件<set>和
using namespace std; 进入set文档我们会发现
set不允许冗余,multiset允许冗余而不破坏结构
set的官方文档:set - C++ 参考
set的介绍

set的声明如下,T就是set底层关键字的类型
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;set默认要求T⽀持⼩于⽐较,如果不⽀持或者想按⾃⼰的需求⾛可以⾃⾏实现仿函数传给第⼆个模版参数
set底层存储数据的内存是从空间配置器申请的,如果需要可以⾃⼰实现内存池,传给第三个参数。
⼀般情况下,我们都不需要传后两个模版参数。
set底层是⽤红⿊树实现,增删查效率是 ,迭代器遍历是⾛的搜索树的中序,所以是有序的。O(logN)
set的接口介绍
构造函数和析构函数
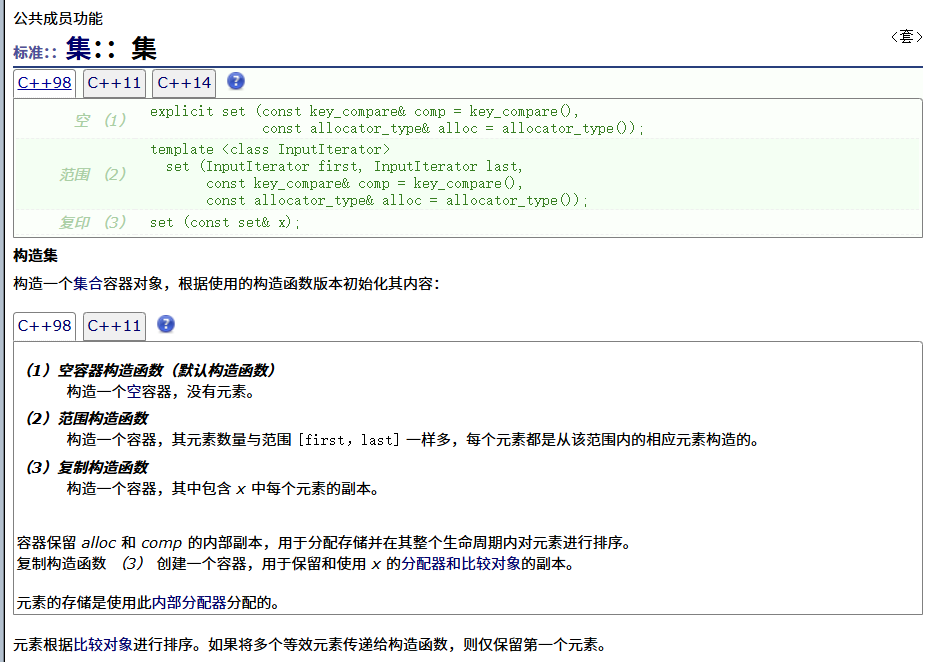
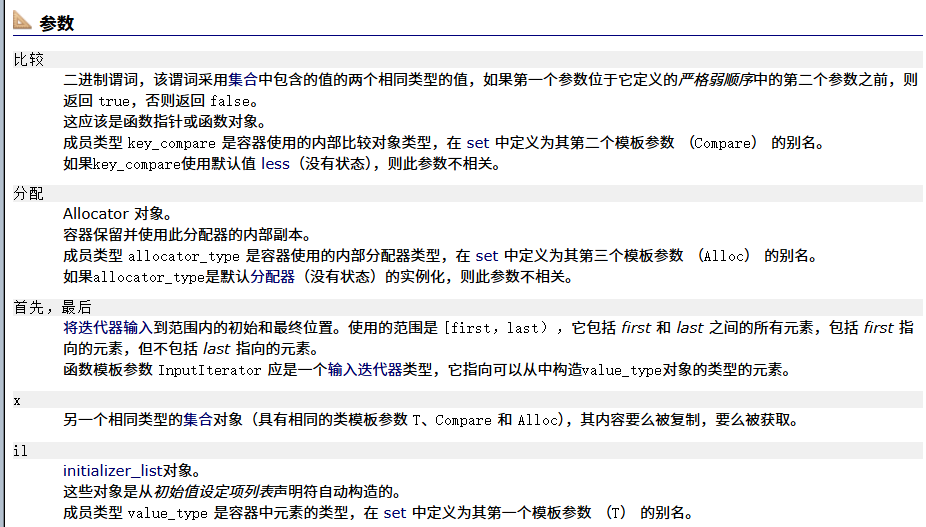
构造函数
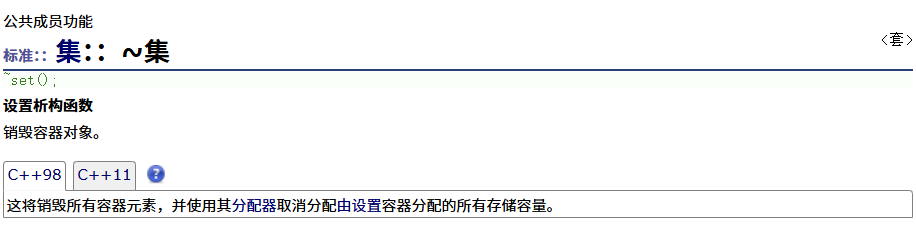
析构函数
=运算符重载
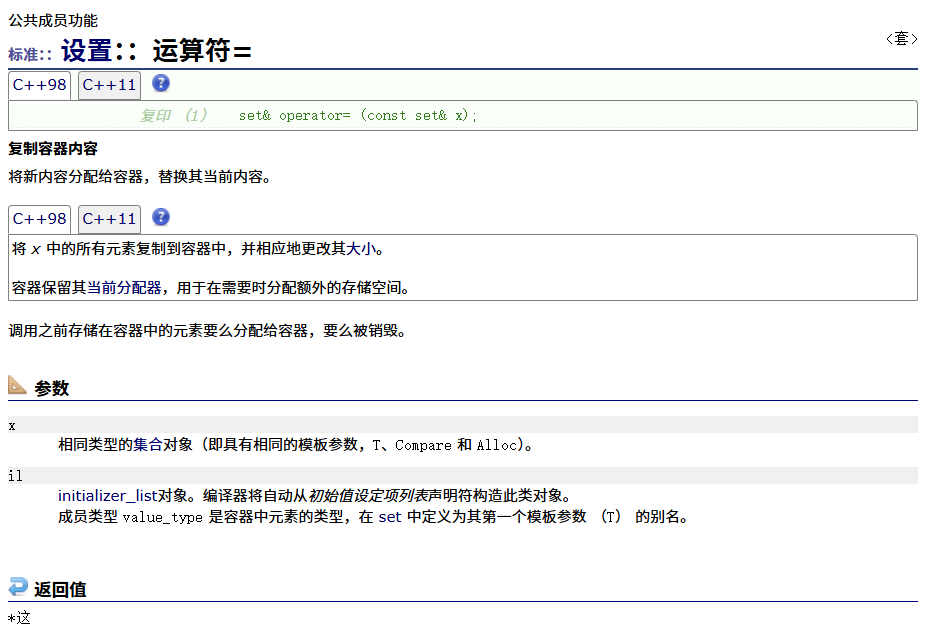
迭代器
正向
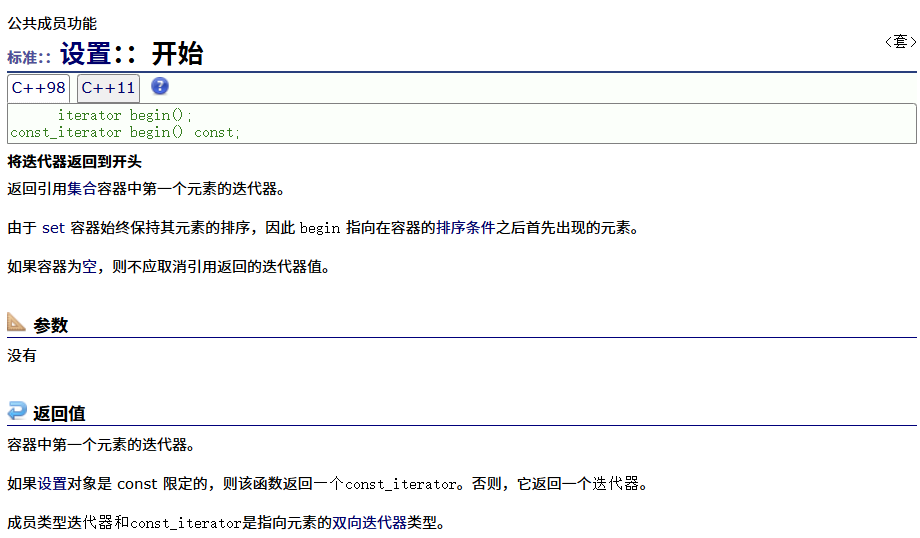
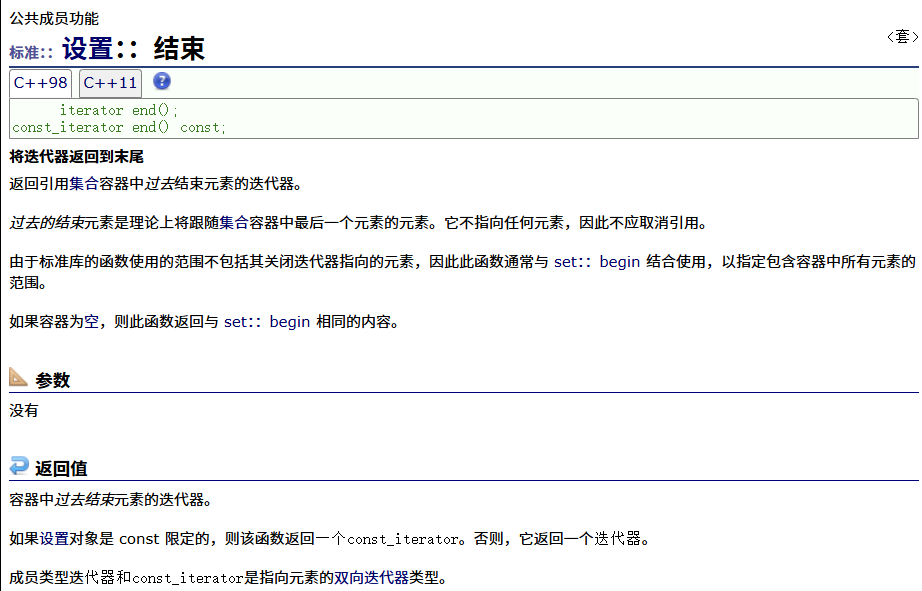
反向
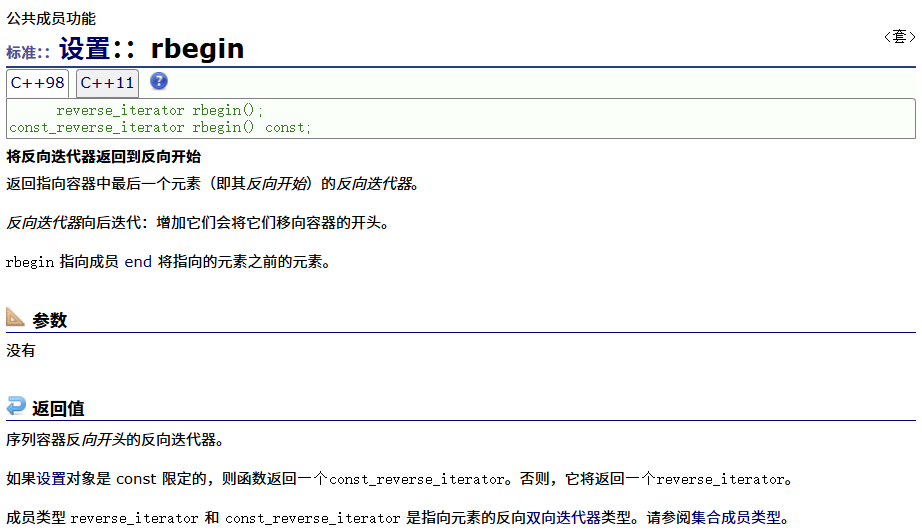

正向const
反向const
容量
empty
size

max_size
相关函数
insert
erase
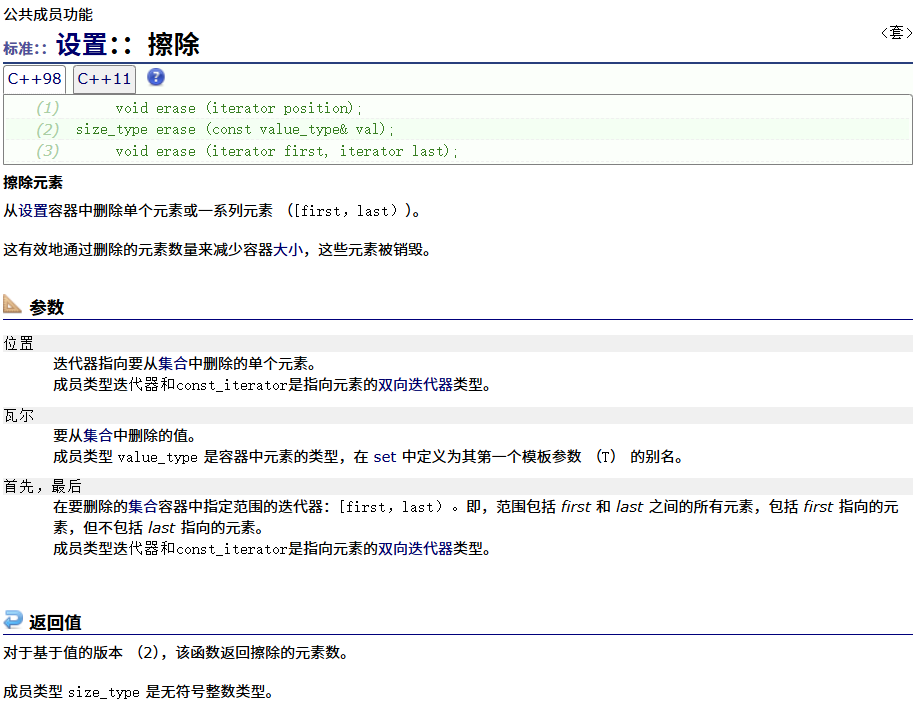
swap

clear
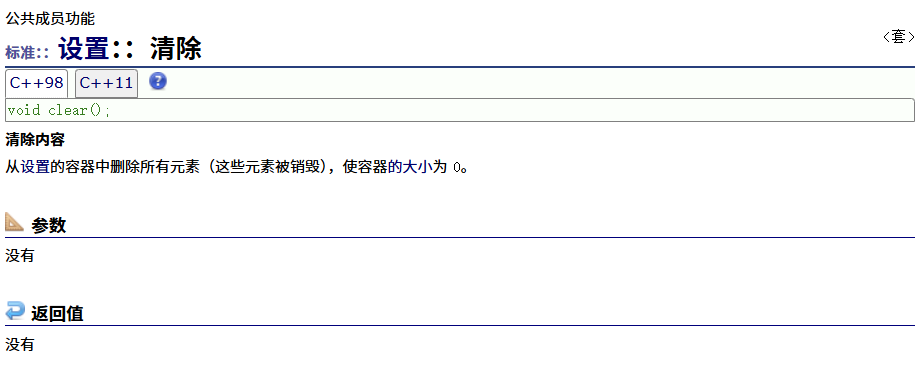
emplace
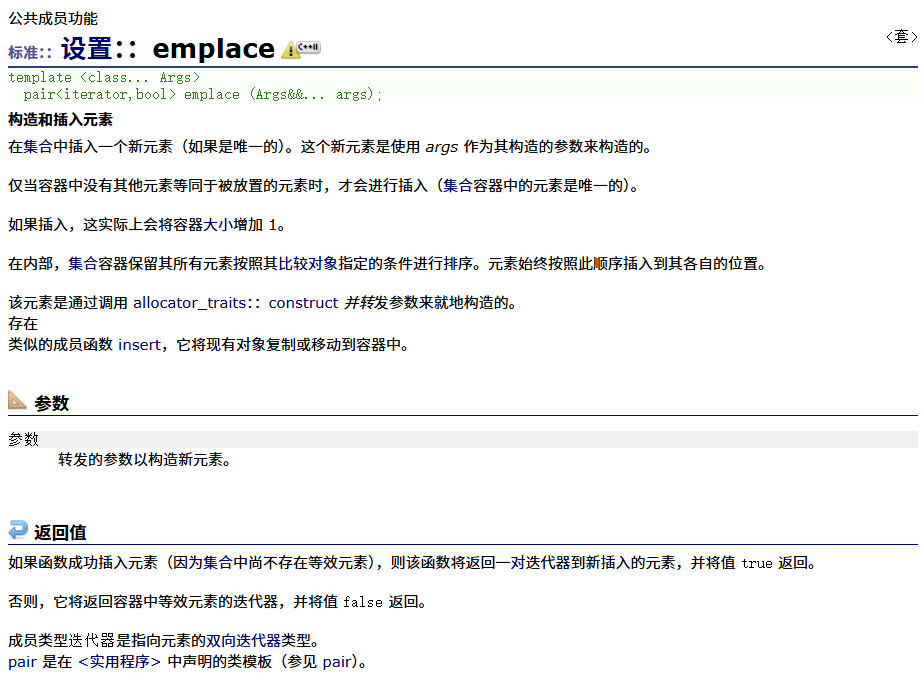
emplace_hint
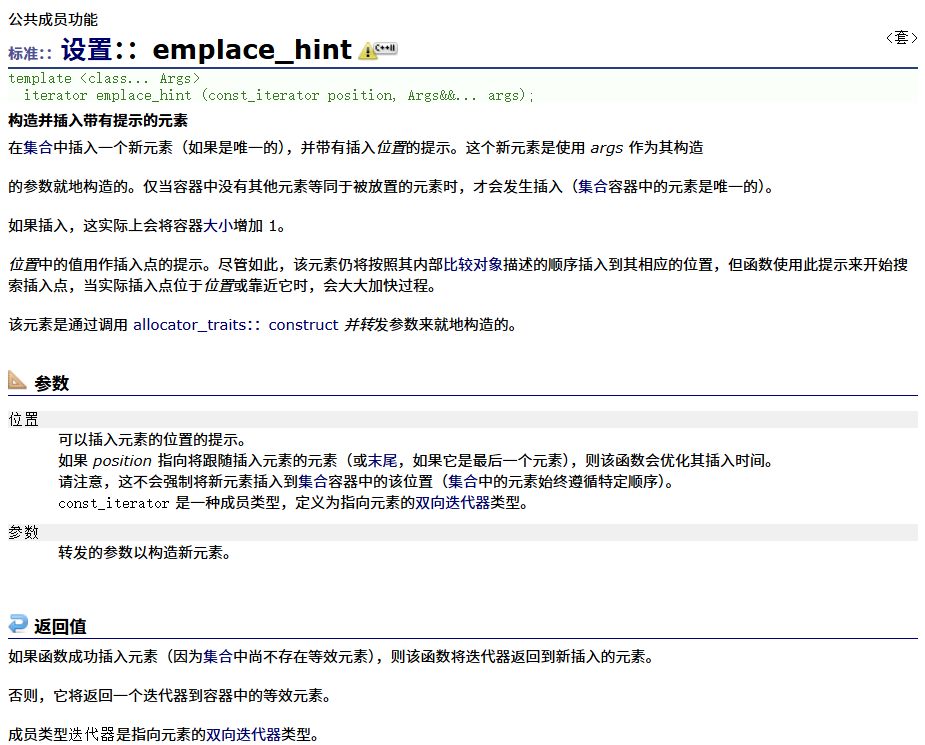
观察者
key_comp 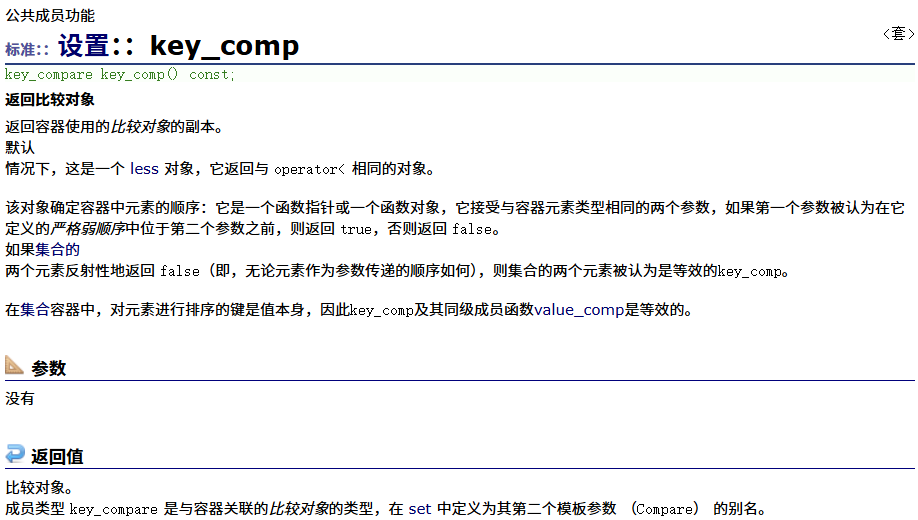
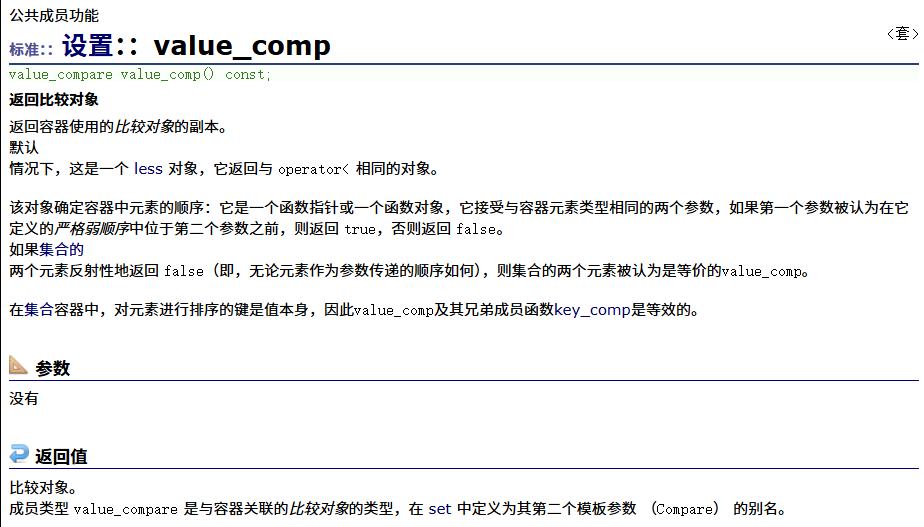
value_comp
操作
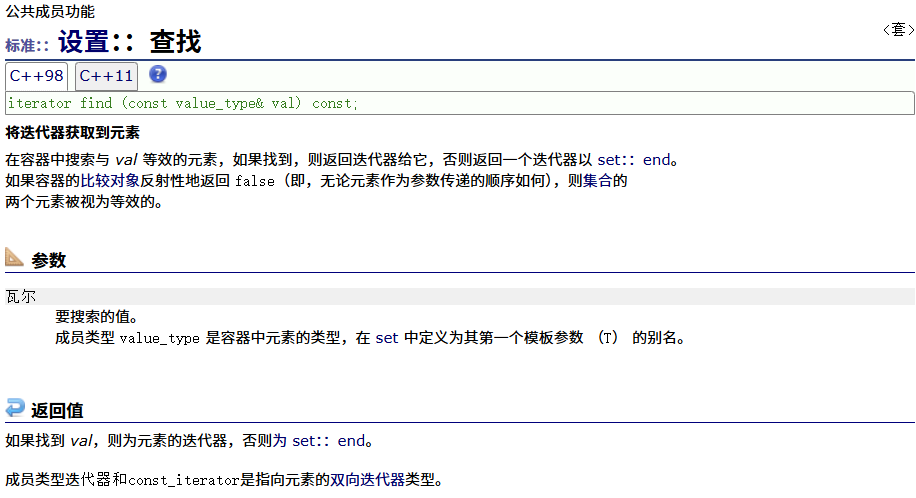
find
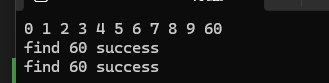
void test2()
{set<int>s = { 0,9,1,4,7,2,3,2,5,8,7,8,3,6,9 };s.insert(60);print(s);//set自己的find//时间复杂度O(log(n))auto it=s.find(60);if (it != s.end()){cout << "find 60 success" << endl;}else{cout << "find 60 failed" << endl;}//算法库的find//时间复杂度O(N)auto ret = find(s.begin(), s.end(), 60);if (it != s.end()){cout << "find 60 success" << endl;}else{cout << "find 60 failed" << endl;}
}算法库也有find函数,但是算法库的find效率比set的低下。
结果为:
multiset中的find中序查找
count

void test3()
{set<int>s = { 0,9,1,4,7,2,3,2,5,8,7,8,3,6,9 };if (s.count(2)){cout << "存在" << " ";}else{cout << "不存在" << " ";}
}结果为:

count是为了和multiset区分,因为它有多个。
lower_bound
upper_bound
void test4()
{set<int>s = { 0,9,1,4,7,2,3,2,5,8,7,8,3,6,9,10,21,10,11,18,19 };//找到[3,9]区间的元素删除//>=3auto it1 = s.lower_bound(3);//>3auto it2 = s.upper_bound(9);//打印区间[it1,it2]for (auto it = it1; it != it2; ++it){cout<<*it<<" ";}cout<<endl;//删除区间[it1,it2]s.erase(it1,it2);print(s);/*for (auto it = it1; it != it2; it++){s.erase(it);}*////print(s);
}结果为:

equal_range
multiset和set的区别
multiset和set的使⽤基本完全类似,主要区别点在于multiset⽀持值冗余,那么insert/find/count/erase都围绕着⽀持值冗余有所差异,具体参看下⾯的样例代码理解。
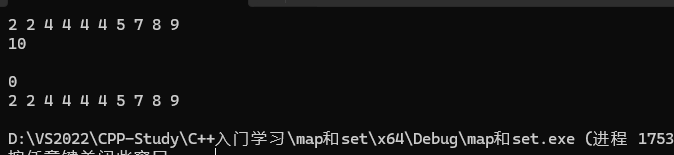
void test5()
{// 相⽐set不同的是,multiset是排序,但是不去重multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;// 相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个int x;cin >> x;auto pos = s.find(x);while (pos != s.end() && *pos == x){cout << *pos << " ";++pos;}cout << endl;// 相⽐set不同的是,count会返回x的实际个数cout << s.count(x) << endl;// 相⽐set不同的是,erase给值时会删除所有的xs.erase(x);for (auto e : s){cout << e << " ";}cout << endl;
}结果为:
set相关的习题
两个数组的交集

老方法:
先使用快慢指针判断是否有环,随后找到环的入口点
新方法:
遍历链表,判断是否在s中,不再就插入,在的第一个就是入口点,如果都不在,就插入了链表结束了都带环,比较两个set,小的++;相等就是交集,同时++。一个遍历就结束了
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//老方法:太麻烦了//是否带环(双指针)//找环的入口点 //新方法:set<Node*>s;//遍历链表,判断是否在s中//不再就插入,在的第一个就是入口点//如果都不在,就插入了链表结束了都带环set<int> s1(nums1.begin(), nums1.end());set<int> s2(nums2.begin(), nums2.end());//// 因为set遍历是有序的,有序值,依次比较//比较//小的++;相等就是交集,同时++。一个练笔就结束了vector<int> ret;auto it1 = s1.begin();auto it2 = s2.begin();while(it1 != s1.end() && it2 != s2.end()){if(*it1 < *it2){it1++;} else if(*it1 > *it2){it2++;} else{ret.push_back(*it1);it1++;it2++;}} return ret;}
};该算法找差集也很合适
1、小的就是差集。小的++
2、相等,同时++
3、一个遍历结束剩下的就是差集
环形链表

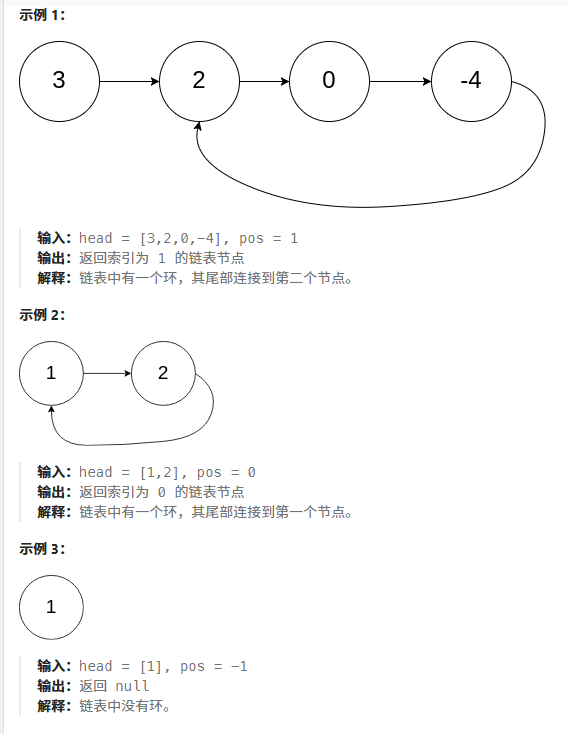
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;ListNode* cur = head;while(cur){auto ret = s.insert(cur);if(ret.second == false)return cur;cur = cur->next;} return nullptr;}
};map的介绍
map和multimap的官方文档:<地图> - C++参考
map的介绍

map的声明如下,Key就是map底层关键字的类型,T是map底层value的类型,set默认要求Key⽀持⼩于⽐较,如果不⽀持或者需要的话可以⾃⾏实现仿函数传给第⼆个模版参数,map底层存储数据的内存是从空间配置器申请的。⼀般情况下,我们都不需要传后两个模版参数。map底层是⽤红⿊树实现,增删查改效率是 O(logN) ,迭代器遍历是⾛的中序,所以是按key有序顺序遍历的
template < class Key, // map::key_type
class T, // map::mapped_type
class Compare = less<Key>, // map::key_compare
class Alloc = allocator<pair<const Key,T> >//map::allocator_type
> class map;pair结构介绍
map底层的红⿊树节点中的数据,使⽤pair<Key, T>存储键值对数据。
pair的官方文档:pair - C++ 参考
typedef pair<const Key, T> value_type;
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}template<class U, class V>pair(const pair<U, V>& pr) : first(pr.first), second(pr.second){}
};
template <class T1, class T2>
inline pair<T1, T2> make_pair(T1 x, T2 y)
{return (pair<T1, T2>(x, y));
}map的接口介绍
构造和析构函数
构造函数

析构函数

=运算符重载
迭代器
正向
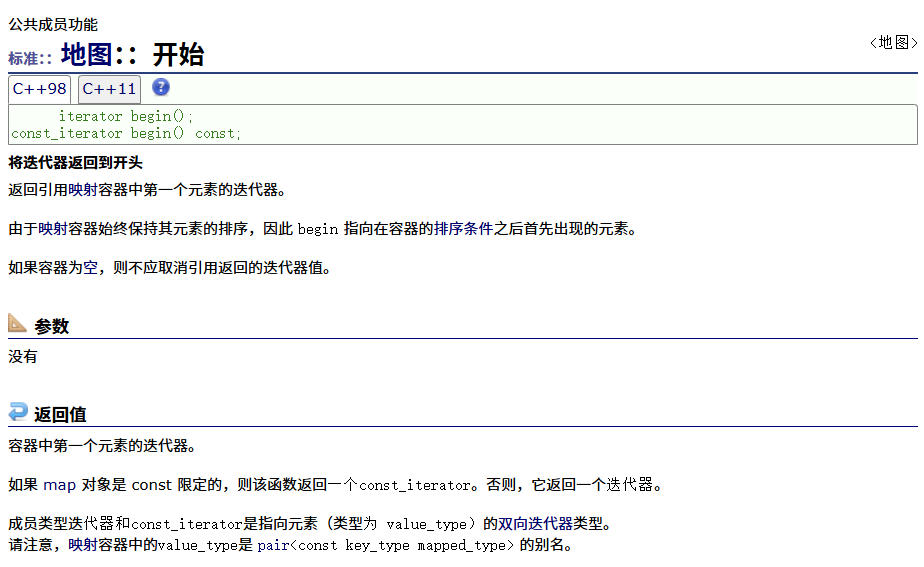
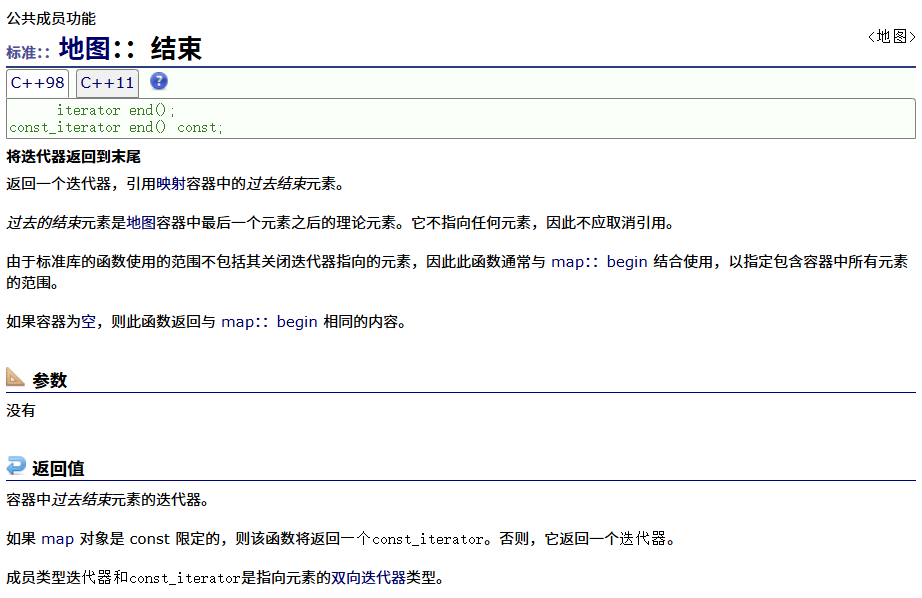
反向
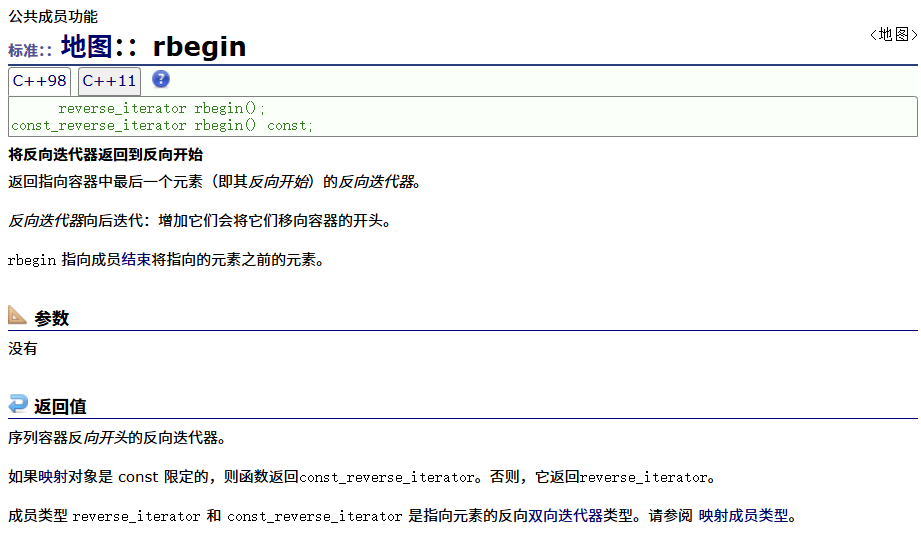

const正向
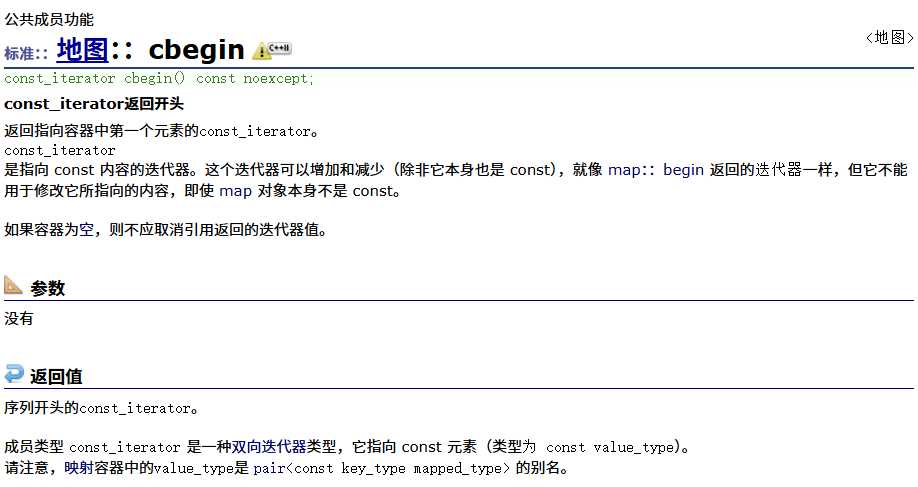
const反向
容量
empty
size
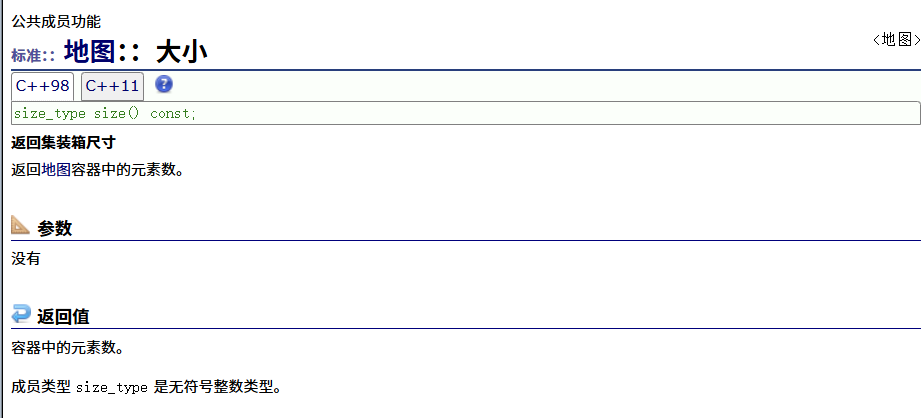
max_size
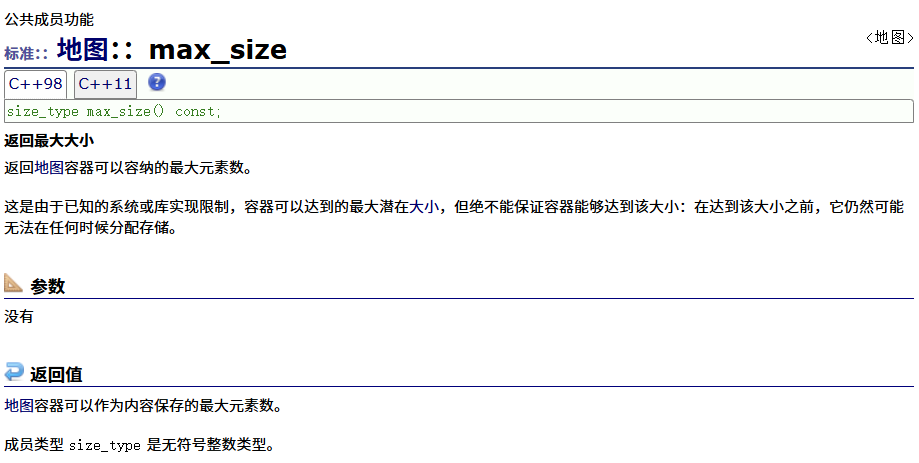
访问
[]运算符重载
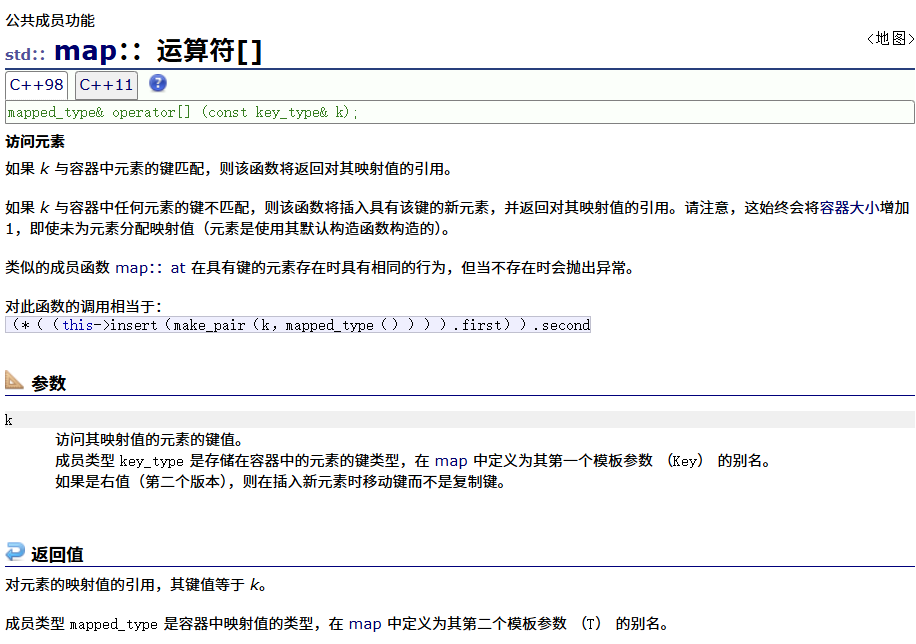
key在map中就插入;如果不在就查找并修改
at
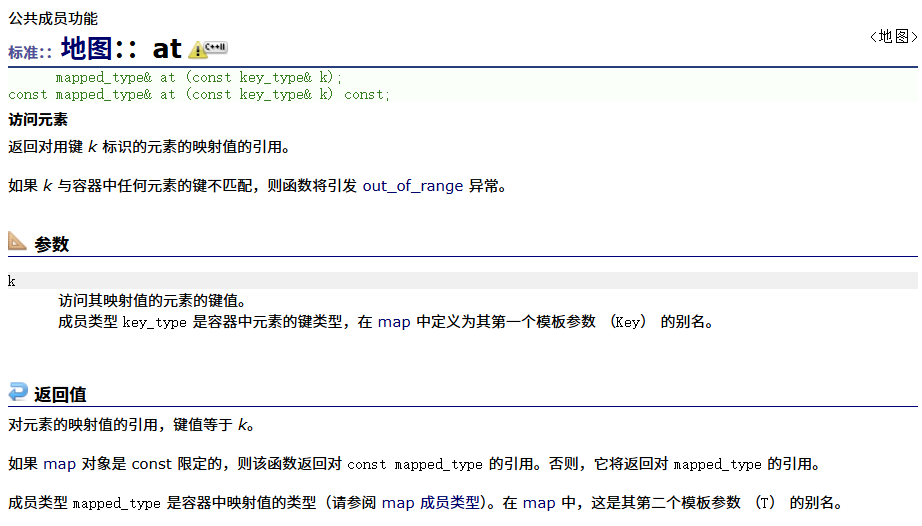
相关函数
insert
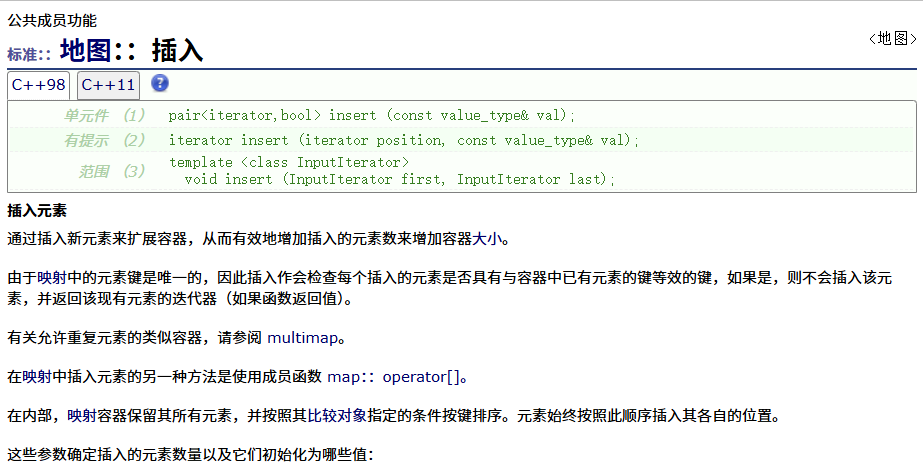
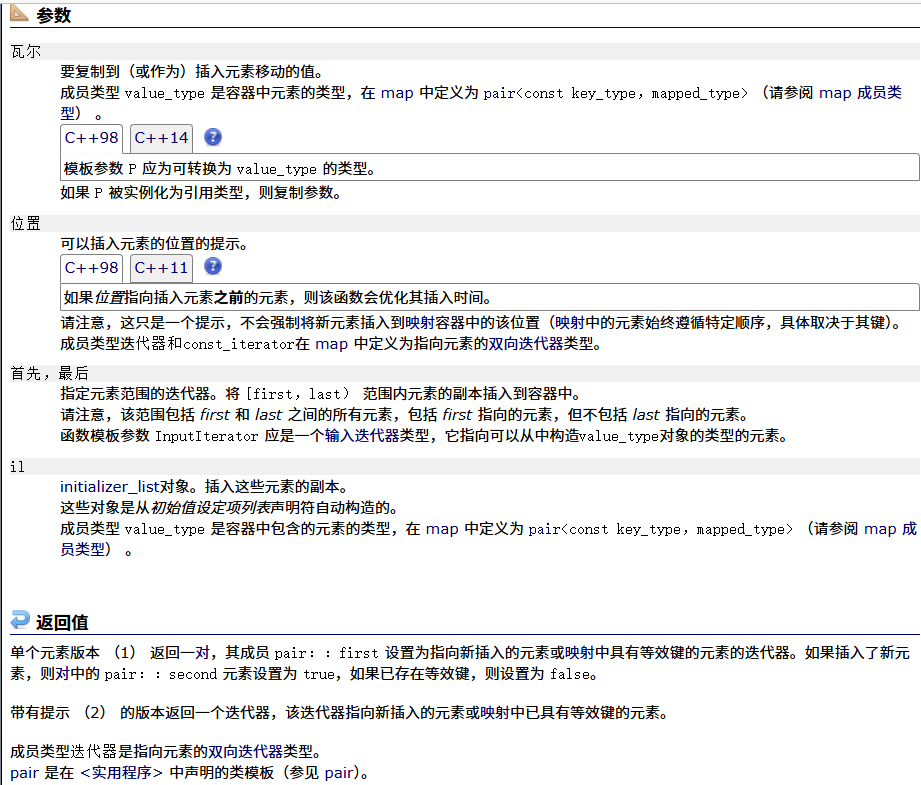
erase
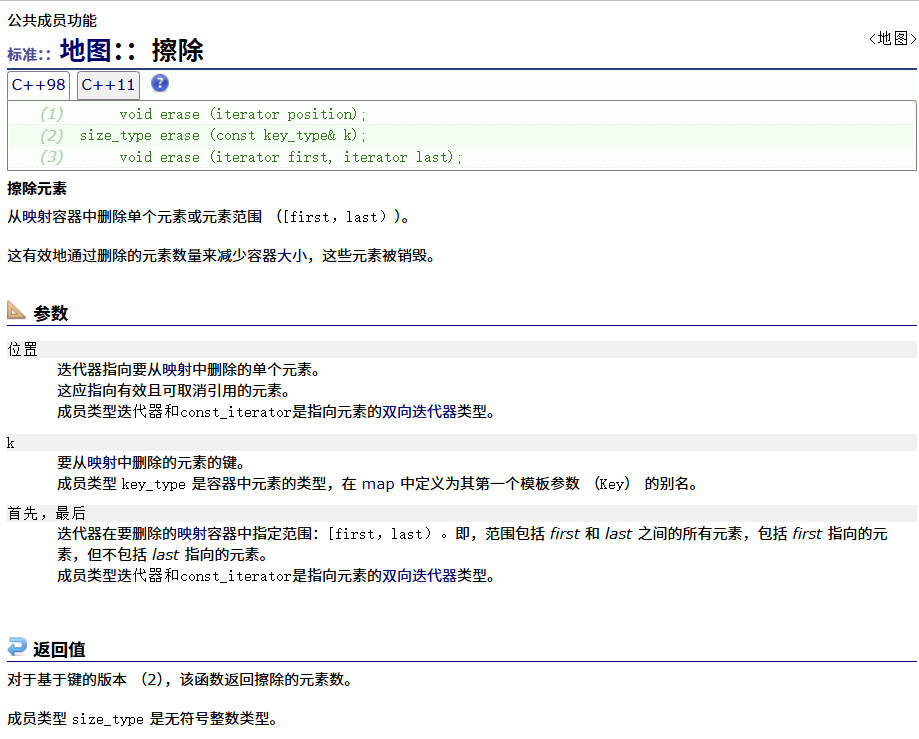
swap

clear
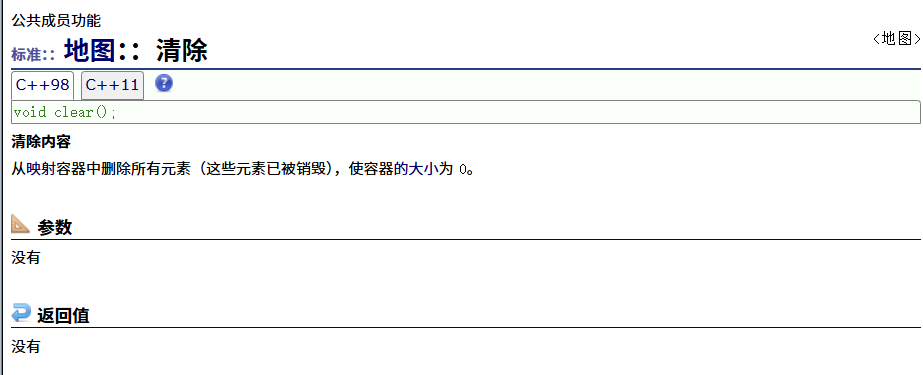
emplace
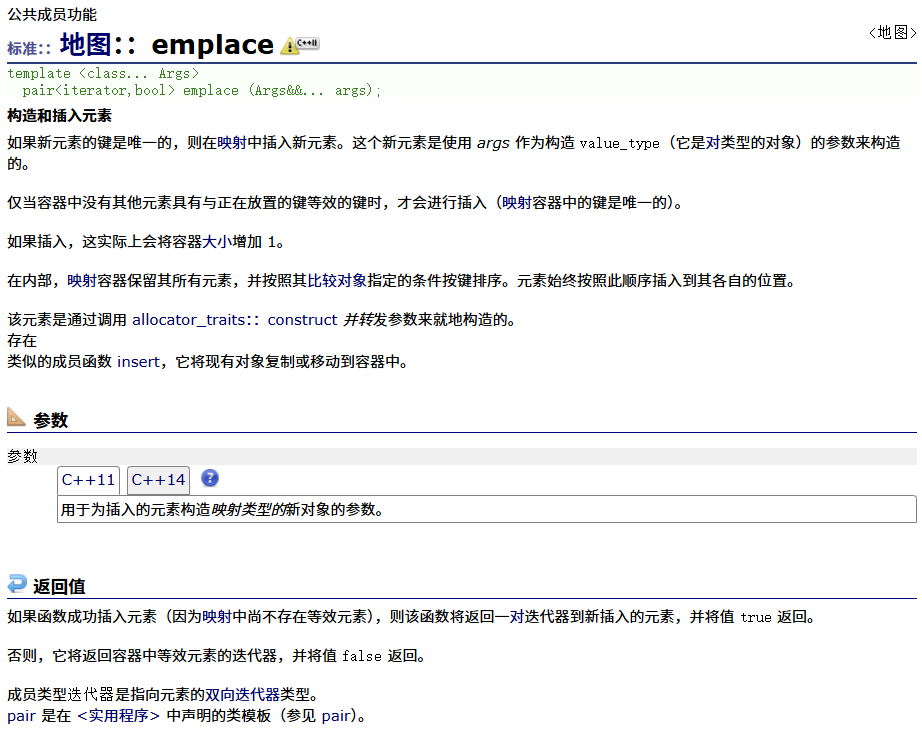
emplace_hint
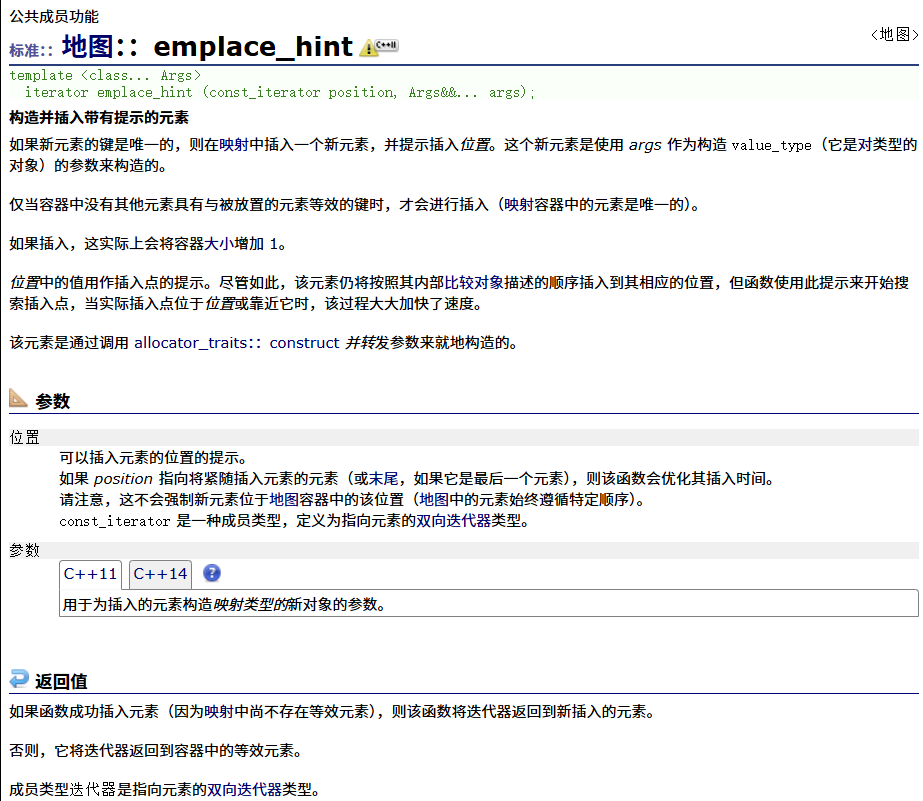
测试:
void test1()
{//比较麻烦的构造方式/*pair<string, string>kv1 = {"sort","排序"};pair<string, string>kv2 = { "left","左" };pair<string, string>kv3 = { "right","右" };pair<string, string>kv4 = { "up","上" };pair<string, string>kv5 = { "down","下" };map<string, string> dirt = {kv1, kv2, kv3, kv4, kv5};*///简化的构造方式map<string, string> dirt = { {"sort","排序"}, {"left","左"}, {"right","右"}, {"up","上"}, {"down","下"} };pair<string, string>kv1 = { "sort","排序" };//dirt.insert(kv1);//make_pair()函数来源于pair文档//make_pair()可以自动推导参数类型,不用模板参数dirt.insert(pair<string, string>{ "sort", "排序" });dirt.insert(make_pair("const","常量属性"));//insert()函数可以自动推导参数类型,不用模板参数//隐式类型转换//推荐这种写法dirt.insert({ "volatile","易变性" });//遍历dirt//map<string,string>::iterator it=dirt.begin();auto it = dirt.begin();while (it!= dirt.end()){//pair没有流重载所以不能写*it//可以这样写cout<<(*it).first<<" : "<<(*it).second<<endl;//更推荐这种写法cout << it->first << " : " << it->second << " ";//相当于//cout << it.operator->()->first << " : " << it.operator->()->second << " ";it++;}cout << endl;//范围forfor (auto& kv : dirt){cout << kv.first << " : " << kv.second << endl;}//使用auto&的原因//避免拷贝开销:/*dirt的元素类型是pair<const string, string>每个pair包含两个string对象,每个string可能包含动态分配的堆内存使用引用auto& 直接访问容器内元素,不创建任何副本*/// 内存布局对比:// 容器内元素: [pair1] -> [key_str_data][val_str_data]// [pair2] -> [key_str_data][val_str_data]// 使用auto&: kv 直接指向容器内元素的内存// 使用auto: kv 是完整的拷贝(包括所有字符串数据)/* 特性 auto& kv auto kv拷贝开销 无拷贝(零开销) 每个元素两次深拷贝内存占用 仅指针大小(约8字节) 每个元素两份完整字符串动态内存 不分配新内存 每次迭代分配新内存修改原容器 可修改value 修改无效(副本)循环速度 ⚡️ 极快 🐢 极慢(尤其大字符串)推荐指数 ★★★★★ ★☆☆☆☆(禁止使用)*///更推荐C++17的结构化绑定//auto& [x, y] = kv1;for (auto& [x, y] : dirt){cout<<"x="<<x<<" y="<<y<<" ";}cout<<endl;
}观察者
key_comp

value_comp
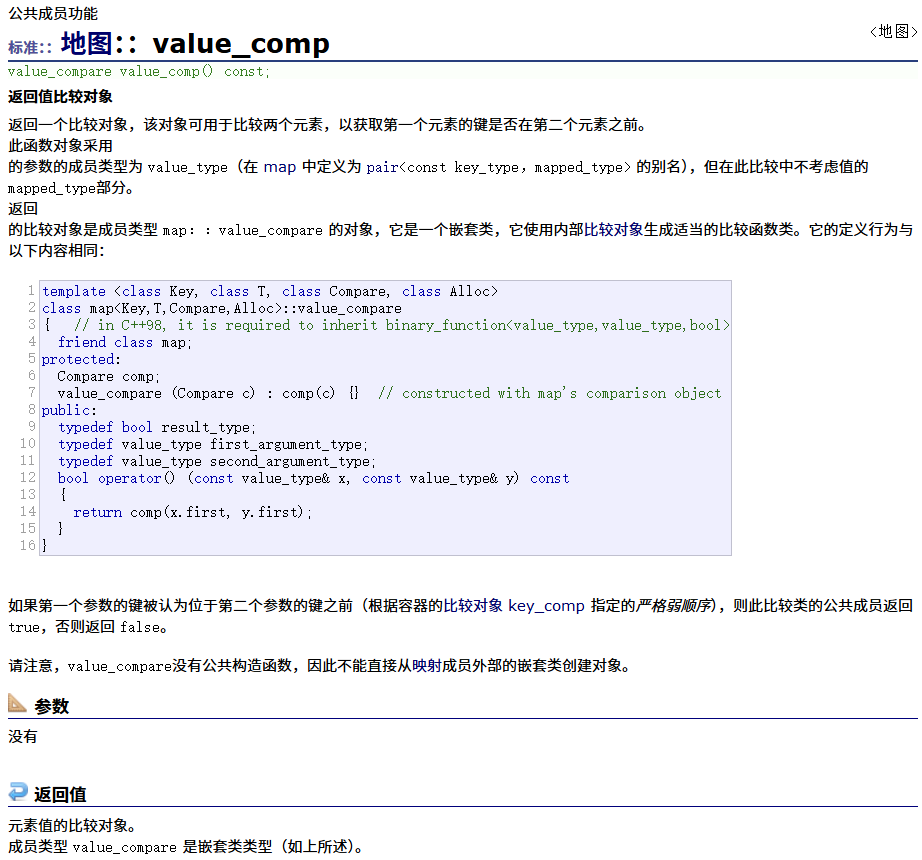
操作
find
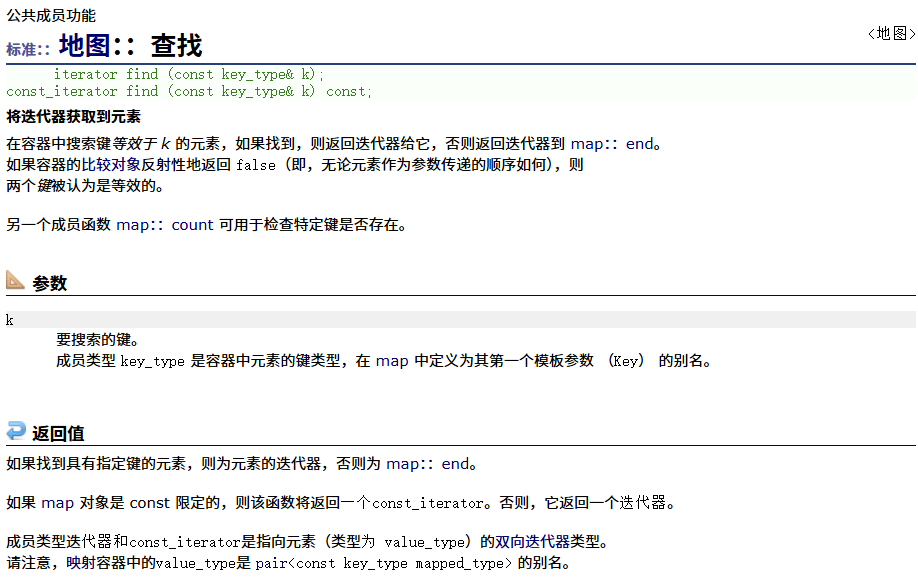
count
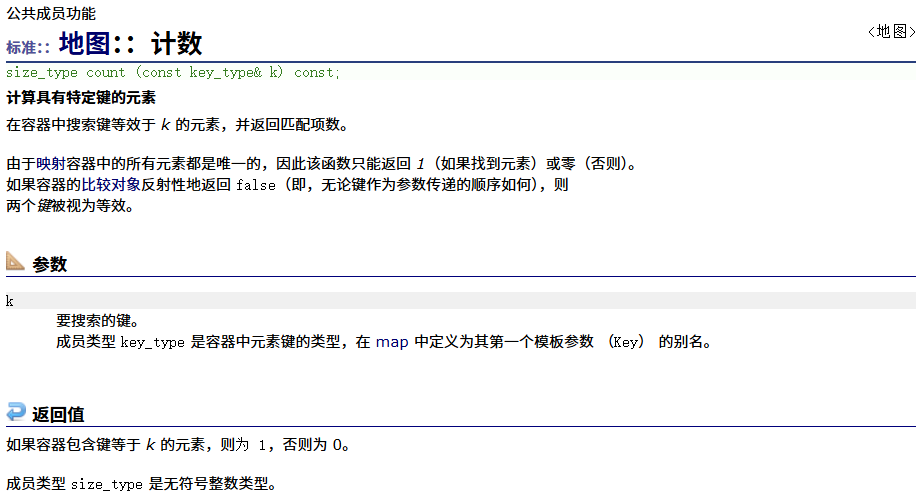
lower_bound

upper_bound

equal_range
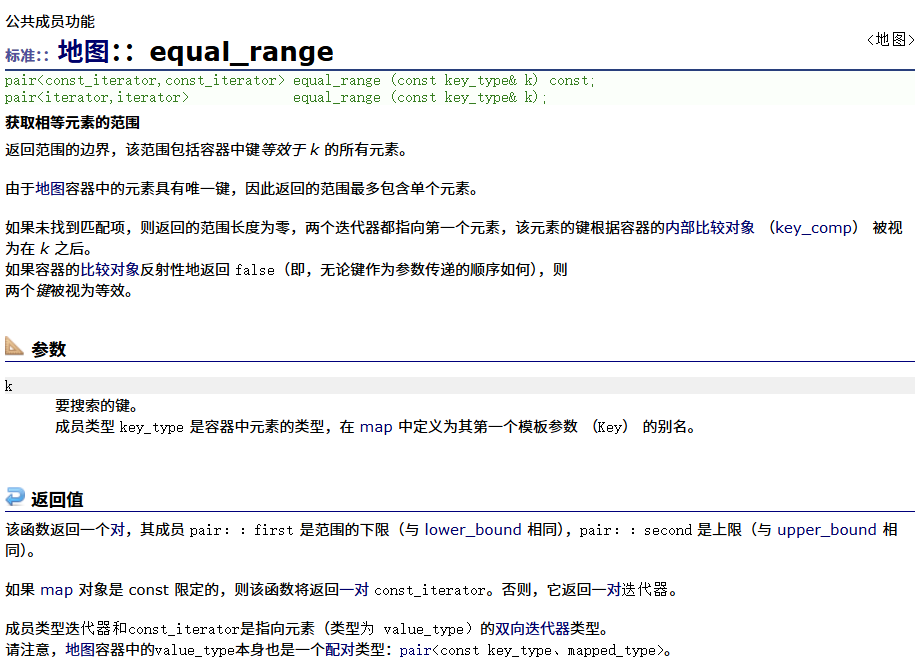
找与key相等的区间[x,y)。
主要适合于multimap
multimap和map的区别
multimap和map的使⽤基本完全类似,主要区别点在于multimap⽀持关键值key冗余,那么insert/find/count/erase都围绕着⽀持关键值key冗余有所差异,这⾥跟set和multiset完全⼀样,⽐如find时,有多个key,返回中序第⼀个。其次就是multimap不⽀持[],因为⽀持key冗余,[]就只能⽀持插⼊了,不能⽀持修改。
map相关的习题
随机链表的复制

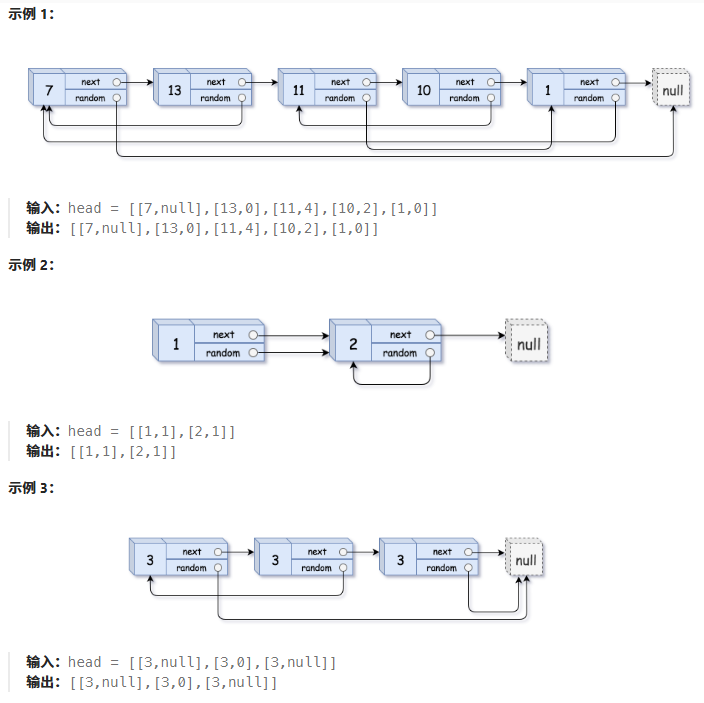
思路:拷贝节点在原节点后面
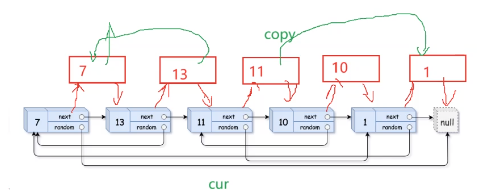
关键的地方在于:copy->random=cur->random->next
步骤:
1、拷贝节点插在原节点后面
2、原节点random控制新节点的random
3、将新节点解下来链接到上面
/*
// Definition for a Node.
class Node {
public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};
*/class Solution
{
public:Node* copyRandomList(Node* head) {map<Node*, Node*> nodeMap;Node* copyhead = nullptr,*copytail = nullptr;Node* cur = head;while(cur){if(copytail == nullptr){copyhead = copytail = new Node(cur->val);} else{copytail->next = new Node(cur->val);copytail = copytail->next;} // 原节点和拷⻉节点map kv存储nodeMap[cur] = copytail;cur = cur->next;} // 处理randomcur = head;Node* copy = copyhead;while(cur){if(cur->random == nullptr){copy->random = nullptr;} else{copy->random = nodeMap[cur->random];} cur = cur->next;copy = copy->next;} return copyhead;}
};前k个高频词汇

class Solution
{
public://老方法:stable_sort函数(稳定排序)// 仿函数// struct compare// {// bool operator()(const pair<string ,int>&kv1,const pair<string ,int>&kv2)// {// return kv1.second>kv2.second;// }// };// vector<string> topKFrequent(vector<string>& words, int k) // {// map<string ,int>countMap;// for(auto& str:words)// {// //统计次数// countMap[str]++;// }// //数据量很大的时候要建小堆// //数据量不大用大堆// //但是这里要按频率所以不建议用小堆// //用排序和大堆都差不多// //不可以用sort直接去排序// //sort要求是随机迭代器,只用string、vector、deque支持// vector<pair<string,int>>v(countMap.begin(),countMap.end());// //sort(v.begin(),v.end(),compare());// //sort不是一个稳定的排序// stable_sort(v.begin(),v.end(),compare());//稳定的排序算法// vector<string>ret;// //取出k个// for(int i=0;i<k;i++)// {// ret.push_back(v[i].first);// }// return ret;//方法二:仿函数//仿函数// struct compare// {// bool operator()(const pair<string ,int>&kv1,const pair<string ,int>&kv2)// {// return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);// }// };// vector<string> topKFrequent(vector<string>& words, int k) // {// map<string ,int>countMap;// for(auto& str:words)// {// //统计次数// countMap[str]++;// }// //数据量很大的时候要建小堆// //数据量不大用大堆// //但是这里要按频率所以不建议用小堆// //用排序和大堆都差不多// //不可以用sort直接去排序// //sort要求是随机迭代器,只用string、vector、deque支持// vector<pair<string,int>>v(countMap.begin(),countMap.end());// //仿函数可以控制比较逻辑// sort(v.begin(),v.end(),compare());//稳定的排序算法// vector<string>ret;// //取出k个// for(int i=0;i<k;i++)// {// ret.push_back(v[i].first);// }// return ret;//方法三:优先级队列struct compare{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2) const{// 比较逻辑:频率高优先,频率相同则字典序小优先return kv1.second < kv2.second ||(kv1.second == kv2.second && kv1.first > kv2.first);}};vector<string> topKFrequent(vector<string>& words, int k){map<string, int> countMap;for (auto& str : words){countMap[str]++;}//数据量很大的时候要建小堆//数据量不大用大堆//但是这里要按频率所以不建议用小堆//用排序和大堆都差不多//不可以用sort直接去排序//sort要求是随机迭代器,只用string、vector、deque支持//建立大堆//priority_queue默认为大堆//不写仿函数的时候priority_queue按pair比,pair默认按小于比priority_queue<pair<string, int>, // - 元素类型: pair<string, int>vector<pair<string, int>>, // - 容器类型: vector<pair<string, int>>compare> // - 比较器类型: compare (去掉括号)pq(countMap.begin(), countMap.end());vector<string> ret;for (int i = 0; i < k; i++){ret.push_back(pq.top().first);pq.pop();}return ret;}
};本期内容就到这里了,喜欢请点个赞谢谢。
封面图自取:
