【LLM】大模型投机采样(Speculative Sampling)推理加速
note
- 投机采样是一种可以从根本上解码计算访存比的方法,保证和使用原始模型的采样分布完全相同。它使用两个模型:一个是原始目标模型,另一个是比原始模型小得多的近似模型。近似模型用于进行自回归串行采样,而大型模型则用于评估采样结果。解码过程中,某些 token 的解码相对容易,某些 token 的解码则很困难。
- 因此,简单的 token 生成可以交给小型模型处理,而困难的 token 则交给大型模型处理。
- 这里的小型模型可以采用与原始模型相同的结构,但参数更少,或者干脆使用 n-gram 模型。小型模型不仅计算量较小,更重要的是减少了内存访问的需求。
文章目录
- note
- 一、自回归解码
- 二、投机解码 Speculative Decoding
- 1、原理解释
- 2、投机采样过程
- 3、评估结果
- 4、vllm在投机采样的加速优化
- 三、MTP和Eagle3投机采样
- 四、相关综述
- Reference
一、自回归解码
当前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理过程可以分为两个阶段:
(1)Prefill:根据输入 Tokens(Recite, the, first, law, of, robotics) 生成第一个输出 Token(A),通过一次 Forward 就可以完成,在 Forward 中,输入 Tokens 间可以并行执行(类似 Bert 这些 Encoder 模型),因此执行效率很高。
(2)Decoding:从生成第一个 Token(A) 之后开始,采用自回归方式一次生成一个 Token,直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束,假设输出总共有 N 个 Token,则 Decoding 阶段需要执行 N-1 次 Forward,这 N-1 次 Forward 只能串行执行,效率很低。另外,在生成过程中,需要关注的 Token 越来越多(每个 Token 的生成都需要 Attention 之前的 Token),计算量也会适当增大。
二、投机解码 Speculative Decoding
1、原理解释
大模型的投机采样(Speculative Sampling)就像是让一个小助手先去猜测接下来会发生什么,然后由大模型来验证这些猜测是否正确。如果猜测对了,就可以直接用这些结果,从而节省大模型自己一步步推理的时间。
具体过程是这样的:
- 小模型先猜:先用一个小模型(草稿模型)快速生成一批可能的“候选token”。
- 大模型验证:然后用大模型(主模型)一次性验证这些候选token是否符合它的预测。
- 对齐则接受,错了则回退:如果小模型猜对了,大模型就直接接受这些结果,省去了逐个生成的时间;如果猜错了,大模型会修正错误的部分。
这种机制可以显著减少大模型的推理步骤,提升推理速度,同时还能保证生成结果的质量。
投机解码过程举例:
(1)draft模型生成下面第一行,但中间的cooking错误
(2)target模型进行验证draft模型刚才先生成的几个token,发现cooking错误,于是改为playing

2、投机采样过程
Google 和 Deepmind 于 2022 年提出投机采样方案 Fast Inference from Transformers via Speculative Decoding,其思路很简单,使用一个高效的小模型来生成多个候选 Token,然后让 LLM 来验证。

假设 MpM_pMp 为目标模型,模型推理就是给定前缀输入 x<1x_{<1}x<1 ,从模型获得对应的分布 p(xt∣xct)p\left(x_{\mathrm{t}} \mid x_{\mathrm{ct}}\right)p(xt∣xct) ,要做的就是加速这个推理过程;假设 MqM_qMq 为针对相同任务的更高效的近似模型,给定前缀输入 xex_{\mathrm{e}}xe ,从模型可以获得对应的分布 q(xt∣xe)\mathrm{q}\left(\mathrm{x}_{\mathrm{t}} \mid \mathrm{x}_{\mathrm{e}}\right)q(xt∣xe) 。核心思想为:
a.使用更高效的模型 Mq\mathrm{M}_{\mathrm{q}}Mq 来生成输出 r∈Z+r \in \mathbb{Z}^{+}r∈Z+个 Token
b.使用目标模型 Mp\mathrm{M}_{\mathrm{p}}Mp 来并行的评估上一步 Mq\mathrm{M}_{\mathrm{q}}Mq 生成的 Token,接受能够满足同一分布的 Token
c.从调整后的分布中生成一个额外的 Token(根据第一个出错 Token 之前的 Token 生成),来修复第一个出错的 Token,如果所有 Token 都被接受,则额外新增一个新生成的 Token,以此来保证每次至少生成一个新的 Token。这样,即使在最坏情况下,目标模型相当于完全串行运行,运行次数也不会超过常规模式直接串行运行目标模型的次数;当然,也很可能能够生成更多的 Token,最多可以达到 r+1r+1r+1 ,这取决于 Mp\mathrm{M}_{\mathrm{p}}Mp 和 Mq\mathrm{M}_{\mathrm{q}}Mq 的相似度。
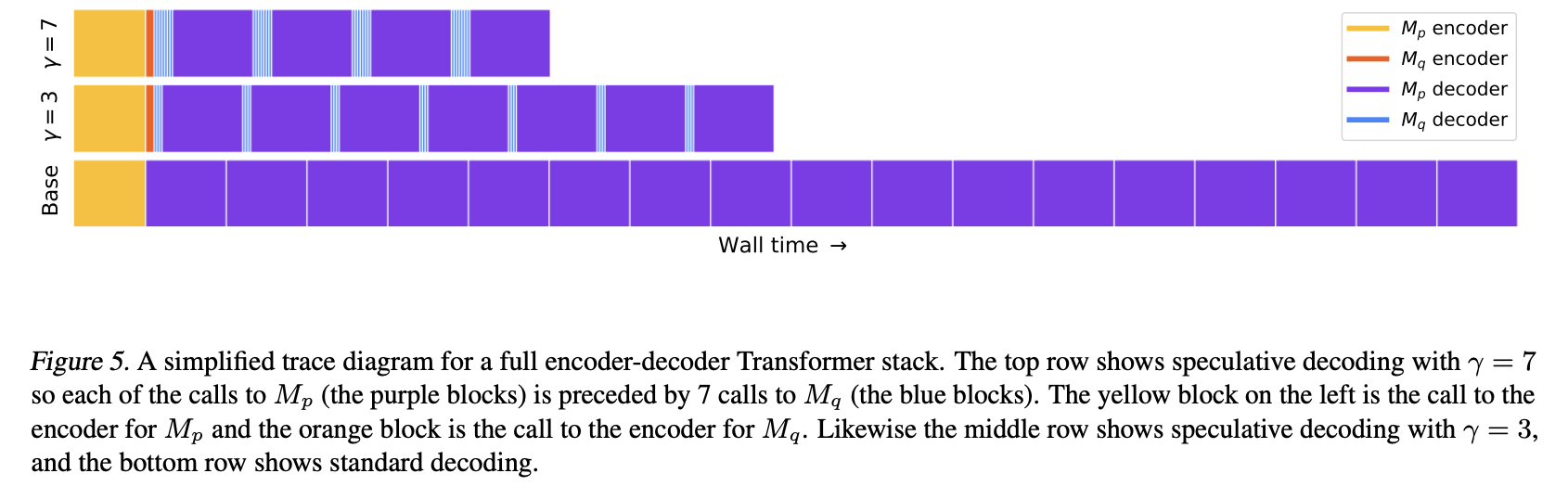
如下图 Figure 5 所示,作者提供了一个简单的示例,包含不同的 rrr(验证的 Token 数目),其中紫色为执行目标模型 MpM_pMp 的 decoder,蓝色为执行近似模型 MqM_qMq 的 decoder,黄色和橙色为调用 encoder。
3、评估结果
作者基于 T5X 代码库验证了 T5-XXL 模型的加速效果。相关的设置如下:
- 模型:标准的 encoder-decoder T5 1.1 版本模型
a.目标模型 MpM_pMp :T5-XXL(11B)
b.近似模型 Mq\mathrm{M}_{\mathrm{q}}Mq :T5-Large(800M),T5-Base(250M),T5-Small(75M) - 任务:
a.英语到德语翻译,基于 WMT EnDe 数据集微调
b.文本总结,基于 CCN/DM 数据集微调 - 硬件:TPU-v4
- 推理参数:
- a.Batch-size: 1
- b.Argmax sampling(temp=0)和 standard sampling(temp=1)
结果如下 Table 2 所示,最小的近似模型 T5-Small(75M)获得最高的加速比(模型很小,推理最快,而且模型生成质量相比 Base 模型没有下降太多,α\alphaα 表示高效模型的质量与目标模型的接近程
度),比如 T5−T 5-T5− Small 在 EnDe 任务上,当 temp =0=0=0 时获得 3.4 倍加速,temp =1=1=1 时获得 2.6 倍加速:

4、vllm在投机采样的加速优化
vllm的优化:优化调度器(使得能够同时生成和验证多个token)、优化内存管理器(处理draft模型和target模型的kv cache)

三、MTP和Eagle3投机采样
目前性能强劲的投机采样技术分别有MTP和Eagle3,但MTP其需要在预训练阶段与基础模型一起训练,限制了MTP在业界的广泛应用。而Eagle3作为一种训练后而集成的技术,很适合在已开源的超大尺寸模型上继续训练,而进一步提升推理效率。
四、相关综述
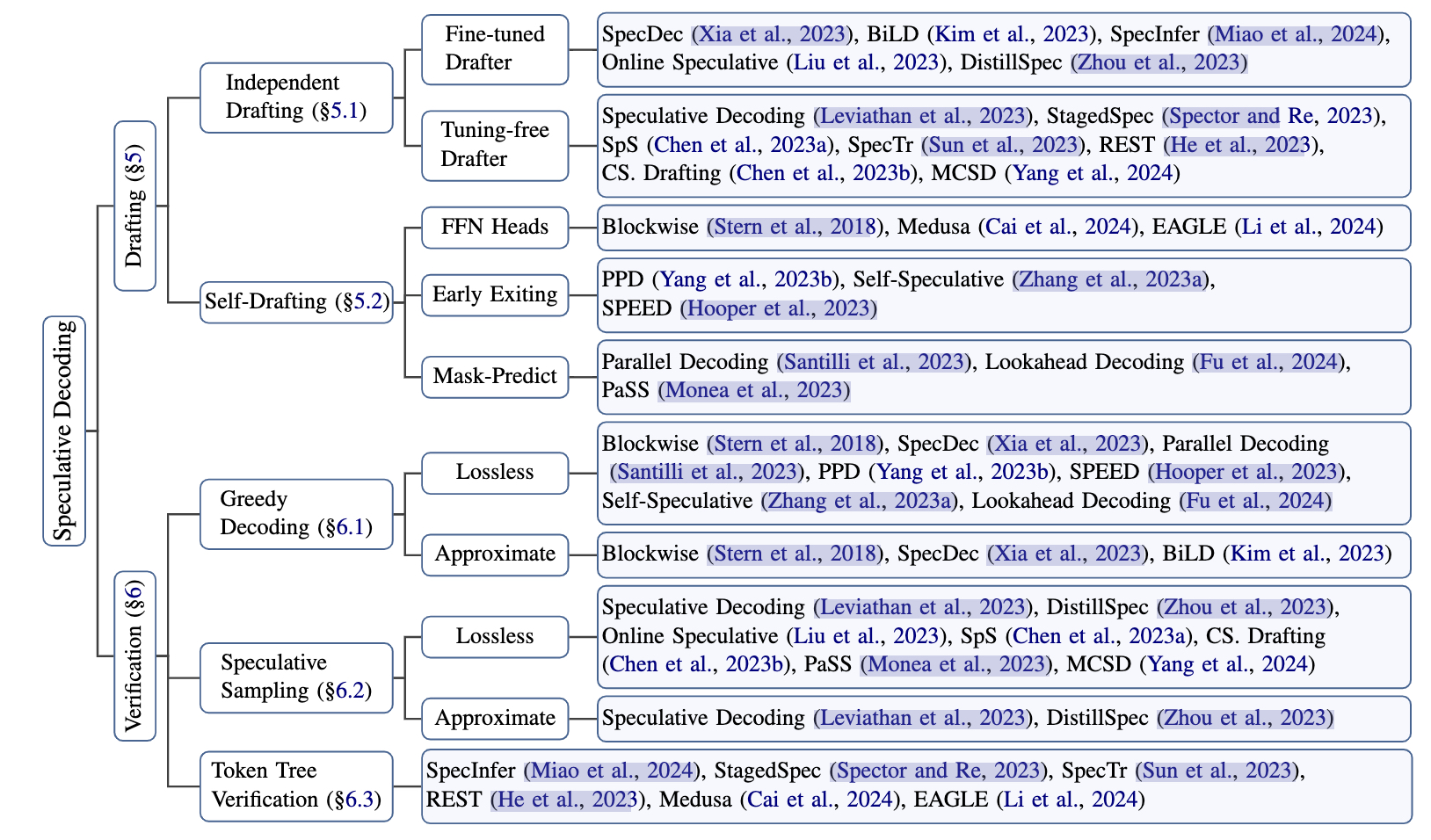
图源自:Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Reference
[1] 打通投机采样最后一公里!SGLang联合美团技术团队开源投机采样训练框架
[2] Fast Inference from Transformers via Speculative Decoding
[3] Accelerating large language model decoding with speculative sampling
https://zhuanlan.zhihu.com/p/651359908
[4] 大模型推理妙招—投机采样(Speculative Decoding)
[5] 万字综述 10+ 种 LLM 投机采样推理加速方案
[6] Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding