【MySQL】事务的基本概念
目录
- 事务是什么
- 事务的回滚机制
- 事务的ACID特性(重点)
- 原子性 (Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
- 使用事务
- 前提条件
- 语法
- 保存点
- 事务的手动提交和自动提交
- 手动提交
- 自动提交
- 事务的隔离性和隔离级别(重点)
- 隔离性是什么
- 为什么要有隔离级别
- 查看和设置隔离级别
- READ UNCOMMITTED - 读未提交与脏读
- READ COMMITTED - 读已提交与不可重复读
- REPEATABLE READ - 可重复读与幻读(MySQL默认隔离级别)
- SERIALIZABLE - 串⾏化
- navicate客户端注意
事务是什么
- 事务就是把一组SQL语句打包成一个整体, 要么全部执行完成, 要么一条也不执行. 这组事务的SQL语句可以是一条, 也可以是多条.
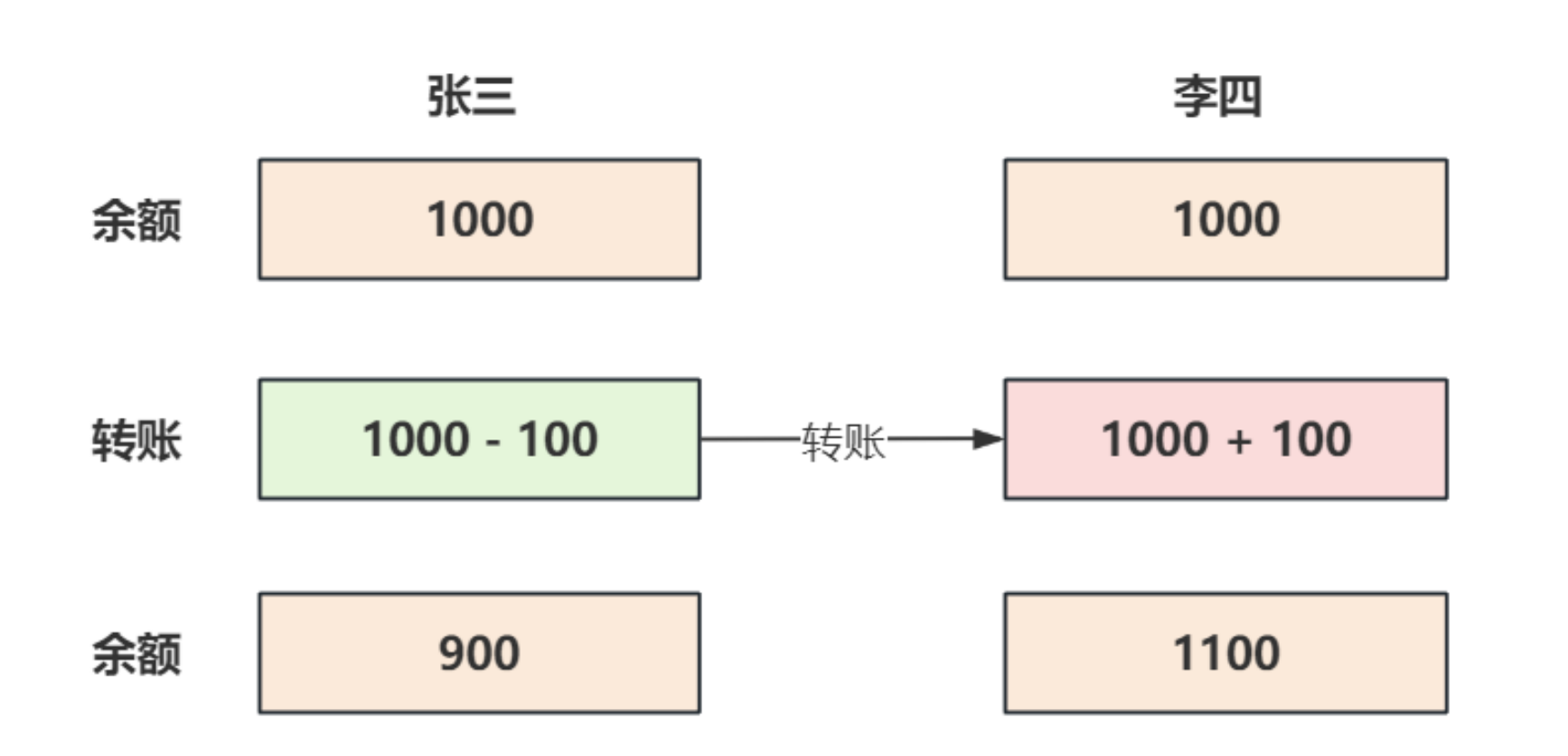
- 在这个事务当中, 我们涉及到两条SQL语句
# ================更新操作===================
# 张三余额减少100
UPDATE bank_account set balance = balance - 100 where name = '张三';
# 李四余额增加100
UPDATE bank_account set balance = balance + 100 where name = '李四';
- 这两条语句就可以打包成一个事务执行
事务的回滚机制
-
在前面的例子中, 我们是说明了这两条SQL语句执行成功的情况. 但是由于各种原因, 有可能我们的事务也会执行失败. 比如说服务器突然崩溃, 断电, 会导致正在运行的事务停止, 发生异常. 那么在转账的例子中, 我们可能出现张三已经把钱转出去了, 张三的余额也变少了. 但是李四并没也收到转账, 那这个问题就大了.
-
对于这种问题的出现, 我们MySQL就给出了回滚机制这个解决方案.
-
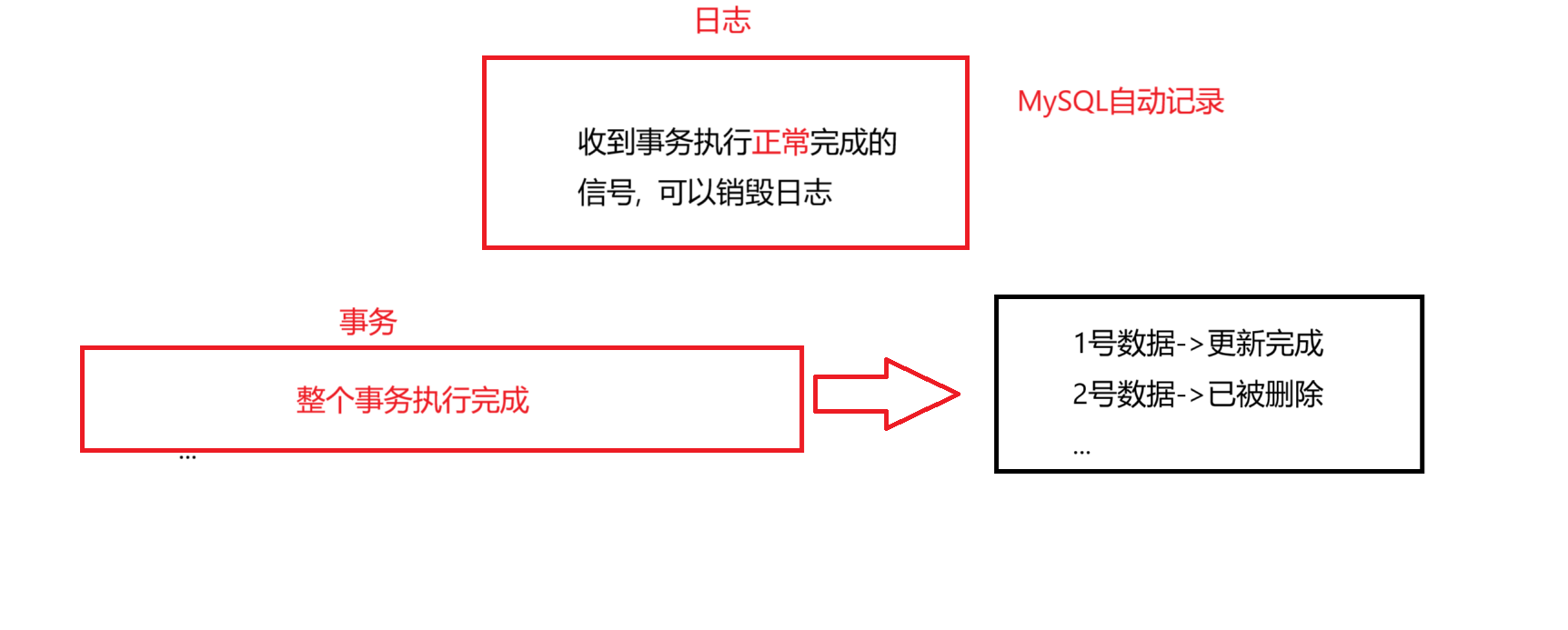
在我们数据库运行的时候, 每次进行增/删/改涉及改动数据的操作的时候, 都会用一个日志, 把当前的操作记录下来.

-
当整个事务提交并完成的情况
-
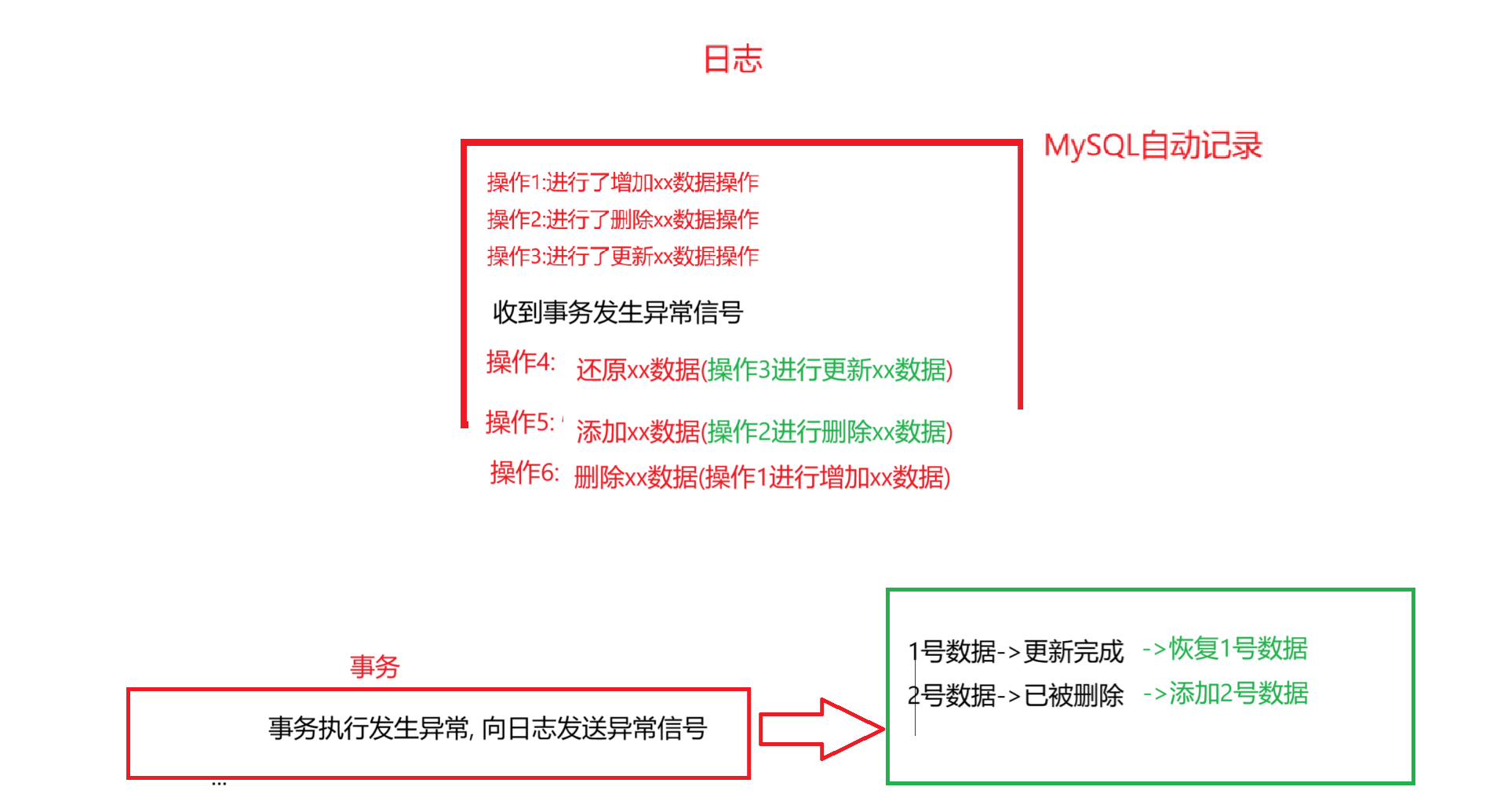
当事务执行的过程中, 出现了异常情况, 我们就会对日志中做出的操作进行相反操作, 把增/删/改的数据恢复. 这就叫做回滚机制
事务的ACID特性(重点)
原子性 (Atomicity)
- 也就是我们上面说的事务要么全部执行, 要么一句也不执行. 但是通过上面的回滚机制( Rollback)了解到, 一句也不执行并非是真的一句也不执行, 而是事务执行过程中如果发生异常, 那么就会通过日志来恢复执行的操作来还原数据, 这样的效果就看起来是一句SQL语句也没有执行.
一致性(Consistency)
- 总的来说就是事务执行前和执行后, 数据必须是合理的, 符合逻辑的.
- 在执行前的总金额是800, 执行后的总金额也是800, 就算是事务的执行过程中发生了异常, 通过回滚机制也可以让数据恢复到执行事务前的状态, 所以事务的原子性对一致性也提供了保证. 这就是事务的一致性

隔离性(Isolation)
- 数据库允许多个客户端对服务器发送事务执行, 服务器会进行并发处理(也就是一心二用, 同一时刻做多个事情), 但是就和人一样, 一旦同时处理的事情多了, 我们就可能会导致出错, 数据库也是如此, 如果同时执行的事情多了, 可能会导致数据出错, 不一致. 为了防止这个情况, 事务可以指定不同的隔离级别. 来解决这个问题.
持久性(Durability)
- 事务处理结束后,对数据的修改将永久的写⼊硬盘,即便系统故障也不会丢失。
使用事务
前提条件
- 要使⽤事务那么数据库就要⽀持事务,在MySQL中⽀持事务的存储引擎是InnoDB,可以通过
show engines; 语句查看:
语法

- 现在bank表中原本有两条数据, balance都是1000.0
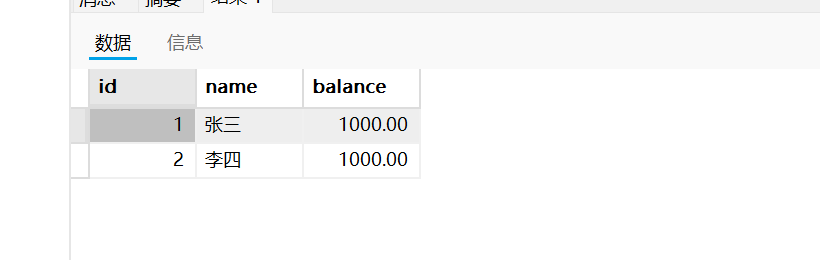
- 现在执行张三扣100, 李四加100, 在更新完后, 事务中查询的确是这样.
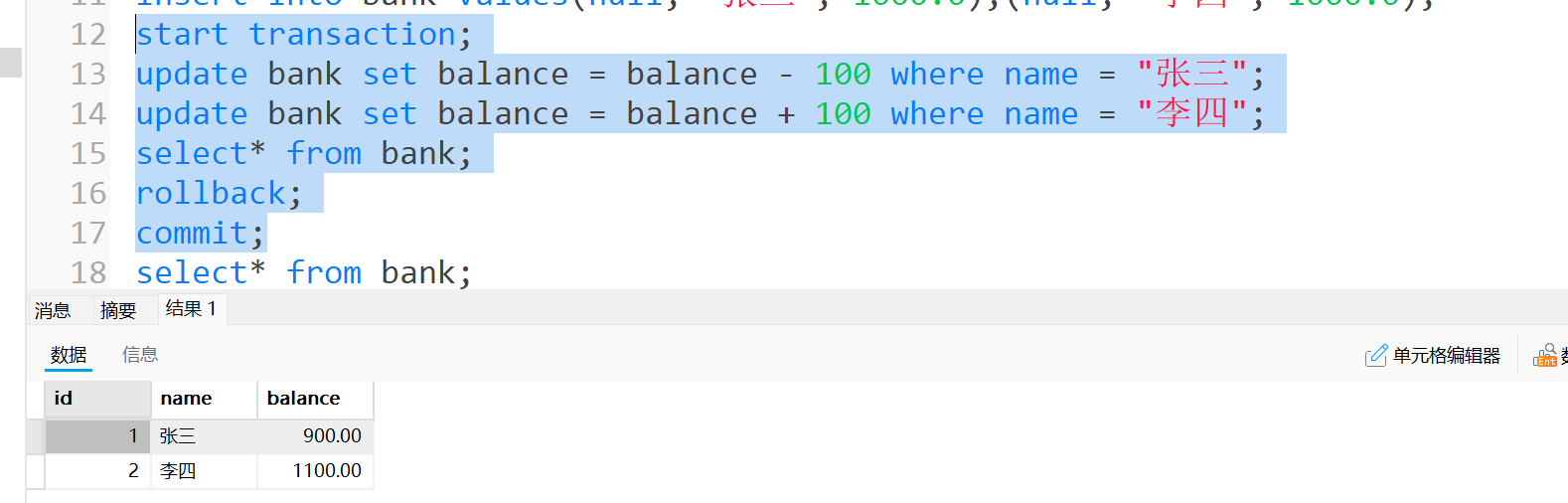
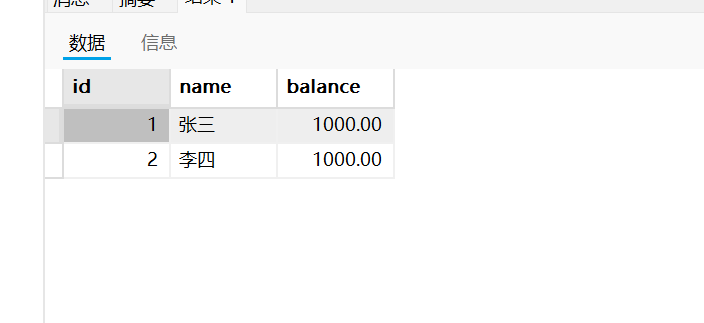
- 但是由于我们rollback(回滚), 就把我们刚刚的操作全部撤回. 数据就恢复当事务执行前的状态.
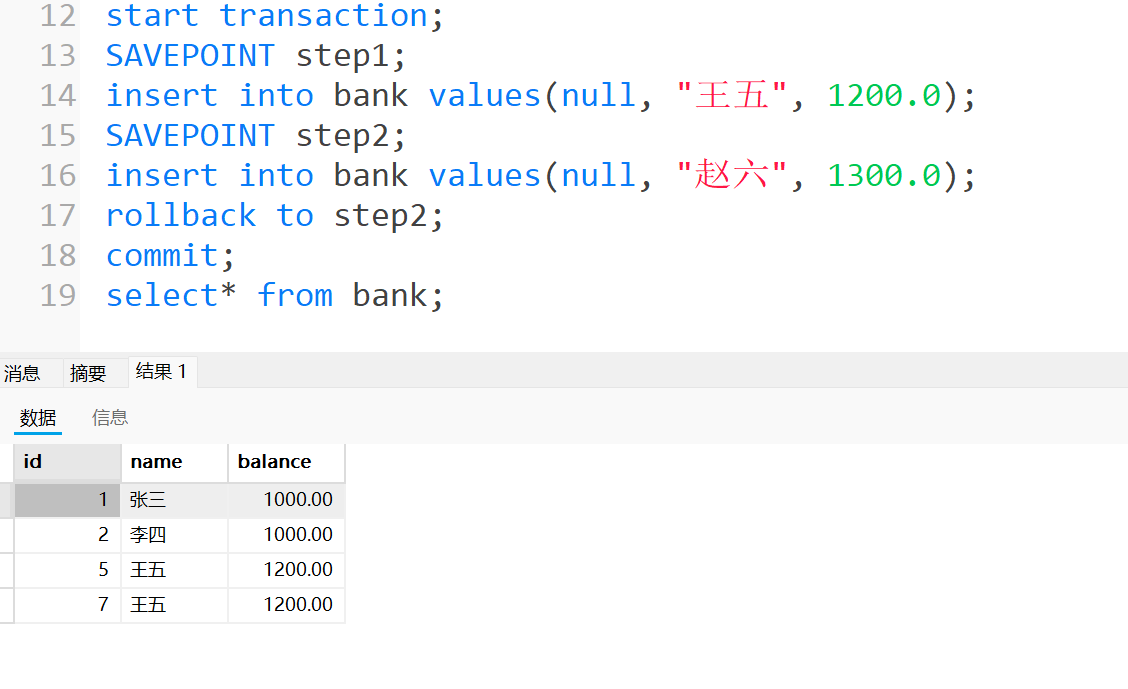
保存点
- 语法:SAVEPOINT sp1; – 创建一个名为 sp1 的保存点
- 回滚到保存点语法: ROLLBACK TO SAVEPOINT savepoint_name;
- 保存点就像我们打游戏的存档功能一样, 比如说我们大黑猴子到了打那个大头娃娃的哪里, 突然你要出去办点事情, 就可以存档你的游戏进度到大头娃娃哪里去了, 等你事情办完了可以回来打开这个存档继续从这个进度开始打, 如果你没有进行存档, 那么游戏进度自动清0了, 你就又得从新来一遍. 这就很反人性了.
- 所以我们数据库的回滚机制也是一样的, 如果我确保前面的事务执行一切正常, 我们可以回滚到判定出异常的那一部分. 而不用让事务从头开始执行.
- 这里我们返回到第二个保存点就是已经插入了王五哪里, 后面的赵六没有插入, 那么事务也就没有插入赵六.
事务的手动提交和自动提交
手动提交

- • ⼿动提交模式下,不⽤显⽰开启事务,执⾏修改操作后,提交或回滚事务时直接使⽤ commit
或 rollback - 已提交的事务不能回滚
自动提交

- 我们之前的单句执行的SQL语句就是自动提交的.
事务的隔离性和隔离级别(重点)
隔离性是什么
- 在前面的ACID特性中我们的第三个特性就是隔离性, 总的来说就是我们很多时候在多个客户端向一个MySQL服务器提交事务, 数据库就会采用并发的处理方式来处理这些事务, 而我们前面说了, 并发操作就是一心二用, 在事情多了的时候, 是很可能会把数据搞错的. 所以我们MySQL提出了隔离级别来解决这种情况. 但是我们不同的隔离级别, 对多个事务, 有着不同的隔离效果, 也就是不完全隔离和完全隔离.
为什么要有隔离级别
- 可能有人会有疑问, 为什么知道并发可能会导致数据出错还不完全隔离. 而是让程序员自己选择隔离级别到底完全隔离还是不完全隔离. 这就要从我们的不同业务场景来说了
- 有的业务追求效率, 有的业务追求准确性.
- 比如我们抖音点赞, 我们可以看到评论区的点赞数是没有给出一个准确的数字的. 通常是看2.2w, 3.3w什么的整体数字, 因为我们点赞是要求我们用户点了那个爱心, 就立马变红表示我们点赞了, 让用户立马得到反馈. 而不是让用户等个1, 2秒吧, 这就是追求效率的场景.
- 再看我们银行转账, 我们银行转账的时候都是给我们客户说, 最多2个小时之内可以得到转账, 这个时候我们银行就是放弃了效率, 宁愿多花费一些时间, 把转账的数据搞对, 我们转出去多少钱, 别人就收到多少钱, 避免出现转出去别人没收到钱等情况, 这就是追求准确率的场景.
总结一下:
- 隔离级别越高. 并发越弱; 效率越低, 准确率越高.
- 隔离级别越低, 并发越强, 效率越高, 准确率越低.
- 我们要根据不同的业务场景来选择隔离级别.
查看和设置隔离级别
- 事务的隔离级别分为全局作⽤域和会话作⽤域,查看不同作⽤域事务的隔离级别,可以使⽤以下的
⽅式:
# 全局作⽤域
SELECT @@GLOBAL.transaction_isolation;
# 会话作⽤域
SELECT @@SESSION.transaction_isolation;
- 会话作用域只对当前客户端生效, 而全局作用域是多个客户端生效.
# ⽰例
# 设置全局事务隔离级别为串⾏化,后续所有事务⽣效,不影响当前事务
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
# 设置会话事务隔离级别为串⾏化,当前会话后续的所有事务⽣效,不影响当前事务,可以在任何时候
执⾏
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
READ UNCOMMITTED - 读未提交与脏读
- 这个隔离级别, 对两个事务执行的顺序没有做出任何的干预
- 这个时候就会出现一个错误就是脏读, 脏读就指的就是事务A未提交的情况下, 事务B直接去读取事务A的数据. 那么这个时候事务A如果发生回滚或异常, 就会把数据还原回去. 这个时候事务B读取的事务A数据就是事务A还原之前的数据, 这个时候由于事务A还原了数据, 被事务B读取的还原之前的数据就是脏数据.
- 事务A, 可以看到我们原始数据两个都是1000, 现在执行事务A张三向李四转账500, 这个时候事务A还没提交
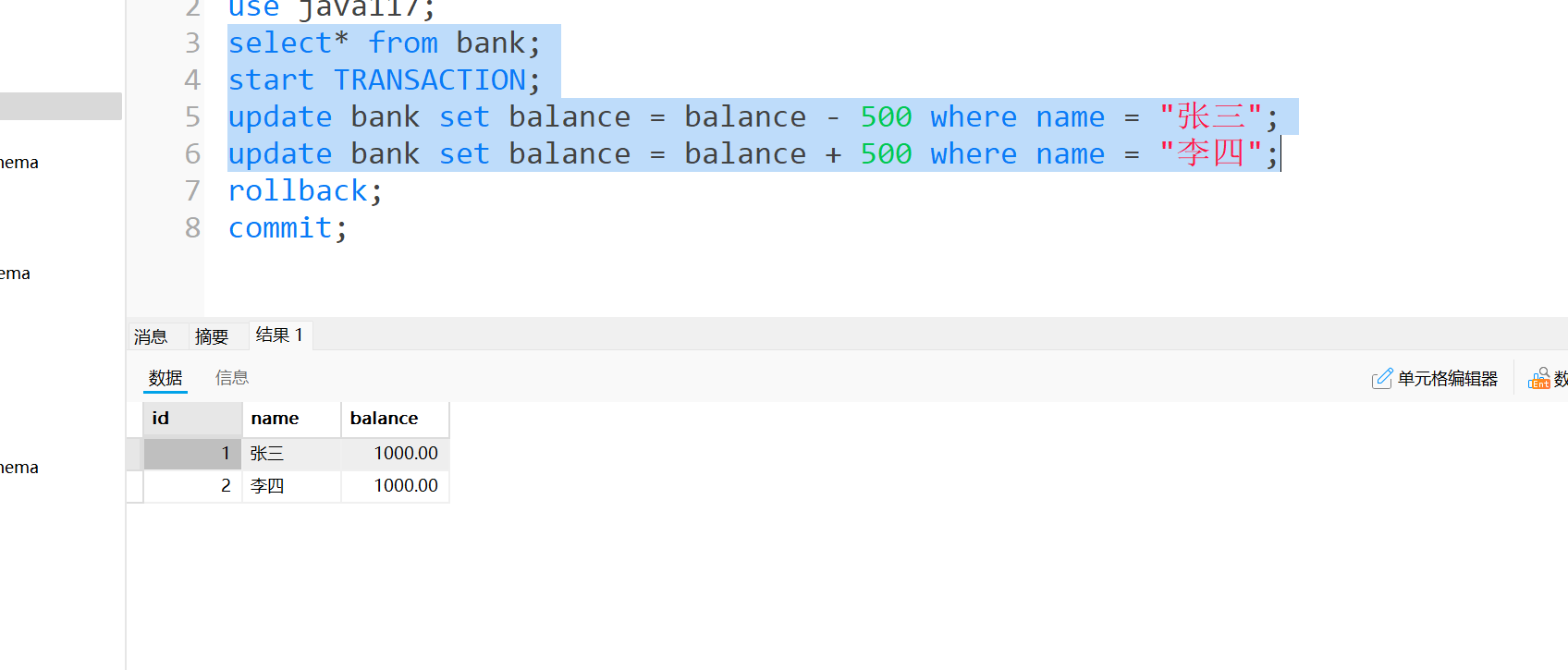
- 事务B: 可以看到我们现在事务B读取的就是事务A转账后的数据.
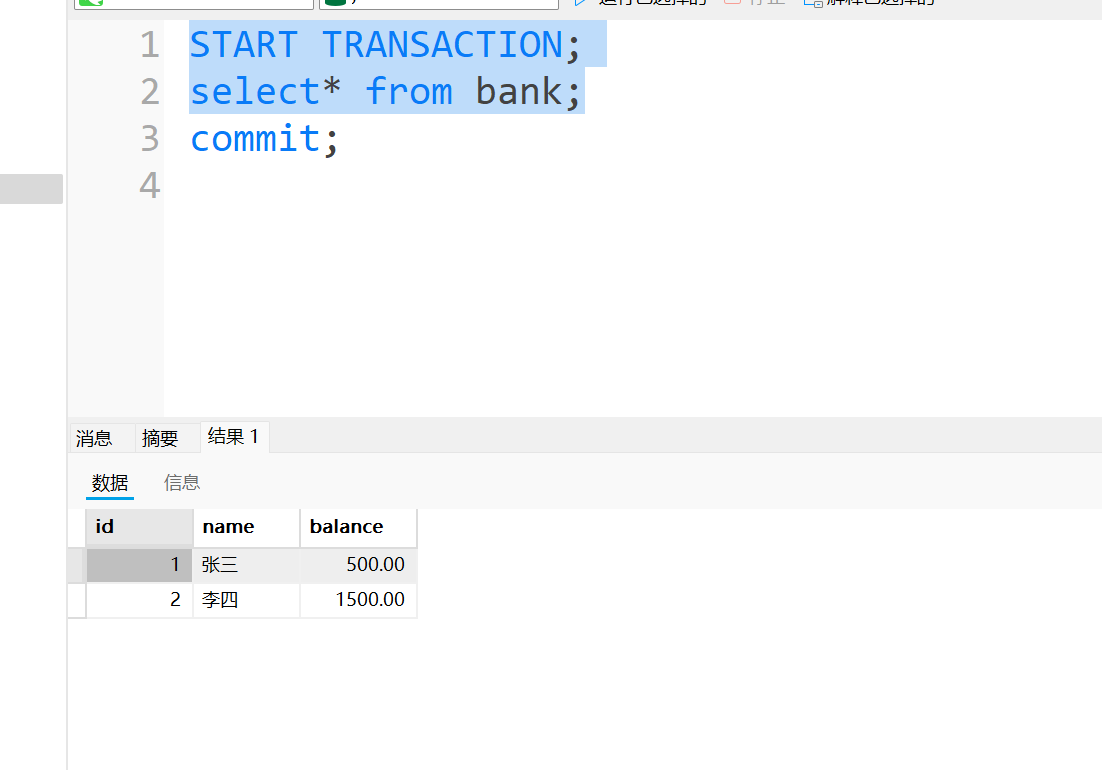
- 事务A: 这个时候事务A由于某种原因回滚了, 撤销了转账的数据. 这个时候数据就变回了转账之前的数据, 两个都是1000
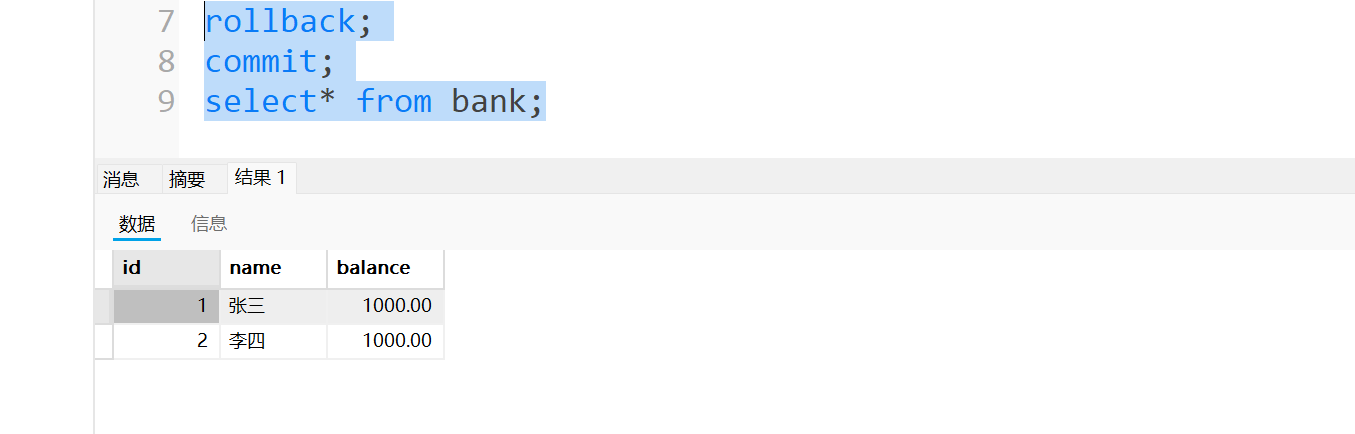
- 那么这个时候事务B就成小丑了, 好不容易读取了数据事务A又还原回去了, 读到的这个数据就是一个脏数据.
- 这个脏读就像我高中班上的一个b哥一样, 有一次月考, b哥偷偷溜进了办公室看了自己的成绩. 一看自己数学140, 给b哥高兴坏了, 跑回来给我们说他数学考了140, 结果后来老师再次审核成绩的时候, 发现b哥的试卷改错了, 重新改一遍下来只剩下80分了, 然后公布成绩的那一天, 我看见b哥的表情是无法形容的.
READ COMMITTED - 读已提交与不可重复读
-
为了解决脏读的这个问题, 我们就把隔离级别设置成读已提交的. 这个时候就解决了脏读的问题.
-
不可重复读就是假设有事务A, 事务B, 事务C, 事务A把数据修改后, 提交了. 事务C读取第一次是事务A修改后的数据, 事务B又把同一个数据修改了. 提交了. 这个时候事务C第二次读取同一个数据读取到的就是事务B修改后的数据. 结果事务C两次读取同一个数据, 都不一样. 这就是不可重复读.
-
事务A: 修改张三的余额, 加上300. 并且事务A提交

-
事务C读取事务A提交后张三的数据. 发现是1300
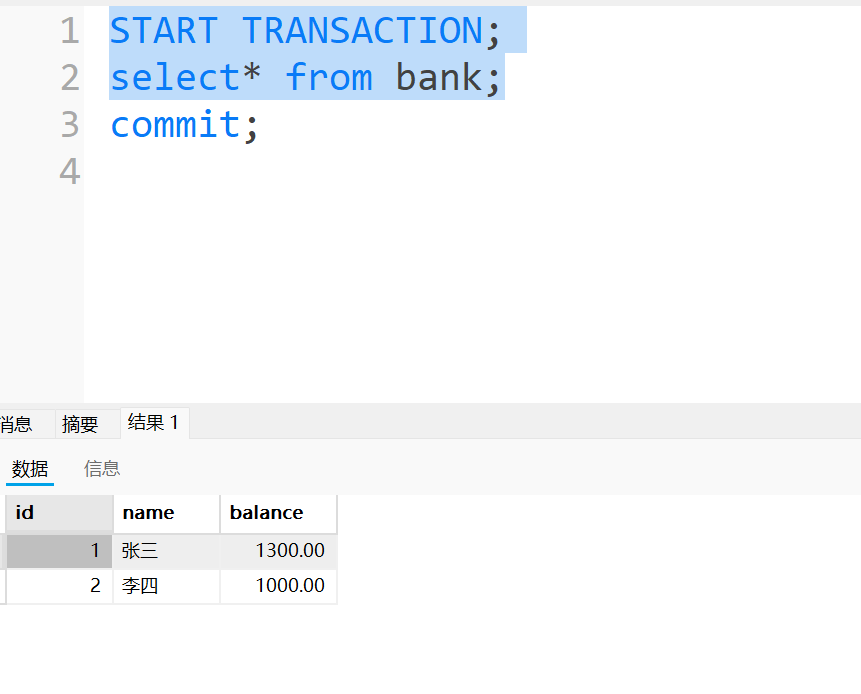
-
事务B, 把张三的数据再增加100, 并且提交.

-
事务C, 第二次查询张三的数据, 结果发现和第一次不一样, 是1400
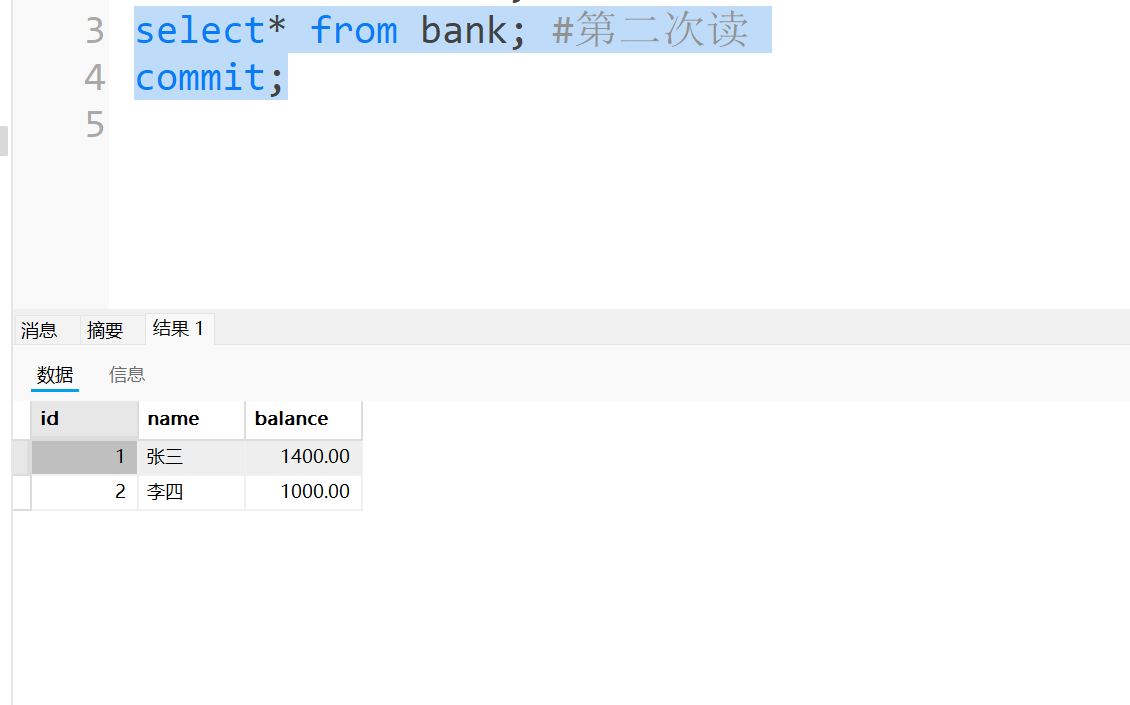
-
这就是不可重复读的问题, 在同一个事务内读同一个数据结果两次不一样. 就如同有一天我姐姐, 上午还给我笑嘻嘻的说老弟今天中午想吃什么, 姐姐给你做. 晚上我和我姐姐说我想吃火锅, 姐姐就不耐烦给我说: 吃什么吃, 找你妈去. 这就让人有点接受不了这个落差了, 事务也是一样的.
REPEATABLE READ - 可重复读与幻读(MySQL默认隔离级别)
- 为了解决不可重复读问题,可以把事务的隔离级别设置为 REPEATABLE READ这时同⼀个事
务中读取的数据在任何时候都是相同的结果,但还会出现⼀个问题,事务A第一次查询的时候得到一个结果集, 事务B趁着这个空隙插入了数据, 这个时候事务A第二次查询的时候得到的结果集就出现了事务B插入的数据, 导致同一个事务内查询的第一次和第二次的结果集不一样 - 事务A第一次查询的结果集只有两条记录
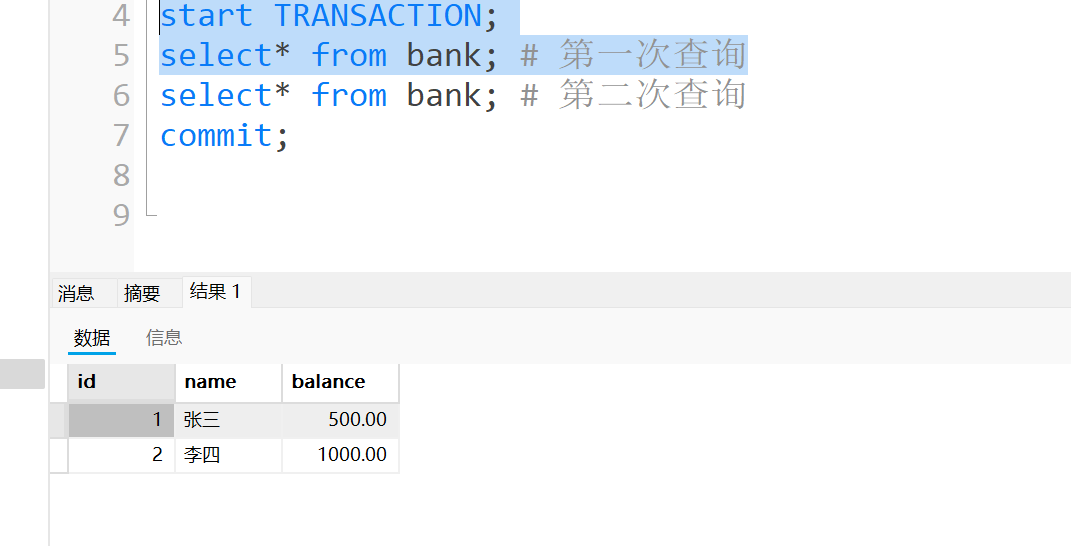
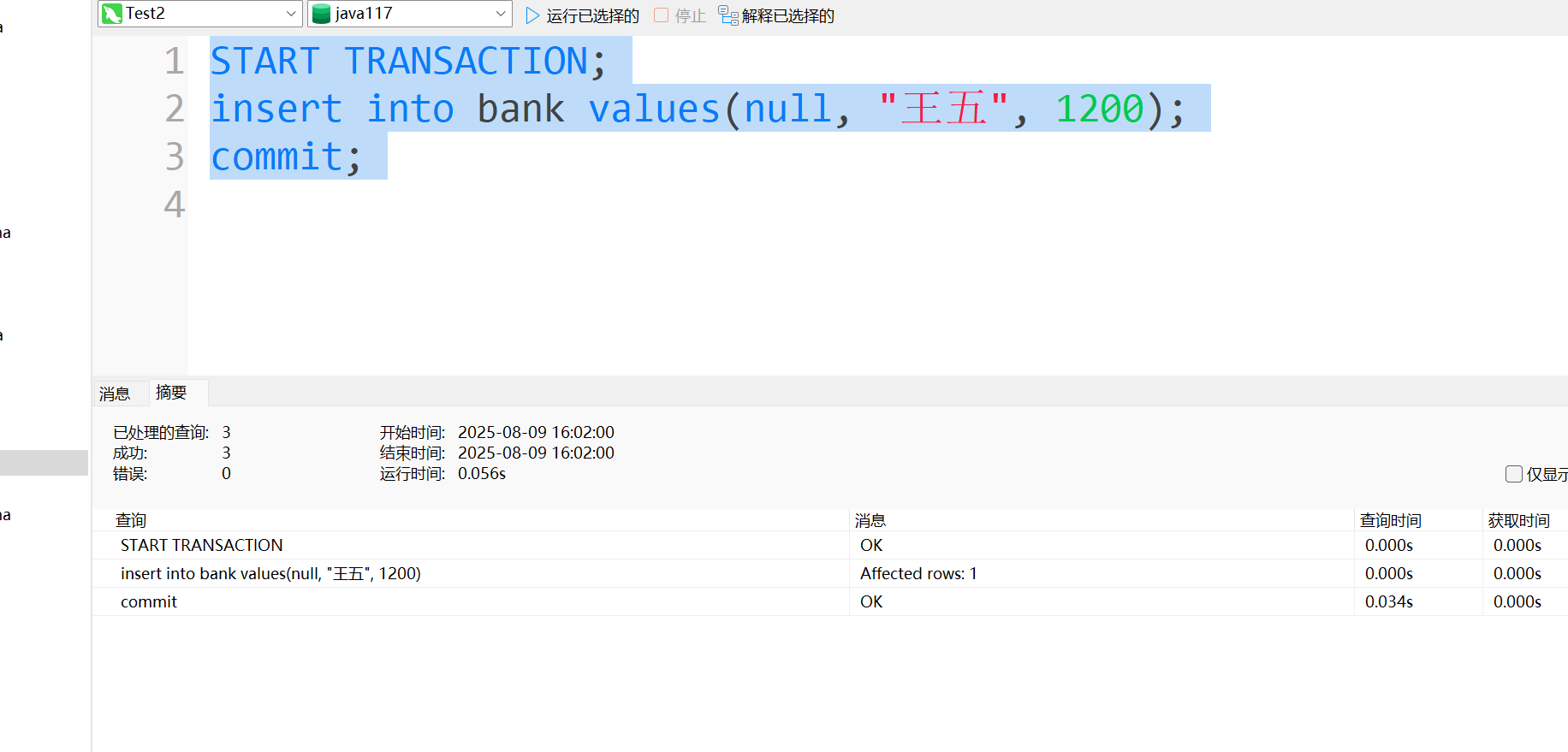
- 事务B趁着事务A还没结束提交, 插入了一条数据
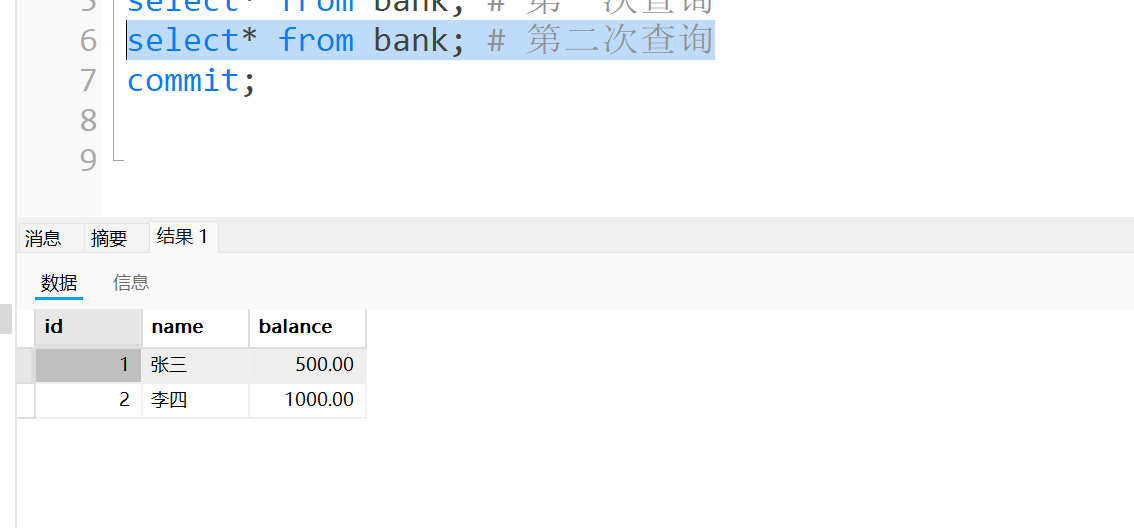
- 事务A第二次查询, 还是两条数据. 根据我们上面说的, 这里应该是3条数据才对. 第一次结果集和第二次结果集的数据不一样. 可是这里还是两条数据,说明我们的REPEATABLE READ隔离级别已经处理了大部分的幻读情况了.
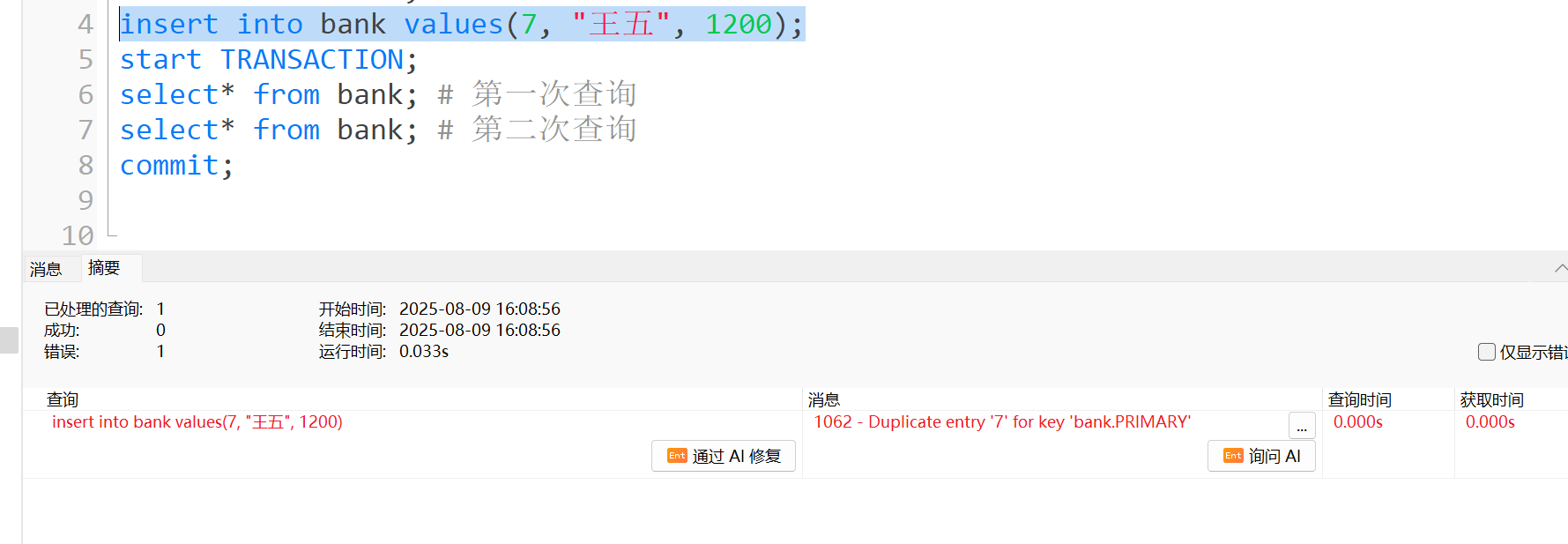
- 这里我们改变策略, 虽然我们查询出来的结果集王五并没有存在, 这个时候我们插入同一个王五的记录进去, 可以看到由于主键约束(主键列不能重复且不能为空), 数据库提示我们这条记录已经存在. 不能进行插入, 所以实际上还是存在幻读的.
SERIALIZABLE - 串⾏化
-
这个隔离级别就是完全解决了幻读的问题, 我们幻读之所以导致结果集不一样, 根本原因就是事务A和事务B同时开启, 事务B同一时刻插入了数据.这个隔离级别, 只能一个事务执行完了, 另一个事务才能执行

-
事务A第一次查询结果集是这样, 我们插入了主键列为20的赵六.
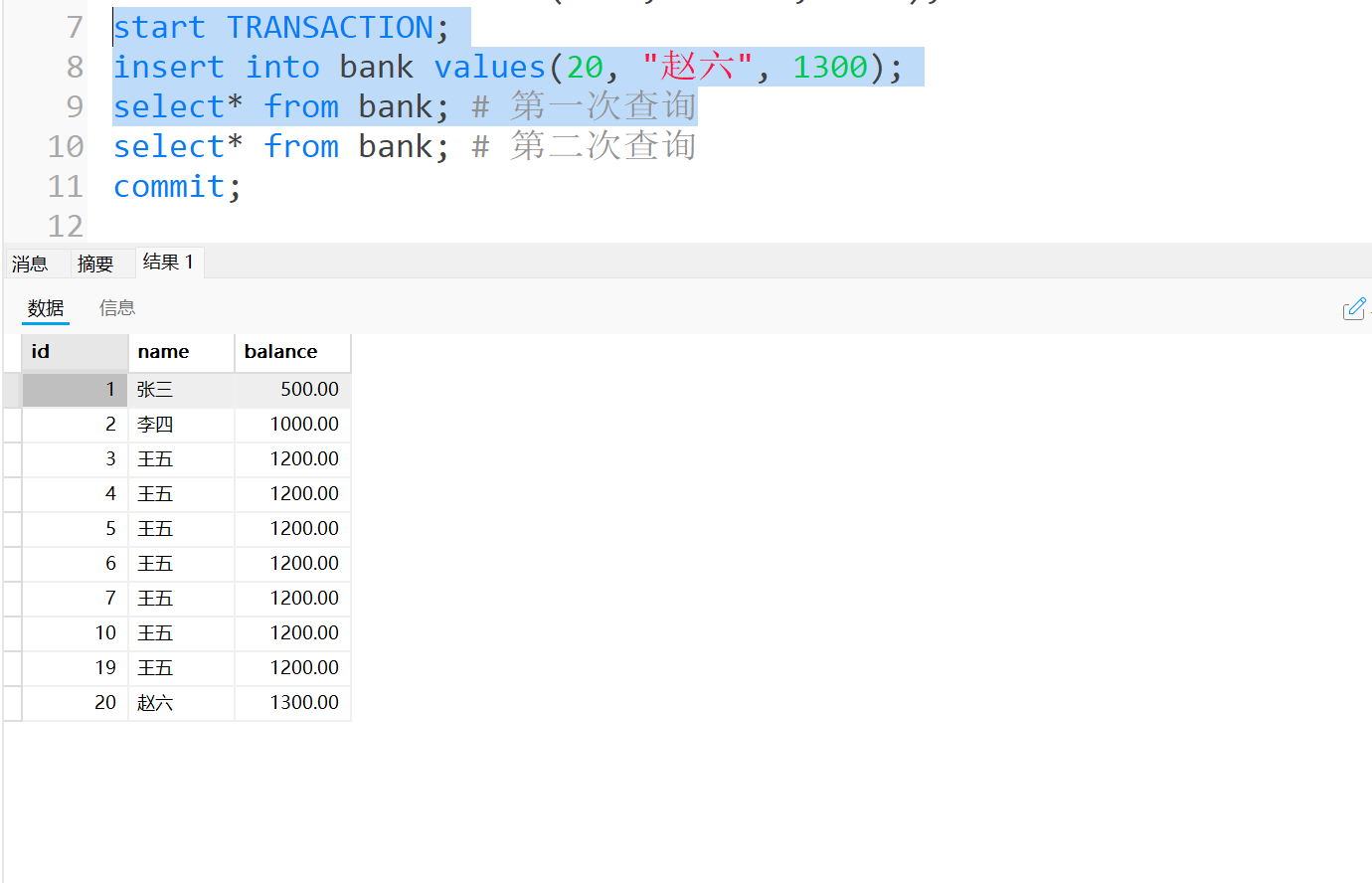
-
这个时候我们开启事务B插入主键列一样的值20, 名字为赵六的进去 正常来说, 我们的下方会说插入成功, 影响了1行, 这里却没有说, 说明这个事务并没有真正去执行并提交
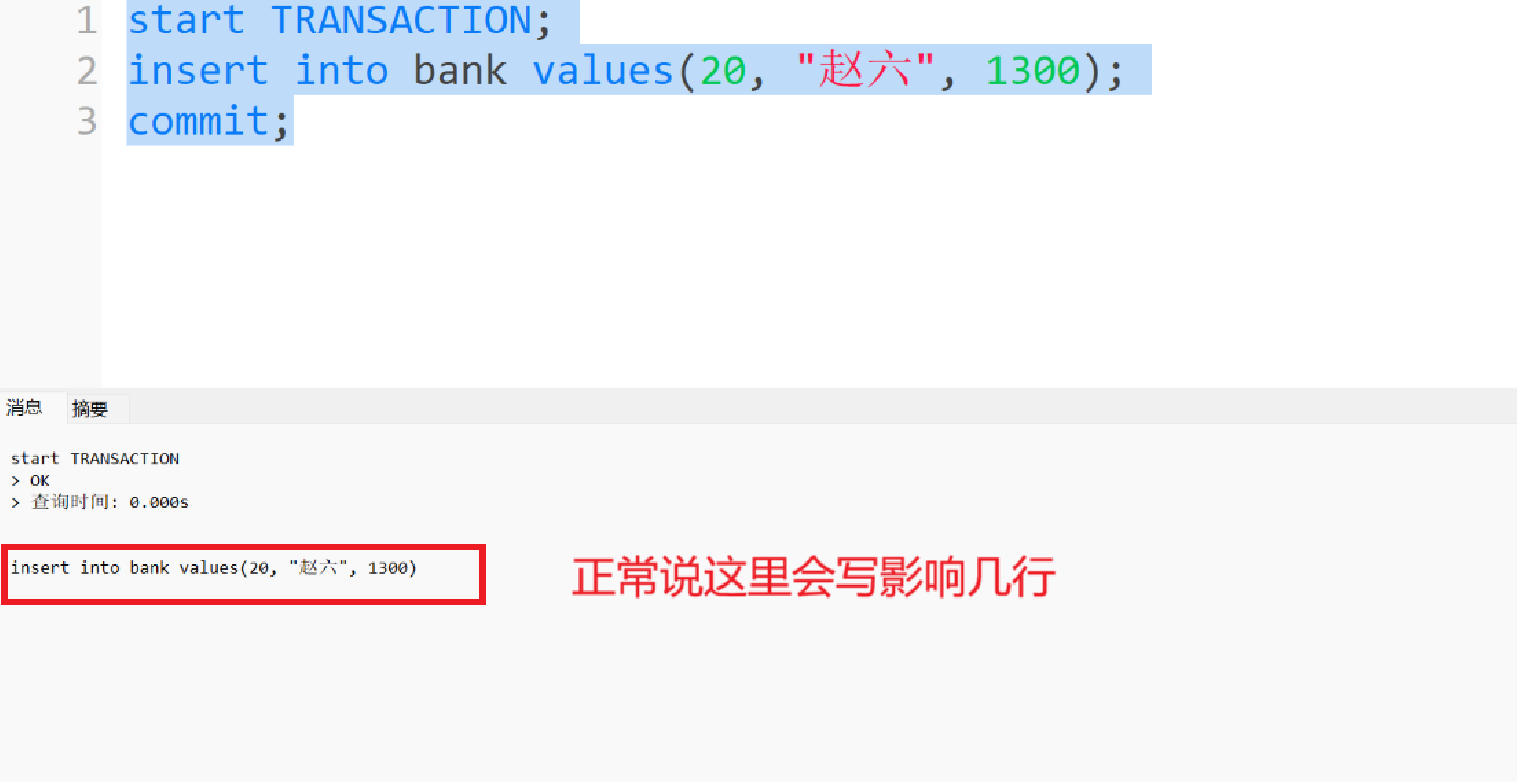
-
事务A: 第二次查询同样的结果, 并没有出现幻读这种不同结果集情况. 这里我们进行提交事务, 事务A完成
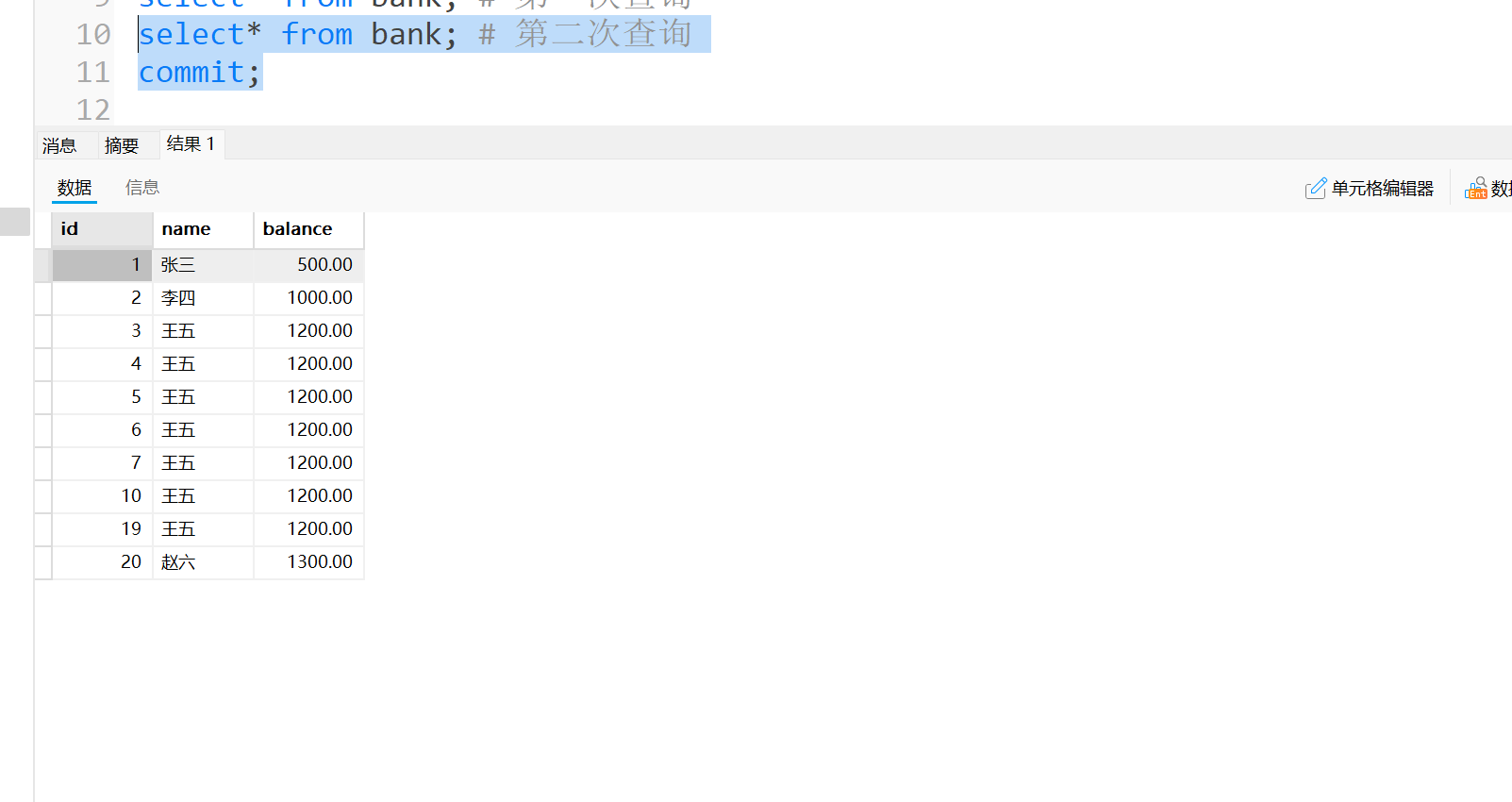
-
事务B: 事务A完成后, 我们返回到事务B, 可以看到我们插入失败了(因为主键列值一样插入失败), 并且我们下面查询时间说用来29秒, 这就是事务B等待了29秒, 说明我们事务B是等待事务A执行提交(事务A花了29秒), 才开始执行的.
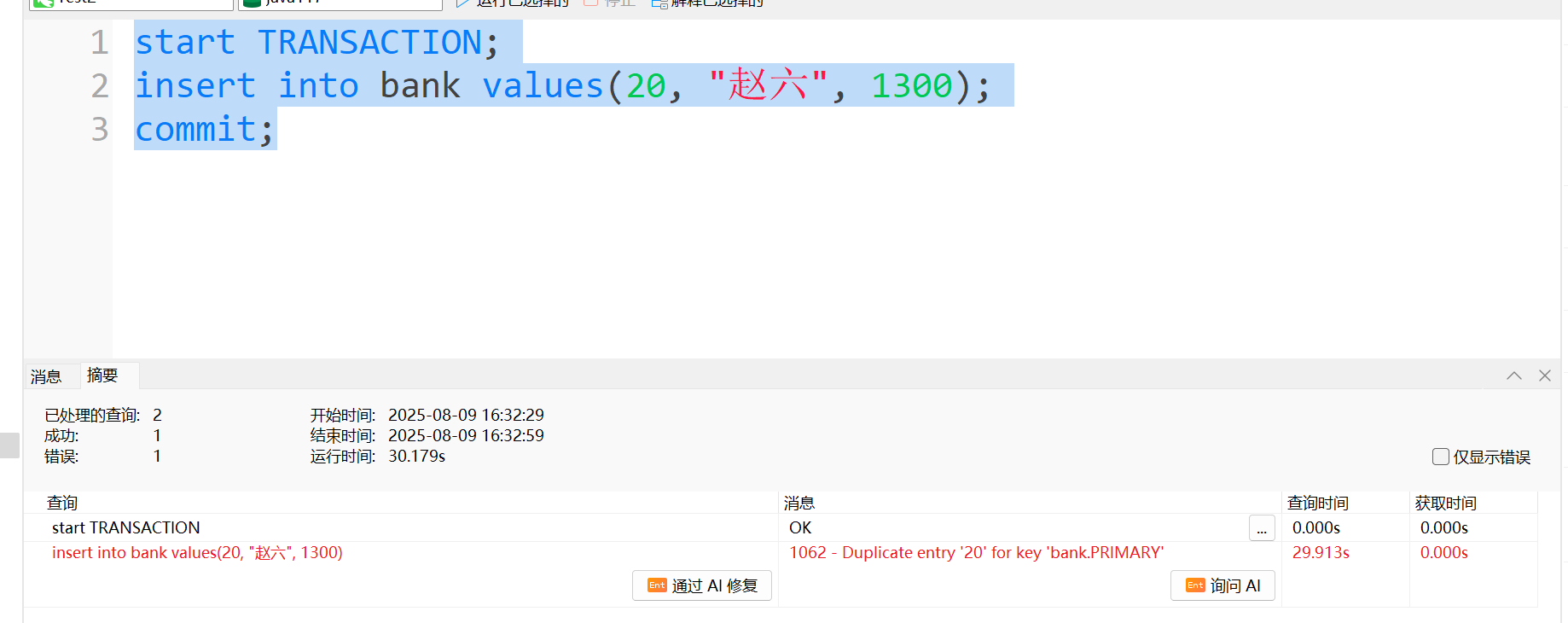
从上面的例子上知道, 我们事务是完全隔离的, 事务A执行完了, 事务B才执行.
navicate客户端注意
- 我们在这个客户端设置隔离级别的时候, 如果有多个客户端(连接), 在客户端A设置了隔离级别. 则要把客户端B关闭, 重新连接, 客户端B的隔离级别才生效