零基础-动手学深度学习-10.1. 注意力提示
灵长类动物的视觉系统接受了大量的感官输入, 这些感官输入远远超过了大脑能够完全处理的程度。 然而,并非所有刺激的影响都是相等的。 意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体,例如猎物和天敌。 只关注一小部分信息的能力对进化更加有意义,使人类得以生存和成功。
自19世纪以来,科学家们一直致力于研究认知神经科学领域的注意力。 本章的很多章节将涉及到一些研究。
首先回顾一个经典注意力框架,解释如何在视觉场景中展开注意力。 受此框架中的注意力提示(attention cues)的启发, 我们将设计能够利用这些注意力提示的模型。 1964年的Nadaraya-Waston核回归(kernel regression)正是具有 注意力机制(attention mechanism)的机器学习的简单演示。
然后继续介绍的是注意力函数,它们在深度学习的注意力模型设计中被广泛使用。 具体来说,我们将展示如何使用这些函数来设计Bahdanau注意力。 Bahdanau注意力是深度学习中的具有突破性价值的注意力模型,它双向对齐并且可以微分。
最后将描述仅仅基于注意力机制的Transformer架构, 该架构中使用了多头注意力(multi-head attention) 和自注意力(self-attention)。 自2017年横空出世,Transformer一直都普遍存在于现代的深度学习应用中, 例如语言、视觉、语音和强化学习领域。
10.1.1. 生物学中的注意力提示


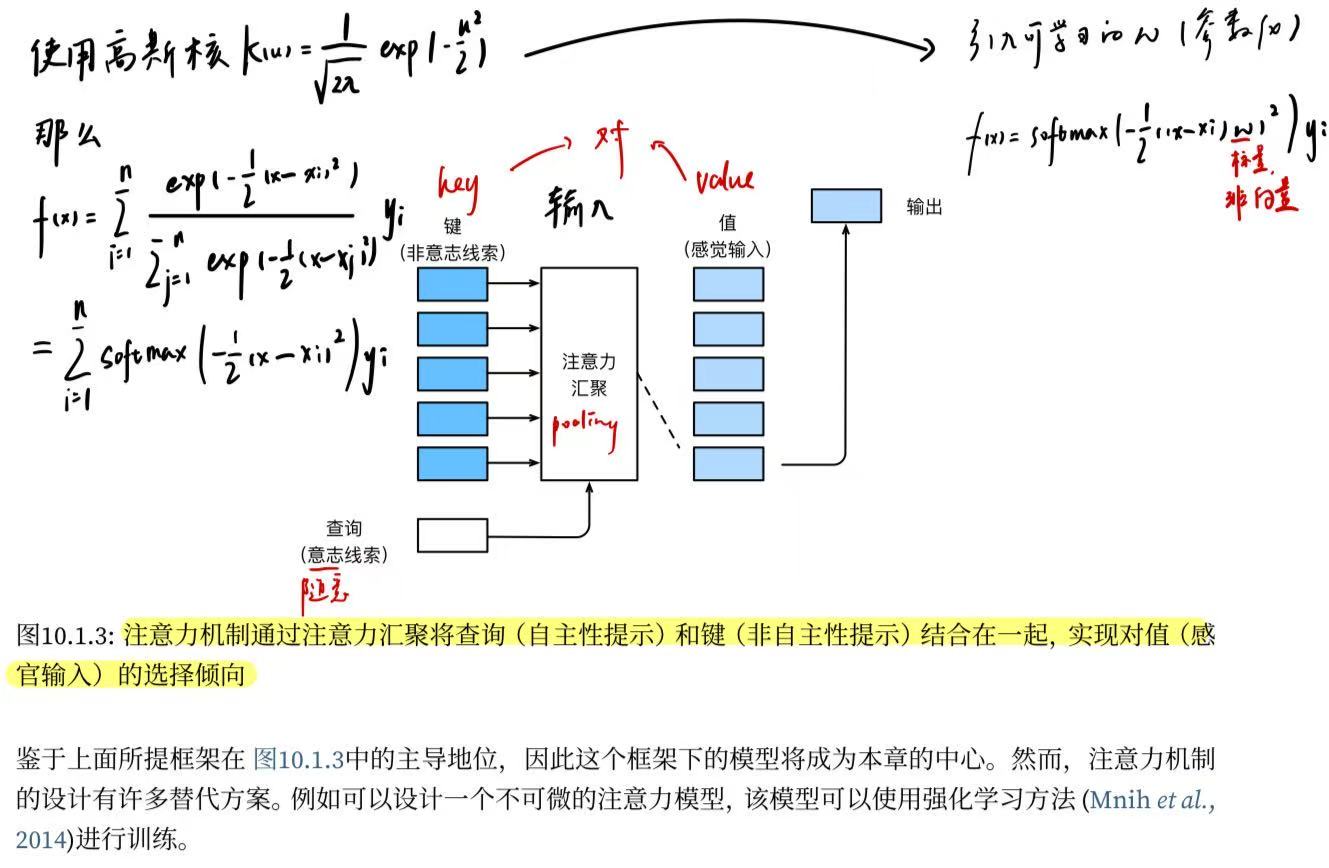
10.1.2. 查询、键和值

10.1.3. 注意力的可视化
平均汇聚层可以被视为输入的加权平均值, 其中各输入的权重是一样的。 实际上,注意力汇聚得到的是加权平均的总和值, 其中权重是在给定的查询和不同的键之间计算得出的。
import torch
from d2l import torch as d2l为了可视化注意力权重,需要定义一个show_heatmaps函数。 其输入matrices的形状是 (要显示的行数,要显示的列数,查询的数目,键的数目)。
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),cmap='Reds'):"""显示矩阵热图"""d2l.use_svg_display()# 设置绘图引擎为 SVG,以获得更清晰的图像num_rows, num_cols = matrices.shape[0], matrices.shape[1]#要显示的行列数提出来
## 创建一个图形和多个子图(根据矩阵的行数和列数)# figsize 指定每个子图的大小# sharex=True 和 sharey=True 表示所有子图共享 x 轴和 y 轴# squeeze=False 确保返回的 axes 是一个二维数组fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,#subplot作图sharex=True, sharey=True, squeeze=False)
# 遍历每一行的子图和对应的矩阵for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
# 遍历每一行中的每个子图和对应的矩阵for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
# 使用 imshow 显示矩阵的热图# matrix.detach().numpy() 将矩阵转换为 NumPy 数组# cmap='Reds' 指定颜色映射为红色系pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
# 如果是最后一行,则设置 x 轴标签if i == num_rows - 1:ax.set_xlabel(xlabel)
# 如果是第一列,则设置 y 轴标签if j == 0:ax.set_ylabel(ylabel)
# 如果提供了标题列表,则设置每个子图的标题if titles:ax.set_title(titles[j])
# 添加颜色条# pcm 是 imshow 的返回值,用于指定颜色条的范围# ax=axes 表示颜色条应用于所有子图# shrink=0.6 缩小颜色条的大小fig.colorbar(pcm, ax=axes, shrink=0.6);下面使用一个简单的例子进行演示。 在本例子中,仅当查询和键相同时,注意力权重为1,否则为0。
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')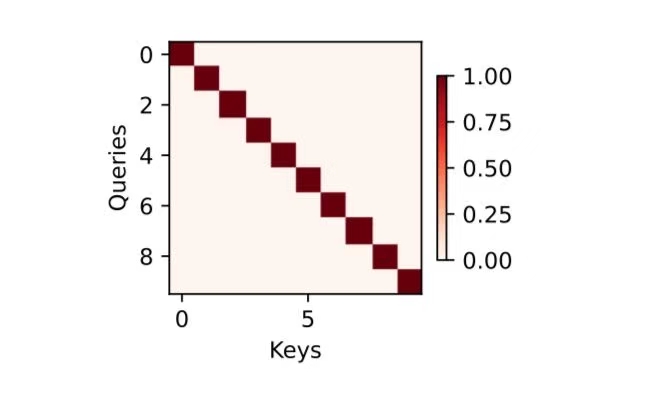
后面的章节内容将经常调用show_heatmaps函数来显示注意力权重。
10.1.4. 小结
人类的注意力是有限的、有价值和稀缺的资源。
受试者使用非自主性和自主性提示有选择性地引导注意力。前者基于突出性,后者则依赖于意识。
注意力机制与全连接层或者汇聚层的区别源于增加的自主提示。
由于包含了自主性提示,注意力机制与全连接的层或汇聚层不同。
注意力机制通过注意力汇聚使选择偏向于值(感官输入),其中包含查询(自主性提示)和键(非自主性提示)。键和值是成对的。
可视化查询和键之间的注意力权重是可行的。