自编教材实操课程学习笔记
文章目录
- 编译器前端
- 预处理
- 词法分析
- 语法分析
- 语义分析
- 例子
- 编译器中端
- 优化方法简述
- 中间代码生成
- 中间代码优化
- 例子
- 编译器后端
- 优化方案简述
- 目标代码生成
- 链接
- 例子
- 编译选项
- 优化方法简述
- 前端选项
- 优化选项
- 代码生成选项
- 链接选项
- 其他选项
- 参考
编译器前端
预处理
LLVM前端通过对源程序的预处理,构成源程序的字符流扫描与分解,将单词序列提取为各类语法短语,
生成抽象语法树,最终转换为中间代码。编译器前端包含的几个过程如下:
1、预编译
2、词法分析
3、语法分析
4、语义分析
词法分析
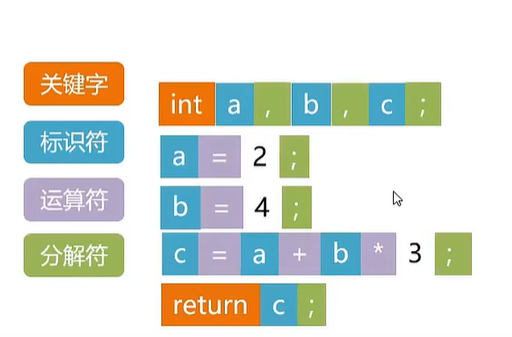
词法分析是对构成程序的源代码从左到右将字符逐个读入编译器,并扫描和分解字符流,从而识别出一个个单词,并确定单词的类型,将识别出的单词转换为统一的语法单元形式。包括如下类型:
①关键字,如int、float、if、sizeof等;
②标识符,用来表示各种名字,如变量、数组名、函数名等
③运算符,包括算术运算符、逻辑运算符、关系运算符等
④分解符,包括舌“,、;”等符号
③常数,包括整型、浮点型、字符型等
语法分析
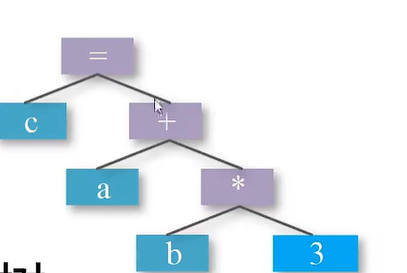
语法分析的任务是将词法分析生成的单词组合成语法短语,同时分析这些短语是否符合高级程序设计语
言中的语法规则。有下面的规则来定义表达式:
①标识符是表达式;
②常数是表达式;
③若表达式1和表达式2都是表达式,那么表达式1+表达式2以及表达式1*表达式2也都是表达式
有下面的规则来定义赋值语句:

语义分析
语义分析阶段的任务是审查源代码有无语义错误,源代码中有些语法成分,按照语法规则去判断是正确的,但不符合语义规则,比如使用了没有声明的变量。
语义分析主要的任务可归结为以下四类:
①完成静态语义审查和处理;
②上下文相关性审查;
③类型匹配审查;
④类型转换。
比如语句c=a+b3中,运算符的两个运算对象分别是b和3,如果b是实型变量,
3是整型常数,语义分析阶段执行类型审查之后,会自动地将整型量转换为实型量
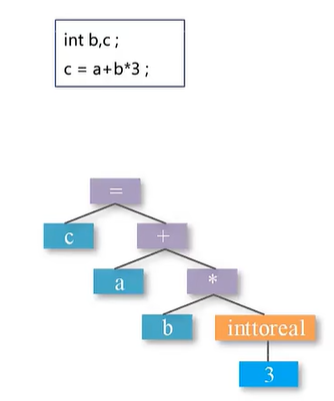
以完成同类型的数据运算,体现在语法分析所得到的语法树上,即增加一个运算符结点(inttoreal)。
例子

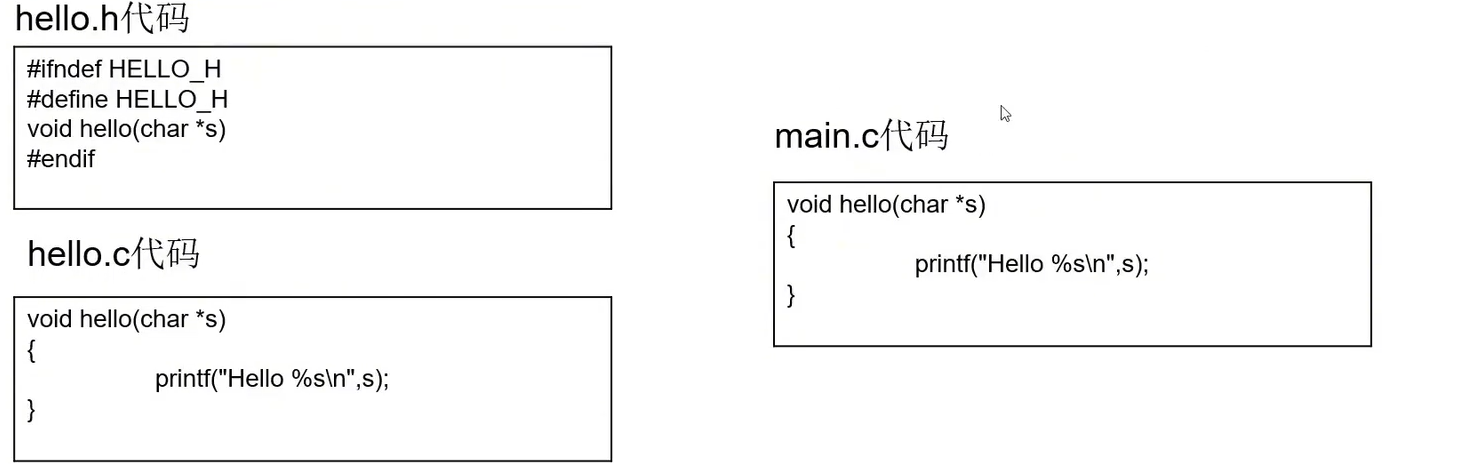
示例一是一个简单的打印程序,用来观察编译的前端阶段所进行的处理。
在程序中包括了头文件、宏定义和注释,在进行预编译后会对这些语句按照预编译规则进行相应的处理;在进行词法分析后会读入源程序的字符流,将其转换为对应的单词序列;在进行语法分析后会依据语法规则把源代码的单词序列组成语法短语构成的语法树;在进行语义分析后可以检查源代码有无语义错误。
预编译
clang -Ehello.c -o hello.i词法分析
clang -fmodules -fsyntax-only -Xclang -dump-tokens hello.c语法分析
clang -fmodules -fsyntax-only -Xclang -ast-dump hello.c
编译器中端
优化方法简述
编译器中端所进行的工作是在在前端的基础上,先将整个语法树转换为中间代码,再通过一系列优化遍
对程序生成的中间代码进行优化,包括中间代码生成与中间代码优化两个部分。
中间代码生成
LLVM中间表示的三种格式:
在内存中的编译中间语言;硬盘上存储的二进制中间语言,
以.bc结尾;以及可读的中间代码格式,以.11结尾
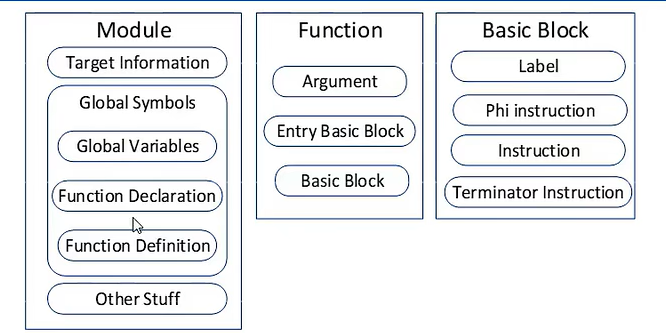
LLVM中间代码结构包括四个部分:
①模块(Module)是LLVMIR的顶层容器,对应于编译前端的每个翻译单元。每个模块由目标机器信息、全局符号(全局变量和函数)及元信息组成。
②函数(Function)就是编程语言中的函数,包括函数签名和若干个基本块,函数内的第一个基本块叫做入口基本块。
③基本块(BasicBlock)是一组顺序执行的指令集合,只有一个入口和一个出口,非头尾指令执行时不
会违背顺序跳转到其他指令上去。每个基本块最后一条指令一般是跳转指令(跳转到其它基本块上去),函数内最后一个基本块的最后一条指令是函数返回指令。
④指令(Instruction)是LLVMIR中的最小可执行单位。
中间代码优化
代码优化阶段的任务是对中间代码进行变换或改造,目的是使生成的代码更为高效。LLVM中优化器opt可
对中间代码实施优化,常见的有删除公共子表达式、循环优化、复写传播、无用赋值的删除等。
-O优化选项用以控制编译器在对程序编译时的优化级别,常用的有-O0、-O1、-O2、-O3、-Ofast。
| 优化等级 | 包含的优化选项 |
|---|---|
| -O1 | 在 -O0 的基础上添加: - -instcombine- -simplifycfg- -loops- -loop-unroll 等 |
| -O2 | 在 -O1 的基础上添加: - -inline- -fvectorize- -fslp-vectorize 等 |
| -O3 | 在 -O2 的基础上添加: - -aggressive-instcombine- -callsite-splitting- -domtree 等 |
| -Ofast | 在 -O3 的基础上添加: - -fno-signed-zeros- -freciprocal-math- -ffp-contract=fast- -menable-unsafe-fp-math- -menable-no-nans- -menable-no-infs- -mreassociate- -fno-trapping-math- -ffast-math- -ffinite-math-only 等 |
例子

clang code-generation.c -S -emit-llvm -o code-generation.llclang code-generation.c -c -emit-llvm -o code-generation.bcllvm-as main.ll -o main.bc
llvm-dis main.bc -o main.ll汇编文件
clang -S main.c -o main.s
编译器后端
优化方案简述
LLVM后端负责将中端优化过的中间表示转换为对应平台的机器代码,通常称为汇编代码,并最终经过汇
编器和链接器生成目标处理器上的二进制可执行文件。LLVM后端主要包括目标代码生成和链接。
目标代码生成
该过程是把中间代码变换成特定机器上的目标代码,形式上包括:绝对指令代码、可重定位的指令代码
、汇编指令代码。这是编译的最后阶段,它的工作与硬件系统结构和指令含义有关,涉及到硬件系统功能部
件的运用、机器指令的选择、各种数据类型变量的存储空间分配以及寄存器分配等。在LLVM中使用clang-S
file.c命令进行编译,生成特定平台的汇编代码.s文件。
以汇编文件中的加法指令为例,该汇编指令由一个操作码和两个操作数组成,操作码add1为加法操作,操作数%x和操作数%y执行加法运算,并将结果放置在%x中。



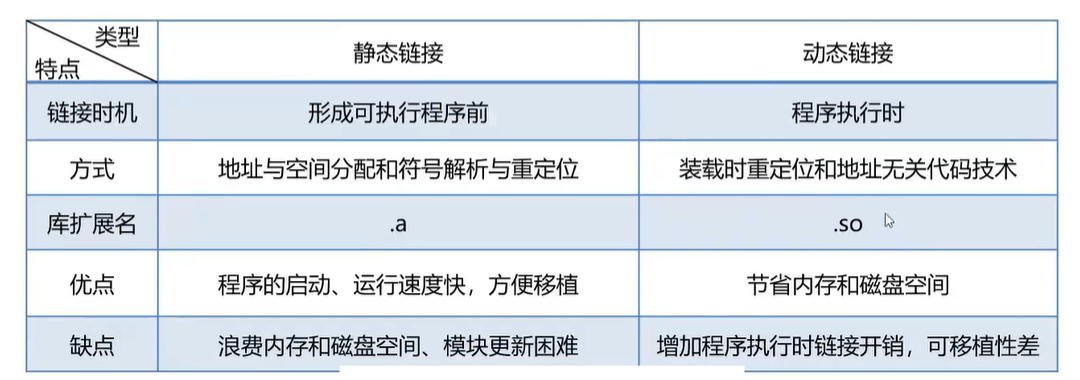
链接
链接的功能是将一个或多个目标文件以及库文件合并为一个可执行文件。链接可以在源代码翻译成机器
代码即编译的时候完成,也可以在程序装入内存时完成,甚至可以在程序运行时完成,根据不同的完成时期
可将链接分为静态链接和动态链接。
例子

生成.o目标代码文件
汇编生成可执行文件
clang -c code.s -o code.ollvm-mc -filetype=obj code.s -o code.o

clang实现链接clang -c a.c -o a.o
clang b.c -o b.o
clang a.o b.o -o ab.out
clang -c -fPIC hello.c
clang -shared -fPIC -o libhello.so hello.o
clang main.c-L lhello -oa.out
编译选项
优化方法简述
编译选项用于使优化人员更好地与编译器交互、更好地与编译器交互,编译器会根据优化人员所加入的编译选项调用内部对应的功能。编译选项包括前端选项、优化选项、代码生成选项、链接选项及其他选项。
前端选项
编译人员可以通过编译选项指定预处理、语言选择和模式等对程序的前端编译过程予以干预。
| 选项 | 功能 |
|---|---|
-include <file> | 将隐式的 #include 添加到预定义缓冲区中,在对源文件进行预处理之前读取该缓冲区 ;预处理 |
-I<directory> | 将指定的目录添加到 include 文件的搜索路径中 ;预处理 |
-F <directory> | 将指定的目录添加到框架 include 文件的搜索路径中 ;前端 |
-fsyntax-only | 防止编译器生成代码,只进行语法级别的检查和修改 ;前端 |
-dump-tokens | 在语法分析过程中,将内部代码拆分为各种单词序列(token);前端 |
-ast-dump | 在语法分析过程中,构建抽象语法树(AST)并对其进行拆解和调试 ;前端 |
-x <language> | 将后续输入文件视为指定 <language> 类型的语言 ;语言和模式 |
-std=<standard> | 指定要编译的语言标准 ;语言和模式 |
-stdlib=<library> | 指定要使用的 C++ 标准库(如 libstdc++ 和 libc++),未指定时使用平台默认值 ;语言和模式 |
-fno-builtin | 禁用内建函数的处理和优化 ;语言和模式 |
-E | 运行预编译阶段,生成预编译文件 ;编译阶段 |
-emit-llvm -S | 运行编译阶段,生成 .ll 中间代码文件 ;编译阶段 |
优化选项
编译器的优化选项种类很多,常用的编译优化选项包括内联优化选项、优化级别选项、循环优化选项、
向量化优化选项、并行优化选项、浮点优化选项等。
| 优化等级 | 包含的优化选项 |
|---|---|
| -O1 | 在-O0基础上添加:-instcombine -simplifycfg -loops -loop-unroll |
| -O2 | 在-O1基础上添加:-inline -fvectorize -fslp-vectorize |
| -O3 | 在-O2基础上添加:-aggressive-instcombine -callsite-splitting -domtree |
| -Ofast | 在-O3基础上添加:-fno-signed-zeros -freciprocal-math -ffp-contract=fast-menable-unsafe-fp-math -menable-no-nans -menable-no-infs-mreassociate -fno-trapping-math -ffast-math -ffinite-math-only |
| 优化类型 | 选项 | 功能描述 | 阶段 |
|---|---|---|---|
| 内联优化 | -inline | 打开内联函数功能 | 中间端优化 |
-finline-functions | 对合适的函数进行内联 | 中间端优化 | |
-inline-aggressive | 在链接时优化期间开启激进的内联优化 | LTO优化 | |
| 循环优化 | -funroll-loops | 打开循环展开 | 中间端优化 |
-fno-unroll-loops | 关闭循环展开 | 中间端优化 | |
-mllvm -unroll-count | 设置循环展开次数 | LLVM优化 | |
-mllvm -unroll-peel-count | 设置循环剥离计数 | LLVM优化 | |
-mllvm-enable-loop-distribute | 开启循环分布优化 | LLVM优化 | |
-interleave-loops | 在向量化过程中启用循环跨步存储 | 中间端优化 | |
| 向量化 | -fvectorize | 开启循环向量化优化 | 中间端优化 |
-fslp-vectorize | 开启基本块级向量化 | 中间端优化 | |
| 浮点优化 | -ffast-math | 开启一系列浮点优化(包含以下多个子选项) | 中间端优化 |
-freeiprocal-math | 允许除法转倒数乘法(包含于-ffast-math) | 中间端优化 | |
-fno-signed-zeros | 忽略浮点零的符号(包含于-ffast-math) | 中间端优化 | |
| 硬件优化 | -mllvm -loop-data-prefetch | 开启预取访问(针对AArch64/PowerPC) | 后端优化 |
| 调试信息 | -Rpass=vectorize | 显示循环/SLP向量化信息 | 诊断输出 |
-Rpass=loop-unroll | 显示循环展开/剥离信息 | 诊断输出 | |
-Rpass-missed=loop-unroll | 显示循环展开失败信息 | 诊断输出 | |
-Rpass=loop-distribute | 显示循环分布信息 | 诊断输出 | |
-Rpass-analysis=loop-distribute | 显示循环分布分析信息 | 诊断输出 |
代码生成选项
在代码生成阶段可以通过编译阶段选项指定不同的处理阶段,通过数据选项选择对数据的处理方式,通过对目标平台选项生成指定平台的代码,通过后端生成选项打开不同后端支持的优化功能。
| 编译阶段 | 选项 | 功能描述 |
|---|---|---|
| 通用编译 | -S | 运行编译阶段,生成.s汇编文件 |
| 后端优化 | -maxx2 | 在-mavx基础上增加AVX2内置函数和指令集支持 |
-msse | 支持MMX和SSE内置函数及代码生成 | |
-msse2 | 在-msse基础上增加SSE2内置函数和代码生成 | |
-mfentry | 在函数入口插入对fentry的调用 | |
-mllvm -disable-x86-lea-opt | 关闭X86架构的LEA优化 | |
| 数据对齐 | -malign-double | 在structs中将双精度对齐为双字(仅x86架构) |
-mdouble=<value> | 指定double类型数据的位数 | |
| 目标平台 | -march=<cpu> | 为特定处理器生成优化代码(如-march=skylake) |
--cuda-host-only | 仅编译CUDA的主机端代码(不编译设备端代码) |
链接选项
| 阶段 | 选项 | 功能描述 |
|---|---|---|
| 编译/汇编 | -c | 运行编译和汇编阶段(不链接),生成.o目标文件 |
-o <file> | 运行完整编译流程(编译+汇编+链接),生成指定名称的可执行文件 | |
| 静态链接 | -Bstatic | 强制静态链接用户库(优先使用.a静态库) |
-l<library> | 指定链接库名(如-lxyz对应libxyz.a或libxyz.so) | |
| 动态链接 | -shared-libsan | 动态链接Sanitizer运行时库(如ASAN/MSAN等) |
| 库路径 | -L<path> | 添加库搜索路径(如-L/usr/local/lib) |
| LTO优化 | -flto=<mode> | 设置链接时优化模式(full完全优化/thin轻量级优化) |
| 系统库 | -lm | 链接标准数学库(libm) |
其他选项
| 选项 | 功能描述 |
|---|---|
--version | 打印编译器版本信息 |
-v | 显示详细版本信息及编译过程中实际执行的命令 |
-### | 仅打印编译将要执行的命令(但不实际运行) |
-help | 显示编译器支持的所有公开选项 |
-help-hidden | 显示包括隐藏选项在内的完整选项列表(开发者专用) |
-time | 为每个编译阶段输出耗时统计 |
| 诊断选项 | 功能描述 |
|---|---|
-Rpass=vectorize | 显示循环向量化和SLP向量化的优化报告 |
-fsave-optimization-record | 生成包含所有优化决策的YAML记录文件(包括失败原因) |
-Rpass=loop-unroll | 输出成功的循环展开优化详情 |
-Rpass-missed=loop-unroll | 报告循环展开优化失败的原因 |
-Rpass=loop-distribute | 显示循环分布优化的具体实施信息 |
-Rpass-analysis=loop-distribute | 输出循环分布优化的分析过程细节 |
-Rpass=loop-versioning | 显示循环多版本优化(Loop Versioning)的应用情况 |
-Rpass-missed=loop-versioning | 报告循环多版本优化失败的具体原因 |
| 调试选项 | 功能描述 |
|---|---|
-mllvm -debug | 打印LLVM优化过程中的完整调试信息(需Debug版编译器) |
-mllvm -debug-only=<pass> | 打印指定优化遍(Pass)的调试信息(如-debug-only=loop-vectorize) |
-debug-pass=<type> | 控制优化遍的调试输出(可选:Structure/Executions/Details) |
-w | 抑制所有警告信息(仅显示错误) |
-g0 | 完全不生成调试符号(等效于-gnone) |
-mllvm -stats | 打印优化过程的统计信息 |
-mllvm -print-after-all | 在每个优化遍后打印IR状态 |
参考
- 自编教材实操课程分享:第五章—编译器前端