强化学习-MATLAB
1.
What is RL
How do i set it and solve it?
benefits and drawbacks
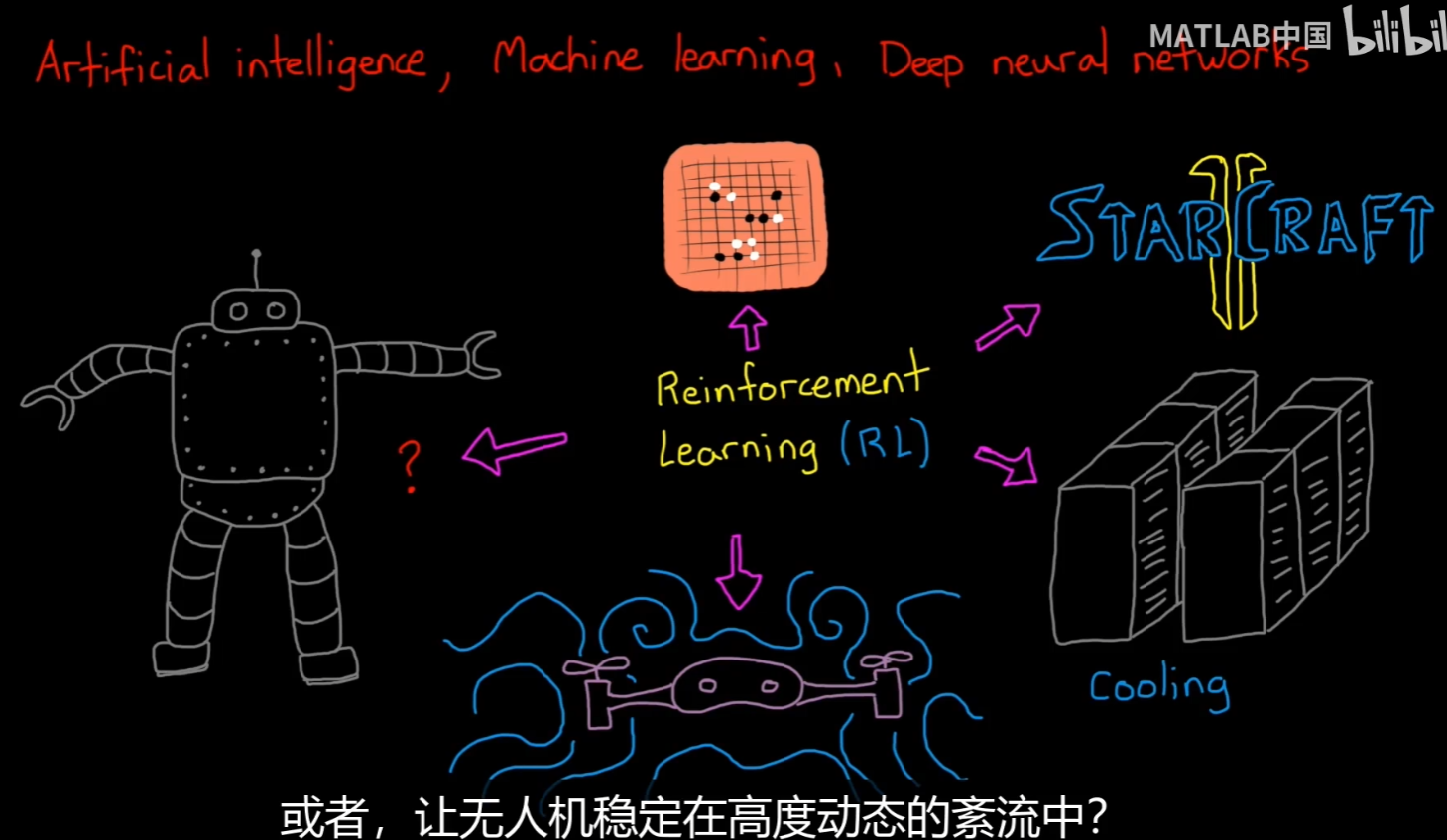

black box -> machine learning
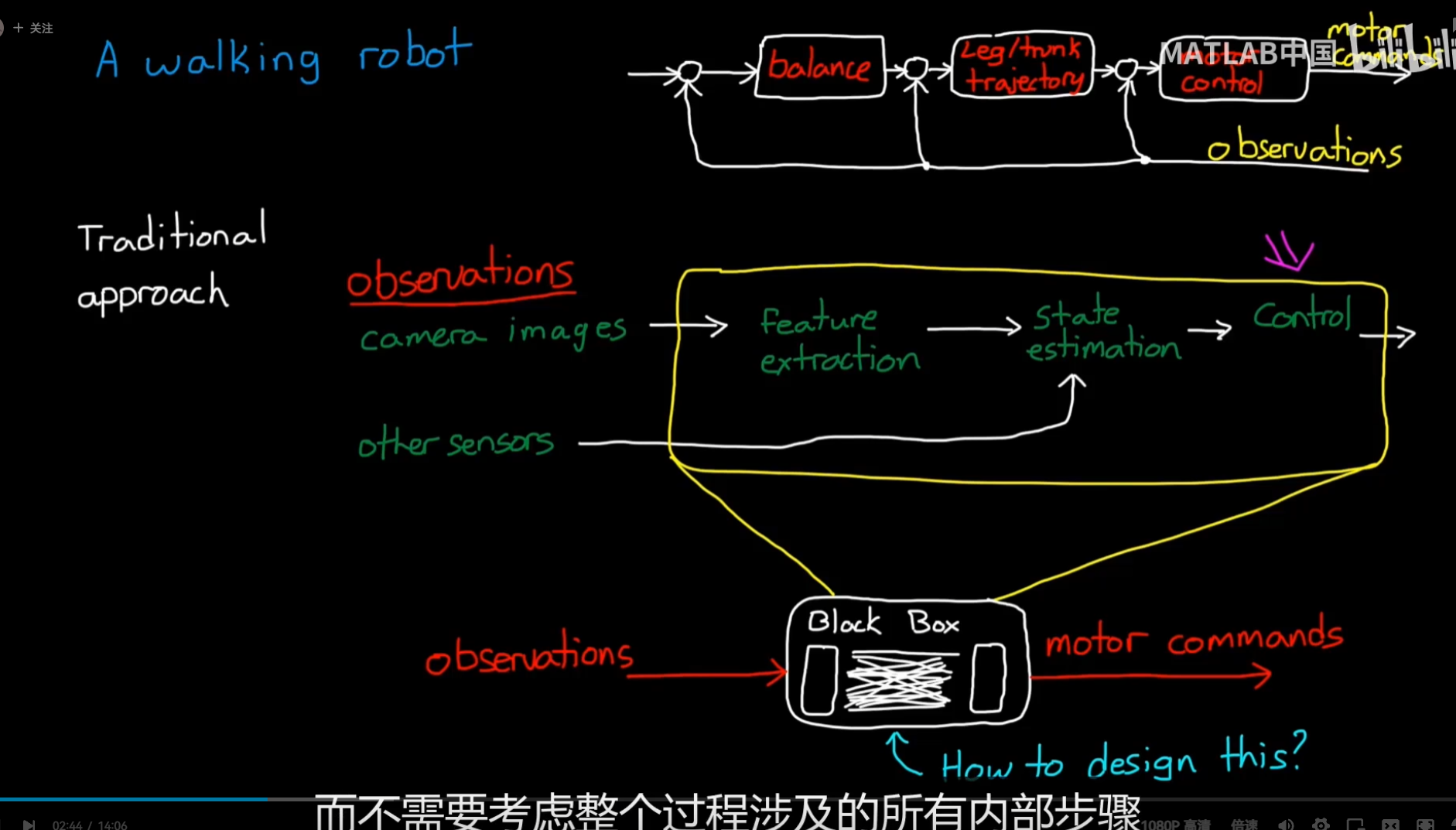
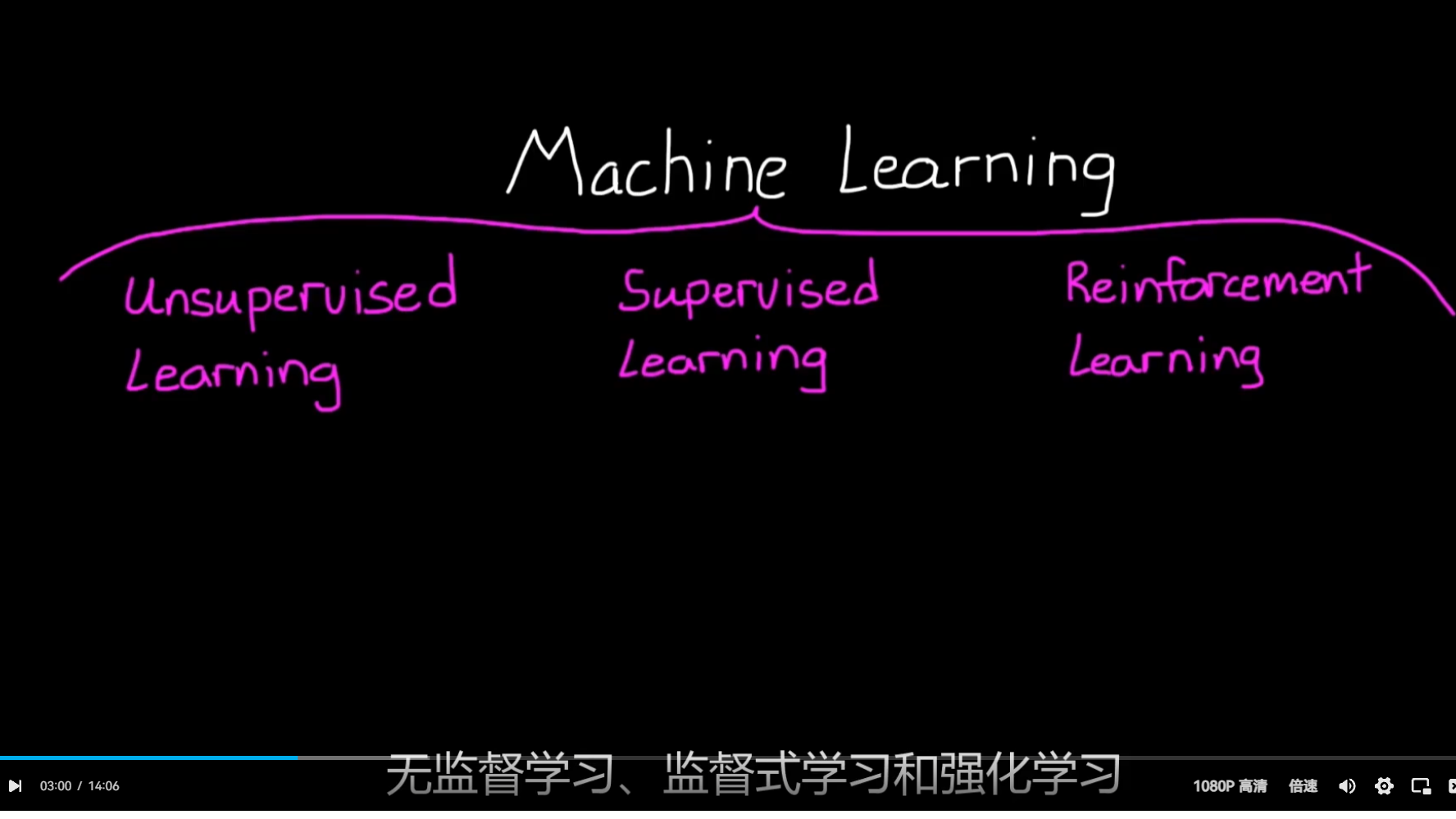
ML combines 3 Paradigm
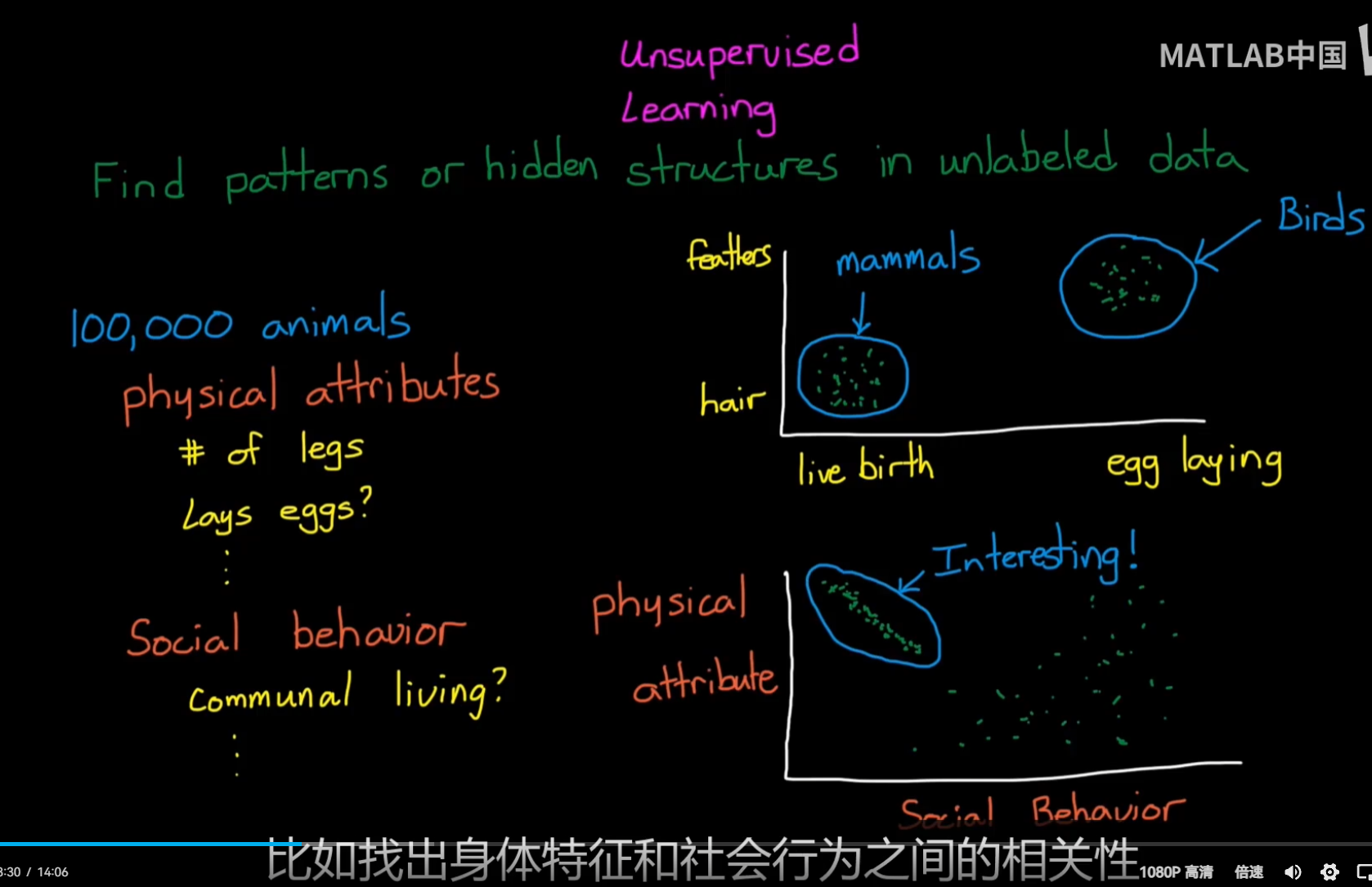
Unsupervised Learning:
不需要标签,根据内在特征进行聚类等相似操作;
Supervised Learning:

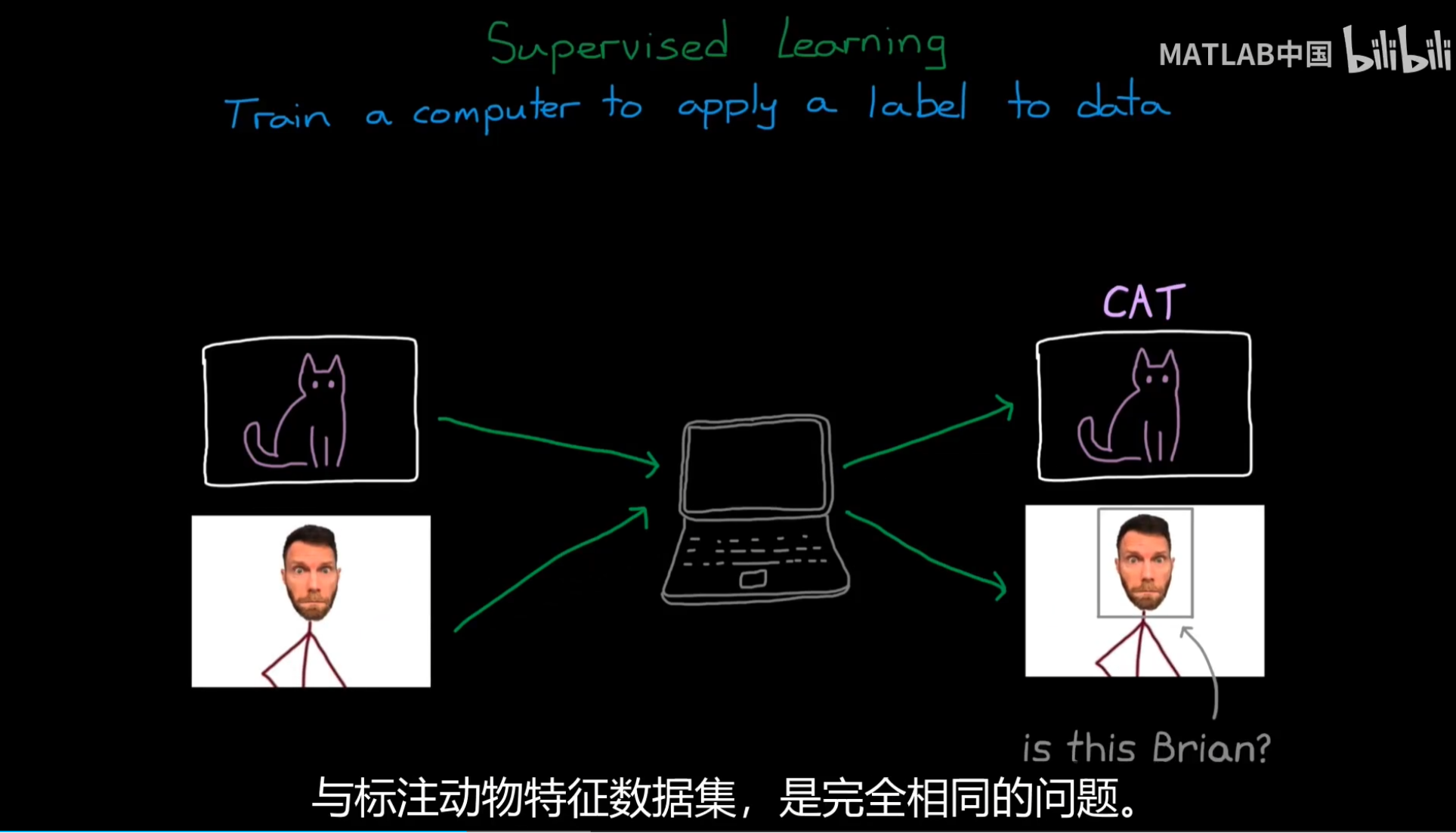
这就是ML所擅长的,从数据中找出特征进而得到label;
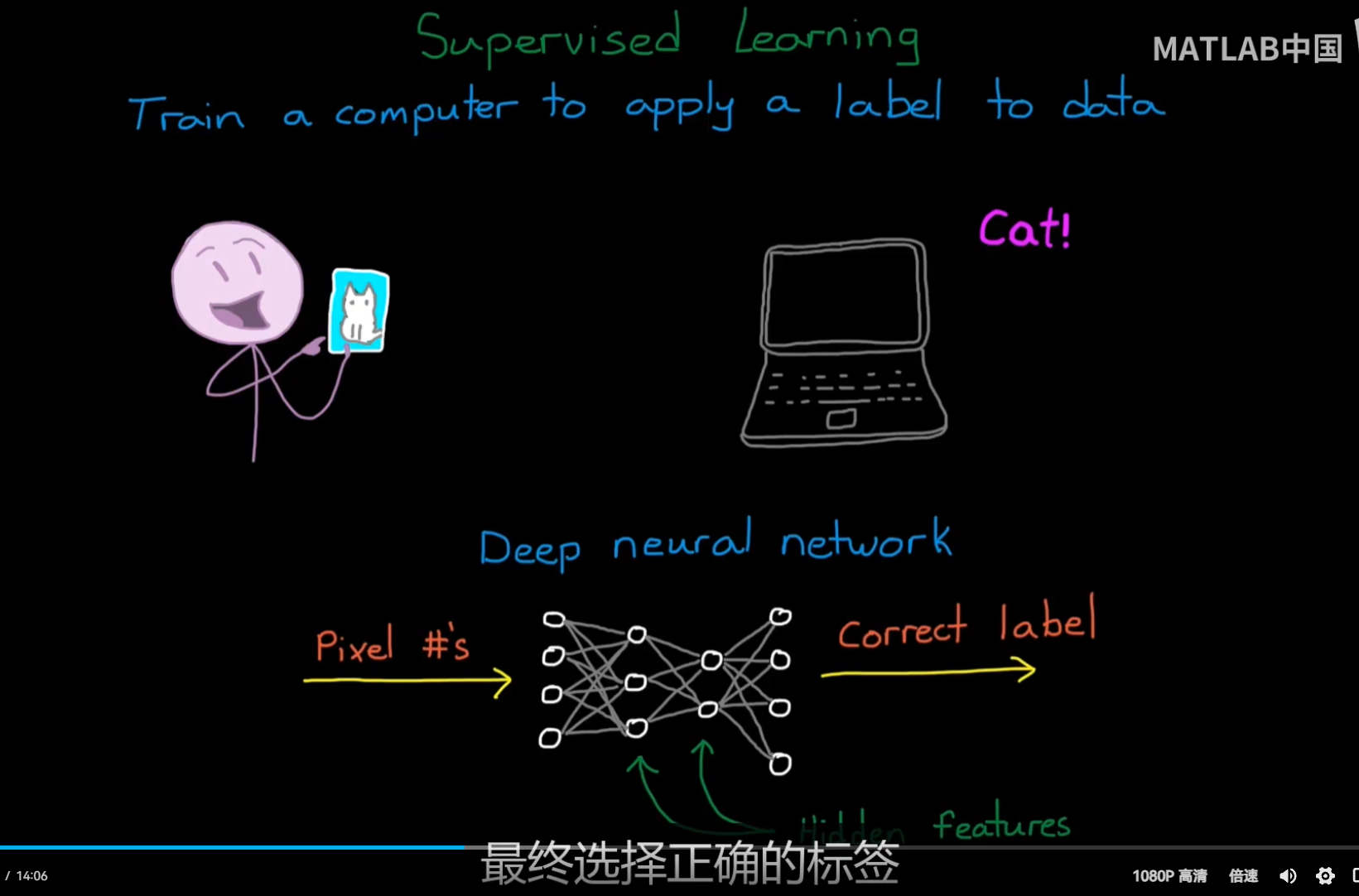
RL与这两个使用静态数据集的学习框架不同;

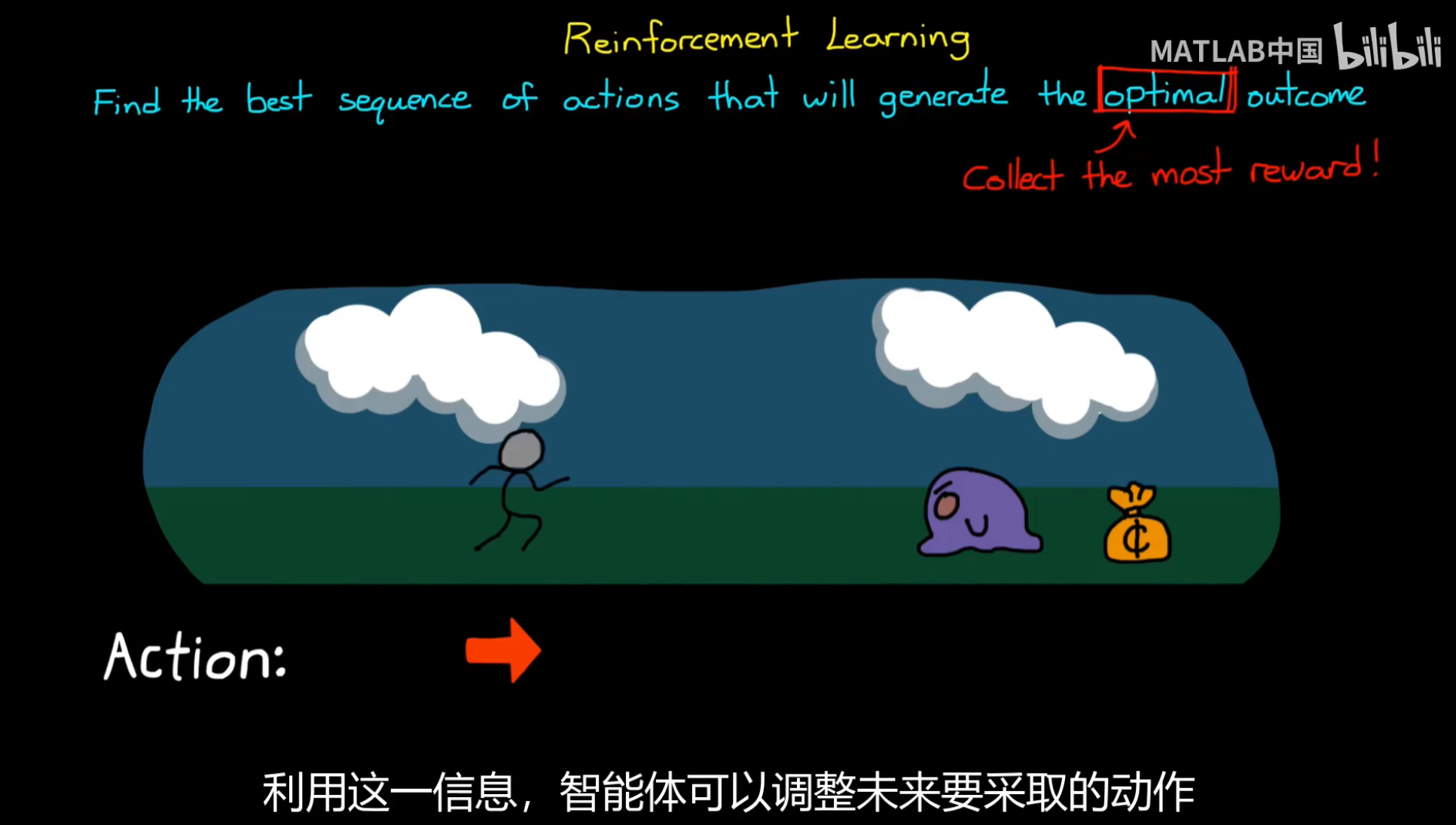
序列行为实现最优的回报;
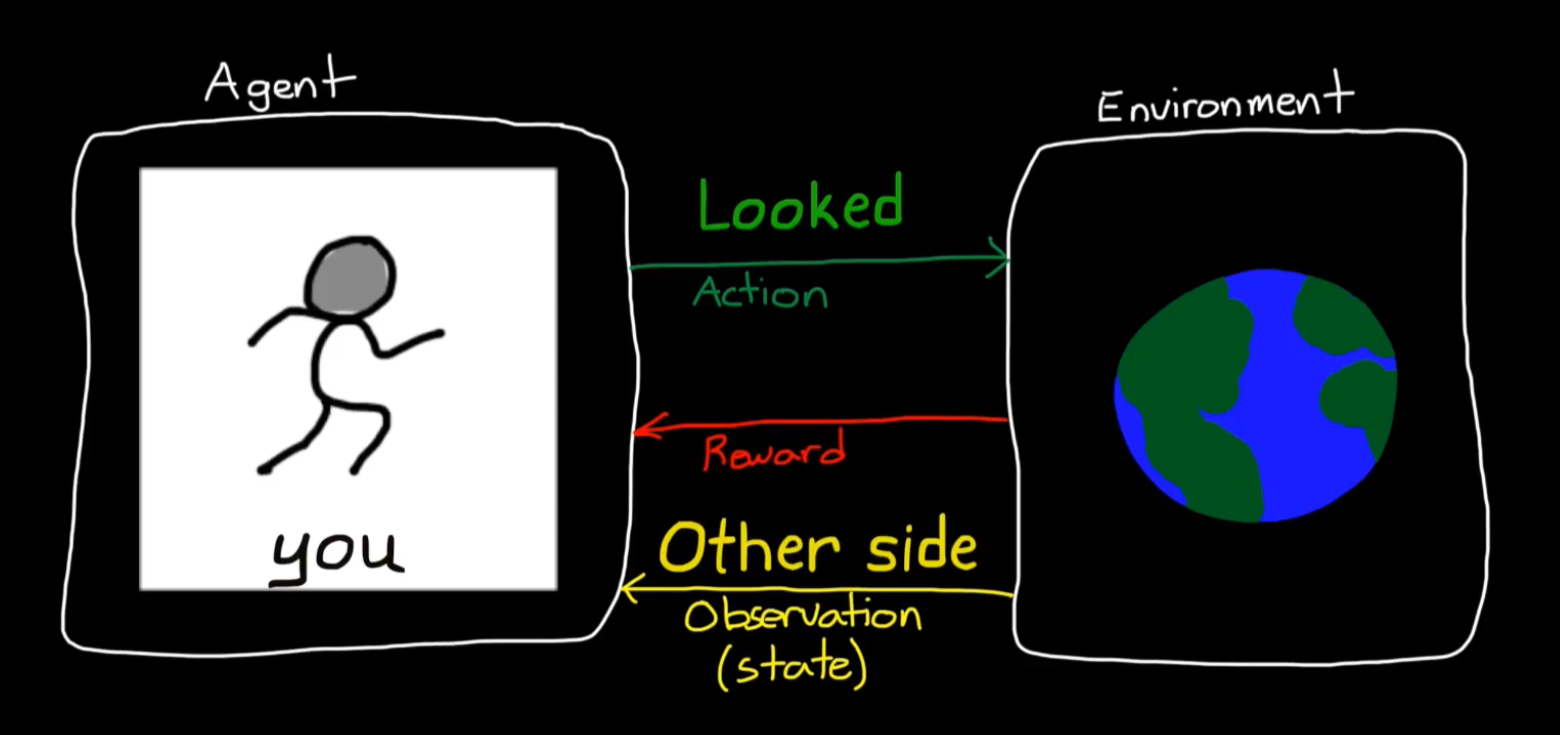
可以将policy使用深度神经网络这也是DRL的由来;
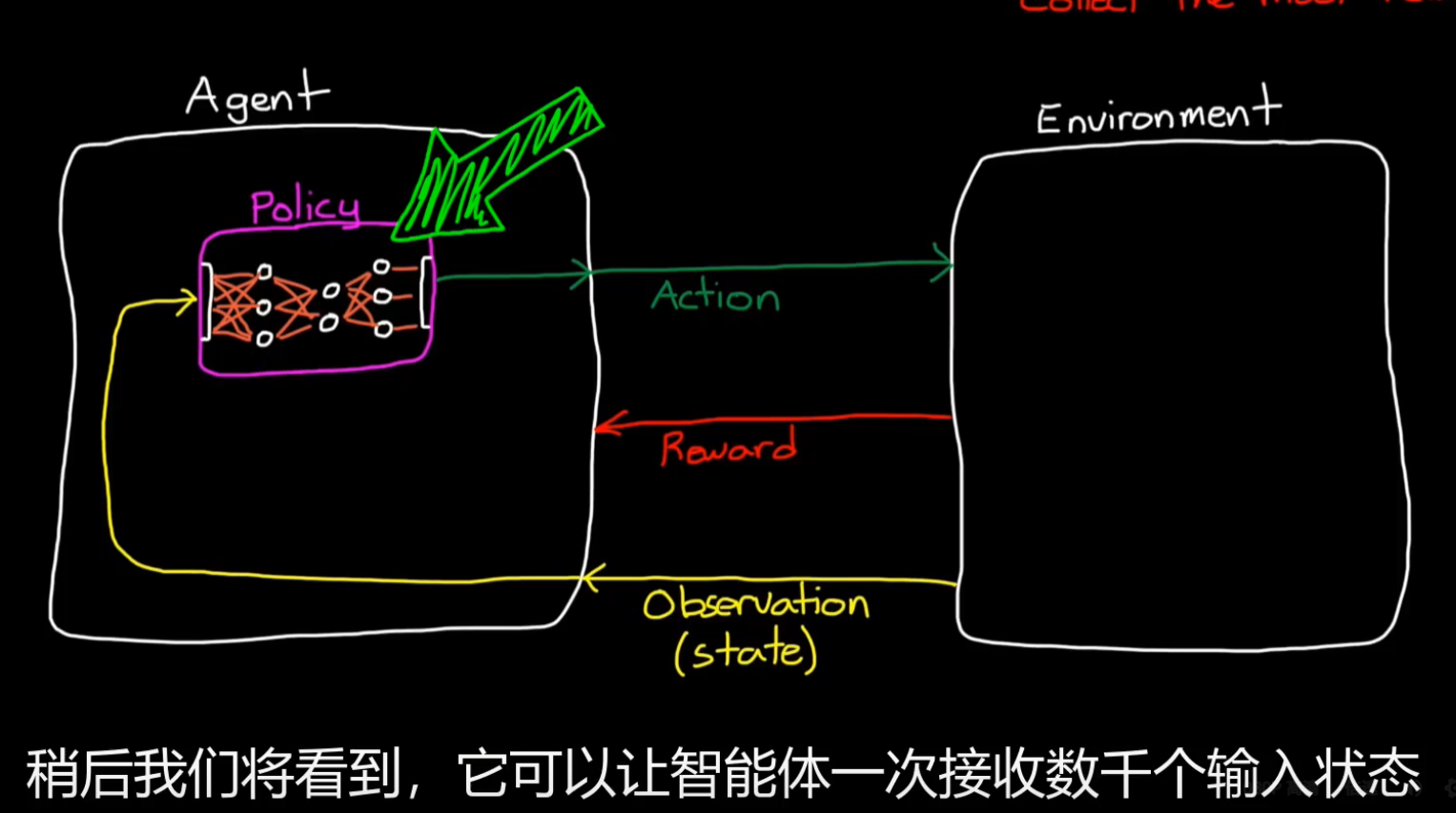
RL算法的作用就是基于观测,奖励等去优化策略,以采取最优动作进而获得最大回报;
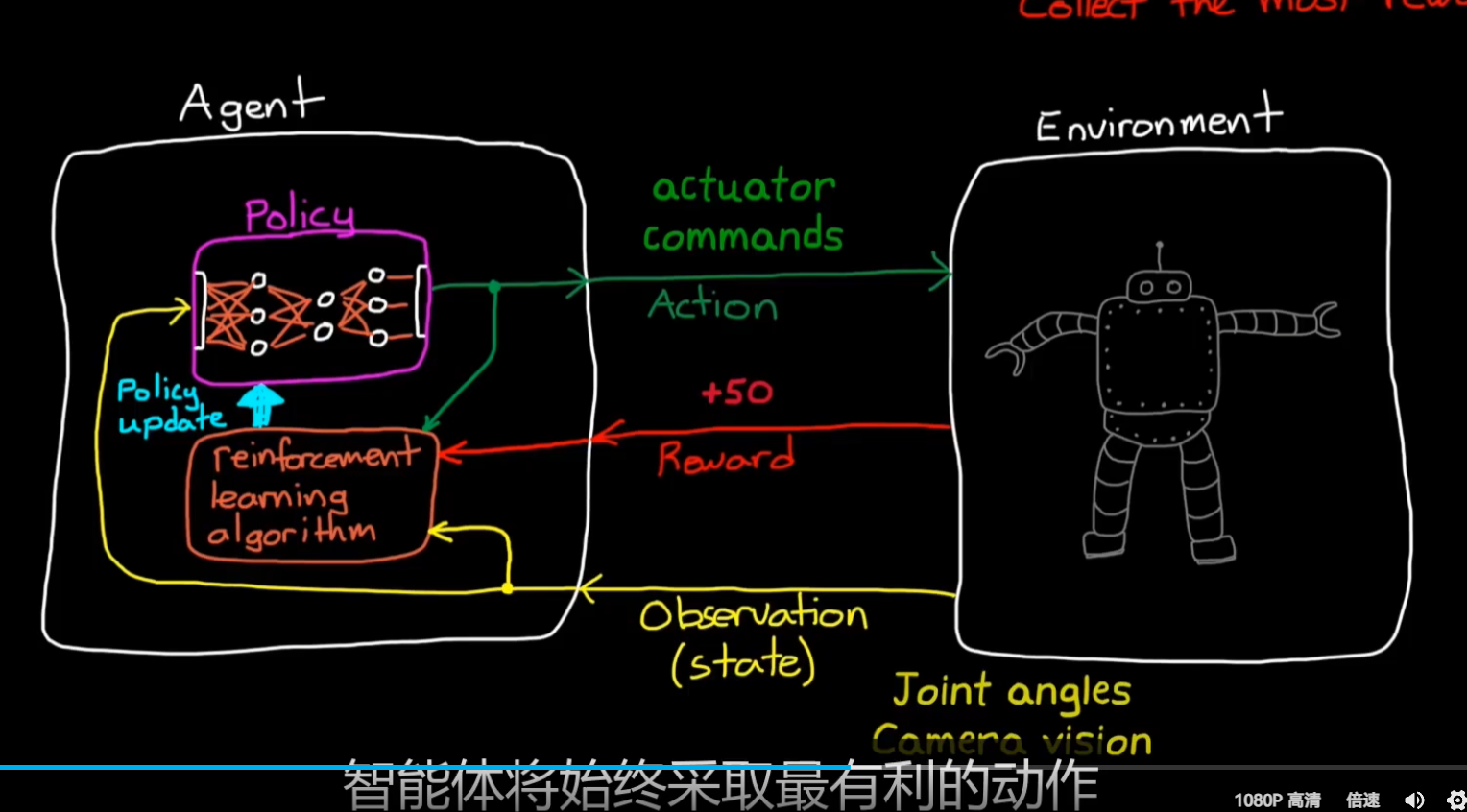
所以,RL就是一个优化问题:

与其他优化问题区分开来:
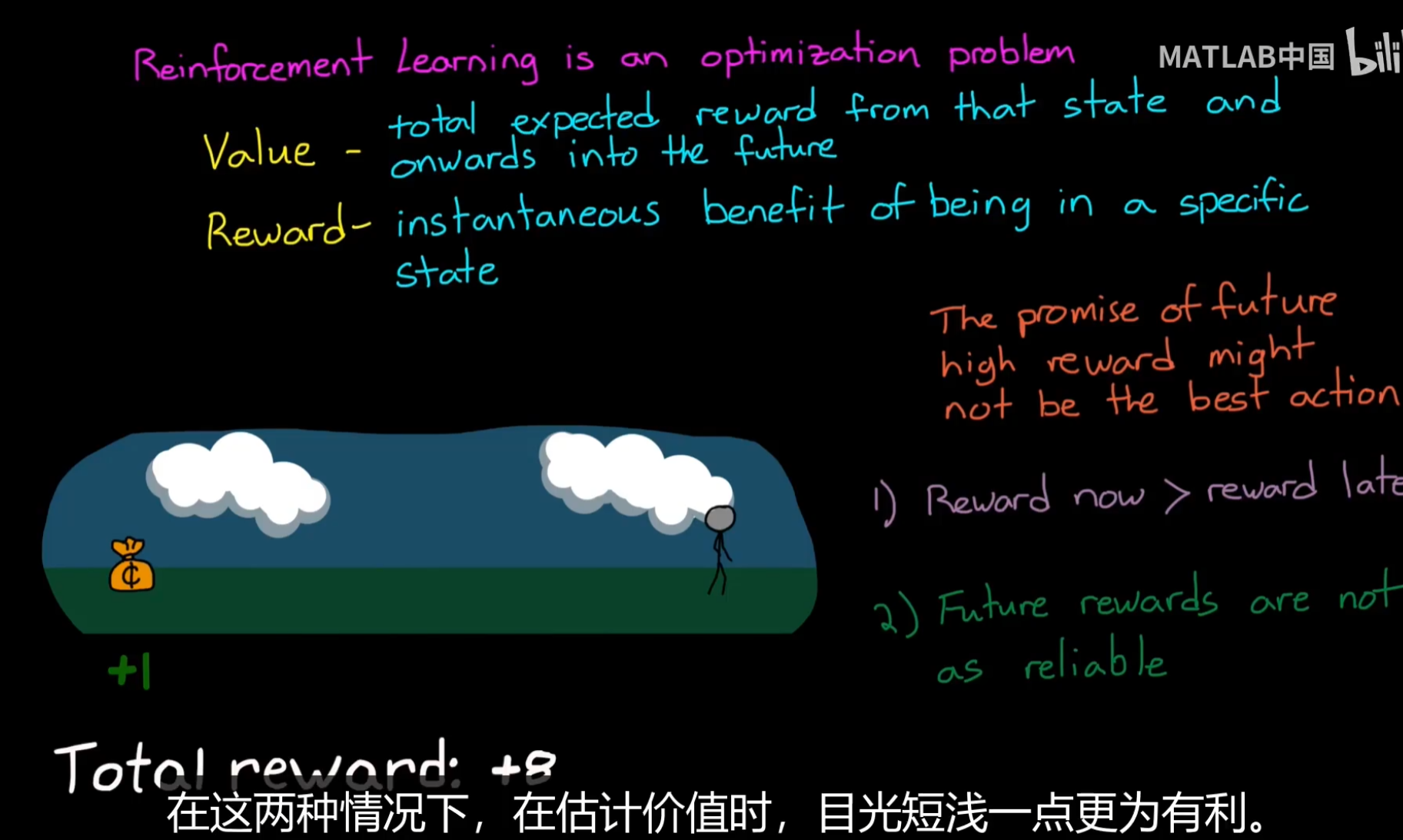
关键点:评估状态价值,将能够使得智能体获得更高回报,而不是只是关注即时奖励;
如果不能够评估状态价值,很有可能导致Agent陷入利用(贪婪)的状态,不断在原地打转;

当然,能够估计越来越远的状态价值,并非适合所有任务,对于金融等任务,等你到了那个时间点,可能并非和预测的一样,因此这种情况下,短视就更加重要;
而控制智能体远视和短视,依靠gamma折扣因子;
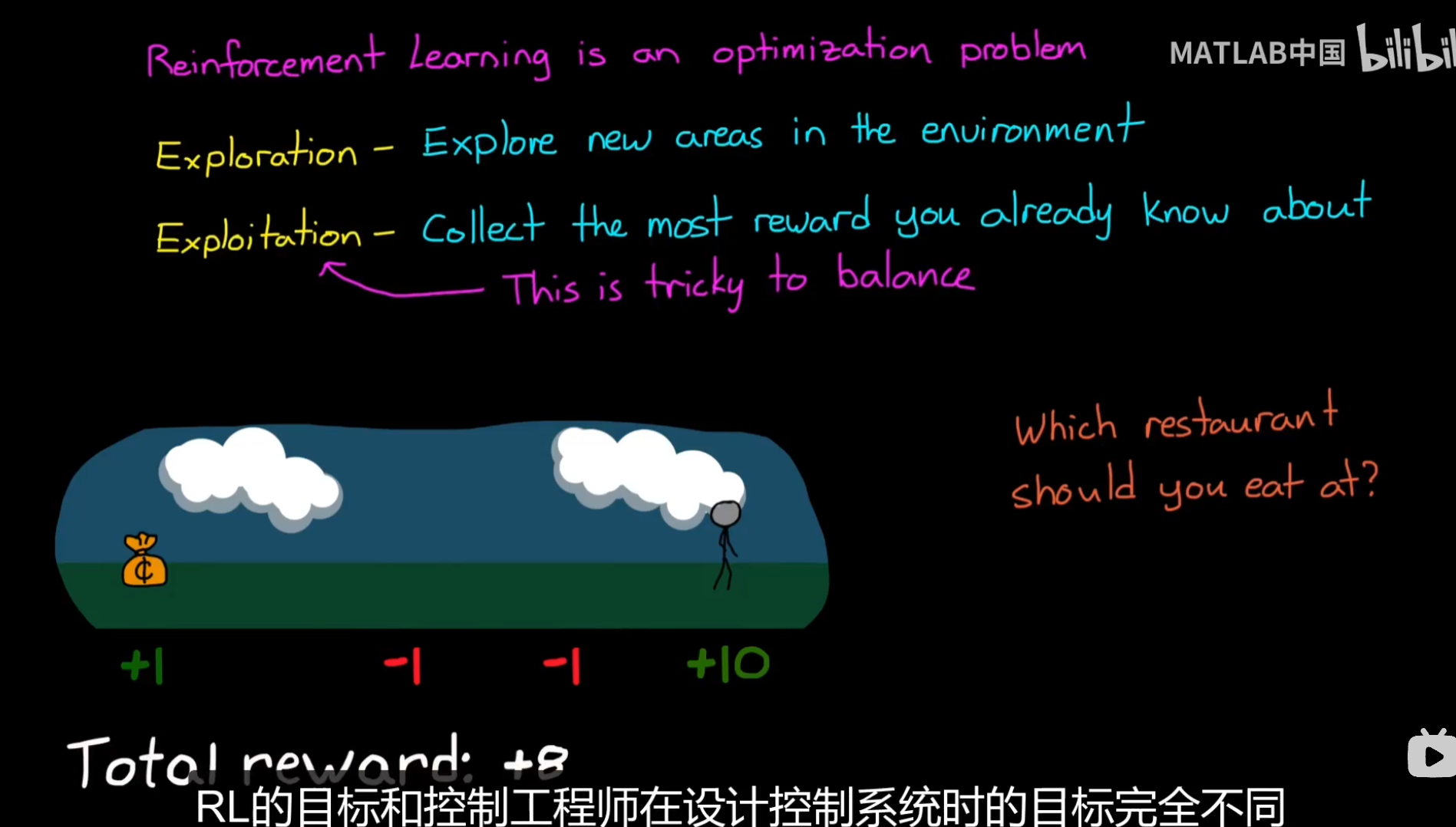
探索利用平衡
智能体能否冒着短期的风险去找到探索一个更大的奖励,进而填补value函数中更多未知部分;
RL问题和控制问题异同:
最小化cost实际上可以通过最大化-reward来实现,
在RL更新过程中实际上也使用了-loss区别于监督学习这类任务;
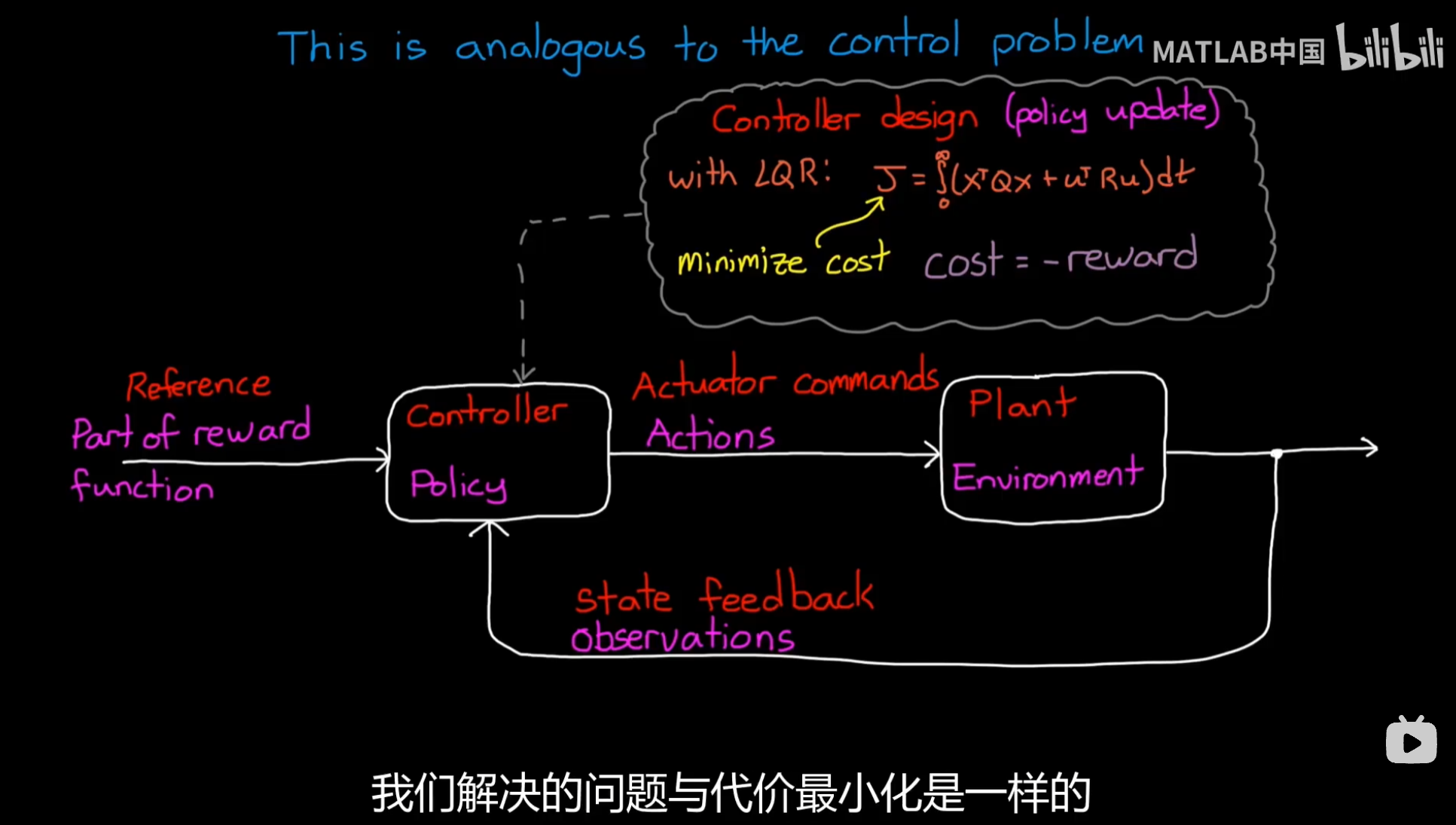
不同:在一段时间内RL需要去学习最优策略,而不是说显式求解
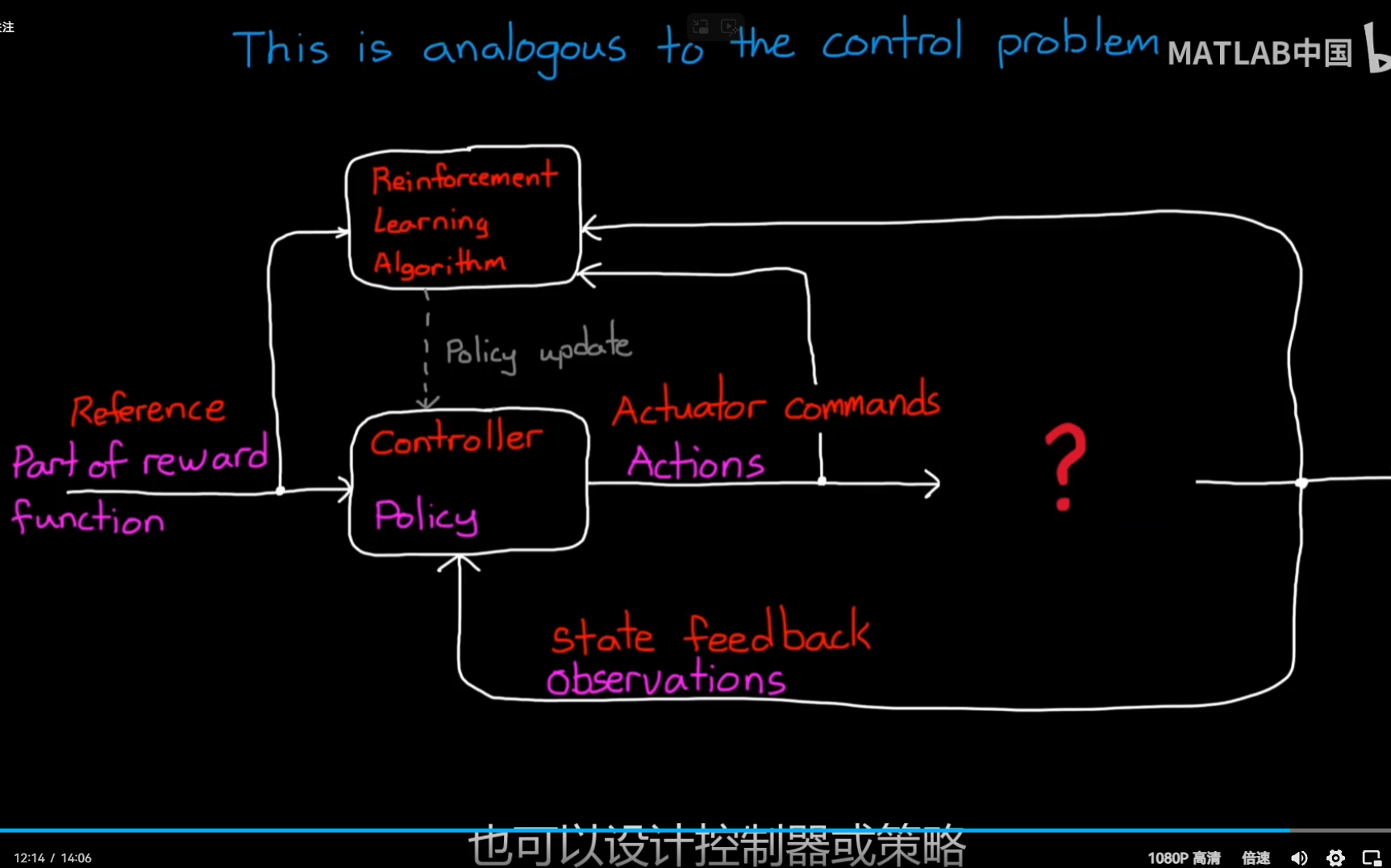
so:

总结:这基本上就是一个任务,我们需要在算法层面考虑的

2.Env and Reward Engineering
工作流:
和控制任务不同,强化学习中环境是除agent之外的所有(包括被控制对象的动态特性)
Model-based很好用,可以避免无效的探索,但是目前model-free使用最多,避免对模型建模
仿真环境好处:
传统控制任务已经做好了仿真,
更加具体:
奖励的设计:
问题:
稀疏奖励和指定优化
之后就是策略和算法(取决于环境设置)
维度灾难:
表格的形式很明显无法应对这种状态很多的情况,尤其是连续空间
此时如果有一个value函数能够通过S-A得到,其实也就是说找到一个拟合函数能够获得s-a的value,那么这个V的结构是什么?实际上很难去设计,通过NN去拟合比较符合