本地部署接入 whisper + ollama qwen3:14b 总结字幕
1. 实现功能
M4-1 接入 whisper + ollama qwen3:14b 总结字幕
- 自动下载视频元数据
- 如果有字幕,只下载字幕
- 使用 ollama 的 qwen3:14b 对字幕内容进行总结
2.运行效果
🔍 正在提取视频元数据…
📝 正在下载所有可用字幕…
[youtube] Extracting URL: https://youtu.be/AU9F-6uWCgE
[youtube] AU9F-6uWCgE: Downloading webpage
[youtube] AU9F-6uWCgE: Downloading tv client config
[youtube] AU9F-6uWCgE: Downloading tv player API JSON
[info] AU9F-6uWCgE: Downloading subtitles: zh-Hans
[info] AU9F-6uWCgE: Downloading 1 format(s): 248+251
Deleting existing file downloads\这AI会做物理题?Skywork-r1v 智商实测,结果出人意料!WebUI 体验。.zh-Hans.srt
[info] Writing video subtitles to: downloads\这AI会做物理题?Skywork-r1v 智商实测,结果出人意料!WebUI 体验。.zh-Hans.srt
WARNING: The extractor specified to use impersonation for this download, but no impersonate target is available. If you encounter errors, then see https://github.com/yt-dlp/yt-dlp#impersonation for information on installing the required dependencies
[download] Destination: downloads\这AI会做物理题?Skywork-r1v 智商实测,结果出人意料!WebUI 体验。.zh-Hans.srt
[download] 100% of 21.61KiB in 00:00:00 at 116.50KiB/s
🤖 正在用 ollama 的 qwen3:14b 总结字幕 …
=== 总结结果 ===
-
🎯 本期主要话题:介绍开源多模态模型 Skywork-r1v 的功能、部署方式和实际应用效果。
-
📌 内容要点:
- Skywork-r1v 是由昆仑万维开发的多模态模型,使用强化学习训练,能够理解图片并进行推理。
- 该模型可以通过 GitHub 和 Huggingface 下载,并支持两种推理方式:Transforms 库和 VLLM。
- 部署过程中需要安装依赖组件,并手动配置 WebUI 程序以实现本地运行。
- 模型在处理图片和推理问题时表现良好,但也存在部分推理错误的情况。
- 🌟 精彩片段或亮点:
- 模型能够根据图片内容进行推理,例如分析图片中的杯子数量和长度关系。
- 在演示过程中,模型对一张折射图片的分析正确,展示了其在特定场景下的准确性和理解能力。
3.实现过程
3.1 搭建环境
Python 环境安装(推荐):
mkdir ytdlp && cd ytdlp
conda create -n ytdlp python=3.10 -y
conda activate ytdlp
pip install -U “yt-dlp[default]”
3.1.1 打开anaconda
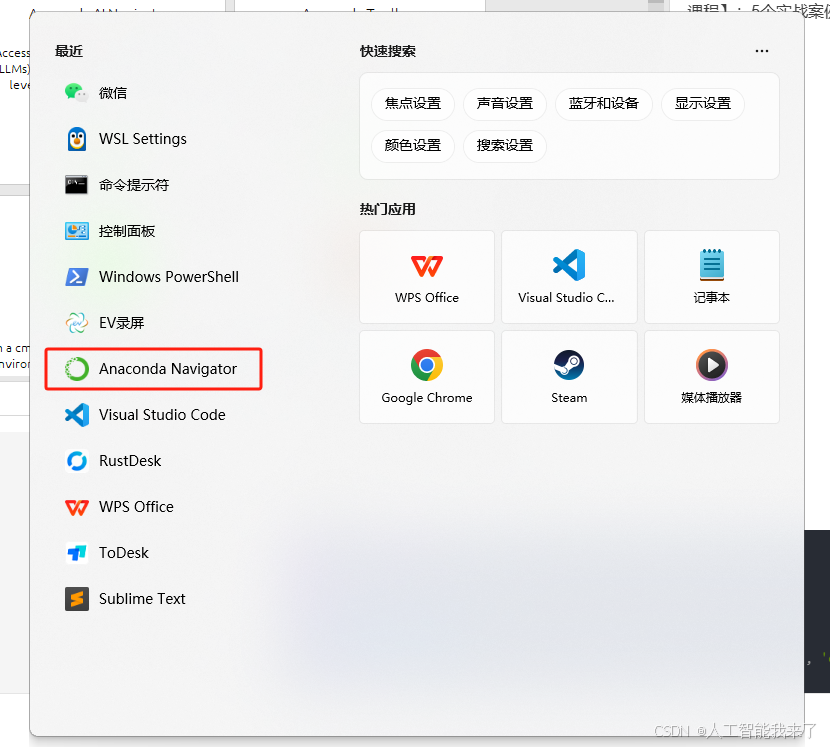
3.1.2 通过图像化界面创建ytdlp环境
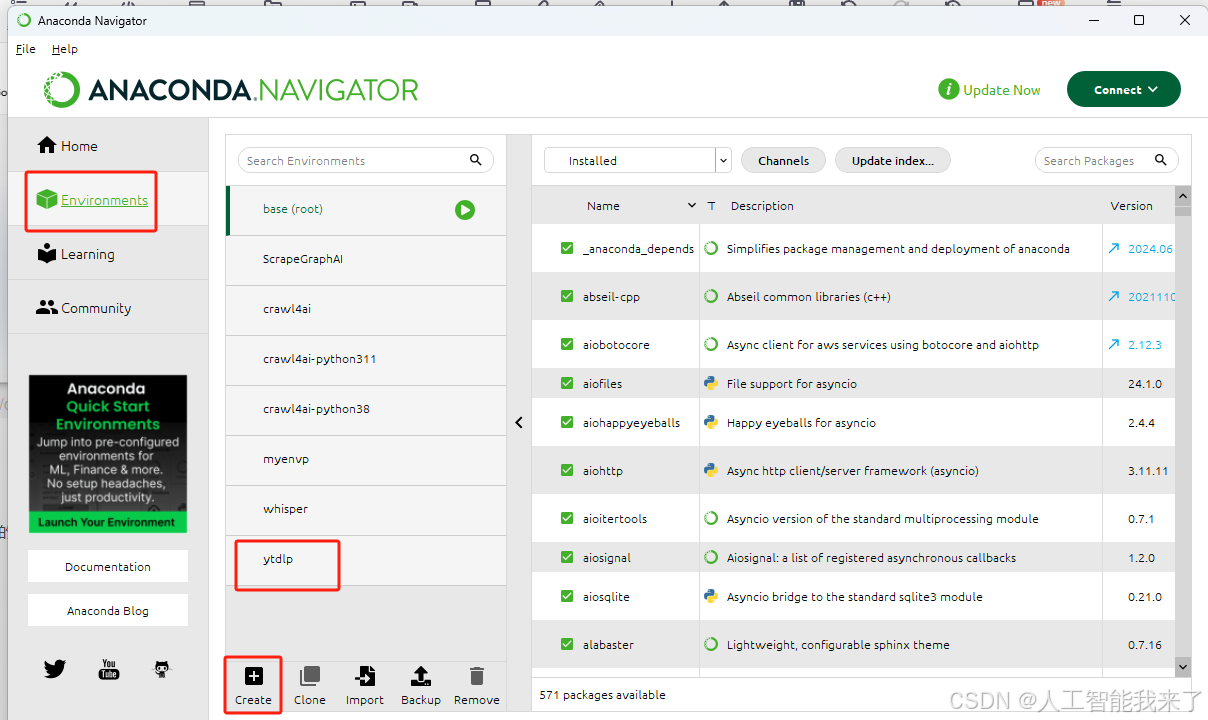
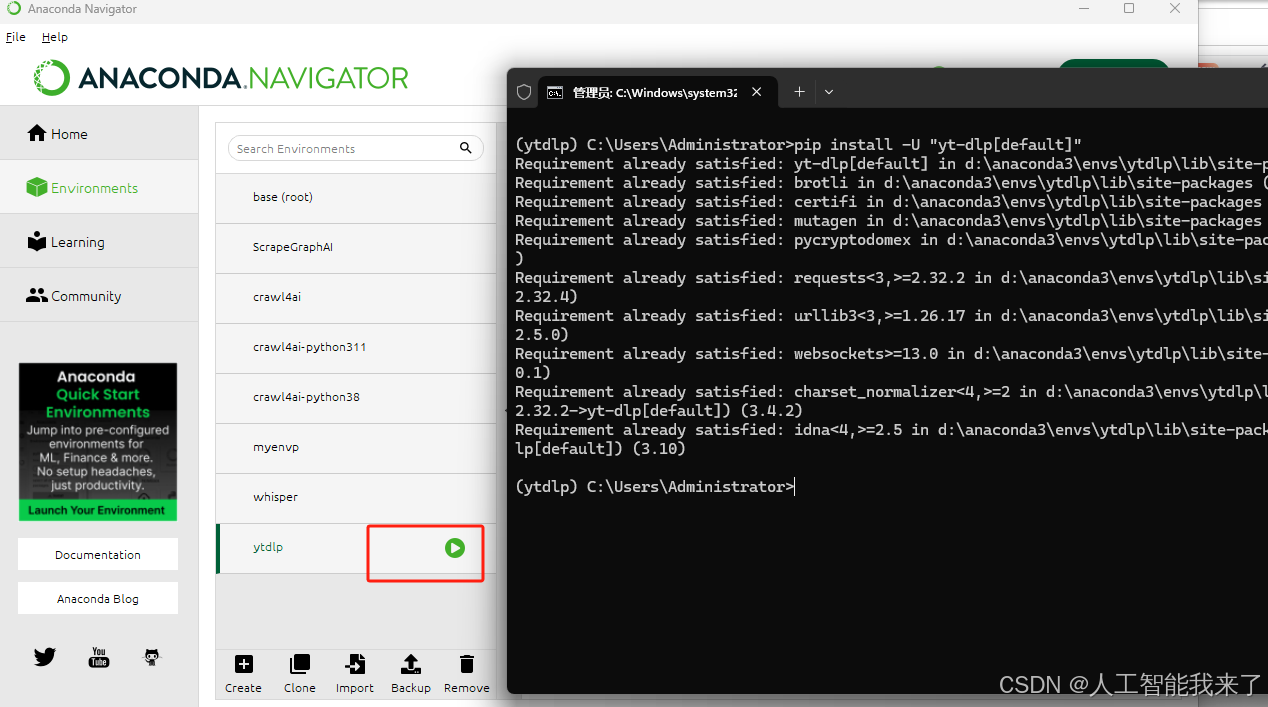
3.1.3 打开ytdlp的open terminal
pip install -U “yt-dlp[default]”
3.1.4 vscode python解析器 选择ytdlp
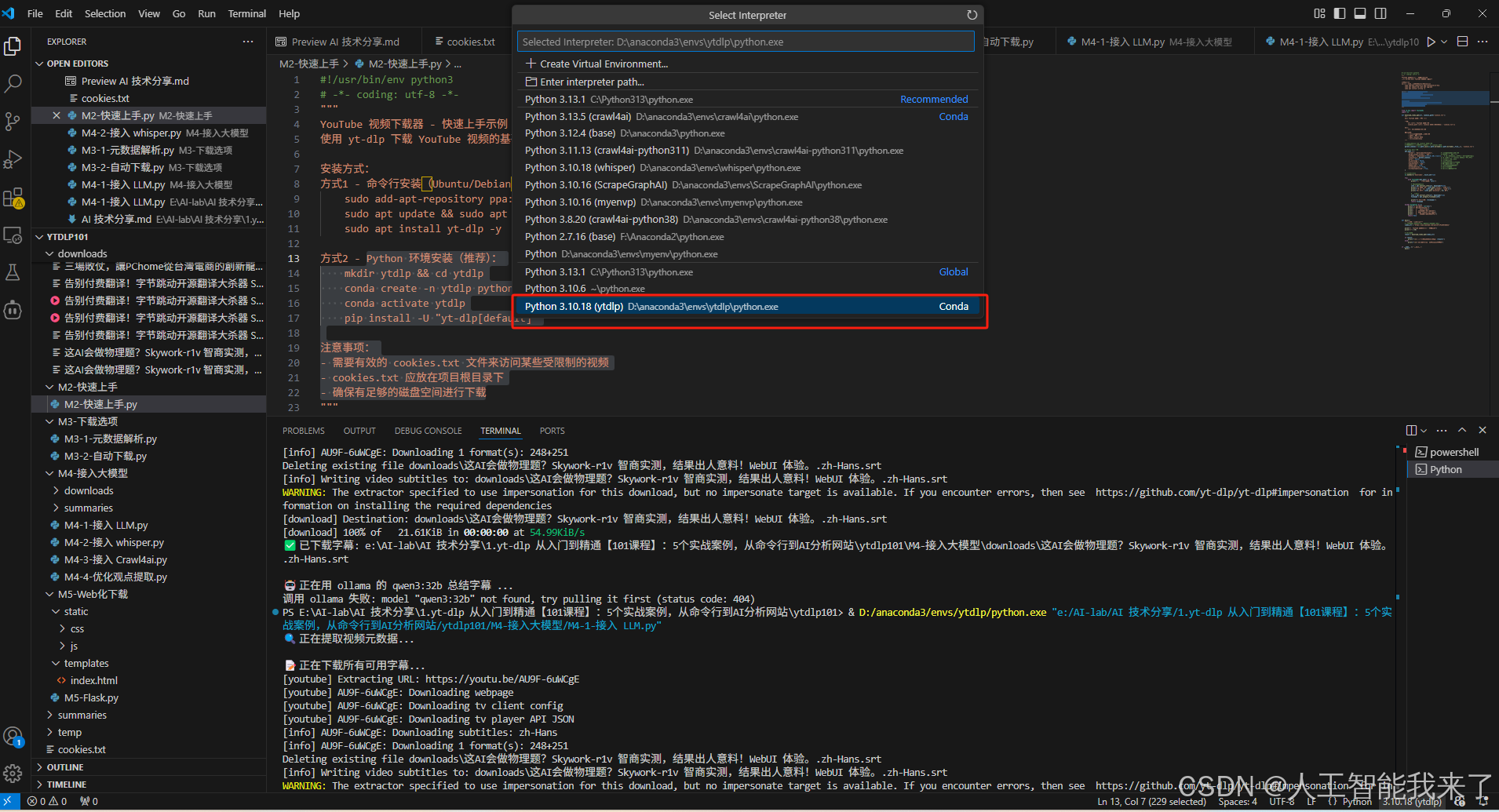
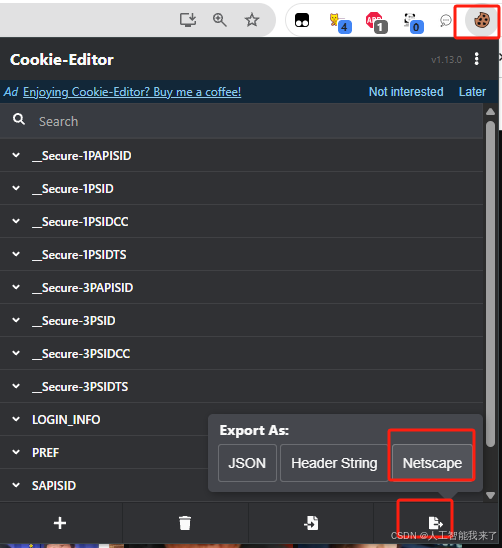
3.1.5 获得cookies.txt内容
3.2 代码
from yt_dlp import YoutubeDL
import os
import subprocessdef get_parent_cookies():return os.path.join(os.path.dirname(os.path.dirname(__file__)), 'cookies.txt')def extract_video_metadata(url):ydl_opts = {'cookiefile': get_parent_cookies(),'quiet': True,'no_warnings': False,'extract_flat': False,'extractor_args': {'youtube': {'player_client': ['tv_embedded', 'web'],}}}with YoutubeDL(ydl_opts) as ydl:try:info = ydl.extract_info(url, download=False)return infoexcept Exception as e:print(f"提取元数据失败: {e}")return Nonedef download_subtitles(url, info):subtitles = info.get('subtitles', {})if not subtitles:print("\n📝 没有可用字幕,跳过下载和总结。")return Noneprint("\n📝 正在下载所有可用字幕...")ydl_opts = {'cookiefile': get_parent_cookies(),'skip_download': True,'writesubtitles': True,'allsubtitles': True,'subtitlesformat': 'srt','outtmpl': 'downloads/%(title).80s.%(ext)s','quiet': False,}with YoutubeDL(ydl_opts) as ydl:ydl.download([url])# 查找下载的srt字幕文件downloads_dir = os.path.join(os.path.dirname(__file__), 'downloads')srt_files = [f for f in os.listdir(downloads_dir) if f.endswith('.srt')]if not srt_files:print("❌ 没有找到下载的字幕文件")return Nonesrt_path = os.path.join(downloads_dir, srt_files[0])print(f"✅ 已下载字幕: {srt_path}")return srt_pathdef summarize_with_ollama(srt_path):print(f"\n🤖 正在用 ollama 的 qwen3:14b 总结字幕 ...")# 自动安装ollama包(如未安装)try:import ollamaexcept ImportError:import sys, subprocesssubprocess.check_call([sys.executable, '-m', 'pip', 'install', 'ollama'])import ollama# 读取并清洗SRT字幕内容,拼接为段落def srt_to_text(srt_content):import relines = srt_content.splitlines()text_lines = []for line in lines:# 跳过序号和时间轴if re.match(r"^\d+$", line):continueif re.match(r"^\d{2}:\d{2}:\d{2},\d{3} --> ", line):continueif line.strip() == '':continuetext_lines.append(line.strip())# 合并为段落,去重相邻重复from itertools import groupbymerged = [k for k, _ in groupby(text_lines)]return ' '.join(merged)with open(srt_path, 'r', encoding='utf-8') as f:srt_content = f.read()clean_text = srt_to_text(srt_content)# 构造 promptprompt = f"""
你是一名专业的视频内容总结助手,请对下列中文视频字幕内容进行总结。目标:让用户能在30秒内了解这期视频的核心内容。请按以下格式输出:
1. 🎯 本期主要话题(用一句话概括主题)
2. 📌 内容要点(3-5条,每条 1 句话)
3. 🌟 精彩片段或亮点(选出最值得一提的内容,1-2条)⚠️ 不要加入你的思考过程,不要说“我认为”或“可能”,只根据字幕原文总结。字幕内容如下:
———
{clean_text}
———
/no_think
"""try:response = ollama.chat(model='qwen3:14b',messages=[{"role": "user", "content": prompt}])print("\n=== 总结结果 ===\n")print(response['message']['content'])except Exception as e:print(f"调用 ollama 失败: {e}")def main():url = "https://youtu.be/AU9F-6uWCgE"print("🔍 正在提取视频元数据...")info = extract_video_metadata(url)if not info:print("❌ 无法获取视频信息")returnsrt_path = download_subtitles(url, info)if srt_path:summarize_with_ollama(srt_path)if __name__ == "__main__":main()