计算BERT-BASE参数量
今天我们来计算一下BERT-BASE的参数量
已知
| Transformer 层数 | 12 |
| 隐藏层维度 | 768 |
| 注意力头数 | 12 |
| 词汇表大小 | 21128 |
| 最大位置编码 | 512 |
BERT的结构
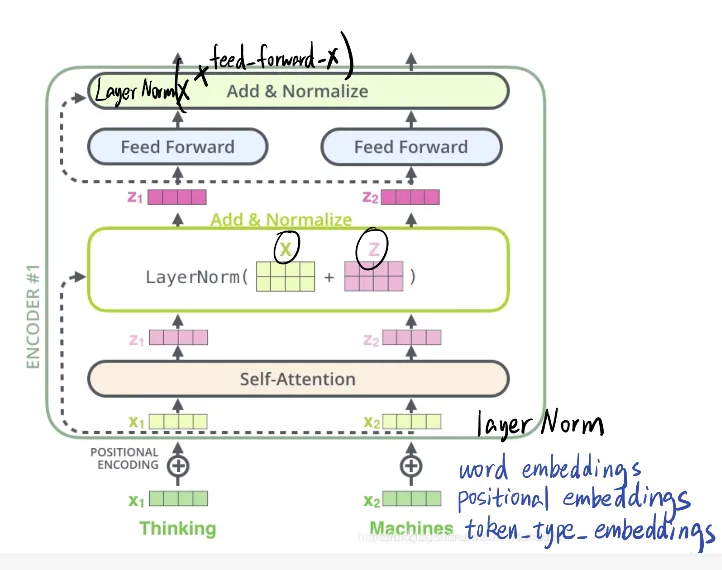
拆分下来看:
1. embedding部分: 输入数字列表,经过embedding层之后相加, 输出矩阵
token embedding: 一个词对应一个向量
V(词表大小)*h(指定向量维度,base中是768)
segment embedding: 区分两句话
2*h (现在已经不用了)
position embedding: 需要事先设置一个最大值,超过截断(512个)
512*h(现在不用绝对位置编码了,用相对位置编码)
注意下图中input中的cls和sep

求和 → 归一化 → 送入 Transformer 层
这里的归一化操作(Layer Norm)用于:
稳定嵌入层输出的分布(不同嵌入成分的尺度可能不同);
避免嵌入向量的绝对值过大,影响后续注意力机制的计算稳定性。
与 Transformer 层中的层归一化一样,嵌入层归一化的参数为两个可学习的向量:缩放参数和偏移参数
embedding层的参数量=V(词表大小)*h(指定向量维度,base中是768)+2*h+512*h+2*h
2. 单个transformer层(包括attention层,feedforward层和ln层)*12
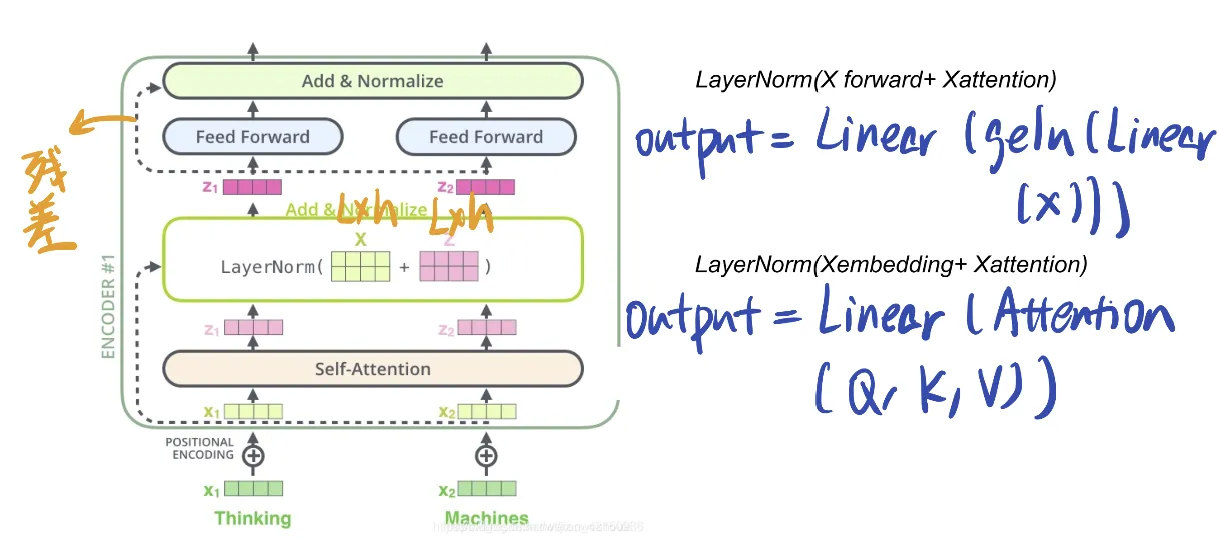
回顾一下这个图
2.1 self-attention部分
输入X 形状 L*h(即embedding之后的输出)
- 线性变换:输入序列通过 3 个独立的线性变换矩阵(W_Q、W_K、W_V)生成 Q(查询)、K(键)、V(值)矩阵(其实是wx+b)。Q,K,V 形状是L*h. WQ,WK,WV 参数量 3*h*h+3*h
- 多头分割:Q、K、V 被分割为 n_heads 个并行的子矩阵(每个头维度为 d_head = d_model /n_heads),实现多视角注意力计算。
- 自注意力计算:每个头独立计算注意力分数:
- 先计算 Q 与 K 的相似度(点积):Q・Kᵀ
- 除以√d_head(除以根号DK原因是如果数值过大,会出现softmax的值极端的情况,缩小绝对值会使得这些值不会都趋向于0)
- 经过 softmax 得到注意力权重(softmax是将每一行归一化,实际是计算每句中任意两个字的相关性)
- 与 V 矩阵相乘得到该头的注意力输出
4. 拼接与投影:所有头的输出拼接后,通过输出投影矩阵(W_O)整合为最终结果,维度与输入保持一致(d_model)。W_O 参数量 h*h+h
5. 残差连接与层归一化:layernorm(X+Z) 注意力输出与原始输入相加(残差连接),再经过层归一化,作为最终输出传递给前馈网络。

2.2 feed forward部分
两个线性层+中间一个激活层
维度变化: h--->4h--->h
一、标准 Feed Forward 层结构与参数
在 Transformer(包括 BERT)中,Feed Forward 层由两个线性变换组成,定义为:
- 输入维度: d_model (通常称为 embedding size,如 BERT-BASE 中为 768, 即h)
- 中间层维度: d_ffn (通常称为 hidden size,如 BERT-BASE 中为4*768, 即4*h)
1. 第一个线性层(升维)
作用:将输入从 d_model 映射到 d_ffn 参数计算: 权重矩阵 + 偏 置向量 = d_model × d_ffn + d_ff n (输入维度 × 中间维度 + 中间维度偏置)
2. 第二个线性层(降维)
作用:将中间层从 d_ffn 映射回 d_model 参数计算: 权重 矩阵 + 偏置向量 = d_ ffn × d_model + d_mo del (中间维度 × 输出维度 + 输出维度偏置)
3.池化层
在 BERT 模型中,池化层(Pooling Layer)的作用是将序列级别的的隐藏状态转换为一个固定长度的向量,用于表示整个输入序列的语义信息。BERT-BASE 中的池化层设计相对简洁,主要通过以下方式实现:
一、BERT-BASE 池化层的核心机制
BERT 采用了一种特殊标记([CLS])+ 线性变换的池化策略,而非传统的平均池化或最大池化。具体流程如下:
- [CLS] 标记的引入 在输入序列的最开头,BERT 会插入一个特殊的 [CLS] (Classification)标记。例如: [CLS] 我 爱 自然 语言 处理 .
- [CLS] 标记的隐藏状态 经过 12 层 Transformer 编码器后, [CLS] 标记对应的隐藏状态(记为 C )被视为整个序列的 “汇总表示”。
- 原因:在预训练阶段, [CLS] 标记会通过自注意力机制 “关注” 整个序列的信息,逐渐学习到整合全局语义的能力。
- 池化层的输出 [CLS] 的隐藏状态会直接作为池化层的输出,其维度为 d_model=768 (与 BERT-BASE 的隐藏层维度一致)。
二、与其他池化方式的对比
BERT 没有采用传统池化(如平均池化),主要原因是:
- 动态适应性: [CLS] 标记的隐藏状态通过自注意力动态捕捉序列中最关键的信息,而平均池化会无差别对待所有 token,可能稀释重要信息。
- 预训练对齐:在预训练的 Next Sentence Prediction(NSP)任务中, [CLS] 被专门用于判断两个句子的关系,天然适合作为序列级表示。
三、池化层的参数
BERT-BASE 的池化层本身没有额外的可学习参数,它直接复用 [CLS] 标记经过最后一层 Transformer 输出的隐藏状态。但在实际应用中,下游任务(如文本分类)通常会在池化输出后添加一个线性层(h*h+h),将 768 维向量映射到任务所需的类别数。这些线性层参数是下游任务训练时学习的,不属于 BERT 预训练模型的池化层参数。
总参数量=嵌入层参数量+transformer层参数量+池化层参数量
=V(词表大小)*h(指定向量维度,base中是768)+2*h+512*h+2*h+(4*h*h+4*h+h*4*h + 4*h+4*h*h+h+2*2*h)*12+h*h+h=102267648
可以用代码验证一下~
from transformers import BertModelmodel = BertModel.from_pretrained(r"\models\bert-base-chinese", return_dict=False)
print("模型实际参数个数为%d" % sum(p.numel() for p in model.parameters()))今天的分享就到这里,有问题欢迎评论区留言 ^_^