[CUDA] CUTLASS | C++ GEMM内核--高度模板化的类
第2章:GEMM内核(C++)
在第1章:CuTe DSL中,我们了解到CuTe DSL如何通过Python原生的方式编写高性能GPU内核,简化复杂的CUDA编程。
虽然CuTe DSL提供了卓越的易用性和快速原型设计能力,但其核心力量最终来源于cutlass底层精心优化的C++机制。
本章将深入探索cutlass的核心:用C++编写的通用矩阵乘法(GEMM)内核。
这些内核就像精心调校的定制引擎,驱动着高速计算。理解它们的角色(即使是高层次的理解)对于领会cutlass如何实现峰值性能至关重要。
核心动力:通用矩阵乘法(GEMM)
想象深度学习或科学计算中的核心操作:将大型矩阵相乘。
这个基础操作被称为**通用矩阵乘法(GEMM)**(表示为C = A * B + D),是现代计算的基石。
优化GEMM至关重要,因为它在训练神经网络或运行模拟等应用中常常成为性能瓶颈,消耗大部分计算时间。
为什么在GPU上优化GEMM如此具有挑战性?
海量并行性:现代GPU拥有数千个核心,如何高效分配任务?数据移动:在不同内存层级(全局内存、共享内存、寄存器)间移动数据非常耗时,关键在于尽可能复用数据并隐藏延迟硬件特性:NVIDIA GPU配备了名为"Tensor Core"的专用单元,专为快速执行低精度(如FP16、BF16、TF32)矩阵乘法设计,利用这些单元需要精确编程
这正是cutlass C++ GEMM内核的价值所在。它们为NVIDIA GPU提供高度优化的手工调优矩阵乘法实现,精心设计以榨取每一分性能。
cutlass将这些复杂内核以C++模板库的形式提供,开发者只需选择最适合特定矩阵乘法问题的"引擎",cutlass将处理所有复杂细节。
本章的学习目标:
cutlassC++ GEMM内核的概念性理解- 如何从高层次配置和启动简单矩阵乘法
- 高性能实现背后的底层机制
C++ GEMM–高度模板化的类
cutlass C++ GEMM内核不是单个函数,而是高度模板化的类。
这意味着它是编译时可定制的蓝图,能够创建多种不同的专用版本。每个版本针对以下特性优化:
- 数据类型:矩阵元素的数值类型(如
float、half、int8_t、bfloat16_t) - 矩阵布局:矩阵在内存中的存储方式(如行优先、列优先)
- 问题规模:矩阵维度(M、N、K)
- GPU架构:目标NVIDIA GPU架构(如Volta、Turing、Ampere、Hopper、Blackwell)
- 专用硬件:是否使用Tensor Core或标准CUDA核心(SIMT)
- 尾声操作:希望融合到GEMM内核中的后处理操作(如激活函数或逐元素加法)
cutlass中设备端GEMM操作的主要入口通常定义在cutlass::gemm::device命名空间内,常见类如cutlass::gemm::device::Gemm。
第一个cutlass C++ GEMM(概念示例)
让我们通过概念性示例了解如何使用cutlass C++内核设置并启动简单GEMM(如C = A * B)。为清晰起见,代码已简化,聚焦于高层次步骤。
#include <cutlass/cutlass.h>
#include <cutlass/gemm/device/gemm.h> // 主GEMM设备类// 需要一些张量分配和初始化的工具
#include <cutlass/util/host_tensor.h>
#include <cutlass/util/device_reference/host/tensor_fill.h>
#include <cutlass/util/device_reference/host/gemm.h> // 用于CPU验证#include <iostream> // 打印输出
解释:
包含必要的cutlass头文件。cutlass/gemm/device/gemm.h是GEMM设备内核类的主头文件,其他工具头文件用于张量管理和验证。
现在定义问题和特定类型的GEMM内核:
// 1. 定义GEMM问题:C = alpha * A * B + beta * C
// 选择简单的float类型GEMM
using ElementA = float;
using ElementB = float;
using ElementC = float;
using ElementAccumulator = float; // 内部累加器类型// 定义矩阵布局:A列优先,B行优先,C列优先
// 对应传统BLAS中的'TN'操作(A转置,B不转置)
using LayoutA = cutlass::layout::ColumnMajor;
using LayoutB = cutlass::layout::RowMajor;
using LayoutC = cutlass::layout::ColumnMajor;// 定义GPU架构(如NVIDIA Ampere架构)
using ArchTag = cutlass::arch::Sm80; // 适用于A100 GPU// 定义操作类别(如Tensor Core或SIMT)
using OpClass = cutlass::arch::OpClassSimt; // 使用标准CUDA核心简化示例// 定义线程块和warp分块尺寸(关键性能参数!)
// ThreadblockShape: 线程块处理的总工作量(M, N, K)
using ThreadblockShape = cutlass::gemm::GemmShape<128, 128, 8>;
// WarpShape: 单个warp处理的工作量(M, N, K)
using WarpShape = cutlass::gemm::GemmShape<32, 64, 8>; // 示例值
// InstructionShape: 硬件指令的分块形状(如SIMT float使用1x1x1)
using InstructionShape = cutlass::gemm::GemmShape<1, 1, 1>;// 定义尾声操作(如简单线性组合)
using EpilogueOutputOp = cutlass::epilogue::thread::LinearCombination<ElementC, // 输出元素类型128 / sizeof(ElementC), // 每次访问加载/存储的元素数量ElementAccumulator, // 累加器元素类型ElementC // alpha/beta的计算元素类型
>;// 定义实际GEMM内核类型(简化示例,实际实例化会更长)
using Gemm = cutlass::gemm::device::Gemm<ElementA, LayoutA,ElementB, LayoutB,ElementC, LayoutC,ElementAccumulator,OpClass,ArchTag,ThreadblockShape,WarpShape,InstructionShape,EpilogueOutputOp,cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>, // 线程块调度方式2 // 流水线阶段数
>;
解释:
这是最复杂的部分:实例化cutlass::gemm::device::Gemm模板。我们定义GEMM操作的所有属性。GemmShape参数对性能至关重要,它们决定了工作在线程块、warp和单个指令间的划分方式。EpilogueOutputOp定义最终累加结果在写入C前的处理方式。
接下来准备数据和启动内核:
// 2. 准备问题规模和数据
long long M = 256;
long long N = 256;
long long K = 128;// 线性组合标量(C = alpha * A * B + beta * C)
float alpha = 1.0f;
float beta = 0.0f; // 对应C = A * B// 分配主机张量
cutlass::HostTensor<ElementA, LayoutA> tensor_A({M, K});
cutlass::HostTensor<ElementB, LayoutB> tensor_B({K, N});
cutlass::HostTensor<ElementC, LayoutC> tensor_C({M, N});
cutlass::HostTensor<ElementC, LayoutC> tensor_D_ref({M, N}); // CPU参考值// 用随机数据初始化主机张量
cutlass::reference::host::TensorFillRandomUniform(tensor_A.host_data(), tensor_A.layout(), 0, 10);
cutlass::reference::host::TensorFillRandomUniform(tensor_B.host_data(), tensor_B.layout(), 0, 10);
cutlass::reference::host::TensorFillRandomUniform(tensor_C.host_data(), tensor_C.layout(), 0, 0); // 初始化C为零// 将主机张量复制到设备
tensor_A.sync_device();
tensor_B.sync_device();
tensor_C.sync_device();// 3. 创建GEMM参数
typename Gemm::Arguments arguments({M, N, K},tensor_A.device_ref(),tensor_B.device_ref(),tensor_C.device_ref(),tensor_C.device_ref(), // 原地更新C{alpha, beta}
);// 4. 创建并启动GEMM操作
Gemm gemm_op;// 检查当前设备是否支持该内核
cutlass::Status status = gemm_op.initialize(arguments);
if (status != cutlass::Status::kSuccess) {std::cerr << "GEMM初始化失败: " << cutlass::cutlass_get_status_string(status) << std::endl;return 1; // 返回错误
}// 启动内核
status = gemm_op(arguments);
if (status != cutlass::Status::kSuccess) {std::cerr << "GEMM启动失败: " << cutlass::cutlass_get_status_string(status) << std::endl;return 1; // 返回错误
}// 5. 将结果从设备复制回主机
tensor_C.sync_host();// 6. (可选)使用CPU参考值验证结果
cutlass::reference::host::gemm({M, N, K},alpha,tensor_A.host_ref(),tensor_B.host_ref(),beta,tensor_C.host_ref(), // 将输出tensor_C作为输入/输出进行验证tensor_D_ref.host_ref()
);// 'tensor_C'现在保存GPU结果,'tensor_D_ref'保存CPU参考结果
// 可对比两者正确性(比较逻辑省略,但cutlass/util/tensor_compare.h提供工具)
std::cout << "GEMM内核成功启动并获取结果(验证步骤省略)。" << std::endl;
// 实际示例中应添加assert(cutlass::reference::host::TensorEquals(...))
解释:
- 定义维度(M、N、K)和标量乘数(
alpha、beta) cutlass::HostTensor简化了主机(CPU)和设备(GPU)内存管理- 用随机值初始化
A和B,C初始化为零 tensor_A.sync_device()将数据从CPU复制到GPUtypename Gemm::Arguments创建包含内核所需输入指针和问题详情的结构体gemm_op.initialize(arguments)准备执行内核(如计算网格/块维度)gemm_op(arguments)实际在GPU上启动CUDA内核tensor_C.sync_host()将计算结果从GPU复制回CPU- 最后展示如何使用
cutlass的主机端参考GEMM进行CPU端验证
这个简化示例展示了使用cutlass C++ GEMM内核的核心流程:通过模板参数定义具体操作,准备参数,最后启动内核。
运行
code:https://github.com/lvy010/AI-exploration/blob/main/cuda-cutlass/README.md
环境配置
apt install -y nvidia-cuda-toolkit
查看

运行:

底层机制:C++内核架构
这些C++ GEMM内核为何如此高效灵活?cutlass采用高度模块化的分层设计,直接映射GPU架构。
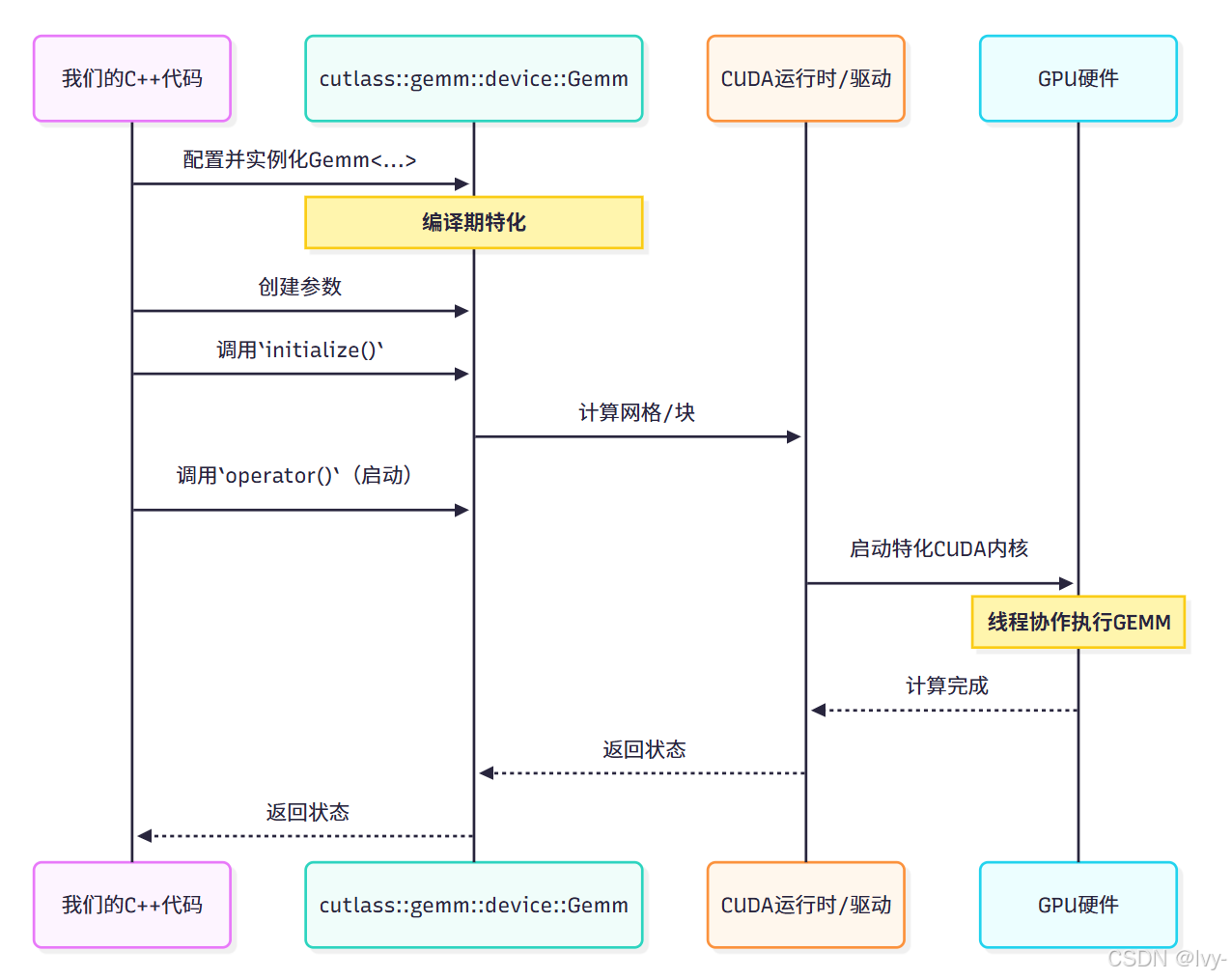
- 编译期特化:
cutlass定义了一个模板,可通过数百种数据类型、分块尺寸和硬件特性组合进行实例化。C++编译器(nvcc)在编译时完成特化,为每个配置生成独特的优化内核。通过查看CHANGELOG.md文件中的"Instruction shapes and redundant accumulation type have been removed from CUTLASS 3.x-style library kernel names to disambiguate kernels and shorten names."等条目,可以看到生成的内核名称示例,如cutlass3x_sm90_tensorop_gemm_bf16_bf16_f32_bf16_bf16_128x256x64_1x1x1_0_tnn_align8_warpspecialized_cooperative_epi_tma - 层次化分解:大型矩阵乘法被分解为可管理的小块:
- 网格:整个问题被划分为"
线程块"(CTAs) - 线程块(CTA)GEMM:每个线程块处理矩阵的一部分,涉及将数据从全局内存加载到快速共享内存,执行warp级GEMM,并将结果写回全局内存。
cutlass提供cutlass/gemm/threadblock/mma.h和cutlass/gemm/threadblock/threadblock_swizzle.h等组件管理这些操作 - Warp GEMM:在每个线程块内,32个线程组成的"warp"协作执行较小矩阵乘法,通常利用Tensor Core。相关抽象定义在
cutlass/gemm/warp/mma.h - MMA(乘加)操作:最底层,单个线程或warp执行原生硬件指令(如Tensor Core的
mma.sync)执行融合乘加操作。这些通过cutlass/arch/mma.h和cutlass/arch/mma_smXY.h(如mma_sm70.h、mma_sm80.h)暴露
- 网格:整个问题被划分为"
- 数据移动流水线:
cutlass编排数据移动以重叠内存访问和计算。大量使用双缓冲(在计算当前数据块时预加载下一块)和异步拷贝(Ampere+ GPU的cp.async)等技术来隐藏延迟 - CuTe C++抽象:如第1章:CuTe DSL所述,
cutlassC++核心使用CuTe C++抽象(核心库)。这些强大的C++模板(cute::Layout、cute::Tensor、cute::TiledCopy、cute::TiledMMA)是cutlass描述数据排列、并行代理和优化操作的基础。CUTLASS 4.x的CHANGELOG.md中提到的CuTe changes: Rewrite ArithTuple and ScaledBasis for robustness and clarity.等变更展示了这些核心组件的演进
C++内核 vs CuTe DSL
对比两种开发方式:
| 特性 | CuTe DSL开发 | 传统cutlass C++内核开发 |
|---|---|---|
| 语法 | Python原生语法,简洁直观 | C++模板,复杂元编程,冗长 |
| 编译时间 | 数量级更快,利用JIT(即时)编译 | 可能非常长,特别是复杂内核和多重实例化时 |
| 原型设计 | 更快原型开发,更直观的实验,易于调试 | 编译-链接周期导致迭代缓慢,调试困难 |
| 抽象层级 | 对CuTe C++抽象的高层Python接口(布局、张量、硬件操作) | 直接使用CuTe C++核心,需要深厚C++功底 |
| 集成 | 原生集成Python深度学习框架(如PyTorch、NumPy) | 需通过C++/Python绑定(如PyTorch C++扩展)集成到Python |
| 目标用户 | 学生、研究人员、性能工程师、Python开发者 | 性能工程师、C++专家 |
| 控制级别 | 高层控制,基于模式生成优化代码 | 终极底层控制,可精细调节每个硬件细节 |
虽然CuTe DSL非常适合无需深厚C++知识即可快速构建和迭代内核,但cutlass C++内核库为需要榨取硬件极限的性能工程师提供了终极灵活性。
(就像内核编写中rust和C语言一样bush)
大多数用户会通过高层框架或CuTe DSL与cutlass交互,但理解C++基础对掌握cutlass能力至关重要。
结论
本章探索了cutlass C++ GEMM内核,将其理解为针对NVIDIA GPU矩阵乘法高度模板化、精心优化的引擎。
我们了解了如何通过丰富的模板参数定义问题,并从C++启动这些内核。更重要的是,我们认识到这些内核底层采用分层设计、高级数据移动策略和强大的CuTe C++抽象(核心库)来实现峰值性能。
现在我们对cutlass GEMM内核有了基本认识,下一章将深入其基础构建模块:CuTe C++抽象(核心库),揭示支撑C++内核和CuTe DSL的强大数据结构和操作。