【完整源码+数据集+部署教程】植物病害检测系统源码和数据集:改进yolo11-MultiSEAMHead
背景意义
研究背景与意义
植物病害的早期检测与诊断对于农业生产的可持续发展至关重要。随着全球气候变化和农业生产方式的转变,植物病害的种类和传播速度日益增加,给农作物的产量和质量带来了严重威胁。因此,开发高效、准确的植物病害检测系统显得尤为重要。传统的人工检测方法不仅耗时耗力,而且容易受到主观因素的影响,难以保证检测结果的准确性和一致性。近年来,计算机视觉和深度学习技术的快速发展为植物病害的自动检测提供了新的解决方案。
本研究基于改进的YOLOv11模型,旨在构建一个高效的植物病害检测系统。该系统将利用一个包含4100张图像的多类别数据集,涵盖10种不同的植物病害和健康状态,包括苹果黑腐病、樱桃粉霉病、葡萄黑腐病等。这些类别的选择不仅反映了当前农业生产中常见的病害类型,也为模型的训练提供了丰富的样本,增强了其泛化能力。通过对这些图像进行实例分割处理,系统能够更精确地识别和定位病害区域,从而为农民提供及时的预警和指导。
此外,基于YOLOv11的改进算法将进一步提升检测的速度和准确性,使得该系统能够在实际应用中实现实时监测。这一研究不仅具有重要的理论意义,也为农业生产实践提供了切实可行的技术支持。通过有效的病害检测,农民可以更好地管理作物,减少化学药剂的使用,从而实现生态农业的目标,促进农业的可持续发展。
图片效果
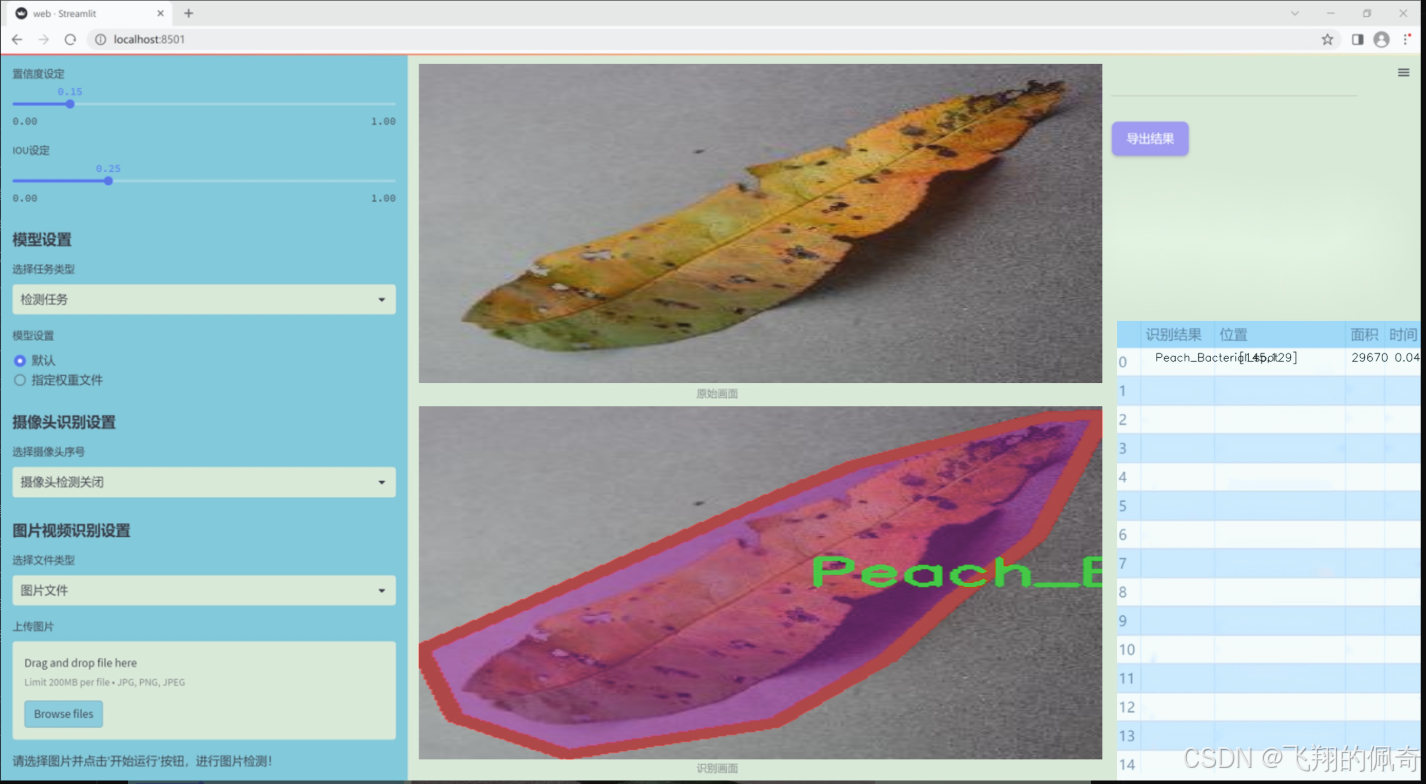
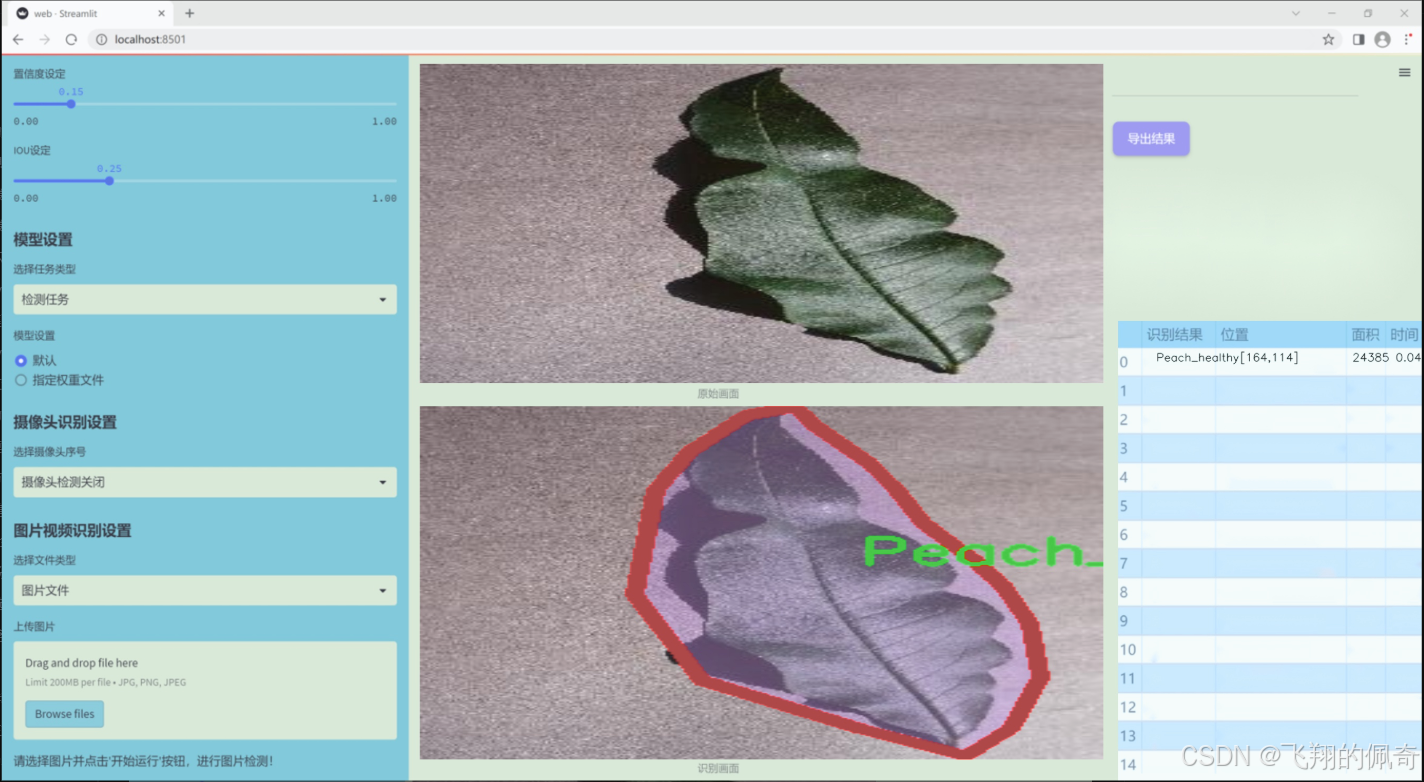
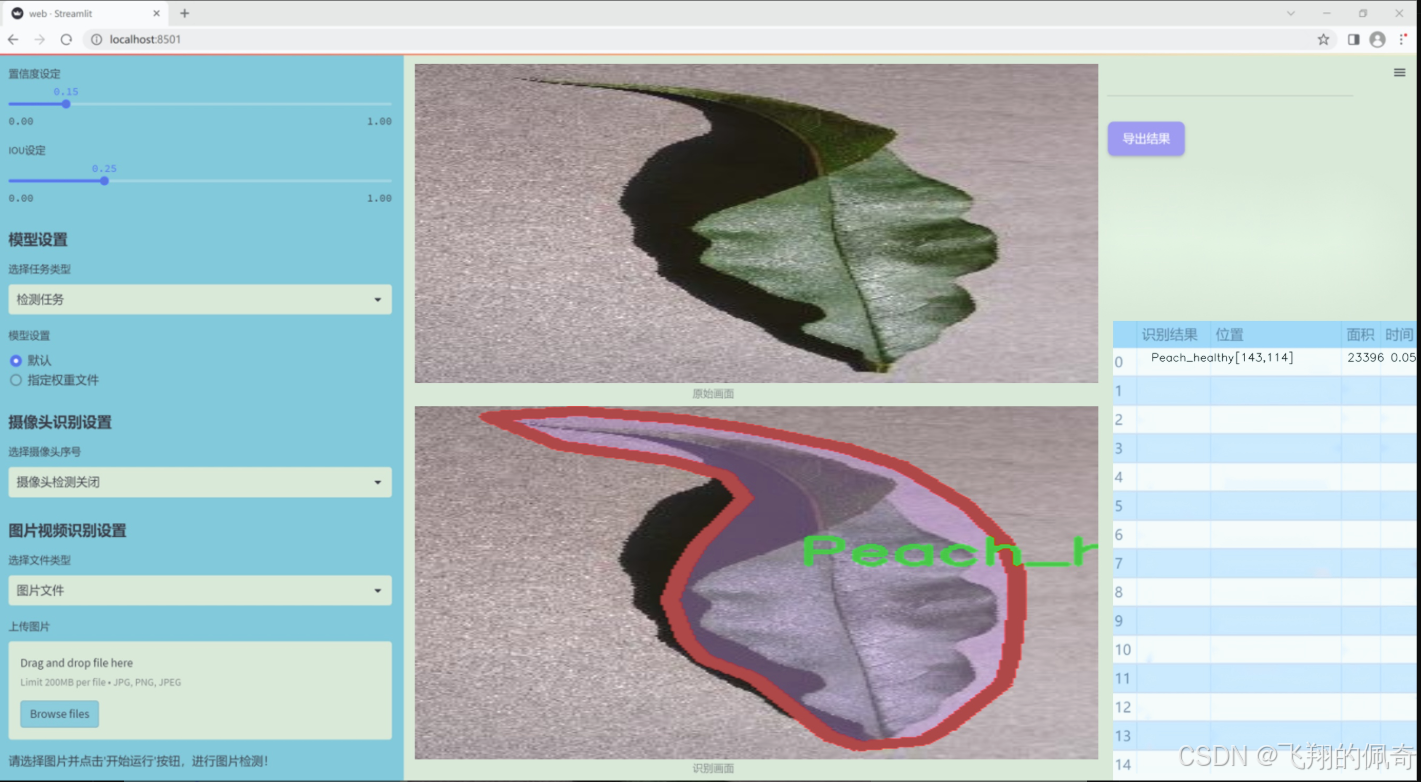
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“plantVillagedeneme”,其主要目标是为改进YOLOv11的植物病害检测系统提供支持。该数据集包含了10个不同的类别,专注于多种植物病害的识别与分类。这些类别包括:苹果黑腐病(Apple_black_rot)、健康苹果(Apple_healthy)、雪松苹果锈病(Cedar_apple_rust)、樱桃粉霉病(Cherry_Powdery_mildew)、健康樱桃(Cherry_healthy)、葡萄黑腐病(Grape_Black_rot)、健康葡萄(Grape_healthy)、桃子细菌性斑点病(Peach_Bacterial_spot)、健康桃子(Peach_healthy)以及土豆早疫病(Potato_Early_blight)。
数据集的多样性使其在植物病害检测领域具有重要的应用价值。每个类别均包含大量的样本图像,这些图像经过精心标注,确保在训练过程中能够有效地提升模型的识别能力。通过对不同植物及其病害的深入学习,YOLOv11模型能够在实际应用中实现高效、准确的病害检测,进而为农业生产提供科学依据和技术支持。
在数据集的构建过程中,研究团队注重图像的多样性和代表性,确保涵盖不同生长阶段、不同环境条件下的植物样本。这种全面的覆盖不仅提高了模型的泛化能力,也增强了其在实际应用中的可靠性。此外,数据集的设计考虑到了不同病害的表现特征,使得模型能够更好地识别和区分相似症状的不同病害,为农民和农业专家提供更为精准的诊断工具。
总之,“plantVillagedeneme”数据集为改进YOLOv11的植物病害检测系统奠定了坚实的基础,期待通过这一项目的实施,能够在植物保护和农业可持续发展方面发挥积极作用。




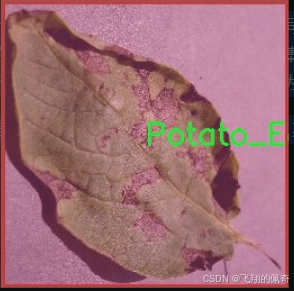
核心代码
以下是经过简化和注释的核心代码部分,主要集中在 DiverseBranchBlock 类及其相关功能上:
import torch
import torch.nn as nn
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
“”"
将卷积核和批归一化层的参数融合
:param kernel: 卷积核
:param bn: 批归一化层
:return: 融合后的卷积核和偏置
“”"
gamma = bn.weight # 获取缩放因子
std = (bn.running_var + bn.eps).sqrt() # 计算标准差
# 融合卷积核和批归一化
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
class DiverseBranchBlock(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=None, dilation=1, groups=1):
“”"
多分支卷积块的初始化
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: 卷积核大小
:param stride: 步幅
:param padding: 填充
:param dilation: 膨胀
:param groups: 分组卷积的组数
“”"
super(DiverseBranchBlock, self).init()
# 计算填充if padding is None:padding = kernel_size // 2 # 默认填充为卷积核大小的一半assert padding == kernel_size // 2# 定义主卷积和批归一化层self.dbb_origin = self.conv_bn(in_channels, out_channels, kernel_size, stride, padding, dilation, groups)# 定义其他分支(1x1卷积、平均池化等)self.dbb_avg = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels),nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))# 1x1卷积层self.dbb_1x1_kxk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels))def conv_bn(self, in_channels, out_channels, kernel_size, stride, padding, dilation, groups):"""创建卷积层和批归一化层的组合:param in_channels: 输入通道数:param out_channels: 输出通道数:param kernel_size: 卷积核大小:param stride: 步幅:param padding: 填充:param dilation: 膨胀:param groups: 分组卷积的组数:return: 包含卷积和批归一化的序列"""conv_layer = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False)bn_layer = nn.BatchNorm2d(out_channels)return nn.Sequential(conv_layer, bn_layer)def forward(self, inputs):"""前向传播:param inputs: 输入数据:return: 输出数据"""out = self.dbb_origin(inputs) # 主卷积输出out += self.dbb_avg(inputs) # 加上平均池化输出out += self.dbb_1x1_kxk(inputs) # 加上1x1卷积输出return out # 返回最终输出
代码说明:
transI_fusebn: 该函数用于将卷积层和批归一化层的参数融合,返回融合后的卷积核和偏置。
DiverseBranchBlock: 这是一个多分支卷积块的实现,包含多个卷积分支。
构造函数 (init): 初始化输入输出通道、卷积核大小、步幅、填充等参数,并定义主卷积层和其他分支。
conv_bn: 创建一个卷积层和批归一化层的组合。
forward: 定义前向传播过程,计算各个分支的输出并相加。
这个简化版本保留了主要的结构和功能,适合于理解多分支卷积块的实现。
这个程序文件 rep_block.py 定义了一些用于构建深度学习模型的模块,主要集中在不同类型的卷积块上。这些卷积块被设计为可以在不同的配置下使用,以提高模型的灵活性和性能。以下是对文件中主要内容的说明。
首先,文件导入了必要的库,包括 PyTorch 和 NumPy。接着,定义了一些用于卷积和批归一化的转换函数。这些函数主要用于将卷积层和批归一化层的权重和偏置进行融合,以便在模型部署时减少计算量。
接下来,定义了几个类,分别实现了不同类型的卷积块:
IdentityBasedConv1x1:这个类实现了一个带有身份映射的 1x1 卷积层。它的权重初始化为零,并通过添加一个身份张量来实现身份映射。这个设计可以在某些情况下提高模型的表达能力。
BNAndPadLayer:这个类结合了批归一化和填充操作。它在进行批归一化后,如果需要,还会对输出进行填充,以保持特征图的尺寸。
DiverseBranchBlock:这是一个复杂的卷积块,包含多个分支。它使用了不同的卷积操作(如 1x1 卷积、3x3 卷积和平均池化),并将它们的输出相加。这个设计使得模型能够学习到多种特征表示。
DiverseBranchBlockNOAct:这个类与 DiverseBranchBlock 类似,但没有非线性激活函数的应用,适用于某些特定的模型结构。
DeepDiverseBranchBlock:这个类扩展了 DiverseBranchBlock,增加了深度学习的能力,允许使用更复杂的结构来提取特征。
WideDiverseBranchBlock:这个类进一步扩展了卷积块的功能,增加了水平和垂直卷积操作,旨在提高模型对不同方向特征的学习能力。
每个卷积块类都实现了前向传播方法 forward,用于计算输入数据的输出。此外,类中还包含了一些初始化方法和参数设置方法,以便在训练和部署阶段使用。
总体而言,这个文件提供了一种灵活的方式来构建深度学习模型的卷积块,支持多种配置和优化策略,以适应不同的任务需求。
10.4 orepa.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
定义一个OREPA模块,继承自nn.Module
class OREPA(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, dilation=1, act=True):
super(OREPA, self).init()
# 初始化参数self.in_channels = in_channelsself.out_channels = out_channelsself.kernel_size = kernel_sizeself.stride = strideself.groups = groupsself.dilation = dilation# 激活函数的选择self.nonlinear = nn.ReLU() if act else nn.Identity()# 权重初始化self.weight_orepa_origin = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, kernel_size, kernel_size))nn.init.kaiming_uniform_(self.weight_orepa_origin, a=0.0)# 扩展卷积的权重self.weight_orepa_avg_conv = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, 1, 1))nn.init.kaiming_uniform_(self.weight_orepa_avg_conv, a=0.0)# 1x1卷积的权重self.weight_orepa_1x1 = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, 1, 1))nn.init.kaiming_uniform_(self.weight_orepa_1x1, a=0.0)# 初始化向量,用于加权不同分支的输出self.vector = nn.Parameter(torch.Tensor(3, out_channels))nn.init.constant_(self.vector[0, :], 1.0) # originnn.init.constant_(self.vector[1, :], 0.0) # avgnn.init.constant_(self.vector[2, :], 0.0) # 1x1def weight_gen(self):# 生成加权后的卷积核weight_orepa_origin = self.weight_orepa_origin * self.vector[0, :].view(-1, 1, 1, 1)weight_orepa_avg = self.weight_orepa_avg_conv * self.vector[1, :].view(-1, 1, 1, 1)weight_orepa_1x1 = self.weight_orepa_1x1 * self.vector[2, :].view(-1, 1, 1, 1)# 返回加权后的卷积核return weight_orepa_origin + weight_orepa_avg + weight_orepa_1x1def forward(self, inputs):# 生成卷积核weight = self.weight_gen()# 进行卷积操作out = F.conv2d(inputs, weight, stride=self.stride, padding=self.kernel_size // 2, dilation=self.dilation, groups=self.groups)# 返回经过激活函数处理的输出return self.nonlinear(out)
定义一个卷积层与批归一化结合的模块
class ConvBN(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1):
super().init()
# 定义卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False)
# 定义批归一化层
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):# 先进行卷积,再进行批归一化return self.bn(self.conv(x))
定义一个RepVGG模块
class RepVGGBlock_OREPA(nn.Module):
def init(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, act=True):
super(RepVGGBlock_OREPA, self).init()
# 初始化参数self.in_channels = in_channelsself.out_channels = out_channelsself.groups = groups# 定义卷积层self.rbr_dense = OREPA(in_channels, out_channels, kernel_size=kernel_size, stride=stride, groups=groups)self.rbr_1x1 = ConvBN(in_channels, out_channels, kernel_size=1, stride=stride, groups=groups)def forward(self, inputs):# 计算不同分支的输出out1 = self.rbr_dense(inputs)out2 = self.rbr_1x1(inputs)# 返回加和后的输出return out1 + out2
代码核心部分解释:
OREPA模块:这是一个自定义的卷积模块,使用了多种卷积核的组合(如3x3卷积、1x1卷积等),并通过一个向量来加权不同分支的输出。
权重生成:weight_gen方法负责生成加权后的卷积核,结合了不同分支的权重。
前向传播:在forward方法中,输入通过生成的卷积核进行卷积操作,并通过激活函数进行处理。
ConvBN模块:结合了卷积和批归一化的模块,便于构建深度网络。
RepVGGBlock_OREPA模块:使用OREPA和ConvBN组合构建的块,支持不同的输入输出通道。
这些模块的设计使得在构建深度学习模型时,可以灵活地使用不同的卷积结构和激活函数,同时保持高效的计算性能。
这个程序文件 orepa.py 实现了一个名为 OREPA 的深度学习模块,主要用于卷积神经网络中的卷积操作。它包含多个类和函数,旨在提供高效的卷积操作,同时支持模型的部署和权重的重参数化。
首先,文件导入了必要的库,包括 PyTorch、NumPy 以及一些自定义的模块。all 列表定义了该模块中可以被外部导入的类。
接下来,定义了一些辅助函数,例如 transI_fusebn 和 transVI_multiscale,这些函数用于处理卷积核和批归一化层的融合,以及对卷积核进行多尺度填充。
OREPA 类是该文件的核心部分,继承自 nn.Module。在其构造函数中,初始化了输入和输出通道、卷积核大小、步幅、填充、分组、扩张等参数。根据是否处于部署模式,初始化不同的卷积层和参数。它使用了多个卷积分支来生成最终的卷积权重,包括原始卷积、平均卷积、深度可分离卷积等。权重生成的逻辑在 weight_gen 方法中实现,通过张量运算组合不同分支的权重。
OREPA_LargeConv 类实现了一个大型卷积层,支持多层的 OREPA 结构。它的构造函数中同样初始化了卷积参数,并在 weight_gen 方法中生成权重。
ConvBN 类则是一个简单的卷积层与批归一化层的组合,支持在部署模式下直接使用融合后的卷积层。
OREPA_3x3_RepVGG 类实现了一个特定的卷积块,支持不同的卷积分支,并可以选择性地使用 Squeeze-and-Excitation (SE) 注意力机制。
最后,RepVGGBlock_OREPA 类是一个更高层次的模块,组合了多个 OREPA 结构和 1x1 卷积,提供了更复杂的特征提取能力。它支持在部署模式下使用融合后的卷积层,并实现了前向传播和权重融合的逻辑。
整体来看,这个文件提供了一种灵活的卷积实现方式,支持多种结构和配置,适用于需要高效卷积操作的深度学习任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻