基于深度学习的nlp
目录
一、背景
二、有监督学习与前馈神经网络
三、处理自然语言数据
1、常见预处理步骤
2、可观测特征
四、网络结构设计
1、卷积
2、循环神经网络
3、长短期记忆网络-LSTM
4、一些实例
(1)情感分类器
(2)词性标注
(3)弧分解依存句法分析
一、背景

-
基于规则(Rule-based)
依赖专家手工编写语法与词典规则,缺乏扩展性。 -
统计学习(Statistical NLP)
使用n-gram、HMM等概率模型进行建模,需要大量特征工程。 -
深度学习驱动(Deep Learning NLP)
利用神经网络自动学习语言表示,实现端到端训练,显著提升任务表现。
里程碑事件
2013:Word2Vec 提出,词向量革命开启。
2017:Transformer发布,取代RNN成为主流。
2018+:BERT、GPT等预训练模型席卷NLP领域。
二、有监督学习与前馈神经网络
在NLP中,许多任务可转化为有监督分类问题,例如:
-
情感分析(positive / negative)
-
新闻分类(体育 / 财经 / 娱乐)
-
意图识别(查询天气 / 订票)
有监督学习流程
-
数据准备:收集标注样本(文本 + 标签)
-
特征表示:将文本转化为向量(One-hot、词向量、BERT embedding)
-
模型训练:利用训练集优化神经网络参数
-
模型评估:在测试集上计算准确率、F1分数等
一些实践经验


三、处理自然语言数据
深度学习的输入必须是数值张量,因此NLP的第一步是文本数字化。
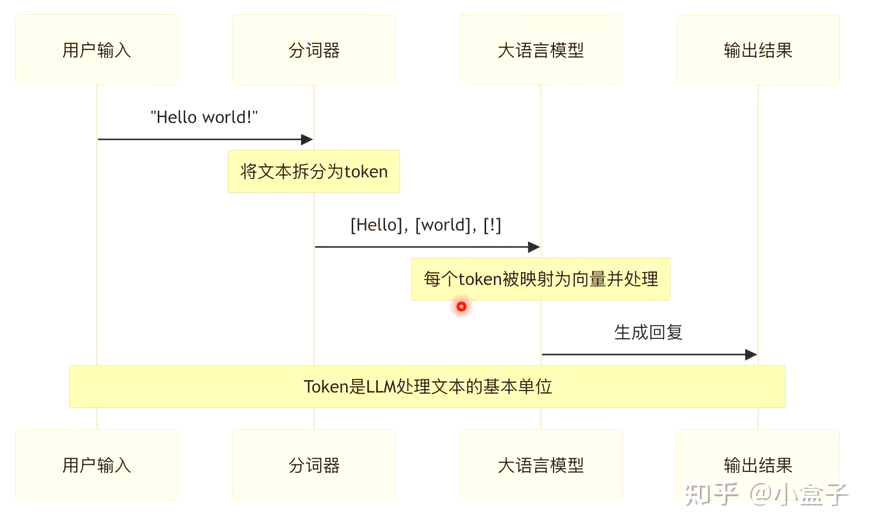
1、常见预处理步骤






-
分词(Tokenization)

-
去除噪声
移除HTML标签、特殊字符、停用词 -
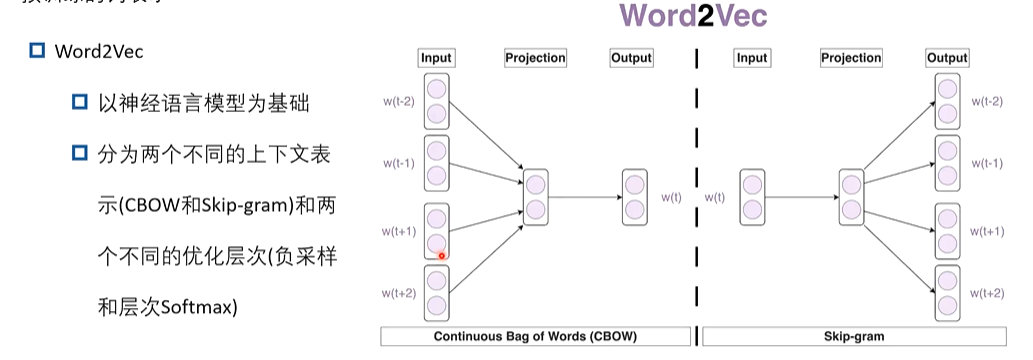
向量化表示:One-hot:稀疏且维度高;词向量(Word2Vec、GloVe):稠密低维,捕捉语义;上下文向量(ELMo、BERT):根据上下文动态生成
-
序列对齐与填充(Padding):将不同长度文本补齐到统一长度
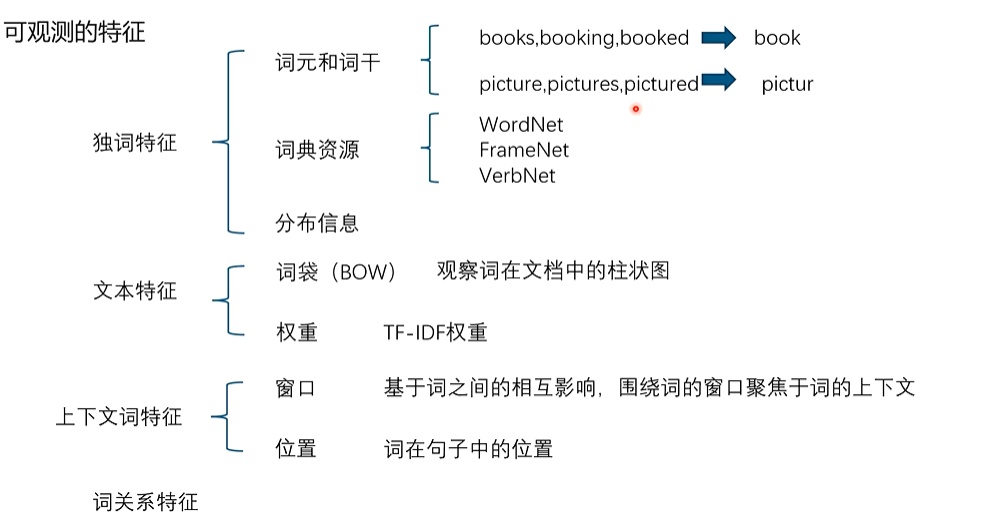
2、可观测特征
-
独词特征
-
词元和词干:例如
books, booking, booked → book,picture, pictures, pictured → pictur(通过词干提取减少词形变化带来的冗余)。 -
词典资源:如 WordNet、FrameNet、VerbNet 提供的语义、同义词、上下位词等知识。
-
分布信息:统计词在不同语境中的出现规律。
-
-
文本特征
-
词袋模型(BOW):将文本表示为词频直方图,不考虑词序。
-
权重:如 TF-IDF,用于衡量某个词对区分文本的重要性。
-
-
上下文词特征
-
窗口:基于相邻词的上下文关系,例如固定大小的窗口聚焦中心词周围的词。
-
位置:记录词在句子或文本中的具体位置。
-
-
词关系特征
-
不仅关注词自身,还研究词与词之间的依存、共现等关系。
-
四、网络结构设计
1、卷积
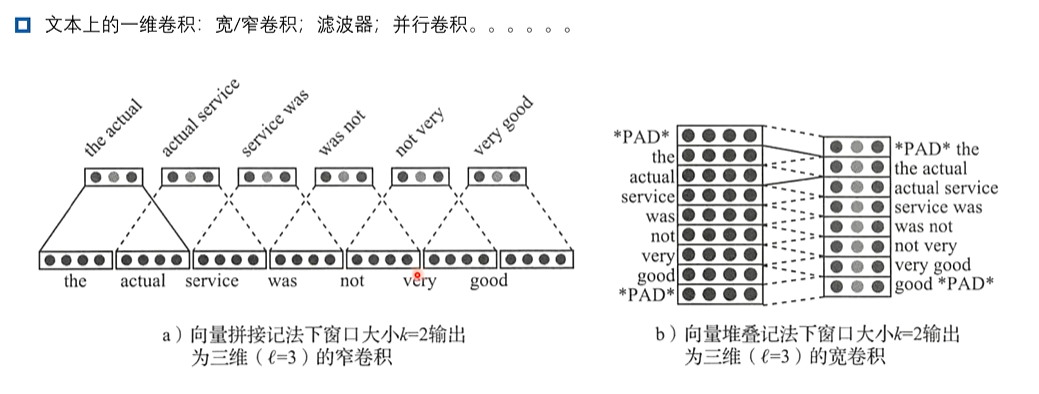
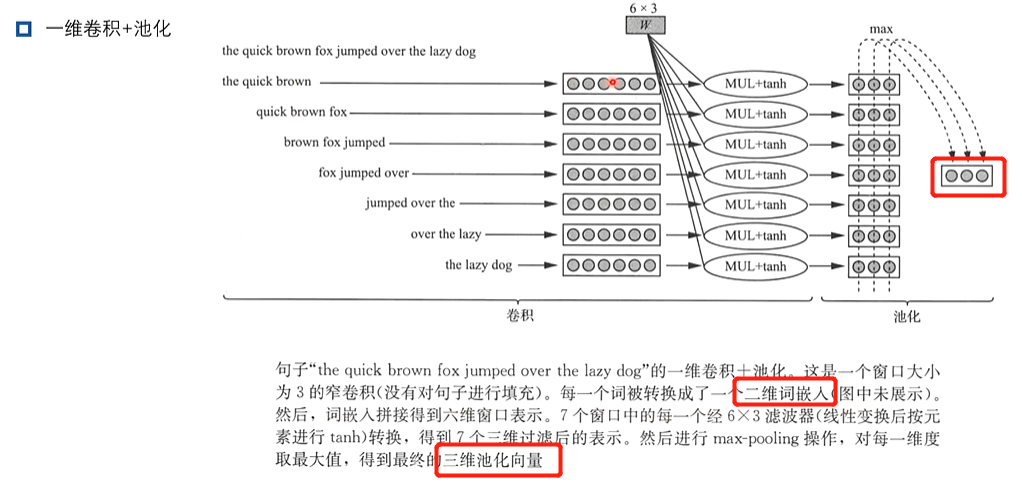
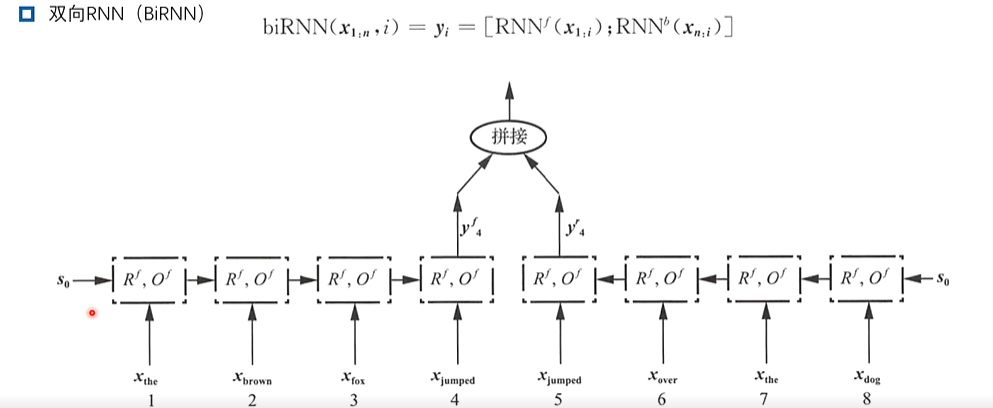
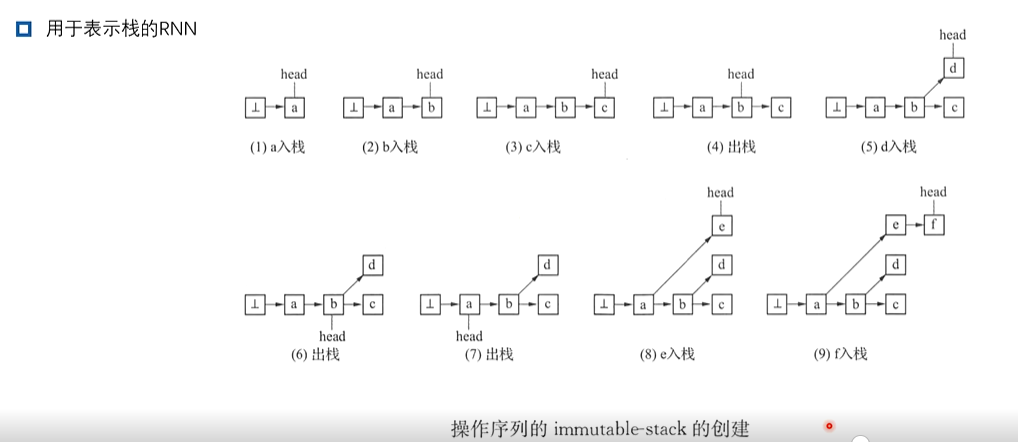
2、循环神经网络
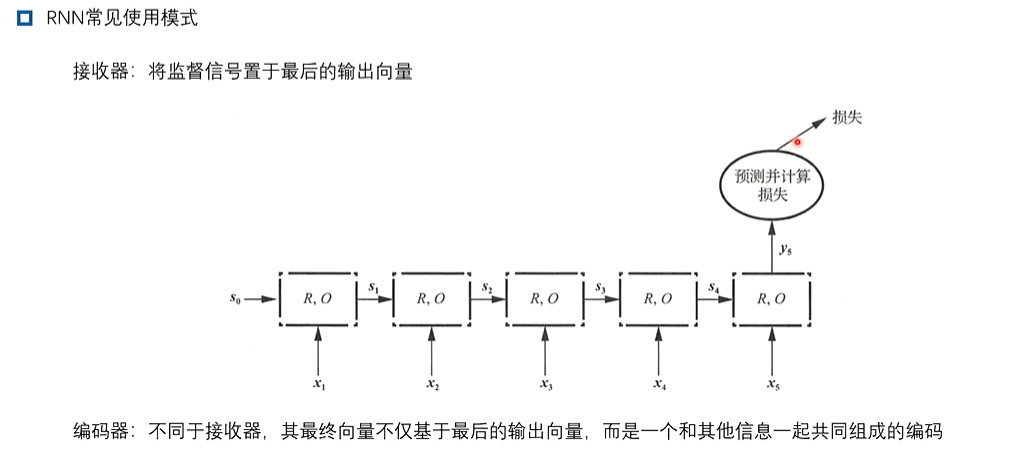
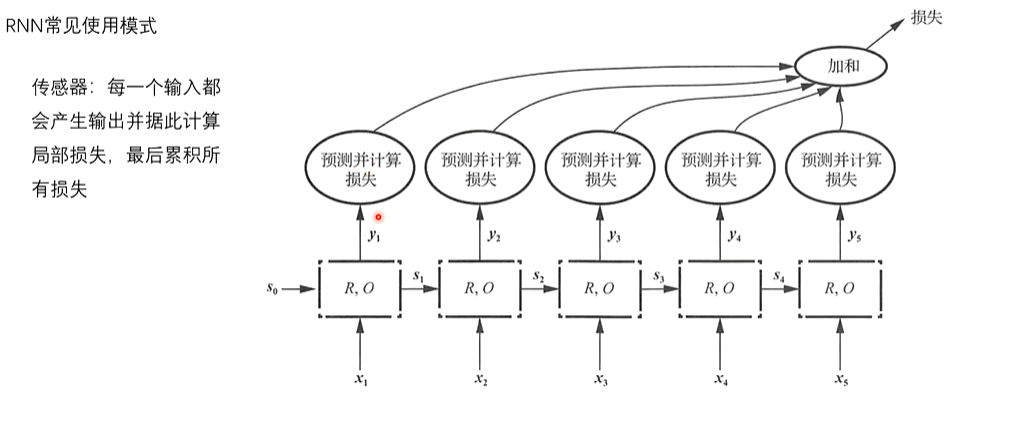
3、长短期记忆网络-LSTM
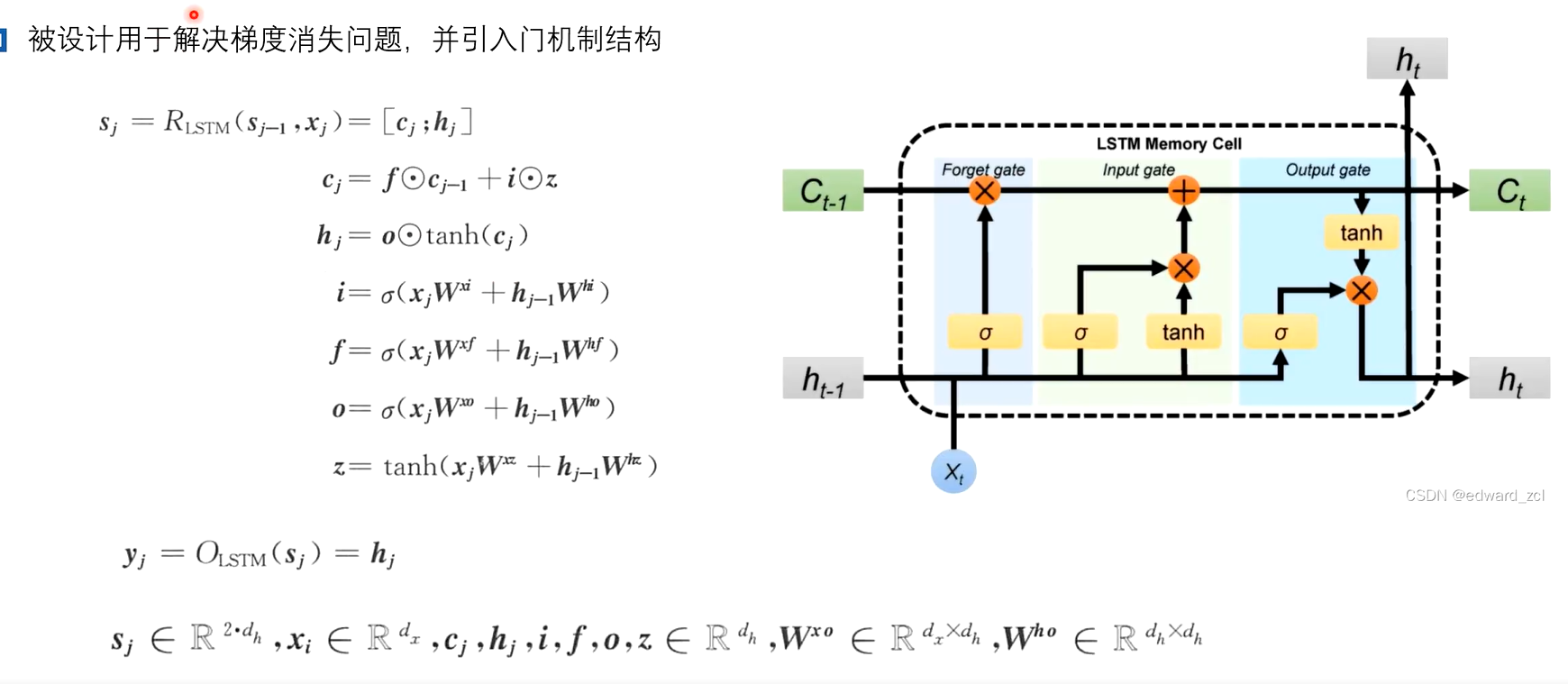
4、一些实例
(1)情感分类器

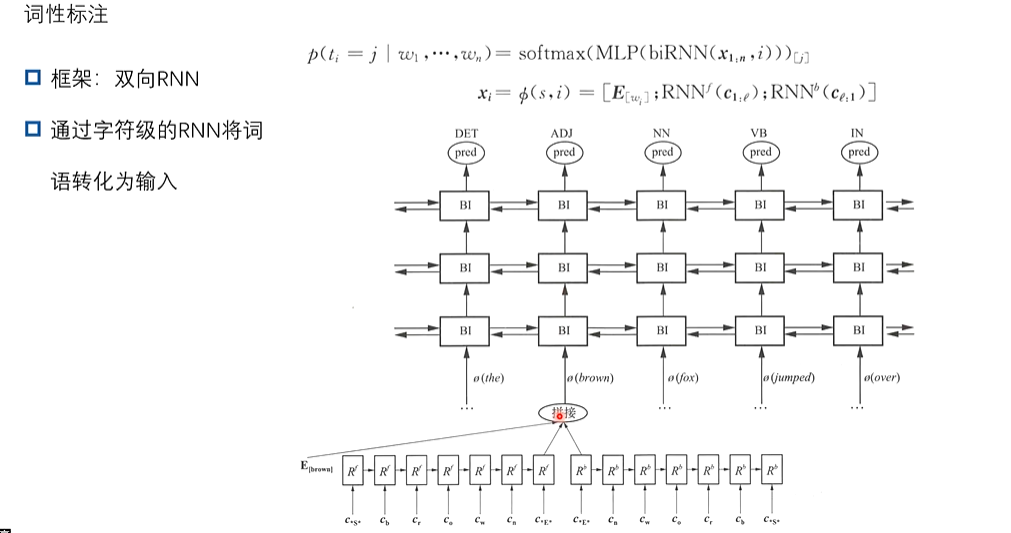
(2)词性标注
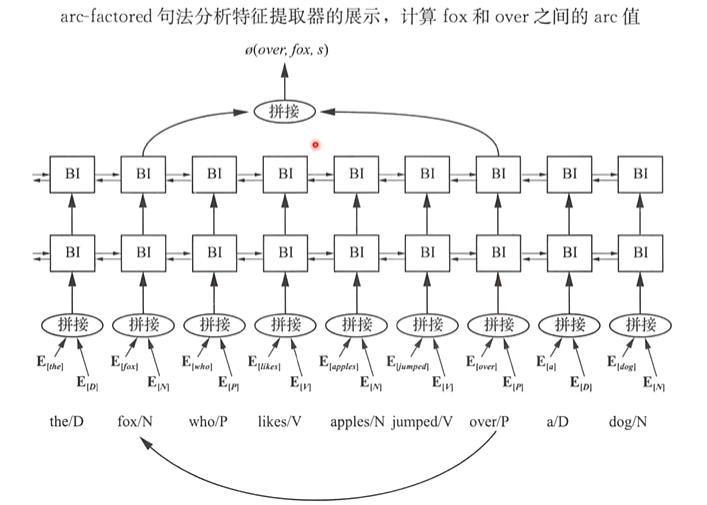
(3)弧分解依存句法分析