通过上下文工程优化LangChain AI Agents(二)
目录
LangGraph BigTool调用的优势
结合上下文工程的RAG
具有知识的Agents的压缩策略
使用子Agents架构隔离上下文
使用沙盒环境进行隔离
LangGraph中的状态隔离
总结所有内容
LangGraph BigTool调用的优势
Agents会使用工具,但给它们太多工具可能会造成混淆,尤其是当工具描述存在重叠时。这会让模型更难选择合适的工具。
一种解决方案是对工具描述使用RAG(检索增强生成),基于语义相似性获取最相关的工具——Drew Breunig将这种方法称为“工具配备(tool loadout)”。
根据最新研究,这种方法能将工具选择的准确率提高多达3倍。
在工具选择方面,LangGraph Bigtool库是理想之选。它通过对工具描述进行语义相似性搜索,为任务选择最相关的工具。它利用LangGraph的长期记忆存储,使agents能够搜索并检索解决特定问题的合适工具。
让我们通过一个包含Python内置math库所有函数的agent来理解langgraph-bigtool。
import math# 从内置`math`库收集函数
all_tools = []
for function_name in dir(math):function = getattr(math, function_name)if not isinstance(function, types.BuiltinFunctionType):continue# 这是`math`库的一个特性if tool := convert_positional_only_function_to_tool(function):all_tools.append(tool)我们首先将Python math模块中的所有函数添加到一个列表中。接下来,我们需要将这些工具描述转换为向量嵌入,以便agent能够执行语义相似性搜索。
为此,我们将使用一个嵌入模型——这里我们选择OpenAI的text-embedding模型。
# 创建工具注册表。这是一个将标识符映射到工具实例的字典。
tool_registry = {str(uuid.uuid4()): toolfor tool in all_tools
}# 在LangGraph存储中索引工具名称和描述。这里我们使用一个简单的内存存储。
embeddings = init_embeddings("openai:text-embedding-3-small")store = InMemoryStore(index={"embed": embeddings,"dims": 1536,"fields": ["description"],}
)
for tool_id, tool in tool_registry.items():store.put(("tools",),tool_id,{"description": f"{tool.name}: {tool.description}",},)每个函数都被分配一个唯一ID,我们将这些函数组织成适当的标准化格式。这种结构化格式确保函数可以轻松转换为嵌入,用于语义搜索。
现在,让我们可视化这个agent,看看嵌入所有数学函数并准备好进行语义搜索后它的样子!
# 初始化agent
builder = create_agent(llm, tool_registry)
agent = builder.compile(store=store)
agent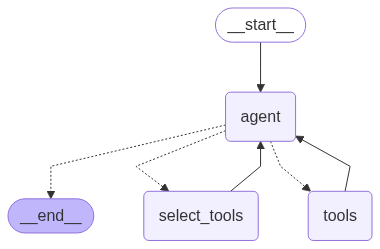
我们的工具Agent
现在,我们可以用一个简单的查询调用agent,观察我们的工具调用型agent如何选择和使用最相关的数学函数来回答问题。
# 导入一个用于格式化和显示消息的工具函数
from utils import format_messages# 定义给agent的查询。
# 这个查询要求agent使用其数学工具之一来计算反余弦。
query = "Use available tools to calculate arc cosine of 0.5."# 用查询调用agent。agent将搜索其工具,
# 根据查询的语义选择'acos'工具并执行它。
result = agent.invoke({"messages": query})# 格式化并显示agent执行后的最终消息。
format_messages(result['messages'])┌────────────── 人类 ───────────────┐
│ 使用可用工具计算0.5的反余弦。 │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 我将搜索用于计算0.5反余弦的工具。 │
│ │
│ 🔧 工具调用:retrieve_tools │
│ 参数:{ │
│ "query": "arc cosine arccos │
│ inverse cosine trig" │
│ } │
└──────────────────────────────────────┘
┌────────────── 🔧 工具输出 ────────┐
│ 可用工具:['acos', 'acosh'] │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 太好了!我找到了acos函数,它可以计算反余弦。│
│ 现在我将用它来计算0.5的反余弦。 │
│ │
│ 🔧 工具调用:acos │
│ 参数:{ "x": 0.5 } │
└──────────────────────────────────────┘
┌────────────── 🔧 工具输出 ────────┐
│ 1.0471975511965976 │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 0.5的反余弦约为**1.047**弧度。 │
│ │
│ ✔ 验证:cos(π/3)=0.5,π/3≈1.047弧度 │
│(60°)。 │
└──────────────────────────────────────┘
可以看到,我们的AI agent能高效调用正确的工具。你可以选择了解更多相关内容:
Toolshed:介绍了Toolshed知识库和高级RAG-工具融合技术,以改进AI agents中的工具选择。
Graph RAG-Tool Fusion:结合向量检索和图遍历,捕捉工具依赖关系。
LLM-Tool-Survey:关于LLM工具学习的综合调查。
ToolRet:用于评估和改进LLM中工具检索的基准。
带有上下文工程的RAG
RAG(检索增强生成,Retrieval-Augmented Generation)是一个广泛的话题,而代码Agent是生产环境中具有Agent特性的RAG的最佳示例之一。
在实践中,RAG通常是上下文工程的核心挑战。正如Windsurf的Varun所指出的:
索引≠上下文检索。结合基于AST的分块进行嵌入搜索是有效的,但随着代码库的增长,这种方法会失效。我们需要混合检索:grep/文件搜索、知识图谱链接以及基于相关性的重排序。
LangGraph提供了教程和视频,帮助将RAG集成到Agent中。通常,你会构建一个检索工具,该工具可以结合使用上述任何RAG技术。
为了进行演示,我们将使用Lilian Weng优秀博客中最新的三个页面,为我们的RAG系统获取文档。
我们将首先使用WebBaseLoader工具提取页面内容。
# 导入WebBaseLoader以从URL获取文档
from langchain_community.document_loaders import WebBaseLoader# 定义Lilian Weng博客文章的URL列表
urls = ["https://lilianweng.github.io/posts/2025-05-01-thinking/","https://lilianweng.github.io/posts/2024-11-28-reward-hacking/","https://lilianweng.github.io/posts/2024-07-07-hallucination/","https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",
]# 使用列表推导式从指定URL加载文档。
# 这会为每个URL创建一个WebBaseLoader并调用其load()方法。
docs = [WebBaseLoader(url).load() for url in urls]为RAG分块数据有多种方法,而适当的分块对于有效的检索至关重要。
在这里,我们将在将获取的文档索引到向量存储之前,将其拆分为更小的块。我们将使用一种简单直接的方法,例如带有重叠段的递归分块,以在块之间保留上下文,同时使它们便于嵌入和检索。
# 导入用于文档分块的文本分割器
from langchain_text_splitters import RecursiveCharacterTextSplitter# 展平文档列表。WebBaseLoader为每个URL返回一个文档列表,
# 因此我们得到的是一个列表的列表。这个推导式将它们合并为一个单一的列表。
docs_list = [item for sublist in docs for item in sublist]# 初始化文本分割器。这将把文档分割成指定大小的更小块,
# 块之间有一些重叠以保持上下文。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=2000, chunk_overlap=50
)# 将文档分割成块。
doc_splits = text_splitter.split_documents(docs_list)现在我们有了分割后的文档,我们可以将它们索引到向量存储中,用于语义搜索。
# 导入用于创建内存向量存储的必要类
from langchain_core.vectorstores import InMemoryVectorStore# 从文档块创建内存向量存储。
# 这使用前面步骤中创建的'doc_splits'和之前初始化的'embeddings'模型
# 来创建文本块的向量表示。
vectorstore = InMemoryVectorStore.from_documents(documents=doc_splits, embedding=embeddings
)# 从向量存储创建检索器。
# 检索器提供了一个接口,可基于查询搜索相关文档。
retriever = vectorstore.as_retriever()我们必须创建一个可在我们的Agent中使用的检索工具。
# 导入用于创建检索工具的函数
from langchain.tools.retriever import create_retriever_tool# 从向量存储检索器创建检索工具。
# 该工具允许Agent基于查询从博客文章中搜索并检索相关文档。
retriever_tool = create_retriever_tool(retriever,"retrieve_blog_posts","搜索并返回有关Lilian Weng博客文章的信息。",
)# 以下行是直接调用工具的示例。
# 它被注释掉是因为在Agent执行流程中不需要,但可能对测试有用。
# retriever_tool.invoke({"query": "types of reward hacking"})现在,我们可以实现一个能够从工具中选择上下文的Agent。
# 为LLM配备工具
tools = [retriever_tool]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)对于基于RAG的解决方案,我们需要创建一个清晰的系统提示来指导Agent的行为。这个提示充当其核心指令集。
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, ToolMessage
from typing_extensions import Literalrag_prompt = """你是一个 helpful 的助手,负责从Lilian Weng的一系列技术博客文章中检索信息。
在使用检索工具收集上下文之前,与用户明确研究范围。思考你获取的任何上下文,
并继续直到你有足够的上下文来回答用户的研究请求。"""接下来,我们定义图的节点。我们需要两个主要节点:
llm_call:这是我们Agent的“大脑”。它接收当前的对话历史(用户查询+之前的工具输出)。然后决定下一步:调用工具或生成最终答案。
tool_node:这是Agent的“行动”部分。它执行llm_call请求的工具调用。将工具的结果返回给Agent。
# --- 定义Agent节点 ---def llm_call(state: MessagesState):"""LLM决定是调用工具还是生成最终答案。"""# 将系统提示添加到当前消息状态messages_with_prompt = [SystemMessage(content=rag_prompt)] + state["messages"]# 用增强的消息列表调用LLMresponse = llm_with_tools.invoke(messages_with_prompt)# 返回LLM的响应以添加到状态中return {"messages": [response]}def tool_node(state: dict):"""执行工具调用并返回观察结果。"""# 获取最后一条消息,其中应该包含工具调用last_message = state["messages"][-1]# 执行每个工具调用并收集结果result = []for tool_call in last_message.tool_calls:tool = tools_by_name[tool_call["name"]]observation = tool.invoke(tool_call["args"])result.append(ToolMessage(content=str(observation), tool_call_id=tool_call["id"]))# 将工具的输出作为消息返回return {"messages": result}我们需要一种方法来控制Agent的流程,决定它应该调用工具还是已经完成。
为了处理这一点,我们将创建一个名为should_continue的条件边函数。
该函数检查LLM的最后一条消息是否包含工具调用。
如果包含,图将路由到tool_node。
如果不包含,执行结束。
# --- 定义条件边 ---def should_continue(state: MessagesState) -> Literal["Action", END]:"""根据LLM是否进行了工具调用来决定下一步。"""last_message = state["messages"][-1]# 如果LLM进行了工具调用,路由到tool_nodeif last_message.tool_calls:return "Action"# 否则,结束工作流return END现在我们可以简单地构建工作流并编译图。
# 构建工作流
agent_builder = StateGraph(MessagesState)# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("environment", tool_node)# 添加边以连接节点
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges("llm_call",should_continue,{# should_continue返回的名称:下一个要访问的节点的名称"Action": "environment",END: END,},
)
agent_builder.add_edge("environment", "llm_call")# 编译Agent
agent = agent_builder.compile()# 显示Agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))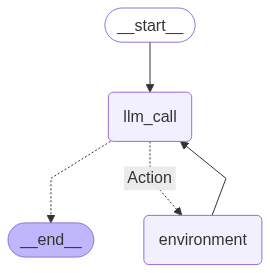
基于RAG的Agent
该图显示了一个清晰的循环:
Agent启动,调用LLM。
根据LLM的决定,它要么执行一个动作(调用我们的检索工具)并循环回来,要么完成并提供答案。
让我们测试我们的RAG Agent。我们将向它询问一个关于“reward hacking”的具体问题,这个问题只能通过检索我们索引的博客文章中的信息来回答。
# 定义用户的查询
query = "博客中讨论了哪些类型的reward hacking?"# 用查询调用Agent
result = agent.invoke({"messages": [("user", query)]})# --- 显示最终消息 ---
# 格式化并打印对话流程
format_messages(result['messages'])┌────────────── 人类 ───────────────┐
│ 明确范围:我想了解Lilian Weng关于强化学习博客中提到的reward hacking类型。 │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 正在从她的文章中获取上下文... │
└──────────────────────────────────────┘
┌────────────── 🔧 工具输出 ────────┐
│ 她在强化学习中列出了3种主要的reward hacking类型: │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 1. **规则博弈(Spec gaming)**——利用奖励漏洞,而非真正的目标。 │
│ │
│ 2. **奖励篡改(Reward tampering)**——更改或破解奖励信号。 │
│ │
│ 3. **自我刺激(Wireheading)**——自我刺激奖励而非完成任务。 │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 这些可能会导致强化学习Agent出现有害的、非预期的行为。 │
└──────────────────────────────────────┘
如你所见,Agent正确识别出需要使用其检索工具。然后,它成功地从博客文章中检索到了相关上下文,并利用该信息提供了详细且准确的答案。
这是一个完美的例子,展示了通过RAG进行的上下文工程如何创建功能强大、知识丰富的Agent。
带有知识型Agent的压缩策略
Agent交互可能跨越数百个回合,并且涉及token密集型的工具调用。总结是管理这种情况的常用方法。
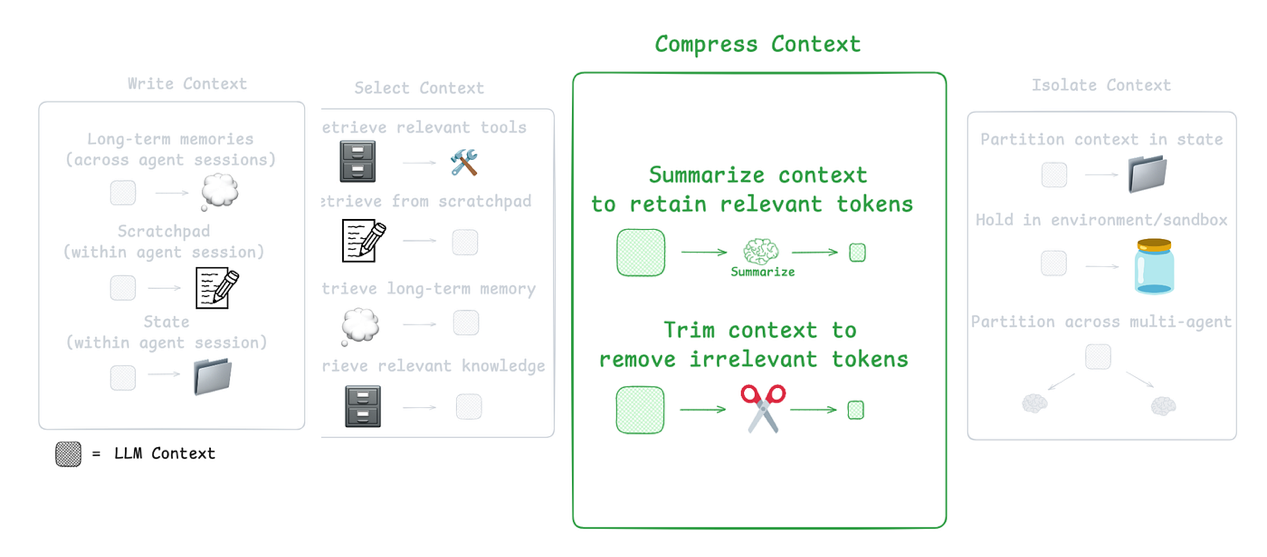
CE的第三个组成部分(来自LangChain文档)
例如:
Claude Code在上下文窗口超过95%时使用“自动压缩”功能,总结整个用户与Agent的交互历史。
总结可以通过递归或分层总结等策略来压缩Agent轨迹。
你也可以在特定节点添加总结:
在token密集型工具调用后(例如搜索工具)——示例见此处。
在Agent与Agent的边界处用于知识传递——Cognition在Devin中通过微调模型实现了这一点。
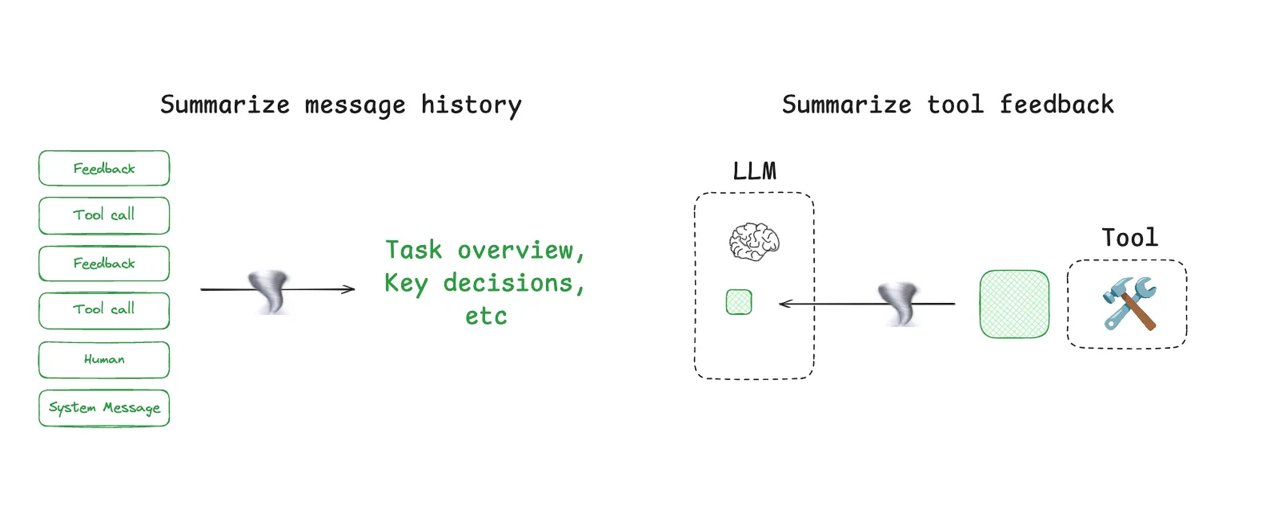
LangGraph的总结方法(来自LangChain文档)
LangGraph是一个底层编排框架,让你能够完全控制:
将Agent设计为一组节点。
明确定义每个节点内的逻辑。
在节点之间传递共享状态对象。
这使得以不同方式压缩上下文变得容易。例如,你可以:
使用消息列表作为Agent状态。
通过内置工具对其进行总结。
我们将使用之前编写的基于RAG的工具调用Agent,并为其添加对话历史总结功能。
首先,我们需要扩展图的状态,添加一个用于存储最终总结的字段。
# 定义包含总结字段的扩展状态
class State(MessagesState):"""包含用于上下文压缩的总结字段的扩展状态。"""summary: str接下来,我们将定义一个专门的总结提示,并保留之前的RAG提示。
# 定义总结提示
summarization_prompt = """总结完整的聊天历史和所有工具反馈,
概述用户的问题以及Agent的操作。"""现在,我们将创建一个summary_node。
该节点将在Agent工作结束时触发,生成整个交互的简洁总结。
llm_call和tool_node保持不变。
def summary_node(state: MessagesState) -> dict:"""生成对话和工具交互的总结。参数:state:图的当前状态,包含消息历史。返回:一个字典,其中键为"summary",值为生成的总结字符串,用于更新状态。"""# 在消息历史前添加总结系统提示messages = [SystemMessage(content=summarization_prompt)] + state["messages"]# 调用语言模型生成总结result = llm.invoke(messages)# 返回总结以存储在状态的'summary'字段中return {"summary": result.content}我们的条件边should_continue现在需要决定是调用工具还是进入新的summary_node。
def should_continue(state: MessagesState) -> Literal["Action", "summary_node"]:"""根据LLM是否进行了工具调用来决定下一步。"""last_message = state["messages"][-1]# 如果LLM进行了工具调用,则执行它们if last_message.tool_calls:return "Action"# 否则,进行总结return "summary_node"让我们构建包含这个最终总结步骤的图。
# 构建RAG Agent工作流
agent_builder = StateGraph(State)# 向工作流添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node)
agent_builder.add_node("summary_node", summary_node)# 定义工作流边
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges("llm_call",should_continue,{"Action": "Action","summary_node": "summary_node",},
)
agent_builder.add_edge("Action", "llm_call")
agent_builder.add_edge("summary_node", END)# 编译Agent
agent = agent_builder.compile()# 显示Agent工作流
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))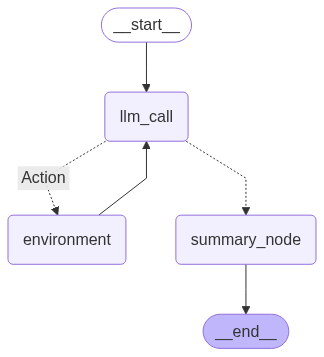
我们创建的Agent
现在,让我们用一个需要获取大量上下文的查询来运行它。
from rich.markdown import Markdownquery = "根据这些博客,为什么强化学习(RL)能改进大语言模型(LLM)的推理能力?"
result = agent.invoke({"messages": [("user", query)]})# 打印给用户的最终消息
format_message(result['messages'][-1])# 打印生成的总结
Markdown(result["summary"])输出:
用户询问了为什么强化学习(RL)能改进大语言模型的推理能力……不错,但它使用了115k token!你可以在这里查看完整轨迹。这是具有token密集型工具调用的Agent面临的常见挑战。一种更高效的方法是在上下文进入Agent的主暂存区之前对其进行压缩。让我们更新RAG Agent,动态总结工具调用的输出。
首先,为这个特定任务准备一个新提示:
tool_summarization_prompt = """你将收到来自RAG系统的文档。
总结这些文档,确保保留所有相关/重要信息。
你的目标只是将文档的大小(token)缩减到更易于管理的程度。"""接下来,我们将修改tool_node以包含这个总结步骤。
def tool_node_with_summarization(state: dict):"""执行工具调用,然后总结输出。"""result = []for tool_call in state["messages"][-1].tool_calls:tool = tools_by_name[tool_call["name"]]observation = tool.invoke(tool_call["args"])# 总结文档summary_msg = llm.invoke([SystemMessage(content=tool_summarization_prompt),("user", str(observation))])result.append(ToolMessage(content=summary_msg.content, tool_call_id=tool_call["id"]))return {"messages": result}现在,我们的should_continue边可以简化,因为我们不再需要最终的summary_node了。
def should_continue(state: MessagesState) -> Literal["Action", END]:"""决定我们是否应该继续循环或停止。"""if state["messages"][-1].tool_calls:return "Action"return END让我们构建并编译这个更高效的Agent。
# 构建工作流
agent_builder = StateGraph(MessagesState)# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node_with_summarization)# 添加边以连接节点
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges("llm_call",should_continue,{"Action": "Action",END: END,},
)
agent_builder.add_edge("Action", "llm_call")# 编译Agent
agent = agent_builder.compile()# 显示Agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))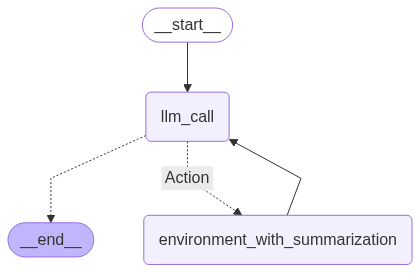
我们更新后的Agent
让我们运行相同的查询,看看差异。
query = "根据这些博客,为什么强化学习(RL)能改进大语言模型(LLM)的推理能力?"
result = agent.invoke({"messages": [("user", query)]})
format_messages(result['messages'])┌────────────── user ───────────────┐
│ 为什么RL能改进LLM的推理能力? │
│ 根据这些博客? │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ 正在搜索Lilian Weng的博客,查找 │
│ RL如何改进LLM推理能力的相关内容... │
│ │
│ 🔧 工具调用:retrieve_blog_posts │
│ 参数:{ │
│ "query": "用于LLM推理的强化学习" │
│ } │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ Lilian Weng解释,RL通过对每个推理步骤的奖励进行训练(基于过程的奖励模型),帮助LLM提升推理能力。这引导模型逐步思考,提高连贯性和逻辑性。 │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ RL通过基于PRM对逐步思考进行奖励,改进LLM的推理能力,鼓励形成连贯、有逻辑的论证,而非仅关注最终答案。它帮助模型自我修正并探索更好的路径。 │
└───────────────────────────────────┘
这次,Agent仅使用了60k token。
这个简单的修改使我们的token使用量几乎减少了一半,使Agent更加高效且经济。
使用子Agent架构隔离上下文
隔离上下文的一种常见方法是将其分配给不同的子Agent。OpenAI的Swarm库就是为这种“关注点分离”而设计的——每个Agent管理特定的子任务,拥有自己的工具、指令和上下文窗口。
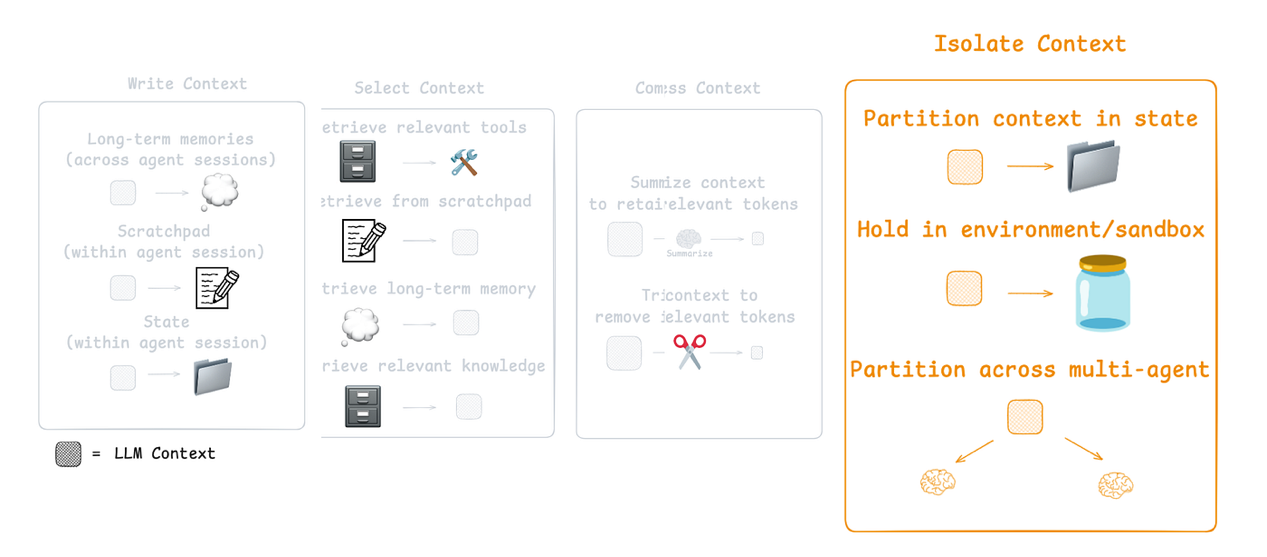
CE的第四个组成部分(来自LangChain文档)
Anthropic的多Agent研究人员表明,具有隔离上下文的多个Agent比单个Agent的表现高出90.2%,因为每个子Agent专注于更狭窄的子任务。
子Agent在各自的上下文窗口中并行运行,同时探索问题的不同方面。
然而,多Agent系统存在一些挑战:
token使用量高得多(有时是单Agent聊天的15倍以上)。
需要精心设计提示词来规划子Agent的工作。
协调子Agent可能很复杂。
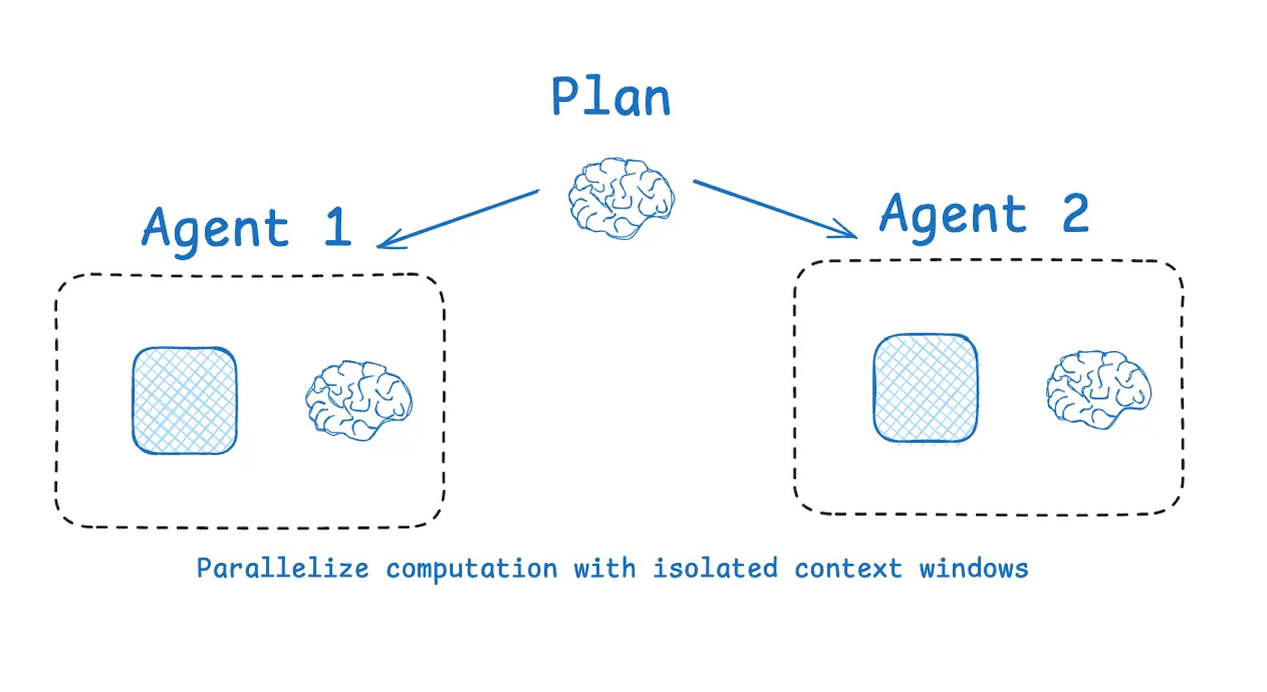
多Agent并行化(来自LangChain文档)
LangGraph支持多Agent设置。一种常见的方法是监督者架构,Anthropic的多Agent研究人员也使用了这种架构。监督者将任务委派给子Agent,每个子Agent在自己的上下文窗口中运行。
让我们构建一个简单的监督者,管理两个Agent:
math_expert(数学专家):处理数学计算。
research_expert(研究专家):搜索并提供研究信息。
监督者将根据查询决定调用哪个专家,并在LangGraph工作流中协调他们的响应。
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor# --- 为每个Agent定义工具 ---
def add(a: float, b: float) -> float:"""Add two numbers."""return a + bdef multiply(a: float, b: float) -> float:"""Multiply two numbers."""return a * bdef web_search(query: str) -> str:"""模拟网页搜索功能,返回FAANG公司的员工数量。"""return ("以下是2024年各FAANG公司的员工数量:\n""1. **Facebook(Meta)**:67,317名员工。\n""2. **Apple**:164,000名员工。\n""3. **Amazon**:1,551,000名员工。\n""4. **Netflix**:14,000名员工。\n""5. **Google(Alphabet)**:181,269名员工。")现在我们可以创建专门的Agent和管理它们的监督者。
# --- 创建具有隔离上下文的专门Agent ---
math_agent = create_react_agent(model=llm,tools=[add, multiply],name="math_expert",prompt="你是数学专家。每次只使用一个工具。"
)research_agent = create_react_agent(model=llm,tools=[web_search],name="research_expert",prompt="你是世界级研究人员,可使用网页搜索。不进行任何数学计算。"
)# --- 创建用于协调Agent的监督者工作流 ---
workflow = create_supervisor([research_agent, math_agent],model=llm,prompt=("你是管理研究专家和数学专家的团队监督者。""将任务委派给合适的Agent以回答用户的查询。""对于时事或事实性问题,使用research_agent。""对于数学问题,使用math_agent。")
)# 编译多Agent应用
app = workflow.compile()让我们执行工作流,看看监督者如何委派任务。
# --- 执行多Agent工作流 ---
result = app.invoke({"messages": [{"role": "user","content": "2024年FAANG公司的员工总数是多少?"}]
})# 格式化并显示结果
format_messages(result['messages'])┌────────────── user ───────────────┐
│ 了解更多关于LangGraph Swarm和 │
│ 多Agent系统的信息。 │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ 正在获取关于LangGraph Swarm及 │
│ 相关资源的详细信息... │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ LangGraph Swarm │
│ 仓库: │
│ https://github.com/langchain-ai/ │
│ langgraph-swarm-py │
│ │
│ • 用于构建具有动态协作功能的多Agent │
│ AI的Python库。 │
│ • Agent根据专业分工移交控制权, │
│ 同时保留对话上下文。 │
│ • 支持自定义移交、流式传输、内存 │
│ 和人工介入。 │
│ • 安装方式: │
│ pip install langgraph-swarm │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ 关于多Agent系统的视频 │
│ 1. https://youtu.be/4nZl32FwU-o │
│ 2. https://youtu.be/JeyDrn1dSUQ │
│ 3. https://youtu.be/B_0TNuYi56w │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ LangGraph Swarm便于构建具有上下文感知能力的多Agent │
│ 系统。查看视频可深入了解多Agent行为。 │
└───────────────────────────────────┘
在这里,监督者正确地为每个任务隔离了上下文——将研究查询发送给研究专家,将数学问题发送给数学家,展示了有效的上下文隔离。
使用沙箱环境进行隔离
HuggingFace的深度研究工具(deep researcher)展示了一种很酷的上下文隔离方式。大多数Agent使用工具调用API,这些API返回JSON参数来运行搜索API等工具并获取结果。
HuggingFace使用CodeAgent来编写调用工具的代码。这些代码在安全的沙箱中运行,运行结果会发送回LLM。
这使得大量数据(如图片或音频)不会占用LLM的token限额。HuggingFace解释道:
[代码Agent允许]更好地处理状态……需要存储此图片/音频/其他内容供以后使用?只需将其作为变量保存在状态中,稍后再使用即可。
在LangGraph中使用沙箱很简单。LangChain沙箱使用Pyodide(编译为WebAssembly的Python)安全地运行不可信的Python代码。你可以将其作为工具添加到任何LangGraph Agent中。
注意:需要Deno环境。在此处安装:
https://docs.deno.com/runtime/getting_started/installation/
from langchain_sandbox import PyodideSandboxTool
from langgraph.prebuilt import create_react_agent# 创建一个具有网络访问权限的沙箱工具,用于安装包
tool = PyodideSandboxTool(allow_net=True)# 使用沙箱工具创建ReAct agent
agent = create_react_agent(llm, tools=[tool])# 使用沙箱执行数学查询
result = await agent.ainvoke({"messages": [{"role": "user", "content": "what's 5 + 7?"}]},
)# 格式化并显示结果
format_messages(result['messages'])│ 5加7等于多少? │
└──────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ 我可以通过在沙箱中执行Python代码来解决这个问题。 │
│ │
│ 🔧 工具调用:pyodide_sandbox │
│ 参数:{ │
│ "code": "print(5 + 7)" │
│ } │
└──────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ 12 │
└──────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ 答案是12。 │
└──────────────────────────────────┘
LangGraph中的状态隔离
Agent的运行时状态对象是另一种很好的上下文隔离方式,类似于沙箱机制。你可以通过 schema(如Pydantic模型)设计这种状态,其中包含用于存储上下文的不同字段。
例如,一个字段(如messages)在每一轮都展示给LLM,而其他字段则将信息隔离存储,直到需要时才使用。
LangGraph围绕状态对象构建,允许你创建自定义状态schema,并在Agent的整个工作流中访问其字段。
例如,你可以将工具调用结果存储在特定字段中,直到必要时才向LLM展示。
总结全文
让我们总结一下到目前为止所做的工作:
我们使用LangGraph的StateGraph创建了用于短期记忆的“暂存区”(scratchpad)和用于长期记忆的InMemoryStore,使Agent能够存储和回忆信息。
我们演示了如何有选择地从Agent的状态和长期记忆中提取相关信息。这包括使用检索增强生成(RAG)查找特定知识,以及使用langgraph-bigtool从众多选项中选择合适的工具。
为了管理长对话和token密集型工具输出,我们实现了总结功能。
我们展示了如何动态压缩RAG结果,以提高Agent的效率并减少token使用量。
我们探索了通过构建多Agent系统(带有将任务委派给专业子Agent的监督者)和使用沙箱环境运行代码来保持上下文分离,避免混淆。
所有这些技术都属于“上下文工程”(Contextual Engineering)的范畴——这是一种通过精心管理AI Agent的工作记忆(上下文)来提高其效率、准确性,并使其能够处理复杂、长期任务的策略。