基于Python的实习僧招聘数据采集与可视化分析,使用matplotlib进行可视化
1 设计背景
1.1项目简介
随着互联网和信息技术的迅猛发展,线上招聘平台成为了连接求职者和企业的重要桥梁。在这一背景下,实习僧作为国内领先的实习招聘平台之一,提供了大量针对大学生群体的实习机会。每年,成千上万的学生通过该平台寻找实习职位,以积累职场经验,并为未来的职业生涯奠定基础。与此同时,企业也通过平台发布招聘信息,吸引优秀的实习生加入。
1.2课题目标
本研究的主要目标是基于Python对实习僧平台的招聘数据进行采集、清洗、分析与可视化,旨在从多个维度深入探讨实习市场的现状和趋势。
2 设计思路
2.1开发环境与工具
开发环境主要包括Python编程语言、网络爬虫技术、数据处理与分析库、数据可视化工具以及Pycharm开发环境,并运用到 Requests,Pandas,Numpy,等库。该项目的开发环境如下表 2-1 所示。
表2-1 系统开发环境版本表
开发工具 | 版本 |
Pycharm | PyCharm Community Edition 2023.2.1 |
Python | Python 3.9 |
Pandas | Pandas 1.1.5 |
Matplotlib | Matplotlib 3.5.3 |
MySQL | MySQL8.0.19 |
2.1.1 Pycharm
PyCharm是一款强大的Python集成开发环境(IDE),由JetBrains公司开发,广泛应用于数据分析、Web开发、人工智能等多个领域。
2.2.2 Python
Python是一种广泛使用的高级编程语言,以其简洁易读的语法和强大的功能而闻名。在基于Python的实习僧招聘数据采集与可视化分析中,Python的优势体现在多个方面,使其成为数据科学和分析领域的热门选择。
2.2.3 Requests
在基于Python的实习僧招聘数据采集与可视化分析中,Requests库作为一款强大的HTTP库,扮演着至关重要的角色。Requests库使得编写网络爬虫变得简单而高效,极大地简化了HTTP请求的过程,成为数据采集的热门工具。
2.2.4 matplotlib
Matplotlib 是一个强大的 Python 可视化库,广泛应用于数据科学、机器学习、科学计算以及工程领域,用于生成各种类型的二维和三维图表。其功能包括生成静态、动态和交互式的可视化图表,支持各种输出格式(如 PNG、PDF、SVG、EPS、JPEG 等)。它的设计灵感来源于 MATLAB,因而具有与 MATLAB 类似的语法结构,但具有开源且跨平台的优势。
2.2技术架构
项目的技术架构分为数据采集、数据处理和数据可视化三个主要部分。
- 数据采集:主要利用Python的requests库来实现。这一过程涉及构建自动化脚本,以定期从实习僧获取最新的招聘信息。requests库能够方便地处理HTTP请求,通过GET方法从网站服务器获取网页HTML内容。为了确保数据的有效性和全面性,可以设置定期请求和动态参数,模拟用户访问行为。获取到的HTML数据需要进一步解析,这里我们使用api接口,它能够有效地解析岗位数据,并通过接送提取招聘信息,如职位名称、公司、地点、薪资等关键信息。
- 数据处理:在完成数据采集后,数据处理环节利用pandas库来对数据进行整理和分析。首先,将采集到的原始数据转换为pandas数据框格式,以便于后续的处理操作。在数据清洗阶段,需要处理缺失值、重复数据和不一致的数据格式,这可以通过pandas的内置函数如dropna()、drop_duplicates()和astype()来实现。接下来,利用pandas强大的数据分析能力,可以对不同维度的数据进行统计和分析。例如,可以对各行业的招聘数量进行聚合,分析区域之间的薪资水平差异,以及职位需求的变化趋势。这些分析结果为进一步的可视化提供了基础。
- 数据可视化:数据可视化是项目的最后阶段,借助matplotlib库实现。matplotlib提供了丰富的图表类型,包括柱状图、折线图、饼图等,适合用于展示多维度的数据分析结果。在本项目中,柱状图可以用于展示不同行业的招聘趋势,饼图则直观地显示行业占比,而地图适合展示区域性的薪资水平和招聘热度。
技术架构图如下2-1:
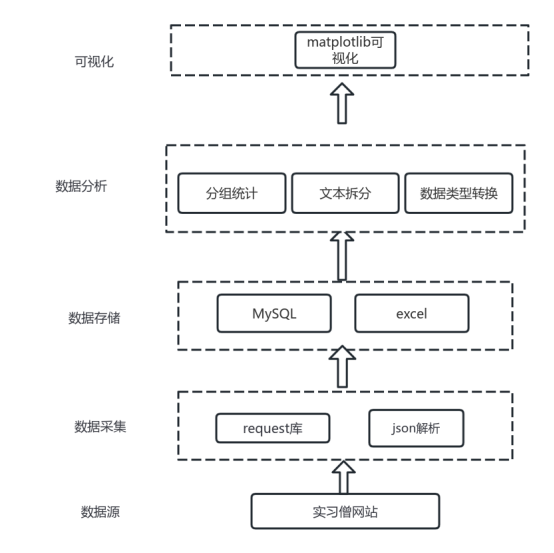
图2-1技术架构图
3 数据采集
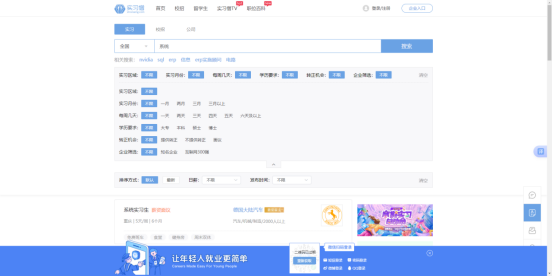
本项目采集实习僧网站招聘数据1824条存入MySQL。采集的网页信息如下图:
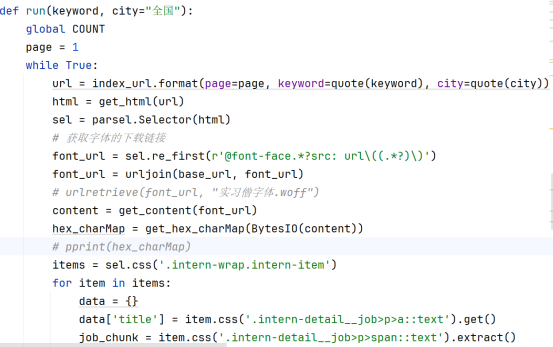
数据采集的实现过程主要依赖于使用Requests库向实习僧的API发送请求,并处理返回的数据。具体的过程如下:
实现了从 实习僧 网站自动抓取招聘数据的功能。首先,通过构造带有参数的 URL,利用 requests 库发送 HTTP 请求获取网页内容。针对每一页,使用 parsel 库对网页进行解析,提取招聘信息,如职位名称、薪资、公司名称、职位福利等。特别地,由于招聘信息中涉及到的某些文本采用了加密字体,代码通过解析页面中的字体下载链接,并利用 fontTools 库解密字体文件,得到真实的文本内容。接着,将提取的每条数据通过 pymysql 库存入 MySQL 数据库。整个过程循环抓取每一页数据,直到没有更多的页面为止。主要代码如下图。
采集结果如下图:
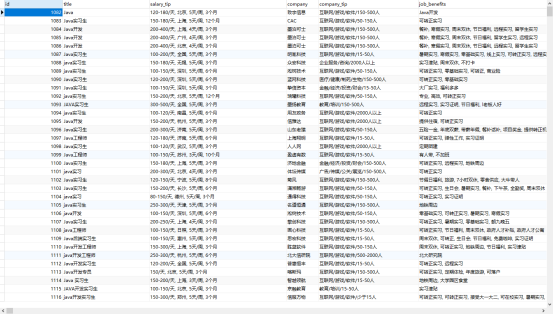
4 数据处理
4.1数据加载和连接数据库
具体实现如下:
使用 pymysql 连接本地的 MySQL 数据库,选择数据库为“实习僧”,并查询其中的“实习僧”表中的所有数据,加载到一个 Pandas DataFrame 中。然后,关闭数据库连接。结果如下图
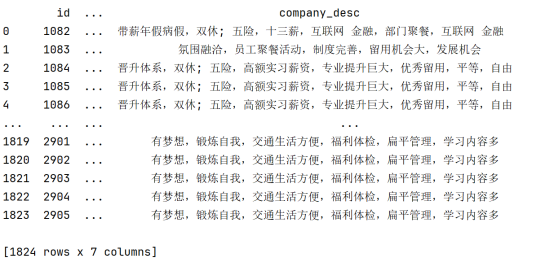
4.2处理 salary_tip 列(薪资信息)
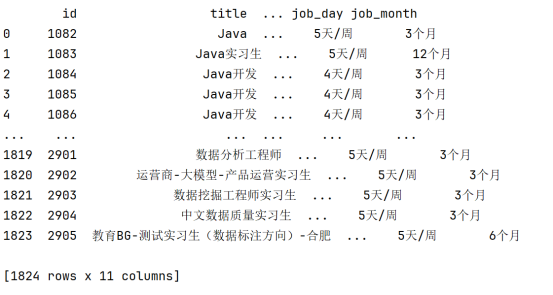
薪资信息在 salary_tip 列中通常包含多个部分(如薪资范围、地区、实习天数和实习月数)。这些信息是以逗号分隔的字符串,使用 str.split() 方法将其拆分成多列:
job_money: 提取薪资金额(范围)部分。
job_diqu: 提取薪资相关的地区信息。
job_day: 提取每周的实习天数。
job_month: 提取实习的月份数。
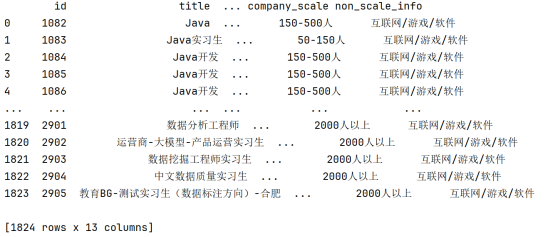
4.3 提取公司规模信息和非公司规模信息
公司规模信息存储在 company_tip 列中,使用正则表达式提取类似“150-500人”或“2000人以上”的模式,将其存储在新列 company_scale 中,继续使用正则表达式,提取 company_tip 列中的非规模信息。正则表达式去除“人”或“人以上”的部分,仅保留其他描述信息,并将其存储在新列 non_scale_info 中。结果如下图:
4.4 转换薪资为数值格式
薪资信息(job_money)在处理时可能包含范围(例如,“1500-2500元”),需要将其转换为数值型。处理规则为提取薪资区间的中间值作为该职位的薪资:
如果薪资区间包含“-”或“/”,则取其平均值作为薪资。
如果薪资信息以“/天”结尾,则提取数值并转换。
处理无效数据(例如“薪资面议”)时去除该行。结果如下图:
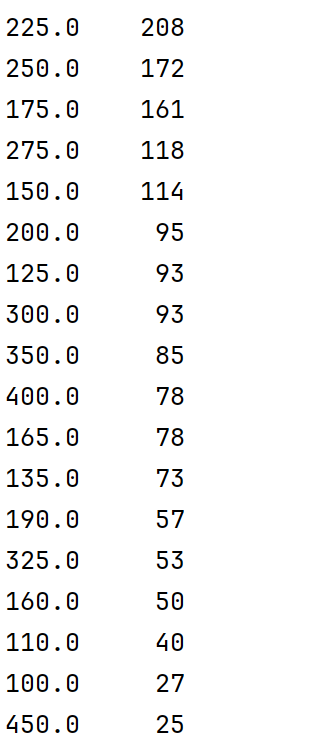
4.5 处理地区信息
在 job_diqu 列中,某些地区数据量可能较少,因此根据地区的出现次数,筛选出数据量较多的地区。这些地区的数据会用于后续分析,剔除数据量过少的地区。结果如下图:
5 数据分析与可视化
5.1公司规模分布情况柱形图实现
通过提取数据中的“company_scale”列,该列存储了企业的规模信息,例如“少于15人”、“15-50人”等。为了确保图表的准确性,使用 groupby() 方法按公司规模分组,计算每个规模类别的招聘职位数。接下来,使用 reindex() 方法将公司规模按预定的顺序(如少于15人、15-50人等)重新排序,以确保柱形图的可读性和逻辑性。
然后,使用 plot.bar() 方法绘制柱形图,并设置坐标轴标签(如“公司规模”和“招聘数量”)及标题(如“公司规模分布情况”)。通过 plt.tick_params() 方法调整坐标轴的刻度显示和旋转角度,使得标签清晰可见。
整个图形通过 plt.show() 显示,最终呈现出不同公司规模类别下职位招聘数量的对比。该柱形图直观展示了不同规模公司对职位需求的分布情况,有助于分析招聘市场的规模差异。如下图
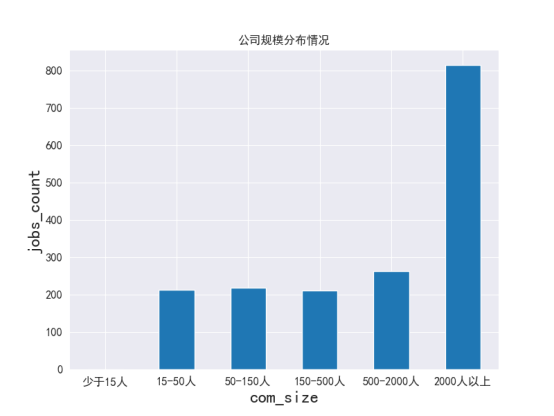
从公司规模分布情况的柱形图结果来看,招聘需求最为旺盛的公司规模是“2000人以上”,共计有814个职位需求,占据最大份额。其次是“500-2000人”规模的公司,招聘需求为263个职位。较小规模公司(如“少于15人”)的招聘需求相对较少,且其值为NaN,可能是数据缺失或未标注。这表明大公司在实习招聘市场中占据主导地位,尤其是企业规模较大的公司提供的职位数量较多。
5.2公司标签词云图实现
从数据中提取“job_benefits”列,该列包含了与岗位福利相关的标签信息。通过将所有标签合并为一个大字符串,使用 split() 方法按逗号分隔,得到所有标签的列表。接着,使用 Counter 类对标签进行频次统计,得到每个标签出现的次数。
然后,构建一个数据框 df1,根据标签出现频次排序,选择出现频次最高的前30个标签。为了生成词云,加载一个背景图,并使用 WordCloud 类的 generate_from_frequencies() 方法,根据标签的频次生成词云图。在词云图中,标签的字体大小根据频次大小调整,频次越高的标签越大,显示效果直观。
最后,通过 plt.imshow() 显示词云图,并使用 plt.axis('off') 关闭坐标轴,使图像更加美观。图中的标签位置和大小由生成的频次数据控制,使得常见标签更加突出,从而清晰地展示出岗位福利的热门关键词。这个词云图帮助我们直观了解招聘职位的福利特点。如下图。

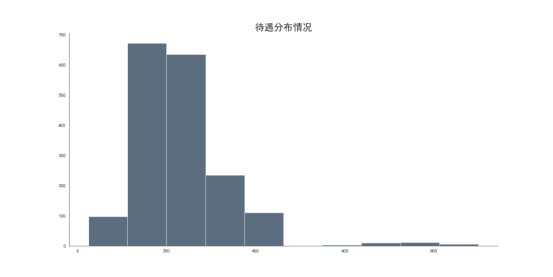
5.3待遇分布情况直方图实现
待遇分布情况直方图的实现首先需要从数据集中提取与薪资相关的列,比如“salary”列,该列包含了各岗位的薪资信息。为了能够绘制直方图,通常需要对薪资数据进行处理,例如去除缺失值或异常值。接着,使用数据分析库(如 pandas)进行薪资数据的清洗和转换,将薪资范围的字符串数据(如“8-10k”)转化为数值数据,可以通过提取数值的中位数或范围的下限来进行转换。
一旦数据处理完成,就可以使用数据可视化库 matplotlib 来绘制直方图。使用 plt.hist() 函数,可以将处理后的薪资数据分成若干个区间,并通过 density=True 标志来显示频率分布。直方图的横轴表示薪资区间,纵轴表示该区间内职位的数量或频率。通过直方图,可以清晰地展示不同薪资水平的职位分布情况,帮助我们了解招聘市场上薪资水平的整体趋势。
最终,通过 plt.show() 展示图像,完成待遇分布情况的可视化,便于分析薪资集中区间及其分布特征。如下图。
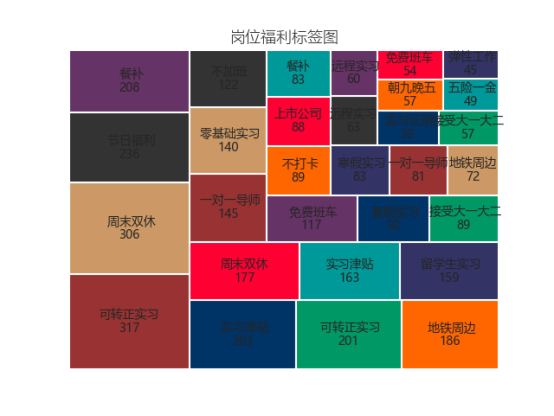
5.4岗位福利标签图实现
从数据框中提取“job_benefits”列并将其转换为一个列表 processed_comments1,该列表包含所有岗位的福利标签。接着,将所有标签合并成一个大字符串,使用逗号分隔,并通过 split(',') 将字符串拆分成独立的标签。使用 Counter 对标签进行频次统计,生成一个字典 dict_,其中键为标签,值为该标签的出现次数。
创建一个包含标签和频次的数据框 df1,并按频次对标签进行排序。选择频次最高的前30个标签用于展示,并将它们的名称和频次分别存储在 name 和 income 变量中。
为了绘制标签图,使用 squarify.plot() 创建一个矩形树图,其中每个矩形的大小与标签的频次相关,颜色通过 colors 列表设置。最后,通过 matplotlib 调整字体、标题、坐标轴等显示属性,去除坐标轴和边框,确保图形整洁美观。通过这种方式,岗位福利标签图可以直观地展示各个福利标签的分布情况,帮助分析最受欢迎的福利选项。如下图。
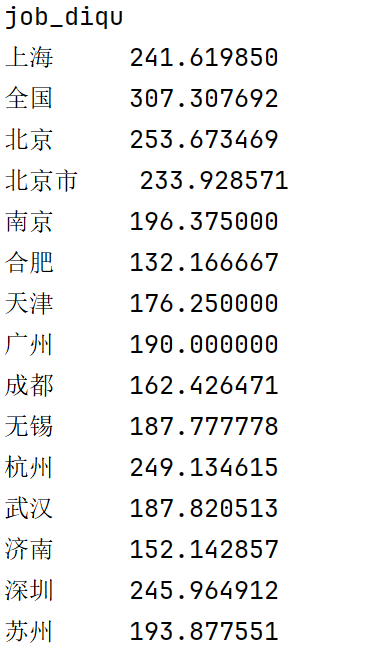
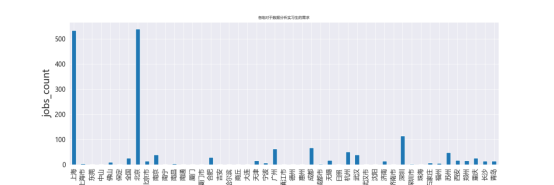
5.5各地对于数据分析实习生的需求柱形图实现
使用 groupby('job_diqu') 对数据进行分组,按地区(job_diqu)统计每个地区的招聘岗位数量。接着,通过 count() 方法计算每个地区的数据分析实习生岗位数量,并使用 plot.bar() 绘制柱形图。这一步将各地区的岗位需求数量呈现为直观的条形图。
为了使图表更加清晰,设置了 ylabel 和 xlabel 分别为“jobs_count”和“job_position”,并指定了字体大小为18,以确保标签的可读性。通过 plt.tick_params(labelsize=12) 设置坐标轴刻度标签的字体大小。最后,通过 plt.title() 设置图表标题为“各地对于数据分析实习生的需求”,便于解释图表的含义。图表通过 plt.show() 展示,直观地显示了各个地区对数据分析实习生的招聘需求,从而帮助分析哪些地区对这一职位的需求更高。如下图。
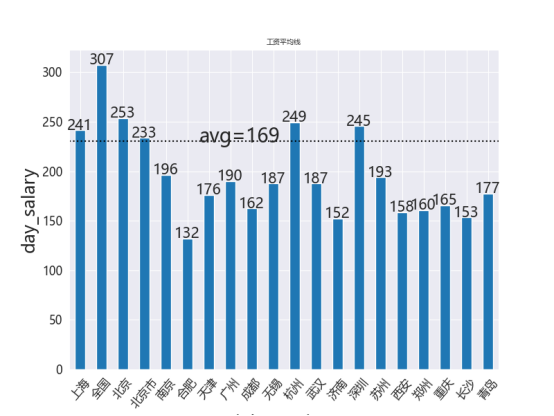
5.6各地工资平均线柱形图实现
将 job_money 列转换为浮动类型,并使用 groupby(['job_diqu']) 对数据按地区进行分组,计算每个地区的平均工资。为了确保数据的有效性,剔除了数据量较少的地区(岗位数小于等于10的地区)。通过 apply(float) 确保计算结果为浮动类型,得到各地区的平均工资。
接着,使用 plot.bar() 绘制柱形图,显示每个地区的数据分析岗位的平均工资。在图表上方,使用 plt.text() 为每个柱形添加具体的数值,以便于直观查看各地区的平均工资。
图中还绘制了全体岗位的平均工资线,使用 plt.axhline() 添加横向虚线表示整体平均工资,并通过 plt.text() 在图中标注出具体的平均工资值。图表的横轴是地区(job_postion),纵轴是工资(day_salary),并通过适当的字体和旋转设置增强图表的可读性。最终,图表清晰地展示了各地区的数据分析岗位的工资水平以及整体平均工资。如下图。
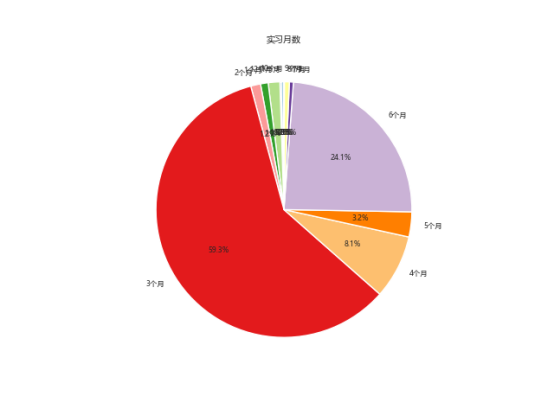
5.7实习月数饼图实现
使用 groupby('job_month') 对数据进行按“实习月数” (job_month) 分组,并通过 count() 计算每个月份的岗位数量,即统计每个月份的职位数量。接着,将这些统计结果存储在 month_counts 变量中,表示每个月份的职位需求量。
使用 plt.pie() 绘制饼图,传入 month_counts 作为数据源,labels=month_counts.index 用于设置饼图的标签,标签为每个月份的名称。autopct='%1.1f%%' 用于显示每个部分占总数的百分比,保留一位小数。startangle=90 设置饼图从90度开始绘制,colors=plt.cm.Paired.colors 设置饼图的颜色,使其更加丰富多彩。
使用 plt.title() 设置饼图的标题为“实习月数”,并通过 plt.show() 显示饼图,直观展示各个月份在招聘岗位中所占的比例。饼图为我们提供了关于不同实习月数需求占比的清晰视图,帮助分析招聘趋势。如下图。