C++高频知识点(十五)
文章目录
- 71. C++11、14、17有哪些特性
- C++14模板变量的简单示例:
- C++17 引入了许多新特性和标准库增强,以下是这些技术点的逐一解析:
- 1. 结构化绑定(Structured Bindings)
- 2. if 和 switch 的初始化语句
- 3. 折叠表达式(Fold Expressions)
- 4. std::optional
- 5. std::variant
- 6. std::any
- 7. std::string_view
- 8. std::filesystem
- 9. constexpr 的扩展
- 10. 内联变量(Inline Variables)
- ODR(One Definition Rule)
- 72. 谈谈 Linux中 进程间的通信方式
- 1. 管道(Pipes)
- 2. 消息队列(Message Queues)
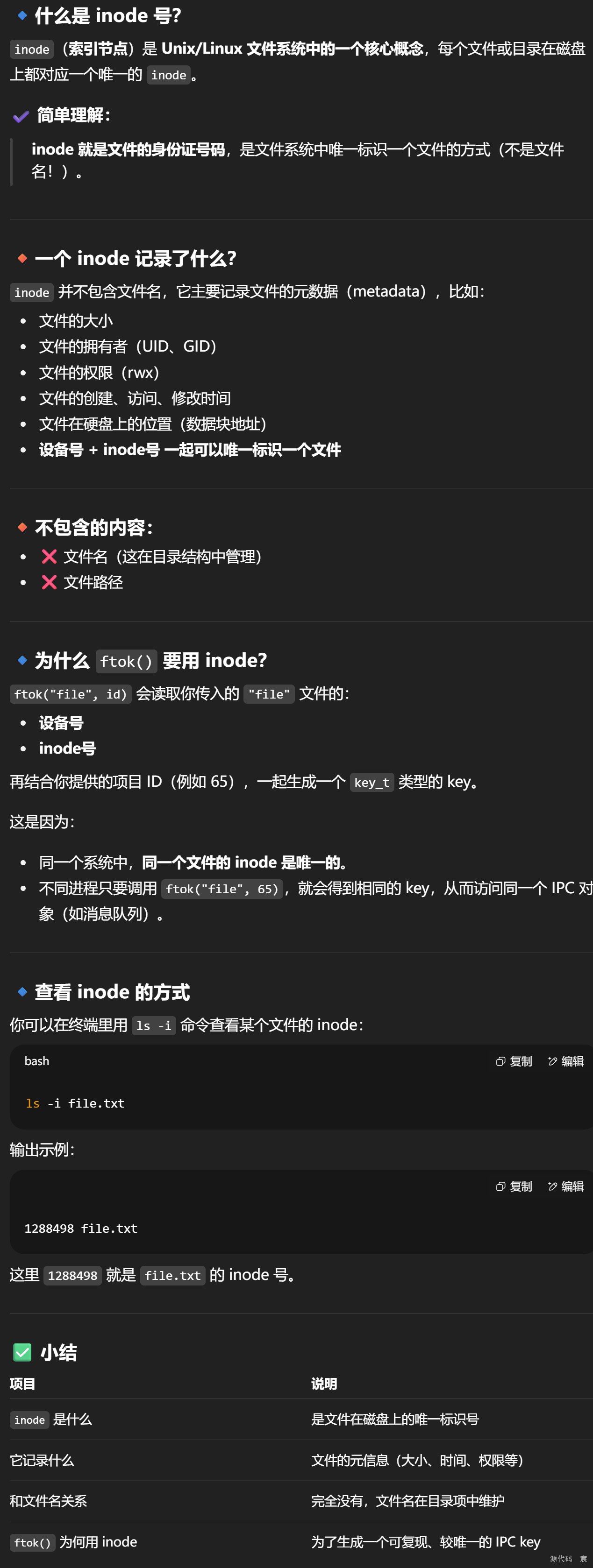
- 什么是 inode 号?
- 3. 共享内存(Shared Memory)
- 4. 信号量(Semaphores)
- 5. 信号(Signals)
- 6. 套接字(Sockets)
- 7. 内存映射(Memory Mapping)
- 内存映射和共享内存
- 内存映射(mmap)用于多个进程共享文件内容
- 73. vector迭代器什么时候会失效,将导致什么后果。
- 74. 说说析构函数的执行顺序,构造函数的执行顺序
- 75. 模板的偏特化
- 1. 完全特化
- 2. 偏特化(Partial Specialization)
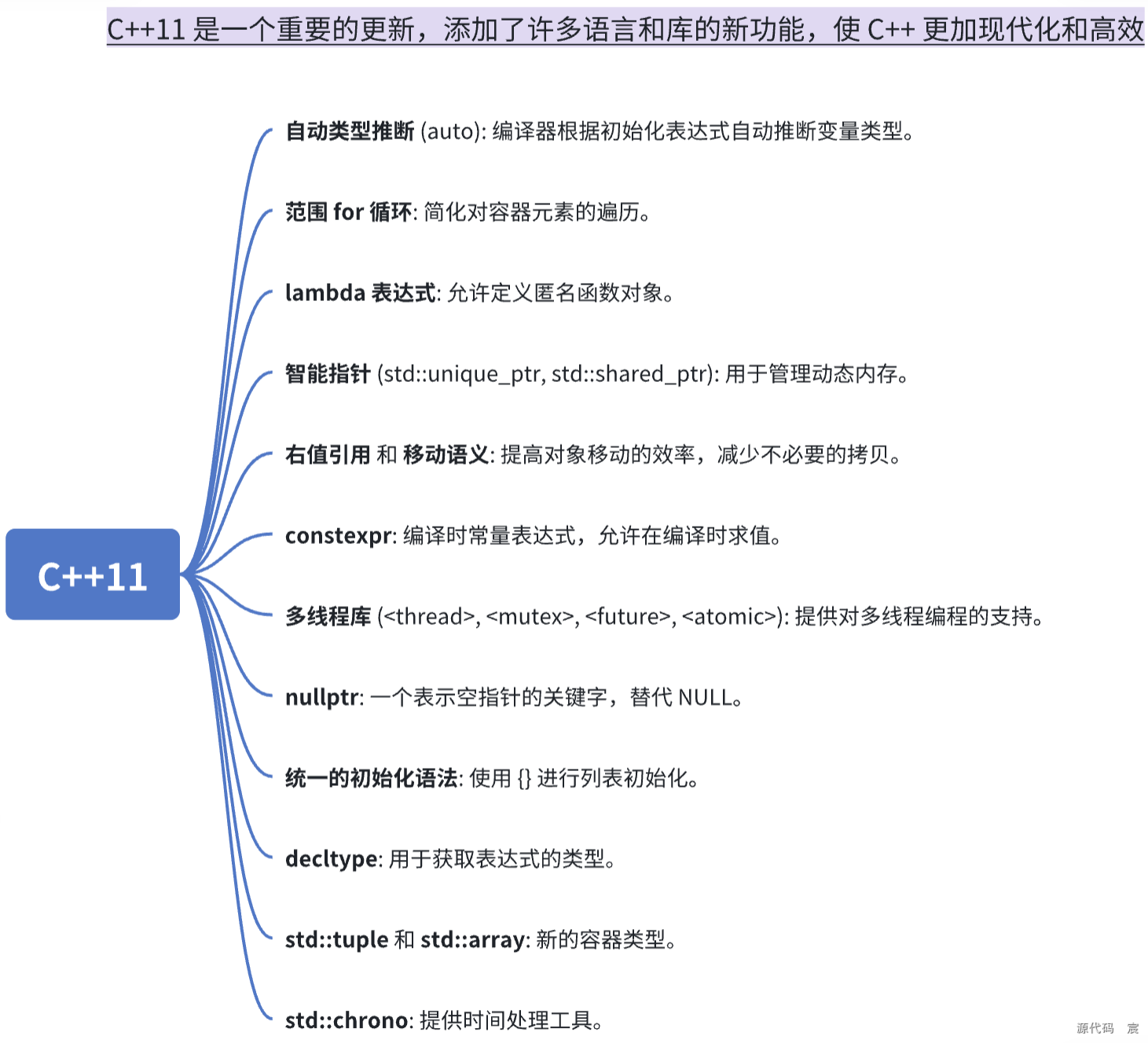
71. C++11、14、17有哪些特性
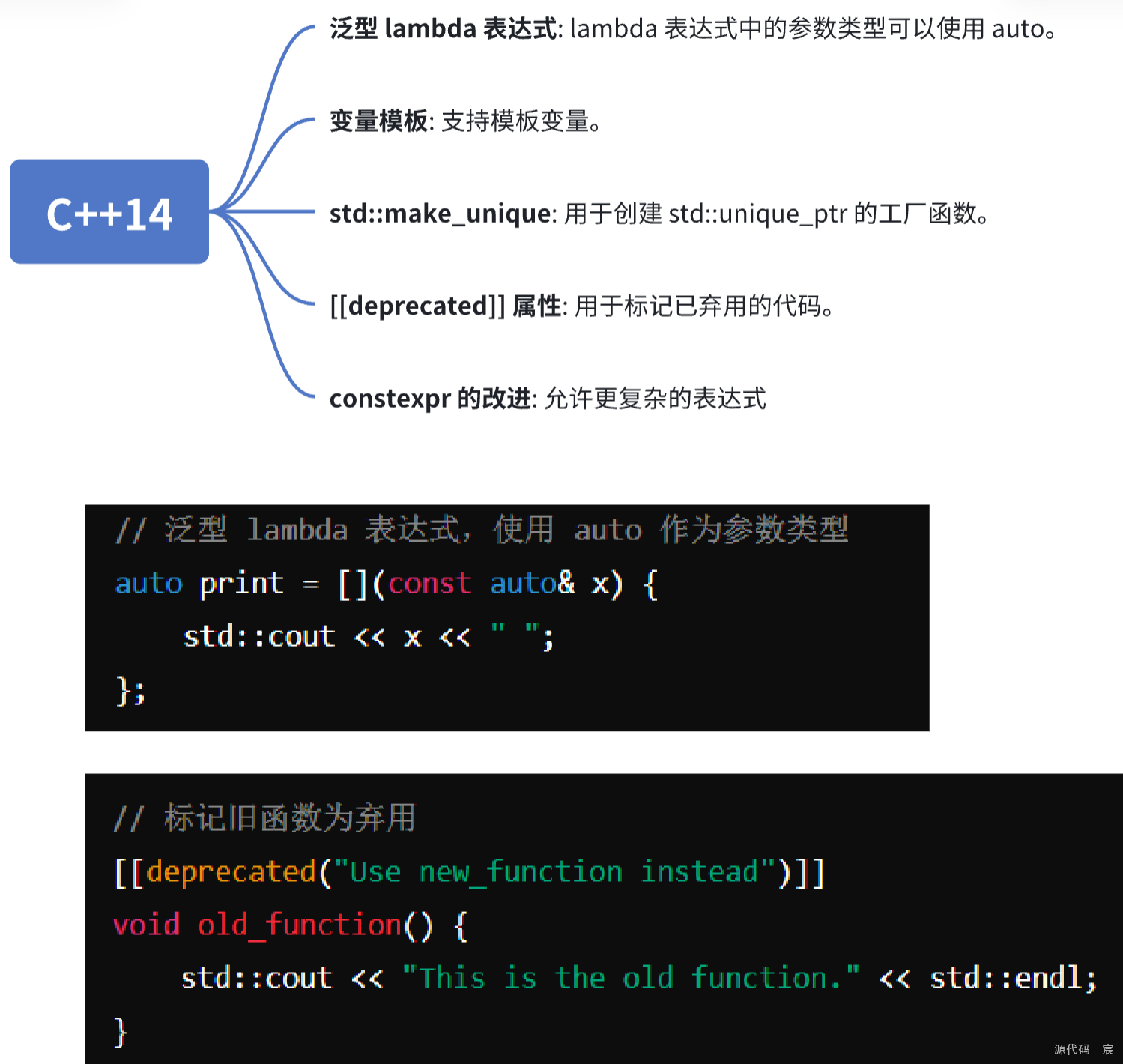
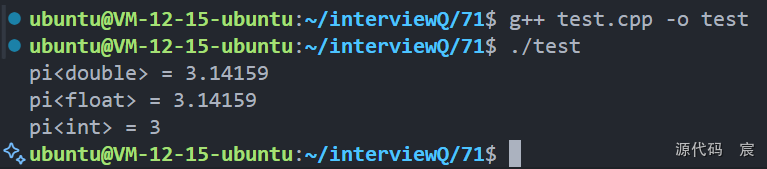
C++14模板变量的简单示例:
#include <iostream>// 定义一个模板变量,用于获取不同类型的圆周率值
template<typename T>
constexpr T pi = T(3.1415926535897932385);int main() {std::cout << "pi<double> = " << pi<double> << std::endl;std::cout << "pi<float> = " << pi<float> << std::endl;std::cout << "pi<int> = " << pi<int> << std::endl;return 0;
}
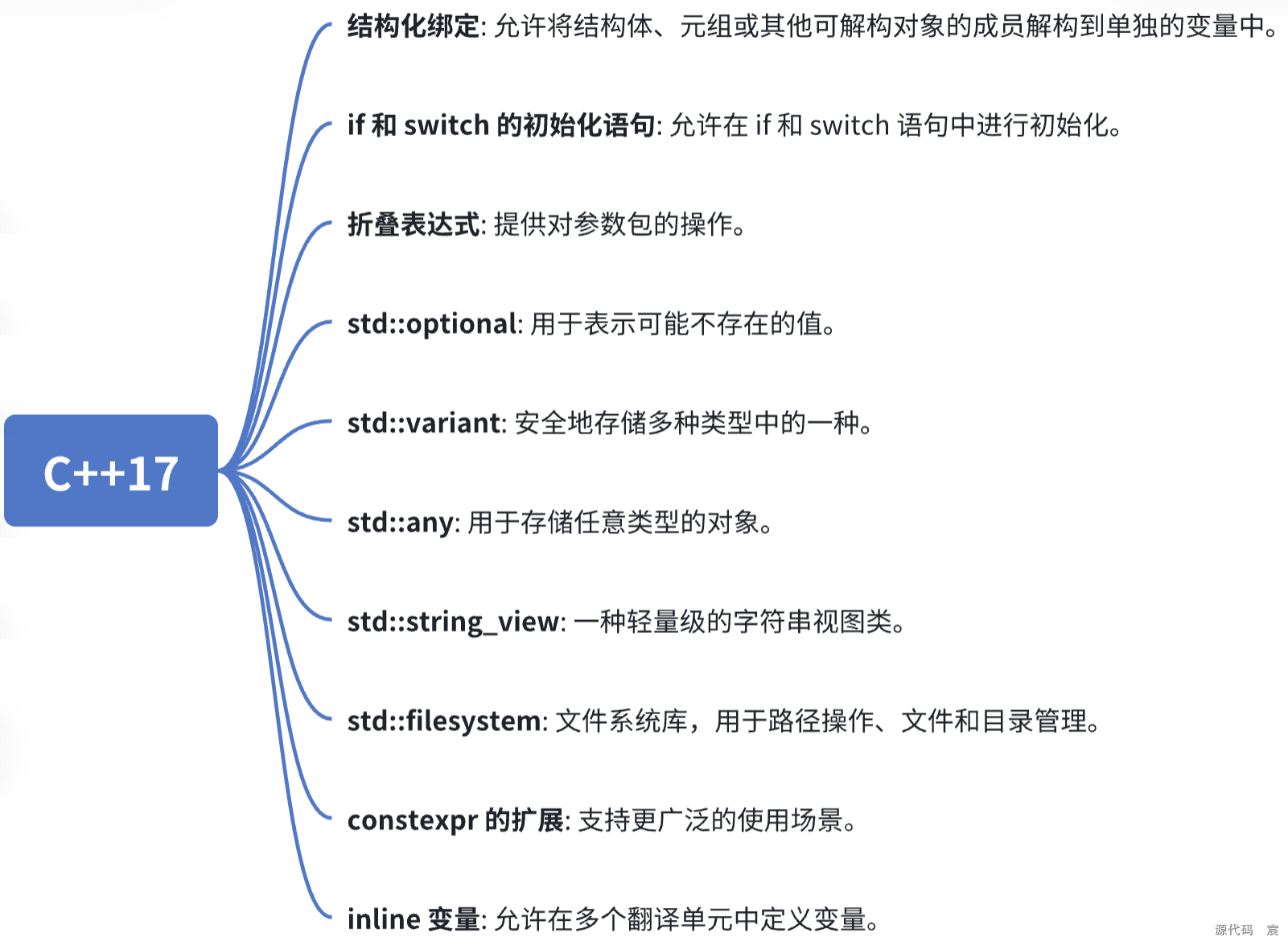
C++17 引入了许多新特性和标准库增强,以下是这些技术点的逐一解析:
1. 结构化绑定(Structured Bindings)
结构化绑定允许将结构体、元组或其他可解构对象的成员解构到单独的变量中,提供了更简洁的语法。
#include <tuple>
#include <iostream>int main() {std::tuple<int, double, std::string> data{1, 2.5, "example"};auto [x, y, z] = data; // 结构化绑定std::cout << x << ", " << y << ", " << z << std::endl;return 0;
}
在这个例子中,auto [x, y, z] 从 std::tuple 中解构出三个独立的变量。

2. if 和 switch 的初始化语句
C++17 允许在 if 和 switch 语句中进行初始化,这使得代码更紧凑和清晰。
#include <iostream>int main() {if (int x = 42; x > 0) {std::cout << "x is positive: " << x << std::endl;}switch (int y = 2; y) {case 1:std::cout << "y is 1" << std::endl;break;case 2:std::cout << "y is 2" << std::endl;break;default:std::cout << "y is something else" << std::endl;break;}return 0;
}

在这段代码中,变量 x 和 y 被分别初始化在 if 和 switch 语句中,限定了它们的作用域。
3. 折叠表达式(Fold Expressions)
折叠表达式简化了参数包的操作,特别是在递归地处理参数包时。
#include <iostream>// 这是一个可变参数模板 (variadic template)。它允许 sum 函数接受任意数量、任意类型的参数。
template<typename... Args>
// Args... 被推导为 int, double, int。
// args... 就代表了传入的 1, 2.0, 3 这三个参数
// args... 是一个函数参数包 (function parameter pack),它代表了传递给函数的所有参数的值。
// 我有一个类型列表叫 Args,现在我声明一个函数参数列表叫 args,它的每个参数都对应 Args 里的一个类型。
auto sum(Args... args) {// 这是整个代码的核心,一个左折叠表达式 (left fold expression)// 它的作用是使用 + 运算符,从左到右依次将参数包 args 中的所有元素相加。// 展开过程如下:((((arg1 + arg2) + arg3) + arg4) + ...)。// 在 sum(1, 2, 3, 4, 5) 这个调用中,它会展开为 ((((1 + 2) + 3) + 4) + 5),最终得到结果 15。return (args + ...); // 左折叠
}int main() {std::cout << sum(1, 2, 3, 4, 5) << std::endl; // 输出 15return 0;
}

在这个例子中,sum 函数利用左折叠表达式 (args + …) 计算参数包的和。
4. std::optional
std::optional 是一个模板类,用于表示一个可能包含值或不包含值的对象,类似于指针的行为,但更安全。
#include <optional>
#include <iostream>// std::optional<int>: 这是函数的返回类型。它表示这个函数可能会返回一个 int 类型的值,也可能什么都不返回
std::optional<int> maybe_return(bool flag) {if (flag) {// 函数将返回一个包含值 42 的 std::optional<int> 对象。std::optional 内部会自动包装这个 42return 42;}// 如果 flag 为 false,函数返回 std::nullopt。这是 std::optional 的一个特殊值,用于明确表示“没有值”。这比返回 nullptr 更清晰,因为 std::optional 不是指针return std::nullopt;
}int main() {// result 将会是一个包含 42 的 std::optional<int> 对象result 将会是一个包含 42 的 std::optional<int> 对象auto result = maybe_return(true);// 这是 std::optional 的一个关键特性。std::optional 对象可以被隐式转换为 bool 类型// 如果 optional 对象包含一个值,它会被评估为 true。// 如果 optional 对象不包含值(即为 std::nullopt),它会被评估为 false。if (result) {// *result: std::optional 重载了 * 运算符,允许你像解引用指针一样来访问它所包含的值// 只有当你确定 optional 对象有值时,才能安全地使用 * 来解引用。如果 optional 没有值就解引用,会导致未定义行为(通常是程序崩溃)。std::cout << "Result is: " << *result << std::endl;} else {std::cout << "No result" << std::endl;}return 0;
}

这里,maybe_return 函数可能返回一个 int 值,也可能不返回任何值。std::optional 提供了更安全的处理方法。
5. std::variant
std::variant 是一个类型安全的联合体,可以存储多种类型中的一种。
#include <variant>
#include <iostream>int main() {// 这是 C++17 引入的一个模板类,用于存储类型安全的联合体 (union)。简单来说,std::variant 可以在其模板参数列表中定义的多种类型中,同一时间只存储其中一种类型的值。// 变量 v 可以存储一个 int、一个 float,或者一个 std::string。// v;: 在默认初始化时,std::variant 会存储其模板参数列表中的第一个类型的默认构造值。在这个例子中,v 默认存储一个 int,其值为 0std::variant<int, float, std::string> v;// v = 42;: 这里将一个 int 类型的值 42 赋给了 v。// std::variant 的赋值运算符会自动处理类型的切换。此时,v 的内部状态会从存储一个 int 变成存储一个 int,其值为 42v = 42;// std::get<int>(v): 这是一个函数模板,用于从 std::variant 中按类型获取其存储的值。// 编译器在编译时会检查 std::variant 的类型列表是否包含 int。如果包含,它会尝试获取当前存储的 int 值。// 重要提示: 使用 std::get<T>(v) 的前提是你确定 v 当前存储的就是类型 T 的值。如果 v 存储的不是 int,而你尝试用 std::get<int> 去访问,程序会抛出 std::bad_variant_access 异常。std::cout << std::get<int>(v) << std::endl;// v = "Hello";: 再次赋值,这次是一个 const char* 类型的字符串字面量。std::variant 的赋值运算符会隐式地将其转换为 std::string 类型。// 此时,v 的内部状态会切换。它不再存储 int,而是开始存储一个 std::string,其值为 "Hello"v = "Hello";std::cout << std::get<std::string>(v) << std::endl;return 0;
}

在这个例子中,std::variant 可以存储 int、float 或 std::string 类型的值。
6. std::any
std::any 是一个类型安全的容器,可以存储任意类型的值。
#include <any>
#include <iostream>int main() {// std::any,这是 C++17 引入的一个模板类,用于存储任何单个类型的值。它提供了一种类型安全的方式来处理动态类型,而不需要预先指定可能存储的类型列表。// std::any 可以存储任何类型的单个值。std::any a = 10;// std::any_cast<int>(a): 这是一个函数模板,用于从 std::any 中按类型提取其存储的值。// 使用 std::any_cast 时,你必须明确指定你想要获取的类型。编译器会在运行时检查 a 内部存储的类型是否与你请求的类型 (int) 匹配std::cout << std::any_cast<int>(a) << std::endl;// std::any 的赋值运算符会自动管理内部的内存。它会销毁旧的 int 值,然后构造一个新的 std::string 对象来存储 "Hello, world"。此时,a 内部存储的类型变成了 std::string。a = std::string("Hello, world");std::cout << std::any_cast<std::string>(a) << std::endl;return 0;
}

std::any 允许存储不同类型的值,并可以通过 std::any_cast 获取存储的值。
7. std::string_view
std::string_view 是一个轻量级的字符串视图类,可以提供字符串的视图而不拥有字符串的存储。
std::string_view,这是 C++17 引入的一个轻量级类。它的核心思想是 “非拥有”。std::string_view 只是一个对现有字符串的引用 ,它不拥有也不管理字符串的内存。它由一个指向字符串起始位置的指针和一个表示长度的计数组成。
函数的参数类型是 std::string_view。这让 print 函数可以接受任何类型的字符串,只要它能被转换成一个 string_view,而无需进行内存分配或数据复制
好处: 无论传入的字符串有多长,print 函数都只会复制一个 std::string_view 对象(通常是 16 字节),而不是整个字符串数据。这在处理大型字符串时能显著提高性能。
#include <iostream>
#include <string_view>void print(std::string_view sv) {std::cout << sv << std::endl;
}int main() {std::string s = "Hello, C++17!";// print(s);: 调用 print 函数并传入 std::string 对象 s。// 隐式转换: 编译器会在这里将 std::string 对象 s 隐式转换为一个 std::string_view。这个转换非常高效,因为它只创建了一个指向 s 内部数据的视图,没有进行任何数据复制。print(s); // 传递 std::stringprint("Hello, World"); // 传递字符串字面量return 0;
}

std::string_view 可以在不复制字符串的情况下提供对字符串数据的只读访问。
8. std::filesystem
std::filesystem 提供了一组用于操作文件系统的库函数,支持路径操作、文件和目录管理等。
#include <iostream>
#include <filesystem>int main() {// std::filesystem::path 是一个专门用于表示文件系统路径的类。// 它的好处是能够自动处理不同操作系统的路径分隔符(比如 Windows 的 \ 和 Linux 的 /),让你的代码更具可移植性std::filesystem::path path = "/home/ubuntu/interviewQ/71/filesystem.cpp";// std::filesystem::exists() 是一个函数,用来检查给定路径所指向的文件或目录是否存在。// 如果存在,它返回 true;如果不存在,则返回 falseif (std::filesystem::exists(path)) {// std::filesystem::file_size() 函数会返回指定文件的大小,单位是字节。// 它的返回类型是 std::uintmax_t,这是一个足够大的无符号整数类型,可以表示任意大小的文件。std::cout << "File size: " << std::filesystem::file_size(path) << " bytes" << std::endl;} else {std::cout << "File does not exist" << std::endl;}return 0;
}
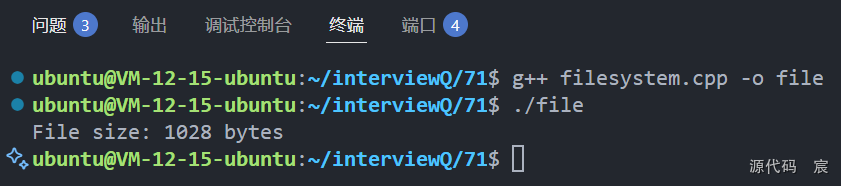
std::filesystem 使得处理文件和目录操作变得更简单和一致。
9. constexpr 的扩展
C++17 扩展了 constexpr 的能力,使其支持更复杂的表达式和控制流,例如 if 语句和循环。
#include <iostream>// constexpr:这个关键字告诉编译器,这个函数 factorial 可以在编译时执行。这意味着,如果函数的参数是编译时已知的常量,那么函数体内的计算也会在编译时完成,而不是等到程序运行时。
constexpr int factorial(int n) {int result = 1;for (int i = 2; i <= n; ++i) {result *= i;}return result;
}int main() {// constexpr int fact5:这里声明了一个 constexpr 类型的变量 fact5。这意味着它的值必须在编译时确定。// factorial(5):因为 5 是一个常量表达式,编译器会调用 factorial 函数,并在编译阶段计算出 5! 的值,也就是 120。// 在最终的编译结果中,fact5 变量将被替换为一个硬编码的常量 120。这等价于你直接写 const int fact5 = 120;constexpr int fact5 = factorial(5); // 在编译时计算// 在这行代码中,fact5 的值已经被编译器计算好了,所以程序运行时直接使用这个常量值,没有任何额外的计算开销。std::cout << "Factorial of 5: " << fact5 << std::endl;return 0;
}

这里的 factorial 函数使用了 for 循环,是 C++17 constexpr 的一个扩展功能。
10. 内联变量(Inline Variables)
C++17 引入了内联变量,允许在多个翻译单元中定义变量而不违反 ODR(One Definition Rule)。
header.h
// header.h
#ifndef HEADER_H
#define HEADER_H// C++17 引入的内联变量 (inline variable) 的代码。它的主要目的是解决在头文件中定义全局变量时可能出现的重复定义问题。
// inline int global_count = 0;: 这一行是整个代码的核心。inline 关键字在这里的作用与在函数上类似,它告诉链接器(linker):“如果我在多个编译单元中看到了这个变量的定义,请将它们视为同一个变量。”
// 重复定义问题: 在 C++17 之前,如果你在头文件中直接定义一个非 const 的全局变量,然后这个头文件被多个 .cpp 文件包含,链接时就会报错,因为每个 .cpp 文件都会生成一个 global_count 的定义,导致链接器无法决定使用哪一个。
// inline 解决了什么: inline 关键字保证了即使 global_count 在多个编译单元中被定义,最终在程序中也只会有一个唯一的 global_count 实例。这允许你安全地在头文件中定义全局变量,而无需担心链接错误。
inline int global_count = 0; // 内联变量#endif
inline.cpp
// main.cpp
// main.cpp
#include "header.h"
#include <iostream>int main() {// #include "header.h": 编译器在这里将 header.h 的内容(包括 inline int global_count = 0;)复制到 inline.cpp 中。global_count++;std::cout << global_count << std::endl;return 0;
}


内联变量 global_count 可以在多个翻译单元中定义且不产生链接错误。
这些新特性使 C++17 更加现代化和强大,为开发者提供了更丰富的工具和更简洁的语法。
ODR(One Definition Rule)

72. 谈谈 Linux中 进程间的通信方式
在 Linux 中,进程间通信(Inter-Process Communication,IPC)是指不同进程之间的数据交换和信号传递。 由于每个进程在自己的地址空间中运行,直接访问彼此的内存是不可能的。因此,Linux 提供了多种 IPC 机制来实现进程间的通信。
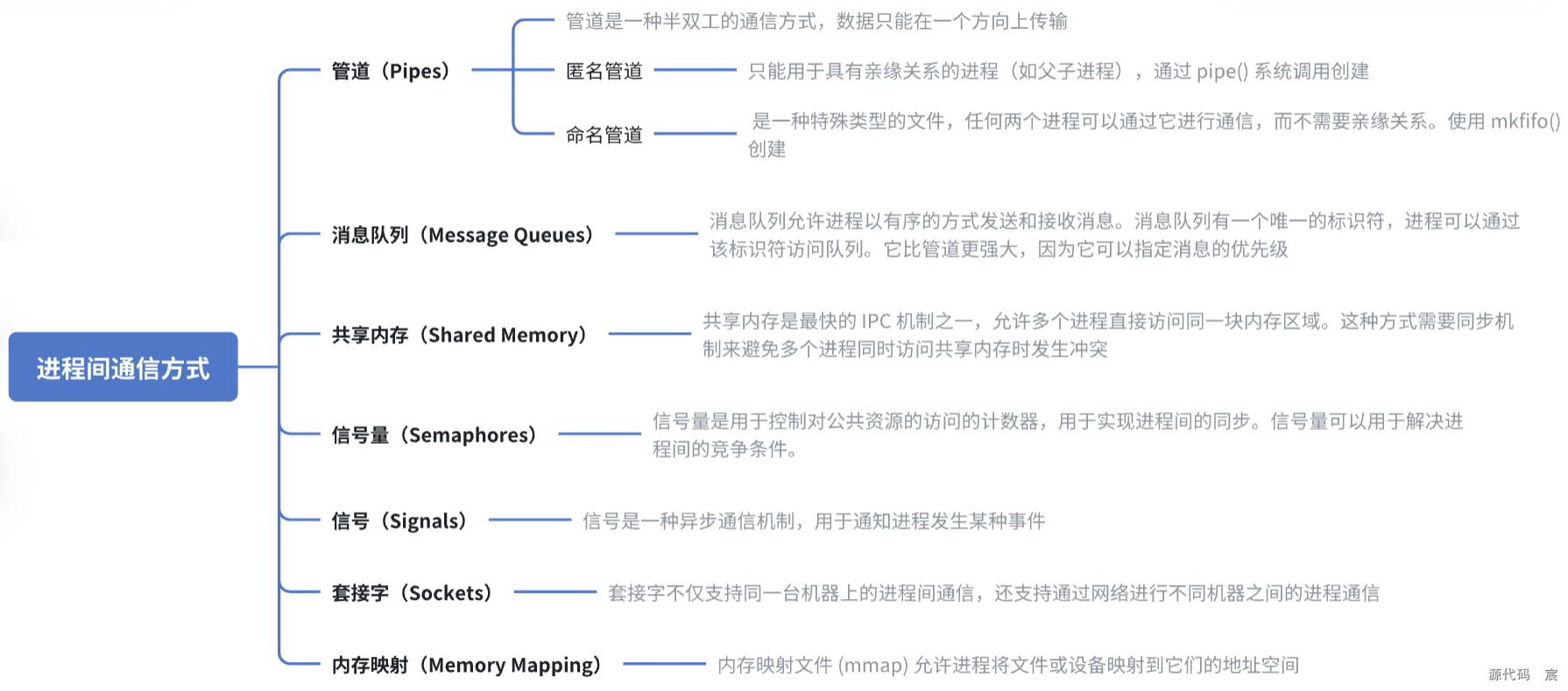
以下是几种常见的 IPC 方式:
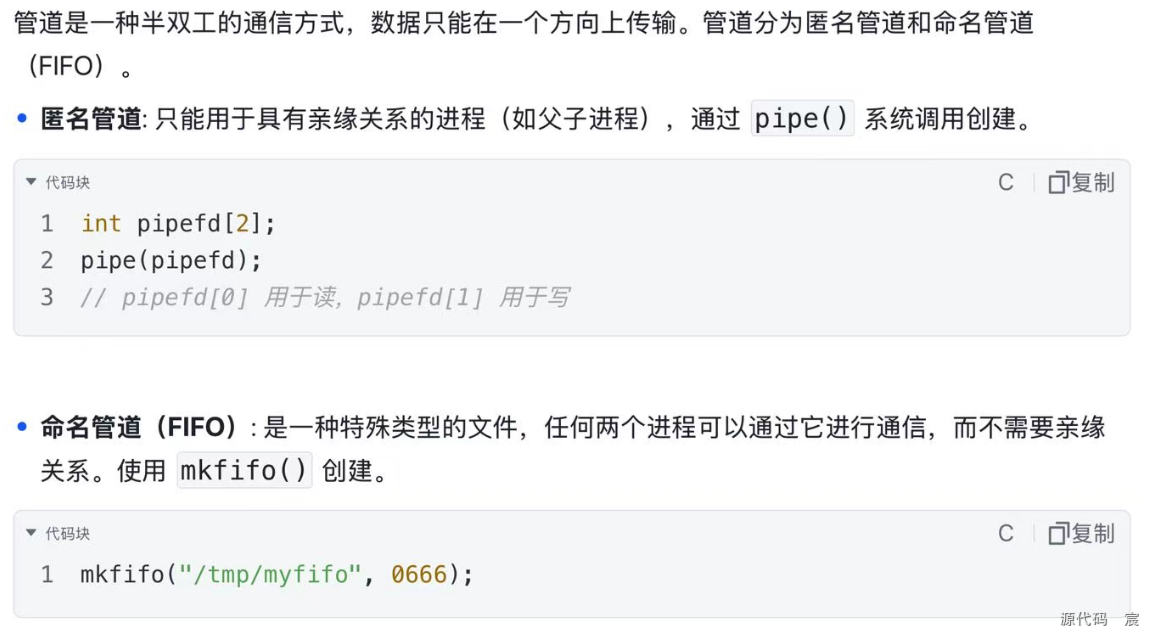
1. 管道(Pipes)
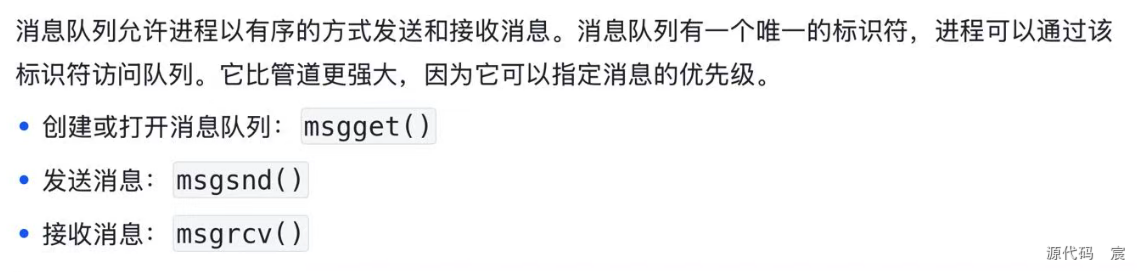
2. 消息队列(Message Queues)
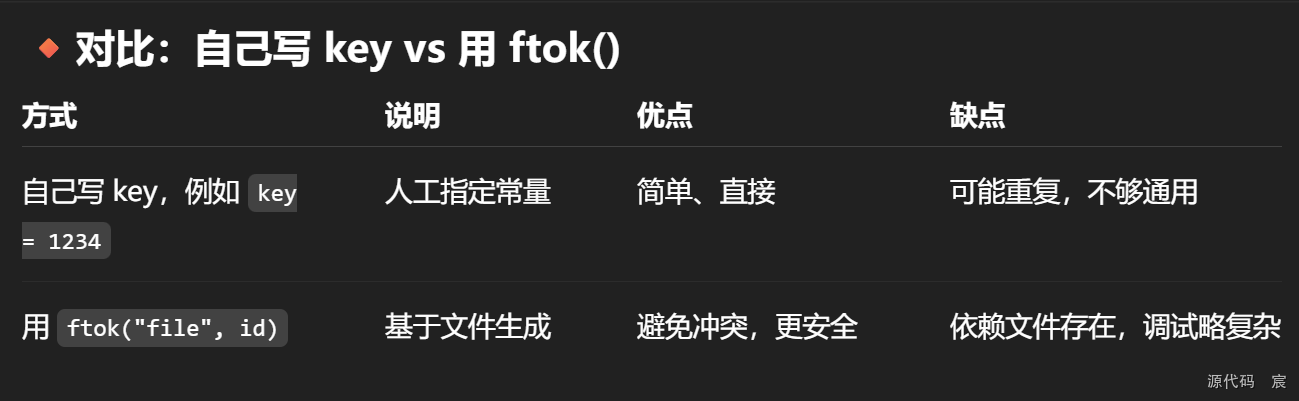
// 使用ftok函数生成一个唯一的键值,该键值用于标识消息队列。
// "file"是一个文件路径,用作生成键值的依据。
// 65是项目的ID,与文件路径一起生成唯一的键值。
// 这两个值结合在一起,系统会利用文件的 inode 编号 + 设备号 + 项目ID 来生成一个较为唯一的 key_t 键值
key_t key = ftok("file", 65); // 使用msgget函数创建一个新的消息队列或访问一个已存在的消息队列。
// key是之前通过ftok函数生成的键值。
// 0666是消息队列的权限设置,类似于文件权限。
// 所有者可读写(0600),
// 群组可读写(0060),
// 其他人可读写(0006)
// IPC_CREAT标志表示如果消息队列不存在,则创建它。
// 成功:返回消息队列ID;
// 失败:返回 -1。
int msgid = msgget(key, 0666 | IPC_CREAT); // 定义一个结构体,用于存储将要发送的消息。
// 这个结构体包含消息的类型和消息文本。
struct msg_buffer { long msg_type; // 消息的类型,用于区分不同的消息 char msg_text[100]; // 消息文本,最大长度为99个字符(最后一个字符留给'\0')
} message; // 初始化消息结构体
message.msg_type = 1; // 设置消息类型为1
strcpy(message.msg_text, "Hello"); // 将消息文本设置为"Hello" // 使用msgsnd函数发送消息到消息队列。
// msgid是消息队列的标识符。
// &message是指向消息结构体的指针。
// sizeof(message)是消息的大小(msg_text)。
// 0是标志位,表示没有特殊的发送选项。
msgsnd(msgid, &message, sizeof(message.msg_text), 0);

什么是 inode 号?
3. 共享内存(Shared Memory)

// 创建一块大小为 1024 字节的共享内存,将字符串 "Hello World" 写入其中
// 使用 ftok() 生成一个用于共享内存标识的 key
key_t key = ftok("shmfile", 65);// 创建或获取一个共享内存段。
// key:上一步生成的 key。
// 1024:请求共享内存大小(单位:字节)。
// 0666:访问权限:
// IPC_CREAT:如果共享内存不存在,则创建它。
// 所有者/群组/其他用户都可读写。
// 成功:返回一个共享内存 ID(shmid)。
// 失败:返回 -1。
int shmid = shmget(key, 1024, 0666 | IPC_CREAT);// 将共享内存段附加(attach)到当前进程的地址空间,从而可以通过普通指针访问它。
// shmid:共享内存段 ID。
// (void*)0:系统自动选择附加地址(一般推荐这样写)。
// 0:默认标志(可读写)。
// 成功:返回共享内存的首地址(指针)。
// 失败:返回 (void*) -1
char *str = (char*) shmat(shmid, (void*)0, 0);// 将字符串 "Hello World" 拷贝到共享内存中
// 此时,其他 attach 到该共享内存段的进程也可以读到这段数据。
// 实际写入的内容是 11 个字符 + \0(共 12 字节)。
strcpy(str, "Hello World");// 将共享内存段从当前进程的地址空间中分离(detach),表示这个进程不再使用它。
shmdt(str);
ftok("shmfile", 65) --> 生成 key|
shmget(key, 1024, IPC_CREAT) --> 创建共享内存段|
shmat() --> 当前进程连接共享内存|
strcpy() --> 写入数据|
shmdt() --> 断开连接(但共享内存还在)
4. 信号量(Semaphores)

// 生成一个唯一的 key。
key_t key = ftok("semfile", 65);// 创建或获取一个信号量集合(即一组信号量)
// key:由 ftok() 生成的键。
// 1:信号量的数量,这里是 1个,用于互斥。
// 0666:权限(所有用户可读写)。
// IPC_CREAT:如果不存在就创建。
// 成功:返回信号量集合 ID(semid)。
// 失败:返回 -1
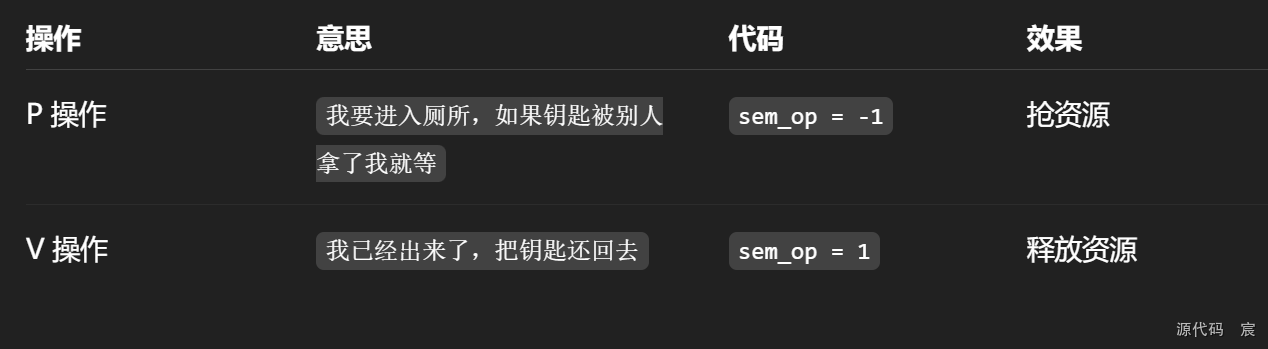
int semid = semget(key, 1, 0666 | IPC_CREAT);// 定义一个 信号量操作结构体,用于指定一次信号量操作
/*
struct sembuf {unsigned short sem_num; // 第几个信号量(从0开始)short sem_op; // 操作值(-1表示P操作,+1表示V操作)short sem_flg; // 标志(通常为0)
};
*/
struct sembuf sb = {0, -1, 0}; // 准备 P操作,等于:我要去拿钥匙// 执行一个或多个信号量操作(本例中只有 1 个)。
/*
semid:信号量集合 ID。
&sb:指向操作结构体的指针。
1:表示我们执行 1 个操作。
*/
semop(semid, &sb, 1); // 执行 P操作(拿钥匙)
// Critical Section
// 我进去了(别人进不来) —— 临界区开始
// 让信号量的值 加 1,相当于“告诉系统:资源释放了,别人可以用了”。
sb.sem_op = 1; // 改成 V操作,等于:我把钥匙还回去
semop(semid, &sb, 1); // 执行 V操作(还钥匙)
// 现在别人可以进去了 —— 临界区结束
5. 信号(Signals)

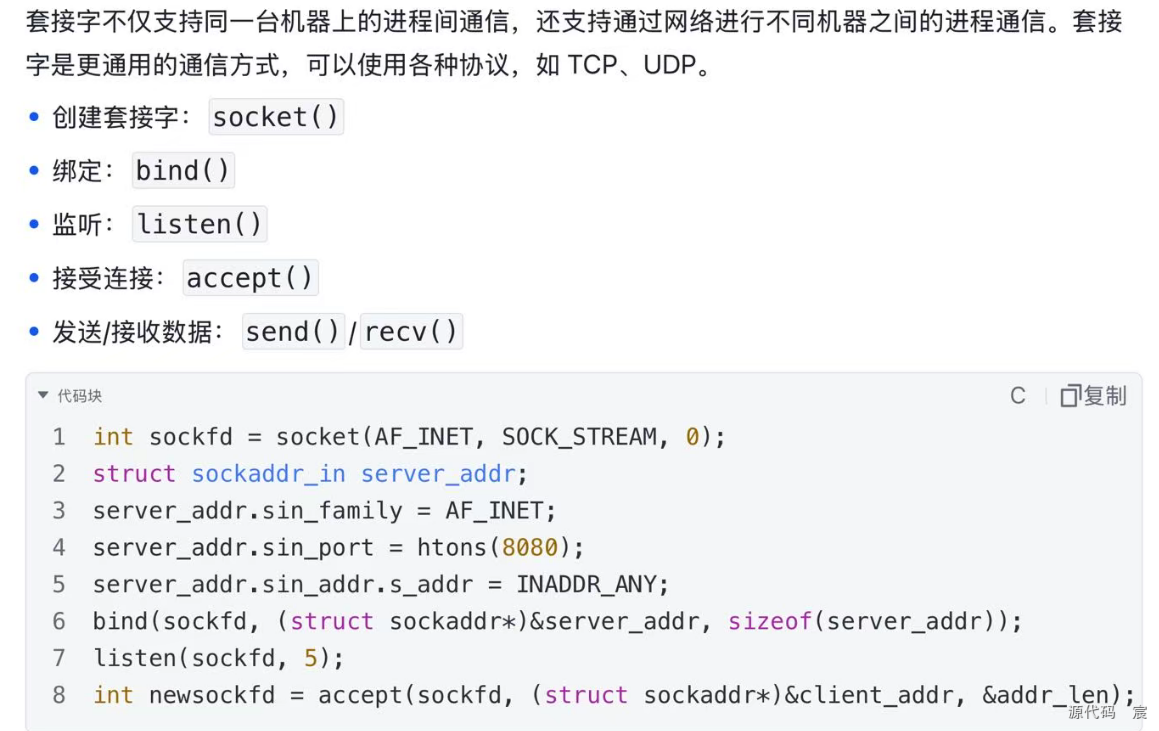
6. 套接字(Sockets)
7. 内存映射(Memory Mapping)

内存映射和共享内存


内存映射(mmap)用于多个进程共享文件内容
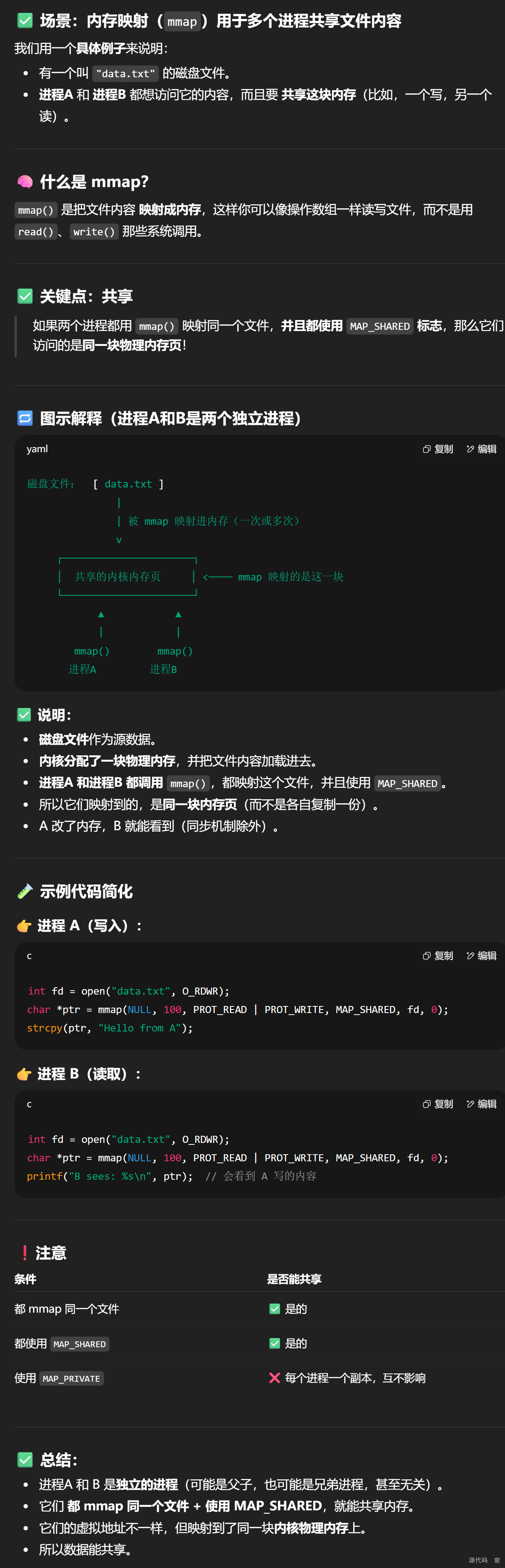
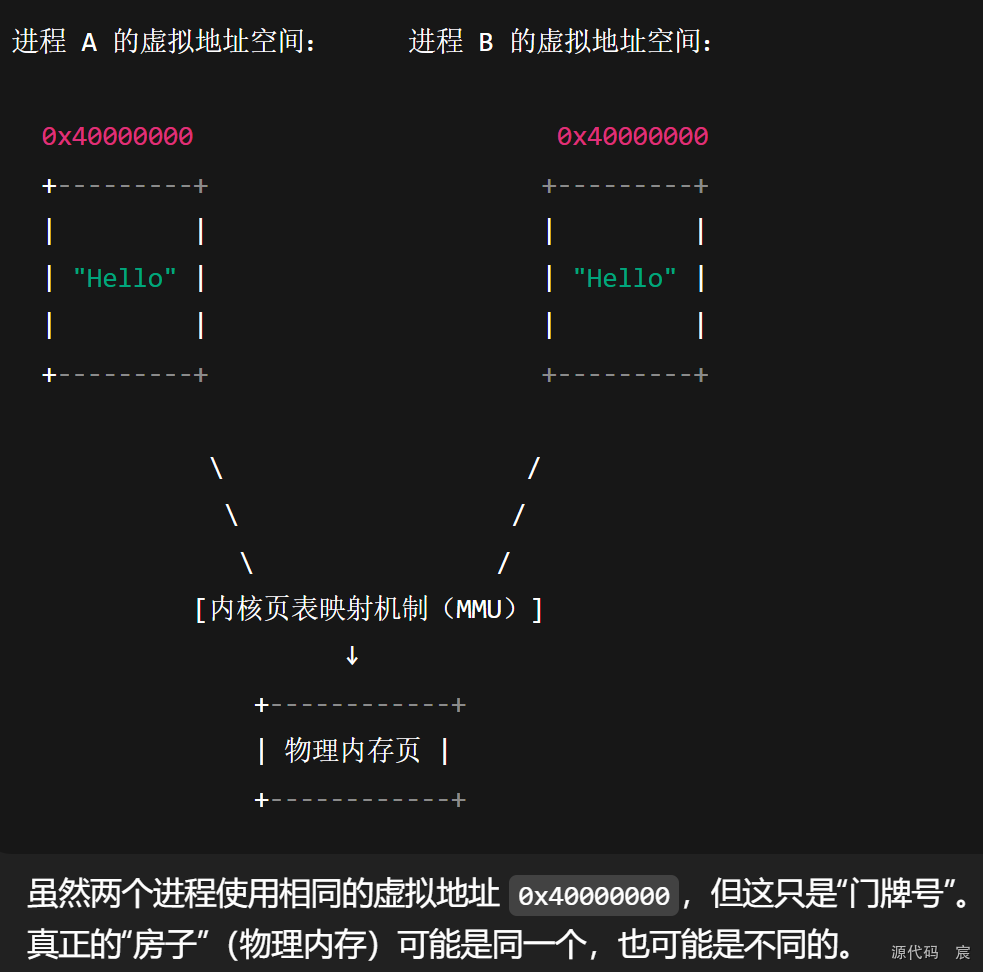
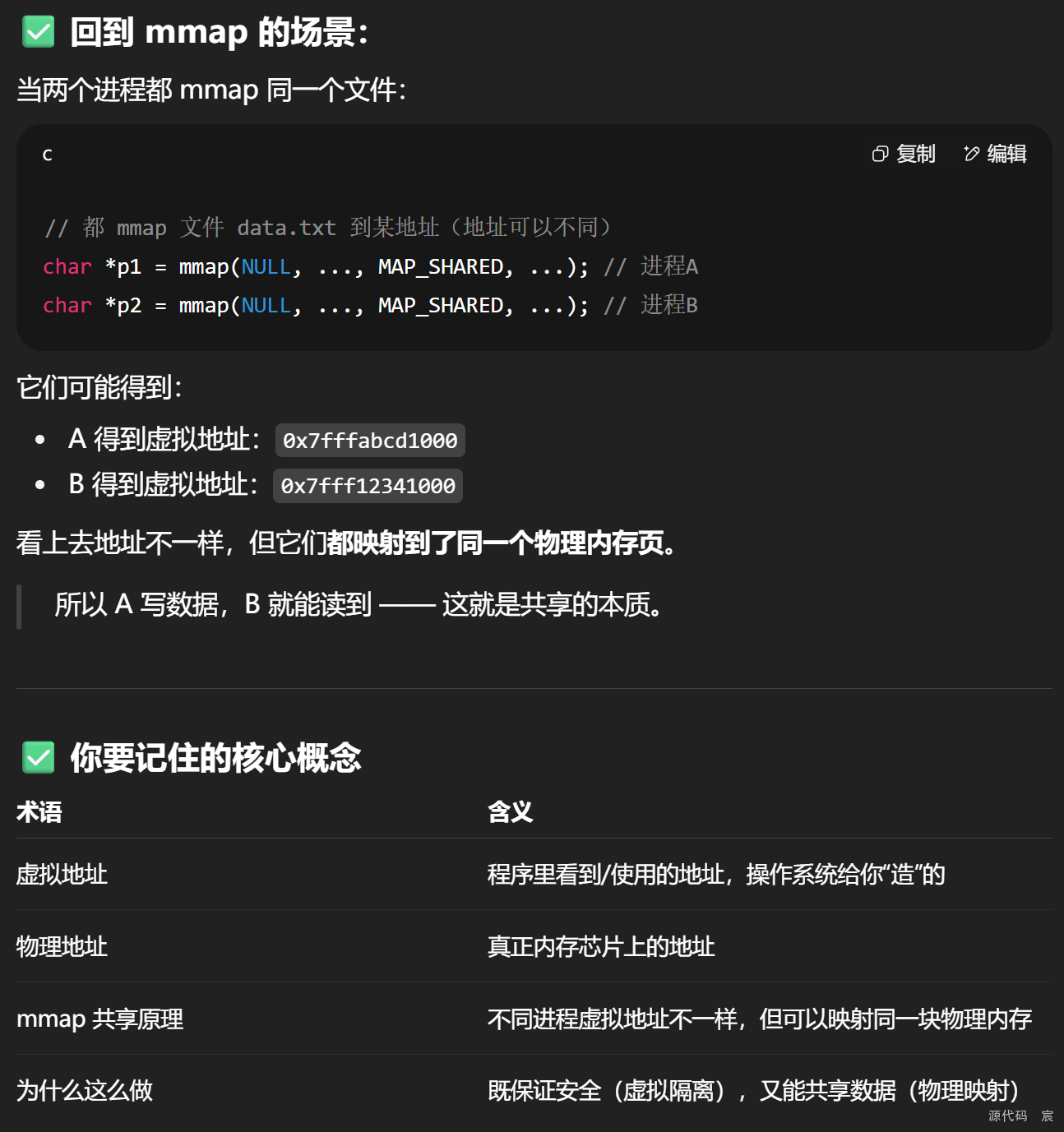
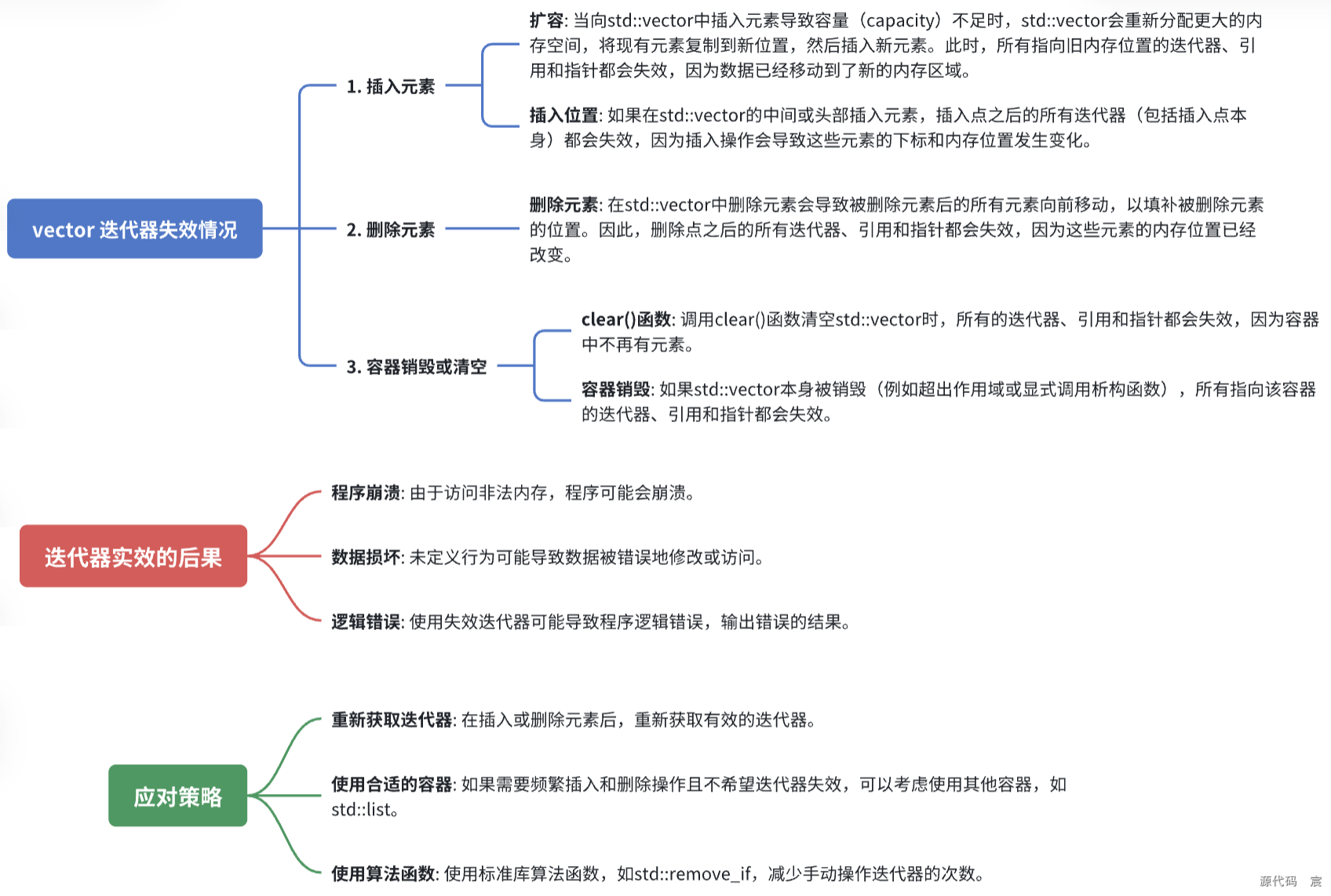
73. vector迭代器什么时候会失效,将导致什么后果。
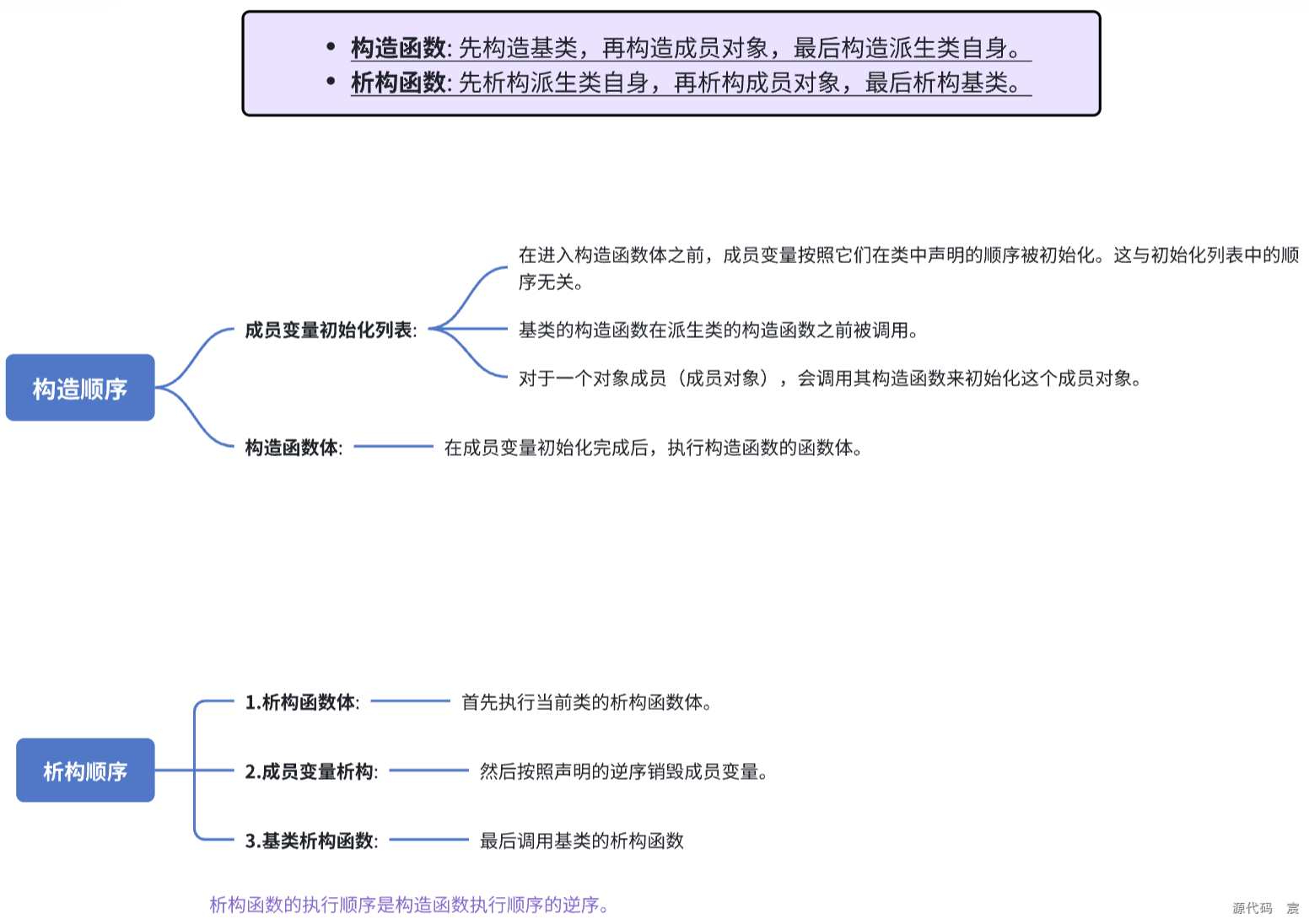
74. 说说析构函数的执行顺序,构造函数的执行顺序
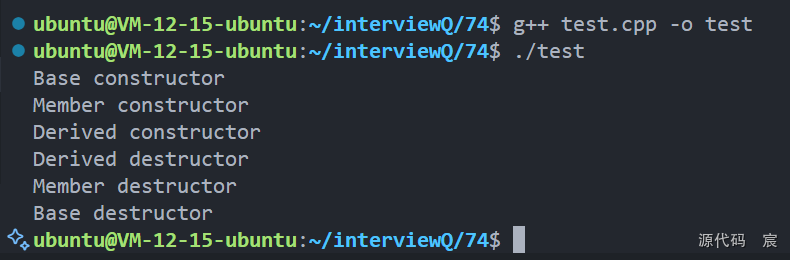
#include <iostream>class Base {
public:Base() { std::cout << "Base constructor\n"; }~Base() { std::cout << "Base destructor\n"; }
};class Member {
public:Member() { std::cout << "Member constructor\n"; }~Member() { std::cout << "Member destructor\n"; }
};class Derived : public Base {Member m;
public:Derived() { std::cout << "Derived constructor\n"; }~Derived() { std::cout << "Derived destructor\n"; }
};int main() {Derived d;return 0;
}/*
在上述代码中,执行顺序如下:
Base构造函数
Member构造函数
Derived构造函数析构函数执行顺序刚好相反
Derived析构函数
Member析构函数
Base析构函数*/
75. 模板的偏特化
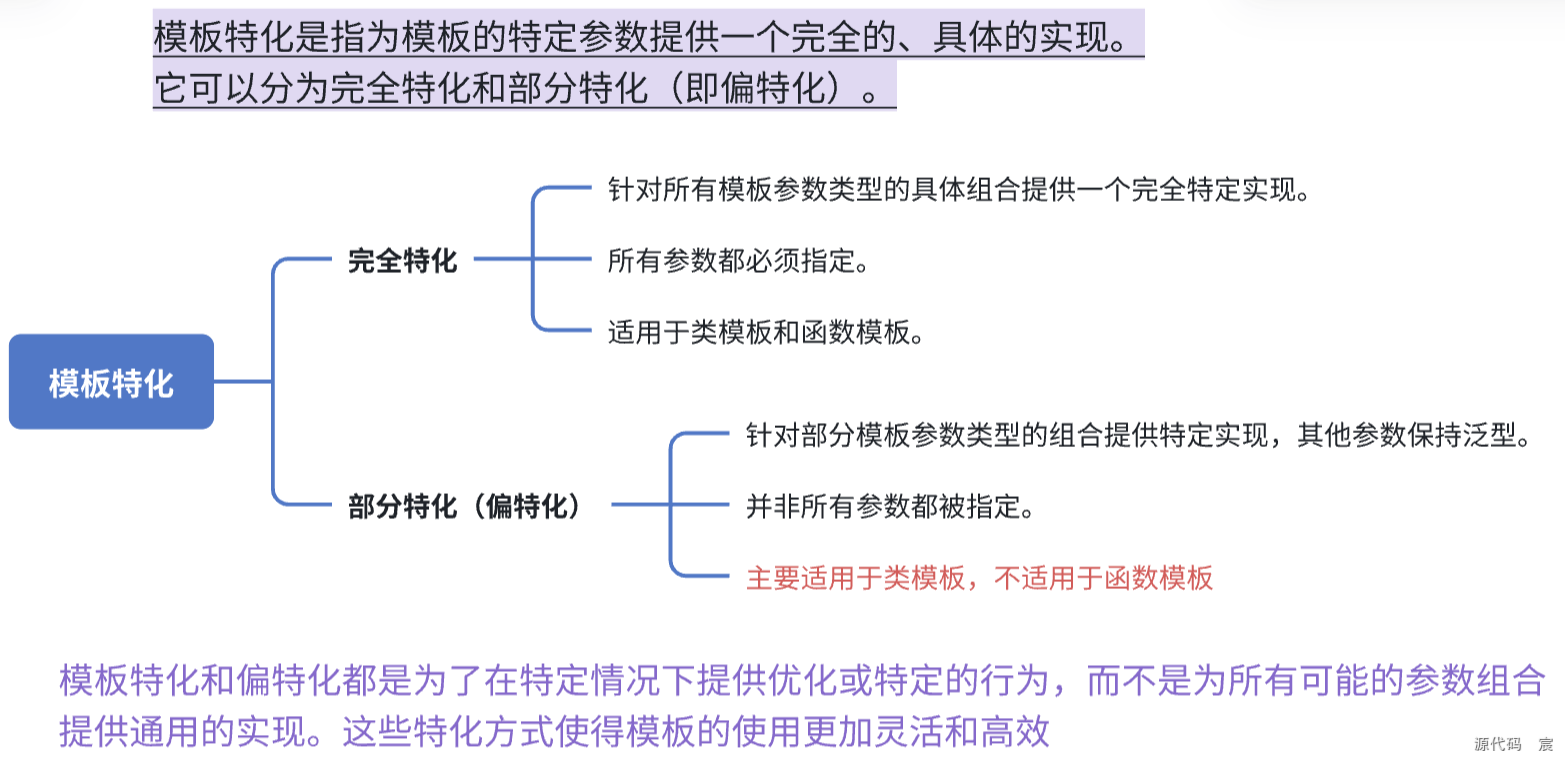
1. 完全特化
完全特化是指为特定的模板参数类型提供一个完全的实现。 所有的模板参数都必须被指定,这意味着没有任何参数保持泛型。
示例:类模板的完全特化
#include <iostream>// 通用模板
// 这个模板适用于 所有类型,比如 MyClass<double>, MyClass<float>, MyClass<char> 等等。
template <typename T>
class MyClass {
public:void show() { std::cout << "General template\n"; }
};// 完全特化:特化为int类型
// template <>:表示完全特化模板。注意:<> 是空的,意味着你在这里为特定类型(int)定制化了一个版本。
// class MyClass<int>:这里定义的是 MyClass 类的特化版本,专门针对 int 类型。
// show() 方法:此特化版本的 show() 方法输出 "Specialized template for int"。
template <>
class MyClass<int> {
public:void show() { std::cout << "Specialized template for int\n"; }
};int main() {MyClass<double> obj1;MyClass<int> obj2;obj1.show(); // 调用通用模板obj2.show(); // 调用完全特化版本return 0;
}

在这个例子中,MyClass<int>是对MyClass模板的完全特化,为int类型提供了特定的实现。
2. 偏特化(Partial Specialization)
偏特化是指为部分指定的模板参数提供特化实现。与完全特化不同,偏特化保留了一部分参数的泛型特性。通常用于类模板,因为函数模板不支持偏特化。
示例:类模板的偏特化
#include <iostream>// 通用模板
template <typename T, typename U>
class MyClass {
public:void show() { std::cout << "Primary template\n"; }
};// 偏特化:当第二个模板参数是int时
template <typename T>
class MyClass<T, int> {
public:void show() { std::cout << "Partial specialization for second parameter int\n"; }
};int main() {MyClass<double, double> obj1;MyClass<double, int> obj2;obj1.show(); // 调用通用模板obj2.show(); // 调用偏特化版本return 0;
}

在这个例子中,MyClass<T, int>是对MyClass模板的偏特化,它特化了第二个模板参数为int的情况。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!