【深度学习机器学习】构建情绪对话模型:从数据到部署的完整实践
目录
前言
一、数据准备:情绪对话模型的基石
1.1 数据来源
1.2 数据审查与质量控制
1.3 去重
1.4 数据集格式
二、模型设计:赋予情绪智能
2.1 模型选择
2.2 输入特征
三、训练与评估:优化模型表现
3.1 训练
3.2 评估
四、部署:让模型落地
4.1 部署方式
4.2 监控与维护
4.3 项目结构图(可视化)
五、生成批量情绪数据执行代码
总结:情绪对话系统 = 数据 + 理解 + 温度

前言
打造一个能够理解和回应人类情绪的对话模型是一项既有趣又复杂的任务。本文将带你逐步了解如何构建这样的模型,涵盖数据准备、模型设计、训练与评估以及部署等环节。我们将以清晰的结构和直观的说明,确保内容易于理解,并通过可视化手段提升效果。
一、数据准备:情绪对话模型的基石
在构建一个能够理解和回应人类情绪的对话系统时,我们不仅需要强大的语言模型,更需要精细化的数据、合理的训练方法与高效的部署策略。本文将以实际项目为例,系统阐述如何构建一个“情绪对话模型”,帮助开发者全面掌握从0到1的关键路径。
数据是任何机器学习项目的核心,对于情绪对话模型尤为重要。数据的质量、多样性和相关性直接影响模型理解和回应情绪的能力。以下是数据准备的详细步骤。
1.1 数据来源
数据质量决定模型上线后的表现。
| 数据来源 | 方式 | 难度 | 是否推荐 |
|---|---|---|---|
| 甲方提供 | 内部数据或平台对话日志 | ✅ 低 | ✅ 推荐 |
| 自主收集 | 手动采集、爬虫、数据接口、AI生成 | ❗ 高 |
情绪对话模型需要反映日常对话中带有情绪色彩的数据。可能的来源包括:
-
甲方提供数据:如果你与客户(如企业)合作,他们可能提供专有数据集,例如客服日志或聊天记录。这是最便捷的方式,但可能存在限制或情绪标注不完整。
-
自行收集数据:自行采集数据成本较高、难度较大,但控制权更高。采集方式包括:
-
手动采集:通过访谈或用户研究收集数据。
-
网络爬虫:从论坛、社交媒体或公开数据集(如微博、X帖子)提取对话。需遵守平台条款和数据隐私法规。
-
数据接口:通过X或其他消息平台的API获取匿名对话数据。
-
AI生成数据:利用高质量API(如某AI的API,详见 https://x.ai/api)生成带有情绪的合成对话。避免使用本地大模型处理数据,因为其效果可能不够稳定。
-
在本项目中,我们采用混合方式:
-
人工指定数据:从一小组种子对话开始,例如:
-
“今天心情不太好。”
-
“推荐一部电影吧。”
-
“怎么才能早睡早起?”
-
“养猫好还是养狗好?”
-
“工作压力好大。”
-
“最近总是失眠。”
-
-
AI扩充数据:使用高质量API基于种子数据生成更多情绪丰富的对话。
1.2 数据审查与质量控制
【✅ 项目选用方式】
本项目数据主要采用两种路径:
✅ 人工指定语料(真实情绪对话)
✅ 基于开源对话数据 + 高质量 API 生成情绪回复
【🔍 数据预处理流程】
1.审查数据合法性
是否为空
是否包含非法字符或敏感信息
是否符合长度限制
2.情绪标注与清洗
标签示例:
{"text": "今天心情不太好", "emotion": "sad"}标注方式:
🤖 使用情绪分类API进行快速打标
🙋 人工复审 & 修正标签
3.去重处理
利用句子相似度(如 BERT embedding + cosine)筛除重复/近似对话:
“怎么了呀,可以给我说说吗?” “怎么了,可以给我说说吗?” “怎么了,能给我说说吗?”
在处理数据之前,需确保数据质量。关键检查包括:
-
非空检查:确保对话内容不为空或不完整。
-
长度要求:验证每条对话是否符合长度标准(例如,10-200字的短对话)。
-
情绪核心词标注:为对话标注情绪关键词(例如,“不好”→负面,“压力”→焦虑)。标注方式:
-
自动化标注:使用NLP工具(如VADER或TextBlob)进行情感分析。
-
人工标注:对于需要人类判断的复杂情绪。
-
可视化建议:使用词云展示数据集中情绪关键词的频率,帮助识别主要情绪和数据覆盖的不足。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例:情绪关键词
emotional_words = ["不好", "压力", "焦虑", "开心", "兴奋"]
wordcloud = WordCloud(width=800, height=400, font_path="SimHei.ttf").generate(" ".join(emotional_words))
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()1.3 去重
重复或近似重复的对话可能导致模型偏差。例如,对于“今天心情不太好”,以下回复几乎相同:
“怎么了?可以跟我说说吗?”
“怎么了?能聊聊吗?”
“出什么事了?想聊聊吗?”
去重方法:
-
相似度比较:使用余弦相似度或Levenshtein距离识别近似重复。
-
工具示例:Python的difflib或sentence-transformers可计算语义相似度。
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
sentences = ["怎么了?可以跟我说说吗?", "怎么了?能聊聊吗?"]
embeddings = model.encode(sentences)
similarity = util.cos_sim(embeddings[0], embeddings[1])
print(f"相似度: {similarity.item():.2f}") # 如果>0.9,视为重复1.4 数据集格式
将数据集标准化为结构化格式(如JSON或CSV),便于处理。示例JSON格式:
[{"dialogue_id": 1,"text": "今天心情不太好。","response": "我在这儿陪你!想聊聊发生了什么吗?","emotion": "负面","core_words": ["不好", "难过"]},...
]二、模型设计:赋予情绪智能
模型需要理解情绪线索并生成适当的回应。基于Transformer的架构(如BERT或GPT)非常适合此类任务,因为它们能捕捉语境细微差别。
2.1 模型选择
预训练模型:从distilbert-base-multilingual-cased或gpt-2等预训练模型开始,利用其语言理解能力。
微调:在情绪对话数据集上进行微调,使模型专注于情绪回应。
定制架构:对于高级项目,可考虑结合情感分析(用于情绪检测)和生成模型(用于回应生成)的混合模型。
情绪对话模型 ≠ 通用聊天机器人,必须具备「情绪理解 + 情绪回应能力」。
✅ 选择思路:
| 模型类别 | 优点 | 缺点 | 推荐使用 |
|---|---|---|---|
| 通用大语言模型(如 Qwen, GPT, DeepSeek) | 语义强,情绪识别准确 | 推理成本高 | ✅ 推理用 |
| 小型微调模型(蒸馏模型) | 成本低,推理快 | 泛化能力弱 | ✅ 部署用 |
🎯 训练目标
-
输入:用户情绪语句
-
输出:合适的情绪安慰或共情回复
示例:
{"input": "我最近一直失眠","label": "睡眠问题很影响心情呢,要不要试试睡前冥想或泡个热水澡?"
}
2.2 输入特征
-
文本输入:用户的对话文本。
-
情绪元数据:将情绪标签或核心词作为额外输入特征,指导模型生成。
可视化建议:绘制训练数据中情绪分布的柱状图,确保数据平衡。
{"type": "bar","data": {"labels": ["负面", "中性", "正面"],"datasets": [{"label": "情绪分布","data": [40, 30, 30],"backgroundColor": ["#FF6B6B", "#4ECDC4", "#45B7D1"],"borderColor": ["#FF6B6B", "#4ECDC4", "#45B7D1"],"borderWidth": 1}]},"options": {"scales": {"y": {"beginAtZero": true,"title": {"display": true,"text": "数量"}},"x": {"title": {"display": true,"text": "情绪类别"}}},"plugins": {"title": {"display": true,"text": "数据集中的情绪分布"}}}
}三、训练与评估:优化模型表现
3.1 训练
-
框架:使用PyTorch或TensorFlow结合Hugging Face的transformers库进行微调。
-
超参数:尝试学习率(如2e-5)、批大小(如16)和训练轮数(如3-5)。
-
损失函数:使用交叉熵损失用于回应生成,并添加辅助损失用于情绪分类。
3.2 评估
-
评估指标:
-
BLEU/ROUGE:衡量回应文本的质量(文本相似度)。
-
情绪准确率:评估模型识别情绪的准确性。
-
人工评估:通过用户研究评估回应的共情度和相关性。
-
-
可视化:绘制训练和验证损失曲线,监控模型收敛。
{"type": "line","data": {"labels": ["第1轮", "第2轮", "第3轮", "第4轮"],"datasets": [{"label": "训练损失","data": [0.5, 0.3, 0.2, 0.15],"borderColor": "#FF6B6B","fill": false},{"label": "验证损失","data": [0.6, 0.4, 0.25, 0.2],"borderColor": "#4ECDC4","fill": false}]},"options": {"scales": {"y": {"beginAtZero": true,"title": {"display": true,"text": "损失值"}},"x": {"title": {"display": true,"text": "训练轮数"}}},"plugins": {"title": {"display": true,"text": "训练与验证损失曲线"}}}
}四、部署:让模型落地
4.1 部署方式
-
云端部署:使用Flask或FastAPI在AWS或Heroku上部署为REST API。
-
移动应用:通过TensorFlow Lite集成到iOS/Android应用。
-
Web界面:使用React和Tailwind CSS开发简单的Web应用供用户交互。
| 方式 | 特点 | 适合场景 |
|---|---|---|
| 本地服务 + API 网关 | 控制权强 | 内网产品接入 |
| 云函数 + 大模型接口(如通义、文心) | 维护简单,延迟稍高 | SaaS、轻量级产品 |
| 微服务容器(如 FastAPI + GPU 服务) | 可弹性伸缩 | 对话类 APP |
🔒 安全与合规
-
对话日志存储加密
-
情绪过激内容自动触发报警/人工干预机制
-
模型输出加入审查机制(内容规避)
示例部署代码(Flask API):
from flask import Flask, request, jsonify
from transformers import pipelineapp = Flask(__name__)
model = pipeline("text-generation", model="your-fine-tuned-model")@app.route("/chat", methods=["POST"])
def chat():user_input = request.json["text"]response = model(user_input, max_length=50)[0]["generated_text"]return jsonify({"response": response})if __name__ == "__main__":app.run(debug=True)4.2 监控与维护
-
用户反馈:收集用户反馈以改进回应。
-
模型更新:定期用新数据重新训练,保持模型相关性。
-
可视化:使用Streamlit等工具创建仪表板,监控API使用情况和回应质量。
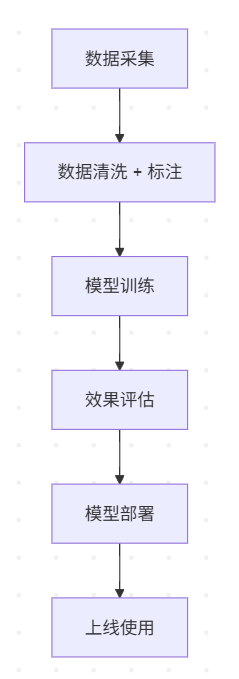
4.3 项目结构图(可视化)
五、生成批量情绪数据执行代码
【替换片段】
ZHIPUAI_API_KEY = os.getenv("ZHIPUAI_API_KEY", "your-api-key")▲your-api-key:替换为“智谱”的APIkey,到官网申请(智谱AI开放平台);
# 批量情绪对话数据生成器
import os
import random
import json
from zhipuai import ZhipuAI# 你的 API KEY(建议通过环境变量或安全方式获取)
ZHIPUAI_API_KEY = os.getenv("ZHIPUAI_API_KEY", "your-api-key")
client = ZhipuAI(api_key=ZHIPUAI_API_KEY)# 情绪主题池(可扩展)
emotional_themes = ["孤独", "焦虑", "失落", "愤怒", "开心", "压抑", "悲伤", "烦躁", "无助", "焦躁"
]# 用户输入句子模板池(可扩展)
user_templates = ["我最近总是感觉{emotion}","你有没有过那种{emotion}的时候?","{emotion}的情绪太折磨人了","我不知道怎么面对这样的{emotion}","{emotion}是种怎样的体验?"
]# 励志、安慰、共情类回复(从LLM中生成)
def generate_response(user_input):prompt = f"你是一个善解人意、富有情感的AI助手,用户说:'{user_input}',请你用温柔的语气进行共情、安慰或鼓励。"response = client.chat.completions.create(model="glm-4",messages=[{"role": "user", "content": prompt}])return response.choices[0].message.content.strip()# 主函数:生成指定数量的样本
def generate_emotional_dialogues(n_samples=100, output_file="emotion_data.jsonl"):dataset = []for _ in range(n_samples):emotion = random.choice(emotional_themes)user_input = random.choice(user_templates).format(emotion=emotion)assistant_response = generate_response(user_input)sample = {"emotion": emotion,"user": user_input,"assistant": assistant_response}dataset.append(sample)# 保存为 JSONL 文件with open(output_file, "w", encoding="utf-8") as f:for item in dataset:f.write(json.dumps(item, ensure_ascii=False) + "\n")print(f"✅ 共生成 {len(dataset)} 条情绪对话数据,保存至: {output_file}")if __name__ == "__main__":generate_emotional_dialogues(n_samples=100)
总结:情绪对话系统 = 数据 + 理解 + 温度
一个优秀的情绪对话系统背后,是数据理解的精度 + 模型设计的温度 + 工程落地的稳定。随着大模型推理能力提升,我们可以更加轻量、柔性地为用户提供真正“共情”的AI对话体验。
构建情绪对话模型是一段融合数据科学、自然语言处理和用户体验设计的旅程。通过精心准备数据、设计强大模型、有效训练和评估以及周密部署,你可以打造一个真正与用户产生情感共鸣的系统。词云、柱状图和损失曲线等可视化工具不仅提升理解,还使过程更直观有趣。
准备好了吗?开始收集数据,尝试不同模型,让你的情绪对话系统活起来吧!