VN1 供应链销量预测建模竞赛技巧总结与分享(七)
文章出自:VN1 Forecasting Competition — What I Learned from the Best Forecasters
本篇文章通过分析VN1预测竞赛,总结了最佳预测者的经验。
技术亮点在于强调了“快速实验”和“模型评估”的重要性,特别是轻量级梯度提升机(LGBM)在准确性和速度上的优势。
SupChains技术团队的相关文章还有:
- SupChains技术团队零售产品销量预测建模方案解析(一)
- SupChains技术团队回答:模型准确率提高 10%,业务可以节省多少钱?(二)
- SupChains团队: 衡量Forecast模型结果在供应链团队内的传递质量(三)
- SupChains团队:供应链数据的异常特征管理指南(四)
- SupChains技术团队:需求预测中减少使用分层次预测(五)
- SupChains团队:全局机器学习模型在需求预测中的应用(六)
文章目录
- 1 VN1 预测竞赛
- 1.1 朴素预测可以击败基础模型
- 1.2 核心技能:评估模型
- 2 顶尖参赛者的见解
- 3 分不同等级的模型
- 3.1 D 级
- 3.2 C 级
- 3.3 B 级
- 3.4 A 级
- 4 模型融合
- 5 结论
1 VN1 预测竞赛
我非常荣幸地在 2024 年 9 月至 10 月期间主办了 VN1 预测竞赛,约有 250 名参赛者(或团队)积极参与。本次竞赛的目标是预测不同电商供应商未来 13 周的销售额(总计约 15,000 种组合;数据集由我们的三家赞助商之一 Flieber 提供)。
竞赛分为两个阶段;第一阶段是热身赛,参赛者可以尝试不同的模型,查看他们的分数,并与其他参与者进行比较,
而第二阶段是真正的竞赛,参赛者只能提交一组预测结果,并且在最终截止日期之前无法看到他们的分数。

你可以在这里下载数据集。
随着竞赛的结束,我花时间收集了前 20 名参赛者的见解。我很高兴能与他们讨论他们的方法、遇到的困难和解决方案。随后,在 11 月,我主持了一场网络研讨会,前 5 名获胜者在会上分享了他们的方法。
在本文中,我将分享我从本次竞赛中获得的经验教训。
技术说明:提交结果的质量通过“分数”(分数 = MAE% + |Bias%|)进行评估,这是我为所有客户实施的一个指标,因为它在指标复杂性和业务价值之间提供了极佳的权衡。你可以在我的书籍《供应链预测数据科学》和《需求预测最佳实践》中相关内容。
免责声明:我的大部分心得体会都基于前 20 名参与者的自述信息以及我与他们的对话。尽管我已尽最大努力,但部分信息可能在传达过程中有所遗失或被误解。
1.1 朴素预测可以击败基础模型
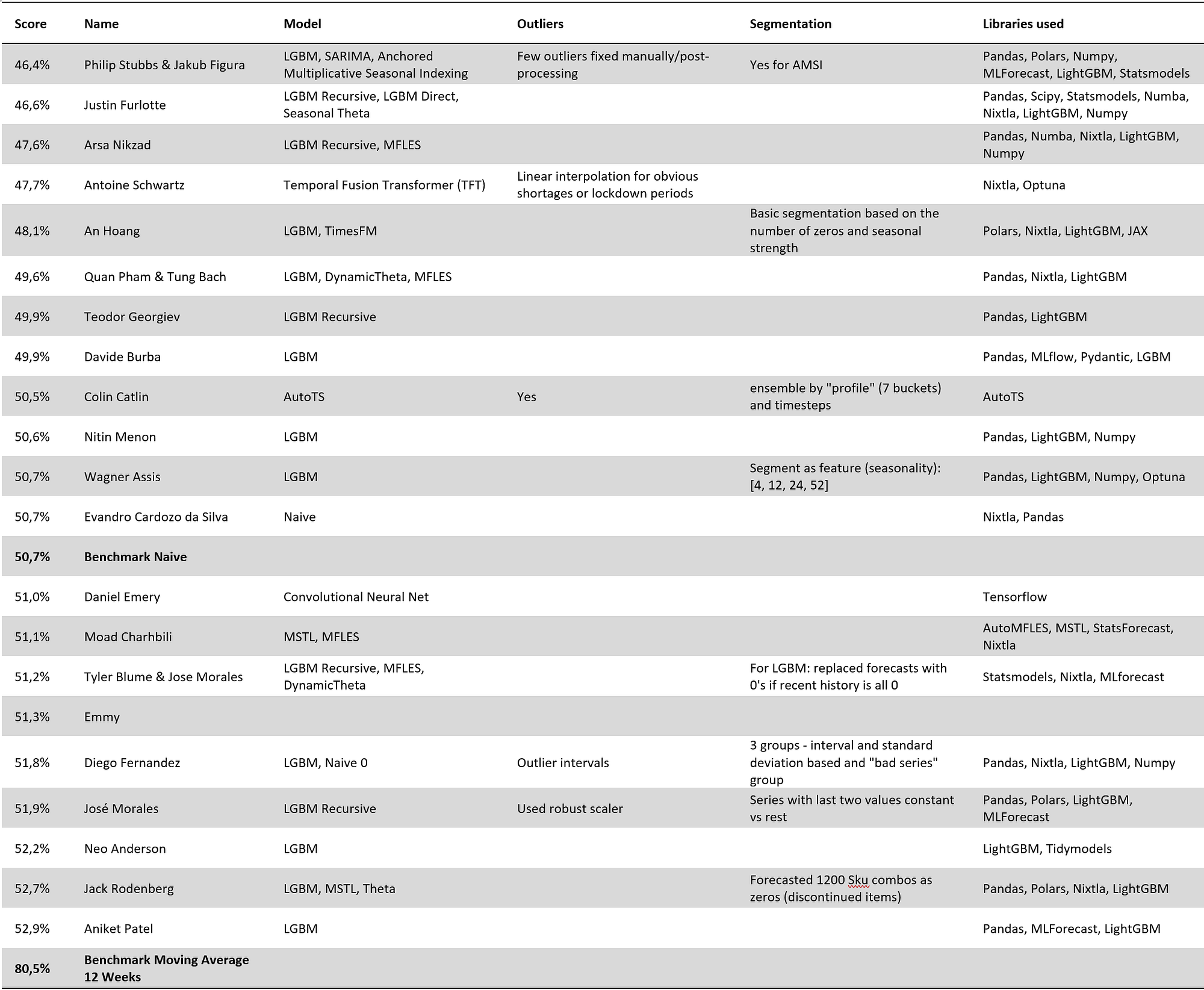
在竞赛设置中,我为参赛者提供了一个基准函数来生成 12 周移动平均线。大多数参赛者都能击败它(在第二阶段,基准模型取得了 80.5% 的分数,而前 20 名参赛者的分数都低于 53%)。但竞赛的主要惊喜是,只有少数参赛者能击败朴素预测,朴素预测取得了 50.7% 的分数。
由于季节性因素,朴素预测在第二阶段比移动平均线产生了更好的预测结果:移动平均线包含了第一阶段的年末销售额,这导致了第二阶段的过度预测。如果结果在几周后进行评估,朴素预测不太可能表现得如此出色。
一位参赛者理解了这一点,在尝试了多种模型后,勇敢地坚持使用朴素预测,并取得了第 12 名。
没有人通过随意提供朴素预测就在 VN1 中取得好成绩:顶尖参赛者在选择最终解决方案之前尝试了多种模型。**理解像朴素预测这样简单的解决方案能带来良好结果,需要技巧和知识。**评估朴素预测的价值并非显而易见:在 250 多名参与者中,只有一人通过分析得出结论,朴素预测比(大多数)其他方法提供了更好的准确性。
请注意,朴素预测击败移动平均线是(极其)不寻常的。这就是为什么我建议不要使用朴素预测作为基准,因为它们太容易被击败了。
1.2 核心技能:评估模型
根据我对顶尖参赛者的采访,他们的主要技能是能够轻松评估、微调和选择模型。他们中的大多数人尝试了不同的方法、特征和参数——没有人仅仅是幸运地尝试了一个默认成功的模型。
这里的关键是使用稳健的测试框架快速迭代(这意味着如果一个模型在你的设置中能带来良好结果,它在未来也很可能带来良好结果)。
2 顶尖参赛者的见解
让我们先从一些见解开始,然后讨论参赛者使用的模型类型。
- 工具。除了一个人之外,所有顶尖参赛者都使用 Python 编程语言(及其多个库)来分析数据并创建预测。没有人报告使用 Excel、VBA、Matlab 或 SQL。大多数参与者使用 Pandas(Python 中的一个库)来处理数据(少数人选择 Polars,一个更快但鲜为人知的替代方案),一半的人报告使用 Nixtla 的模型或实用函数。
我给任何想进行大规模预测的人的建议是学习 Python 并跳过 Excel、VBA、Matlab 和 SQL。 - 异常值检测。只有两名参与者报告了标记异常值。我个人不使用任何统计方法来标记异常值,我也不建议我的客户这样做。
- 短缺和零值。三名参与者报告了标记短缺或生命周期结束的产品。不幸的是,竞赛没有使用库存数据来自动标记短缺,因此我们无法证明使用库存数据的重要性。我将尽最大努力将其纳入我的下一次竞赛(VN2)。即使我的客户不向我提供他们的历史库存数据,我仍然会花时间标记短缺和生命周期结束:简单的方法通常能提供切实的附加价值。
- 聚类。一些参与者对产品进行了聚类。最常见的是,聚类是基于季节性模式。
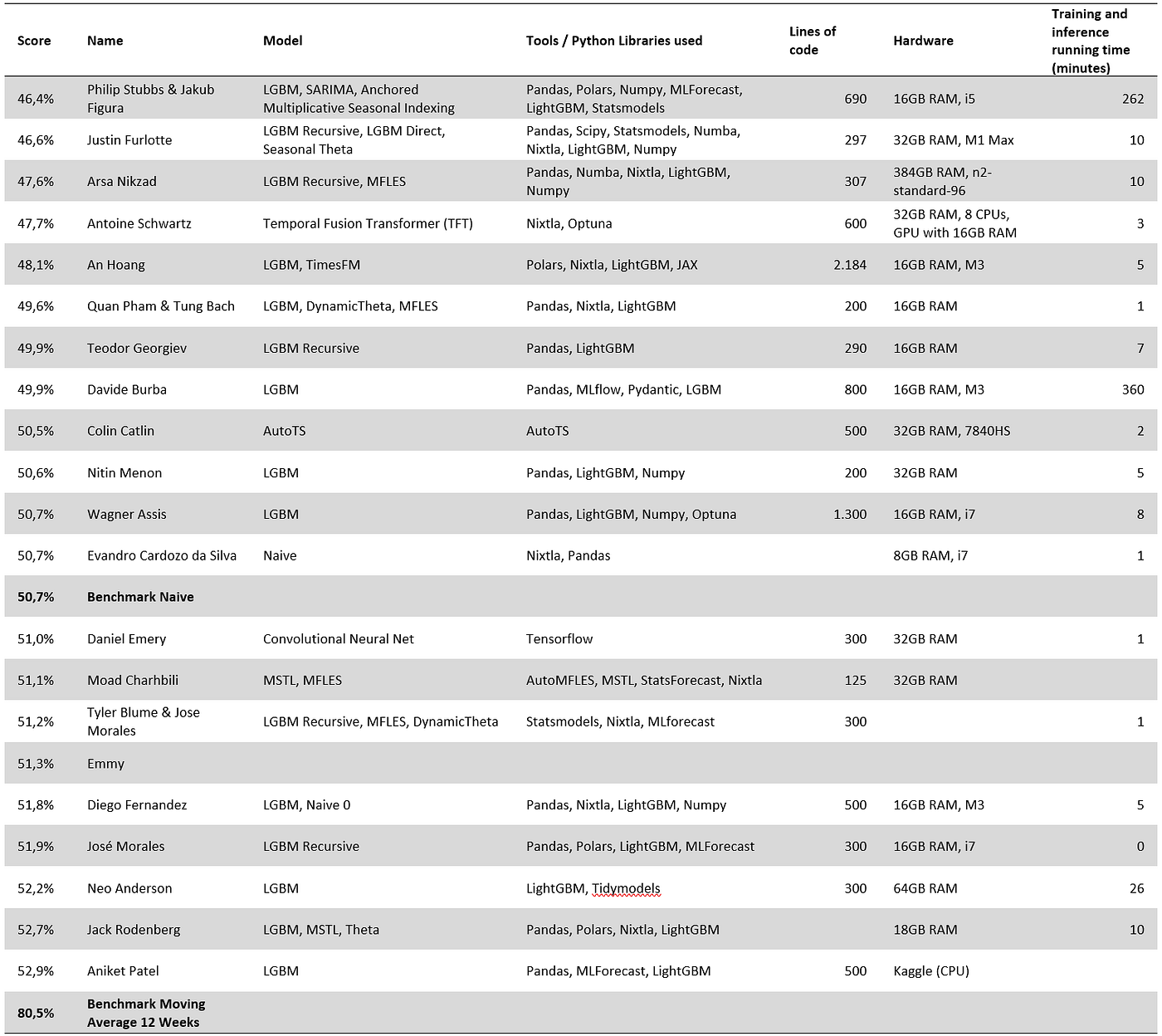
- 代码复杂性。一半的参与者在不到 300 行代码内交付了解决方案。这突出表明,如果你知道自己在做什么,你可以用很少的复杂性交付高价值。代码复杂性还取决于所使用的库以及参与者是否包含了优化模型所需的代码。
在实时环境中将模型投入生产可能还需要更多的代码来增强鲁棒性并应对大多数边缘情况。此外,参与者收到了结构化数据,无需处理促销和短缺。 - 运行时间。几乎所有解决方案都能在 10 分钟内提供预测——机器学习确实很快。只有两个团队报告了更长的运行时间。获胜团队由于使用了 ARIMA(一个出了名的慢模型——我稍后会再谈到这一点),在 4 小时 30 分钟内提供了预测。第二个“慢”模型是因为参与者通过集成其模型 30 次来挤出额外的准确性(换句话说,他运行了他的模型 30 次)。
- 参数优化。大多数机器学习模型都需要超参数调优。然而,一些参赛者坚持使用其模型的库默认值,而另一些则花费了长达 200 小时的交叉验证时间来优化它们。令人惊讶的是,使用默认值对某些模型的准确性影响不大。
特征工程似乎比参数优化更重要。
3 分不同等级的模型
VN1——像大多数数据科学竞赛一样——是一场社交竞赛:人们分享想法和笔记本并进行交流。因此,最终在竞赛中使用的模型具有有机性。很可能如果有人在第一天分享了一个达到合理分数的笔记本,许多参赛者都会使用它。参赛者时间有限,所以如果他们找到一个有效的方法和一个即用型笔记本,他们就会使用它。
我将使用的(或未使用的)模型从 D 级(最差)到 A 级(最佳)进行了分类。

VN1 中的预测模型
3.1 D 级
如果前 20 名中没有人使用这些模型,我将其归类为 D 级。
- Facebook Prophet(及其神经版本)。Facebook Prophet 在过去几年中已被揭示为一种糟糕的供应链需求预测模型。然而,你仍然经常在互联网上看到人们提倡它(或将其用作基准)。前 20 名中没有人使用它,我也不建议我的任何客户使用它。
- XGBoost 和 CatBoost 没有被前 20 名中的任何人使用。在提升树方面,所有参与者都更喜欢 LGBM 的实现。根据我的经验,XGBoost 提供了与 LGBM 相似的性能,但通常(但并非总是)更慢。另一方面,根据我有限的经验,CatBoost 的可靠性较低。
- 前 20 名中没有人使用指数平滑模型(又称 Holt-Winters)的“常规”实现。我个人喜欢这些模型:它们易于理解、易于大规模实现,并且如果适当调整,可以提供相对良好的结果。
- 神经网络。没有人使用简单的(前馈多层)神经网络。不幸的是,这些模型运行速度相对较慢,同时需要大量的超参数调优。在 SupChains,我们自 2019 年以来就没有使用神经网络来预测需求。
3.2 C 级
C 级模型是那些很少被使用,通常只作为集成模型一部分的模型。
- ARIMA 仅被一个团队(获胜团队)使用,导致该团队运行时间过长(4 小时 30 分钟),而其他解决方案在不到 10 分钟内运行完毕。我不使用 ARIMA,也不建议我的客户使用它(实际上,我曾指导多家公司放弃 ARIMA):它极其缓慢,除了 VN1 的这个结果之外,我从未见过 ARIMA 在我见过的任何供应链数据集上与常规指数平滑相比能带来价值。此外,ARIMA 难以处理零值(它们在供应链中无处不在),并且很难理解短缺和促销。请注意,获胜团队在模型集成中使用了 ARIMA,其中 ARIMA 仅占整体集成的 30%。
- 一名参与者使用了自动化时间序列机器学习框架(AutoTS)。尽管需要 180 小时的优化时间和比大多数其他解决方案更多的代码行,但它的表现并不特别出色。我不会建议我的客户使用 ML 自动化框架:它太慢了,而且通常不会产生准确的预测。
- 最后,一名参赛者使用了卷积神经网络。
3.3 B 级
这些是已被多个参赛者证明具有附加价值的最佳模型。
- 两名参赛者使用 Transformer 模型来预测需求,这是一种新型模型,据我所知,这是首次在此预测竞赛中使用。我们很可能会在接下来的竞赛中看到越来越多的 Transformer 模型。
- 20 名参赛者中有 4 名使用了 Theta 模型,该模型可追溯到 2000 年代初期。Theta 在 M3 竞赛中获得冠军后声名鹊起。对于 VN1,Nixtla 的 DynamicTheta 实现似乎获得了很大的关注,并以很少的计算时间取得了很好的结果。
据我所知,Theta 在 M5 或 Intermarché 竞赛中没有被(成功地)使用。因此,目前尚不清楚 Theta 是强势回归,还是恰好在这个特定数据集上表现良好。
3.4 A 级
最佳中的最佳:Light Gradient Boosted Machine (LGBM)!大多数顶尖参赛者都使用了它,报告了良好的准确性和快速执行。LGBM 已被许多参与者在之前的预测竞赛(M5 和 Intermarché)中使用,它也是我们 SupChains 最喜欢的模型。我建议它也应该成为你预测工作的核心。
4 模型融合
最后,大多数参赛者都依赖于融合(不同)模型:他们不是坚持使用单一模型,而是结合了不同模型的预测。他们还结合了同一模型的不同实例:由于大多数机器学习模型本质上是随机的,你可以平均 10 或 100 个使用相同底层模型的预测(许多参与者使用 LGBM 采用了这种技术)。
集成模型几乎可以保证带来更好的结果;它就像免费的午餐一样。
5 结论
VN1 预测竞赛中大多数顶尖参赛者的成功可归因于几个关键因素:
- 结构化的模型评估框架 — 建立清晰系统的模型性能评估框架对于选择最佳预测方法至关重要。如果你无法正确评估模型的质量,你就无法制作出优秀的预测工具——就这么简单。
- 快速实验 — 快速迭代的能力使参赛者能够尝试更多模型,选择更好的特征,并更有效地微调他们的模型。
- 模型探索 — 顶尖表现者在选择最终方法之前测试了各种模型和技术。
- 特征工程 — 创建、测试和选择有意义的特征被证明是实现卓越预测准确性的主要区别因素。
- LGBM — LightGBM 成为主导模型,提供出色的准确性和速度,同时易于使用。
- 融合不同的解决方案