29-数据仓库与Apache Hive-创建库、创建表
1.使用hivesql创建数据库
1.1 SQL中的DDL
create drop alter 三个组成
DDL不涉及表内部的操作
DDL主要做什么? 对数据库内部的对象进行创建、删除、修改

1.2 HiveSQL Hive SQL(HQL)与标准SQL的语法大同小异,基本相通;
基于Hive的设计、使用特点,HQL中create语法(尤其create table)将是学习
掌握Hive DDL语法的重中之重。建表是否成功直接影响数据文件是否映射成功,
进而影响后续是否可以基于SQL分析数据。通俗点说,没有表,表没有数据,
你用Hive分析什么呢?选择正确的方向,往往比盲目努力重要。 1.3数据库database
在Hive中,默认的数据库叫做default,存储数据位置位于HDFS的/user/hive/warehouse下。
用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。1.3.1 create database
create database用于创建新的数据库
COMMENT:数据库的注释说明语句
LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db
WITH DBPROPERTIES:用于指定一些数据库的属性配置。

创建好数据库以后去hdfs上查看一下!!!
1.4创建表

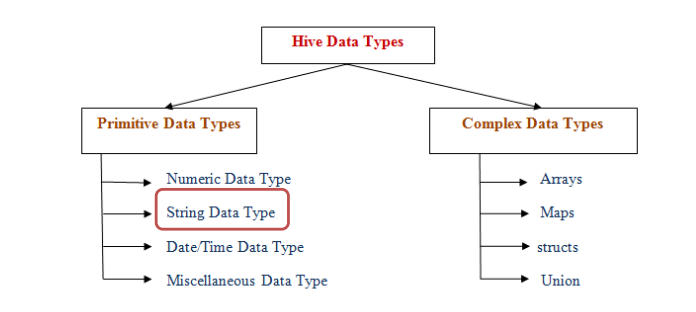
1.4.1数据类型
Hive数据类型指的是表中列的字段类型;
整体分为两类:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
最常用的数据类型是字符串String和数字类型Int。
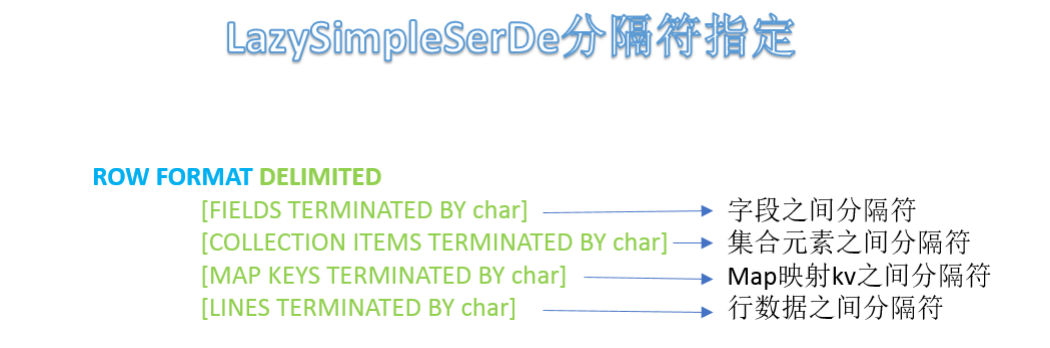
1.4.2分隔符指定语法
ROW FORMATDELIMITED语法用于指定字段之间等相关的分隔符,这样Hive才能正确的读取解析数据。
或者说只有分隔符指定正确,解析数据成功,我们才能在表中看到数据。1.4.3分隔符指定语法LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射kv之间、换行的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。
1.4.4 ive默认分隔符
Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
默认的分割符是’\001’,是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的。
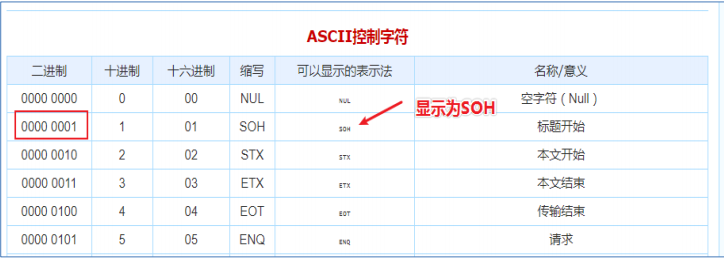
SOH 字符需要使用notepad++ 工具才能看到
-- 2.创建表
create table t_archer(
id int comment 'ID',
name string comment '英雄名称',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',role_assist string comment '次要定位'
) comment '王者荣耀射手信息表'
row format delimited
fields terminated by '\t';1.5使用hdfs暴力导入数据
1.6作业
作业: 文件team_ace_player.txt中记录了手游《王者荣耀》主要战队内最受欢迎的王牌选手信息,字段之间使用的是\001作为分隔符,要求在Hive中建表映射成功该文件。
字段:id、team_name(战队名称)、ace_player_name(王牌选手名字)
表名: t_team_ace_player