在NVIDIA Orin上用TensorRT对YOLO12进行多路加速并行推理时内存泄漏(下)
接上篇
在NVIDIA Orin上用TensorRT对YOLO12进行多路加速并行推理时内存泄漏(上)
通过上篇的分析,发现问题在采集数据到传入GPU之前的阶段。但随着新一轮长时间测试发现,问题依然存在。
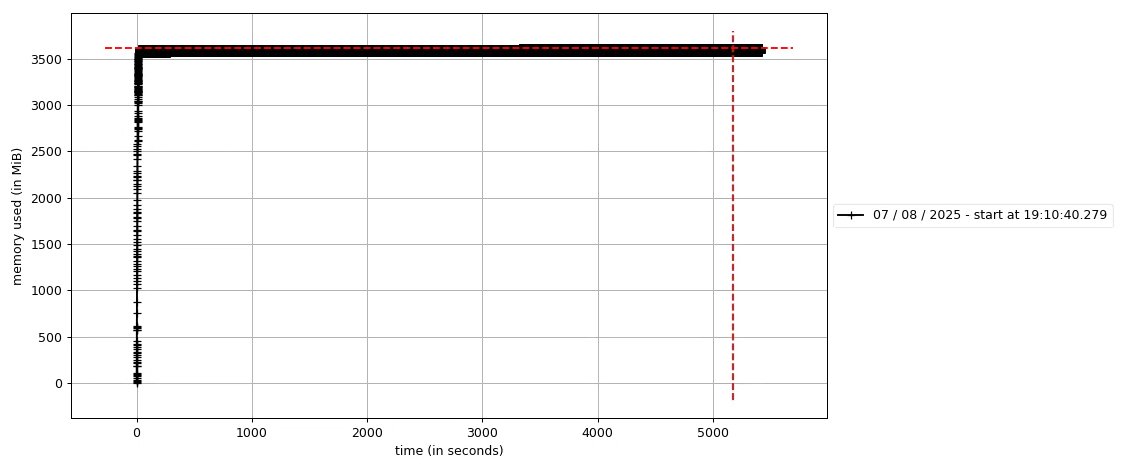
如上图,在运行20多分钟内存开始增长,这个增长只要一开始就会持续直到程序直接卡掉。于是又开启新一轮的排查。
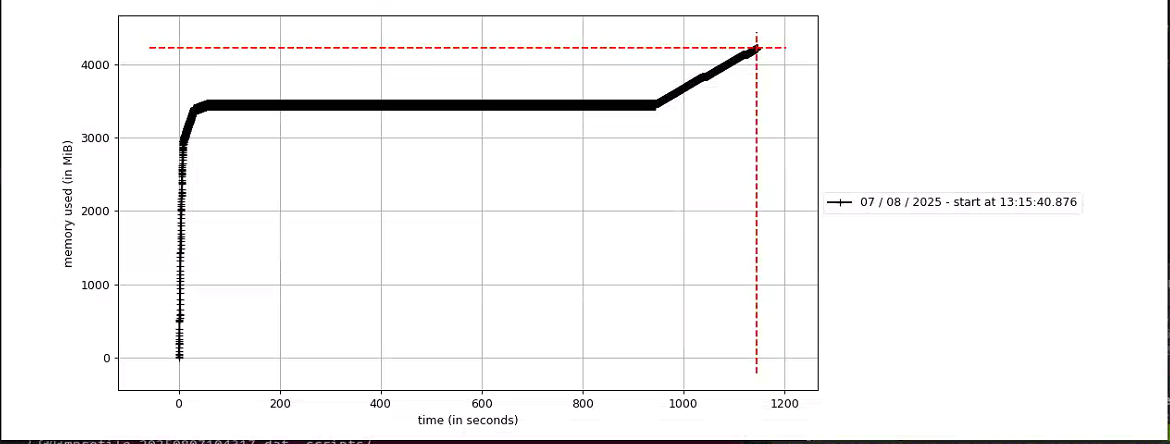
首先,控制变量,使用YOLO12s-DET的engine模型进行推理测试,内存增长情况如下图:在7000s(近两个小时的测试中),内存都在平稳无变化。
于是,继续摸排问题,发现同样的前处理,YOLO12-DET是没有问题,再加上上图的内存无变化情况,便排除前处理部分。
再次来到后处理及检测结果转换部分的内容,😓,饶了一圈再次回来。只能说抓住本质才是解决问题的唯一方法。
由于有之前的经验,没有再使用memory_profiler这个工具进行后处理各个部分的内存异常监测。这次我采用比较原始的方法,因为经过多次测试发现了一个内存开始增长的现象,就是只要程序一旦卡顿,内存就开始增长。
在这么做之前,把所有可能的结果都是尝试了,结果无一解决这个问题。包括及时释放变量内存、定时强制清理内存等等。
然后,把问题范围缩小到当前的后处理代码部分,以及避开内存监测工具。
现在就采用打断电的方式,再次测试等到程序卡顿现象出现。打断点就是在可以代码前面加一行输出。
print("this is fun1.")
def fun1print("this is fun2.")
def fun2等到程序停到这里不动的时候就可定定位到程序卡在哪一步了。
很快,程序很快就卡在bbox_iou这里了。程序在这里停住了,然后内存开始持续增长。
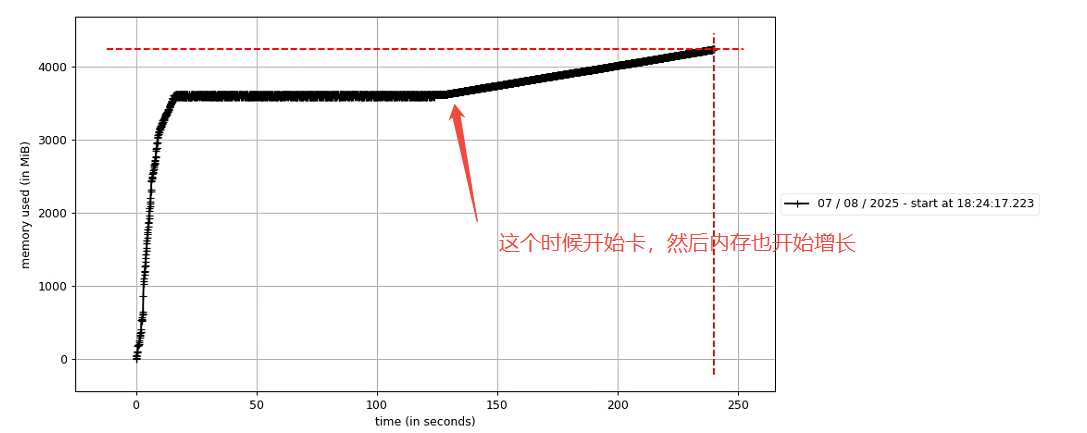
进一步打断点,发现程序在bbox_iou的while循环里面空转。
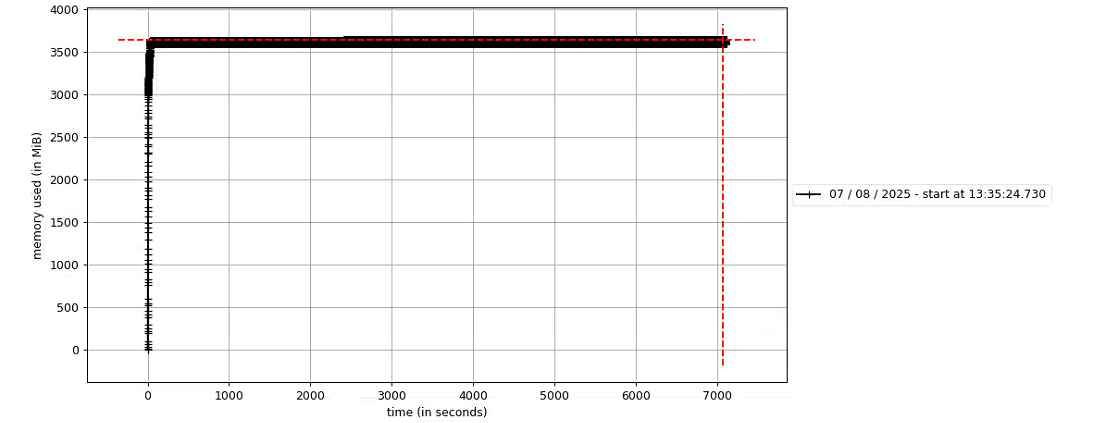
随即对该死循环进行特殊处理,最新测试如下,5000s内无异常。至此该问题得到解决。