构建语义搜索引擎:Weaviate的实践与探索
随着人工智能技术的飞速发展,我们与数据的交互方式正在发生深刻变革。传统的基于关键词的搜索方法已经难以满足日益复杂的用户需求,而语义搜索作为一种新兴的搜索技术,正逐渐成为主流。本文将介绍如何使用开源向量数据库Weaviate构建一个语义搜索引擎,并通过实际案例展示其强大功能。
一、什么是语义搜索?
语义搜索是一种基于数据含义而非关键词匹配的搜索技术。它通过理解用户查询的意图和上下文,返回更加相关和准确的结果。例如,当用户搜索“舒适的阅读角落”时,语义搜索引擎不仅会返回包含这些关键词的结果,还会展示与“舒适的壁炉旁软椅”相关的图片,从而提供更加丰富和直观的搜索体验。
二、Weaviate简介
Weaviate是一个开源的向量数据库,专为存储和处理高维数据(如文本、图像、视频等)而设计。它通过机器学习生成的向量嵌入,实现了基于语义的数据检索,而非传统的精确匹配。Weaviate的核心优势在于其AI原生架构和模块化设计,使其能够轻松集成到各种AI应用中,如推荐引擎、聊天机器人和语义搜索引擎等。
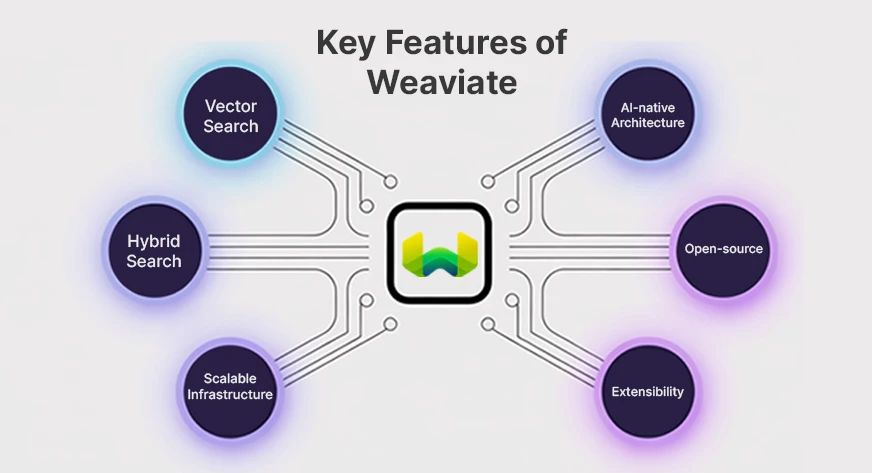
三、Weaviate的核心特性
- 向量搜索:Weaviate能够将数据存储为向量嵌入,并基于语义相似性进行搜索,从而提高搜索的准确性和相关性。
- 混合搜索:结合向量搜索和传统关键词搜索,Weaviate能够提供更加全面和相关的搜索结果。
- 可扩展架构:支持单节点和分布式部署,能够处理大规模数据集,并确保高性能。
- AI原生支持:内置机器学习模型,支持直接生成向量嵌入,无需额外的平台或工具。
- 开源与可扩展性:作为开源项目,Weaviate允许用户进行定制和扩展,并支持多种机器学习模型和外部数据源的集成。
四、构建语义搜索引擎的实践
本文将通过一个实际案例,展示如何使用Weaviate构建一个基于**检索增强生成(RAG)**的语义搜索引擎。RAG是一种结合了信息检索和生成式AI的技术,能够根据用户查询从知识库中检索相关信息,并生成准确的答案。
1. 环境准备
首先,确保安装了Python和必要的依赖库。通过以下命令创建并激活虚拟环境:
python3 -m venv weaviate-env
source weaviate-env/bin/activate
pip install weaviate-client openai
2. 部署Weaviate
Weaviate可以通过两种方式部署:
- Weaviate云服务:访问Weaviate官网注册并创建集群,选择OpenAI模块。
- 本地部署:使用Docker Compose运行Weaviate。创建一个
docker-compose.yml文件,配置如下:
version: '3.4'
services:weaviate:image: semitechnologies/weaviate:latestports:- "8080:8080"environment:QUERY_DEFAULTS_LIMIT: 25AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'PERSISTENCE_DATA_PATH: './data'DEFAULT_VECTORIZER_MODULE: 'text2vec-openai'ENABLE_MODULES: 'text2vec-openai,generative-openai'OPENAI_APIKEY: 'your-openai-key-here'
启动Weaviate服务:
docker-compose up -d
3. 连接Weaviate并定义Schema
使用Python客户端连接Weaviate,并定义一个包含问题、答案和类别的Schema:
import os
import weaviate
from weaviate.classes.init import Authclient = weaviate.connect_to_weaviate_cloud(cluster_url=os.getenv("WEAVIATE_URL"),auth_credentials=Auth.api_key(os.getenv("WEAVIATE_API_KEY")),headers={"X-OpenAI-Api-Key": os.getenv("OPENAI_API_KEY")}
)schema = {"classes": [{"class": "Question","description": "QA dataset","properties": [{"name": "question", "dataType": ["text"]},{"name": "answer", "dataType": ["text"]},{"name": "category", "dataType": ["string"]}],"vectorizer": "text2vec-openai","generative": {"module": "generative-openai"}}]
}client.schema.delete_all()
client.schema.create(schema)
print("Schema defined")
4. 插入数据
创建一个简单的问答数据集,并批量插入到Weaviate中:
data = [{"question": "Only mammal in Proboscidea order?", "answer": "Elephant", "category": "ANIMALS"},{"question": "Organ that stores glycogen?", "answer": "Liver", "category": "SCIENCE"}
]with client.batch as batch:batch.batch_size = 20for obj in data:batch.add_data_object(obj, "Question")print(f"Indexed {len(data)} items")
5. 语义搜索
使用nearText进行语义搜索,查找与“最大的大象”相关的问题和答案:
res = (client.query.get("Question", ["question", "answer", "_additional {certainty}"]).with_near_text({"concepts": ["largest elephant"], "certainty": 0.7}).with_limit(2).do())print("Semantic search results:")
for item in res["data"]["Get"]["Question"]:q, a, c = item["question"], item["answer"], item["_additional"]["certainty"]print(f"- Q: {q} → A: {a} (certainty {c:.2f})")
6. 检索增强生成(RAG)
结合Weaviate的检索功能和OpenAI的生成能力,生成基于检索结果的答案:
rag = (client.query.get("Question", ["question", "answer"]).with_near_text({"concepts": ["animal that weighs a ton"]}).with_limit(1).with_generate(single_result=True).do())generated = rag["data"]["Get"]["Question"][0]["generate"]["singleResult"]
print("RAG answer:", generated)
五、Weaviate的优势与挑战
优势
- 开源与灵活:Weaviate的开源特性使其高度可定制,适合各种应用场景。
- 强大的语义搜索能力:通过向量嵌入,Weaviate能够理解数据的语义,提供更加相关的搜索结果。
- 混合搜索支持:结合向量搜索和关键词搜索,满足多样化的用户需求。
- 可扩展性:支持分布式部署,能够处理大规模数据,保证高性能。
挑战
- 学习曲线:对于初学者来说,理解和配置向量数据库可能需要一定的学习成本。
- 依赖外部模型:Weaviate依赖如OpenAI等外部模型生成向量嵌入,可能需要考虑API调用成本和数据隐私问题。
- 数据管理:在大规模数据集下,如何有效管理和优化数据存储与检索仍是一个挑战。
六、总结
Weaviate作为一个开源的向量数据库,凭借其强大的语义搜索能力和灵活的架构,正在引领AI驱动的数据管理技术的发展。通过本文的实践案例,我们可以看到,利用Weaviate构建语义搜索引擎不仅可行,而且高效。随着人工智能技术的不断进步,Weaviate有望在更多领域发挥其独特的优势,助力开发者构建更加智能和高效的应用。
无论是推荐系统、聊天机器人还是复杂的语义搜索引擎,Weaviate都为实现基于语义的数据检索提供了坚实的基础。未来,随着技术的不断演进,Weaviate将继续推动数据管理领域的创新,为用户带来更加智能和个性化的体验。