第三节 YOLOv5数据集构成
目录
3.1 数据集收集
3.3.1 图片类型数据收集
1)、公开数据集网站
2)、自作数据集:
(1)、可以自行使用手机进行拍摄。然后使用labelimg进行标注。
(2)、网络爬取图片,然后使用labelimg进行标注。
(3)、调节图片大小640 X 640代码:
3.2 标注工具
3.3 数据集文件创建规则
(一)、数据集文件夹建立规则:
(二)、标签文件格式(YOLO 格式)
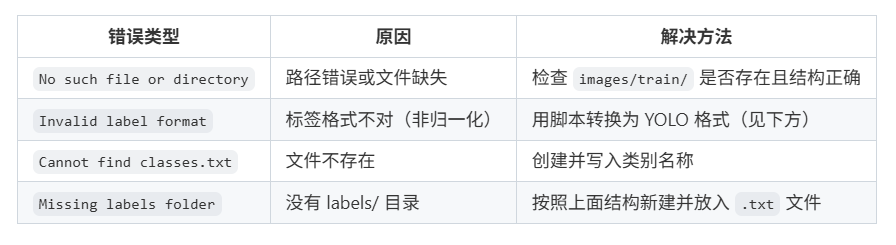
(三)、classes.txt 文件(必须存在)
(四)、数据集配置文件(.yaml)
(五)、常见错误及解决方案
3.1 数据集收集
3.3.1 图片类型数据收集
1)、公开数据集网站
免费数据集网站_数据集下载网站-CSDN博客
2)、自作数据集:
(1)、可以自行使用手机进行拍摄。然后使用labelimg进行标注。
(2)、网络爬取图片,然后使用labelimg进行标注。
下面是爬取百度的香菇照片的程序:
import os
import re
import time
import requests
import uuid
from urllib.parse import quote
from concurrent.futures import ThreadPoolExecutorclass EnhancedImageSpider:def __init__(self, keyword, max_count=100, save_dir='images'):self.keyword = keywordself.max_count = max_countself.save_dir = save_dirself.downloaded = 0self.failed_urls = set()self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Referer': 'https://www.baidu.com/','DNT': '1'}self.session = requests.Session()self.session.headers.update(self.headers)os.makedirs(self.save_dir, exist_ok=True)def _generate_search_urls(self):"""生成新版图片搜索接口URL"""base_url = 'https://image.baidu.com/search/acjson?'params = {'tn': 'resultjson_com','ipn': 'rj','ct': '201326592','is': '','fp': 'result','queryWord': quote(self.keyword),'cl': '2','lm': '-1','ie': 'utf-8','oe': 'utf-8','adpicid': '','st': '-1','z': '','ic': '','hd': '','latest': '','copyright': '','word': quote(self.keyword),'s': '','se': '','tab': '','width': '','height': '','face': '0','istype': '2','qc': '','nc': '1','fr': '','expermode': '','pn': '30', # 每页数量'rn': '30','gsm': '1e','1698767417934': ''}for page in range(0, self.max_count // 30 + 1):params['pn'] = str(page * 30)yield base_url + '&'.join([f'{k}={v}' for k, v in params.items()])def _extract_image_urls(self, html):"""从页面中提取真实图片URL"""pattern = re.compile(r'"thumbURL":"(https?://[^"]+?)"')return list(set(pattern.findall(html)))def _get_valid_urls(self):"""获取有效图片URL"""seen = set()for search_url in self._generate_search_urls():try:response = self.session.get(search_url, timeout=10)response.raise_for_status()urls = self._extract_image_urls(response.text)for url in urls:if url not in seen and self.downloaded < self.max_count:seen.add(url)yield urltime.sleep(1.2 + abs(hash(url)) % 10 / 10) # 动态间隔except Exception as e:print(f"请求失败: {e}")continuedef _download_with_retry(self, url, retries=3):"""带重试机制的下载函数"""for attempt in range(retries):try:response = self.session.get(url, timeout=15)if response.status_code == 200:if response.headers.get('Content-Type', '').startswith('image/'):return response.contentelif response.status_code in [403, 404]:return Noneexcept Exception as e:print(f"下载尝试 {attempt + 1} 失败: {e}")time.sleep(1)return Nonedef _save_image(self, content):"""安全保存图片"""try:filename = f"{self.keyword}_{uuid.uuid4().hex[:8]}.jpg"save_path = os.path.join(self.save_dir, filename)with open(save_path, 'wb') as f:f.write(content)self.downloaded += 1print(f"成功下载 ({self.downloaded}/{self.max_count}): {filename}")return Trueexcept Exception as e:print(f"保存失败: {e}")return Falsedef run(self):"""执行爬取任务"""print(f"开始爬取 [{self.keyword}] 图片...")with ThreadPoolExecutor(max_workers=4) as executor:futures = []for url in self._get_valid_urls():if self.downloaded >= self.max_count:breakfutures.append(executor.submit(self._process_image, url))for future in futures:future.result()print(f"任务完成,成功下载 {self.downloaded} 张图片,失败 {len(self.failed_urls)} 次")def _process_image(self, url):"""处理单张图片"""content = self._download_with_retry(url)if content and self._save_image(content):return Trueself.failed_urls.add(url)return Falseif __name__ == "__main__":spider = EnhancedImageSpider(# 要收集数据集的名称keyword="香菇",# 最大照片数量max_count=250,# 保存到那个文件夹save_dir='香菇')spider.run()代码运行结果:
 注意事项:
注意事项:
(1)、网络下载的图像大小不一,要进一步编写代码将图片的尺寸大小修改成符合模型的输入图像尺寸大小。(调节图片大小640 X 640代码)
(2)、网络爬虫的图像可能模糊不清甚至下载与数据集不相关的图片,需要人工筛选。
(3)、调节图片大小640 X 640代码:
import os
from PIL import Image# ====================== 配置参数 ======================
data_dir = './终版数据集'
output_dir = './yolov5_数据集'
target_size = (640, 640)os.makedirs(output_dir, exist_ok=True)classes = [d for d in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, d))]
print(f"找到 {len(classes)} 个类别:{classes}")for class_name in classes:src_path = os.path.join(data_dir, class_name)dst_path = os.path.join(output_dir, class_name)os.makedirs(dst_path, exist_ok=True)image_files = [f for f in os.listdir(src_path) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff'))]print(f"\n正在处理 {class_name} 类别,共 {len(image_files)} 张图片...")for img_file in image_files:src_img_path = os.path.join(src_path, img_file)try:with Image.open(src_img_path) as img:img.thumbnail(target_size, Image.Resampling.LANCZOS)new_img = Image.new("RGB", target_size, (0, 0, 0))x = (target_size[0] - img.size[0]) // 2y = (target_size[1] - img.size[1]) // 2new_img.paste(img, (x, y))# ✅ 关键修复:正确生成新文件名 + 路径new_filename = f"{os.path.splitext(img_file)[0]}_resized.jpg"new_img.save(os.path.join(dst_path, new_filename), 'JPEG')except Exception as e:print(f"❌ 处理失败:{src_img_path} -> {e}")print(f"✅ {class_name} 类别处理完成!")print("\n🎉 所有图片已成功调整至 640x640 并保存到 ./yolov5_数据集/")3.2 标注工具
使用方法:LabelImg(目标检测标注工具)的安装与使用教程-CSDN博客
安装labelimg指令:
pip install labelimg
激活labelimg指令:
labelimg
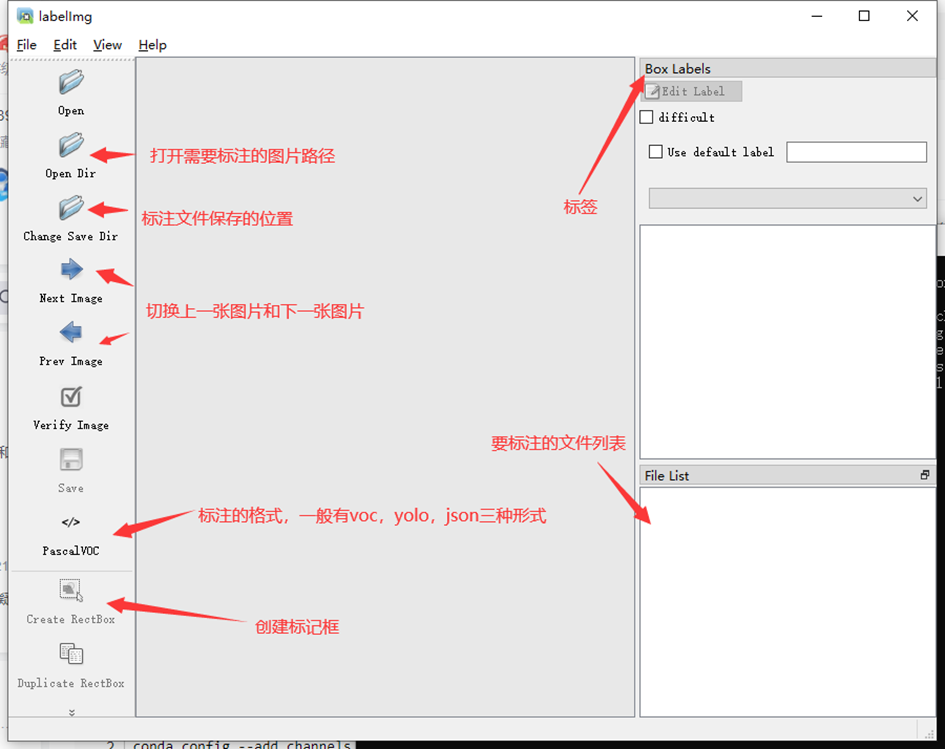 上面是启动了labelimg,下面还需要设置一下。
上面是启动了labelimg,下面还需要设置一下。
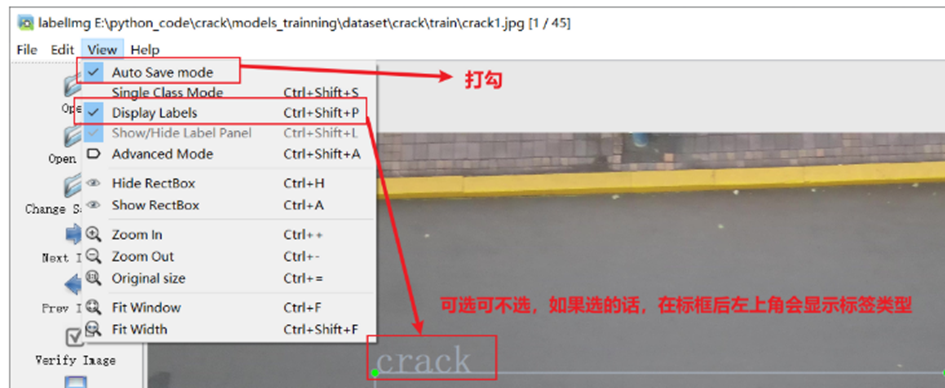
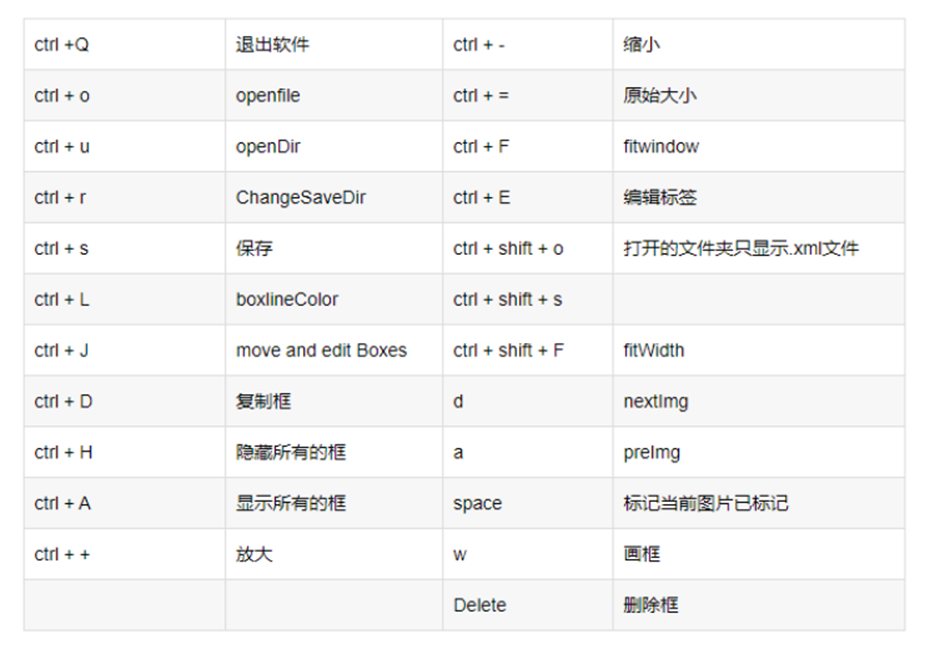
labelimg快捷键:
3.3 数据集文件创建规则
(一)、数据集文件夹建立规则:
dataset
├── images
│ ├── train(用来放训练集图片)
│ ├── val(用来放验证集张图片)
│
├── labels
│ ├── train(用来放训练集图片的标签)
│ ├── val(用来放验证集图片的标签)
│
│ ├── predefined_classes.txt 定义自己要标注的所有类别注意:
- 所有图片和标签文件都必须按类别分文件夹存放(不能混在一起)
- 图片格式支持
.jpg,.png,.bmp,.tiff(推荐 JPG) - 标签文件名与图片一致(如
image.jpg→image.txt)
(二)、标签文件格式(YOLO 格式)
每个 .txt 文件中每行表示一个目标框:
class_id center_x center_y width height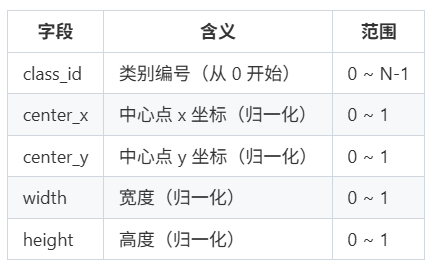

(三)、classes.txt 文件(必须存在)
例如:如果要分类荔枝品种,则classes文件会显示如下内容。

- 每行一个类别名称(英文或中文均可)
- 编号顺序必须与标签文件中的
class_id对应 - 如果你用的是中文类名,YOLOv5 会自动处理(但建议用英文更稳定)
(四)、数据集配置文件(.yaml)
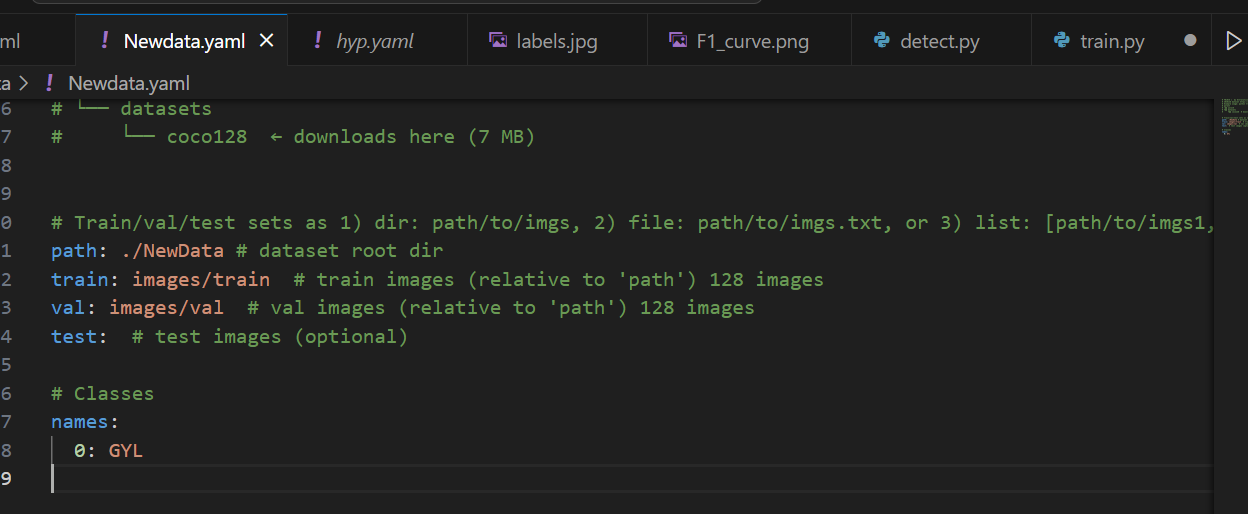 注意:
注意:
path是整个数据集文件夹路径(包含 images/ 和 labels/)train和val是相对路径(相对于path)nc是类别数(必须等于 classes.txt 行数)
补充可能出现的路径问题:运行yolov5训练时遇到Exception: Dataset not found ❌_dataset not found , missing paths-CSDN博客
(五)、常见错误及解决方案