佳文鉴赏 || FD-LLM:用于机器故障诊断的大规模语言模型

论文题目:FD-LLM: Large language model for fault diagnosis of machines。
第一作者:Hamzah A.A.M.Qaid5
通讯作者:See-Kiong Ng
通讯单位:Institute of Data Science, National University of Singapore, Singapore, Singapore
发表时间:2024年12月3日
引用参考:arXiv:2412.01218v1 [cs.AI] 2 Dec 2024
论文地址:https://arxiv.org/abs/2412.01218
目录:
一、FD-LLM 模型概述
1.1 研究背景
1.2 模型架构
1.3 主要贡献
二、数据预处理与编码
2.1 数据来源与预处理
2.2 编码方法
2.3 数据集配置
三、模型训练与评估
3.1 实验设置
3.2 模型选择
3.3 评估指标
四、实验结果与讨论
4.1 实验设置
4.2 模型选择
4.3 评估指标
五、结束语
🚀 读完本文,你将获得以下超实用技能和知识储备:
- 理解 FD-LLM 模型的核心机制:掌握如何将大规模语言模型(LLM)应用于机器故障诊断。
- 掌握数据预处理与编码方法:学会如何将振动信号等时间序列数据转换为 LLM 可以处理的格式。
- 了解模型训练与评估:熟悉如何使用 LLM 进行多分类任务,并评估模型的性能。
- 应用到实际项目中:将 FD-LLM 模型应用于实际的机器故障诊断任务,提升诊断效率和准确性。
一、FD-LLM 模型概述
1.1 研究背景
在现代工业系统中,机器故障诊断(Fault Diagnosis, FD) 是确保生产效率和设备可靠性的重要环节。传统的机器学习(ML)和深度学习(DL)方法虽然在故障诊断中取得了显著进展,但在处理复杂的、异构的数据源时仍面临挑战。此外,这些方法通常需要大量的标注数据进行训练,并且在不同操作条件或机器组件之间泛化能力有限。
近年来,大规模语言模型(LLMs) 在自然语言处理(NLP)领域取得了突破性进展。这些模型通过预训练和微调,能够处理大量的文本数据,并在多种任务中表现出色。研究团队提出了一种创新的方法, 将 LLMs 应用于机器故障诊断, 通过将时间序列数据(如振动信号)编码为文本输入,使 LLMs 能够处理这些数据。
1.2 模型架构
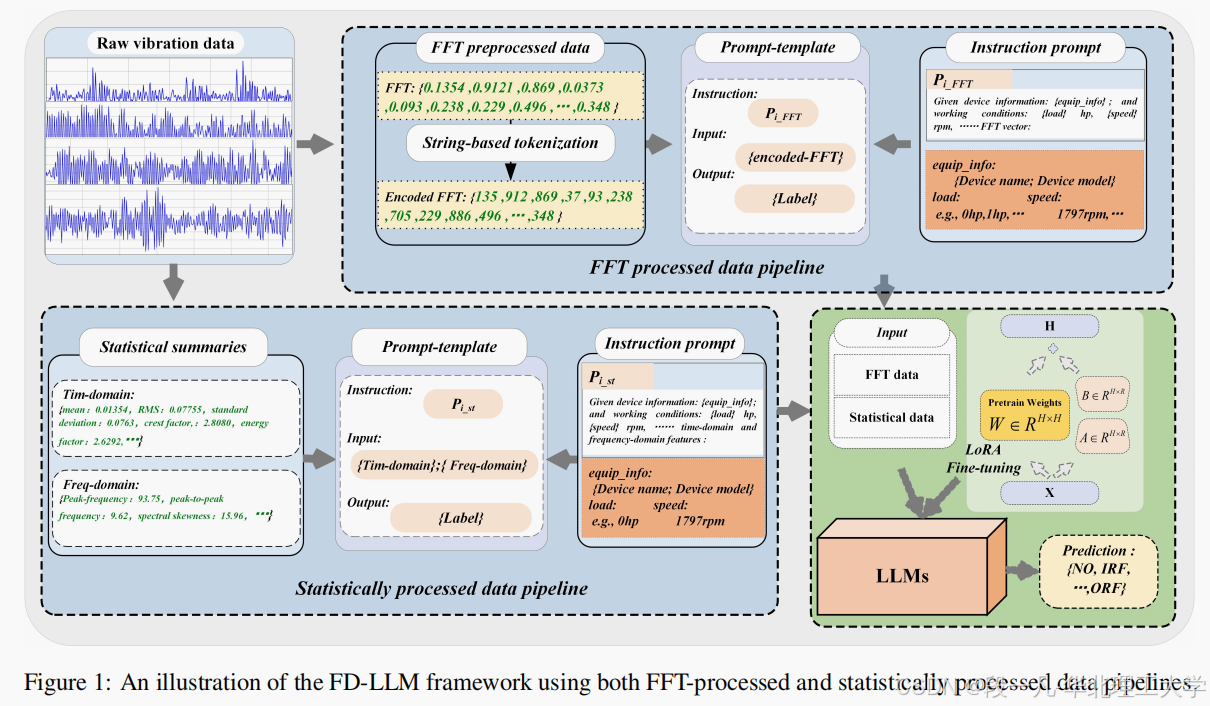
FD-LLM 模型的核心在于将故障诊断任务转化为多分类问题。具体来说,该模型通过以下步骤实现:
- 数据预处理:将振动信号转换为 LLM 可以处理的格式,包括基于字符串的标记化和统计特征提取。
- 指令微调:使用低秩适应(LoRA)技术对 LLM 进行微调,使其适应故障诊断任务。
- 后处理与评估:将 LLM 的文本预测结果映射为数值标签,并使用标准的 DL 和 ML 评估指标进行性能评估。
1.3 主要贡献
研究团队的主要贡献包括:
- 提出了一种新的框架FD-LLM,使 LLMs 能够适应故障诊断任务。
- 探索了两种振动信号编码方法:基于字符串的标记化和统计特征提取。
- 在多种操作条件和机器组件设置下评估了模型的适应性和泛化能力。
二、数据预处理与编码
2.1 数据来源与预处理
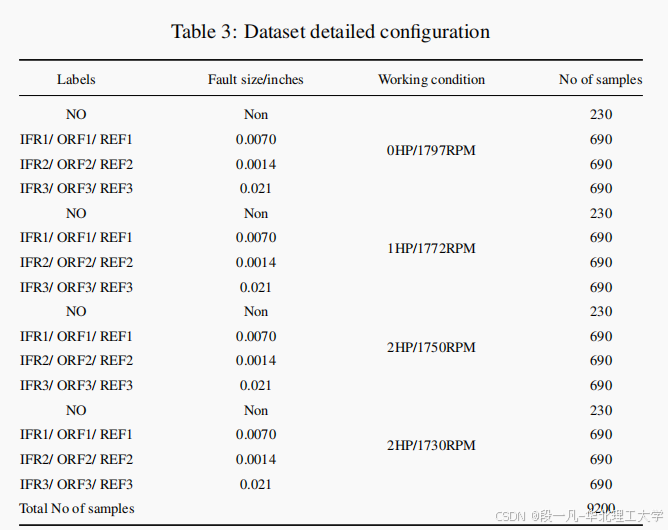
FD-LLM 模型使用了 Case Western Reserve University (CWRU) 数据集,该数据集包含了正常和故障状态下球轴承的振动信号。这些信号通过在电机外壳上安装的加速度计采集,采样率为 12KHz 和 48KHz。
2.2 编码方法
FD-LLM 模型探索了两种编码方法:
-
基于字符串的标记化:将 FFT 处理后的振动信号转换为文本表示。
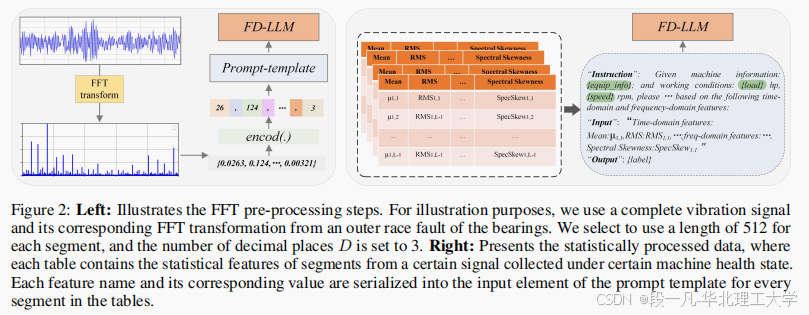
-
统计特征提取:从时间域和频率域提取统计特征,生成每个信号的统计摘要。

2.3 数据集配置
FD-LLM 模型在不同的实验设置下评估了模型的性能,包括传统故障诊断设置、跨操作条件设置和跨机器组件设置。
三、模型训练与评估
3.1 实验设置
FD-LLM 模型在 CWRU 数据集上进行了广泛的实验,评估了模型在不同操作条件和机器组件下的性能。
3.2 模型选择
FD-LLM 模型选择了四种开源 LLMs:Llama3-8B、Llama3-8B-instruct、Qwen1.5-7B 和 Mistral-7B-v0.2。这些模型在处理数值数据方面表现出色。

3.3 评估指标
FD-LLM 模型使用了多种标准的 DL 和 ML 评估指标,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数。

四、实验结果与讨论
4.1 传统故障诊断设置
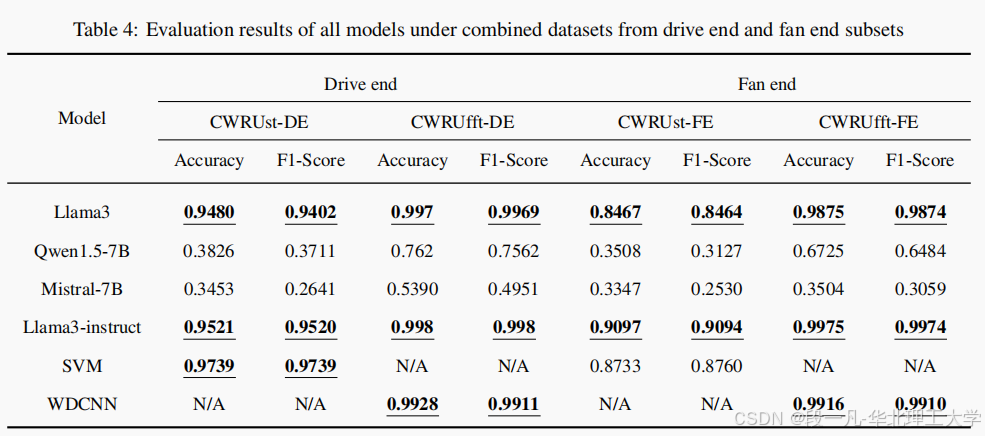
在传统故障诊断设置下,FD-LLM 模型在驱动端(DE)和风扇端(FE)的数据上进行了评估。结果显示,Llama3 和 Llama3-instruct 在 FFT 处理的数据上表现最佳,准确率和 F1 分数接近 100%。
4.2 跨数据集评估
在跨数据集评估中,FD-LLM 模型在不同操作条件和机器组件下的性能进行了评估。结果显示,Llama3 和 Llama3-instruct 在新的操作条件下表现出色,但在跨机器组件设置下性能有所下降。
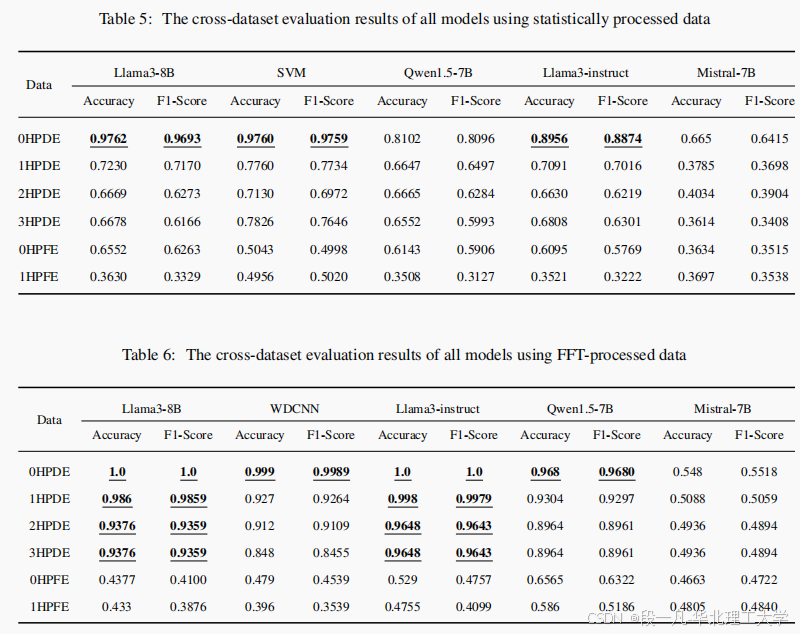
4.3 总体评估
在总体评估中,FD-LLM 模型在包含所有数据的综合数据集上进行了评估。结果显示,Llama3 和 Llama3-instruct 在统计处理和 FFT 处理的数据上均表现出色,准确率和 F1 分数接近 100%。
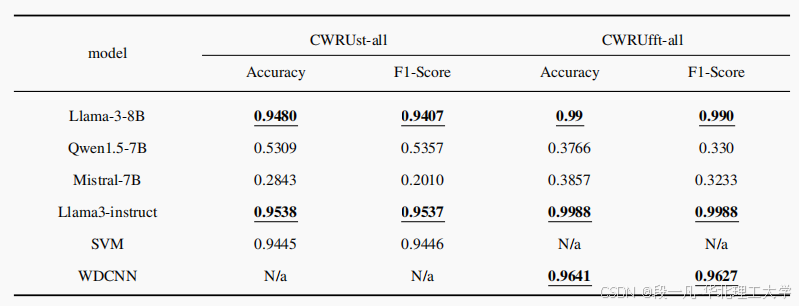
五、结束语
FD-LLM 模型展示了将大规模语言模型应用于机器故障诊断的巨大潜力。通过将时间序列数据编码为文本输入,FD-LLM 模型能够有效地处理复杂的振动信号,并在多种实验设置下表现出色。未来的研究可以进一步探索如何增强模型在跨机器组件设置下的适应性,以提高系统的鲁棒性和可靠性。
希望本文能够帮助你更好地理解和应用 FD-LLM 模型。如果你对 FD-LLM 模型有更多问题,或者在实际应用中遇到了困难,欢迎在评论区留言,我会尽力为你解答。同时,也欢迎你关注我的博客,获取更多关于机器学习和深度学习的实用技巧和经验分享。
最后,感谢你的阅读!如果你觉得本文对你有帮助,不妨点赞和关注,我会继续分享更多关于工业大数据与人工智能工业应用领域的佳文鉴赏系列。🚀
关注专栏,每周更新,带你持续了解更多前沿性科研报道。
版权归文章作者所有,本文为对原文的翻译性总结介绍与解读,或有不当之处,敬请指正!