大数据之HBase
Apache HBase
依赖框架:Hadoop、Zookeeper
整合框架:Phoenix、Hive
一、简介
Apache HBase 是以HDFS为数据存储的,一种分布式、可扩展的NoSQL数据库。
1.1 HBase数据模型
HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。BigTable 是一个稀疏的、分布式的、持久的多维排序map。
之后对于映射的解释如下:
该映射由行键、列键和时间戳索引作为Key;映射中的每个值都是一个未解释的字节数组。(未解释就是经过序列化的, 更节省存储空间)
最终 HBase 关于数据模型和 BigTable 的对应关系如下:
HBase 使用与 BigTable 非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
最终理解 HBase 数据模型的关键在用 稀疏、分布式、多维、排序 的映射。其中映射 map 指代非关系型数据库的 key-value 结构。
1.1.1 HBase逻辑结构
HBase可以用于存储多种结构的数据,以JSON为例,存储的数据原貌为:
{"row_key1": {"personal_info": {"name": "zhangsan","city": "北京","phone": "131********"},"office_info": {"tel": "010-1111111","address": "xx区"}},"row_key11": {"personal_info": {"city": "上海","phone": "132********"},"office_info": {"tel": "010-1111111"}},"row_key2": {......}
}
数据存储 稀疏,数据存储 多维,不同的行具有不同的列。
数据存储整体 有序,按照RowKey的字典序排序,RowKey为Byte数组。
将表格按照行拆分,块名称为Region,用于实现 分布式 结构。
按照列族切分为Store用于底层存储到不同的文件夹中,便于文件对应。
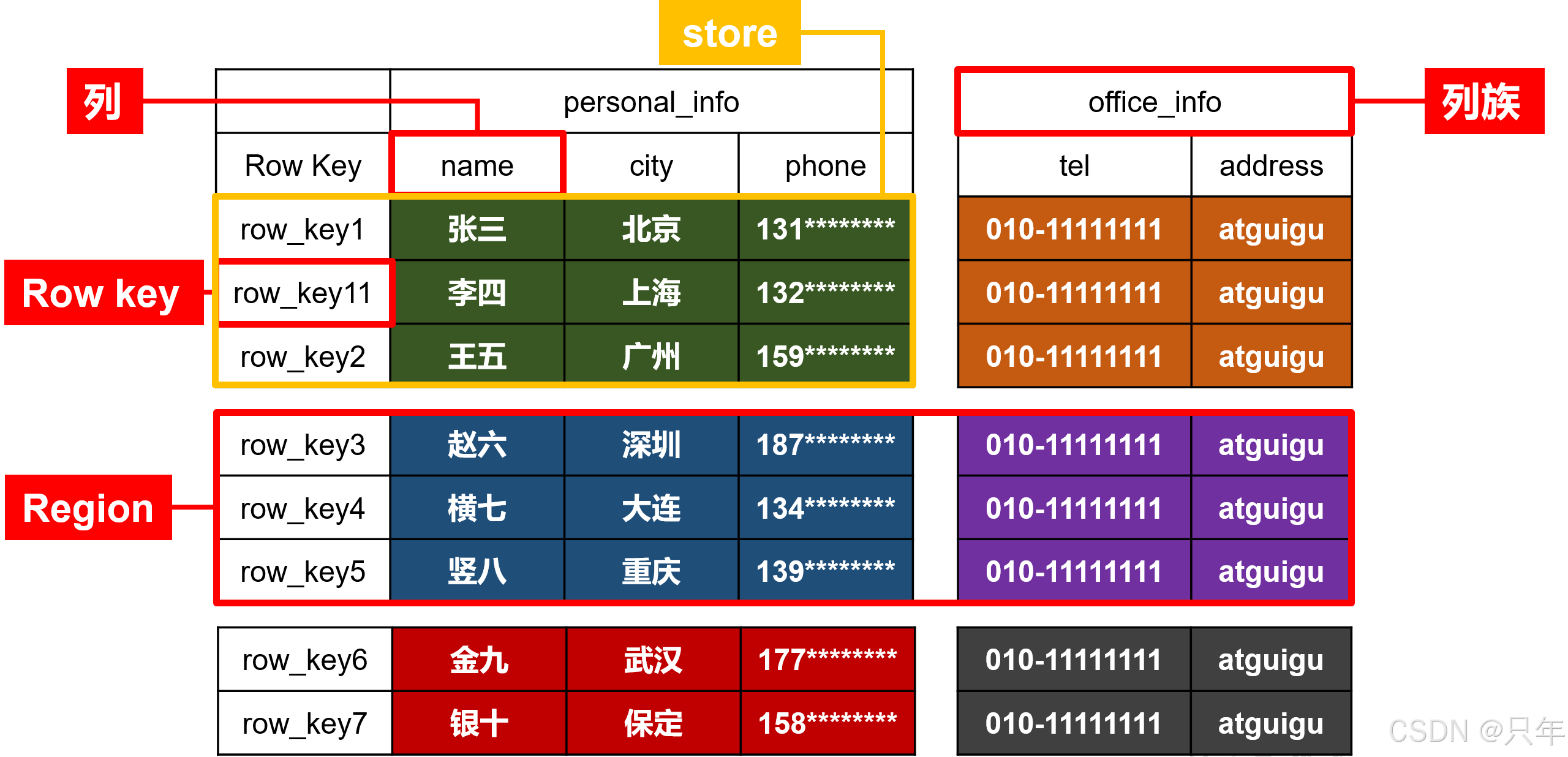
列族、列(列名)、Row Key(行号-用来排序和整理数据的, Row Key有个特点一定是按照字典序排序好的)。
1.1.2 HBase物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储。
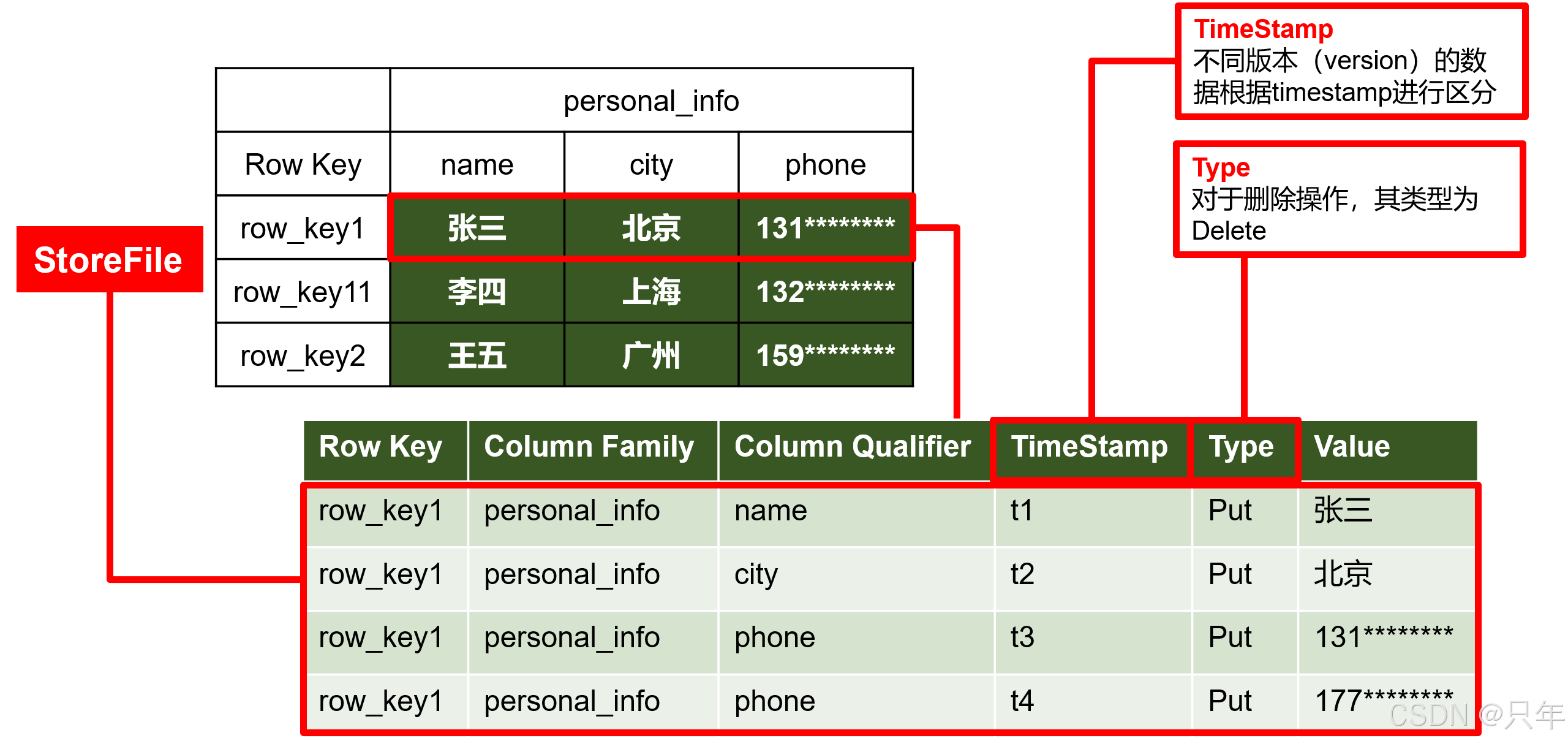
1.1.3 数据模型
-
Name Space
命名空间,类似于关系型数据库的DatabBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
-
Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
-
Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
-
Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
-
Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
-
Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据是没有类型的,全部是字节数组形式存贮。
1.2 HBase基本架构
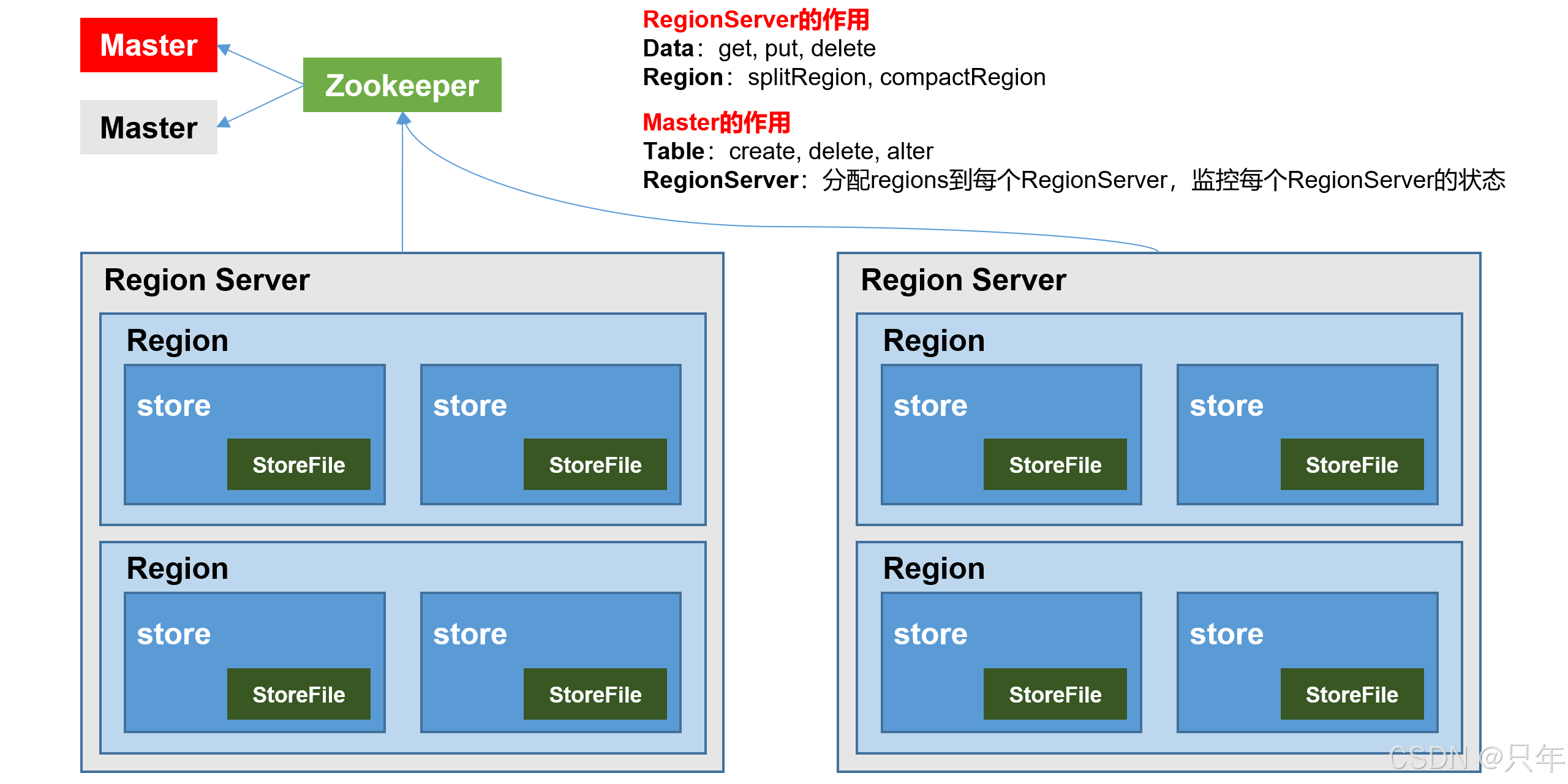
架构角色
-
Master
实现类为HMaster,负责监控集群中所有的RegionServer实例。主要作用如下:
- 管理元数据表格 hbase:meta。接收用户对表格创建修改删除的命令并执行
- 监控region是否需要进行负载均衡,故障转移和region的拆分
通过启动多个后台线程监控实现上述功能
- LoadBalancer 负载均衡器
周期性监控 region 分布在 regionServer 上面是否均衡,由参数 hbase.balancer.period 控制周期时间,默认5分钟。
-
CatalogJanitor 元数据管理器
定期检查和清理 hbase:meta 中的数据。meta 表内容在进阶中介绍。
-
把 master 需要执行的任务记录到预写日志WAL中,如果 master 宕机,让 backupMaster 读取日志继续干。
-
Region Server
Region Server实现类为HReigonServer,主要作用如下
- 负责数据 cell 的处理,例如写入数据 put,查询数据 get 等
- 拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
-
Zookeeper
HBase通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有 meta 表的位置信息。
HBase 对于数据的读写操作是直接访问 Zookeeper 的,在 2.3 版本退出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper 的压力。
-
HDFS
HDFS为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
二、HBase安装部署
2.1 安装部署
先决条件:zk、hadoop
# 启动zookeeper集群
zk.sh start
# 启动hadoop集群
mycluster.sh start
HBase安装步骤
# 上传文件到 /opt/software
[atguigu@hadoop102 software]$ ll | grep hbase
-rw-r--r--. 1 atguigu atguigu 283415422 8月 3 2025 hbase-2.4.11-bin.tar.gz# 解压
[atguigu@hadoop102 software]$ tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/# 配置环境变量
[atguigu@hadoop102 module]$ vim /etc/profile.d/my_env.sh
---
HBASE_HOME=/opt/module/hbase-2.4.11
PATH=$PATH:$HBASE_HOME/binexport HBASE_HOME
---[atguigu@hadoop102 software]$ xsync /opt/module/hbase-2.4.11
[atguigu@hadoop102 software]$ xsync /etc/profile.d/my_env.sh
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
修改配置
# hbase-env.sh修改内容(这个配置表示要不要使用hbase)
---
export HBASE_MANAGES_ZK=false
---
<!-- hbase-site.xml修改内容 -->
<configuration><!-- 我们要把数据放到HDFS上面, 给HBase的目录就是根目录下的hbase目录 --><property><name>hbase.rootdir</name><value>hdfs://hadoop102:8020/hbase</value></property><!-- 是否启用分布式集群 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- 使用已经安装部署好的zk地址 --><property><name>hbase.zookeeper.quorum</name><value>hadoop102,hadoop103,hadoop104</value></property>
</configuration>
# regionservers
[atguigu@hadoop102 conf]$ vim regionservers
---
hadoop102
hadoop103
hadoop104
---
# 解决HBase和Hadoop的log4j兼容问题, 修改 HBase 的 jar 包, 使用 hadoop 的jar包
[atguigu@hadoop102 conf]$ mv /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak# 分发hbase
[atguigu@hadoop102 conf]$ xsync /opt/module/hbase-2.4.11
2.2 启动验证
单点启动
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
群起
start-hbase.sh
对应的停止服务
stop-hbase.sh
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
2.3 页面访问
http://hadoop102:16010
2.4 高可用(可选)
在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。
# 1.关闭HBase集群(如果没有开启则跳过此步)
stop-hbase.sh
# 2.在conf目录下创建backup-masters文件
touch conf/backup-masters
# 3.在backup-masters文件中配置高可用HMaster节点
echo hadoop103 > conf/backup-masters
# 4.将整个conf目录scp到其他节点
scp -r conf/ hadoop103:/opt/module/hbase-2.4.11/
scp -r conf/ hadoop104:/opt/module/hbase-2.4.11/
# 5.打开页面测试查看
http://hadooo102:16010
三、HBase Shell操作
3.1 基本操作
-
进入 HBase 客户端
hbase shell -
查看帮助命令, 例如
help 'list_namespace'help
3.2 namespace
# 查看命名空间
list_namespace
# 创建命名空间
create_namespace 'bigdata'
3.3 DDL
3.3.1 查看表
# 查看所有表, 得到的是空, 没有hbase:meta和hbase:namespace这两张表,是因为hbase帮我们忽略了,不让使用这两张表
hbase:006:0> list
=> []
3.3.2 创建表
# 创建表, 如果不指定命名空间, 在默认default空间下, 可以直接写表名, 我们这里创建student表, 指定两个列族
create 'student', 'info', 'msg'

# 创建表时指定命名空间、指定列族信息
create 'bigdata:person', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg', VERSIONS => 5}
3.3.3 查看表详情
# 查看表的详细信息
describe 'student'
3.3.4 修改表结构
# 修改表中列族信息
alter 'student', NAME => 'info', VERSIONS => 5# 新增表中列组信息(如果表中没有此列族, 那么就是增加)
alter 'student', NAME => 'info1', VERSIONS => 5
# 删除表中列族
alter 'student', 'delete' => 'info1'
3.3.5 删除表
hbase:001:0> drop 'student'ERROR: Table student is enabled. Disable it first.For usage try 'help "drop"'Took 0.2618 seconds
# 报错, 原因是这个表 student 是可用的, 删除前需要将此表标记为不可用# 也就是删除表需要两步, 先 disable, 再 drop
disable 'student'
drop 'student'
3.4 DML
3.4.1 写入数据
在 HBase 里写入数据,只能添加结构中最底层的Cell。命令就是put往里面放数据,同时兼具有修改数据的功能,它会自动采用覆盖的一种形式。可以手动写入时间戳指定Cell版本,推荐不写默认使用当前系统时间。
create 'bigdata:student', 'info', 'msg'
-- 第一次新增数据
hbase:007:0> put 'bigdata:student', '1001', 'info:name', 'zhangsan'
Took 0.0769 seconds
-- 更新: 重复RowKey, 相同列, 数据会进行覆盖
hbase:008:0> put 'bigdata:student', '1001', 'info:name', 'lisi'
Took 0.0159 seconds
-- 再更新, 版本覆盖
hbase:009:0> put 'bigdata:student', '1001', 'info:name', 'wangwu'
Took 0.0054 seconds
-- 新增
hbase:010:0> put 'bigdata:student', '1002', 'info:name', 'zhaoliu'
Took 0.0062 seconds
hbase:011:0> put 'bigdata:student', '1003', 'info:age', '18'
Took 0.0059 seconds
如果重复写入相同 RowKey,相同列的数据,会写入多个版本进行覆盖。
3.4.2 读取数据
读取数据的方法有两个: get 和 scan。
get最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行cell。
hbase:016:0> put 'bigdata:student','1003','info:name','tianqi'
Took 0.0064 seconds-- GET 哪个表的哪行数据 (虽然有俩数据, 但其实是两个Cell, 是一行的. 都是1003这行, 列族是 info, 列名是age和name)
hbase:017:0> get 'bigdata:student','1003'
COLUMN CELLinfo:age timestamp=2025-08-03T13:24:14.218, value=18info:name timestamp=2025-08-03T14:08:22.488, value=tianqi
1 row(s)
Took 0.0061 seconds-- 同时还能过滤下, Get 哪一行的哪几列数据
hbase:018:0> get 'bigdata:student','1003', {COLUMN => 'info:name'}
COLUMN CELLinfo:name timestamp=2025-08-03T14:08:22.488, value=tianqi
1 row(s)
Took 0.0085 seconds
想要查询多行,可以用scan,扫描,可以扫描多行、甚至整张表。
hbase:019:0> scan 'bigdata:student'
ROW COLUMN+CELL 1001 column=info:name, timestamp=2025-08-03T13:22:56.224, value=wangwu1002 column=info:name, timestamp=2025-08-03T13:23:40.811, value=zhaoliu1003 column=info:age, timestamp=2025-08-03T13:24:14.218, value=181003 column=info:name, timestamp=2025-08-03T14:08:22.488, value=tianqi
3 row(s)
Took 0.0266 seconds-- 过滤(左闭右开)
hbase:022:0> scan 'bigdata:student', {STARTROW => '1001', STOPROW => '1003'}
ROW COLUMN+CELL1001 column=info:name, timestamp=2025-08-03T13:22:56.224, value=wangwu1002 column=info:name, timestamp=2025-08-03T13:23:40.811, value=zhaoliu
2 row(s)
Took 0.0132 seconds
3.4.3 删除数据
-- 删除某行某cell, 只是删除最新的版本, 之前的版本还会在
delete 'bigdata:student','1001','info:name'-- 看,还有1001,只不过变为了lisi
hbase:025:0> scan 'bigdata:student'
ROW COLUMN+CELL 1001 column=info:name, timestamp=2025-08-03T13:22:51.964, value=lisi1002 column=info:name, timestamp=2025-08-03T13:23:40.811, value=zhaoliu1003 column=info:age, timestamp=2025-08-03T13:24:14.218, value=181003 column=info:name, timestamp=2025-08-03T14:08:22.488, value=tianqi
3 row(s)
Took 0.0116 seconds
把数据改为多个版本,是可以同时读取到多个版本的
hbase:026:0> alter 'bigdata:student',{NAME => 'info', VERSIONS => 3}
-- 可以把上面写入数据的多复制几份, 验证效果
put 'bigdata:student', '1001', 'info:name', 'zhangsan1'
put 'bigdata:student', '1001', 'info:name', 'lisi1'
put 'bigdata:student', '1001', 'info:name', 'wangwu1'put 'bigdata:student', '1001', 'info:name', 'zhangsan2'
put 'bigdata:student', '1001', 'info:name', 'lisi2'
put 'bigdata:student', '1001', 'info:name', 'wangwu2'put 'bigdata:student', '1001', 'info:name', 'zhangsan3'
put 'bigdata:student', '1001', 'info:name', 'lisi3'
put 'bigdata:student', '1001', 'info:name', 'wangwu3'put 'bigdata:student', '1001', 'info:name', 'zhangsan4'
put 'bigdata:student', '1001', 'info:name', 'lisi4'
put 'bigdata:student', '1001', 'info:name', 'wangwu4'put 'bigdata:student', '1001', 'info:name', 'zhangsan5'
put 'bigdata:student', '1001', 'info:name', 'lisi5'
put 'bigdata:student', '1001', 'info:name', 'wangwu5'hbase:047:0> get 'bigdata:student','1001',{COLUMN => 'info:name', VERSIONS => 6}
COLUMN CELL info:name timestamp=2025-08-03T14:32:15.044, value=wangwu5info:name timestamp=2025-08-03T14:32:13.823, value=lisi5info:name timestamp=2025-08-03T14:32:13.812, value=zhangsan5
1 row(s)
Took 0.0072 seconds
-- 我查询指定的6, 为什么结果是3份呢?是因为我们在上面给bigdata:student的VERSIONS指定的3,只有3个版本
如果要删除所有, 可以 deleteall
deleteall 'bigdata:student','1001','info:name'hbase:049:0> get