Boosting 知识点整理:调参技巧、可解释性工具与实战案例
Boosting 技术全面解析(二):调参技巧、可解释性工具与实战案例
在上一篇文章中,我们从原理角度出发,系统讲解了 Boosting 的工作机制,深入比较了 AdaBoost、GBM 及主流框架(XGBoost、LightGBM、CatBoost),并与随机森林进行了对比分析。本文将作为续篇,重点介绍 Boosting 模型的调参思路、可解释性工具以及一个典型实战案例,帮助你实现从理解到应用的跨越。
一、Boosting 模型调参思路与技巧
Boosting 模型调参虽然繁琐,但一旦掌握其背后逻辑,就能大幅提升模型表现。以下以 XGBoost 为例,介绍典型调参步骤。
1. 学习率(learning_rate)与迭代次数(n_estimators)
learning_rate决定每个模型对最终预测结果的贡献,一般设为 0.01~0.3。- 学习率越小,需要的
n_estimators越多,训练更稳健但耗时增加。
调参建议:
learning_rate = 0.05
n_estimators = 1000
early_stopping_rounds = 50 # 避免过拟合
2. 树的结构控制参数
| 参数 | 作用 | 建议值 |
|---|---|---|
max_depth | 树的最大深度 | 3~10 |
min_child_weight | 最小叶子节点样本权重和 | 1~10 |
gamma(min_split_loss) | 最小损失减少要求 | 0~5 |
subsample | 每棵树用到的样本比例 | 0.6~1.0 |
colsample_bytree | 每棵树用到的特征比例 | 0.6~1.0 |
3. 正则化参数
reg_alpha(L1 正则)与reg_lambda(L2 正则)控制模型复杂度。- 可在过拟合时提高这两个值。
4. 调参技巧建议
Boosting 的调参目标是找到一个在泛化能力、训练时间和模型复杂度之间平衡的最佳方案。以下是调参的一般建议顺序:
- 设定较高的 n_estimators:比如 500~1000,为后续早停或学习率调节留出空间。
- 设置学习率 learning_rate(0.05 或 0.1 是常用初始值):值越小,训练越慢但精度更高。
- 调整 max_depth 或 num_leaves:控制每棵树的复杂度,避免过拟合。
- 调节 min_child_weight / min_samples_split:提升模型鲁棒性。
- 增加正则项 reg_alpha / reg_lambda:约束模型复杂度。
- 应用 early_stopping_rounds:防止模型在验证集上过拟合。
Tips:不要一次调整多个参数,每次只调整一到两个参数,观察其对性能指标(如 F1)影响。
二、Boosting 模型的可解释性方法
Boosting 虽然效果强劲,但可解释性相对较弱,被称为“黑盒模型”。我们可以使用以下工具提升其透明度:
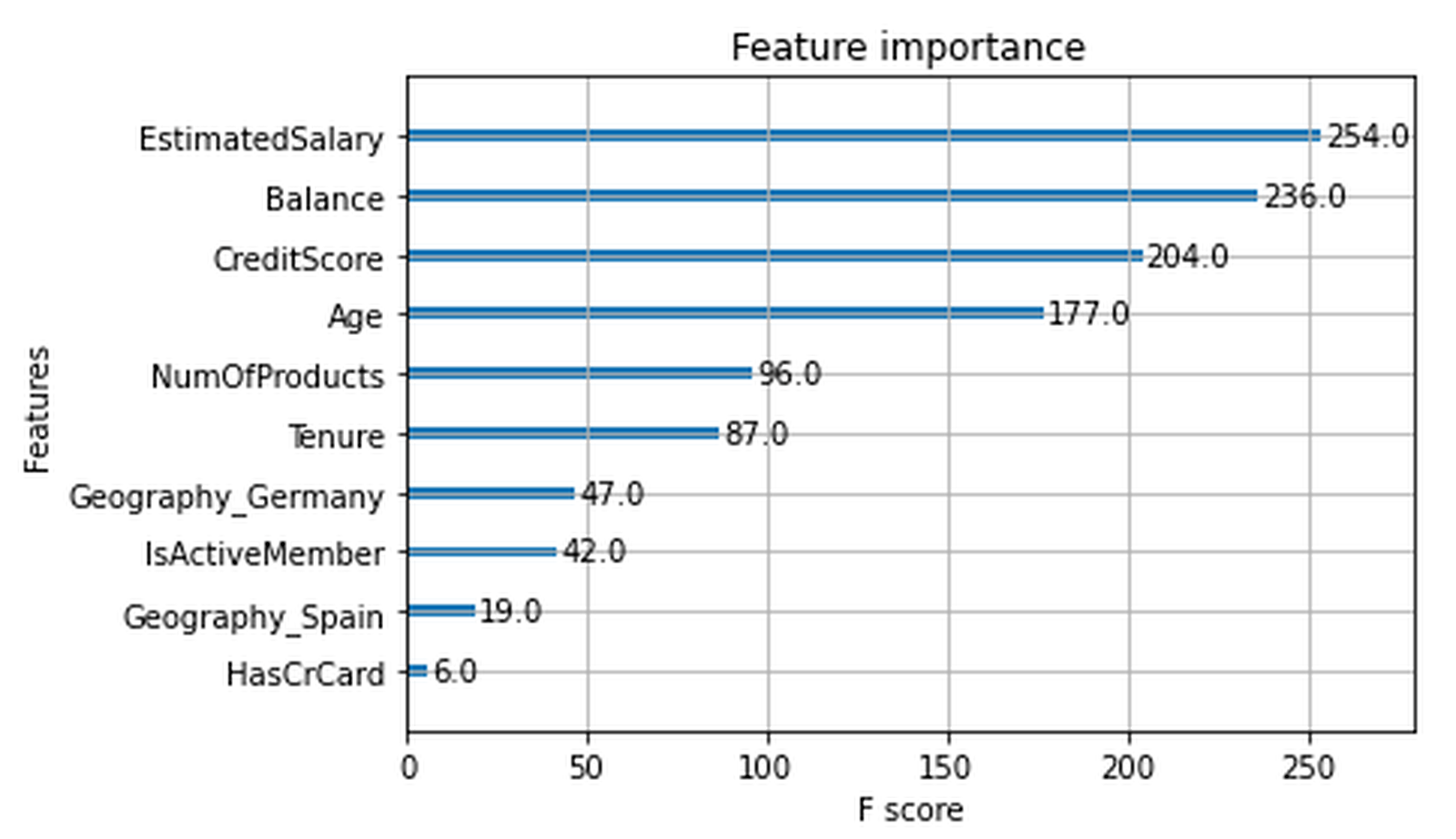
1. 特征重要性(Feature Importance)
- 常用指标:
gain、weight、cover。 - XGBoost 示例:
from xgboost import plot_importance
plot_importance(model)
2. SHAP(SHapley Additive exPlanations)
SHAP 是一种模型无关的解释方法,能量化每个特征对预测结果的边际贡献。
import shap
explainer = shap.Explainer(model)
shap_values = explainer(X)
shap.plots.beeswarm(shap_values)
SHAP 可视化优势:
- 展示全局特征影响(Beeswarm 图)
- 显示单个预测解释(Force 图)
- 对模型进行深度诊断
3. 混淆矩阵与评估指标可视化
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
preds = model.predict(X_test)
cm = confusion_matrix(y_test, preds)
ConfusionMatrixDisplay(confusion_matrix=cm).plot()
三、XGBoost 模型实战:员工流失预测
我们使用 XGBoost 对一个典型的员工流失数据集进行建模,完整展示调参、训练、保存与评估全过程。
1. 导入必要库
import numpy as np
import pandas as pd
from xgboost import XGBClassifier, plot_importance
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
import pickle
pd.set_option('display.max_columns', None)
2. 构建模型与超参数网格
xgb = XGBClassifier(objective='binary:logistic', random_state=0) cv_params = {'max_depth': [4,5,6,7,8], 'min_child_weight': [1,2,3,4,5],'learning_rate': [0.1, 0.2, 0.3],'n_estimators': [75, 100, 125]
} scoring = {'accuracy', 'precision', 'recall', 'f1'}
xgb_cv = GridSearchCV(xgb, cv_params, scoring=scoring, cv=5, refit='f1')
3. 模型训练与保存
xgb_cv.fit(X_train, y_train)with open('xgb_cv_model.pickle', 'wb') as f:pickle.dump(xgb_cv, f)
4. 模型评估与对比
print('Best F1 (CV): ', xgb_cv.best_score_)xgb_preds = xgb_cv.predict(X_test)
print('F1: ', f1_score(y_test, xgb_preds))
print('Recall: ', recall_score(y_test, xgb_preds))
print('Precision: ', precision_score(y_test, xgb_preds))
print('Accuracy: ', accuracy_score(y_test, xgb_preds))
5. 可解释性输出
def conf_matrix_plot(model, x_data, y_data):pred = model.predict(x_data)cm = confusion_matrix(y_data, pred)disp = ConfusionMatrixDisplay(confusion_matrix=cm)disp.plot()plt.show()conf_matrix_plot(xgb_cv, X_test, y_test)
plot_importance(xgb_cv.best_estimator_)
四、总结与展望
本篇文章介绍了 Boosting 模型的调参流程、可解释性分析方法,并通过 XGBoost 的完整建模过程演示了这些理论如何落地应用。我们可以看到,在结构化数据的分类问题中,Boosting 模型(如 XGBoost)通过合理调参和分析,能够兼顾精度、泛化能力与业务解释性。