Text2SQL 智能问答系统开发-spider验证集(三)
概述
已完成
- 基础 Text2SQL 功能实现
实现用户输入自然语言问题后,系统能够自动生成 SQL 并执行返回结果。 - 用户交互优化
支持用户通过补充信息对查询进行调整,提升易用性。 - 模糊时间处理机制
对“最近”“近期”等模糊时间关键词进行补全或引导,提升时间表达准确性。 - 预定义高频问题与回答
对一些可预见的问题设置高质量回复,提高响应质量和效率。 - 高质量测试集
- 引入高质量的测试集来测试Text2SQL的效果与准确率
后续优化
- 构建高质量知识库
针对数据结构、字段定义、样例问题等,持续完善知识库,确保 SQL 生成的准确率。 - 引入持续学习机制
通过用户反馈和历史数据,不断优化模型能力与表现。 - 智能体节点,自动纠错
- 避免现在一次性生成SQL,多次生成纠错,提高质量
- 多路径打分机制
- 让模型从多个角度(或不同 Prompt/Few-shot)生成多个 SQL 候选
- 再让模型自己“评估哪一个最优”,从而选出最靠谱的一条执行
- 用户意图识别,问题泛化(系统级别)
- 对专业的业务知识、以及缩写的理解:
例如:查询四大行信息、四大银行信息,其中四大行和四大银行都是简称,需要转化为数据库存储的内容,需要做映射
- 对专业的业务知识、以及缩写的理解:
spider验证集准备
spider验证集github开源地址:https://github.com/xlang-ai/Spider2/blob/main/spider2-lite/spider2-lite.jsonl
- Download local database, unzip and put all the
<font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">.sqlite</font>files into directory<font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">spider2-lite/resource/databases/spider2-localdb</font>. - 写python脚本,将.sqlite文件的内容存储到pgsql,本次验证集使用brazilian_E_Commerce数据库作为测试数据库,因此只创建和初始化brazilian_E_Commerce数据库
创建表和数据库
CREATE TABLE olist_customers ( customer_id TEXT, customer_unique_id TEXT, customer_zip_code_prefix BIGINT, customer_city TEXT, customer_state TEXT );CREATE TABLE olist_sellers ( seller_id TEXT, seller_zip_code_prefix BIGINT, seller_city TEXT, seller_state TEXT );CREATE TABLE olist_order_reviews ( review_id TEXT, order_id TEXT, review_score BIGINT, review_comment_title TEXT, review_comment_message TEXT, review_creation_date TEXT, review_answer_timestamp TEXT );CREATE TABLE olist_order_items ( order_id TEXT, order_item_id BIGINT, product_id TEXT, seller_id TEXT, shipping_limit_date TEXT, price FLOAT, freight_value FLOAT );CREATE TABLE olist_products ( product_id TEXT, product_category_name TEXT, product_name_lenght FLOAT, product_description_lenght FLOAT, product_photos_qty FLOAT, product_weight_g FLOAT, product_length_cm FLOAT, product_height_cm FLOAT, product_width_cm FLOAT );CREATE TABLE olist_geolocation ( geolocation_zip_code_prefix BIGINT, geolocation_lat FLOAT, geolocation_lng FLOAT, geolocation_city TEXT, geolocation_state TEXT );CREATE TABLE product_category_name_translation ( product_category_name TEXT, product_category_name_english TEXT );CREATE TABLE olist_orders ( order_id TEXT, customer_id TEXT, order_status TEXT, order_purchase_timestamp TEXT, order_approved_at TEXT, order_delivered_carrier_date TEXT, order_delivered_customer_date TEXT, order_estimated_delivery_date TEXT );CREATE TABLE olist_order_payments ( order_id TEXT, payment_sequential BIGINT, payment_type TEXT, payment_installments BIGINT, payment_value FLOAT );CREATE TABLE olist_products_dataset ( index BIGINT, product_id TEXT, product_category_name TEXT, product_name_lenght FLOAT, product_description_lenght FLOAT, product_photos_qty FLOAT, product_weight_g FLOAT, product_length_cm FLOAT, product_height_cm FLOAT, product_width_cm FLOAT );
python脚本将sqlite数据存储到pgsql
import sqlite3
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMITSQLITE_FILE = "Brazilian_E_Commerce.sqlite"
PG_HOST = "127.0.0.1"
PG_PORT = 5432
PG_USER = "postgres"
PG_PASSWORD = "difyai123456"
PG_DB_NAME = "brazilian_e_commerce"
BATCH_SIZE = 1000 # 每批插入多少行def create_postgres_database():conn = psycopg2.connect(dbname='postgres', user=PG_USER, password=PG_PASSWORD,host=PG_HOST, port=PG_PORT)conn.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)cur = conn.cursor()cur.execute(f"SELECT 1 FROM pg_database WHERE datname = '{PG_DB_NAME}';")if not cur.fetchone():cur.execute(f"CREATE DATABASE {PG_DB_NAME};")print(f" 数据库 {PG_DB_NAME} 已创建")else:print(f"数据库 {PG_DB_NAME} 已存在")cur.close()conn.close()# ---------- 连接 SQLite 和 PostgreSQL ----------
sqlite_conn = sqlite3.connect(SQLITE_FILE)
sqlite_cursor = sqlite_conn.cursor()create_postgres_database()pg_conn = psycopg2.connect(dbname=PG_DB_NAME, user=PG_USER, password=PG_PASSWORD,host=PG_HOST, port=PG_PORT
)
pg_cursor = pg_conn.cursor()# ---------- 获取 SQLite 所有表 ----------
sqlite_cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = [row[0] for row in sqlite_cursor.fetchall()]# ---------- 遍历所有表 ----------
for table in tables:print(f"\n 正在迁移表:{table}")# 获取字段信息sqlite_cursor.execute(f"PRAGMA table_info({table})")columns_info = sqlite_cursor.fetchall()col_names = [col[1] for col in columns_info]placeholders = ','.join(['%s'] * len(col_names))insert_sql = f'INSERT INTO "{table}" ({", ".join(col_names)}) VALUES ({placeholders})'# 检查目标表是否存在pg_cursor.execute("SELECT EXISTS (SELECT FROM information_schema.tables WHERE table_schema = 'public' AND table_name = %s);",(table,))exists = pg_cursor.fetchone()[0]if not exists:print(f" PostgreSQL 中未找到表 {table},请先手动建表。")continue# 分批读取和写入sqlite_cursor.execute(f'SELECT * FROM "{table}"')total_inserted = 0while True:batch = sqlite_cursor.fetchmany(BATCH_SIZE)if not batch:breakpg_cursor.executemany(insert_sql, batch)pg_conn.commit()total_inserted += len(batch)print(f"已导入 {total_inserted} 行...", end="\r")print(f"表 {table} 导入完成,共 {total_inserted} 行")# ---------- 清理资源 ----------
sqlite_cursor.close()
sqlite_conn.close()
pg_cursor.close()
pg_conn.close()print("\n🎉 所有表已成功迁移到 PostgreSQL!")- 关于spider问题的说明:
示例问题存储地址
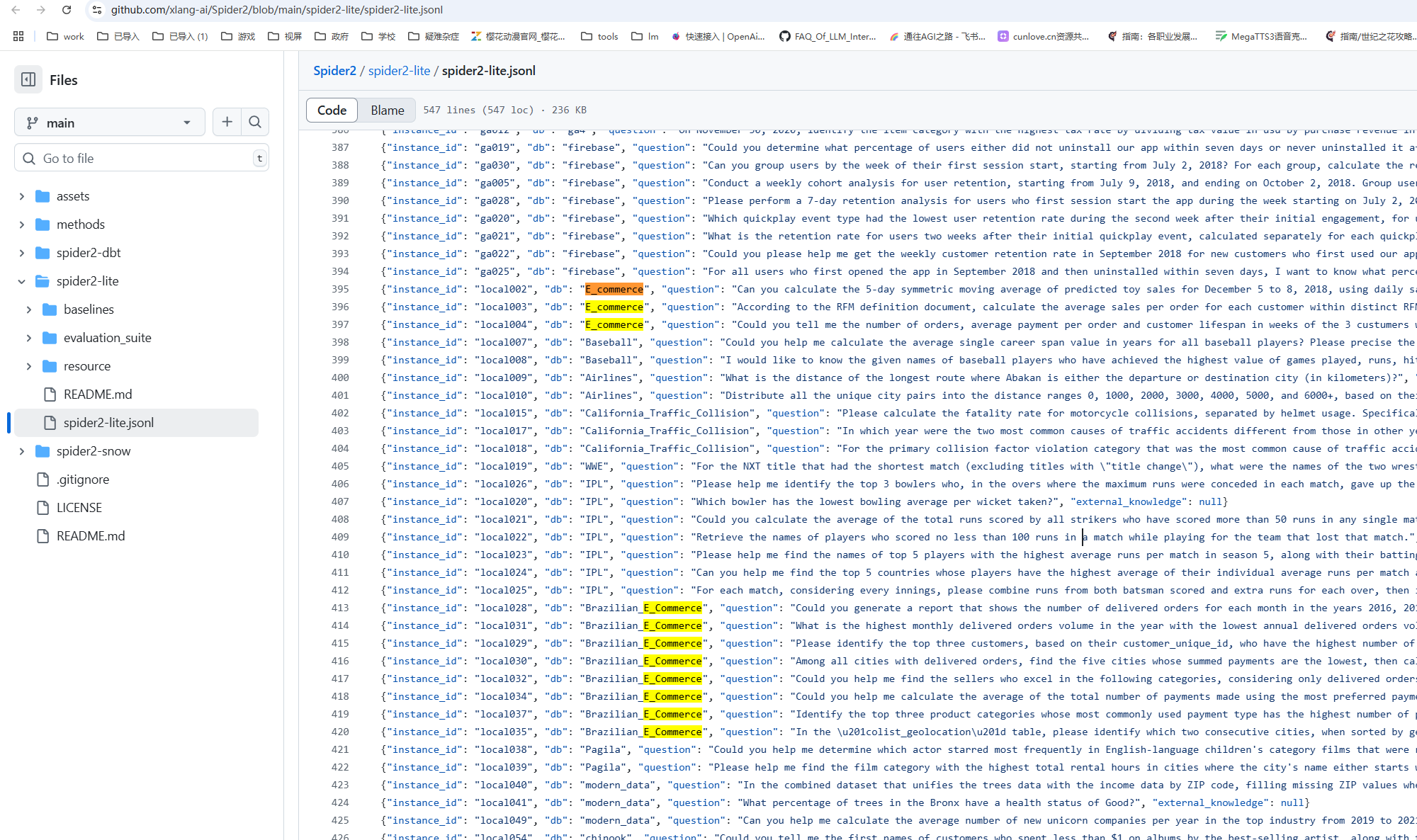
示例sql存储地址
测试问题
{"instance_id": "local028", "db": "Brazilian_E_Commerce", "question": "Could you generate a report that shows the number of delivered orders for each month in the years 2016, 2017, and 2018? Each column represents a year, and each row represents a month", "external_knowledge": null}
{"instance_id": "local031", "db": "Brazilian_E_Commerce", "question": "What is the highest monthly delivered orders volume in the year with the lowest annual delivered orders volume among 2016, 2017, and 2018?", "external_knowledge": null}
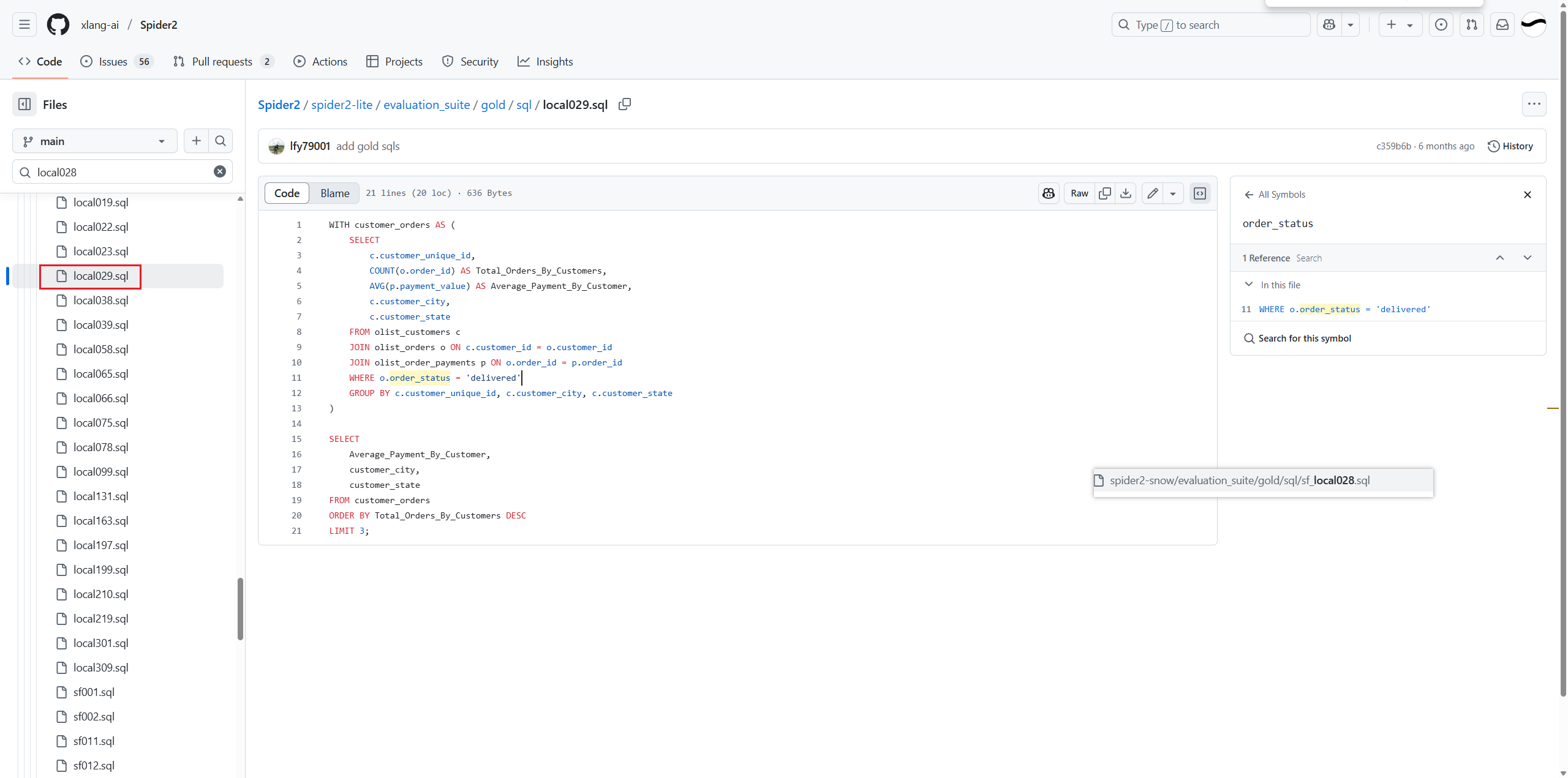
{"instance_id": "local029", "db": "Brazilian_E_Commerce", "question": "Please identify the top three customers, based on their customer_unique_id, who have the highest number of delivered orders, and provide the average payment value, city, and state for each of these customers.", "external_knowledge": null}
{"instance_id": "local030", "db": "Brazilian_E_Commerce", "question": "Among all cities with delivered orders, find the five cities whose summed payments are the lowest, then calculate the average of their total payments and the average of their total delivered order counts.", "external_knowledge": null}
{"instance_id": "local032", "db": "Brazilian_E_Commerce", "question": "Could you help me find the sellers who excel in the following categories, considering only delivered orders: the seller with the highest number of distinct customer unique IDs, the seller with the highest profit (calculated as price minus freight value), the seller with the highest number of distinct orders, and the seller with the most 5-star ratings? For each category, please provide the seller ID and the corresponding value, labeling each row with a description of the achievement.", "external_knowledge": null}
{"instance_id": "local034", "db": "Brazilian_E_Commerce", "question": "Could you help me calculate the average of the total number of payments made using the most preferred payment method for each product category, where the most preferred payment method in a category is the one with the highest number of payments?", "external_knowledge": null}
{"instance_id": "local037", "db": "Brazilian_E_Commerce", "question": "Identify the top three product categories whose most commonly used payment type has the highest number of payments across all categories, and specify the number of payments made in each category using that payment type.", "external_knowledge": null}
{"instance_id": "local035", "db": "Brazilian_E_Commerce", "question": "In the \u201colist_geolocation\u201d table, please identify which two consecutive cities, when sorted by geolocation_state, geolocation_city, geolocation_zip_code_prefix, geolocation_lat, and geolocation_lng, have the greatest distance between them based on the difference in distance computed between each city and its immediate predecessor in that ordering.", "external_knowledge": "spherical_law.md"}
local028(通过,基本符合)
Could you generate a report that shows the number of delivered orders for each month in the years 2016, 2017, and 2018? Each column represents a year, and each row represents a month
# 生成SQL
SELECTTO_CHAR( TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ), 'Month' ) AS MONTH,COUNT ( CASE WHEN TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ) BETWEEN '2016-01-01' AND '2016-12-31' THEN order_id END ) AS year_2016,COUNT ( CASE WHEN TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ) BETWEEN '2017-01-01' AND '2017-12-31' THEN order_id END ) AS year_2017,COUNT ( CASE WHEN TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ) BETWEEN '2018-01-01' AND '2018-12-31' THEN order_id END ) AS year_2018
FROMolist_orders
WHEREorder_status = 'delivered' AND order_delivered_customer_date IS NOT NULL AND TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ) BETWEEN '2016-01-01' AND '2018-12-31'
GROUP BYTO_CHAR( TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ), 'Month' )
ORDER BYTO_DATE( TO_CHAR( TO_DATE( order_delivered_customer_date, 'YYYY-MM-DD' ), 'Month' ), 'Month' );
分析
TO_CHAR(..., 'Month') 的问题
- 返回的是字符串,比如
'January '(注意:固定长度,右侧填充空格); - 导致排序不准:字符串
'April '会比'February '排前面。
优化版本
SELECTTO_CHAR(order_delivered_customer_date, 'MM') AS month_num,TO_CHAR(order_delivered_customer_date, 'Month') AS month_name,COUNT(CASE WHEN EXTRACT(YEAR FROM order_delivered_customer_date) = 2016 THEN order_id END) AS year_2016,COUNT(CASE WHEN EXTRACT(YEAR FROM order_delivered_customer_date) = 2017 THEN order_id END) AS year_2017,COUNT(CASE WHEN EXTRACT(YEAR FROM order_delivered_customer_date) = 2018 THEN order_id END) AS year_2018
FROM olist_orders
WHERE order_status = 'delivered'AND order_delivered_customer_date BETWEEN '2016-01-01' AND '2018-12-31'
GROUP BY month_num, month_name
ORDER BY month_num;local029(通过-完全符合)
Please identify the top three customers, based on their customer_unique_id, who have the highest number of delivered orders, and provide the average payment value, city, and state for each of these customers.
# 预期SQL
WITH customer_orders AS (SELECTc.customer_unique_id,COUNT(o.order_id) AS Total_Orders_By_Customers,AVG(p.payment_value) AS Average_Payment_By_Customer,c.customer_city,c.customer_stateFROM olist_customers cJOIN olist_orders o ON c.customer_id = o.customer_idJOIN olist_order_payments p ON o.order_id = p.order_idWHERE o.order_status = 'delivered'GROUP BY c.customer_unique_id, c.customer_city, c.customer_state
)SELECT Average_Payment_By_Customer,customer_city,customer_state
FROM customer_orders
ORDER BY Total_Orders_By_Customers DESC
LIMIT 3;# 模型生成SQL
SELECT C.customer_unique_id,COUNT ( o.order_id ) AS delivered_orders_count,ROUND( AVG ( CAST ( P.payment_value AS NUMERIC ) ), 2 ) AS avg_payment_value,C.customer_city,C.customer_state
FROMolist_customersC JOIN olist_orders o ON C.customer_id = o.customer_idJOIN olist_order_payments P ON o.order_id = P.order_id
WHEREo.order_status = 'delivered'
GROUP BYC.customer_unique_id,C.customer_city,C.customer_state
ORDER BYdelivered_orders_count DESC LIMIT 3;
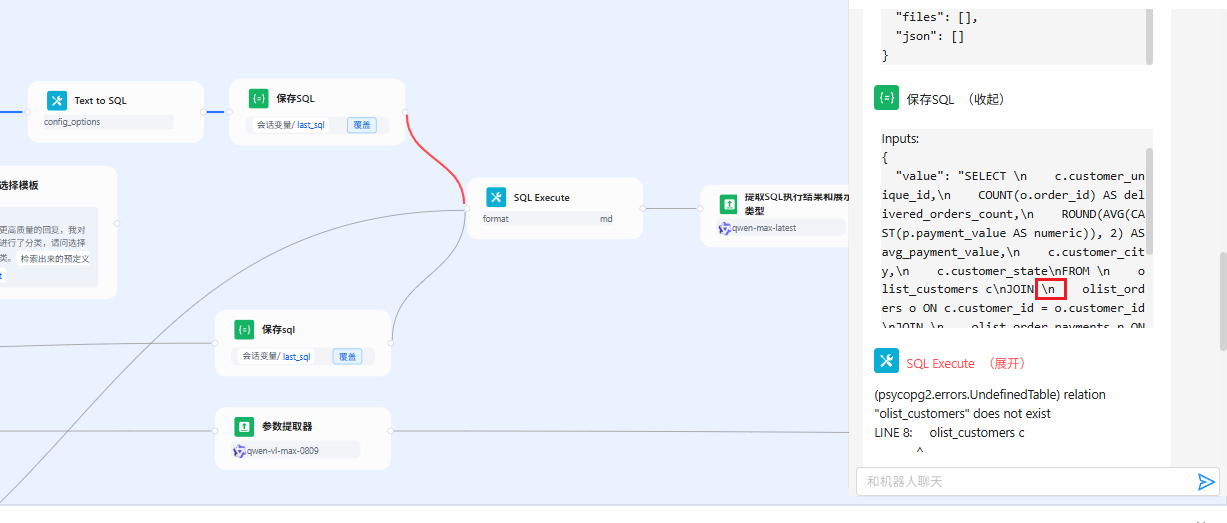
错误部分:
生成\n导致SQL执行出错
local030(通过-完全符合-但是流程有小瑕疵)
Among all cities with delivered orders, find the five cities whose summed payments are the lowest, then calculate the average of their total payments and the average of their total delivered order counts.
输出结果:有点问题,这和我写的Prompt有点出入,看来在text2sql这个节点还是改为智能体能够循环纠错比较好。
Here’s the PostgreSQL query to find the five cities with the lowest summed payments for delivered orders, then calculate the averages of their total payments and delivered order counts:\n\nSELECT \n AVG(total_payment) AS avg_total_payment,\n AVG(order_count) AS avg_order_count\nFROM (\n SELECT \n c.customer_city,\n SUM(p.payment_value) AS total_payment,\n COUNT(DISTINCT o.order_id) AS order_count\n FROM olist_orders o\n JOIN olist_order_payments p ON o.order_id = p.order_id\n JOIN olist_customers c ON o.customer_id = c.customer_id\n WHERE o.order_status = ‘delivered’\n GROUP BY c.customer_city\n ORDER BY total_payment ASC\n LIMIT 5\n) AS lowest_payment_cities;\n\nNote: I noticed a potential typo in the condition - I used ‘delivered’ as the order_status value based on the context, but please verify if this is the correct status value for delivered orders in your dataset. If it should be ‘delivered’ or another value, please adjust accordingly.
# 拆解出来的SQL如下
SELECT AVG( total_payment ) AS avg_total_payment,AVG ( order_count ) AS avg_order_count
FROM(SELECT C.customer_city,SUM ( P.payment_value ) AS total_payment,COUNT ( DISTINCT o.order_id ) AS order_count FROMolist_orders oJOIN olist_order_payments P ON o.order_id = P.order_idJOIN olist_customers C ON o.customer_id = C.customer_id WHEREo.order_status = 'delivered' GROUP BYC.customer_city ORDER BYtotal_payment ASC LIMIT 5 ) AS lowest_payment_cities;
分析
需要再text2sql的时候显示指出不允许生成解释信息的提示
local031(语法报错-已解决)
What is the highest monthly delivered orders volume in the year with the lowest annual delivered orders volume among 2016, 2017, and 2018?
WITH annual_orders AS (SELECT EXTRACT( YEAR FROM CAST ( order_delivered_customer_date AS DATE ) ) AS YEAR,COUNT ( * ) AS annual_count FROMolist_orders WHEREorder_status = 'delivered' AND EXTRACT ( YEAR FROM CAST ( order_delivered_customer_date AS DATE ) ) IN ( 2016, 2017, 2018 ) GROUP BYEXTRACT ( YEAR FROM CAST ( order_delivered_customer_date AS DATE ) ) SELECT EXTRACT( MONTH FROM CAST ( o.order_delivered_customer_date AS DATE ) ) AS MONTH,COUNT ( * ) AS monthly_count FROMolist_orders o WHEREorder_status = 'delivered' AND EXTRACT ( YEAR FROM CAST ( o.order_delivered_customer_date AS DATE ) ) = ( SELECT YEAR FROM annual_orders ORDER BY annual_count ASC LIMIT 1 ) GROUP BYEXTRACT ( MONTH FROM CAST ( o.order_delivered_customer_date AS DATE ) ) ORDER BYmonthly_count DESC LIMIT 1;
解决方案:增加一个校验LLM
## 角色定义:
你是一个 SQL 质量审查助手,擅长根据用户提出的自然语言问题,判断其对应 SQL 语句是否准确实现了意图,并在不吻合时对SQL进行修改,修改成吻合用户意图的SQL, 最终输出为可执行SQL, 不需要任何解释。你使用的SQL引擎是 环境变量 / sql_engine_type ;## 输入内容:
自然语言问题(用户需求): 会话变量 / last_question ;
用户提供的 SQL 语句: Text to SQL / text ;
✅ 任务目标
你需要:
1. 判断 SQL 是否完整且准确地实现了自然语言问题中的要求;
2. 找出不匹配的部分或潜在缺陷(如缺失的筛选条件、错误的聚合逻辑、多字段误用等);
3. 如果发现问题,提供一份优化后的可直接执行的 SQL ,不需要任何解释;
4. 如果没有问题,则原样输出SQL;
5. 性能优化,如果有多余的join可以尝试去除,优化SQL执行效率;
WITH YearlyDeliveries AS (SELECT EXTRACT( YEAR FROM order_delivered_customer_date :: TIMESTAMP ) AS YEAR,COUNT ( * ) AS annual_delivery_count FROMolist_orders WHEREorder_status = 'delivered' AND order_delivered_customer_date IS NOT NULL AND EXTRACT ( YEAR FROM order_delivered_customer_date :: TIMESTAMP ) IN ( 2016, 2017, 2018 ) GROUP BYYEAR ),LowestYear AS ( SELECT YEAR FROM YearlyDeliveries ORDER BY annual_delivery_count ASC LIMIT 1 ),MonthlyDeliveries AS (SELECT EXTRACT( YEAR FROM order_delivered_customer_date :: TIMESTAMP ) AS YEAR,EXTRACT ( MONTH FROM order_delivered_customer_date :: TIMESTAMP ) AS MONTH,COUNT ( * ) AS monthly_delivery_count FROMolist_orders WHEREorder_status = 'delivered' AND order_delivered_customer_date IS NOT NULL AND EXTRACT ( YEAR FROM order_delivered_customer_date :: TIMESTAMP ) = ( SELECT YEAR FROM LowestYear ) GROUP BYYEAR,MONTH ) SELECT MAX( monthly_delivery_count ) AS highest_monthly_delivery_count
FROMMonthlyDeliveries;
local032(语法错误-已解决)
Could you help me find the sellers who excel in the following categories, considering only delivered orders: the seller with the highest number of distinct customer unique IDs, the seller with the highest profit (calculated as price minus freight value), the seller with the highest number of distinct orders, and the seller with the most 5-star ratings? For each category, please provide the seller ID and the corresponding value, labeling each row with a description of the achievement.
生成结果:
Here’s the PostgreSQL query to find the top sellers in each requested category for delivered orders:\n\nSELECT \n ‘Seller with most distinct customers’ AS achievement,\n seller_id,\n COUNT(DISTINCT customer_id) AS value\nFROM olist_order_items oi\nJOIN olist_orders o ON oi.order_id = o.order_id\nWHERE o.order_status = ‘delivered’\nGROUP BY seller_id\nORDER BY value DESC\nLIMIT 1\n\nUNION ALL\n\nSELECT \n ‘Seller with highest profit’ AS achievement,\n seller_id,\n SUM(price - freight_value) AS value\nFROM olist_order_items oi\nJOIN olist_orders o ON oi.order_id = o.order_id\nWHERE o.order_status = ‘delivered’\nGROUP BY seller_id\nORDER BY value DESC\nLIMIT 1\n\nUNION ALL\n\nSELECT \n ‘Seller with most distinct orders’ AS achievement,\n seller_id,\n COUNT(DISTINCT oi.order_id) AS value\nFROM olist_order_items oi\nJOIN olist_orders o ON oi.order_id = o.order_id\nWHERE o.order_status = ‘delivered’\nGROUP BY seller_id\nORDER BY value DESC\nLIMIT 1\n\nUNION ALL\n\nSELECT \n ‘Seller with most 5-star ratings’ AS achievement,\n seller_id,\n COUNT(*) AS value\nFROM olist_order_items oi\nJOIN olist_orders o ON oi.order_id = o.order_id\nJOIN olist_order_reviews r ON o.order_id = r.order_id\nWHERE o.order_status = ‘delivered’ AND r.review_score = 5\nGROUP BY seller_id\nORDER BY value DESC\nLIMIT 1;\n\nNote: I noticed the schema didn’t include the olist_order_reviews table which would be needed for the 5-star ratings query. You would need to provide that table’s schema for that part of the query to work. The other three queries will work with the provided schema.
SELECT'Seller with most distinct customers' AS achievement,seller_id,COUNT ( DISTINCT customer_id ) AS
VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_id
WHEREo.order_status = 'delivered'
GROUP BYseller_id
ORDER BYVALUE
DESC LIMIT 1 UNION ALL
SELECT'Seller with highest profit' AS achievement,seller_id,SUM ( price - freight_value ) AS
VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_id
WHEREo.order_status = 'delivered'
GROUP BYseller_id
ORDER BYVALUE
DESC LIMIT 1 UNION ALL
SELECT'Seller with most distinct orders' AS achievement,seller_id,COUNT ( DISTINCT oi.order_id ) AS
VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_id
WHEREo.order_status = 'delivered'
GROUP BYseller_id
ORDER BYVALUE
DESC LIMIT 1 UNION ALL
SELECT'Seller with most 5-star ratings' AS achievement,seller_id,COUNT ( * ) AS
VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_idJOIN olist_order_reviews r ON o.order_id = r.order_id
WHEREo.order_status = 'delivered' AND r.review_score = 5
GROUP BYseller_id
ORDER BYVALUE
DESC LIMIT 1
解决方案:校验LLM
WITH distinct_customers AS (SELECTseller_id,COUNT ( DISTINCT customer_unique_id ) AS VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_idJOIN olist_customers C ON o.customer_id = C.customer_id WHEREo.order_status = 'delivered' GROUP BYseller_id ORDER BYCOUNT ( DISTINCT customer_unique_id ) DESC LIMIT 1 ),highest_profit AS (SELECTseller_id,SUM ( price - freight_value ) AS VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_id WHEREo.order_status = 'delivered' GROUP BYseller_id ORDER BYSUM ( price - freight_value ) DESC LIMIT 1 ),distinct_orders AS (SELECTseller_id,COUNT ( DISTINCT oi.order_id ) AS VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_id WHEREo.order_status = 'delivered' GROUP BYseller_id ORDER BYCOUNT ( DISTINCT oi.order_id ) DESC LIMIT 1 ),most_5_star_ratings AS (SELECToi.seller_id,COUNT ( * ) AS VALUEFROMolist_order_items oiJOIN olist_orders o ON oi.order_id = o.order_idJOIN olist_order_reviews r ON o.order_id = r.order_id WHEREo.order_status = 'delivered' AND r.review_score = 5 GROUP BYoi.seller_id ORDER BYCOUNT ( * ) DESC LIMIT 1 ) SELECT'Highest number of distinct customers' AS achievement,seller_id,VALUEFROMdistinct_customers UNION ALL
SELECT'Highest profit' AS achievement,seller_id,VALUEFROMhighest_profit UNION ALL
SELECT'Highest number of distinct orders' AS achievement,seller_id,VALUEFROMdistinct_orders UNION ALL
SELECT'Most 5-star ratings' AS achievement,seller_id,VALUEFROMmost_5_star_ratings;
local034(语法报错-逻辑错误)
Could you help me calculate the average of the total number of payments made using the most preferred payment method for each product category, where the most preferred payment method in a category is the one with the highest number of payments?
你能帮我计算每个产品类别中最常用的支付方式的支付总次数的平均值吗?
其中,“最常用的支付方式”指的是在该类别中支付次数最多的那种支付方式。
SELECT的P应该是payment_counts表
然后最终查询出来的AVG并不是真正的AVG
SELECT P.product_category_name,AVG ( payment_counts.total_payments ) AS avg_total_payments
FROM(SELECTop.payment_type,P.product_category_name,COUNT ( * ) AS total_payments,RANK ( ) OVER ( PARTITION BY P.product_category_name ORDER BY COUNT ( * ) DESC ) AS payment_rank FROMolist_order_payments opJOIN olist_orders o ON op.order_id = o.order_idJOIN olist_products_dataset P ON o.order_id = P.product_id GROUP BYop.payment_type,P.product_category_name ) AS payment_counts
WHEREpayment_counts.payment_rank = 1
GROUP BYP.product_category_name LIMIT 5;
解决方案:增加一个校验LLM
SUM(op.payment_sequential):这个字段是支付的序列号,不是支付金额也不是支付次数。应该是使用 COUNT(*) 来统计支付次数。
SELECT AVG( total_payments ) AS avg_payments
FROM(SELECT P.product_category_name,SUM ( op.payment_sequential ) AS total_payments FROMolist_order_payments opJOIN olist_order_items oi ON op.order_id = oi.order_idJOIN olist_products_dataset P ON oi.product_id = P.product_idJOIN (SELECT P.product_category_name,op.payment_type,COUNT ( * ) AS payment_count,RANK ( ) OVER ( PARTITION BY P.product_category_name ORDER BY COUNT ( * ) DESC ) AS RANK FROMolist_order_payments opJOIN olist_order_items oi ON op.order_id = oi.order_idJOIN olist_products_dataset P ON oi.product_id = P.product_id GROUP BYP.product_category_name,op.payment_type ) preferred ON P.product_category_name = preferred.product_category_name AND op.payment_type = preferred.payment_type AND preferred.RANK = 1 GROUP BYP.product_category_name ) category_totals;
local035(通过-完全符合)
In the \u201colist_geolocation\u201d table, please identify which two consecutive cities, when sorted by geolocation_state, geolocation_city, geolocation_zip_code_prefix, geolocation_lat, and geolocation_lng, have the greatest distance between them based on the difference in distance computed between each city and its immediate predecessor in that ordering.
输出内容:
WITH ordered_locations AS (SELECTgeolocation_city,geolocation_lat,geolocation_lng,LAG ( geolocation_city ) OVER ( ORDER BY geolocation_state, geolocation_city, geolocation_zip_code_prefix, geolocation_lat, geolocation_lng ) AS prev_city,LAG ( geolocation_lat ) OVER ( ORDER BY geolocation_state, geolocation_city, geolocation_zip_code_prefix, geolocation_lat, geolocation_lng ) AS prev_lat,LAG ( geolocation_lng ) OVER ( ORDER BY geolocation_state, geolocation_city, geolocation_zip_code_prefix, geolocation_lat, geolocation_lng ) AS prev_lng FROMolist_geolocation ),distance_calculations AS (SELECTgeolocation_city,prev_city,SQRT ( POWER ( geolocation_lat - prev_lat, 2 ) + POWER ( geolocation_lng - prev_lng, 2 ) ) AS distance FROMordered_locations WHEREprev_city IS NOT NULL ) SELECTprev_city AS city1,geolocation_city AS city2,distance
FROMdistance_calculations
ORDER BYdistance DESC LIMIT 1;
local037(逻辑不匹配)
Identify the top three product categories whose most commonly used payment type has the highest number of payments across all categories, and specify the number of payments made in each category using that payment type.
输出SQL
SELECT P.product_category_name,pop.payment_type,COUNT ( * ) AS payment_count
FROMolist_order_payments popJOIN olist_order_items ooi ON pop.order_id = ooi.order_idJOIN olist_products_dataset P ON ooi.product_id = P.product_id
GROUP BYP.product_category_name,pop.payment_type
ORDER BYpayment_count DESC LIMIT 3;
分析
需求;
- 每个 product category 内,先找出最常用的 payment_type;
- 然后在所有 category 的“最常用 payment_type”中,选出支付次数最多的前 3 个 category;
- 最终输出:这些 category 的名称、它们各自最常用的 payment_type,以及该支付方式的支付次数。
输出的SQL:
- 统计 每个产品类别、每种支付方式的支付次数;
- 然后选出全表中支付次数最多的前 3 个“产品类别 + 支付方式”组合。
正确的SQL应该为
WITH category_payment_counts AS (SELECT p.product_category_name,pop.payment_type,COUNT(*) AS payment_countFROMolist_order_payments popJOIN olist_order_items ooi ON pop.order_id = ooi.order_idJOIN olist_products_dataset p ON ooi.product_id = p.product_idGROUP BY p.product_category_name, pop.payment_type
),
most_used_payment_per_category AS (SELECT DISTINCT ON (product_category_name)product_category_name,payment_type,payment_countFROM category_payment_countsORDER BY product_category_name, payment_count DESC
)
SELECT product_category_name,payment_type,payment_count
FROM most_used_payment_per_category
ORDER BY payment_count DESC
LIMIT 3;总结
在本轮 Text2SQL 能力验证中,选取了 8 个具有代表性的问题进行测试,涵盖了常见的数据统计、聚合查询、过滤条件、多表关联等场景。
测试结果:
准确生成 SQL 的问题数量:6 个
生成错误或不符合预期的问题数量:2 个
准确率:75%
错误案例分析:
出错的两个问题均为逻辑较复杂或歧义较大的自然语言表达,主要问题包括:
问题语义不够清晰,例如涉及多个隐含条件,模型在缺乏上下文的情况下难以准确理解用户意图。
推理链条较长,需要多步转换或子查询逻辑,超出了当前 LLM 在单步推理中的稳定能力范围。
初步结论:
当前 Text2SQL 系统在常规查询任务中具备较强的生成能力,尤其是在表结构清晰、问题意图明确的情况下表现良好。
对于复杂语义、多层条件嵌套的问题,仍需进一步增强模型的“问题理解”和“逻辑推理”能力。
已经能够胜任比较简单的应用场景