得物向量数据库落地实践
一,背景
信息通信技术(ICT)正经历着前所未有的变革浪潮,以大模型和生成式人工智能(GenAI)为代表的技术突破,正在引发全球产业体系的深刻变革,成为驱动企业技术架构革新和商业模式转型的关键引擎。
得物是广受年轻人喜爱的品质生活购物社区。在 AI 鉴别、图搜、算法、安全风控等场景下都广泛使用了 GenAI 技术。
向量数据库作为 GenAI 的基础设施之一,通过量化的高维空间数据结构(如 HNSW 算法),实现对嵌入向量(Embeddings Vector)的高效存储、索引和最近邻搜索(ANN),支撑包括多模态数据表征在内的复杂智能应用。
二,认识向量数据库
向量数据来源和存储

一般向量数据库中向量的来源是将图片、音频、视频、文本等非结构化数据,将这些非结构化数据通过对应的量化算法计算出一个多维度的向量(生产使用一般向量维度会大于 512),并且将向量数据持久化在特定的存储上。
向量数据库是如何工作

向量数据库在查询的时候一般会将需要查询的非结构化数据通过量化,计算成一个多维度向量数据,然后在数据库中搜索出和查询向量相似的数据。(需要注意的是这边查询的是相似的数据而不是相同的数据)。
三,向量数据库对比传统数据库


向量数据库在数据结构、检索方法、擅长领域与传统数据库有很大的不同。
传统数据库
结构是处理离散的标量数据类型(例如数字和字符串),并通过行和列来表达组织数据(就是一个表格)。传统数据库主要为了解决结构化数据的精确管理和高效查询问题。并且传统数据库通过 B 树索引、哈希索引等数据结构,能够快速定位到精确匹配的记录。更重要的是,传统数据库通过 ACID 事务特性(原子性、一致性、隔离性、持久性)确保了在数据中数据的绝对准确性。
向量数据库
为了解决非结构化数据的语义搜索问题,解决如何在海量的高维向量数据中,快速找到与查询向量最相似的结果。比如在推荐系统中找到与用户喜好相似的物品,或在图像库中检索出与查询图片最相近的图片。这类问题的特点是:
查询的不是精确匹配,而是相似度排名。
数据维度极高(通常 128-2048 维)。
数据规模庞大(可能达到十亿级别)。
传统数据库的精确查询方式在这种场景下完全失效,因为:
无法为高维向量建立有效的 B 树索引。
计算全量数据的精确相似度代价过高。
无法支持"相似但不完全相同"的搜索需求。
四,如何选择向量数据库
向量数据库比较
下面我们通过 10 个不同维度来比较一下不同向量数据库的区别

从上面表格可以看到:
自 2016 年起 ,向量数据库逐渐崭露头角,成为 AI 和大数据领域的重要基础设施。而到了 2021 年之后 ,随着深度学习、大模型和推荐系统的迅猛发展,向量数据库正式迈入爆发式增长时代 ,成为现代数据架构中不可或缺的核心组件。
超过半数的向量数据库均采用分布式架构设计,并且这些支持分布式部署的系统普遍具备弹性扩缩容能力,能够根据业务需求实现资源的动态调整。
当业务需要处理亿级甚至更高规模的向量数据时,推荐以下高性能、可扩展的向量数据库:Vespa、Milvus/Zilliz、Vald、Qdrant。
当前主流的向量数据库普遍采用模块化、插件式的设计理念。其核心引擎大多基于 C/C++ 开发,以追求极致的性能表现。与此同时,Go 和 Rust 也正在这一领域崭露头角。
在向量数据库领域,HNSW(Hierarchical Navigable Small-World)和 DiskANN 正逐渐成为主流索引方案。其中 HNSW 主要以内存搜索为主,DiskANN 主要以磁盘搜索为主。值得注意的是,Qdrant 在优化 HNSW 的基础上,进一步实现了 基于磁盘的 HNSW 检索能力。
选择流行的索引
在向量数据库技术领域,有 HNSW 和 DiskANN 作为两大主流索引方案,各自展现了独特的技术优势。我们从以下关键维度进行专业对比分析。

从上表格我们可以得到,HNSW 和 DiskANN 适用于不同的场景:
HNSW :以 内存优先 的设计实现高性能搜索,适合 低延迟、高吞吐 要求严格的场景,如实时推荐、广告检索等。
DiskANN :以 磁盘存储优化 为核心,在保证较高召回率的同时 显著降低硬件成本 ,适用于大规模数据下的经济型检索需求。
随着数据规模的持续增长,HNSW 和 DiskANN 的混合部署模式 或将成为行业标准,让用户能根据业务需求灵活选择 "极致性能" 或 "最优成本" 的检索策略。
综合比较和选择

从表格中可以得到:
如果数据流比较小,并且自身对 Redis、PG、ES 比较熟悉,就可以选择 Redis、PG、ES。如 DBA 团队就比较适合。
如果数据量比较大,并且前期人力不足可以使用云托管方案。选择 Zilliz、Pinecone、Vespa 或者 Qdrant,如果后期计划从云上迁移到自建可以选择 Zilliz、Vespa 或者 Qdrant。
得物选择 Milvus 作为向量数据库
我们的需求
社区图搜和 AI 鉴别需要大量的数据支持,得物业务场景要求能支持十亿级向量数据搜索,有如下要求:
大数据量高性能搜索,RT 需要在 90ms 以内。
大数据量但是性能要求不高时,RT 满足 500ms 以内。
需要支持快速扩缩容:
满足上面 2 点就已经锁定在 Milvus、Qdrant 这两个向量数据库。如果从架构复杂度和维护/学习成本的角度考虑,我们应该优先选择 Qdrant,因为它的架构相比 Milvus 没有那么复杂,并且维护/学习成本没有 Milvus 高,重要的 Qdrant 可以单独集群部署,不需要 k8s 技术栈的支撑。
Milvus 和 Qdrant 架构比较
Milvus 架构:

Milvus 部署依赖许多外部组件,如存储元信息的 ETCD、存储使用的 MinIO、消息存储 Pulasr 等。
Qdrant:

Qdrant 完全独立开发,支持集群部署,不需要借助 ETCD、Pulsar 等组件。
选择 Milvus 的原因
※ 业务发展需求
业务属于快速发展阶段,数量的变化导致扩缩容频繁,使用支持 k8s 的 Milvus 在扩缩容方面会比 Qdrant 快的多。
※ 技术储备和社区良好
对 DBA 而言,向量数据库领域需要持续的知识更新和技术支持。从问题解决效率来看,国内技术社区对 Milvus 的支持体系相较于 Qdrant 更为完善。
※ 契合得物 DBA 开发栈
Milvus 使用的开发语言是 Go,契合 DBA 团队技术栈,在部分运维场景下,通过二次开发满足运维需求。例如:使用 milvus-backup 工具做迁移,部分的 segment 有问题需要跳过。自行修改一下代码编译运行即可满足需求。

五,Milvus 在得物的实践
部署架构演进
小试牛刀
初始阶段,我们把 Milvus 部署在 K8S 上,默认使用 HNSW 索引。架构图如下,Milvus 整个架构较为复杂,外部依赖的组件多,每个集群需要部署自己的 ETCD、ZK、消息队列模块,多套集群共享着同一个存储。

存储拆分,每个集群独立存储
共享存储瓶颈导致稳定性问题凸显。
随着业务规模扩展,集群数量呈指数级增长,我们观测到部分集群节点出现异常重启现象,经诊断确认该问题源于底层共享存储存在性能瓶颈。


独立资源池迁移至共享资源池
通过混布的方式提升资源利用率。
前期为了在性能和稳定性上更好的服务业务,Milvus 部署的底层机器都是独立的,目的就是为了和其他应用隔离开,不相互影响。但是随着集群的越来越多,并不是所有的集群对稳定性和性能要求那么高,从监控上看 Milvus 集群池的资源使用不超过 10%。为了提高公司资源利用率,我们将独立部署的 Milvus 迁移高共享资源池中,和大数据、业务应用等 K8S 部署相关服务进行混合部署。

DiskANN 索引的使用
数据量大且搜索 QPS 小时选择 DiskANN 作为索引。通过监控发现有很多集群数据量比较大,但是 QPS 并不是那么高,这时候就考虑对这些性能要求不高的集群是否有降本的方案。通过了解我们默认使用的 HNSW 索引需要将所有数据都加载到内存中进行搜索,第一反应就是它的内存查询和 Redis 一样,那是否有类似 pika 的方案内存只存少部分数据大部分数据存在磁盘上。这时候发现 DiskANN 就能达到这样的效果。
性能压测
※ 集群规格


QPS

图片延时(ms)
新增 DiskANN 索引后集群架构
增加 DiskANN 后我们需要对相关服务器上挂载 NVME SSD 磁盘,用于在磁盘上搜索最终数据。

DiskANN 加载数据过程

引入 Zilliz
经过大规模生产验证,Milvus 在实际业务场景中展现出卓越的性能表现和稳定性,获得业务方的高度认可。并且也吸引来了 C 端核心业务系统的使用。在使用前,我们使用了业务真实流量充分的对 Milvus 进行了压测,发现 Milvus 在亿级别数据量的情况下满足不了业务,因此对于部分核心场景我们使用了 Zilliz。
Milvus 和 Zilliz 压测
业务的要求是集群返回的 RT 不能操过 90ms。
使用真实的业务数据(亿级别)和业务请求对 Milvus 进行压测,发现 Milvus 并不能满足业务的需求。
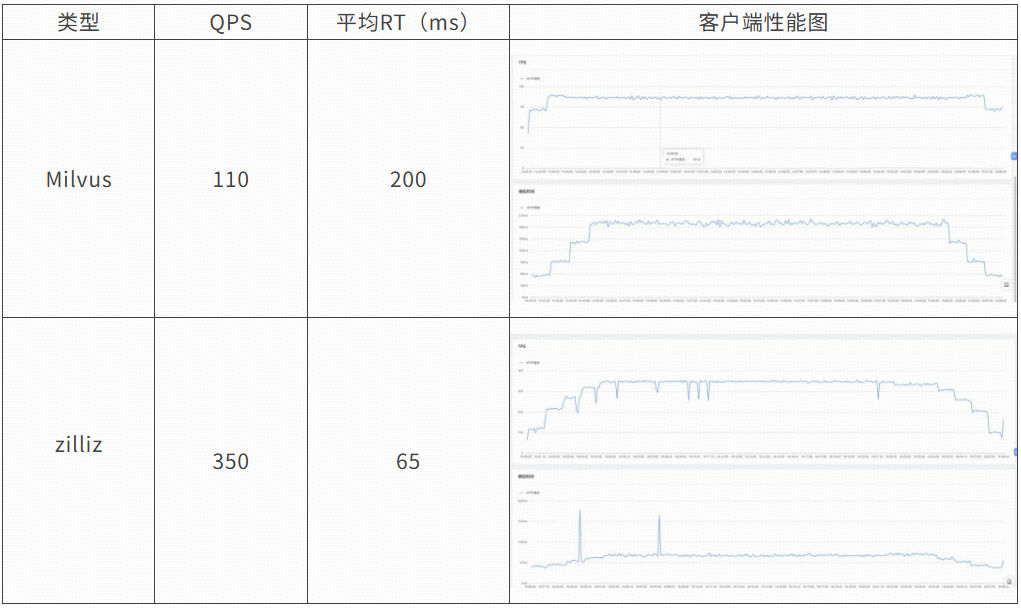
Milvus RT 200 不满足业务需求,并且 QPS 一直上不去,无论我们对 QueryNode 扩容多大,其中还发生过,将 Query 扩容到 60 个后,反而 RT 上升的问题,排查后是因为有的 QueryNode 和 Proxy 交互的时候网络会抖动影响了整体的 RT。
从上面可以看出就算业务能容忍 RT=200ms 的,Milvus 也需要创建 3 个相同的集群提供业务访问,并且业务需要改造代码实现多写、多读的功能,最终还会发现 3 个集群的成本远高于 Zilliz。
通过成本和性能上的考虑,对于大数据量并且性能和稳定性要求高场景,我们将选用 Zilliz。
迁移方案
对于不同业务场景,我们分别制定了以下 3 种迁移方案:
方案 1:业务自行导入数据使用

方案 2:备份恢复 + 业务增量

方案 3:全量 + 增量 + 业务双写/回滚

高可用架构部署
随着业务关键性持续提升,Milvus 对应的 SLA 变得越来越重要。在此背景下,构建完善的 Milvus 高可用架构与灾备体系已成为系统设计的核心考量要素。比如:主从、多 zone 部署,Proxy 高可用,Minio 高可用,一个 zone 完全挂了怎么办等问题?
方案 1: 同城多机房混部
正常访问:
该方案会有客户端会有跨机房访问的情况。
跨机房访问节点:
客户端 -> SLB
SLB -> Proxy
Proxy -> QueryNode
SLB 有高可用
Proxy 有高可用

当部分节点不可用:
当 zone 1 中的 proxy 1 不可用,不影响整个访问链路,其他 Proxy 依然可以接受请求。
当 zone 1 中的 QueryNode 1 不可用,会出现访问报错的问题。需要重建 QueryNode1,有可能在 Zone 2 新建 QueryNode 5,原本请求 QueryNode 1 的流量会重新指向 QueryNode 5。
当 Zone1 不可用:
访问会切换到 Zone 2 的备用 SLB 中。
备用 SLB 会访问本机房的 Proxy。
由于 QueryNode 1 和 QueryNode 2 已经不可用,需要重建 QueryNode,新生成 QueryNode 5、QueryNode 6 并且加载数据提供访问。

方案 2: 同城多 zone 多副本就近访问
正常访问:
不同 zone 的客户端访问本地的 SLB。
使用了 QueryNode 多副本特性,各自 zone 的 QueryNode 都加载了所有数据。
Proxy -> QueryNode 的访问,目前 Proxy 只能随机访问所有 zone 的 QueryNode(这是 Milvus 的限制)

当部分节点不可用:
当每个 zone 都有 1 个 Proxy 故障,并不影响业务正常访问。
由于 QueryNode 开启了副本,只要每个 zone 不相同的 QueryNode 故障,集群还是能正常运行。需要注意的是这时候需要考虑剩下的 QueryNode 性能是否满足需求。所以一般业务需要有限流功能,在剩余的 QueryNode 不满足需求时,业务需要限流,直到其他 QueryNode 恢复。

整个 Zone 不可用:
当 Zone1 整个不可用,不影响 Zone2 的访问。

方案 3: 同城多 zone 单独部署业务交叉访问互相 backup
正常访问:
每个 zone 都有单独部署的 milvus 集群。
每个集群的有同时满足 业务 1、业务 2 访问的数据。
业务访问 Proxy 的时候是有交叉访问的情况
业务改造会比较多,需要实现双写。

当部分节点不可用:
当 Zone1 中的 Proxy1 部可用,不会影响 Zone1 的整个集群访问。
当 Zone1 的 QueryNode1 不可用,会影响到线路 1、2 的正常访问,这时候业务需要切换不访问 Zone1 的 SLB。

当整个 zone 不可用
整个 zone1 不可用,由于线路 1 会访问到 zone1 的 SLB,因此线路 1 访问会报错,业务需要将线路 1 切换成线路 2。

六,向量数据库运维沉淀
索引结构和搜索原理
HNSW 索引
※ 相关信息

※ 内存结构
由于空间问题,图中并没有完全按 M=16、ef=200 参数进行画图。

※ HNSW 搜索过程
现在需要搜索向量 N = [....]
第一步:
在第一层随机选择一个节点,如:3。

第二步:
通过节点 3,从第 1 层转跳到第 2 层
在第 2 层,通过节点 3 获取到相邻的节点:节点 1、节点 2、节点 5、节点 6。
将搜索节点 N 逐个和 节点 1、节点 2、节点 5、节点 6 进行计算出各自的距离。并且选择距离最短的节点 6。
节点 N -> 节点 1:10
节点 N -> 节点 2:6
节点 N -> 节点 5:9
节点 N -> 节点 6:3
节点 N -> 节点 3:4
将 节点 1、节点 2、节点 5、节点 6、节点 3 放入结果候选集中。

第三步:
。通过节点 6,从第二层跳到底 3 层
在第 3 层,通过节点 6 获取到相邻的节点:节点 2、节点 3、节点 6、节点 9,其中 节点 2、节点 3、节点 6 已经存在,因此只需要将 节点 9 放入候选结果集。
如果候选结果集合没有满,则继续便利 节点 2、节点 3、节点 9 的邻居,直到 节点数=ef=200。

DiskANN 索引
※ 相关信息
※ 存储结构和裁剪过程
由于画图空间问题,没办法将 聚类数=10、100/内存聚类、1w/磁盘聚类 信息画全。

初始化随机连接:DiskANN 算法会将向量数据生成一个密集的网络图,其中点和点是随机链接的,并且每个点大概有 500 个链接。
裁剪冗余链接:通过计算点和点点距离裁剪掉一些冗余的链接,留下质量高的链接。
添加快速导航链接:计算出图中若干个中心点,并且将这些中心点进行链接,并且这些链接会跳过其他点,如果图中黄色链接。
重复进行裁剪优化过程,达到最优的情况。
PQ 量化操作生成索引:
将向量分成多个子空间。
独立对每个子空间进行聚类操作,并且计算出多个质心。
将每个子向量映射到最近的质心 ID。
※ DiskANN 搜索过程
现在需要搜索向量 N = [....]
第一步(内存索引中搜索):
将搜索的向量进行量化。
将量化后的数据在内存中索引寻找到离自己较近的质心为入口进行下一步搜索。

第二步(内存中搜索):
通过第一个节点,寻找到它的所有相邻节点。
通过内存 PQ 代码计算搜索节点和相邻节点的近似距离。
这些邻居节点都是潜在的下次搜索候选口节点。

第三步(磁盘中搜索):
通过计算搜索节点和相邻节点的真实距离,并且得到距离最近的一个节点(需要从磁盘上读取证实的节点数据并计算)。
并且通过得到的最新节点获取到新的相邻节点。

第四步(磁盘中搜索):
反复先进二、三步骤操作,直到找到足够数量的邻居。

并不是你想的那样
querynode 越多越快?
querynode 越多,查询越快,并发越高?
※误区原因
将 querynode 看成 redis cluster,增加节点数能提高查询并发,然而并不是。redis cluster 增加节点,数据量会尽可能的打散到每个节点中,所以增加节点和性能提升是相对成正比。但是 milvus 不一样,milvus 打散的基本单位是 segment,一般 segment 大小(1G/个),他的粒度比 redis cluster 要大。理论上的理想情况是 1 个 segment 对应 1 个 querynode,但是实际情况会收到多因素的干扰,会导致 querynode 越多出现不稳定的概率越大,如某个 querynode 网络抖动会影响整体的查询 RT。
不能提升性能例 1:
部分 segment 数 < querynode 数,或部分 querynode 没有任何 segment。

不能提升性能例 2:
querynode 过多,其中 1 个 querynode RT 高,导致整体客户端 RT 高。

标量索引提高性能
在标量上创建索引,搜索带上标量过来能提高性能?
※误区原因
使用传统关系型数据库的索引查询来理解 Milvus 的索引查询,字段上创建了索引能使用到索引扫描进行数据查询,比全表扫描快。然而并不是,关系型数据库的属于精确查询,Milvus 属于近似最近邻搜索(ANNS),milvus 的查询是不保证绝对精确,使用了标量索引查询反而会导致数据变稀疏查询会变慢。
使用标量索引筛选不一定快原因,如下示例:
通过标量搜索后再使用 ANNS 搜索过程:
1.Collection A 中的数据如下,其中 is_delete 是标量,其中的值有 0 和 1。

2.使用标量搜索 is_delete=1 后剩余的数据。

通过标量 is_delete=1 搜索成功之后,有可能结果集会很大,结果集数据如果内存存放不下需要使用到磁盘存储,之后再在结果集中通过 ANNS 获取到最终需要的数据,如果需要频繁进行磁盘交互则搜索性能会很差。
3.再使用 ANNS 搜索获取最终数据。

通过 ANNS 搜索后再使用标量搜索,过程如下:
1.Collection A 中的数据如下,其中 is_delete 是标量,其中的值有 0 和 1。

2.使用 ANNS 搜索
使用 ANNS 搜索能直接很快地获取到满足条件的数据。

3.再使用标量过滤,获取到最终的数据。

思考:
在第二步如果使用 ANNS 搜索完成之后到底是否需要使用标量索引进行搜索。
如果需要使用标量索引进行搜索那边在 ANNS 搜索后的结果集需要额外的进行索引构建,然后再进行过滤。构建构建过程其实也是需要便利结果集,那么是不是可以直接在便利的时候直接进行结果集的筛选。
那么其实在某种程度上是不是标量索引没那么好用。
大量单行 dml 不批量写入能提高数据库性能
大量单行 dml,不使用批量写入操作,能提高数据库性能。
※误区原因
使用传统关系型数据库为了让系统尽量少的大事务,减少锁问题并且提高数据库性能。然而实际上 Milvus 如果有很多的小事务反而会影响到数据库的性能。因为 Milvus 进行 dml 操作会生成 deltalog、insertlog,当 dml 都是小事务就会生成大量的相对较小的 deltalog 和 insertlog 文件,deltalog 和 insertlog 在和 segment 做合并的时候会增加打开和关闭文件次数,并且增加做合并次数,导致 io 一直处于繁忙状态。
deltalog 和 insertlog 生成的契机有 2 种:
当数据量达到了一定的阈值会进行生成 deltalog 或 insertlog。
Milvus 会定时进行生成 deltalog 或 insertlog。
eltalog、insertlog 和 segment 合并过程

人为让 deltalog、segment 执行时机可预测
如果业务对数据实现要求不是那么高,建议使用定时批量的方式对数据进行写入,比如可以通过监控获取到每天的波谷时间段,在波谷时间段内进行集中式数据写入。原因是如果不停的在做写入,无法判断进行合并 segment 的时间点,要是在高峰期进行了合并操作,很有可能会影响到集群性能。
错误处理
※ 2.2.6 批量删除数据 bug,导致业务无法查询
报错:
pymilvus.exceptions.MilvusException: <MilvusException: (code=1, message=syncTimestamp Failed:err: find no available rootcoord, check rootcoord state
, /go/src/github.com/milvus-io/milvus/internal/util/trace/stack_trace.go:51 github.com/milvus-io/milvus/internal/util/trace.StackTrace
/go/src/github.com/milvus-io/milvus/internal/util/grpcclient/client.go:329 github.com/milvus-io/milvus/internal/util/grpcclient.(*ClientBase[...]).ReCall
/go/src/github.com/milvus-io/milvus/internal/distributed/rootcoord/client/client.go:421 github.com/milvus-io/milvus/internal/distributed/rootcoord/client.(*Client).AllocTimestamp
/go/src/github.com/milvus-io/milvus/internal/proxy/timestamp.go:61 github.com/milvus-io/milvus/internal/proxy.(*timestampAllocator).alloc
/go/src/github.com/milvus-io/milvus/internal/proxy/timestamp.go:83 github.com/milvus-io/milvus/internal/proxy.(*timestampAllocator).AllocOne
/go/src/github.com/milvus-io/milvus/internal/proxy/task_scheduler.go:172 github.com/milvus-io/milvus/internal/proxy.(*baseTaskQueue).Enqueue
/go/src/github.com/milvus-io/milvus/internal/proxy/impl.go:2818 github.com/milvus-io/milvus/internal/proxy.(*Proxy).Search
/go/src/github.com/milvus-io/milvus/internal/distributed/proxy/service.go:680 github.com/milvus-io/milvus/internal/distributed/proxy.(*Server).Search
/go/pkg/mod/github.com/milvus-io/milvus-proto/go-api@v0.0.0-20230324025554-5bbe6698c2b0/milvuspb/milvus.pb.go:10560 github.com/milvus-io/milvus-proto/go-api/milvuspb._MilvusService_Search_Handler.func1
/go/src/github.com/milvus-io/milvus/internal/proxy/rate_limit_interceptor.go:47 github.com/milvus-io/milvus/internal/proxy.RateLimitInterceptor.func1
)>解决:将集群升级到 2.2.16,并且让业务 批量删除和写入数据。
※ find no available rootcoord, check rootcoord state
报错:
[2024/09/26 08:19:14.956 +00:00] [ERROR] [grpcclient/client.go:158] ["failed to get client address"] [error="find no available rootcoord, check rootcoord state"] [stack="github.com/milvus-io/milvus/internal/util/grpcclient.(*ClientBase[...]).connect
/go/src/github.com/milvus-io/milvus/internal/util/grpcclient/client.go:158
github.com/milvus-io/milvus/internal/util/grpcclient.(*ClientBase[...]).GetGrpcClient
/go/src/github.com/milvus-io/milvus/internal/util/grpcclient/client.go:131
github.com/milvus-io/milvus/internal/util/grpcclient.(*ClientBase[...]).callOnce
/go/src/github.com/milvus-io/milvus/internal/util/grpcclient/client.go:256
github.com/milvus-io/milvus/internal/util/grpcclient.(*ClientBase[...]).ReCall
/go/src/github.com/milvus-io/milvus/internal/util/grpcclient/client.go:312
github.com/milvus-io/milvus/internal/distributed/rootcoord/client.(*Client).GetComponentStates
/go/src/github.com/milvus-io/milvus/internal/distributed/rootcoord/client/client.go:129
github.com/milvus-io/milvus/internal/util/funcutil.WaitForComponentStates.func1
/go/src/github.com/milvus-io/milvus/internal/util/funcutil/func.go:65
github.com/milvus-io/milvus/internal/util/retry.Do
/go/src/github.com/milvus-io/milvus/internal/util/retry/retry.go:42
github.com/milvus-io/milvus/internal/util/funcutil.WaitForComponentStates
/go/src/github.com/milvus-io/milvus/internal/util/funcutil/func.go:89
github.com/milvus-io/milvus/internal/util/funcutil.WaitForComponentHealthy
/go/src/github.com/milvus-io/milvus/internal/util/funcutil/func.go:104
github.com/milvus-io/milvus/internal/distributed/datanode.(*Server).init
/go/src/github.com/milvus-io/milvus/internal/distributed/datanode/service.go:275
github.com/milvus-io/milvus/internal/distributed/datanode.(*Server).Run
/go/src/github.com/milvus-io/milvus/internal/distributed/datanode/service.go:172
github.com/milvus-io/milvus/cmd/components.(*DataNode).Run
/go/src/github.com/milvus-io/milvus/cmd/components/data_node.go:51
github.com/milvus-io/milvus/cmd/roles.runComponent[...].func1
/go/src/github.com/milvus-io/milvus/cmd/roles/roles.go:102"]问题:rootcoord 和其他 pod 通信出现了问题。
解决:先重建 rootcoord,再依次重建相关的 querynode、indexnode、queryrecord、indexrecord。
※ 页面查询报错
(Search 372 failed, reason Timestamp lag too large lag)
[2024/09/26 09:14:13.063 +00:00] [WARN] [retry/retry.go:44] ["retry func failed"] ["retry time"=0] [error="Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_search.go:529] ["QueryNode search result error"] [traceID=62505beaa974c903] [msgID=452812354979102723] [nodeID=372] [reason="Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_policies.go:132] ["failed to do query with node"] [traceID=62505beaa974c903] [nodeID=372] [dmlChannels="[by-dev-rootcoord-dml_6_442659379752037218v0,by-dev-rootcoord-dml_7_442659379752037218v1]"] [error="code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_policies.go:159] ["retry another query node with round robin"] [traceID=62505beaa974c903] [Nexts="{\"by-dev-rootcoord-dml_6_442659379752037218v0\":-1,\"by-dev-rootcoord-dml_7_442659379752037218v1\":-1}"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_policies.go:60] ["no shard leaders were available"] [traceID=62505beaa974c903] [channel=by-dev-rootcoord-dml_6_442659379752037218v0] [leaders="[<NodeID: 372>]"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_policies.go:119] ["failed to search/query with round-robin policy"] [traceID=62505beaa974c903] [error="Channel: by-dev-rootcoord-dml_7_442659379752037218v1 returns err: code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)Channel: by-dev-rootcoord-dml_6_442659379752037218v0 returns err: code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_search.go:412] ["failed to do search"] [traceID=62505beaa974c903] [Shards="map[by-dev-rootcoord-dml_6_442659379752037218v0:[<NodeID: 372>] by-dev-rootcoord-dml_7_442659379752037218v1:[<NodeID: 372>]]"] [error="code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_search.go:425] ["first search failed, updating shardleader caches and retry search"] [traceID=62505beaa974c903] [error="code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [INFO] [proxy/meta_cache.go:767] ["clearing shard cache for collection"] [collectionName=xxx]
[2024/09/26 09:14:13.063 +00:00] [WARN] [retry/retry.go:44] ["retry func failed"] ["retry time"=0] [error="code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)"]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/task_scheduler.go:473] ["Failed to execute task: "] [error="fail to search on all shard leaders, err=All attempts results:\nattempt #1:code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)\nattempt #2:context canceled\n"] [traceID=62505beaa974c903]
[2024/09/26 09:14:13.063 +00:00] [WARN] [proxy/impl.go:2861] ["Search failed to WaitToFinish"] [traceID=62505beaa974c903] [error="fail to search on all shard leaders, err=All attempts results:\nattempt #1:code: UnexpectedError, error: fail to Search, QueryNode ID=372, reason=Search 372 failed, reason Timestamp lag too large lag(28h44m48.341s) max(24h0m0s) err %!w(<nil>)\nattempt #2:context canceled\n"] [role=proxy] [msgID=452812354979102723] [db=] [collection=xxx] [partitions="[]"] [dsl=] [len(PlaceholderGroup)=4108] [OutputFields="[id,text,extra]"] [search_params="[{\"key\":\"params\",\"value\":\"{\\\"ef\\\":250}\"},{\"key\":\"anns_field\",\"value\":\"vector\"},{\"key\":\"topk\",\"value\":\"100\"},{\"key\":\"metric_type\",\"value\":\"L2\"},{\"key\":\"round_decimal\",\"value\":\"-1\"}]"] [travel_timestamp=0] [guarantee_timestamp=0]问题:pulsar 组件对应相关 pod 问题导致不进行消费。
解决:将 pulsar 组件相关 pod 进行重建,查看日志,并且等待消费 pulsar 完成。
※ Query Node 限制内存不足
(memory quota exhausted)
报错:
<MilvusException: (code=53, message=deny to write, reason: memory quota exhausted, please allocate more resources, req: /milvus.proto.milvus.MilvusService/Insert)>原因:配置中 Query Node 配置内存上线达到瓶颈。
解决:增加 Query Node 配置或者增加 QueryNode 节点数。
※ 底层磁盘瓶颈导致 ETCD 访问超时
报错:

解决:从架构方面上进行解决,在集群维度将磁盘进行隔离,每个集群使用独立磁盘。
七,未来展望
数据迁移闭环
数据迁移闭环:对于业务数据加载到向量数据库的场景,业务只关心数据的读取和使用,不需要关心数据的量化和写入。DBA 侧建立数据迁移闭环(下图绿色部分)。
数据准确性校验
对于上游数据(如 MySQL)和下游向量数据库数据库一致性校验问题,DBA 业将协同业务、Milvus 进行共建校验工具,保障数据的准确性。

往期回顾
1.社区搜索离线回溯系统设计:架构、挑战与性能优化|得物技术
2.从 Rust 模块化探索到 DLB 2.0 实践|得物技术
3.eBPF 助力 NAS 分钟级别 Pod 实例溯源|得物技术
4.正品库拍照 PWA 应用的实现与性能优化|得物技术
5.汇金资损防控体系建设及实践 | 得物技术
文 / 呆呆 少晖
关注得物技术,每周二、四更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任