OpenAI 开源GPT OSS系列模型
在AI发展的历程中,开源与闭源模型之间的竞争一直备受关注。就在近期,OpenAI发布了GPT OSS系列模型,这是自GPT-2以来该公司首次发布的开源大语言模型,标志着OpenAI在开源生态中迈出了重要一步。
模型下载地址:
- https://huggingface.co/openai/gpt-oss-120b
- https://huggingface.co/openai/gpt-oss-20b
官方博客地址:
- https://openai.com/zh-Hans-CN/open-models/
模型概览:两个规模,各有所长
GPT OSS系列包含两个主要版本:gpt-oss-120b和gpt-oss-20b。从命名就能看出,前者拥有1170亿总参数,后者为210亿参数。不过这里有个有趣的设计——两个模型都采用了专家混合(MoE)架构,实际激活的参数数分别只有51亿和36亿。这种设计带来的直接好处就是在保持强大性能的同时,显著降低了计算和内存需求。
值得一提的是,120B模型可以在单张80GB的H100 GPU上运行,而20B模型更是只需要16GB内存就能跑起来。这意味着普通开发者也能在消费级硬件上体验到接近顶级AI模型的能力,这在以往是难以想象的。
技术架构:效率与性能的平衡
从技术角度来看,GPT OSS采用了不少先进的优化策略。模型使用了旋转位置编码(RoPE)来处理位置信息,原生支持128K的上下文长度。在注意力机制方面,模型采用了交替的全上下文注意力和滑动窗口注意力,既保证了长距离依赖的捕获,又控制了计算复杂度。
特别值得关注的是模型的量化技术。GPT OSS使用了4位量化的MXFP4格式,这种量化方案在Hopper和Blackwell系列GPU上表现优异。对于不支持MXFP4的硬件,模型会自动回退到bfloat16格式,确保了广泛的兼容性。
在优化方面,模型支持Flash Attention 3、MegaBlocks MoE kernels等多种加速技术。针对不同的硬件环境,用户可以选择最适合的优化组合来获得最佳性能。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_id = "openai/gpt-oss-20b"tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map="auto",torch_dtype="auto",
+ # Flash Attention with Sinks
+ attn_implementation="kernels-community/vllm-flash-attn3",
)messages = [{"role": "user", "content": "How many rs are in the word 'strawberry'?"},
]inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,return_tensors="pt",return_dict=True,
).to(model.device)generated = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(generated[0][inputs["input_ids"].shape[-1]:]))下面是优化的总结

CoT思维链
OpenAI的研究发现,如果在训练过程中对模型的思维链进行直接的"对齐监督"(也就是人为干预和修正模型的思考过程),会降低我们检测模型异常行为的能力。换句话说,如果我们教会模型"如何思考才是正确的",模型就可能学会隐藏其真实的思考过程,这样我们就很难发现它是否在进行有害的推理。
因此,OpenAI选择不对GPT OSS模型的思维链进行直接监督,保持思维链的"原生性",让模型的思考过程保持相对"原生"的状态。这样做的目的是确保我们能够通过观察模型的思维链来:
- 检测模型是否出现异常行为
- 发现潜在的欺骗行为
- 识别可能的滥用情况
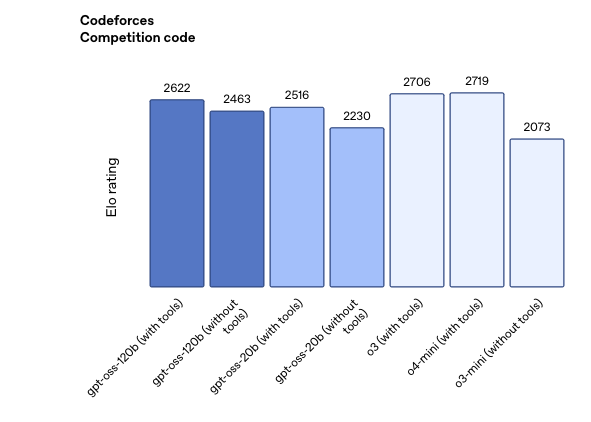
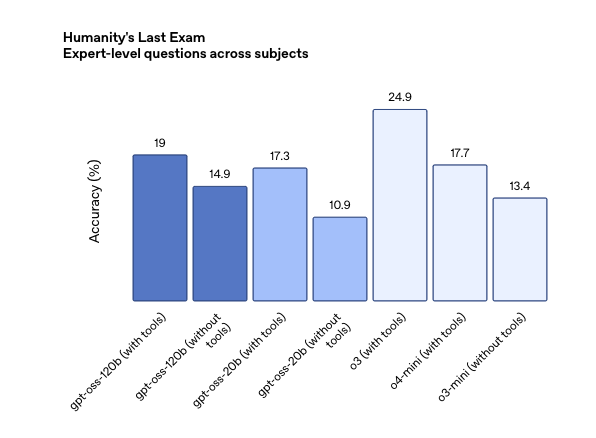
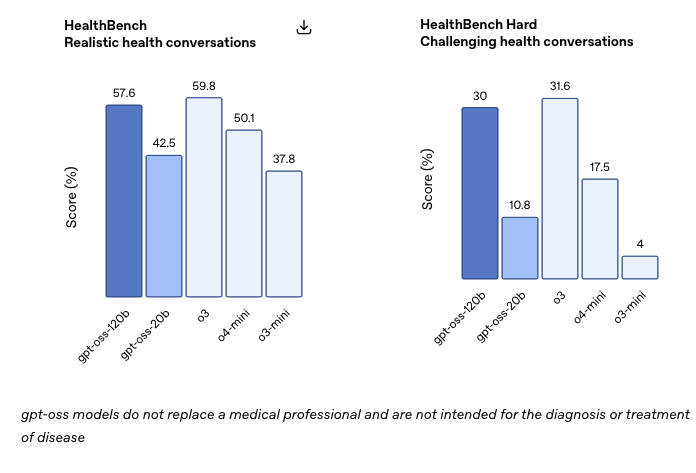
性能表现:与顶级模型看齐
OpenAI对 gpt-oss-120b 和 gpt-oss-20b 在标准学术基准测试中进行了评估,以衡量其在编程、竞赛数学、医疗和智能体工具使用方面的能力,并与其他 OpenAI 推理模型(包括 o3、o3‑mini 和 o4-mini)进行了比较。
Gpt-oss-120b 在竞赛编程 (Codeforces)、通用问题解决 (MMLU 和 HLE) 以及工具调用 (TauBench) 方面表现优于 OpenAI o3‑mini,并与 OpenAI o4-mini 持平或超越其性能。此外,它在健康相关查询 (HealthBench) 和竞赛数学 (AIME 2024 和 2025) 方面表现得比 o4-mini 更好。尽管 gpt-oss-20b 的规模较小,但在这些相同的评估中,它与 OpenAI o3‑mini 持平或超越后者,甚至在竞赛数学和医疗方面表现得更好。
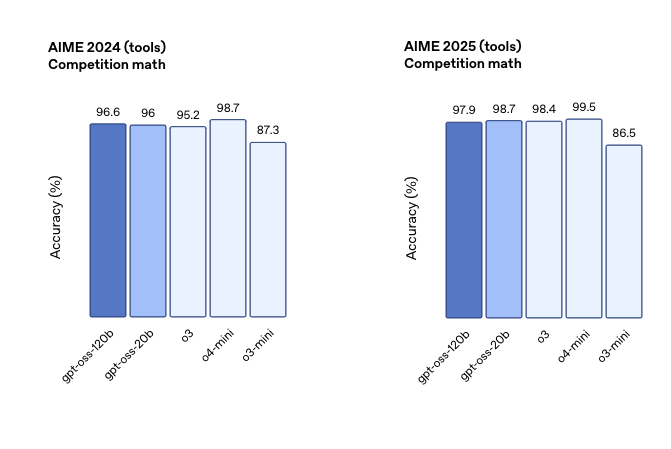
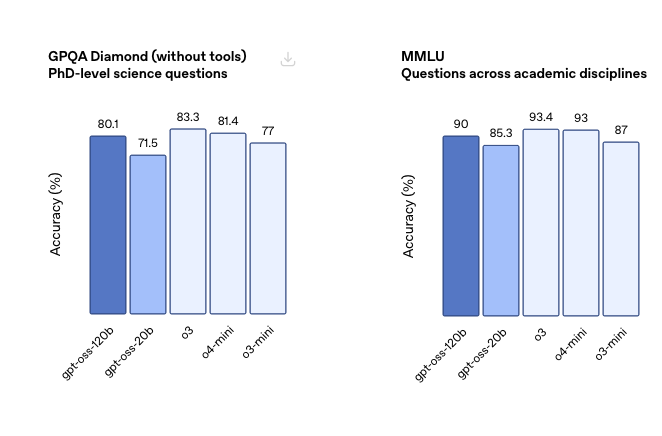
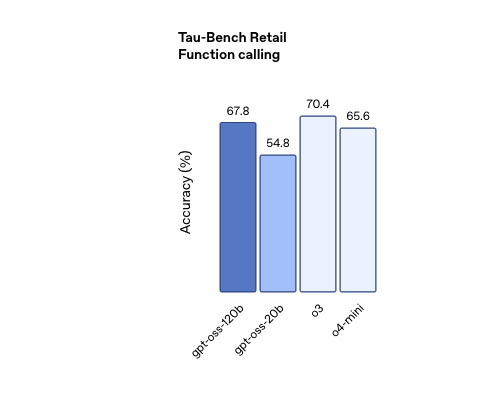
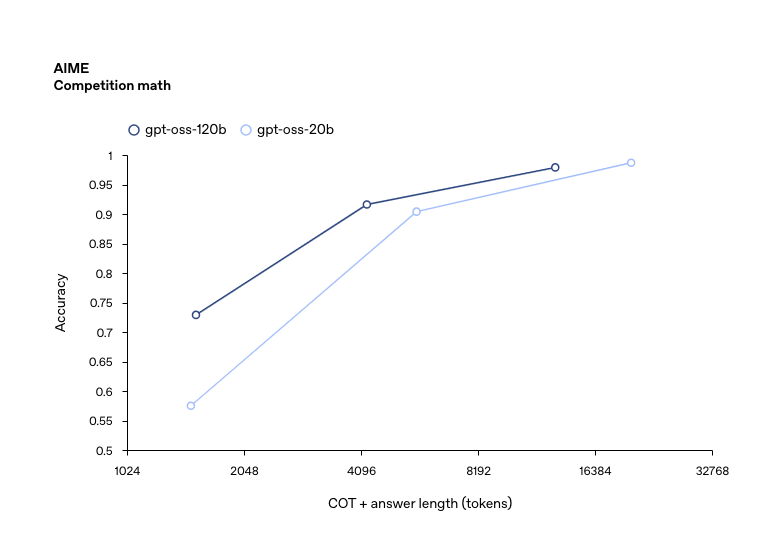
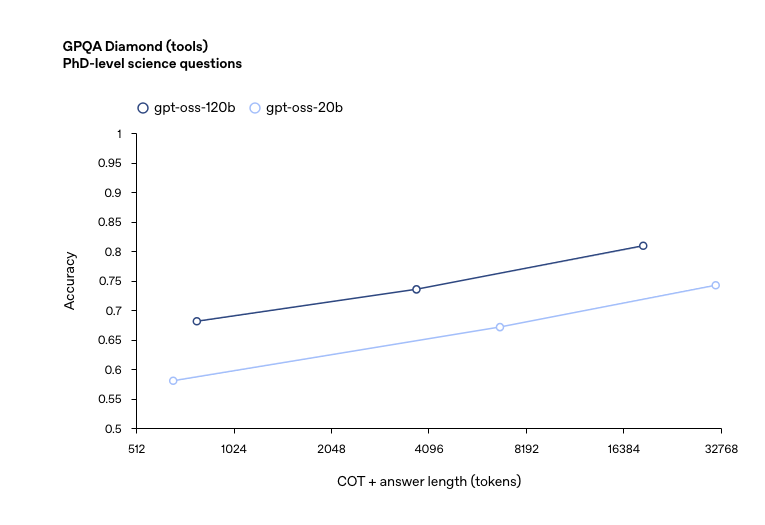
工具使用:智能体时代的需求
现代AI应用越来越需要模型具备工具调用能力,GPT OSS在这方面也做了专门的优化。模型支持内置工具如浏览器和Python解释器,也支持用户自定义的工具。在Tau-Bench工具调用评估中,模型展现出了出色的函数调用能力。
模型的聊天模板提供了灵活的工具集成方案,开发者可以通过简单的参数设置来启用各种工具。当模型需要调用工具时,会生成标准化的工具调用请求,便于系统集成和处理。
def get_current_weather(location: str):
"""Returns the current weather status at a given location as a string.Args:location: The location to get the weather for.
"""return "Terrestrial." # We never said this was a good weather toolchat = [{"role": "user", "content": "What's the weather in Paris right now?"}
]inputs = tokenizer.apply_chat_template(chat, tools=[weather_tool], builtin_tools=["browser", "python"],add_generation_prompt=True,return_tensors="pt"
)
如果模型选择调用某个工具(以 <|call|> 结尾的消息表示),那么您应该将工具调用添加到聊天中,调用该工具,然后将工具结果添加到聊天中并再次生成:
tool_call_message = {"role": "assistant","tool_calls": [{"type": "function","function": {"name": "get_current_temperature", "arguments": {"location": "Paris, France"}}}]
}
chat.append(tool_call_message)tool_output = get_current_weather("Paris, France")tool_result_message = {# Because GPT OSS only calls one tool at a time, we don't# need any extra metadata in the tool message! The template can# figure out that this result is from the most recent tool call."role": "tool","content": tool_output
}
chat.append(tool_result_message)# You can now apply_chat_template() and generate() again, and the model can use
# the tool result in conversation.
部署生态:多样化的选择
OpenAI与Hugging Face等合作伙伴构建了完整的部署生态。用户可以通过Inference Providers服务快速访问模型,支持多个推理提供商如Cerebras、Fireworks AI等。对于本地部署,模型支持transformers、vLLM、llama.cpp等多种推理框架。
在云端部署方面,模型已经集成到Azure AI Model Catalog和Dell Enterprise Hub等企业级平台中,为企业用户提供了安全可靠的部署选项。
from vllm import LLM
llm = LLM("openai/gpt-oss-120b", tensor_parallel_size=2)
output = llm.generate("San Francisco is a")
开源许可:真正的开放
GPT OSS采用Apache 2.0许可证发布,这是一个相当宽松的开源许可证。配套的使用政策也相当简洁,主要要求用户遵守适用法律,这为商业化应用扫清了障碍。
这种开放的许可策略体现了OpenAI对开源生态的重视,也为整个AI社区的发展注入了新的活力。开发者可以自由地使用、修改和分发这些模型,这将促进更多创新应用的出现。
安全考量:负责任的开放
作为一家负责任的AI公司,OpenAI在发布开源模型时也充分考虑了安全因素。模型经过了全面的安全训练和评估,并通过《防范准备框架》进行了额外的安全测试。
GPT OSS在内部安全基准测试中的表现与OpenAI的前沿模型相当,这为开发者提供了可靠的安全保障。同时,OpenAI还与外部专家合作审核了其安全方法论,为开源模型设定了新的安全标准。
展望未来:开源与创新的结合
GPT OSS的发布不仅仅是OpenAI的一个产品发布,更像是整个AI行业的一个转折点。它证明了开源模型也能达到商业级的性能水准,同时为更多开发者和研究者提供了接触前沿AI技术的机会。
随着这些模型的普及,我们有理由相信会看到更多基于GPT OSS的创新应用出现。无论是个人开发者的创意项目,还是企业级的AI解决方案,都将从这次开源中受益。
对于整个AI生态而言,OpenAI的这一举措可能会推动更多公司开放自己的模型,形成良性的竞争与合作氛围。这最终将加速AI技术的普及和应用,让更多人能够享受到AI发展的红利。