【机器学习深度学习】模型量化
目录
前言
一、什么是模型量化?
二、为什么需要模型量化?
三、量化的本质:精度与效率的平衡艺术
四、学术界:量化研究的“花式操作”
✅ 1. 常规量化(FP32 ➝ INT8)
✅ 2. 更极致的位宽压缩
五、工业界:现实中的“量化之路”
✅1、工业界主流选择:INT8 推理 + FP32 训练
✅2、为什么是 INT8?
✅3、工业实现方式:插入 Quantize / Dequantize 层
六、量化类型全览与对比
七、实际部署:量化效果有多好?
八、量化的挑战与未来趋势
❗ 当前挑战
🔮 未来趋势
九、总结一句话
📚 推荐资源:

前言
随着大模型的爆发式增长,部署一个体积庞大、计算密集的神经网络已成为许多企业和开发者的挑战。幸运的是,**模型量化(Quantization)**技术提供了一种无需更改模型结构、即可实现显著加速和压缩的方式,尤其在移动端和边缘设备中表现突出。
本文将围绕量化的基本概念、学术研究、工业落地、常见技术路径与可视化示意,帮你快速全面掌握这一深度学习部署核心技术。
一、什么是模型量化?
当模型精度从32位降至8位,推理速度提升4倍,存储空间减少75%——这就是量化技术创造的AI效率奇迹
模型量化是指:将原本使用高精度浮点数(如 FP32)表示的模型参数与激活值,转换为低精度格式(如 INT8、FP16、INT4 等)表示,从而减少存储、加速计算、节省能耗。
📊 可视化:不同精度的存储需求对比
| 数据类型 | 位宽 | 示例值范围 | 存储成本 | 典型用途 |
|---|---|---|---|---|
| FP32 | 32位 | ±10^38 | ⭐⭐⭐⭐ | 训练 & 推理 |
| FP16 | 16位 | ±6.5×10^4 | ⭐⭐ | 混合精度训练 |
| INT8 | 8位 | -128~127 | ⭐ | 主要用于推理 |
| INT4/2/1 | 更低 | 仅少量状态 | 🌟 | 极限压缩场景 |
二、为什么需要模型量化?
深度学习模型(如ResNet、BERT)通常用32位浮点数(FP32)存储权重,参数量动辄上亿,导致以下问题:
-
内存占用大:模型文件大,手机、嵌入式设备存不下。
-
推理慢:FP32计算量大,延迟高,耗电多。
-
部署难:边缘设备(如IoT、自动驾驶)资源有限,跑不动大模型。
量化通过将高精度(如FP32)转为低精度(如INT8、FP16),大幅降低存储和计算需求。就像把高清视频压缩成标清,既省空间又能快速播放。
三、量化的本质:精度与效率的平衡艺术
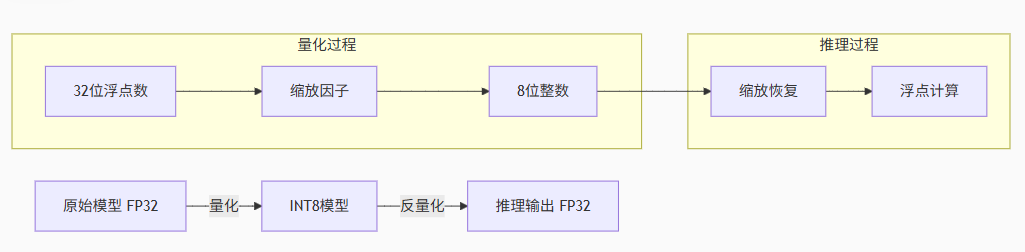
精度对比:
| 格式 | 位数 | 数值范围 | 内存占用 | 计算效率 |
|---|---|---|---|---|
| FP32 | 32 | ±3.4e38 | 100% | 1x |
| FP16 | 16 | ±65504 | 50% | 2-3x |
| INT8 | 8 | [-128, 127] | 25% | 3-4x |
| 二值 | 1 | {0,1}或{-1,1} | 3% | 10x+ |
四、学术界:量化研究的“花式操作”
在学术界,量化被研究得非常深入、精细,甚至演变出了各种极致压缩方案:
✅ 1. 常规量化(FP32 ➝ INT8)
最通用的量化方案
精度损失小,已支持众多平台和框架
✅ 2. 更极致的位宽压缩
| 方法 | 权重取值 | 特点 |
|---|---|---|
| 二值神经网络(BNN) | {-1, +1} | 极限压缩 + 位操作加速 |
| 三值神经网络(Ternary Net) | {-1, 0, +1} | 增强表达能力 |
| XNOR-Net | 输入 + 权重均为二值 | 可用 XNOR 和 Bitcount 实现卷积 |
🔬 研究亮点:极大压缩存储与计算复杂度,理论加速高达 58 倍
🚧 现实问题:精度下降明显,部署复杂,仅适合部分特定任务(如小模型图像分类)
五、工业界:现实中的“量化之路”
✅1、工业界主流选择:INT8 推理 + FP32 训练
目前企业落地最多的是:训练仍用 FP32,高精度确保性能;部署推理时转换为 INT8,以实现加速与压缩
✅2、为什么是 INT8?
-
INT8 精度尚可控制
-
可在大多数硬件上加速计算(尤其是 ARM、NVIDIA、华为昇腾等)
-
框架支持完善:TensorRT、ONNX、PyTorch、TensorFlow Lite 都已支持 INT8 推理
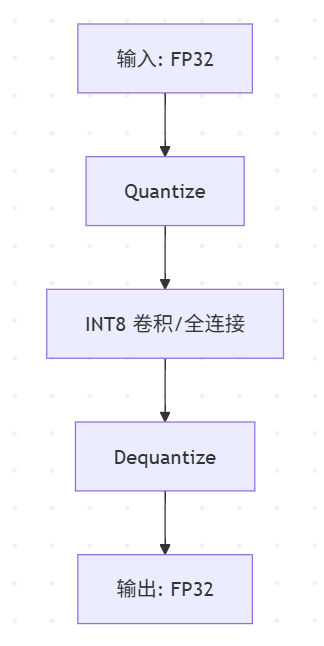
✅3、工业实现方式:插入 Quantize / Dequantize 层
一般不会直接替换网络中的操作,而是:
-
将输入张量通过
Quantize转为 INT8; -
在算子内部以 INT8 计算;
-
输出再通过
Dequantize转回 FP32。
📉 图示建议:模型量化结构流程图
六、量化类型全览与对比
| 类型 | 简述 | 代表应用 |
|---|---|---|
| 后训练量化(PTQ) | 模型训练完再静态转换为 INT8 | 快速部署,对精度要求较低 |
| 量化感知训练(QAT) | 训练中加入量化噪声,模拟 INT8 过程 | 精度更高,适合精度敏感任务 |
| 动态量化 | 仅在推理过程中动态将权重转换为 INT8 | 适合 LSTM、Transformer 模型 |
| 混合精度训练(Mixed FP16) | FP32+FP16 混合,训练速度提升内存减半 | 训练阶段常用,精度影响小 |
七、实际部署:量化效果有多好?
以 ResNet50 为例,对比三种精度下的存储与推理性能:
| 模型 | 精度类型 | 大小(MB) | 延迟(ms) | 精度下降 |
|---|---|---|---|---|
| ResNet50 | FP32 | 97 | 85 | - |
| ResNet50 | FP16 | 48 | 63 | <1% |
| ResNet50 | INT8 | 24 | 42 | <2% |
📌 实际加速依赖硬件支持,INT8 常见于 ARM、GPU Tensor Core、Edge TPU 等。
八、量化的挑战与未来趋势
❗ 当前挑战
-
精度下降(尤其是小模型、复杂任务)
-
不同硬件支持差异大(尤其 INT4 以下)
-
算子支持不完整(如自定义层可能不支持 INT8)
🔮 未来趋势
-
自动化量化工具链完善(如 PyTorch Export Quantization Config)
-
更细粒度的混合精度策略
-
联合蒸馏、剪枝、多目标优化实现综合压缩效果
九、总结一句话
模型量化是工业界最成熟、最通用的模型压缩技术,尤其 INT8 推理已成为边缘部署的首选标准。
📚 推荐资源:
-
NVIDIA TensorRT INT8 文档
-
PyTorch 量化官方指南
-
Google XNOR-Net 论文
-
Mixed Precision Training 论文