埋点技术进阶:如何构建高效的数据采集架构
埋点技术作为数据采集的关键手段,其重要性不言而喻。传统的埋点技术在面对大规模数据采集时,常常会遇到性能瓶颈、数据丢失等问题。因此,构建一个高效、可靠且可扩展的数据采集架构显得尤为重要。高效的数据采集架构不仅能确保数据的准确性和完整性,还能提升系统的性能和可扩展性。本文中,嗨数君将从数据源、数据传输、数据存储到架构设计原则,为你提供一套完整的解决方案。
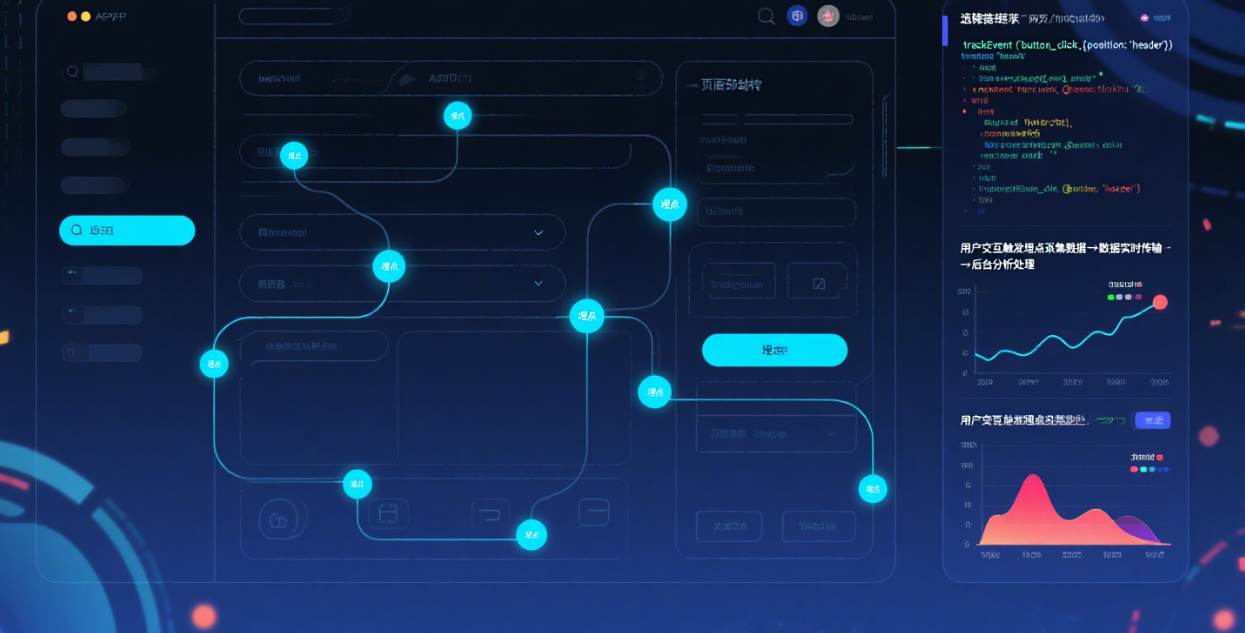
一、数据采集架构的组成部分
(一)数据源
数据源是数据采集的起点,主要包括前端埋点、后端埋点和日志数据。
前端埋点:前端埋点主要通过JavaScript代码嵌入网页或移动应用中,捕获用户的行为数据,如点击、滑动、停留时间等。前端埋点的优势在于能够直接获取用户的行为细节,但需要考虑代码的兼容性和性能优化。
后端埋点:后端埋点则通过服务器端的代码实现,捕获用户的请求和响应数据。后端埋点的优势在于数据的完整性和准确性,但需要与前端埋点配合,以避免数据重复采集。
日志数据:日志数据是系统运行过程中产生的记录,包括访问日志、错误日志等。日志数据的采集通常通过日志收集工具(如Logstash、Fluentd)实现,能够提供系统的运行状态和异常信息。
(二)数据传输
数据传输是数据采集的关键环节,其主要目的是将数据从数据源传输到数据存储系统。常见的数据传输方式包括HTTP协议、WebSocket协议和消息队列。
HTTP协议:HTTP协议是最常用的数据传输方式,适用于前端埋点数据的传输。HTTP协议的优点是简单易用,缺点是每次传输都需要建立连接,效率较低。
WebSocket协议:WebSocket协议是一种基于TCP的全双工通信协议,适用于实时数据传输。WebSocket协议的优点是能够保持长连接,减少连接开销,但对服务器的并发处理能力要求较高。
消息队列:消息队列(如Kafka、RabbitMQ)是一种高效的异步数据传输方式,适用于大规模数据的采集和处理。消息队列的优点是能够缓冲数据,提高系统的吞吐量和可靠性,但需要额外的运维成本。
(三)数据存储
数据存储是数据采集的终点,其主要目的是将采集到的数据持久化存储,以便后续的分析和处理。常见的数据存储方式包括关系型数据库、NoSQL数据库和数据仓库。
关系型数据库:关系型数据库(如MySQL、PostgreSQL)适用于结构化数据的存储和查询,具有强大的事务处理能力和数据一致性保证。关系型数据库的优点是易于理解和使用,缺点是扩展性较差。
NoSQL数据库:NoSQL数据库(如MongoDB、Redis)适用于非结构化或半结构化数据的存储,具有高扩展性和高性能。NoSQL数据库的优点是能够处理大规模数据,缺点是数据一致性较弱。
数据仓库:数据仓库(如Hadoop、ClickHouse)是一种用于数据存储和分析的分布式系统,适用于大规模数据的存储和复杂查询。数据仓库的优点是能够处理海量数据,缺点是部署和维护成本较高。
二、高效数据采集架构的设计原则
(一)可扩展性
可扩展性是指系统能够随着数据量和用户量的增加而进行扩展,以满足不断增长的需求。常见的扩展方式包括水平扩展和垂直扩展。
水平扩展:水平扩展是指通过增加服务器数量来提升系统的处理能力。水平扩展的优点是能够灵活应对数据量的增长,缺点是需要解决数据一致性问题。
垂直扩展:垂直扩展是指通过提升单台服务器的性能(如增加CPU、内存)来提升系统的处理能力。垂直扩展的优点是简单直接,缺点是存在硬件瓶颈。
(二)高可用性
高可用性是指系统能够在各种故障情况下保持正常运行,确保数据的持续采集和存储。常见的高可用性设计包括冗余设计和故障转移。
冗余设计:冗余设计是指通过增加冗余节点来提高系统的可靠性。冗余设计的优点是能够避免单点故障,缺点是增加了系统的复杂性。
故障转移:故障转移是指在系统出现故障时,能够自动切换到备用节点,确保系统的正常运行。故障转移的优点是能够减少故障对系统的影响,缺点是需要复杂的故障检测和切换机制。
(三)低延迟
低延迟是指系统能够快速响应数据采集请求,确保数据的实时性。低延迟的设计需要从数据传输和数据存储两个方面入手。
数据传输优化:通过选择合适的数据传输方式(如WebSocket协议、消息队列)和优化网络配置,减少数据传输的延迟。
数据存储优化:通过选择高性能的数据存储系统(如NoSQL数据库、数据仓库)和优化数据存储结构,提高数据存储和查询的效率。
三、技术选型
在构建高效的数据采集架构时,技术选型至关重要。以下是一些常见的技术选型及其应用场景。
消息队列是高效数据采集架构中的关键组件,能够缓冲数据,提高系统的吞吐量和可靠性。常见的消息队列包括Kafka和RabbitMQ。
Kafka:Kafka是一种高吞吐量的分布式消息队列,适用于大规模数据的采集和处理。Kafka的优点是能够处理海量数据,支持高并发,缺点是运维成本较高。
RabbitMQ:RabbitMQ是一种功能强大的消息队列,支持多种消息协议和复杂的路由规则。RabbitMQ的优点是易于使用,支持多种语言,缺点是性能相对较低。
在实际应用中,技术人员需要根据自身的需求和资源情况,灵活选择合适的技术方案。同时,持续关注技术的发展动态,不断优化和完善数据采集架构,以应对不断变化的数据需求。