CoRL-2025 | 北大“如影随形”具身导航智能体!TrackVLA:复杂自然环境中的具身视觉跟踪


- 作者:Shaoan Wang1,2^{1,2}1,2, Jiazhao Zhang1,2^{1,2}1,2, Minghan Li2^{2}2, Jiahang Liu2^{2}2, Anqi Li1,2^{1,2}1,2, Kui Wu3^{3}3, Fangwei Zhong4^{4}4, Junzhi Yu1^{1}1, Zhizheng Zhang2,5^{2,5}2,5, He Wang1,2,5^{1,2,5}1,2,5
- 单位:1^{1}1北京大学,2^{2}2加尔博特,3^{3}3北京航空航天大学,4^{4}4北京师范大学,5^{5}5北京人工智能研究院
- 论文标题:TrackVLA: Embodied Visual Tracking in the Wild
- 论文链接:http://arxiv.org/abs/2505.23189
- 项目主页:https://pku-epic.github.io/TrackVLA-web/
- 代码链接:https://github.com/wsakobe/TrackVLA
主要贡献
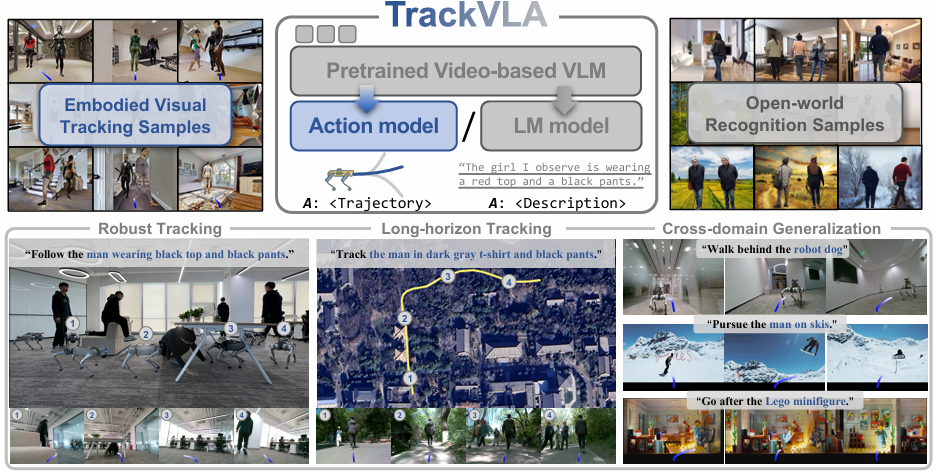
- 提出用于“具身视觉跟踪”任务的视觉-语言-行动模型TrackVLA,能够同时输出跟踪轨迹和基于文本的响应。
- 构建了一个大规模数据集,包含 855K 具身视觉跟踪样本和 855K 开放世界识别样本,用于训练 TrackVLA,使其学习视觉跟踪和目标识别之间的协同作用。
- 通过大量实验表明 TrackVLA 在模拟环境中实现了顶尖性能,并且具备强大的泛化能力,能够以零样本(zero-shot)的方式部署到现实场景中。
研究背景
- 具身视觉跟踪的重要性:具身视觉跟踪是具身智能(Embodied AI)中的一个基本技能,能够让智能体在动态环境中仅依靠自身视角(egocentric vision)跟踪特定目标,在机器人领域有广泛的应用需求。
- 任务的挑战性:该任务极具挑战性,因为它依赖于两个紧密耦合的技能——目标识别(准确识别并区分目标)和轨迹规划(确定最优动作以有效跟踪)。在严重遮挡和高度动态场景等复杂条件下,这种耦合关系更加难以处理。
- 现有方法的局限性:以往的方法通常将识别和规划模块分离,通过检测模型和规划模型分别解决。虽然取得了一定进展,但受限于类别级跟踪且只能在相对开阔的区域使用,因为这种分离设计会导致识别模型和规划模型之间的误差累积。
方法
具身视觉跟踪任务定义
- 在每个时间戳 TTT,给定一个自然语言指令 III(描述特定目标的外观)和一系列 egocentric RGB 观测 OT={x1,…,xT}O_T = \{x_1, \dots, x_T\}OT={x1,…,xT},智能体需要输出下一个动作 aT∈A={v,ω}a_T \in A = \{v, \omega\}aT∈A={v,ω},以持续跟踪描述中的目标。
- 动作空间 AAA 包括智能体的线速度 vvv 和角速度 ω\omegaω。任务成功与否取决于智能体是否能够持续保持与目标的适当距离(1–3 米)并面向目标。
TrackVLA 模型架构
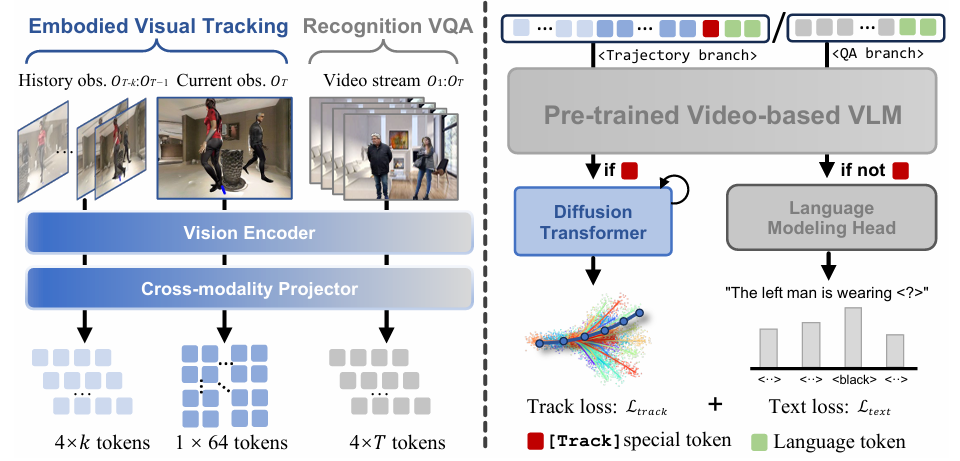
观察编码
- 输入:给定 egocentric RGB 序列 OT={x1,…,xT}O_T = \{x_1, \dots, x_T\}OT={x1,…,xT}。
- 视觉特征提取:使用预训练的视觉编码器(EVA-CLIP)提取视觉特征 V1:T∈RN×CV_{1:T} \in \mathbb{R}^{N \times C}V1:T∈RN×C,其中 NNN 是 patch 数量(设置为 256),CCC 是嵌入维度。
- 网格池化策略:为了生成更紧凑的表示,采用网格池化策略,生成细粒度和粗粒度的视觉特征:
- 细粒度特征 Vfine∈R64×CV_{\text{fine}} \in \mathbb{R}^{64 \times C}Vfine∈R64×C:用于最新的跟踪观测,增强目标识别。
- 粗粒度特征 Vcoarse∈R4×CV_{\text{coarse}} \in \mathbb{R}^{4 \times C}Vcoarse∈R4×C:用于历史跟踪和基于 VQA 的识别任务。
- 滑动窗口机制:为了保持一致的推理速度,使用滑动窗口机制仅保留最新的 kkk 帧(在实现中设置为 32 帧)。
- 视觉token序列构建:
- 对于具身视觉跟踪任务:VtrackT={VcoarseT−k,…,VcoarseT−1,VfineT}V_{\text{track}}^T = \{V_{\text{coarse}}^{T - k}, \dots, V_{\text{coarse}}^{T - 1}, V_{\text{fine}}^T\}VtrackT={VcoarseT−k,…,VcoarseT−1,VfineT}。
- 对于视频问答(VQA)识别任务:VVQAT={Vcoarse1,…,VcoarseT}V_{\text{VQA}}^T = \{V_{\text{coarse}}^1, \dots, V_{\text{coarse}}^T\}VVQAT={Vcoarse1,…,VcoarseT}。
- 跨模态投影:使用一个两层的 MLP(多层感知机)作为跨模态投影器 P(⋅)P(\cdot)P(⋅),将视觉特征投影到大型语言模型的潜在空间中:EVT=P(VT)E_V^T = P(V_T)EVT=P(VT)。
大型语言模型前向传播
- 输入构建:将视觉token EVTE_V^TEVT 与语言token EIE_IEI 拼接,并在跟踪任务中添加特殊 [Track] token,然后输入到 LLM 中。
- 预测token:LLM 输出预测token EpredTE_{\text{pred}}^TEpredT,根据任务类型(是否包含 [Track] token)进行不同的处理:
- 目标识别任务:使用标准的语言建模头自回归地解码预测token,生成词汇答案。
- 轨迹规划任务:将预测token作为条件输入到动作模型中,生成导航轨迹。
基于锚点的扩散动作模型
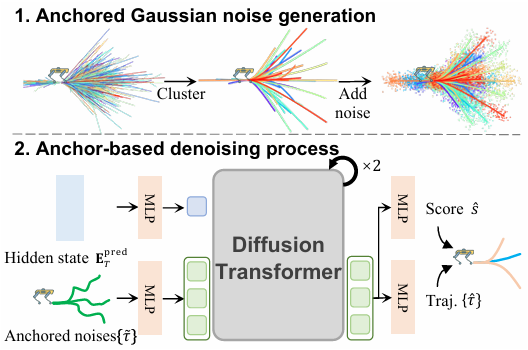
- 锚点生成:从训练数据中收集所有轨迹,并使用 K-means 聚类得到一组轨迹锚点 {τi}i=1M\{\tau_i\}_{i=1}^M{τi}i=1M,其中 MMM 是锚点数量,每个锚点 τi=(xi,yi,θi)i=1Nw\tau_i = (x_i, y_i, \theta_i)_{i=1}^{N_w}τi=(xi,yi,θi)i=1Nw 表示一个机器人轨迹模式,NwN_wNw 是每个轨迹中的航点数量。
- 噪声锚点生成:对每个锚点添加高斯噪声,生成噪声锚点 {τ~i}i=1M\{\tilde{\tau}_i\}_{i=1}^M{τ~i}i=1M。
- 动作模型输入:动作模型 Aθ(⋅)A_\theta(\cdot)Aθ(⋅) 以噪声锚点 {τ~i}i=1M\{\tilde{\tau}_i\}_{i=1}^M{τ~i}i=1M 和条件 EpredTE_{\text{pred}}^TEpredT 作为输入,输出去噪后的轨迹 {τ^i}i=1M\{\hat{\tau}_i\}_{i=1}^M{τ^i}i=1M 和对应的轨迹分类分数 {s^i}i=1M\{\hat{s}_i\}_{i=1}^M{s^i}i=1M:
{s^i,τ^i}i=1M=Aθ({τ~i}i=1M,EpredT) \{\hat{s}_i, \hat{\tau}_i\}_{i=1}^M = A_\theta \left( \{\tilde{\tau}_i\}_{i=1}^M, E_{\text{pred}}^T \right) {s^i,τ^i}i=1M=Aθ({τ~i}i=1M,EpredT) - 标签分配:将最接近真实轨迹 τgt\tau_{\text{gt}}τgt 的锚点轨迹标记为正样本(snearest=1s_{\text{nearest}} = 1snearest=1),其余标记为负样本(selse=0s_{\text{else}} = 0selse=0)。
- 损失函数:跟踪损失 LtrackL_{\text{track}}Ltrack 定义为:
Ltrack=∑i=1M[si⋅MSE(τ^i,τgt)+λ⋅BCE(s^i,si)] L_{\text{track}} = \sum_{i=1}^M \left[ s_i \cdot \text{MSE}(\hat{\tau}_i, \tau_{\text{gt}}) + \lambda \cdot \text{BCE}(\hat{s}_i, s_i) \right] Ltrack=i=1∑M[si⋅MSE(τ^i,τgt)+λ⋅BCE(s^i,si)]
其中,λ\lambdaλ 是平衡参数。整体训练损失 LLL 是跟踪损失 LtrackL_{\text{track}}Ltrack 和文本预测损失 LtextL_{\text{text}}Ltext 的加权组合:
L=Ltrack+αLtext L = L_{\text{track}} + \alpha L_{\text{text}} L=Ltrack+αLtext
实现细节
- 训练细节:遵循视觉 - 语言建模(VLM)的标准实践,仅训练一个 epoch,并且在整个训练过程中冻结视觉编码器的参数。
- 推理细节:在推理过程中,使用特殊 [Track] token指示当前任务。如果存在 [Track] token,LLM 仅执行单步自回归,并将输出隐藏状态传递给动作模型以预测轨迹。对于 VQA 任务,LLM 执行完整的自回归解码以根据视觉观测回答问题。
数据收集
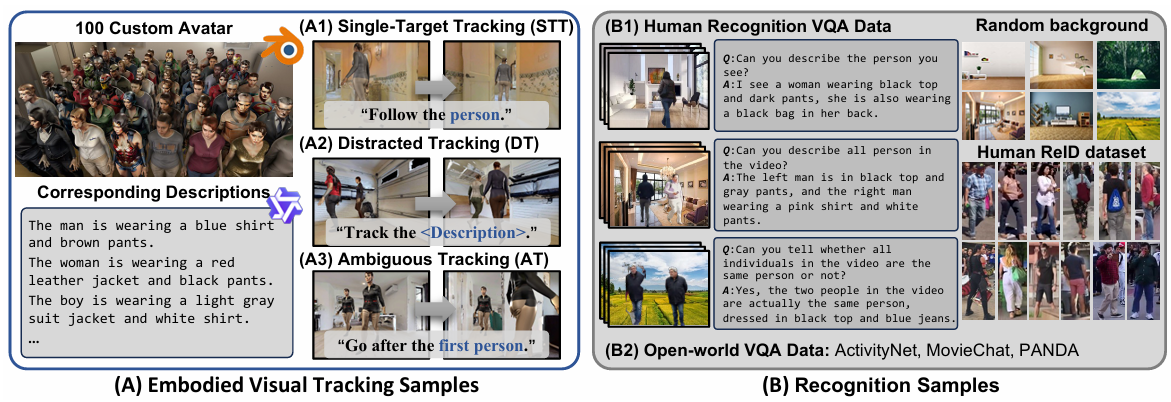
为了训练 TrackVLA 模型,论文收集了两种类型的数据:
- 具身视觉跟踪数据:用于训练模型的跟踪能力。
- 视频问答数据:用于增强模型的目标识别能力。

具身视觉跟踪数据
具身视觉跟踪模拟器
- 基于 Habitat 3.0:使用 Habitat 3.0 模拟器作为基础,提供了碰撞检测和渲染功能。
- 人形化身生成:
- 使用 SMPL-X 人类模型 生成多样化的人形化身。
- 随机初始化化身的形状和纹理贴图(使用 ATLAS 数据集)。
- 使用 Qwen-VL2.5 模型为每个化身生成对应的文本描述。
- 自然人类行为:
- 为每个化身分配一系列目标点,使其按顺序到达。
- 行走速度随机采样自自然人类行走速度范围(1.0 m/s - 1.5 m/s)。
- 使用 ORCA 算法实现动态碰撞避免和响应式交互,使行为更加自然。
具身视觉跟踪基准测试
-
数据集构建:
- 生成 100 个多样化的人形化身 和对应的描述。
- 使用 804 个场景环境(来自 HM3D 和 MP3D 数据集)。
- 生成 25,986 个剧集,分为训练集(21,771 个剧集,703 个场景)和测试集(4,215 个剧集,101 个未见场景)。
-
任务分类:
- 单目标跟踪(Single-Target Tracking, STT):简单指令,如“跟随人/男人/女人”。
- 干扰跟踪(Distracted Tracking, DT):需要识别目标的细粒度描述,如“跟随穿着黑色西装、白色腰带的浅色皮肤男人”。
- 模糊跟踪(Ambiguity Tracking, AT):在存在外观相同的干扰项时识别正确目标,如“跟随你首先看到的人”。
-
数据收集:
- 收集 885K 个具身视觉跟踪样本,覆盖上述三种任务。
- 每个样本包括导航历史(RGB 序列)、目标描述和专家轨迹 τgt\tau_{\text{gt}}τgt。
视频问答数据
为了增强 TrackVLA 的开放世界识别能力,论文还收集了 855K 个识别样本,具体如下:
人类识别 VQA 数据
- 数据来源:基于 SYNTH-PEDES 数据集构建。
- 数据构建:
- 随机选择 1-3 张人类图像,放置在多样化的背景上。
- 生成的样本包含对每个个体的属性描述、相对空间位置以及是否为同一身份的描述。
开放世界 VQA 数据
- 数据来源:使用公开的 VQA 数据集(如 ActivityNet、MovieChat、PANDA)。
- 数据作用:提供开放世界的描述,增强 TrackVLA 对未见目标的识别能力。
实验
实验设置
- 基准测试:在公共基准测试 Gym-UnrealCV 上进行零样本评估,以及在自建的 EVT-Bench 上进行评估。
- 基线方法:与多种现有顶尖方法进行比较,包括基于模型的方法 IBVS、基于强化学习(RL)的方法(如 DiMP、SARL、AD-VAT 等)和基于模仿学习(IL)的方法 Uni-NaVid。
- 评估指标:采用 Gym-UnrealCV 和 EVT-Bench 的标准评估指标,包括成功率(SR)、平均剧集长度(EL)、跟踪率(TR)和碰撞率(CR)。
定量比较结果
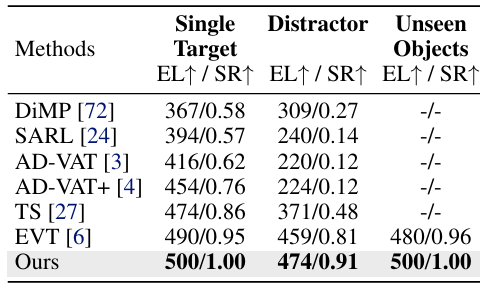
- 在 Gym-UnrealCV 上的零样本性能:TrackVLA 在单目标跟踪和未见目标对象任务上成功跟踪目标达整个任务时长(500 步),在更具挑战性的干扰任务中也超越了之前的顶尖方法 EVT,在平均剧集长度上提升了 3.25%,成功率提升了 12.3%。
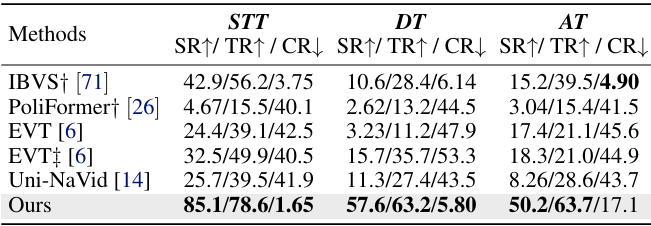
- 在 EVT-Bench 上的性能:TrackVLA 在所有三个任务(STT、DT 和 AT)中均显著优于现有方法,与 VLA 方法 Uni-NaVid 相比有明显提升,但在从单目标跟踪过渡到干扰跟踪和模糊跟踪时性能有所下降,说明在复杂环境中准确识别并跟踪指定目标仍具挑战性。
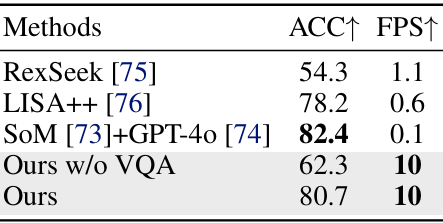
- 目标识别性能:TrackVLA 在区分 SYNTH-PEDES 中随机选择的未见人类图像对的识别任务上,与顶尖的视觉语言模型(VLM)进行比较,准确率达到 80.7%,且推理速度达到 10 FPS,比基于 GPT 的基线快约 100 倍,且与 VQA 样本共同微调后识别性能显著提升 29.53%。
定性结果

在现实世界中展示了 TrackVLA 在复杂场景(如杂乱环境、低光照条件、追捕 - 逃避任务和多人识别)中的定性结果,证明了 TrackVLA 在现实世界场景中具有强大的从模拟到现实的迁移能力,能够在高度动态环境中实现零样本部署。
消融研究
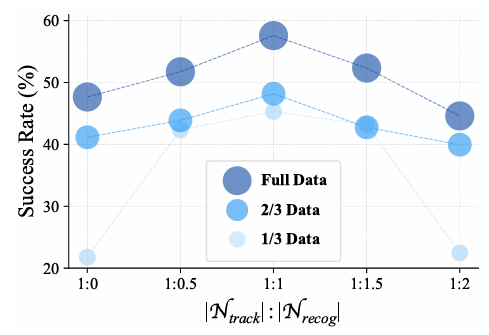
- 数据规模和数据比例:在 EVT-Bench 的 DT 任务上进行消融实验,发现增加训练样本规模能持续提升性能,且 1:1 的数据比例(具身视觉跟踪样本与开放世界识别样本)表现最佳,可能是因为更平衡的梯度更新。
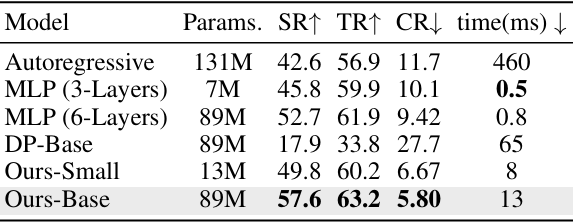
- 动作模型架构:对不同动作模型在 DT 任务上的性能进行评估,结果表明 TrackVLA 所采用的基于锚点的扩散模型在所有指标上均优于自回归模型、多层感知机(MLP)和普通扩散策略等现有基线,且随着扩散变换器(DiT)骨干网络的扩展,动作模型性能持续提升,显示出扩散变换器动作模型的可扩展性。
结论与未来工作
- 结论:
- TrackVLA 是一个为具身视觉跟踪任务设计的视觉 - 语言 - 行动(VLA)模型,通过在大规模具身视觉跟踪数据和开放世界识别数据上联合训练,实现了视觉跟踪和目标识别之间的协同作用,展现出强大的模拟到现实的泛化能力,能够在现实世界场景中实现零样本部署。
- 未来工作:
- 尽管 TrackVLA 表现良好,但仍存在一些局限性。例如,当前方法仅依赖于 egocentric 观测,导致 TrackVLA 的视野较窄(通常为 90°视场角),未来可以考虑整合全景或多视角输入以增强跟踪鲁棒性;
- 此外,当前方法仅使用了航点控制器,缺乏更灵活的局部运动控制器,未来可以考虑引入此类控制器以提高移动速度并扩大可达区域。
