kafka部署集群模式
Kafka部署(3.7)
生产环境推荐的kafka部署方式为operator方式部署,Strimzi是目前最主流的operator方案。集群数据量较小的话,可以采用NFS共享存储,数据量较大的话可使用local pv存储
部署operator
operator部署方式为helm或yaml文件部署,此处以helm方式部署为例:
必须优先部署operator (版本要适配否则安装不上kafka)
注意:0.45以上不在支持zk
helm pull strimzi/strimzi-kafka-operator --version 0.42.0
tar -zxf strimzi-kafka-operator-helm-3-chart-0.42.0.tgz
ls
helm install strimzi ./strimzi-kafka-operator -n kafka --create-namespace

查看示例文件
Strimzi官方仓库提供了各种场景下的示例文件,资源清单下载地址:https://github.com/strimzi/strimzi-kafka-operator/releases
strimzi-0.42.0.tar.gz
tar 解压

/root/lq-service/kafka/strimzi-0.42.0/examples/kafka

kafka-persistent.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的持久集群。(推荐)
kafka-jbod.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点(每个节点使用多个持久卷)的持久集群。
kafka-persistent-single.yaml:部署具有单个 ZooKeeper 节点和单个 Kafka 节点的持久集群。
kafka-ephemeral.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的临时群集。
kafka-ephemeral-single.yaml:部署具有三个 ZooKeeper 节点和一个 Kafka 节点的临时群集。
创建pvc资源
[root@tiaoban kafka]# cat kafka-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-my-cluster-zookeeper-0namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-my-cluster-zookeeper-1namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-my-cluster-zookeeper-2namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-0-my-cluster-kafka-0namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-0-my-cluster-kafka-1namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: data-0-my-cluster-kafka-2namespace: kafka
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 100Gi
部署kafka和zookeeper
参考官方仓库的kafka-persistent.yaml示例文件,部署三个 ZooKeeper 和三个 Kafka 节点的持久集群。kafka-persistent.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:name: my-cluster
spec:kafka:version: 3.7.1replicas: 3listeners:- name: plainport: 9092type: internaltls: false- name: tlsport: 9093type: internaltls: trueconfig:offsets.topic.replication.factor: 3transaction.state.log.replication.factor: 3transaction.state.log.min.isr: 2default.replication.factor: 3min.insync.replicas: 2inter.broker.protocol.version: "3.7"storage:type: jbodvolumes:- id: 0type: persistent-claimsize: 10GideleteClaim: falsezookeeper:replicas: 3storage:type: persistent-claimsize: 10GideleteClaim: falseentityOperator:topicOperator: {}userOperator: {}kubectl apply -f kafka-persistent.yaml
kubectl get po -n kafka
访问验证
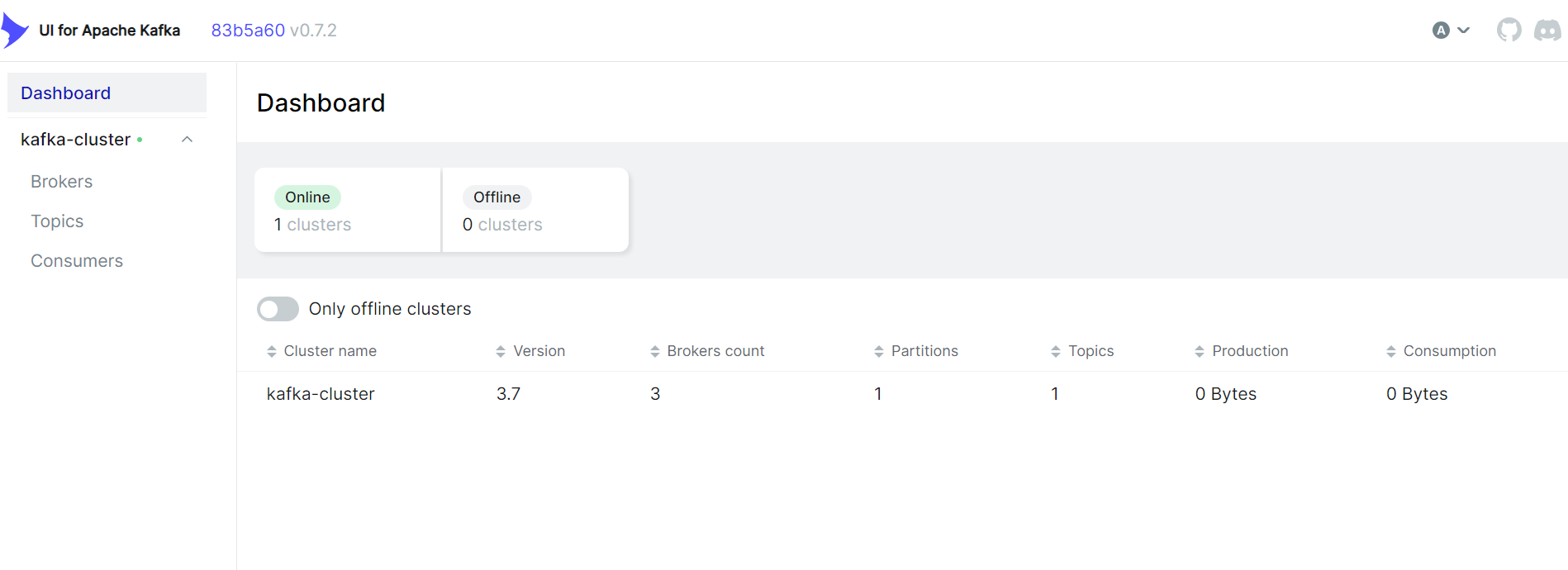
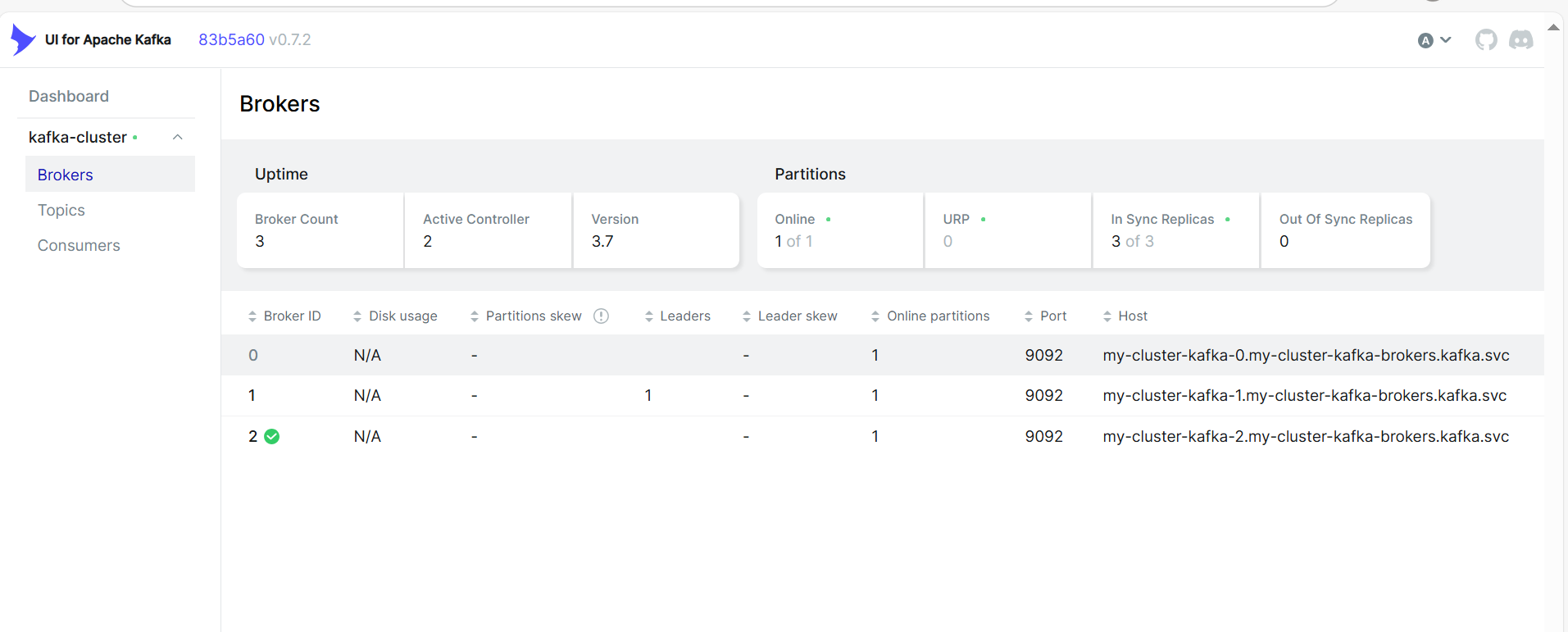
查看资源信息,已成功创建相关pod和svc资源。


部署kafka-ui
创建configmap和ingress资源,在configmap中指定kafka连接地址。以traefik为例,创建ingress资源便于通过域名方式访问。
需要先授权
traefik.containo.us_ingressroutes.yaml.yaml
地址:https://raw.githubusercontent.com/traefik/traefik/v2.6/docs/content/reference/dynamic-configuration/traefik.containo.us_ingressroutes.yaml
[root@021rjsh216171s kafka]# cat kafka-ui.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: kafka-ui-helm-valuesnamespace: kafka
data:KAFKA_CLUSTERS_0_NAME: "kafka-cluster"KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: "my-cluster-kafka-brokers.kafka.svc:9092"AUTH_TYPE: "DISABLED"MANAGEMENT_HEALTH_LDAP_ENABLED: "FALSE"
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:name: kafka-uinamespace: kafka
spec:entryPoints:- webroutes:- match: Host(`kafka-ui.local.com`) 域名kind: Ruleservices:- name: kafka-uiport: 80
helm方式部署kafka-ui并指定配置文件
helm repo add kafka-ui https://provectus.github.io/kafka-ui
helm install kafka-ui kafka-ui/kafka-ui -n kafka --set existingConfigMap="kafka-ui-helm-values"